Java操作Hadoop、Map、Reduce合成
原始数据:
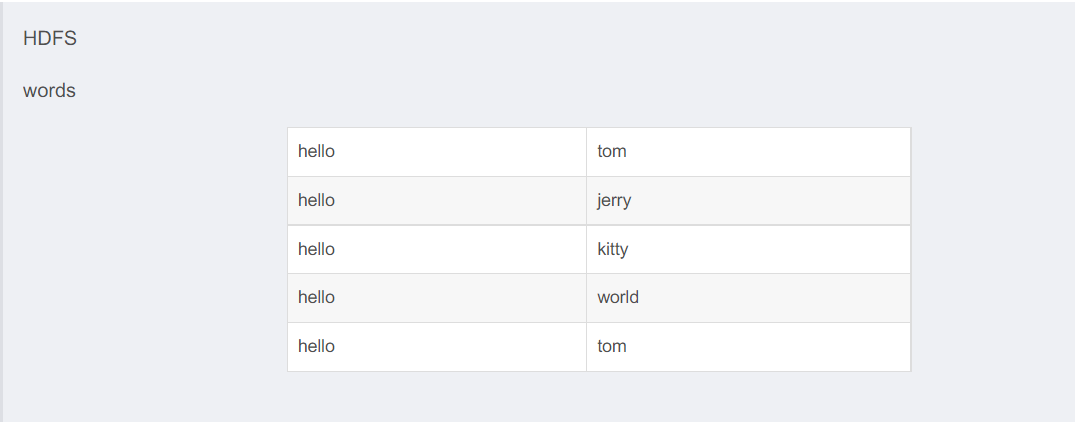
Map阶段
1.每次读一行数据,
2.拆分每行数据,
3.每个单词碰到一次写个1
<0, "hello tom">
<10, "hello jerry">
<22, "hello kitty">
<34, "hello world">
<46, "hello tom">
点击查看代码
/**
* @ClassName:WordCountReduce
* @Description:TODO
* @author:Li Wei Ning
* @Date:2022/4/28 10:55
*/
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Text 数据类型:字符串类型 String
* IntWritable reduce阶段的输入类型 int
* Text reduce阶段的输出数据类型 String类型
* IntWritable 输出词频个数 Int型
* @author 暖阳
*/
public class WordCountReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
/**
* key 输入的 键
* value 输入的 值
* context 上下文对象,用于输出键值对
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context){
try {
int sum=0;
for(IntWritable val:values){
sum+=val.get();
}
context.write(key,new IntWritable(sum));
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println("成功!!!");
}
}
}
reduce阶段
1.把单词对应的那些1
2遍历
3求和
<hello, {1,1,1,1,1}>
<jerry, {1}>
<kitty, {1}>
<tom, {1,1}>
<world, {1}>
点击查看代码
/**
* @ClassName:WordCountReduce
* @Description:TODO
* @author:Li Wei Ning
* @Date:2022/4/28 10:55
*/
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Text 数据类型:字符串类型 String
* IntWritable reduce阶段的输入类型 int
* Text reduce阶段的输出数据类型 String类型
* IntWritable 输出词频个数 Int型
* @author 暖阳
*/
public class WordCountReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
/**
* key 输入的 键
* value 输入的 值
* context 上下文对象,用于输出键值对
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context){
try {
int sum=0;
for(IntWritable val:values){
sum+=val.get();
}
context.write(key,new IntWritable(sum));
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println("成功!!!");
}
}
}
整合合并
点击查看代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @ClassName:WordCount
* @Description:TODO
* @author:Li Wei Ning
* @Date:2022/4/28 10:54
*/
public class WordCountTest {
public static void main(String[] args) {
try {
/*定义配置*/
Configuration config = new Configuration();
/* config.set("fs.defaultFS", "hdfs://192.168.47.128:9000");*/
/*定义一个工作任务,用于套接map和reduce两个阶段*/
Job job = Job.getInstance(config);
/* 定义工作任务用map*/
job.setMapperClass(WordCountMap.class);
/*定义map的输出key*/
job.setMapOutputKeyClass(Text.class);
/*定义map的输出value*/
job.setMapOutputValueClass(IntWritable.class);
/*定义map的文件路径*/
Path srcPath = new Path("C:/Users/暖阳/Desktop/123.txt");
/*定义map的输入文件*/
FileInputFormat.setInputPaths(job,srcPath);
/* 定义reduce用哪个类*/
job.setReducerClass(WordCountReduce.class);
/*指定reduce的输出key*/
job.setOutputKeyClass(Text.class);
/*指定reduce的输出value*/
job.setOutputValueClass(IntWritable.class);
/* 定义主类*/
job.setJarByClass(WordCountTest.class);
/*定义reduce的输出文件路径*/
Path outPath = new Path("C:/Users/暖阳/Desktop/WordCountTest");
/*输出最终结果文件路径*/
FileOutputFormat.setOutputPath(job, outPath);
/*提交job并关闭程序*/
System.exit(job.waitForCompletion(true) ? 0 : 1);
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println("最终的");
}
}
}
输出结果
hello 5
jerry 1
kitty 1
tom 2
world 1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号