Coursera-Getting and Cleaning Data-Week3-dplyr+tidyr+lubridate的组合拳
Coursera-Getting and Cleaning Data-Week3
Wednesday, February 04, 2015
好久不写笔记了,年底略忙。。
Getting and Cleaning Data第三周其实没什么好说的,一个quiz,一个project,加一个swirl。
基本上swirl已经把第三周的内容都概括进去了。就是dplyr, tidyr以及lubridate包的学习和使用。其中dplyr专注于选择/筛选,tidyr关注于数据重塑型,二lubridate是我目前接触过的最好用的R中处理时间的包。
这三个包都是Hadley Wickam开发的,秉承了这系列包简洁,实用,好理解的特点。dplyr包尤其像sql语句,select, group_by什么的,有sql基础的人理解起来不会很难。
该系列swirl安装代码如下:
library(swirl)
install_from_swirl("Getting and Cleaning Data")关于dplyr,swirl本身已经写得很详尽了。不过开发者有自己的一个总结。我最开始是在一个人的微博里看到这张图的。然后追本索源发现,它原载于Rstudio官网Cheatsheets网页。里面还有markdown/Shiny包的快捷应用图像,值得初学者打印一整张下来好好学习。

dplyr+tidyr
总结一下dplyr+tidyr的应用,就是:
1)筛选/选择数据: select, filter。其中select选择列,filter添加筛选条件(类似于SQL中的where).select里有如select(iris,contains/ends_with/everthing等快速筛选用法。这个在上文所提的Cheatsheets里有,不再综述。
2)整合数据,类似于reshape2:gather(从宽变窄),spread(从窄变宽),可以快速改变数据结构。
3)数据排序/命名:arrange(行排序),rename(重命名列)
4)添加删除变量,多表查询:mutate(列,类似于cbind),transmute(几列并行),join, left_join等。
同时,因为他们系出同门,我们可以用%>%来简化代码,避免重复输入。
lubridate
关于lubridate包,常用的为:
1)指定格式的数据输出,如ymd("20110604")和mdy("06-04-2011")等,只要指定好ymdhms的顺序,R可以协助识别许多数据
2)常见数据的处理,如second(arrive),wday(arrive),并可添加时区(tz)
3)计算区间,如interval(arrive,leave,tz="Pacific/Auckland"),
需要注意的是,这个包的使用涉及了R时区的概念。如果你是中文系统,发现你的monday, sunday被系统自动替换成周一,周日等中文字符的话,请看时区设置Sys.setlocale。 我是windows系统,所以改成英文的话是Sys.setlocale("LC_TIME","English")。这个在接下来的画图课里有一定的用处。
基本上过了一遍swirl后,quiz不是大问题。
Project
关于project,中英文一起看吧,题目写得有点简略了,但是重点是探索的过程。
我们那个超级好人超级NICE的TA David Hood在讨论区里曾发过一张图给看不懂题目的人解释一下数据结构。因为TA都在讨论区发过了,所以我觉得可以共享一下。
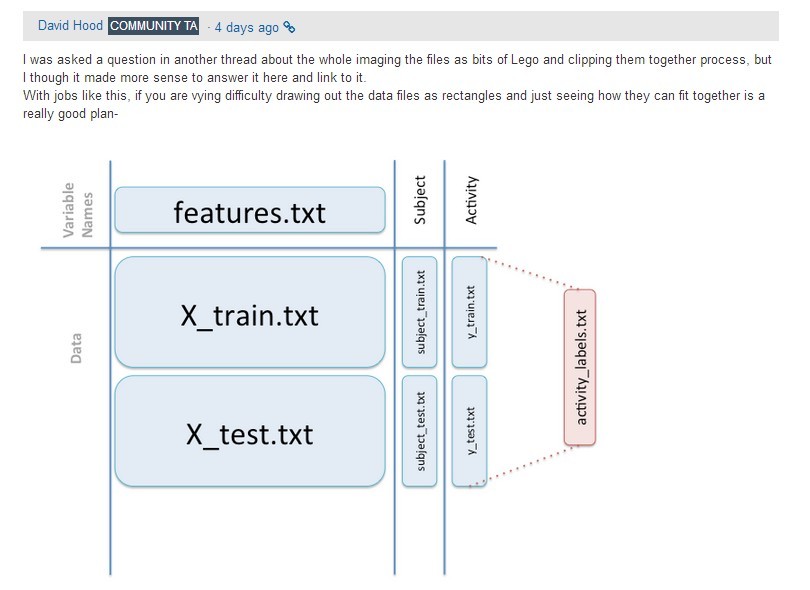
这里需要注意,老师满强调tidy data的概念。不管是宽的数据还是短的数据,只要符合tidy data规则,都算tidy data。各位有兴趣可以回去啃啃Hadley的那个PDF。
之前跟Q群的人讨论这个project时,看到有四种处理该project某一问的方法。包括简洁的group_by+summarize_each,或者绕一个圈的gather+group_by+summarize+spread组合,还有用reshape2的melt+dcsat组合,以及R programming里面着重介绍的循环+apply/lapply组合。有兴趣的可以自行尝试~~
在数据分析里,数据处理是一个苦差事。有人说一个数据挖掘项目,可能数据处理会占用60-70%甚至更多的时间,建模什么的,一旦数据处理好了,就很快,因为常用且经过时间验证的可靠模型也就那么几种。同时这个数据处理,也是了解业务的一个重要途径。所以这门课还是不可或缺的。我的博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号