
Redis 高并发带来的一些问题
前言
本文讲述Redis在遇到高并发时的一些问题。即遇到大量请求时需要思考的点,如缓存穿透 缓存击穿 缓存雪崩 热key处理。一般中小型传统软件企业,很难碰到这个问题。如果有大并发的项目,流量有几百万左右。这些要深刻考虑。
1. 缓存穿透和缓存击穿
简单的讲就是如果该数据原本就不存在,那么就会发生缓存穿透;如果缓存内容因为各种原因失效,那么就会发生缓存击穿。具体一点来说,如果缓存中不存在需要查询的内容,一般情况下需要再深入一层进行查询,一般为不能承受压力的关系型数据库(承压能力为缓存的1%,甚至更低),如果数据库中不存在,则叫做缓存穿透;反之,如果数据库中存在这个数据,则叫做缓存击穿。这种查询在流量不高的情况下,不会出现问题,如果查询数据库的流量过高,尤其是数据库中不存在的情况下,严重时会导致数据库不可用,连带影响使用数据库的其他业务,本业务也有很大的可能性受到影响。
缓存穿透指缓存中数据不存在,然后大量请求查数据库导致数据库异常。缓存没有数据,数据库也有数据,穿透两层。
缓存击穿指缓存中数据不存在,数据库中有此数据,请求穿透一层。
1.1 缓存穿透
解决方案如下
1.1.1 空值缓存
既然该数据本身就不存在,最简单粗暴的方式就是直接将不存在的值定义为空(视具体业务和缓存的方式定义为null或者””)。具体方式是每次查询完数据库,我们可以将key在缓存中设置对应的值为空,短期内再次查询这个key的时候就不用查询数据库了。
为了系统的最终一致性,这些key必须设置过期时间,或者必须存在更新方式,防止这个key的数据后期真实存在,但该key始终为空,导致数据不一致的情况出现。
缺点:如果key数量巨大且分散无任何规律,就会浪费大量缓存空间,并且不能抗住瞬时流量冲击(尤其是遇到恶意的攻击的时候,有可能将缓存空间打爆,影响范围更大),需要额外配置降级开关(查询数据库的开关或者限流),这时本方案就显得没想象的那么美好。针对不能抗住瞬时流量的情况,常见的处理方式是使用计数器,对不存在的key进行计数,当某个key在一定时间达到一定的量级,就查询一次数据库,按照数据库的返回值对key进行缓存。未达指定阈值数量之前,按照商定的空值返回。
应用场景:key全集数据数据量级较小,并且完全可预测,可以通过提前填充的方式直接将数据缓存。
1.1.2 布隆过滤器(BloomFilter)
提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。迅速判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
实际应用中,Google BigTable,Apache HBbase 和 Apache Cassandra 使用布隆过滤器减少对不存在的行和列的查找。
高效的hash算法:建议的算法包括MurmurHash、Fnv的稳定高效的算法。
1.2 缓存击穿
解决方案如下:
1.2.1 利用互斥锁
利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
这是比较常见的做法,是在缓存失效的时候,不是立即去查询数据库,先抢互斥锁(比如Redis的SETNX一个mutex key),当操作返回成功时(即获取到互斥锁),再进行查询数据库的操作并回设缓存;否则,就重试整个获取缓存的方法或者直接返回空。
1.2.3 异步构建缓存
采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
当缓存失效时,不是立刻去查询数据库,而是先创建缓存更新的异步任务,然后直接返回空值。这种做法不会阻塞当前线程,并且对于数据库的压力基本可控,但牺牲了整体数据的一致性。从实际的使用看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,所有查询返回的内容均为空值,但是对于一致性要求不高的互联网功能来说这个还是可以忍受。
2. 缓存雪崩
缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
(一)给缓存的失效时间,加上一个随机值,避免集体失效,但是不能彻底规避。
(二)使用互斥锁,但是该方案吞吐量明显下降了。
(三)双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点
- I 从缓存A读数据库,有则直接返回
- II A没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程。
- III 更新线程同时更新缓存A和缓存B。
3. 热key
热key问题说来也很简单,就是瞬间有几十万的请求去访问redis上某个固定的key,从而压垮缓存服务的情情况。
3.1 怎么发现热key
方法一:凭借业务经验,进行预估哪些是热key
其实这个方法还是挺有可行性的。比如某商品在做秒杀,那这个商品的key就可以判断出是热key。缺点很明显,并非所有业务都能预估出哪些key是热key。
方法二:在客户端进行收集
这个方式就是在操作redis之前,加入一行代码进行数据统计。那么这个数据统计的方式有很多种,也可以是给外部的通讯系统发送一个通知信息。缺点就是对客户端代码造成入侵。
方法三:在Proxy层做收集
有些集群架构是下面这样的,Proxy可以是Twemproxy,是统一的入口。可以在Proxy层做收集上报,但是缺点很明显,并非所有的redis集群架构都有proxy。
graph LR
clinet-->proxy
proxy-->redis1
proxy-->redis2
proxy-->redis3
方法四:用redis自带命令
(1)monitor命令,该命令可以实时抓取出redis服务器接收到的命令,然后写代码统计出热key是啥。当然,也有现成的分析工具可以给你使用,比如redis-faina。但是该命令在高并发的条件下,有内存增暴增的隐患,还会降低redis的性能。
(2)hotkeys参数,redis 4.0.3提供了redis-cli的热点key发现功能,执行redis-cli时加上–hotkeys选项即可。但是该参数在执行的时候,如果key比较多,执行起来比较慢。
方法五:自己抓包评估
Redis客户端使用TCP协议与服务端进行交互,通信协议采用的是RESP。自己写程序监听端口,按照RESP协议规则解析数据,进行分析。缺点就是开发成本高,维护困难,有丢包可能性。
以上五种方案,各有优缺点。根据自己业务场景进行抉择即可。那么发现热key后,如何解决呢?
3.2 如何解决
(1) 利用二级缓存
比如利用ehcache,或者一个HashMap都可以。在你发现热key以后,把热key加载到系统的JVM中。
针对这种热key请求,会直接从jvm中取,而不会走到redis层。
假设此时有十万个针对同一个key的请求过来,如果没有本地缓存,这十万个请求就直接怼到同一台redis上了。
现在假设,你的应用层有50台机器,OK,你也有jvm缓存了。这十万个请求平均分散开来,每个机器有2000个请求,会从JVM中取到value值,然后返回数据。避免了十万个请求怼到同一台redis上的情形。
(2) 备份热key
这个方案主要防止热key放在一台redis服务器中,把热key服务到集群中的多台服务器中。根据redis集群数量构建一个新的key,判断这个key不存在后,把热key数据复制到这个新key上,这个新key也冗余到了其他redis集群中,下次取的时候计算方式是新key方式,取到了。
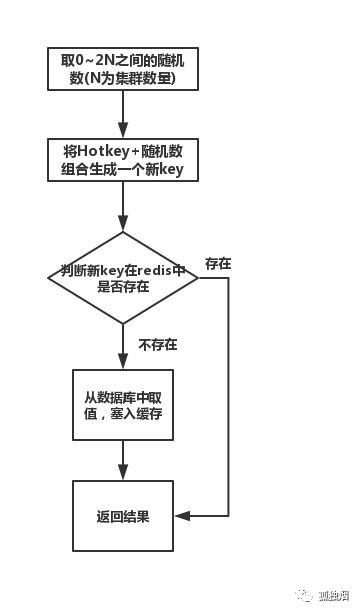
有办法在项目运行过程中,自动发现热key,然后程序自动处理么?
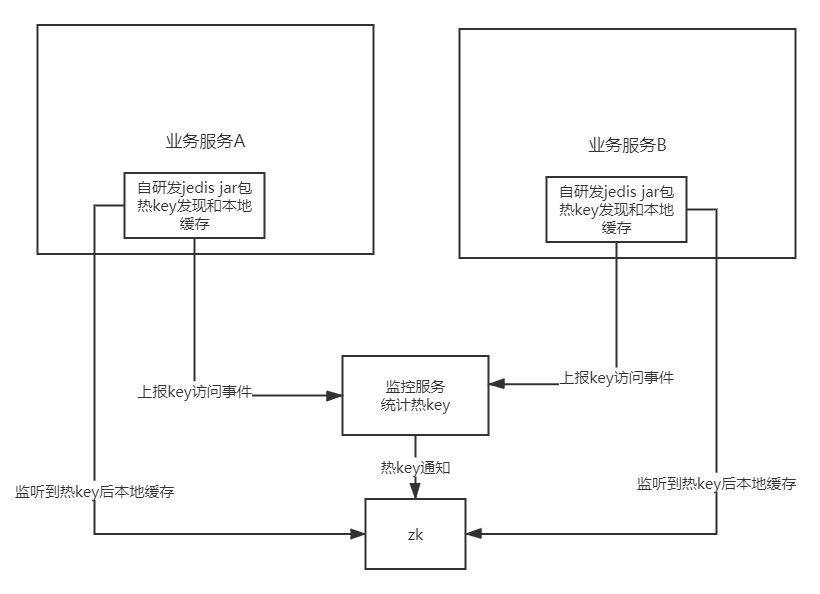
(1)监控热key
(2)通知系统做处理
监控热key的方式上面有说到,监控服务监控到热key后通过手段(如zk)通知各个业务系统缓存热key。如下图所示
4. 并发竞争key
这个问题大致就是,同时有多个子系统去set一个key。这个时候要注意什么呢?大家思考过么。需要说明一下,博主提前百度了一下,发现答案基本都是推荐用redis事务机制。博主不推荐使用redis的事务机制。因为我们的生产环境,基本都是redis集群环境,做了数据分片操作。你一个事务中有涉及到多个key操作的时候,这多个key不一定都存储在同一个redis-server上。因此,redis的事务机制,十分鸡肋。
解决方案:
(1)如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较简单。
(2)如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.
期望按照key1的value值按照 valueA-->valueB-->valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。加版本号的方式。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。总之,灵活变通。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号