Scrapy-redis
scrapy-redis是一个基于redis的scrapy组件,通过它可以快速实现简单分布式爬虫程序,该组件本质上提供了三大功能:
- scheduler - 调度器
- dupefilter - URL去重规则(被调度器使用)
- pipeline - 数据持久化
1.用redis去重url


# ############### scrapy redis连接 #################### REDIS_HOST = '140.143.227.206' # 主机名 REDIS_PORT = 8888 # 端口 REDIS_PARAMS = {'password':'beta'}# Redis连接参数 # 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,}) REDIS_ENCODING = "utf-8" # redis编码类型 默认:'utf-8' # REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置) DUPEFILTER_KEY = 'dupefilter:%(timestamp)s' # DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' DUPEFILTER_CLASS = 'dbd.xxx.RedisDupeFilter'
from scrapy.dupefilter import BaseDupeFilter import redis from scrapy.utils.request import request_fingerprint import scrapy_redis class DupFilter(BaseDupeFilter): def __init__(self): self.conn = redis.Redis(host='140.143.227.206',port=8888,password='beta') def request_seen(self, request): """ 检测当前请求是否已经被访问过 :param request: :return: True表示已经访问过;False表示未访问过 """ fid = request_fingerprint(request) result = self.conn.sadd('visited_urls', fid) if result == 1: return False return True from scrapy_redis.dupefilter import RFPDupeFilter from scrapy_redis.connection import get_redis_from_settings from scrapy_redis import defaults class RedisDupeFilter(RFPDupeFilter): @classmethod def from_settings(cls, settings): """Returns an instance from given settings. This uses by default the key ``dupefilter:<timestamp>``. When using the ``scrapy_redis.scheduler.Scheduler`` class, this method is not used as it needs to pass the spider name in the key. Parameters ---------- settings : scrapy.settings.Settings Returns ------- RFPDupeFilter A RFPDupeFilter instance. """ server = get_redis_from_settings(settings) # XXX: This creates one-time key. needed to support to use this # class as standalone dupefilter with scrapy's default scheduler # if scrapy passes spider on open() method this wouldn't be needed # TODO: Use SCRAPY_JOB env as default and fallback to timestamp. key = defaults.DUPEFILTER_KEY % {'timestamp': 'xiaodongbei'} #时间戳字符串格式化 debug = settings.getbool('DUPEFILTER_DEBUG') return cls(server, key=key, debug=debug)
基于redis的有序集合实现队列
import redis class PriorityQueue(object): """Per-spider priority queue abstraction using redis' sorted set""" def __init__(self): self.server = redis.Redis(host='140.143.227.206',port=8888,password='beta') def push(self, request,score): """Push a request""" # data = self._encode_request(request) # score = -request.priority # We don't use zadd method as the order of arguments change depending on # whether the class is Redis or StrictRedis, and the option of using # kwargs only accepts strings, not bytes. self.server.execute_command('ZADD', 'xxxxxx', score, request) def pop(self, timeout=0): """ Pop a request timeout not support in this queue class """ # use atomic range/remove using multi/exec pipe = self.server.pipeline() pipe.multi() pipe.zrange('xxxxxx', 0, 0).zremrangebyrank('xxxxxx', 0, 0) results, count = pipe.execute() if results: return results[0] q = PriorityQueue() q.push('alex',99) q.push('oldboy',56) q.push('eric',77) v1 = q.pop() print(v1) v2 = q.pop() print(v2) v3 = q.pop() print(v3)
2、调度器
scrapy-redis中的调度器是如何实现的?
将请求通过pickle进行序列化,然后添加到redis:列表
或者有序集合中.(根据配置文件)
SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat"
# ############### scrapy redis连接 #################### REDIS_HOST = '140.143.227.206' # 主机名 REDIS_PORT = 8888 # 端口 REDIS_PARAMS = {'password':'beta'} # Redis连接参数 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,}) REDIS_ENCODING = "utf-8" # redis编码类型 默认:'utf-8' # REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置) ################ 去重 ###################### DUPEFILTER_KEY = 'dupefilter:%(timestamp)s' DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # ###################### 调度器 ###################### from scrapy_redis.scheduler import Scheduler # 由scrapy_redis的调度器来进行负责调配 # enqueue_request: 向调度器中添加任务 # next_request: 去调度器中获取一个任务 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 规定任务存放的顺序 # 优先级 DEPTH_PRIORITY = 1 # 广度优先 # DEPTH_PRIORITY = -1 # 深度优先 SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表) # 广度优先 # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表) # 深度优先 # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表) """ redis = { chouti:requests:[ pickle.dumps(Request(url='Http://wwwww',callback=self.parse)), pickle.dumps(Request(url='Http://wwwww',callback=self.parse)), pickle.dumps(Request(url='Http://wwwww',callback=self.parse)), ], cnblogs:requests:[ ] } """ SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle SCHEDULER_PERSIST = False # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空 SCHEDULER_FLUSH_ON_START = True # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空 # SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。 SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 去重规则对应处理的类 START_URLS_KEY = '%(name)s:start_urls' REDIS_START_URLS_AS_SET = False
调度器的源码是如何实现的?
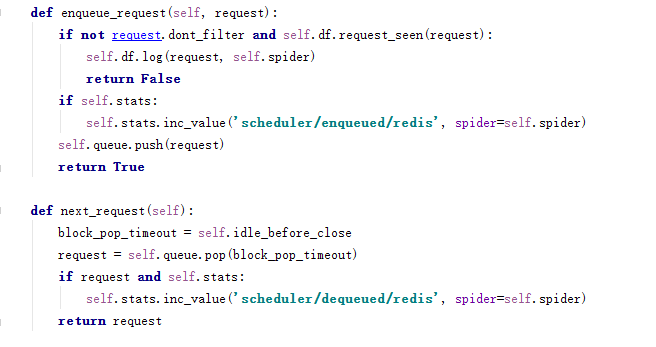
主要是enqueue_request()
next_request()两个方法
3.pipelines
使用scrapy-redis内置的pipeline做持久化,就是将item对象保存到redis的列表中:
配置文件中:单独使用pipelins
#使用scrapy-redis内置的pipeline做持久化,就是将item对象保存到redis的列表中:
#配置文件中:
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300,
}
I can feel you forgetting me。。 有一种默契叫做我不理你,你就不理我
