7 search搜索及评分机制
7.1 search搜索入门
7.1.1 query string search
无条件搜索所有
GET /book/_search
{
"took" : 969,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "Bootstrap开发",
"description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel" : "201002",
"price" : 38.6,
"timestamp" : "2021-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"bootstrap",
"dev"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2021-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2021-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
}
]
}
}
解释
-
took:耗费了几毫秒
-
timed_out:是否超时,这里是没有
-
_shards:到几个分片搜索,成功几个,跳过几个,失败几个。
-
hits.total:查询结果的数量,3个document
-
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
-
hits.hits:包含了匹配搜索的document的所有详细数据
7.1.2 传参
与http请求传参类似
GET /book/_search?q=name:java&sort=price:desc
类比sql: select * from book where name like ’ %java%’ order by price desc
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : null,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
},
"sort" : [
68.6
]
}
]
}
}
7.1.3 图解timeout
GET /book/_search?timeout=10ms
全局设置:配置文件中设置 search.default_search_timeout:100ms。默认不超时。

7.2 multi-index 多索引搜索
7.2.1 multi-index搜索模式
如何一次性搜索多个index和多个type下的数据
GET /_search:所有索引下的所有数据都搜索出来
GET /index1/_search:指定一个index,搜索其下所有的数据
GET /index1,index2/_search:同时搜索两个index下的数据
GET /index*/_search:按照通配符去匹配多个索引
应用场景:生产环境log索引可以按照日期分开。
-
log_to_es_20210910
-
log_to_es_20210911
-
log_to_es_20210912
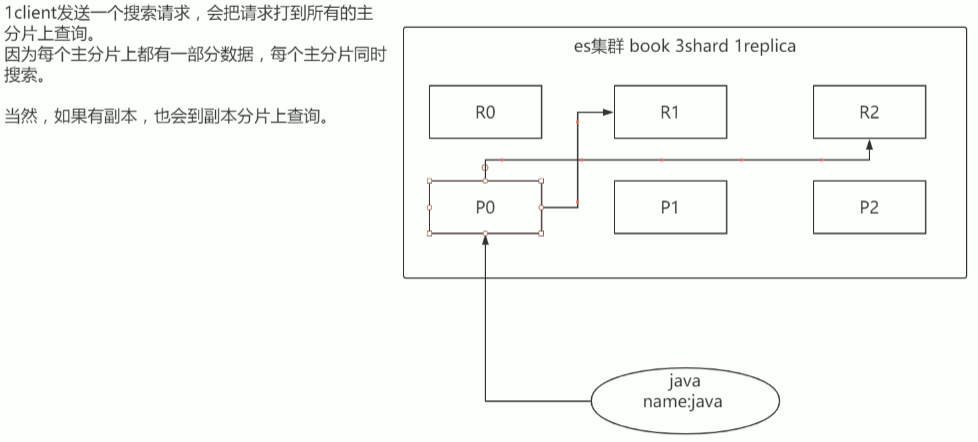
7.2.2 初步图解一下简单的搜索原理
搜索原理初步图解
7.3 分页搜索
7.3.1 分页搜索的语法
sql: select * from book limit 1,5
size,from
GET /book/_search?size=10
GET /book/_search?size=10&from=0
GET /book/_search?size=10&from=20
GET /book_search?from=0&size=3
7.3.2 deep paging
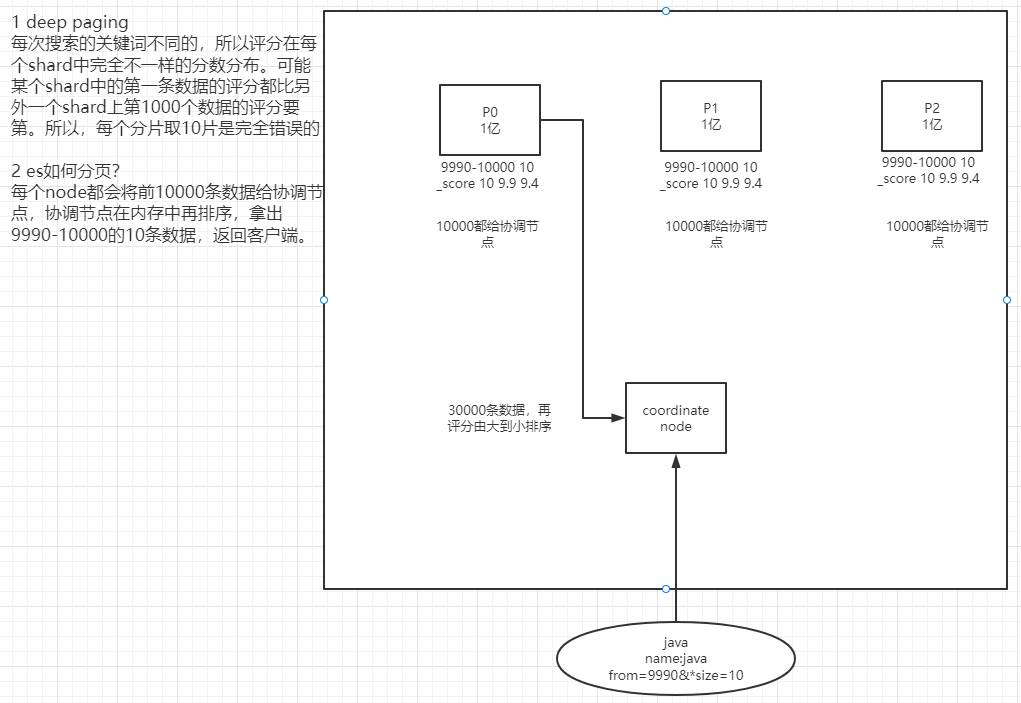
1)什么是deep paging
根据相关度评分倒排序,所以分页过深,协调节点会将大量数据聚合分析。
2)deep paging 性能问题
-
消耗网络带宽,因为所搜过深的话,各 shard 要把数据传递给 coordinate node,这个过程是有大量数据传递的,消耗网络。
-
消耗内存,各 shard 要把数据传送给 coordinate node,这个传递回来的数据,是被 coordinate node 保存在内存中的,这样会大量消耗内存。
-
消耗cup,coordinate node 要把传回来的数据进行排序,这个排序过程很消耗cpu。
所以:鉴于deep paging的性能问题,所有应尽量减少使用。
7.4 query string基础语法
7.4.1 query string基础语法
-
GET /book/_search?q=name:java
-
GET /book/_search?q=+name:java
-
GET /book/_search?q=-name:java
一个是掌握q=field:search content的语法,还有一个是掌握+和-的含义
7.4.2 _all metadata的原理和作用
GET /book/_search?q=java
直接可以搜索所有的field,任意一个field包含指定的关键字就可以搜索出来。我们在进行中搜索的时候,难道是对document中的每一个field都进行一次搜索吗?不是的。
es中_all元数据。建立索引的时候,插入一条docunment,es会将所有的field值经行全量分词,把这些分词,放到_all field中。在搜索的时候,没有指定field,就在_all搜索。
举例
{
name:jack
email:123@qq.com
address:beijing
}
_all : jack,123@qq.com,beijing
7.5 query DSL入门
7.5.1 DSL
query string 后边的参数原来越多,搜索条件越来越复杂,不能满足需求。
GET /book/_search?q=name:java&size=10&from=0&sort=price:desc
DSL:Domain Specified Language,特定领域的语言
es特有的搜索语言,可在请求体中携带搜索条件,功能强大。
查询全部 GET /book/_search
GET /book/_search
{
"query": { "match_all": {} }
}
排序 GET /book/_search?sort=price:desc
GET /book/_search
{
"query" : {
"match" : {
"name" : " java"
}
},
"sort": [
{ "price": "desc" }
]
}
分页查询 GET /book/_search?size=10&from=0
GET /book/_search
{
"query": { "match_all": {} },
"from": 0,
"size": 1
}
指定返回字段 GET /book/ _search? _source=name,studymodel
GET /book/_search
{
"query": { "match_all": {} },
"_source": ["name", "studymodel"]
}
通过组合以上各种类型查询,实现复杂查询。
7.5.2 Query DSL语法
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,
GET /test_index/_search
{
"query": {
"match": {
"test_field": "test"
}
}
}
7.5.3 组合多个搜索条件
搜索需求:title必须包含elasticsearch,content可以包含elasticsearch也可以不包含,author_id必须不为111
sql where and or !=
初始数据:
POST /website/_doc/1
{
"title": "my hadoop article",
"content": "hadoop is very bad",
"author_id": 111
}
POST /website/_doc/2
{
"title": "my elasticsearch article",
"content": "es is very bad",
"author_id": 112
}
POST /website/_doc/3
{
"title": "my elasticsearch article",
"content": "es is very goods",
"author_id": 111
}
搜索:
GET /website/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "elasticsearch"
}
}
],
"should": [
{
"match": {
"content": "elasticsearch"
}
}
],
"must_not": [
{
"match": {
"author_id": 111
}
}
]
}
}
}
返回:
{
"took" : 66,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.4700036,
"hits" : [
{
"_index" : "website",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.4700036,
"_source" : {
"title" : "my elasticsearch article",
"content" : "es is very bad",
"author_id" : 112
}
}
]
}
}
更复杂的搜索需求:
select * from test_index where name='tom' or (hired =true and (personality ='good' and rude != true ))
GET /test_index/_search
{
"query": {
"bool": {
"must": { "match":{ "name": "tom" }},
"should": [
{ "match":{ "hired": true }},
{ "bool": {
"must":{ "match": { "personality": "good" }},
"must_not": { "match": { "rude": true }}
}}
],
"minimum_should_match": 1
}
}
}
7.6 full-text search 全文检索
7.6.1 全文检索
重新创建book索引
PUT /book/
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"description":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"studymodel":{
"type": "keyword"
},
"price":{
"type": "double"
},
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"pic":{
"type":"text",
"index":false
}
}
}
}
插入数据
PUT /book/_doc/1
{
"name": "Bootstrap开发",
"description": "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel": "201002",
"price":38.6,
"timestamp":"2019-08-25 19:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "bootstrap", "dev"]
}
PUT /book/_doc/2
{
"name": "java编程思想",
"description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel": "201001",
"price":68.6,
"timestamp":"2021-08-25 19:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "java", "dev"]
}
PUT /book/_doc/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"price":88.6,
"timestamp":"2021-08-24 19:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "spring", "java"]
}
搜索
GET /book/_search
{
"query": {
"bool": {
"must": [
{"match": {
"description": "java"
}
}
]
}
}
}
7.6.2 _score初探
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.7936629,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.7936629,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2021-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.5796132,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2021-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
}
]
}
}
结果分析
1、建立索引时, description字段 term倒排索引
java 2,3
程序员 3
2、搜索时,直接找description中含有java的文档 2,3,并且3号文档含有两个java字段,一个程序员,所以得分高,排在前面。2号文档含有一个java,排在后面。
7.7 DSL 语法练习
7.7.1 match_all
GET /book/_search
{
"query": {
"match_all": {}
}
}
7.7.2 match
GET /book/_search
{
"query": {
"match": {
"description": "java程序员"
}
}
}
7.7.3 multi_match
GET /book/_search
{
"query": {
"multi_match": {
"query": "java程序员",
"fields": ["name", "description"]
}
}
}
7.7.4 range query 范围查询
GET /book/_search
{
"query": {
"range": {
"price": {
"gte": 80,
"lte": 90
}
}
}
}
7.7.5 term query
字段为keyword时,存储和搜索都不分词
GET /book/_search
{
"query": {
"term": {
"description": "java程序员"
}
}
}
7.7.6 terms query
GET /book/_search
{
"query": { "terms": { "tag": [ "search", "full_text", "nosql" ] }}
}
7.7.7 exist query 查询有某些字段值的文档
GET /_search
{
"query": {
"exists": {
"field": "join_date"
}
}
}
7.7.8 Fuzzy query
返回包含与搜索词类似的词的文档,该词由Levenshtein编辑距离度量。
包括以下几种情况:
-
更改角色(box→fox)
-
删除字符(aple→apple)
-
插入字符(sick→sic)
-
调换两个相邻字符(ACT→CAT)
GET /book/_search
{
"query": {
"fuzzy": {
"description": {
"value": "jave"
}
}
}
}
7.7.9 IDs
GET /book/_search
{
"query": {
"ids" : {
"values" : ["1", "4", "100"]
}
}
}
7.7.10 prefix 前缀查询
GET /book/_search
{
"query": {
"prefix": {
"description": {
"value": "spring"
}
}
}
}
7.7.11 Regexp query 正则查询
GET /book/_search
{
"query": {
"regexp": {
"description": {
"value": "j.*a",
"flags" : "ALL",
"max_determinized_states": 10000,
"rewrite": "constant_score"
}
}
}
}
7.8 Filter
7.8.1 filter与query示例
需求:用户查询description中有"java程序员",并且价格大于80小于90的数据。
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"description": "java程序员"
}
},
{
"range": {
"price": {
"gte": 50,
"lte": 90
}
}
}
]
}
}
}
使用filter:
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"description": "java程序员"
}
}
],
"filter": {
"range": {
"price": {
"gte": 50,
"lte": 90
}
}
}
}
}
}
7.8.2 filter与query对比
filter,仅仅只是按照搜索条件过滤出需要的数据而已,不计算任何相关度分数,对相关度没有任何影响。
query,会去计算每个document相对于搜索条件的相关度,并按照相关度进行排序。
应用场景:
一般来说,如果你是在进行搜索,需要将最匹配搜索条件的数据先返回,那么用query 如果你只是要根据一些条件筛选出一部分数据,不关注其排序,那么用filter
7.8.3 filter与query性能
filter,不需要计算相关度分数,不需要按照相关度分数进行排序,同时还有内置的自动cache最常使用filter的数据
query,相反,要计算相关度分数,按照分数进行排序,而且无法cache结果
7.9 定位错误语法
验证错误语句:
GET /book/_validate/query?explain
{
"query": {
"mach": {
"description": "java程序员"
}
}
}
返回:
{
"valid" : false,
"error" : "org.elasticsearch.common.ParsingException: no [query] registered for [mach]"
}
正确:
GET /book/_validate/query?explain
{
"query": {
"match": {
"description": "java程序员"
}
}
}
返回:
{
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"valid" : true,
"explanations" : [
{
"index" : "book",
"valid" : true,
"explanation" : "description:java description:程序员"
}
]
}
一般用在那种特别复杂庞大的搜索下,比如你一下子写了上百行的搜索,这个时候可以先用validate api去验证一下,搜索是否合法。
合法以后,explain就像mysql的执行计划,可以看到搜索的目标等信息。
7.10 定制排序规则
7.10.1 默认排序规则
默认情况下,是按照_score降序排序的
然而,某些情况下,可能没有有用的_score,比如说filter
GET book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"description": "java程序员"
}
}
]
}
}
}
当然,也可以是constant_score
7.10.2 定制排序规则
相当于sql中orderby ?sort=sprice:desc
GET /book/_search
{
"query": {
"constant_score": {
"filter" : {
"term" : {
"studymodel" : "201001"
}
}
}
},
"sort": [
{
"price": {
"order": "asc"
}
}
]
}
7.11 Text字段排序问题
如果对一个text field进行排序,结果往往不准确,因为分词后是多个单词,再排序就不是我们想要的结果了。
通常解决方案是
方案一:fielddate:true
PUT /website
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fielddata": true
},
"content": {
"type": "text"
},
"post_date": {
"type": "date"
},
"author_id": {
"type": "long"
}
}
}
}
方案二:将一个text field建立两次索引,一个分词,用来进行搜索;一个不分词,用来进行排序。
PUT /website
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"content": {
"type": "text"
},
"post_date": {
"type": "date"
},
"author_id": {
"type": "long"
}
}
}
}
插入数据
PUT /website/_doc/1
{
"title": "first article",
"content": "this is my second article",
"post_date": "2021-01-01",
"author_id": 110
}
PUT /website/_doc/2
{
"title": "second article",
"content": "this is my second article",
"post_date": "2021-01-01",
"author_id": 110
}
PUT /website/_doc/3
{
"title": "third article",
"content": "this is my third article",
"post_date": "2021-01-02",
"author_id": 110
}
搜索
GET /website/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"title.keyword": {
"order": "desc"
}
}
]
}
7.12. Scroll分批查询
场景:下载某一个索引中1亿条数据,到文件或是数据库。
不能一下全查出来,系统内存溢出。所以使用scoll滚动搜索技术,一批一批查询。
scoll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的
每次发送scroll请求,我们还需要指定一个scoll参数,指定一个时间窗口,每次搜索请求只要在这个时间窗口内能完成就可以了。
搜索
GET /book/_search?scroll=1m
{
"query": {
"match_all": {}
},
"size": 3
}
返回
{
"_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFmRKVTlyX2VlUWd5M2FaM2RYV29Ra0EAAAAAAAA6PxZpUnJMdEFBZFJjR0c3dktBMm5zWmhn",
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
]
}
}
获得的结果会有一个scoll_id,下一次再发送scoll请求的时候,必须带上这个scoll_id
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFmRKVTlyX2VlUWd5M2FaM2RYV29Ra0EAAAAAAAA6PxZpUnJMdEFBZFJjR0c3dktBMm5zWmhn"
}
与分页区别:
分页给用户看的 deep paging
scroll是用户系统内部操作,如下载批量数据,数据转移。零停机改变索引映射。
7.13 评分机制详解
7.13.1 评分机制 TF\IDF
7.13.2 算法介绍
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度。
Elasticsearch使用的是 term frequency/inverse document frequency算法,简称为TF/IDF算法。TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)
1)Term frequency:搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关。

举例:搜索请求:阿莫西林胶囊
doc1 : 阿莫西林胶囊是什么,阿莫西林胶囊能做什么,阿莫西林胶囊结构
doc2 : 本药店有阿莫西林胶囊,红霉素胶囊,青霉素胶囊
结果:doc1 > doc2
2)Inverse document frequency:搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关.
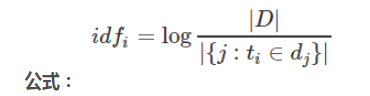

举例:搜索请求:阿莫西林胶囊
doc1:A市健康大药房简介。本药店有阿莫西林胶囊、红霉素胶囊,青霉素胶囊...
doc2:B市民生大药房简介。本药店有阿莫西林胶囊、红霉素胶囊,青霉素胶囊...
doc3:C市未来大药房简介。本药店有阿莫西林胶囊、红霉素胶囊,青霉素胶囊...
结果:整个索引库中出现少的词,相关度越弱
3)Field-length norm:field长度,field越长,相关度越弱
举例:搜索请求:A市 阿莫西林胶囊
doc1 : {"title":"A市健康大药房简介","content ":"本药店有阿莫西林胶囊、红霉素胶囊,青霉素胶囊。(一万字)"}
doc2 : {"title":"B市民生大药房简介","content ":"本药店有阿莫西林胶囊、红霉素胶囊,青霉素胶囊。(一万字)"}
结果:doc1>doc2
7.13.3 _score是如何被计算出来的
-
对用户输入关键词分词。
-
每个分词分别计算对每个匹配文档的tf值个idf值。
-
综合每个分词的tf/idf值,利用公式计算每个文档总分。
GET /book/_search?explain=true
{
"query": {
"match": {
"description": "java程序员"
}
}
}
返回
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.137549,
"hits" : [
{
"_shard" : "[book][0]",
"_node" : "MDA45-r6SUGJ0ZyqyhTINA",
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 2.137549,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2021-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
},
"_explanation" : {
"value" : 2.137549,
"description" : "sum of:",
"details" : [
{
"value" : 0.7936629,
"description" : "weight(description:java in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.7936629,
"description" : "score(freq=2.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.47000363,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.7675597,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 2.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 12.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 35.333332,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 1.3438859,
"description" : "weight(description:程序员 in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 1.3438859,
"description" : "score(freq=1.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",