企业级实战模块二:ELK+Filebeat+Kafka+ZooKeeper构建大数据日志分析平台案例(上)
1 日志分析平台架构图
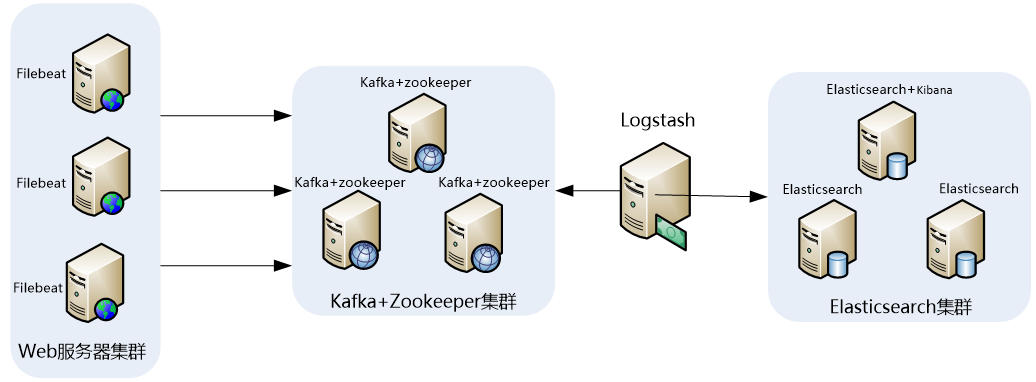
此架构稍微有些复杂,因此,这里做一下架构解读。 这个架构图从左到右,总共分为5层,每层实现的功能和含义分别介绍如下:
第一层、数据采集层
数据采集层位于最左边的业务服务器集群上,在每个业务服务器上面安装了filebeat做日志收集,然后把采集到的原始日志发送到Kafka+zookeeper集群上。
第二层、消息队列层
原始日志发送到Kafka+zookeeper集群上后,会进行集中存储,此时,filbeat是消息的生产者,存储的消息可以随时被消费。
第三层、数据分析层
Logstash作为消费者,会去Kafka+zookeeper集群节点实时拉取原始日志,然后将获取到的原始日志根据规则进行分析、清洗、过滤,最后将清洗好的日志转发至Elasticsearch集群。
Elasticsearch集群在接收到logstash发送过来的数据后,执行写磁盘,建索引库等操作,最后将结构化的数据存储到Elasticsearch集群上。
第五层、数据查询、展示层
Kibana是一个可视化的数据展示平台,当有数据检索请求时,它从Elasticsearch集群上读取数据,然后进行可视化出图和多维度分析。
2 环境与角色说明
2.1 服务器环境与角色
操作系统统一采用Centos7.9版本,各个服务器角色如下表所示:
| 服务器配置 | 主机名 | 角色 | IP地址 | 所属集群 |
|---|---|---|---|---|
| 1C1G | filebeat-server | 业务服务器+filebeat | 192.168.5.3 | 业务服务器集群 |
| 1C2G | kafka-zk-01 | Kafka+ ZooKeeper | 192.168.5.4 | KB集群 |
| 1C2G | kafka-zk-02 | Kafka+ ZooKeeper | 192.168.5.5 | KB集群 |
| 1C2G | kafka-zk-03 | Kafka+ ZooKeeper | 192.168.5.6 | KB集群 |
| 1C2G | logstash-server | Logstash、Kibana | 192.168.5.7 | 数据转发 |
| 1C2G | Elasticsearch-01 | ES Master、ES NataNode | 192.168.5.8 | ES集群 |
| 1C2G | Elasticsearch-02 | ES Master、ES NataNode | 192.168.5.9 | ES集群 |
| 1C2G | Elasticsearch-03 | ES Master、ES NataNode | 192.168.5.10 | ES集群 |
2.2 软件环境与版本
下表详细说明了安装软件对应的名称和版本号,其中,ELK三款软件推荐选择一样的版本,
| 软件名称 | 版本号 | 说明 |
|---|---|---|
| JDK | JDK 1.8.0_231 | Java环境解析器 |
| Kafka | kafka_2.13-3.0.0 | 消息通信中间件 |
| zookeeper | apache-zookeeper-3.7.0-bi | 资源调度、协作 |
| elasticsearch | elasticsearch-7.15.0-linux-x86_64 | 日志存储 |
| Logstash | logstash-7.15.0-linux-x86_64 | 日志收集、过滤、转发 |
| filebeat | filebeat-7.15.0-linux-x86_64 | 前端日志收集器 |
| kibana | kibana-7.15.0-linux-x86_64 | 日志展示、分析 |
3 设置基础环境以及安装JDK环境(所有服务器执行)
3.1 设置基础环境
关闭防火墙及selinux
systemctl stop firewalld && systemctl disable firewalld
swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
修改主机名
hostnamectl set-hostname "hostname" && bash
3.2 选择合适版本并下载JDK
Zookeeper 、elasticsearch和Logstash都依赖于Java环境,并且elasticsearch和Logstash要求JDK版本至少在JDK1.7或者以上,因此,在安装zookeeper、Elasticsearch和Logstash的机器上,必须要安装JDK,一般推荐使用最新版本的JDK
从oracle官网下载linux-64版本的JDK,下载时,选择适合自己机器运行环境的版本,oracle官网提供的JDK都是二进制版本的,因此,JDK的安装非常简单,只需将下载下来的程序包解压到相应的目录即可。安装过程如下:
tar zxvf jdk-8u231-linux-x64.tar.gz
mv jdk1.8.0_231/ /usr/local/java
3.3 设置JDK的环境变量
要让程序能够识别JDK路径,需要设置环境变量,这里我们将JDK环境变量设置到/etc/profile文件中。添加如下内容到/etc/profile文件最后:
cat <<EOF>>/etc/profile
#Java环境变量
set java environment
JAVA_HOME=/usr/local/java/
JRE_HOME=/usr/local/java/jre/
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
EOF
然后执行如下命令让设置生效:
source /etc/profile
java -version

4 安装并配置elasticsearch集群(部分服务器执行)
4.1 elasticsearch集群的架构与角色
在ElasticSearch的架构中,有三类角色,分别是Client Node、Data Node和Master Node,搜索查询的请求一般是经过Client Node来向Data Node获取数据,而索引查询首先请求Master Node节点,然后Master Node将请求分配到多个Data Node节点完成一次索引查询。
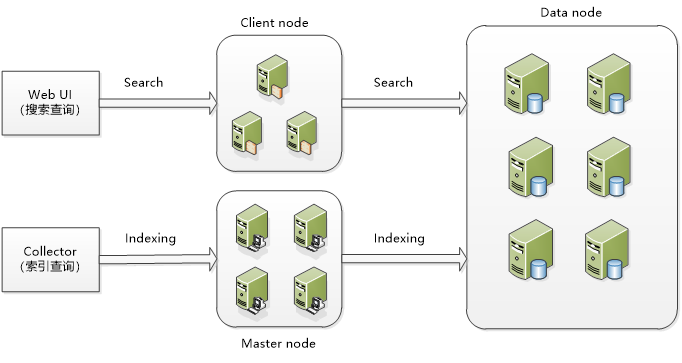
集群中每个角色的含义介绍如下:
master node:
可以理解为主节点,主要用于元数据(metadata)的处理,比如索引的新增、删除、分片分配等,以及管理集群各个节点的状态。elasticsearch集群中可以定义多个主节点,但是,在同一时刻,只有一个主节点起作用,其它定义的主节点,是作为主节点的候选节点存在。当一个主节点故障后,集群会从候选主节点中选举出新的主节点。
data node:
数据节点,这些节点上保存了数据分片。它负责数据相关操作,比如分片的CRUD、搜索和整合等操作。数据节点上面执行的操作都比较消耗 CPU、内存和I/O资源,因此数据节点服务器要选择较好的硬件配置,才能获取高效的存储和分析性能。
client node:
客户端节点,属于可选节点,是作为任务分发用的,它里面也会存元数据,但是它不会对元数据做任何修改。client node存在的好处是可以分担data node的一部分压力,因为elasticsearch的查询是两层汇聚的结果,第一层是在data node上做查询结果汇聚,然后把结果发给client node,client node接收到data node发来的结果后再做第二次的汇聚,然后把最终的查询结果返回给用户。这样,client node就替data node分担了部分压力
4.2 安装elasticsearch与授权
elasticsearch的安装非常简单,首先从官网https://www.elastic.co/下载页面找到适合的版本,可选择zip、tar、rpm等格式的安装包下载
mkdir /usr/local/elk
tar -zxvf elasticsearch-7.15.0-linux-x86_64.tar.gz -C /usr/local/elk/
由于ElasticSearch可以接收用户输入的脚本并且执行,为了系统安全考虑,需要创建一个单独的用户用来运行elasticSearch,这里创建的普通用户是es,操作如下:
groupadd es
useradd es -g es
然后将elasticsearch的安装目录都授权给es用户,操作如下:
chown -R es:es /usr/local/elk/elasticsearch-7.15.0
4.3 操作系统调优
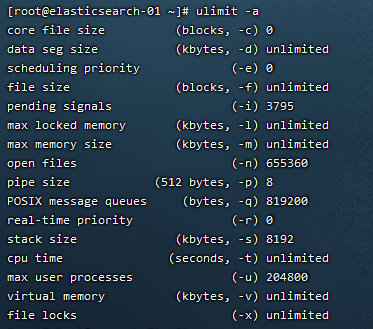
操作系统以及JVM调优主要是针对安装elasticsearch的机器。对于操作系统,需要调整几个内核参数,fs.file-max主要是配置系统最大打开文件描述符数,建议修改为655360或者更高,vm.max_map_count影响Java线程数量,用于限制一个进程可以拥有的VMA(虚拟内存区域)的大小,系统默认是65530,建议修改成262144或者更高。将下面内容添加到/etc/sysctl.conf文件中:
cat <<EOF>>/etc/sysctl.conf
fs.file-max=655360
vm.max_map_count = 262144
EOF
另外,还需要调整进程最大打开文件描述符(nofile)、最大用户进程数(nproc)和最大锁定内存地址空间(memlock),添加如下内容到/etc/security/limits.conf文件中:
cat <<EOF>>/etc/security/limits.conf
* soft nproc 204800
* hard nproc 204800
* soft nofile 655360
* hard nofile 655360
* soft memlock unlimited
* hard memlock unlimited
EOF
最后,还需要修改/etc/security/limits.d/20-nproc.conf文件(centos7.x系统),将:
* soft nproc 4096
# 修改为:
* soft nproc 20480
或者直接删除/etc/security/limits.d/20-nproc.conf文件也行。
sed -i 's/4096/20480/g' /etc/security/limits.d/20-nproc.conf
使配置文件生效
sysctl -p

重新连接对话框
4.4 JVM调优
JVM调优主要是针对elasticsearch的JVM内存资源进行优化,elasticsearch的内存资源配置文件为jvm.options,此文件位于/usr/local/elk/elasticsearch-7.15.0/config目录下,打开此文件,修改如下内容:
-Xms2g
-Xmx2g
可以看到,默认JVM内存为2g,可根据服务器内存大小,修改为合适的值。一般设置为服务器物理内存的一半最佳。
4.5 配置elasticsearch
elasticsearch的配置文件均在elasticsearch根目录下的config文件夹,这里是/usr/local/elk/elasticsearch-7.15.0/config目录,主要有jvm.options、elasticsearch.yml和log4j2.properties三个主要配置文件。这里重点介绍elasticsearch.yml一些重要的配置项及其含义。这里配置的elasticsearch.yml文件内容如下:
cat <<EOF>>/usr/local/elk/elasticsearch-7.15.0/config/elasticsearch.yml
#集群名称
cluster.name: cluster-es
#节点名称, 每个节点的名称不能重复
node.name: server-02
#ip 地址, 每个节点的地址不能重复
network.host: 0.0.0.0
#是不是有资格主节点
node.master: true
node.data: true
http.port: 9200
path.data: /data1/elasticsearch,/data2/elasticsearch
path.logs: /usr/local/elk/elasticsearch-7.15.0/logs
# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["server-01"]
#es7.x 之后新增的配置,节点发现
discovery.zen.ping_timeout: 3s
discovery.seed_hosts: ["192.168.5.8:9300","192.168.5.9:9300","192.168.5.10:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
#集群内同时启动的数据任务个数,默认是 2 个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个
cluster.routing.allocation.node_concurrent_recoveries: 16
#初始化数据恢复时,并发恢复线程的个数,默认 4 个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
EOF
创建存储目录并赋予启动用户权限
mkdir -p /data{1,2}/elasticsearch/
chown es:es -R /data{1,2}/
4.6 启动elasticsearch
切换到es用户下启动elasticsearch集群即可。分别登录到server1、server2和server3三台主机上,执行如下操作:
su - es
sh /usr/local/elk/elasticsearch-7.15.0/bin/elasticsearch -d
其中,“-d”参数的意思是将elasticsearch放到后台运行。
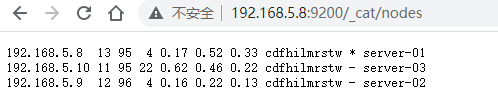
4.7 验证elasticsearch集群的可用性
http://192.168.5.8:9200/_cat/nodes
5 安装并配置ZooKeeper集群
5.1 下载与安装zookeeper
ZooKeeper是用Java编写的,需要安装Java运行环境,可以从zookeeper官网https://zookeeper.apache.org/获取zookeeper安装包,将下载下来的安装包直接解压到一个路径下即可完成zookeeper的安装,
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz
mv apache-zookeeper-3.7.0-bin /usr/local/zookeeper
5.2 配置zookeeper
zookeeper安装到了/usr/local目录下,因此,zookeeper的配置模板文件为/usr/local/zookeeper/conf/zoo_sample.cfg,拷贝zoo_sample.cfg并重命名为zoo.cfg,重点配置如下内容:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
server.1=172.16.213.51:2888:3888
server.2=172.16.213.109:2888:3888
server.3=172.16.213.75:2888:3888
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
scp /usr/local/zookeeper/conf/zoo.cfg root@192.168.5.5:/usr/local/zookeeper/conf/zoo.cfg
scp /usr/local/zookeeper/conf/zoo.cfg root@192.168.5.6:/usr/local/zookeeper/conf/zoo.cfg
mkdir -p /data/zookeeper
echo 1 > /data/zookeeper/myid
每个配置项含义如下:
-
tickTime:zookeeper使用的基本时间度量单位,以毫秒为单位,它用来控制心跳和超时。2000表示2 tickTime。更低的tickTime值可以更快地发现超时问题。
-
initLimit:这个配置项是用来配置Zookeeper集群中Follower服务器初始化连接到Leader时,最长能忍受多少个心跳时间间隔数(也就是tickTime)l
-
syncLimit:这个配置项标识Leader与Follower之间发送消息,请求和应答时间长度最长不能超过多少个tickTime的时间长度
-
dataDir:必须配置项,用于配置存储快照文件的目录。需要事先创建好这个目录,如果没有配置dataLogDir,那么事务日志也会存储在此目录。
-
clientPort:zookeeper服务进程监听的TCP端口,默认情况下,服务端会监听2181端口。
-
server.A=B:C:D:其中A是一个数字,表示这是第几个服务器;B是这个服务器的IP地址;C表示的是这个服务器与集群中的Leader服务器通信的端口;D 表示如果集群中的Leader服务器宕机了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
除了修改zoo.cfg配置文件外,集群模式下还要配置一个文件myid,这个文件需要放在dataDir配置项指定的目录下,这个文件里面只有一个数字,如果要写入1,表示第一个服务器,与zoo.cfg文本中的server.1中的1对应,以此类推,在集群的第二个服务器zoo.cfg配置文件中dataDir配置项指定的目录下创建myid文件,写入2,这个2与zoo.cfg文本中的server.2中的2对应。Zookeeper在启动时会读取这个文件,得到里面的数据与zoo.cfg里面的配置信息比较,从而判断每个zookeeper server的对应关系。
为了保证zookeeper集群配置的规范性,建议将zookeeper集群中每台服务器的安装和配置文件路径都保存一致。
5.3 启动zookeeper集群
在三个节点依次执行如下命令,启动Zookeeper服务:
sh /usr/local/zookeeper/bin/zkServer.sh start
Zookeeper启动后,通过jps命令(jdk内置命令)可以看到有一个QuorumPeerMain标识,这个就是Zookeeper启动的进程,前面的数字是Zookeeper进程的PID。
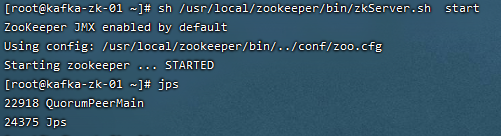
有时候为了启动Zookeeper方面,也可以添加zookeeper环境变量到系统的/etc/profile中,这样,在任意路径都可以执行“zkServer.sh start”命令了,添加环境变量的内容为:
cat <<EOF>>/etc/profile
#zookeeper环境变量
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
EOF

 浙公网安备 33010602011771号
浙公网安备 33010602011771号