第二周总结
第二周总结
- python基本数据类型
- 基础运算符
- 垃圾回收机制和流程控制
- while for 循环
- 基本数据类型内置方法
- python学习之数据类型
bool 布尔值
1.用来判断事物的对错 是否可行 主要用于流程控制
2.只有两种判断
True 对的 可行的 真的
False 错的 不可行 假的
3.python中所有的数据都自带布尔值
布尔值有False的数据:
0 None ''[] {}
布尔值为True的数据:
除了上面 都是True
4.储存布尔值的变量名有一般推荐使用is_开头
is_delete = False
is_alive = True
tuple元组
1.'不可变'的列表
元组内索引的内存地址不可以修改
2.小括号括起来 内部可以存放多个数据值
数据值之间逗号隔开 数据值可以是任何数据类型
3.代码实现
t1 = (11, 22, 'jason')
4.元组和列表的区别
l1 = [11, 22, 33]
print(l1[2]) # 索引2对应的数据值
l1[2] = 666
print(l1[2]) # [11, 22, 666] 列表可以修改
# t1 = (11, 22 ,33)
# t1[2] = 999
# print(t1[2]) #会报错 不可修改
5.元组内如果只有一个数据值
t1 = (1)
t2 = (11.11)
t3 = ('jason')
print(type(t1), type(t2), type(t3)) # <class 'int'> <class 'float'> <class 'str'>
t1 = (1,)
t2 = (11.11,)
t3 = ('jason',)
print(type(t1), type(t2), type(t3))
# <class 'tuple'> <class 'tuple'> <class 'tuple'>
'''
可以存放多个数据值的同时 如果里面暂且只有一个数据值 那么建议加上逗号
'''
set集合数据类型
1.集合只能用于去重和关系运算
2.集合内数据只能是不可变类型
3.大括号括起来 内部存放多个数据值 数据值与数据值之间逗号隔开 数据值不是k:v键值对
4.代码实现
s1 = {1, 2, 3, 4, 5, 6}
5.定义空集合与空字典
{} 默认是字典
set() 定义空集合
用户交互
1.获取用户输入 input
input获取到的数据值都会同意处理成字符串类型
2.输出内部信息 print
1.括号内既可以放数据值也可以放变量名 并且支持多个 逗号隔开即可
2.print自带换行符
换行符:\r\n \n(斜杠与字母组合到一起可能会产生特殊的含义)
3.print也可以切换结束符
print(数据,end='默认是\n')
扩展:python2与python3中两个关键字的区别
python2中
input方法需要用户自己提前指定数据类型 写什么类型就是什么类型
raw_input方法与python3中input一致 输入的统一处理成字符串
python2中
print方法有两种使用方式
print 数据值
print(数据值)
格式化输出
提前定义一些内容 使用的时候可以局部修改
奖状 录取通知书 合同
代码实现:
现实生活中大部分使用下划线提示别人填写内容
在程序中需要使用占位符 %s %d
info = '%s同志你好'
'''单个占位符'''
# print(info % 'Jason') # Jason同志你好
# print('%s同志你好' % 'Tony') # Tony同志你好
# print(info % ('jason',))
# print('%s同志你好' % ('Tony',))
'''多个占位符'''
# desc = '姓名:%s 年龄:%s 爱好:%s'
# print(desc % ('jason', 18, ?'read'))
# print('姓名:%s 年龄:%s 爱好:%s' % ('tony', 28, 'rap'))
'''注意事项:有几个占位符就需要几个数据值'''
# print('my name is %s my age is %s' % ('jason',)) # 少了不行
# print('my name is %s my age is %s' % ('jason', 18, 'read')) # 多了不行
'''不同占位符的区别'''
# demo1 = '%s您好 您本月的话费是%s 余额是%s' # %s常见数据类型都支持
# print(demo1 % ('jason', 100, 10000000000000))
# demo2 = '%d您好 您本月的话费是%d 余额是%d' # %d只支持数字类型
# print(demo2 % ('tony', 1000000000, -100000))
print('%08d'% 123) # 00000123
print('%08d'% 1234324324) # 1234324324
基本运算符
1.数学运算符
+ - * / % // **
简化写法
n = 10
n += 1 # n = n + 1
n -= 1 # n = n - 1
n *= 1 # n = n * 1
n /= 1 # n = n / 1
n %= 1 # n = n % 1 取余数
n //= 1 # n = n // 1 取整
n **= 1 # n = n ** 1 次方
2.比较运算符
< > <= >= ==(代码中两个等于号才是等于) !=(不等于)
1.链式赋值
name = 'jason'
name1 = name
name2 = name1
name = name1 = name2 = 'jason'
2.交叉赋值
m = 100
n = 999
'''方式一:采取中间变量'''
temp = n
m = n
n = temp
print(m, n) # 999 999
'''方式二 交叉赋值语法'''
m, n = n, m
print(m, n) #999 100
3.解压赋值
name_list = ['jason', 'kevin', 'tony', 'oscar']
name1, name2, name3, name4 = name_list
'''解压赋值在使用的时候 正常情况下需要保证左边的变量名与右边的数据值个数一致'''
'''当需要解压的数据个数特别多 并且我们只需要使用其中的几个 那么可以打破上述的规则'''
# a, *b = name_list # *会自动接收多余的数据 组织成列表赋值给后面的变量名
# print(a) # jason
# print(b) # ['kevin', 'tony', 'oscar']
逻辑运算符
'''主要配合条件一起使用'''
and 与
and 连接的多个条件必须全部成立 结果才能成立
# 如果条件中全部由and组成那么判断起来非常的简单 只要发现一个不成立 结果就不成立
print(1 < 10 and 666) # 666 成立
print(1 < 10 and 2 < 8) # True 成立
print(111 and 222) # 222 成立
如果需要你准确的说出具体的结果值 那么需要按照下列方式
如果and左边的条件是成立的 那么就完全取决于右边的条件
右边如果直接是数据值 那么结果就是该数据值 如果是含有表达式 则为布尔值
or 或
# or连接的多个条件只要有一个成立 结果就成立
如果条件中全部由or组成那么判断起来非常的简单 只要发现一个成立 结果就成立
# print(1 < 10 or 666) # True
# print(666 or 1 > 10) # 666
print(0 or False) # False
print(0 or 111) # 111
not 非
取反
类似于说反话
"""
三者混合使用的时候有优先级之分 但是我们不需要记忆优先级 应该通过代码的形式提前规定好优先级
eg: 先乘除有加减 但是可以使用括号来改变优先级
(3>4 and 4>3) or ((1==3 and 'x' == 'x') or 3 >3) # False
"""
垃圾回收机制
"""
有一些语言 内存空间的申请和释放都需要程序员自己写代码才可以完成
但是python却不需要 通过垃圾回收机制自动管理
"""
一.引用计数器
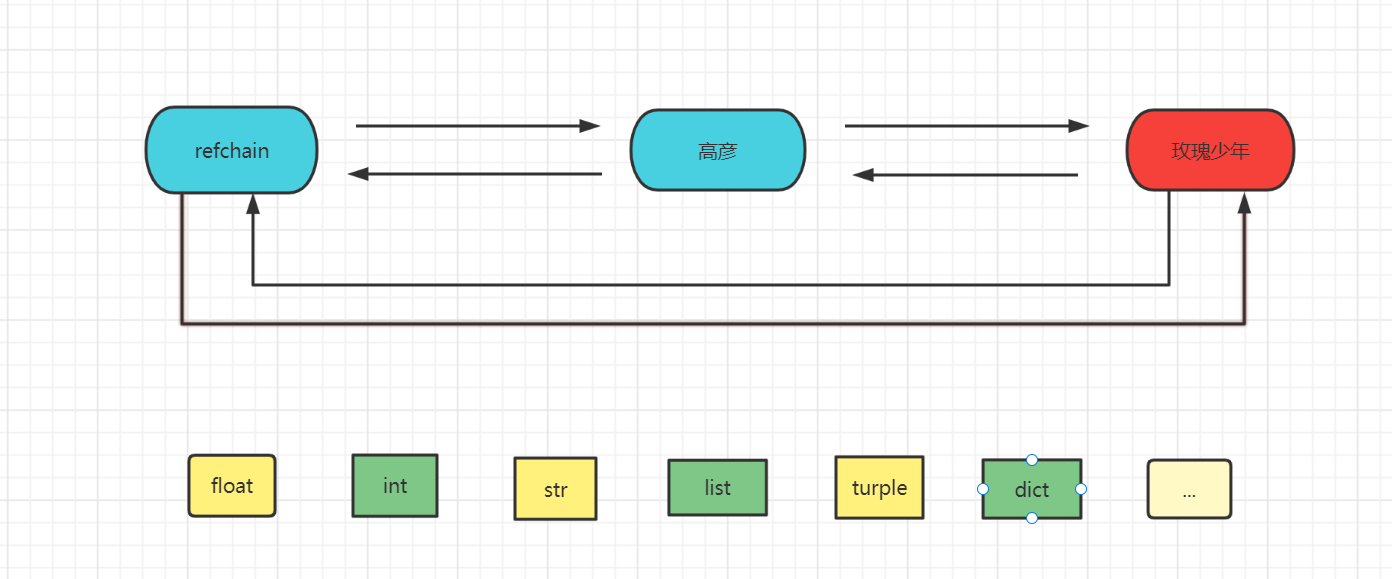
在python程序中创建的任何对象都会放在refchain链表中。
也就是说如果你得到了refchain,也就得到了python程序中的所有对象。
name = 'gaoyan' # 数据值jason身上的引用计数为1
name1 = name # 数据值jason身上的引用计数加一 为2
del name1 # 数据值jason身上的引用计数减一 为1
当数据值身上的引用计数为0的时候 就会被垃圾回收机制当做垃圾回收掉
当数据值身上的引用计数不为0的时候 永远不会被垃圾回收机制回收
二.标记清除
主要针对循环引用问题
l1 = [11, 22] # 引用计数为1
l2 = [33, 44] # 引用计数为1
l1.append(l2) # l1 = [11, 22, l2列表] 引用计数为2
l2.append(l1) # l2 = [33, 44, l1列表] 引用计数为2
del l1 # 断开变量名l1与列表的绑定关系 引用计数为1
del l2 # 断开变量名l2与列表的绑定关系 引用计数为1
当内存占用达到临界值的时候 程序会自动停止 然后扫描程序中所有的数据
并给只产生循环引用的数据打上标记 之后一次性清除
三. 分代回收
圾回收机制的频繁运行也会损耗各项资源
新生代、青春代、老年代(越往下检测频率越低)
流程控制理论
流程控制>>>:控制事物的执行流程
事物执行流程总共可以分为三种
1.顺序结构
从上往下依次执行 我们之前所编写的代码都属于该结构
2.分支结构
事物的执行会根据条件的不同做出不同的执行策略
3.循环结构
事物的执行会根据某个条件出现重复
ps:在代码的世界里 很多时候可能会出现三者混合
流程控制之分支理论
- python中使用代码的缩进来表示代码的从属关系
从属关系:缩进的代码(子代码)是否执行取决于上面没有缩进的 - 并不是所有的代码都可以拥有缩进的代码(子代码)
if关键字 - 如果有多行子代码属于同一个父代码 那么这些子代码需要保证相同的缩进量
- python中针对缩进量没有具体的要求 但是推荐使用四个空格(windows中tab键)
- 当某一行代码需要编写子代码的时候 那么这一行代码的结尾肯定需要冒号
- 相同缩进量的代码彼此之间平起平坐 按照顺序结构依次执行
流程控制之循环结构
1. 单if分支结构
if 条件:
条件成立之后才会执行代码块
username = input('username>>>:')
if username == 'Danielwei';
print ('老师好')
2.if...else...分支结构
if 条件:
条件成立之后执行的子代码
else:
条件不成立执行的子代码
username = input('username>>>:')
if username == '吴彦祖':
print('老师好')
else:
print('fuck off')
3.if...elif...else分支结构
if 条件1:
条件1成立之后执行的子代码
elif 条件2:
条件1不成立 条件2成立执行的子代码
elif 条件3:
条件1和2都不成立 条件3成立执行的子代码
else:
上述条件都不成立 执行的子代码
ps:中间的elif可以写多个、上述子代码永远只会走一个
score = input('请输入学生成绩>>>:')
score = int(score) # 将字符串的整数转换成整型的整数
if score >= 90:
print('优秀')
elif score >= 80:
print('良好')
elif score >= 70:
print('一般')
elif score >= 60:
print('及格')
else:
print('挂科 交钱重修')
4.if的嵌套使用(有点难)
age = 28
height = 170
weight = 110
is_beautiful = True
is_success = False
username = 'tony'
if username == 'tony':
print('tony发现目标')
if age < 30 and height > 160 and weight < 150 and is_beautiful:
print('大妹纸 手机掏出来 让我加微信')
if is_success:
print('吃饭 看电影 天黑了...')
else:
print('去你妹的 流氓!!!')
else:
print('不好意思 算了...关了灯都一样')
else:
print('不是本少爷')
while for 循环补充
就是想让一些代码反复的执行
while 条件:
条件成立之后执行的子代码(循环体代码)
1.先判断条件是否成立
2.如果成立则执行循环体代码
3.循环体代码执行完毕后再次回到条件判断处 判断条件是否成立
4.如果成立 则继续执行循环体代码
5.按照上述规律依次执行 直到条件不成立才会结束循环体代码的执行
# count = 1
# while count < 5:
# print('hello world')
# count += 1 # count = count + 1
# print('想不想干饭?')
break # 强行结束循环体
while循环体代码一旦执行到break会直接结束循环
continue # 直接跳到条件判断处
while循环体代码一旦执行到continue会结束本次循环 开始下一次循环
while 条件:
循环体代码
else:
循环体代码没有被强制结束的情况下 执行完毕就会执行else子代码
基本数据类型内置方法
我们之前学习的每一种数据类型本身都含有一系列的操作方法,内置方法是其中最多的(自带的功能)
在python中数据类型调用内置方法的统一句式为>>>:句点符
'jason'.字符串内置方法
绑定字符串的变量名.字符串内置方法
str.字符串内置方法
ps:数据类型的内置方法比较的多 想要掌握,不可以靠死记硬背 更多时候靠的是孰能生巧.
int整形相关操作
1.类型转换(将其他类型数据转换成整形)
int(其他数据类型)
2.进制数转换
十进制转换其他进制
0b二进制缩写 print(bin(100)) # 0b1100100
0x八进制缩写 print(oct(100)) # 0o144
0x十六进制缩写 print(hex(100)) # 0x64
ps:浮点型可以直接转 字符串必须满足内部是纯数字才可以
'''
数字的开头如果是0b则为二进制 0o则为八进制 0x则为十六进制
'''
其他进制转十进制
print(int(0b1100100))
print(int(0o144))
print(int(0x64))
print(int("0b1100100", 2))
print(int("0o144", 8))
print(int("0x64", 16))
3.python自身对数字的敏感度较低(精确度低)
python这门语言其实不厉害 主要是背后有大佬
如果需要进准的计算需要借助于模块numpy.....
float浮点型相关操作
1.类型转换
float(其他数据类型)
字符串里面可以允许出现一个小数点 其他必须是纯数字
2.python自身对数字的敏感度较低(精确度低)
str字符串相关操作
1.类型转换
str(其他类型数据)
ps:可以转换任意数据类型(只需要在后面加引号即可)
2.必须要掌握的方法
2.1.索引取值(其实位置0开始 超出范围直接报错)
s1 = ('hello world!') # 定义变量名
print(s1[0]) # 打印输出 h
print(s1[-1]) # 输出结果 !支持负数 从末尾开始
2.2.切片操作
print(s1[1:5]) # 索引取值 从1取到4 顾头不顾尾
print(s1[-1:-5]) # 输出结果空白 默认索引从左到右开始
print(s1[-5:-1]) # 输出结果orld 默认索引数据从左到右开始
2.3 修改切片方向
print(s1[1:5:1]) # 输出 ello 默认从1开始 差值为1
print(s1[1:5:2]) # 输出 el 默认从1开始 差值为2
print(s1[-1:-5:-1]) # 反方向的种 从后面开始 差值1 索引到4
print(s1[:]) # 不写数字就默认都要
print(s1[2:]) # 从索引2开始往后都要
print(s1[:5]) # 从索引0开始往后要到4
print(s1[::2]) # 索引所有值 差值2
2.4.统计字符串中字符的个数
print(len(s1)) # 12 总共有12个数
2.5.移除字符串首尾指定的字符
username = input('username>>>:').strip() # .strip
res1 = '$$wei$$'
print(res1.strip('$')) # wei
print(res1.lstrip('$')) # wei$$
print(res1.rstrip('$')) # $$wei
2.6.切割字符串中指定的字符
res = 'jason|123|read'
print(res.split('|')) # ['jason', '123', 'read'] 该方法的处理结果是一个列表
name, password, hobby = res.split('|') # 使用变量名代替对应的字符
print(res.split('|', maxsplit=1)) # maxsplit:最大切割值 后面数字多少 切割多少
# ['jason', '123|read'] 默认从左往右切指定个数
print(res.rsplit('|',maxsplit=1))
# ['jason|123', 'read'] 从右往左切指定个数
resplit:从右到左
2.7.字符串格式化输出
format玩法1:等价于占位符
res = 'my name is {} my age is {}'.format('wei', 123) # {}等价于占位符
print(res
format玩法2:索引取值并支持反复使用
res = 'my name is {0} my age is {1} {0} {0} {1}'.format('jason', 123)
print(res) # my name is jason my age is 123 jason jason 123
format玩法3:占位符见名知意
res = 'my name is {name1} my age is {age1}'.format(name1='jason', age1=123)
print(res) # my name is jason my age is 123 jason 123 jason
format玩法4:推荐使用(******* 给鸡哥拉满!!!!!!)
3.字符串
1.大小写相关
res = 'hElLO WorlD 666'
print(res.upper()) # HELLO WORLD 666 全部大写
print(res.lower()) # hello world 666 字母全部小写
'''
图片验证码:生成没有大小写统一的验证码 展示给用户看
获取用户输入的验证码 将用户输入的验证码和当初产生的验证码统一转大写或者小写再比对
'''
code = 'zBcqD1'
print('请输入图中的验证码的内容',code)
cs_code = input('请输入验证码>>>:').strip()
if cs_code.upper() == code.upper(): # upper:全部大写 lower:英文小写
print('验证码正确')
3.1 判断字符串中的大小写
res = 'hello world'
print(res.isupper()) # 判断字符串是否是纯大写 False
print(res.islower()) # 判断字符串是否是纯小写 True
3.2 判断字符串是否是纯数字
res = ''
print(res.isdigit()) # sdigit是python的一个函数,主要用于检查是否为数字 False
guess_age = input('guess_age>>>:').strip() # 获取用户输入值
if guess_age.isdigit(): # 判断用户输入值是否是数字
guess_age = int(guess_age) # 如果是
print('年龄', guess_age) # 打印年龄
else:
print('代笔!年龄都不知道怎么输入啊??'))
3.3替换字符串中指定的内容
res = 'my name is jason jason jason jason jason'
print(res.replace('jason', '你想要输入的')) # 前面不变 后面更改
# my name is handsome handsome handsome handsome handsome(输出结果)
print(res.replace('jason', 'tonySB', 1))
# my name is tonySB jason jason jason jason 从左到右替换指定内容
3.4.字符串的拼接
ss1 = 'hello'
ss2 = 'world'
print(ss1 + '$$$' + ss2) # hello$$$world
print(ss1 * 10) # 10遍hello
print('|'.join(['jason', '123', 'read', 'JDB'])) # jason|123|read|JDB 加入到每个字符串
print('|'.join(['jason', 123])) #运行失败 参与拼接的数据值必须都是字符串
3.5 统计指定字符出现的次数
res = 'hello world'
print(res.count('l')) # 3 count:计数
3.6 判断字符串的开头或者结尾
res = 'jason say hello'
res = 'jason say hello'
print(res.startswith('jason')) # True startswith 开头
print(res.startswith('j')) # True
print(res.startswith('jas')) # True
print(res.startswith('a')) # False
print(res.startswith('son')) # False
print(res.startswith('say')) # False
print(res.endswith('o')) # True endswith 结尾
print(res.endswith('llo')) # True
print(res.endswith('hello')) # True
3.7.其他方法补充
res = 'helLO wORld hELlo worLD'
print(res.title()) # Hello World Hello World 每个英文首字母大写
print(res.capitalize()) # Hello world hello world 第一个英文大写
print(res.swapcase()) # HELlo WorLD HelLO WORld 相反 大写的小写 小写的大写
print(res.index('O')) # 找索引值
print(res.find('O') # 实现检索字符串并且输出运算值的意思
print(res.index('c')) # 找不到直接报错
print(res.find('c')) # 找不到默认返回 找不到默认返回-1
print(res.find('LO')) # 也是类似索引值 找到下划线地址
list列表相关操作
1. 类型转换
list(其他数据类型)
ps:能够被for循环的数据类型都可以转成列表
print(list('hello world'))
# ['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd']
print(list({'name': 'jason', 'pwd': 123}))
# name pwd 字典也是取k值
print(list((1, 2, 3, 4))) # 1 2 3 4 元组
print(list({1, 2, 3, 4, 5})) # 1 2 3 4 5 字典
2.需要掌握的方法
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
1.索引取值(正负数)
print(l1[0]) # 111
print(l1[-1]) # 888
2.切片操作 与字符串讲解操作一致
print(l1[0:5]) # 111 222 333 444 取范围值1-4
print(l1[:]) # 111, 222, 333, 444, 555, 666, 777, 888
3.间隔数 方向 与字符串讲解操作一致
print(l1[::-1]) # 从尾往首 888 777 666 555 444 333 222 111
4.统计列表中数据值的个数
print(len(l1)) # 8
5.数据值修改
l1[0] = 123 # 123 222 333 ... 定义一个新的列表值
print(l1)
6.列表添加数据值
方式1:尾部追加数据值
l1.append('干饭') # apeend :在对象后面增加
print(l1) # [111, 222, 333, 444, 555, 666, 777, 888, '干饭']
l1.append(['jason', 'kevin', 'jerry'])
print(l1) # [111, 222, 333, 444, 555, 666, 777, 888, ['jason', 'kevin', 'jerry']]
方式2:任意位置插入数据值
l1.insert(0, 'jason') # ['jason', 111, 222, 333, 444, 555, 666, 777, 888]
print(l1) # 加在哪里看索引值的位置
l1.insert(1, [11, 22, 33, 44]) 在1位牵引值添加列表
print(l1) # [111, [11, 22, 33, 44], 222, 333, 444, 555, 666, 777, 888]
方式3:扩展列表 合并列表
ll1 = [11, 22, 33]
ll2 = [44, 55, 66]
print(ll1 + ll2) # [11, 22, 33, 44, 55, 66]
ll1.extend(ll2) # for循环+append
# xtend()函数主要是用于在列表末尾一次性追加另一个序列中的多个值(即用新列表扩展原来的列表
print(ll1) # [11, 22, 33, 44, 55, 66]
for i in ll2: # [11, 22, 33, 44]
ll1.append(i) # [11, 22, 33, 44, 55]
print(ll1) # [11, 22, 33, 44, 55, 66]
7.删除列表数据
方式1:通用的删除关键字del
del l1[0]
print(l1)
方式2:remove
l1.remove(444) # 括号内填写数据值 然后删除444
print(l1) # [111, 222, 333, 555, 666]
方式3:pop
ll1 = [111, 222, 333, 444, 555, 666]
ll1.pop(3) # 括号内填写索引值
print(ll1) # [111, 222, 333, 555, 666]
ll1.pop() # 默认尾部弹出数据值
print(ll1) # [111, 222, 333, 555]
res = ll1.pop(3)
print(res) # 444 pop 可以取出 等新的变量命名
res = ll1.remove(444)
print(res1) # None
8.排序
ss = [54, 99, 55, 76, 12, 43, 76, 88, 99, 100, 33]
ss.sort() # 默认是升序: python中sort() 函数用于对原列表进行排序
print(ss) # [12, 33, 43, 54, 55, 76, 76, 88, 99, 99, 100]
ss.sort(reverse=True)
# “reverse是python一个列表的内置函数,是列表独有的,用于列表中数据的反转,颠倒
print(ss) # 改为降序
# [100, 99, 99, 88, 76, 76, 55, 54, 43, 33, 12]
9.统计列表中某个数据值出现的次数
print(l1.count(111))
10.颠倒列表顺序
ss.reverse()
print(ss) # [33, 100, 99, 88, 76, 43, 12, 76, 55, 99, 54]
可变类型与不可变类型
s1 = '$$jason$$'
l1 = [11, 22, 33 ]
res = s1.strip('$') # jason
print(s1) # $$jason$$
'''字符串在调用内置方法之后并不会修改自己 而是产生了一个新的结果
如何查看调用方法之后有没有新的结果 可以在调用该方法的代码左侧添加变量名和赋值符号
res = s1.strip('$')
'''
print(s1.strip('$')) # jason
ret = l1.append(44) # 在数据最后添加一个数据值
print(l1) # [11, 22, 33, 44]
print(ret) # None
'''列表在调用内置方法之后修改的就是自身 并没有产生一个新的结果'''
可变类型:值改变 内存地址不变
l1 = [11, 22, 33]
print(l1) # [11, 22, 33]
print(id(l1)) # 2750734773384 内存地址
l1.append(44)
print(l1) # [11, 22, 33, 44]
print(id(l1)) # 2750734773384 内存地址不变
不可变类型:值改变 内存地址肯定变
res = '$$hello world$$'
print(res) # $$hello world$$
print(id(res)) # 1624393531568
res1 = res.strip('$')
print(res1) # hello world
print(id(res1)) # 1624393493360
dict字典相关操作
1.类型转换
dict()
字典的转换一般不使用关键字 而是靠自己手动转
2.必须要学的操作
u_dict = {
'name':'wei',
'password':3472,
'hobby':['baskertball','swimming']
}
2.1.按k取值(不推荐使用)
print(u_dict['username']) # 输出wei
print(u_dict['phone'])
2.2 按内置方法get取值(推荐使用)
print(u_dict.get('username')) # wei
print(u_dict.get('age')) # None
print(u_dict.get('name', '没有哟 嘿嘿嘿'))
# wei 键存在的情况下获取对应的值
print(u_dict.get('phone', '没有哟 嘿嘿嘿'))
# 键不存在默认返回None 但是可以通过第二个参数自定义
2.3 修改数据值
print(id(u_dict)) # 2274169855864
u_dict['name'] = 'tony'
print(id(u_dict)) # 2274169855864
print(u_dict)
# 'name': 'tony', 'password': 3472, 'hobby': ['baskertball', 'swimming']}
2.4 新增键对值
u_dict['age'] = 18 # 键不存在则新增键值对
print(u_dict)
2.5 删除数据
del u_dict['name']
print(u_dict)
# {'password': 3472, 'hobby': ['baskertball', 'swimming'], 'age': 18}
res = u_dict.pop('password')
print(u_dict) # {'hobby': ['baskertball', 'swimming'], 'age': 18}
print(res) # 3472
2.6 统计字典中键值对的个数
print(len(u_dict)) # 3
2.7 字典三剑客
print(u_dict.keys()) #一次性取所有的键
# dict_keys(['name', 'password', 'hobby'])
print(u_dict.values()) # 一次性获取字典所有的值
#dict_values(['wei', 3472, ['baskertball', 'swimming']])
print(u_dict.items())
#dict_items([('name', 'wei'), ('password', 3472), ('hobby', ['baskertball', 'swimming'])])
for i in u_dict.items():
k,v = i
print(k, v)
2.8 补充
print(dict.fromkeys(['name', 'pwd', 'hobby'], 123))
# {'name': 123, 'pwd': 123, 'hobby': 123}
# 快速生成值相同的字典
res = dict.fromkeys(['name', 'pwd', 'hobby'], [])
print(res) # {'name': [], 'pwd': [], 'hobby': []}
res['name'].append('jason')
res['pwd'].append(123)
res['hobby'].append('study')
print(res)
'''当第二个公共值是可变类型的时候 一定要注意 通过任何一个键修改都会影响所有'''
# res = user_dict.setdefault('username','tony')
# print(user_dict, res) # 键存在则不修改 结果是键对应的值
# res = user_dict.setdefault('age',123)
# print(user_dict, res) # 存不存在则新增键值对 结果是新增的值
user_dict.popitem() # 弹出键值对 后进先出
tuple元组相关操作
1.类型转换
tuple()
ps:支持for循环的数据类型都可以转成元组
2.元组必须掌握的方法
t1 = (11, 22, 33, 44, 55, 66)
# 1.索引取值
print(t1[0])
# 2.切片操作
print(t1[:])
print(t1[0:4])
print(t1[:-4])
# 3.间隔、方向
print(t1[0:6:2]) # (11, 33, 55)
print(t1[::-2]) # (66, 44, 22)
# 4.统计元组内数据值的个数
print(len(t1)) # 6
# 5.统计元组内某个数据值出现的次数
print(t1.count(11))
# 6.统计元组内指定数据值的索引值
print(t1.index(22))
# 7.元组内如果只有一个数据值那么逗号不能少
# 8.元组内索引绑定的内存地址不能被修改(注意区分 可变与不可变)
# 9.元组不能新增或删除数据
set集合相关操作
1.类型转换
set()
集合内数据必须是不可变类型(整型 浮点型 字符串 元组)
集合内数据也是无序的 没有索引的概念
2.集合需要掌握的方法
去重
关系运算
ps:只有遇到上述两种需求的时候才应该考虑使用集合
3.去重
s1 = {11, 22, 11, 22, 22, 11, 222, 11, 22, 33, 22}
l1 = [11, 22, 33, 22, 11, 22, 33, 22, 11, 22, 33, 22]
s1 = set(l1) #
l1 = list(s1)
print(l1) #
'''集合的去重无法保留原先数据的排列顺序'''
4.关系运算
群体之间做差异化校验
两个微信账户之间 有不同的好友 有相同的好友
f1 = {'jason', 'tony', 'jerry', 'oscar'} # 用户1的好友列表
f2 = {'jack', 'jason', 'tom', 'tony'} # 用户2的好友列表
# 1.求两个人的共同好友
print(f1 & f2) # {'jason', 'tony'}
# 2.求用户1独有的好友
print(f1 - f2) # {'jerry', 'oscar'}
# 3.求两个人所有的好友
print(f1 | f2) # {'jason', 'jack', 'tom', 'tony', 'oscar', 'jerry'}
# 4.求两个人各自独有的好友
print(f1 ^ f2) # {'oscar', 'tom', 'jack', 'jerry'}
# 5.父集 子集
print(f1 > f2)
print(f1 < f2)
字符编码(理论)
1.针对乱码不要慌 切换编码慢慢试即可
2.编码与解码
编码:将人类的字符按照指定的编码编码成计算机能够读懂的数据
字符串.encode()
解码:将计算机能够读懂的数据按照指定的编码解码成人能够读懂
bytes类型数据.decode()
3.python2与python3差异
python2默认的编码是ASCII
1.文件头
# encoding:utf8
2.字符串前面加u
u'你好啊'
python3默认的编码是utf系列(unicode)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号