企业级实战模块三:ELK+Filebeat+Kafka+ZooKeeper构建大数据日志分析平台案例(下)
1 安装并配置Kafka Broker集群
可以从kafka官网https://kafka.apache.org/downloads获取kafka安装包,将下载下来的安装包直接解压到一个路径下即可完成kafka的安装,这里统一将kafka安装到/usr/local目录下,基本操作过程如下:
tar -zxvf kafka_2.11-2.2.2.tgz
mv kafka_2.11-2.2.2 /usr/local/kafka
注意:file 是对Kafka有严格的版本限制,需要在file 官网查看支持的版本https://www.elastic.co/guide/en/beats/filebeat/7.15/kafka-output.html
1.2 配置kafka集群
这里将kafka安装到/usr/local目录下,因此,kafka的主配置文件为/usr/local/kafka/config/server.properties,这里以节点kafkazk1为例,重点介绍一些常用配置项的含义:
broker.id=1
listeners=PLAINTEXT://192.168.5.4:9092
log.dirs=/usr/local/kafka/logs
num.partitions=6
log.retention.hours=60
log.segment.bytes=1073741824
zookeeper.connect=192.168.5.4:2181,192.168.5.5:2181,192.168.5.6:2181
auto.create.topics.enable=true
delete.topic.enable=true
每个配置项含义如下:
-
broker.id:每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况。
-
listeners:设置kafka的监听地址与端口,可以将监听地址设置为主机名或IP地址,这里将监听地址设置为IP地址。
-
log.dirs:这个参数用于配置kafka保存数据的位置,kafka中所有的消息都会存在这个目录下。可以通过逗号来指定多个路径, kafka会根据最少被使用的原则选择目录分配新的parition。需要注意的是,kafka在分配parition的时候选择的规则不是按照磁盘的空间大小来定的,而是根据分配的 parition的个数多小而定。
-
num.partitions:这个参数用于设置新创建的topic有多少个分区,可以根据消费者实际情况配置,配置过小会影响消费性能。这里配置6个。
-
log.retention.hours:这个参数用于配置kafka中消息保存的时间,还支持log.retention.minutes和
-
log.retention.ms配置项。这三个参数都会控制删除过期数据的时间,推荐使用log.retention.ms。如果多个同时设置,那么会选择最小的那个。
-
log.segment.bytes:配置partition中每个segment数据文件的大小,默认是1GB,超过这个大小会自动创建一个新的segment file。
-
zookeeper.connect:这个参数用于指定zookeeper所在的地址,它存储了broker的元信息。 这个值可以通过逗号设置多个值,每个值的格式均为:hostname:port/path,每个部分的含义如下:
-
hostname:表示zookeeper服务器的主机名或者IP地址,这里设置为IP地址。
-
port: 表示是zookeeper服务器监听连接的端口号。
-
/path:表示kafka在zookeeper上的根目录。如果不设置,会使用根目录。
-
-
auto.create.topics.enable:这个参数用于设置是否自动创建topic,如果请求一个topic时发现还没有创建, kafka会在broker上自动创建一个topic,如果需要严格的控制topic的创建,那么可以设置
-
auto.create.topics.enable为false,禁止自动创建topic。
-
delete.topic.enable:在0.8.2版本之后,Kafka提供了删除topic的功能,但是默认并不会直接将topic数据物理删除。如果要从物理上删除(即删除topic后,数据文件也会一同删除),就需要设置此配置项为true。
1.3 启动kafka集群
在启动kafka集群前,需要确保ZooKeeper集群已经正常启动。接着,依次在kafka各个节点上执行如下命令即可:
cd /usr/local/kafka && nohup bin/kafka-server-start.sh config/server.properties &
这里将kafka放到后台运行,启动后,会在启动kafka的当前目录下生成一个nohup.out文件,可通过此文件查看kafka的启动和运行状态。通过jps指令,可以看到有个Kafka标识,这是kafka进程成功启动的标志。
1.4 kafka集群基本命令操作
kefka提供了多个命令用于查看、创建、修改、删除topic信息,也可以通过命令测试如何生产消息、消费消息等,这些命令位于kafka安装目录的bin目录下,这里是/usr/local/kafka/bin。登录任意一台kafka集群节点,切换到此目录下,即可进行命令操作。下面列举kafka的一些常用命令的使用方法。
1)创建一个topic,并指定topic属性(副本数、分区数等)
bin/kafka-topics.sh --create --zookeeper 192.168.5.4:2181,192.168.5.5:2181,192.168.5.6:2181 --replication-factor 1 --partitions 3 --topic mytopic

2)显示topic列表
bin/kafka-topics.sh --zookeeper 192.168.5.4:2181,192.168.5.5:2181,192.168.5.6:2181 --list

3)查看某个topic的状态
bin/kafka-topics.sh --describe --zookeeper 192.168.5.4:2181,192.168.5.5:2181,192.168.5.6:2181 --topic mytopic

4)生产消息
bin/kafka-console-producer.sh --broker-list 192.168.5.4:9092,192.168.5.5:9092,192.168.5.6:9092 --topice mytopic

5)消费消息
bin/kafka-console-consumer.sh --bootstrap-server 192.168.5.4:9092,192.168.5.5:9092,192.168.5.6:9092 --topic mytopic --from-beginning

6)删除topic
bin/kafka-topics.sh --zookeeper 192.168.5.4:2181,192.168.5.5:2181,192.168.5.6:2181 --delete --topic mytopic

2 安装并配置Filebeat
2.1 为什么要使用filebeat
Logstash功能虽然强大,但是它依赖java、在数据量大的时候,Logstash进程会消耗过多的系统资源,这将严重影响业务系统的性能,而filebeat就是一个完美的替代者,filebeat是Beat成员之一,基于Go语言,没有任何依赖,配置文件简单,格式明了,同时,filebeat比logstash更加轻量级,所以占用系统资源极少,非常适合安装在生产机器上。
2.2 下载与安装filebeat
由于filebeat基于go语言开发,无其他任何依赖,因而安装非常简单,可以从elastic官网https://www.elastic.co/downloads/beats/filebeat 获取filebeat安装包,将下载下来的安装包直接解压到一个路径下即可完成filebeat的安装。根据前面的规划,将filebeat安装到filebeatserver主机上,这里设定将filebeat安装到/usr/local目录下,基本操作过程如下:
tar -zxvf filebeat-7.15.0-linux-x86_64.tar.gz
mv filebeat-7.15.0-linux-x86_64 /usr/local/filebeat
2.3 配置filebeat
filebeat的配置文件目录为/usr/local/filebeat/filebeat.yml,这里仅列出常用的配置项,内容如下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
- /var/log/secure
fields:
log_topic: osmessages
name: "192.168.5.3"
output.kafka:
enabled: true
hosts: ["192.168.5.4:9092","192.168.5.5:9092","192.168.5.6:9092"]
# version: "2.2.2"
topic: '%{[fields][log_topic]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
logging.level: debug
配置项的含义介绍如下:
-
filebeat.inputs:用于定义数据原型。
-
type:指定数据的输入类型,这里是log,即日志,是默认值,还可以指定为stdin,即标准输入。
-
enabled: true:启用手工配置filebeat,而不是采用模块方式配置filebeat。
-
paths:用于指定要监控的日志文件,可以指定一个完整路径的文件,也可以是一个模糊匹配格式,例如:
- /data/nginx/logs/nginx_*.log,该配置表示将获取/data/nginx/logs目录下的所有以.log结尾的文件,注意这里有个破折号“-”,要在paths配置项基础上进行缩进,不然启动filebeat会报错,另外破折号前面不能有tab缩进,建议通过空格方式缩进。
- /var/log/*.log,该配置表示将获取/var/log目录的所有子目录中以”.log”结尾的文件,而不会去查找/var/log目录下以”.log”结尾的文件。
-
name: 设置filebeat收集的日志中对应主机的名字,如果配置为空,则使用该服务器的主机名。这里设置为IP,便于区分多台主机的日志信息。
-
output.kafka:filebeat支持多种输出,支持向kafka,logstash,elasticsearch输出数据,这里的设置是将数据输出到kafka。
-
enabled:表明这个模块是启动的。
-
host: 指定输出数据到kafka集群上,地址为kafka集群IP加端口号。
-
topic:指定要发送数据给kafka集群的哪个topic,若指定的topic不存在,则会自动创建此topic。注意topic的写法,在filebeat6.x之前版本是通过“%{[type]}”来自动获取document_type配置项的值。而在filebeat6.x之后版本是通过'%{[fields][log_topic]}'来获取日志分类的。
-
logging.level:定义filebeat的日志输出级别,有critical、error、warning、info、debug五种级别可选,在调试的时候可选择debug模式。
2.4 启动filebeat收集日志
所有配置完成之后,就可以启动filebeat,开启收集日志进程了,启动方式如下:
cd /usr/local/filebeat
nohup ./filebeat -e -c filebeat.yml &
这样,就把filebeat进程放到后台运行起来了。启动后,在当前目录下会生成一个nohup.out文件,可以查看filebeat启动日志和运行状态。
2.5 查看消息
登录到Kafka集群节点,执行
bin/kafka-topics.sh --zookeeper 192.168.5.4:2181,192.168.5.5:2181,192.168.5.6:2181 --list

bin/kafka-console-consumer.sh --bootstrap-server 192.168.5.4:9092,192.168.5.5:9092,192.168.5.6:9092 --topic osmessages
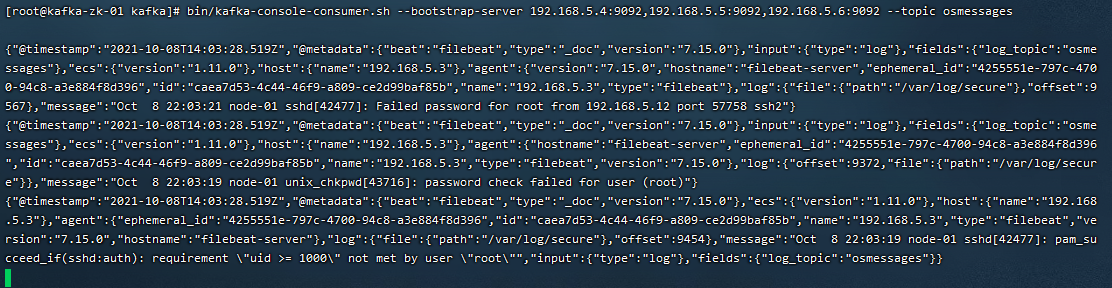
2.5 filebeat输出信息格式解读
这里以操作系统中/var/log/secure文件的日志格式为例,选取一个SSH登录系统失败的日志,内容如下:
Oct 8 21:52:17 node-01 sshd[33361]: Failed password for root from 192.168.5.11 port 49424 ssh2
filebeat接收到/var/log/secure日志后,会将上面日志发送到kafka集群,在kafka任意一个节点上,消费输出日志内容如下:
{"@timestamp":"2021-10-08T13:55:06.457Z",
"@metadata":{"beat":"filebeat","type":"_doc","version":"7.15.0"},
"input":{"type":"log"},
"fields":{"log_topic":"osmessages"},
"host":{"name":"192.168.5.3"},
"agent":{"type":"filebeat","version":"7.15.0","hostname":"filebeat-server","ephemeral_id":"4255551e-797c-4700-94c8-a3e884f8d396","id":"caea7d53-4c44-46f9-a809-ce2d99baf85b","name":"192.168.5.3"},
"ecs":{"version":"1.11.0"},
"log":{"offset":8730,"file":{"path":"/var/log/secure"}},
"message":"Oct 8 21:55:05 node-01 sshd[35904]: Failed password for root from 192.168.5.12 port 57756 ssh2"}
3 安装并配置Logstash服务
3.1 下载与安装Logstash
可以从elastic官网https://www.elastic.co/downloads/logstash 获取logstash安装包,将下载下来的安装包直接解压到一个路径下即可完成logstash的安装。根据前面的规划,将logstash安装到logstashserver主机(172.16.213.120)上,这里统一将logstash安装到/usr/local目录下,基本操作过程如下:
tar -zxvf logstash-7.15.0-linux-x86_64.tar.gz
mv logstash-7.15.0 /usr/local/logstash
3.2 logstash 工作原理
Logstash是一个开源的、服务端的数据处理pipeline(管道),它可以接收多个源的数据、然后对它们进行转换、最终将它们发送到指定类型的目的地。Logstash是通过插件机制实现各种功能的,可以在https://github.com/logstash-plugins 下载各种功能的插件,也可以自行编写插件。
Logstash实现的功能主要分为接收数据、解析过滤并转换数据、输出数据三个部分,对应的插件依次是input插件、filter插件、output插件,其中,filter插件是可选的,其它两个是必须插件。也就是说在一个完整的Logstash配置文件中,必须有input插件和output插件。
3.3 配置logstash作为转发节点
logstash是作为一个二级转发节点使用的,也就是它将kafka作为数据接收源,然后将数据发送到elasticsearch集群中,按照这个需求,新建logstash事件配置文件kafka_os_into_es.conf,内容如下:
input {
kafka {
bootstrap_servers => "192.168.5.4:9092,192.168.5.5:9092,192.168.5.6:9092"
topics => ["osmessages"]
}
}
output {
elasticsearch {
hosts => ["192.168.5.8:9200","192.168.5.9:9200","192.168.5.10:9200"]
index => " osmessageslog-%{+YYYY-MM-dd}"
}
}
3.4 启动logstash转发日志
cd /usr/local/logstash/
nohup bin/logstash -f config/kafka_os_into_es.conf &
4 安装并配置Kibana展示日志数据
4.1 下载与安装Kibana
kibana使用JavaScript语言编写,安装部署十分简单,即下即用,可以从elastic官网https://www.elastic.co/cn/downloads/kibana 下载所需的版本,这里需要注意的是Kibana与Elasticsearch的版本必须一致,另外,在安装Kibana时,要确保Elasticsearch、Logstash和kafka已经安装完毕。
将下载下来的安装包直接解压到一个路径下即可完成kibana的安装,根据前面的规划,将kibana安装到主机上,然后统一将kibana安装到/usr/local目录下,基本操作过程如下:
tar zxvf kibana-7.15.0-linux-x86_64.tar.gz
mv kibana-7.15.0-linux-x86_64 /usr/local/kibana
4.2 配置Kibana
由于将Kibana安装到了/usr/local目录下,因此,Kibana的配置文件为/usr/local/kibana/kibana.yml,Kibana配置非常简单,这里仅列出常用的配置项,内容如下:
cat <<EOF>>/usr/local/kibana/config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.5.8:9200"]
kibana.index: ".kibana"
i18n.locale: "zh-CN"
EOF
其中,每个配置项的含义介绍如下:
-
server.port:kibana绑定的监听端口,默认是5601。
-
server.host:kibana绑定的IP地址,如果内网访问,设置为内网地址即可。
-
elasticsearch.url:kibana访问ElasticSearch的地址,如果是ElasticSearch集群,添加任一集群节点IP即可,官方推荐是设置为ElasticSearch集群中client node角色的节点IP。
-
kibana.index:用于存储kibana数据信息的索引,这个可以在kibanaweb界面中看到。
4.3 启动Kibana服务与web配置
所有配置完成后,就可以启动kibana了,启动kibana服务的命令在/usr/local/kibana/bin目录下,执行如下命令启动kibana服务:
cd /usr/local/kibana
nohup bin/kibana --allow-root &
5 调试并验证日志数据流向
经过上面的配置过程,大数据日志分析平台已经基本构建完成,由于整个配置架构比较复杂,这里来梳理下各个功能模块的数据和业务流向。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号