python16_day03【集合、编码、函数、递归、内置函数】
一、集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
 View Code
View Code1 #创建: 2 s = {3,5,9,10} #创建一个数值集合 3 t = set("Hello") #创建一个唯一字符的集合 4 5 #基础功能: 6 a = t | s # t 和 s的并集 7 b = t & s # t 和 s的交集 8 c = t – s # 求差集(项在t中,但不在s中) 9 d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中) 10 11 基本操作: 12 t.add('x') # 添加一项 13 s.update([10,37,42]) # 在s中添加多项 14 15 16 #删除: 17 使用remove()可以删除一项: 18 t.remove('H') 19 20 #其它 21 len(s) 22 set 的长度 23 24 x in s 25 测试 x 是否是 s 的成员 26 27 x not in s 28 测试 x 是否不是 s 的成员 29 30 s.issubset(t) 31 s <= t 32 测试是否 s 中的每一个元素都在 t 中 33 34 s.issuperset(t) 35 s >= t 36 测试是否 t 中的每一个元素都在 s 中 37 38 s.union(t) 39 s | t 40 返回一个新的 set 包含 s 和 t 中的每一个元素 41 42 s.intersection(t) 43 s & t 44 返回一个新的 set 包含 s 和 t 中的公共元素 45 46 s.difference(t) 47 s - t 48 返回一个新的 set 包含 s 中有但是 t 中没有的元素 49 50 s.symmetric_difference(t) 51 s ^ t 52 返回一个新的 set 包含 s 和 t 中不重复的元素 53 54 s.copy() 55 返回 set “s”的一个浅复制

二、字符编码
1.http://www.cnblogs.com/yuanchenqi/articles/5956943.html
2.需知
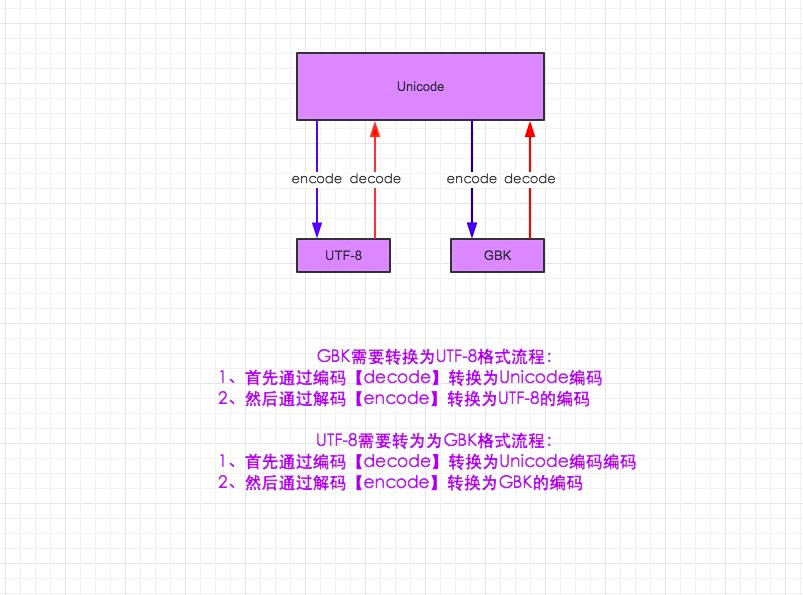
a.在python2默认编码是ASCII, python3里默认是unicode
b.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本,
不过在文件里存的还是utf-8,因为utf8省空间
b.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
先说python2
- py2里默认编码是ascii
- 文件开头那个编码声明是告诉解释这个代码的程序 以什么编码格式 把这段代码读入到内存,因为到了内存里,这段代码其实是以bytes二进制格式存的,不过即使是2进制流,也可以按不同的编码格式转成2进制流,你懂么?
- 如果在文件头声明了#_*_coding:utf-8*_,就可以写中文了, 不声明的话,python在处理这段代码时按ascii,显然会出错, 加了这个声明后,里面的代码就全是utf-8格式了
- 在有#_*_coding:utf-8*_的情况下,你在声明变量如果写成name=u"大保健",那这个字符就是unicode格式,不加这个u,那你声明的字符串就是utf-8格式
- utf-8 to gbk怎么转,utf8先decode成unicode,再encode成gbk
再说python3
- py3里默认文件编码就是utf-8,所以可以直接写中文,也不需要文件头声明编码了,干的漂亮
- 你声明的变量默认是unicode编码,不是utf-8, 因为默认即是unicode了(不像在py2里,你想直接声明成unicode还得在变量前加个u), 此时你想转成gbk的话,直接your_str.encode("gbk")即可以
- 但py3里,你在your_str.encode("gbk")时,感觉好像还加了一个动作,就是就是encode的数据变成了bytes里,我操,这是怎么个情况,因为在py3里,str and bytes做了明确的区分,你可以理解为bytes就是2进制流,你会说,我看到的不是010101这样的2进制呀, 那是因为python为了让你能对数据进行操作而在内存级别又帮你做了一层封装,否则让你直接看到一堆2进制,你能看出哪个字符对应哪段2进制么?什么?自己换算,得了吧,你连超过2位数的数字加减运算都费劲,还还是省省心吧。
- 那你说,在py2里好像也有bytes呀,是的,不过py2里的bytes只是对str做了个别名,没有像py3一样给你显示的多出来一层封装,但其实其内部还是封装了的。 这么讲吧, 无论是2还是三, 从硬盘到内存,数据格式都是 010101二进制到-->b'\xe4\xbd\xa0\xe5\xa5\xbd' bytes类型-->按照指定编码转成你能看懂的文字
编码应用比较多的场景应该是爬虫了,互联网上很多网站用的编码格式很杂,虽然整体趋向都变成utf-8,但现在还是很杂,所以爬网页时就需要你进行各种编码的转换,不过生活正在变美好,期待一个不需要转码的世界。
最后,编码is a piece of fucking shit, noboby likes it.
三、函数
1.形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
2.实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
3.默认参数:放到最后面。
4.正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。
5.非固定参数:若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数。(*args,**kwargs)
四、局部变量和全局变量
在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:
在定义局部变量的子程序内,局部变量起作用;在其它地方全局变量起作用。
五、返回值
要想获取函数的执行结果,就可以用return语句把结果返回
注意:
- 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,so 也可以理解为 return 语句代表着函数的结束
- 如果未在函数中指定return,那这个函数的返回值为None
六、递归算法
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
def calc(n):
print(n)
if int(n/2) > 0:
calc(int(n/2))
print(n)
calc(10)
print("result:", calc(10)) #None
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
如何获取最后一层的1:
def calc(n):
print(n)
if int(n/2) > 0:
n = calc(int(n/2)) #n=1,“1”值通过一层一层的返回最终print("result:", calc(10))
return n
calc(10)
print("result:", calc(10))
使用递归实现二分树查找:
data = range(1, 2000)
def bianry_search(find_str, data_set):
mid = int(len(data_set)/2)
if mid == 0:
if data_set[mid] == find_str:
print("find it finally", find_str)
else:
print("not find it.", find_str)
return #查找完成,要退出,不然出错。
if data_set[mid] == find_str:
print("find it", find_str, mid)
elif data_set[mid] > find_str:
print("going to search left:", data_set[mid], data_set[0:mid])
bianry_search(find_str, data_set[0:mid]) #递归方式,调用自己。
elif data_set[mid] < find_str:
print("going to search right:", data_set[mid],data_set[mid+1:])
bianry_search(find_str, data_set[mid+1:])
bianry_search(100, data)
七、匿名函数
#这段代码
def calc(n):
return n**n
print(calc(10))
#换成匿名函数
calc = lambda n:n**n
print(calc(10))
res = map(lambda x:x**2,[1,5,7,4,8])
for i in res:
print(i)
输出:
1
25
49
16
64
八、高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
def add(x,y,f):
return f(x) + f(y)
res = add(3,-6,abs)
print(res)
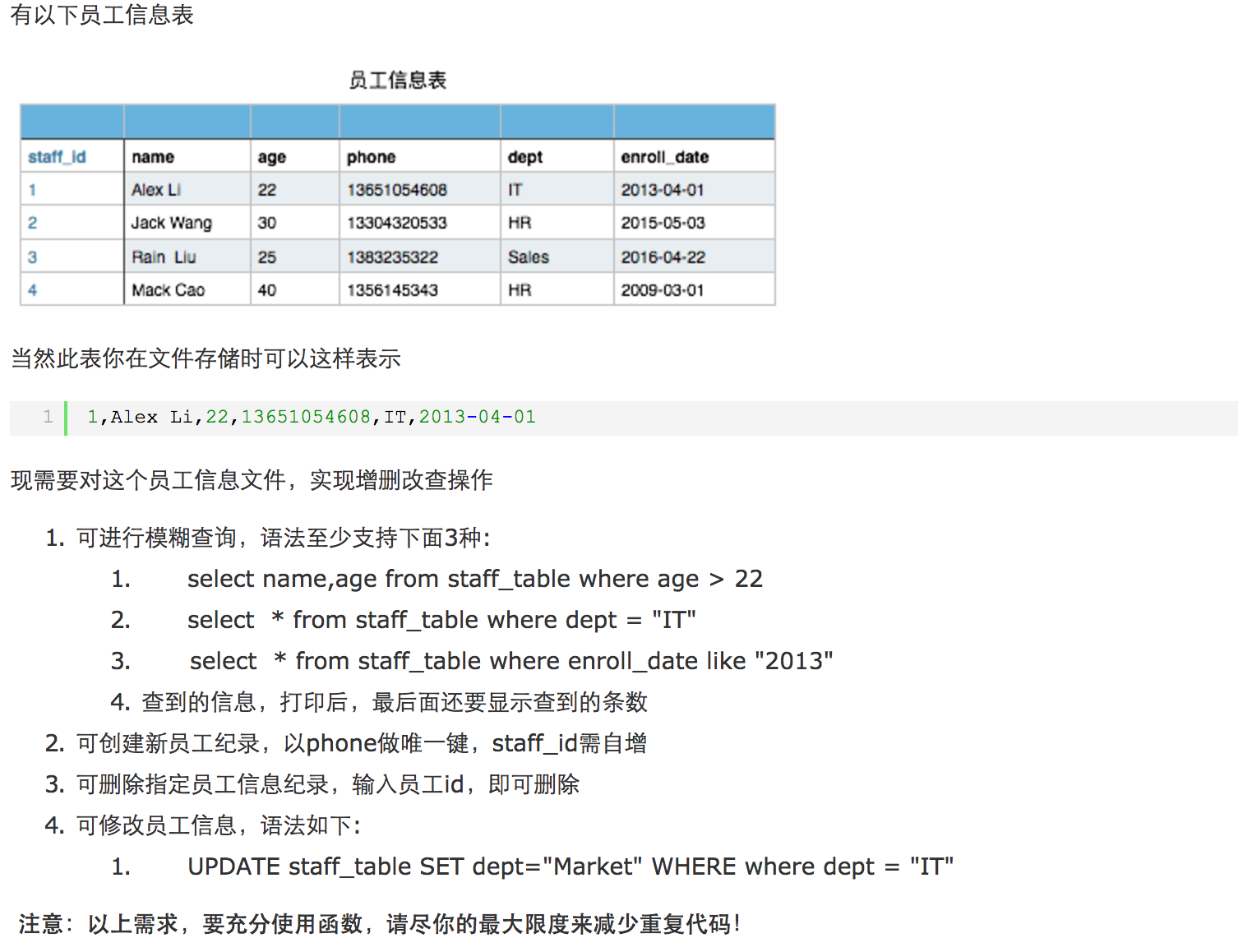
九、作业

 浙公网安备 33010602011771号
浙公网安备 33010602011771号