部署的策略对比
前言
目前软件的更新迭代意味更频繁的部署,更加频繁也意味着已经部署的代码会对站点可用性和客户体验带来负面影响。这就是制定代码部署策略如此重要的原因,因为它可以最大限度的降低产品和客户的风险。
那么如何不停机部署?常见的部署方式有那些?
1. 部署方式
1.1 大爆炸部署
顾名思义,停机更新。"大爆炸”部署一次性更新整个应用或者其中的大部分。不适用于现代应用,因为面向公众的或者是关键业务应用无法接受这种风险,一旦中断就意味着巨大的经济损失。回滚通常耗时且代价巨大,甚至是不可能的。
不够有的时候也会使用吧,给用户发通知,并且都是在夜间进行更新的。大爆炸的方式适合非生产环境系统(例如,重新创建开发环境),或者是类似桌面应用这种供应商打包的解决方案。
1.2 蓝绿、红黑、A/B 部署
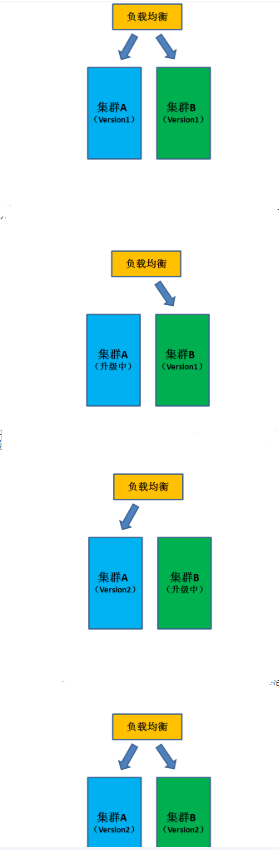
开始集群A和集群B同时提供服务,升级时摘除一个集群A进行升级,升级好后从B切换到A,然后对B进行升级,升级后加入负载均衡中。
也可以对B进行保留不进行升级,在A升级后如果出现问题后可将流量在切换回B。
蓝绿部署依赖流量路由。这可以通过更新主机的 DNS CNAMES 来完成。但是,TTL 太久会导致这些变更被延迟。或者,你可以改变负载均衡的配置,让变更立即生效。类似 ELB 的连接特性可以用来提供无缝连接。
1.3 滚动部署
在滚动部署中,应用的新版本逐步替换旧版本。实际的部署发生在一段时间内。在此期间,新旧版本会共存,而不会影响功能和用户体验。这个过程可以更轻易的回滚和旧组件不兼容的任何新组件。
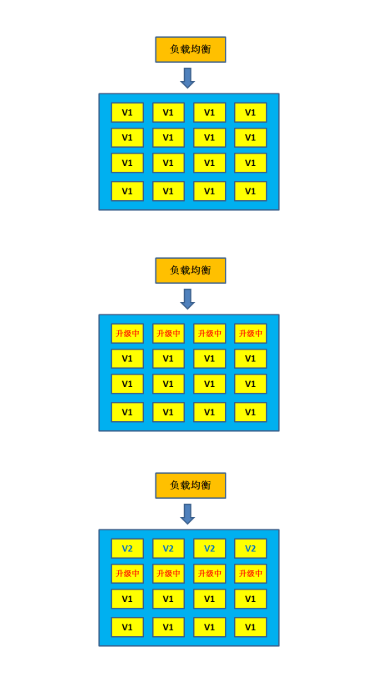
在集群中逐步更新节点为新的版本。
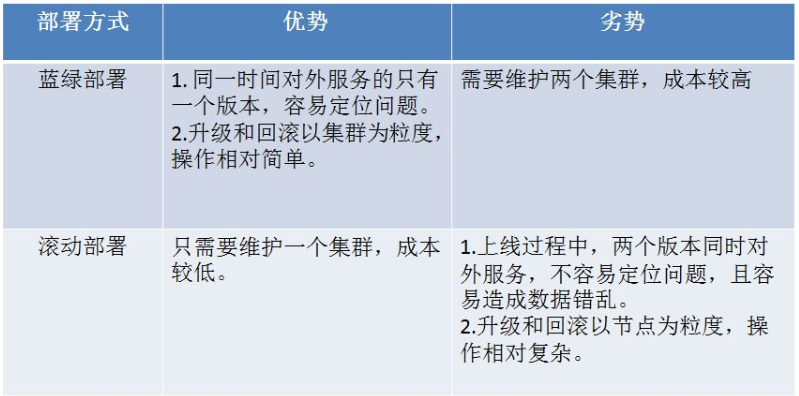
蓝绿部署和滚动部署的对比:
1.4 金丝雀部署
金丝雀部署和蓝绿有点像,但是它更加规避风险。你可以阶段性的进行,而不用一次性从蓝色版本切换到绿色版本。
采用金丝雀部署,你可以在生产环境的基础设施中小范围的部署新的应用代码。一旦应用签署发布,只有少数用户被路由到它。最大限度的降低影响。
如果没有错误发生,新版本可以逐渐推广到整个基础设施。
金丝雀部署的主要挑战是设计一种路由部分用户到新应用的方法。 此外,一些应用可能需要同类用户进行测试,另一些应用可能每次都需要不同类型的用户。
探索一些技术,来考虑路由新用户的方法:
- 在允许外部用户访问之前,将内部用户暴露给金丝雀部署;
- 基于源 IP 范围的路由;
- 在特定地理区域发布应用;
- 使用应用程序逻辑为特定用户和群体解锁新特性。当应用为其他用户上线后,移除此逻辑。
有点像微信体验版本,内测申请。
2. 部署最佳实践
现代应用团队可以遵循一些最佳实践,来最大限度的降低部署风险:
-
使用部署清单。例如,清单上可能有一项是“在确保停止应用服务后,备份所有数据库”,来防止数据损坏。
-
采用持续集成(CI)。CI 确保从代码仓库检入的特性分支代码,只会在经过一系列的依赖检查,单元和集成测试,并且成功构建后,才会合并到主干分支。如果过程中出现错误,构建就会失败,并通知应用团队。所以使用 CI 意味着应用的每次变更在部署之前都会进行测试。常见的 CI 工具包括:CircleCI,Jenkins。
-
采用持续交付(CD)。使用 CD 打包 CI 构建的代码产物,并随时准备部署到一个或多个环境中。
-
使用标准操作环境(SOEs)来确保环境一致性。你可以使用类似 Vagrant 和 Packer 这样的工具来部署工作站和服务器。
-
使用自动化构建工具来自动化环境构建。使用这些工具,通常都是简单的点击一个按钮,来销毁整个基础设施栈并从头开始构建。CloudFormation 就是这种工具。
-
在目标服务器中使用类似 Puppet、Chef 和 Ansible 这样的配置管理工具,来自动应用 OS 设置、打补丁和安装软件。
-
使用 Slack 这样的通信渠道来自动通知不成功的构建和应用故障。
-
创建一个程序,在部署失败的时候向负责的团队发送警告。理想情况下,你会在 CI 环境中捕获这些内容,但是如果变更已经部署了,你将需要一种方法来通知负责的团队。
-
无论是因为可用性还是错误率问题,对健康检查失败的部署启用自动回滚。
2.1 部署后监控
即使你采用了所有的这些最佳实践,事情仍然可能会失败。因此,对部署后立即发生的问题进行监控,与规划和执行完美的部署同样重要。
应用性能监控(APM)工具可以帮助团队监控关键性能指标,包括部署后的服务器响应时长。应用和系统架构的变更会极大的影响应用性能。
类似 Rollbar 这样的错误监控解决方案同样重要。它会迅速通知团队新部署或重新激活部署中的错误,这些部署可能会引发严重的 bug,需要立即引起关注。
如果没有错误监控工具,这些 bug 可能永远也不会被发现。虽然一些遇到 bug 的用户会花时间反馈,但大多数其他用户不会这样做。随着时间推移,客户的负面体验会降低满意度,甚至更糟糕的是,阻碍正在进行的业务交易。
错误监控工具还可以在运维 /DevOps 团队和开发者之间,共享所有部署后发生的问题。这些共享让团队变得更具有协作性,响应能力更强。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号