爬虫之Xpath的使用
什么是Xpath
Xpath是一门在HTML、XML文档中查找信息的语言,可以用来在HTML/XML文档中对元素和属性进行遍历
XML:可扩展标记语言,被设计为传输和存储数据,其焦点是数据内容,每个XML的标签叫做节点,
Xpath节点选择工具:
Chrome插件XPath Helper
开源的XPath表达式编辑工具XMLQuire(XML格式文件可用)
Firefox插件XPathChecker
Xpath语法

/表示根节点,
/html/head/title/text()
学习重点:
1、a/text() a的文本内容
a//text() a下的所有文本内容
//a[text()='下一页']选择文本为下一页的a标签
2、/html/head/link/@href 获取属性
//ul[@id='detail-list']/li/p/text()
./当前节点 ../上一级节点
3.//表示从html的任意位置开始选择
//li 整个文档中的li标签
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:

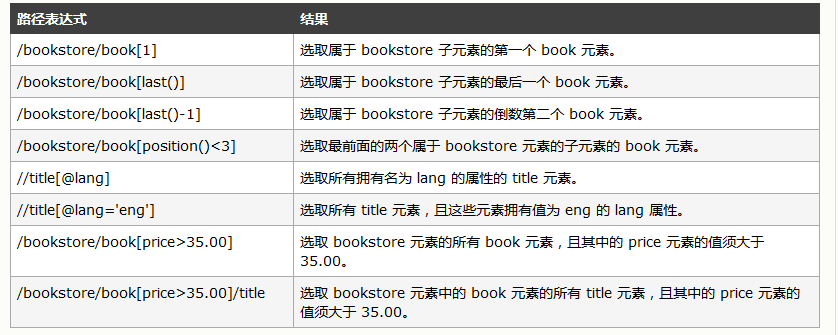
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。

实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

LXML的使用
导入lxml的etree库,from lxml import etree
利用etree.HTML将字符串转化为Element对象
Element对象具有Xpath方法,
HTML=etree.HTML(text)
lxml可以自动修正html代码,但是也可能会改错,使用etree.tostring来查看修正后的HTML,然后根据修改后的HTML使用Xpath。
文件读取
除了直接读取字符串,还支持从文件读取内容。比如我们新建一个文件叫做 hello.html
利用 parse 方法来读取文件
from lxml import etree
html = etree.parse('hello.html')
result = etree.tostring(html, pretty_print=True)
print(result)
XPath实例测试
(1)获取所有的 <li> 标签
from lxml import etree
html = etree.parse('hello.html')
print type(html)
result = html.xpath('//li')
print result
print len(result)
print type(result)
print type(result[0])
<type 'lxml.etree._ElementTree'> [<Element li at 0x1014e0e18>, <Element li at 0x1014e0ef0>, <Element li at 0x1014e0f38>, <Element li at 0x1014e0f80>, <Element li at 0x1014e0fc8>] 5 <type 'list'> <type 'lxml.etree._Element'>
可见,etree.parse 的类型是 ElementTree,通过调用 xpath 以后,得到了一个列表,包含了 5 个 <li> 元素,每个元素都是 Element 类型
I can feel you forgetting me。。 有一种默契叫做我不理你,你就不理我

