
day14学习内容分享
今日内容概要
- 算法简介及而二分法
- 三元表达式
- 各种生成式
- 匿名函数
- 重要内置函数
- 常见内置函数
内容详细
算法简介及二分法
算法(概念了解)
- 什么是算法
算法就是解决问题的有效方法 不是所有的算法都很高效 也有不合格的算法 - 算法应用场景
推荐算法(抖音视频推送 淘宝商品推送)
成像算法(AI相关)......
几乎涵盖了我们日常生活中的方方面面 - 算法的条件
输入性, 输出性,明确性, 有限性,有效性 - 时间复杂度
O(1)< O(login)<O(n)<O(n^2)<O(n!) - 常见的大O运行时间(n一般为元素的个数):
- O(logn):对数时间,例如:二分查找
- O(n): 线性时间,简单查找
- O(nlogn): 快速排序
- O(n^2):选择排序
- O(n!):旅行商问题解决方案##
二分法
二分法是一个高效的算法 用于计算机的查找过程中
1.使用要求
二分法查找依赖的是顺序结构表,数组
# 必须是有序的
查找针对的是有序数据 所以只能用插入、删除操作不频繁,一次性多次查找的场景中
2.二分法的缺陷
针对开头结尾的数据 查找效率很低
常见算法的原理以及伪代码
"""数据量太小不适合二分查找,与直接遍历相比效率提升不明显。但有一个例外,就是数据之间的比较操作非常费时,比如数组中存储的都是组成长度超过100的字符串。
"""
3.一般要求找到某一个值或一个位置。
二分法代码示例
l1 = [12, 21, 32, 43, 56, 76, 87, 98, 123, 321, 453, 565, 678, 754, 812, 987, 1001, 1232]
# 定义需要查找的数字
def get_middle(l1, targer_num):
if len(l1) == 0:
print('没找到')
return
# 获取列表中的中间值 //遇到小数 取整
middle_index = len(l1) // 2
# 比较目标数据值与中间索引值的大小
if targer_num > l1[middle_index]:
# 切片保留中间值右边的一半
right_l1 = l1[middle_index+1:]
print(right_l1)
# 针对右边一半的列表继续二分并判断
return get_middle(right_l1, targer_num)
elif targer_num < l1[middle_index]:
# 切片左边一半的列表继续二分并判断
left_l1 = l1[:middle_index]
print(left_l1)
return get_middle(left_l1, targer_num)
else:
print('恭喜你找到了')
get_middle(l1, 754)
三元表达式
# 简化步骤:代码简单并且只有一行 那么可以直接在冒号后面编写
name = 'jason'
if name == 'jason':print('老师')
else:print('学生')
# 三元表达式:
res = '老师' if name == 'jason' else '学生'
print(res)
"""
数据值1 if 条件 else 数据值2
条件成立则使用数据值1 条件不成立则使用数据值2
当结果是二选一的情况下 使用三元表达式比较简便
不推荐多个三元表达式嵌套
"""
各种生成式/表达式/推导式
给所有列表的人名的后面加上_NB的后缀
# new_list = []
# for name in namelist:
# data = f'{name}_nb'
# new_list.append(data)
# print(new_list)
new_list = [name + '_nb' for name in namelist]
print(new_list)
# 复杂情况
new_list = ['大佬' if name == 'wei' else '小赤佬' for name in namelist if name != 'jason']
print(new_list)
# 先看for循环 执行后面的 再看前面
-
列表生成式
先看for循环 每次for循环之后再看for关键字前面的操作
-
字典生成式
![image]()
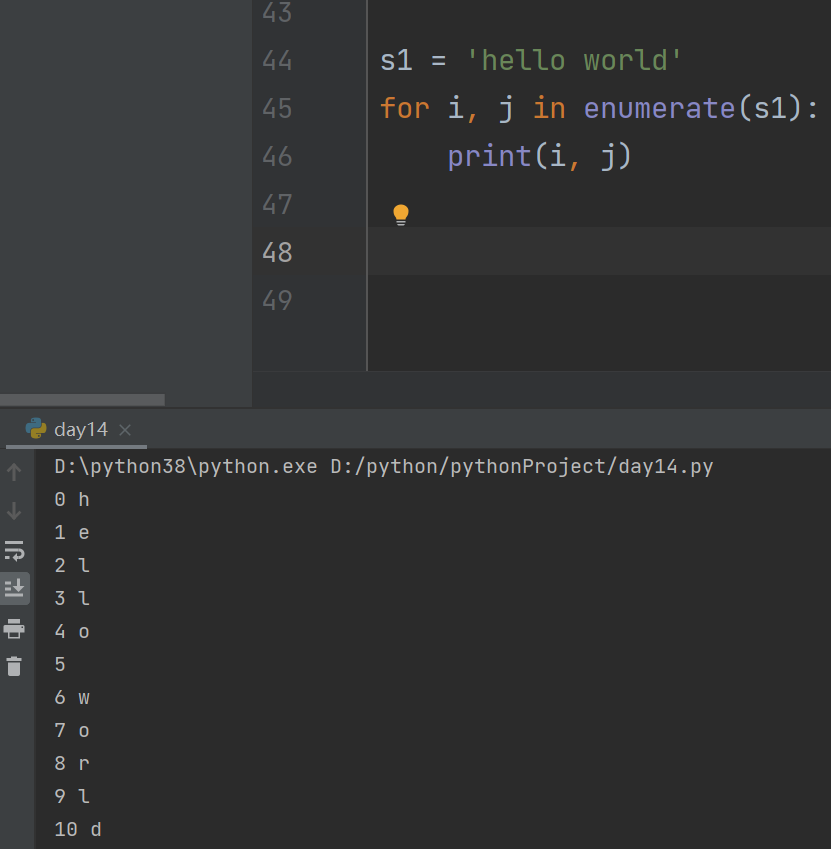
s1 = 'hello world' for i, j in enumerate(s1): # start= 代表从哪里开始 print(i, j) d1 = {i: j for i, j in enumerate('hello')} print(d1) # {0: 'h', 1: 'e', 2: 'l', 3: 'l', 4: 'o'} -
集合生成式
res = {i for i in 'hello'} print(res) # {'l', 'e', 'h', 'o'}
匿名函数
没有名字的函数 需要使用关键字lambda
语法结构
lambda 形参:返回值
使用场景
lambda a,b:a+b
匿名函数一般不单独使用 需要配合其他函数一起用
常见内置函数
1.map() 映射
l1 = [1, 2, 3, 4, 5]
# def func(a):
# return a + 1
res = map(lambda x:x+1, l1)
print(list(res)) # [2, 3, 4, 5, 6]
2.max()\min()
l1 = [11, 22, 33, 44]
res = max(l1)
d1 = {
'zj': 100,
'jason': 8888,
'berk': 99999999,
'oscar': 1
}
def func(a):
return d1.get(a)
res = max(d1, key=func)
print(res)
3. reduce
reduce 传多个值 返回一个值
from functools import reduce
l1 = [11, 22, 33, 44, 55, 66, 77, 88]
res = reduce(lambda a, b:a * b, l1)
print(res)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号