
Kubernetes 系列(九):配置AlertManager报警
Prometheus将数据采集和报警分成了两个模块。报警规则配置在Prometheus Servers上,然后发送报警信息到AlertManger,然后我们的AlertManager就来管理这些报警信息,包括silencing、inhibition,聚合报警信息过后通过email、PagerDuty、HipChat、Slack 等方式发送消息提示。
让AlertManager提供服务总的来说就下面3步: * 安装和配置AlertManger * 配置Prometheus来和AlertManager通信 * 在Prometheus中创建报警规则。
1.安装和配置AlertManager
新建 alertmanager-config.yaml:
kind: ConfigMap apiVersion: v1 metadata: name: alertmanager namespace: monitoring data: alertmanager.yml: |- global: smtp_smarthost: "smtp.qq.com:465" smtp_from: "xxx@qq.com" smtp_auth_username: "xxx@qq.com" --发件人邮箱 smtp_auth_password: "rwqrfhtrocefdeih" --授权码 smtp_require_tls: false route: group_by: [] group_wait: 30s group_interval: 1m repeat_interval: 1m receiver: default-receiver receivers: - name: default-receiver email_configs: - to: 'xxx@163.com' --收件人邮箱
新建alertmanager-deploy.yaml:
--- apiVersion: apps/v1 kind: Deployment metadata: labels: name: alertmanager-deployment name: alertmanager namespace: monitoring spec: replicas: 1 selector: matchLabels: app: alertmanager template: metadata: labels: app: alertmanager spec: containers: - image: prom/alertmanager:v0.16.1 name: alertmanager ports: - containerPort: 9093 protocol: TCP volumeMounts: - mountPath: "/alertmanager" name: data - mountPath: "/etc/alertmanager" name: config-volume resources: requests: cpu: 50m memory: 50Mi limits: cpu: 200m memory: 200Mi volumes: - name: data emptyDir: {} - name: config-volume configMap: name: alertmanager --- apiVersion: v1 kind: Service metadata: labels: app: alertmanager annotations: prometheus.io/scrape: 'true' name: alertmanager namespace: monitoring spec: type: NodePort ports: - port: 9093 targetPort: 9093 nodePort: 31192 selector: app: alertmanager
部署:
kubectl apply -f alertmanager-config.yaml
kubectl apply -f alertmanager-deploy.yaml
2. 配置alertmanager与prometheus通信
修改Prometheus的config-map.yaml,添加如下配置:
alerting: alertmanagers: - static_configs: - targets: ["alertmanager.monitoring.svc:9093"]
3.配置告警规则,新建prometheus-rules.yaml:
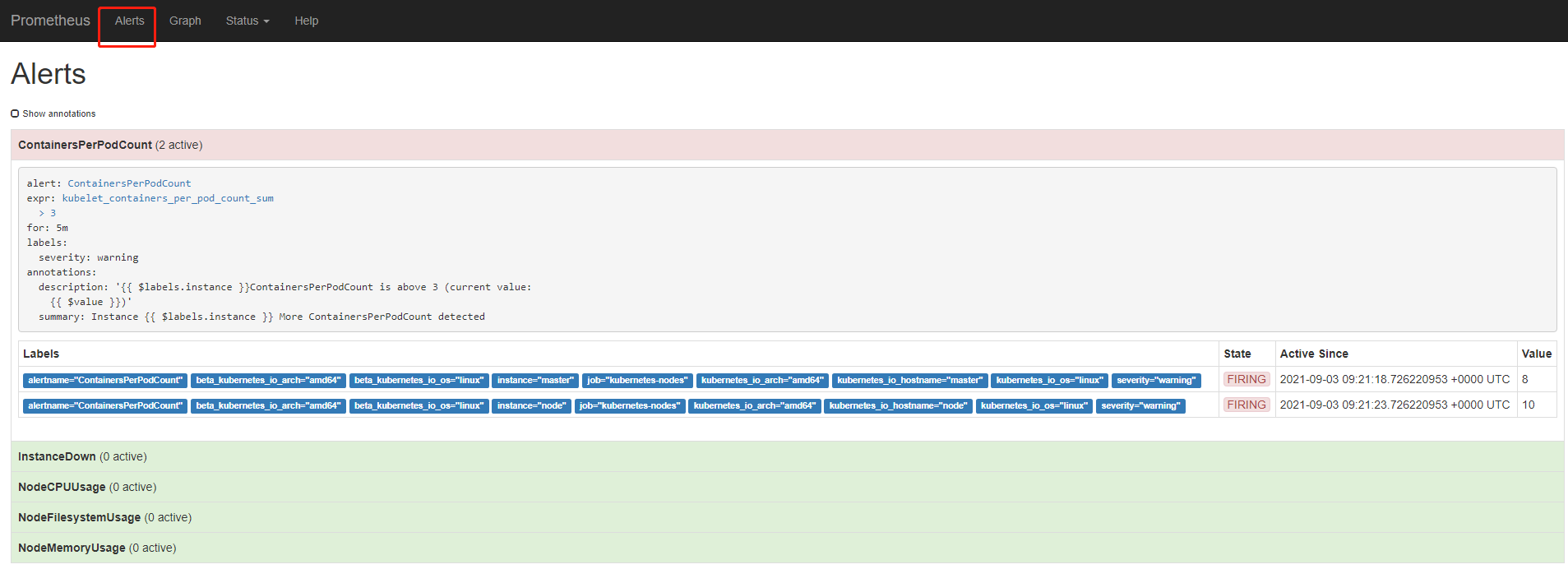
apiVersion: v1 kind: ConfigMap metadata: name: prometheus-rules namespace: monitoring data: general.rules: | groups: - name: general.rules rules: - alert: InstanceDown expr: up == 0 for: 1m labels: severity: error annotations: summary: "Instance {{ $labels.instance }} stop job" description: "{{ $labels.instance }} job {{ $labels.job }} stop job one minute." node.rules: | groups: - name: node.rules rules: - alert: NodeFilesystemUsage expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 10 for: 5m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} : {{ $labels.mountpoint }} High Filesystem usage detected" description: "{{ $labels.instance }}: {{ $labels.mountpoint }} Filesystem usage is above 10% (current value: {{ $value }})" - alert: NodeMemoryUsage expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 10 for: 5m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} High Memory usage detected" description: "{{ $labels.instance }}Memory usage is above 10% (current value: {{ $value }})" - alert: NodeCPUUsage expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 10 for: 5m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} High CPU usage detected" description: "{{ $labels.instance }}CPU usage is above 10% (current value: {{ $value }})" - alert: ContainersPerPodCount expr: kubelet_containers_per_pod_count_sum>3 for: 5m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} More ContainersPerPodCount detected" description: "{{ $labels.instance }}ContainersPerPodCount is above 3 (current value: {{ $value }})"
接着我们要让prometheus能读取到rules配置,所以要修改两个地方,第一个是prometheus-deployment.yaml,添加如下配置:
- name: prometheus-rules configMap: name: prometheus-rules - name: alertmanager-config-volume configMap: name: alertmanager
然后修改prometheus的config-map.yaml,添加如下配置:
rule_files: - /etc/prometheus/rules/*.rules
重新加载修改后的prometheus配置文件:
kubectl apply -f config-map.yaml
kubectl apply -f prometheus-deployment.yaml
这个时候我们去刷新Prometheus的UI界面就能看到AlertManager的相关数据了:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号