第二次结对作业
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018SE2/homework/11248 |
|---|---|
| 作业目标 | <解决爬虫登入问题 爬取经验写入文件> |
| 作业源代码 | https://gitee.com/its_fucking_great |
| 队员1 | <211806335> |
| 队员2 | <211806344> |
结对再体验
结对感受
在经历过上一次的结对磨合之后这次的结对体验可以说是完美无瑕,凭借着我们互相对对方的深刻认知我们在一开始便分好工进行结对编程,在这次的结对中能感受到1+1>2,两个人的一起努力能够比两个人分开做做的更好,效率更高,错误更少,我们也慢慢爱了结对编程。
结对照片

代码行数及时间预估
- 代码行数:96行
- 需求分析时间:40min
- 编码时间:360min
思路分析
思维导图
在接触到题目时我们便做了这个思维导图,简单的理清了一下自己的思路。首先爬虫解决爬取数据问题,通过url进入到课堂完成内,在爬到数据后先存到数组中,根据题目需求计算最高分,最低分,平均分,最后写入到文本文件。

代码分析
- 首先在一开始,我们通过《Java 爬虫遇到需要登录的网站,该怎么办?》中学习到解决爬虫的登入问题,并且使用第一次编程作业中的方法将课程完成部分的第一个div爬取出来测试是否能够成功爬取。

- 这里我们通过循环遍历将data-url都存入到数组中,输出测试,方便进行下一步的工作。
Elements items = document.getElementsByClass("interaction-row");
String[] urls = new String[14];
int i=0;
for (Element item : items) {
if(item.text().contains("课堂完成")) {
urls[i] = item.attr("data-url");
System.out.println(urls[i]);
i++;
}
}
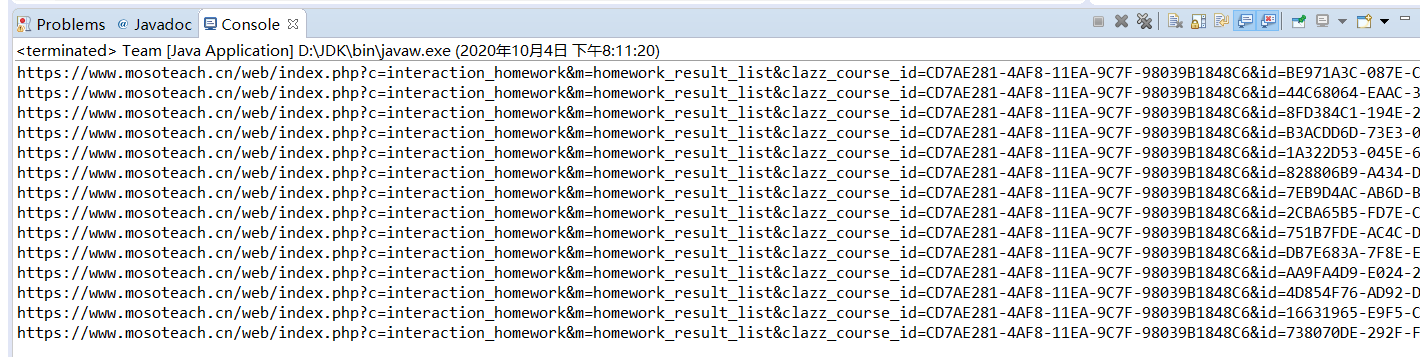
- 在观察课堂活动里的作业结果我们发现了主要分为三个部分,1.未提交,2.尚无评分,3.已评阅。在未提交这个情况里,通过页面元素的观察发现可以通过homework-info来将未提交的经验设为0,而尚无评分评分的情况下可以直接将经验设为0,最后通过字符串提取出经验值。
int exp;
if (eStu.select("[class=homework-info ]").text().contains("未提交")) {
exp = 0;
} else if (eStu.child(3).child(1).child(1).text().contains("尚无评分")) {
exp = 0;
} else {
String text = eStu.child(3).child(1).child(1).text().replaceAll(" 分", "");
exp = Integer.parseInt(text);
}
return exp;
- 我们创建了一个pojo学生类,之后创建一个泛型集合用来存放班级里学生的信息,并且打开第一个网页通过遍历将学生信息存入泛型数组中,并且初始学生的经验为第一个活动的经验。
ArrayList<Student> stuList = new ArrayList<>();
Document d = Jsoup.connect(urls[0]).header("Cookie", cookie).maxBodySize(Integer.MAX_VALUE).get();
Elements eStus = d.getElementsByClass("homework-item");// 获取学生信息元素集合
// 循环遍历,将班上所有同学的姓名。学号导入集合,并设置初始经验
for (Element eStu : eStus) {
String name = eStu.child(0).child(1).child(0).text();
String num = eStu.child(0).child(1).child(1).text();
stuList.add(new Student(name, num, getSore(eStu)));
}
- 通过循环爬取剩下每个活动,将活动中学生的经验根据学号查找对应相加。
// 循环所有活动url,设置全面经验
for (i = 1; i < urls.length; i++) {
System.out.println("正在爬取第" + (i + 1) + "个");
d = Jsoup.connect(urls[i]).header("Cookie", cookie).maxBodySize(Integer.MAX_VALUE).get();
Elements eStus2 = d.getElementsByClass("homework-item");
// 遍历页面每个学生信息
for (Element eStu : eStus2) {
String num = eStu.child(0).child(1).child(1).text();
//遍历学生列表,找到相同学号的加经验
for (Student stu : stuList) {
if (stu.getNumber().equals(num))
stu.setScore(stu.getScore() + getSore(eStu));
}
}
}
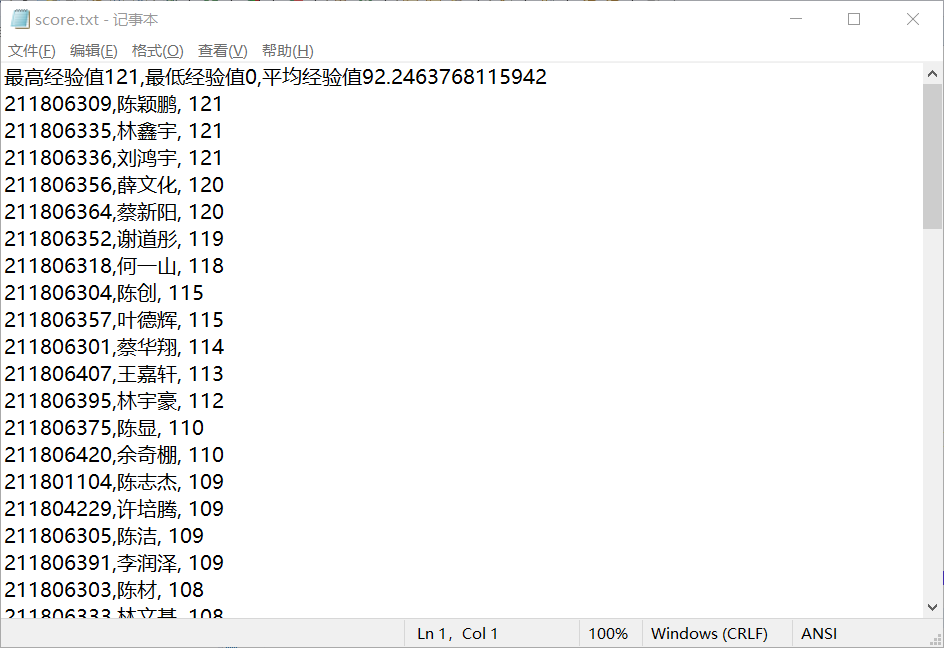
- 最后将数据写入文件,通过之前学习的打印输出流,将每个学生的信息经验和班级里的最高分,最低分,平均分,写入到记事本文件中,最终可以在文件中看到我们这次爬取的最终数据。
commit记录
问题总结
在爬取经验时,我们只能爬取到末尾经验为0的同学,一开始我们认为时我们的算法出现了问题,我们找了很久都没发现问题,最终在陈少龙同学的指导下我们了解到了是因为jsuop的爬取范围有限,所以只能先爬取到前面的同学,又因为云班的排序方式所以我们只能爬取到经验为0的同学。所以我们将爬取范围设置为最大值。

心得体会
在这次的作业中,我们发现了许多我们问题:拖延症晚期,每次作业都是到最后一天才开始写不到最后一天不会写一样,这也导致了我们的作业及时度分数都没有得到,对以前的知识已经有些忘记,在这次我们使用到之前的知识时候发现大部分已经忘记,对知识掌握的不牢靠,我们越学习会发现自己不懂的越多,所以希望我们下次能够解决我们的问题,做得更好。
参考文献

 浙公网安备 33010602011771号
浙公网安备 33010602011771号