
Basic MF
(1) 基本思想
将评分矩阵R分解为用户矩阵U和项目矩阵S, 通过不断的迭代训练使得U和S的乘积越来越接近真实矩阵
(2)具体的过程如图
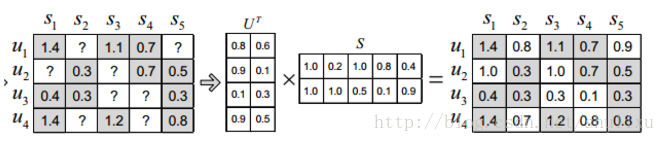
(3)目标函数如下,当Loss最小的时候,U和S的乘积可以近似的替代R
$$ min \ Loss = min \ \sum_{i=1}^{m} \sum_{j=1}^{n} (R_{ij} - U_i^TS_j)^2 $$
(4)更新函数
$$ U_i \leftarrow U_i - \eta \frac{\partial L}{\partial U_i}, \ S_j \leftarrow S_j-\eta \frac{\partial L}{\partial S_j} $$
η是学习速率
当η = 1.5时,通常以震荡的形式接近极值点
当η < 1时,迭代单调趋向极值点
当η > 2时,不会收敛,围绕极值点逐渐发散
具体取什么值要根据实验经验,另外还需要在每一步对学习速率进行衰减,目的是使算法尽快收敛。
该方法也叫 LFM(latent factor model).
(5)正则化,解决过拟合问题
$$ min\ Loss = min \ \sum_{i=1}^{m} \sum_{j=1}^{n} (R_{ij} - U_i^TS_j)^2
+ \lambda (|| U_{i} ||^{2} + || S_{j} ||^{2}) $$
梯度下降结束的条件:真实值和预测值的差小于阈值
(6)参数
隐特征个数:F
学习速率:α
正则化参数:λ
负样本/正样本比例:R
实验发现,R 对 LFM 性能影响最大,随着负样本数目的增加,LFM 的准确率和召回率有明显提高,
当 R > 10后趋于稳定,
同时,随着负样本数目增加,覆盖率不断降低,流行度不断增加,说明 ratio 参数控制了推荐算法发掘长尾的能力。
另外,与之前实验比较,在所有指标上都优于 UserCF 和 ItemCF。
然而当数据集非常稀疏时,LFM 的性能会明显下降。
(7)实际应用
LFM 模型在实际使用中有一个困难,就是很难实现实时推荐。经典的 LFM 模型每次训练都需要扫描所有的用户行为记录,并且需要在用户行为记录上反复迭代来优化参数,所以每次训练都很耗时,实际应用中只能每天训练一次。在新闻推荐中,冷启动问题非常明显,每天都会有大量的新闻,这些新闻往往如昙花一现,在很短的时间获得很多人的关注,然后在很短时间内失去关注,实时性就非常重要。
雅虎对此提出了一个解决方案。
首先,利用新闻链接的内容属性(关键词、类别等)得到链接 i 的内容特征向量 $ y_i $ , 其次,实时收集用户对链接的行为,并且用这些数据得到链接 i 的隐特征向量 $ q_i $ ,然后,利用下面的公式预测用户 u 是否会单击链接 i:
$$ r_{ui}=x^T_uy_i+p^T_uq_i $$
$ y_i $ : 根据物品的内容属性直接生成
$ x_{uk} $ : 用户 u 对内容特征 k 的兴趣程度,用户向量 xuxu 可以根据历史行为记录获得,每天计算一次
$ p_u , q_i $ : 实时拿到的用户最近几小时的行为训练 LFM 模型获得
对于一个新加入的物品 i,可以通过 $ x^T_uy_i $ 估计用户 u 对物品 i 的兴趣,然后经过几个小时后,通过 $ p^T_uq_i $ 得到更准确的预测值。
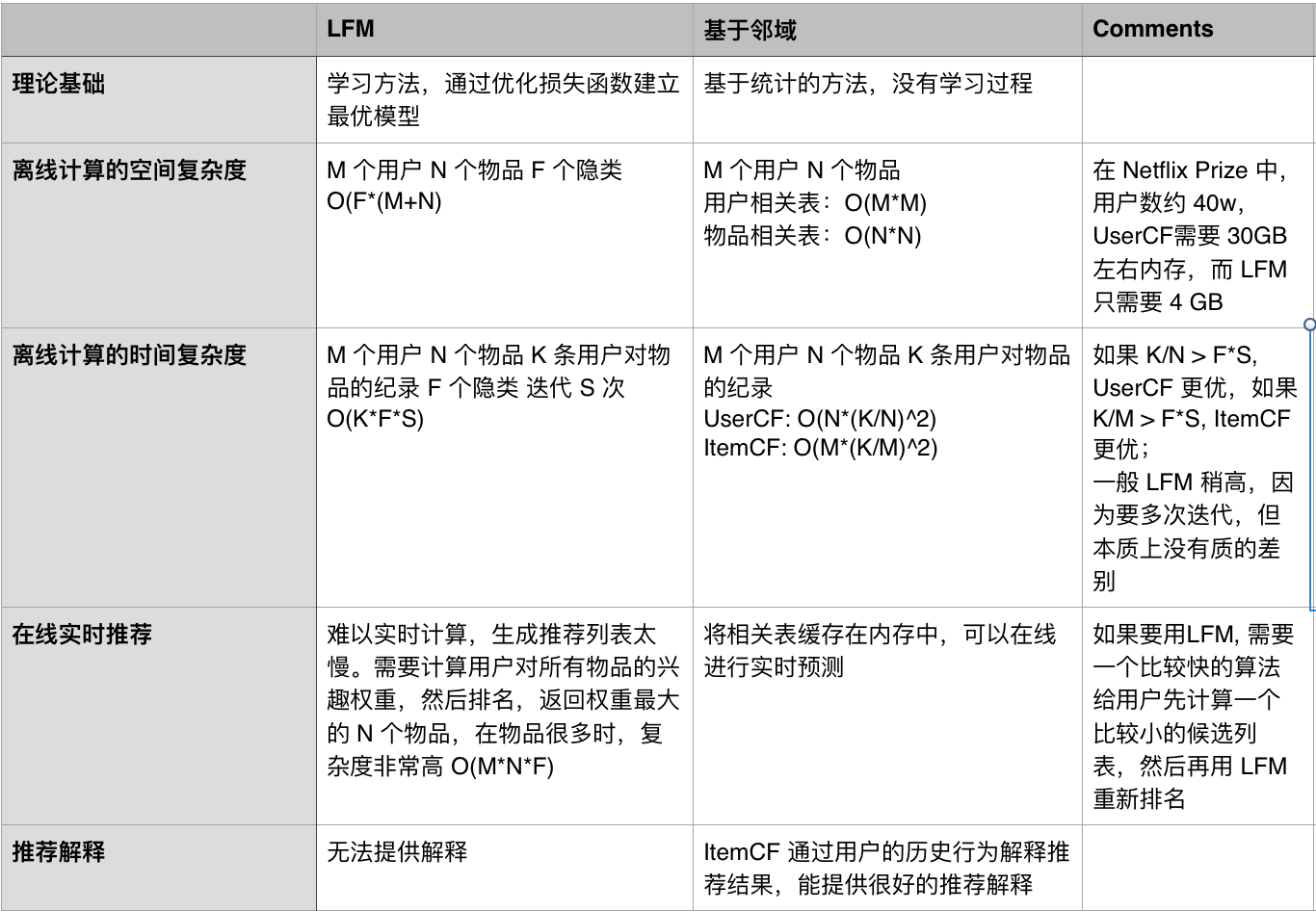
(8)优缺点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号