JAVA基础
- Program Files:如果安装的软件是64位,则会默认安装到该目录下
- Program Files(x86):如果安装的软件是32位,则会默认安装到该目录下
- 软件工程师:
- 是一种职位的名称,通常是通过计算机的“某种编程语言”完成软件的开发
- Java软件工程师:通过Java编程语言完成软件的开发,通常是开发应用软件
- 计算机包括两部分:
- 硬件:鼠标、键盘、显示器、主机箱内部的CPU、内存条、硬盘等
- 注意计算机只有硬件是无法工作的,需要有软件驱动硬件才能工作
- 软件:系统软件和应用软件
- 系统软件:直接和硬件交互的软件,例如Win7、Winxp、Win8、Win10、Linux操作系统
- 应用软件:应用软件通常运行在系统软件中,例如qq运行在Windows操作系统上,qq就是应用软件,Win7就是系统软件
- 硬件:鼠标、键盘、显示器、主机箱内部的CPU、内存条、硬盘等
- Windows常见DOS命令(在最初的windows计算机中没有图形界面,只有DOS命令窗口):
- exit—退出当前DOS窗口
- cls(clear screen)—清屏
- dir(directory)—列出当前目录下的子文件/子目录
- cd(change directory) 相对路径/绝对路径—改变目录
- 绝对路径:表示该路径从某个磁盘的盘符下作为出发点的路径
- 相对路径:表示该路径从当前所在的路径下作为出发点的路径
- cd..—回到上级目录(..也是相对目录,.也是相对目录)
- cd\—回到根目录
- cd..\..\:回到指定的上级目录
- d: c: f:—切换盘符
- mkdir(make directory) 目录名称—创建文件夹
- del— del命令可以指定的文件而不能删除文件夹,eg:del *.class(支持模糊匹配)
- Tab键——自动补全
- 怎么查看本机的IP地址?什么是IP地址?有什么用?
- A计算机在网络中要想定位到(连接到)B计算机,那么必须要先知道B计算机的IP地址,IP地址也可以看做计算机在同一个网络当中的身份证号(唯一标识)
- ipconfig(ip地址的配置信息)
- ipconfig /all 该命令后面添加一个-all参数可以查看更详细的网络信息,这个详细的信息中包括网卡(要上网就需要网卡)的物理地址,例如:0A-00-27-00-00-06,这个物理地址具有全球唯一性,物理地址通常叫做MAC地址
- 把自己家的所有人的MAC地址绑定到路由器上就可以防止别人家的蹭网
- 怎么查看两台计算机是否可以正常通信?
- ping命令
- 语法格式:ping IP地址/ping 域名(www.baidu.com) 域名底层最终还是会被解析成IP地址的形式
- ping www.baidu.com -t 加上-t参数表示一直访问
- 快捷键:
- alt+table—应用之间快速切换
- window+d—切换到桌面
- window+l—锁屏
- window+r运行窗口
- tab—向右缩进
- shift+table—向左缩进
- 文本编辑器快捷键:
- 复制 ctrl+c
- 粘贴 ctrl+v
- 剪切 ctrl+x
- 保存 ctrl+s
- 撤销 ctrl+z
- 重做 ctrl+y
- 全选 ctrl+a
- 查找 ctrl+f
- 计算机语言(也叫计算机编程语言:用来编写程序)的发展:
- 什么是计算机编程语言?
- 提前的人为的制定好的一套交流规则,有的时候,有的语法需要死记硬背,不需要问为什么,只要遵循这套语法规则,那么程序员和计算机之间就可以很好的交流。这就是计算机编程语言。计算机编程语言有很多,例如:C语言、C++、Java、PHP.......
- 计算机语言发展史
- 第一代语言—机器语言(执行效率最高,不需要编译,计算机可以直接识别):主要编写二进制码。直接编写101010001这样的二进制,以打孔机为代表
- 计算机是由电流驱动的,电流只能表示两种状态:正、负,而正可以表示1,负对应0,101010001这些二进制代码正好和自然世界中的十进制存在转换关系,所以计算机可以模拟现实世界当中的事物
- 第二代语言—低级语言:主要以汇编语言为代表,在低级语言中已经引入了一些英语单词,例如变量赋值:mov a to b;
- 第三代语言—高级语言:几乎和人类语言完全相同,即使没有学习过计算机编程,只要看到这段代码就知道该代码完成什么功能,例如C语言(面向过程)、C++(半面向过程、半面向对象)、JAVA(纯面向对象,底层C++)
- 第一代语言—机器语言(执行效率最高,不需要编译,计算机可以直接识别):主要编写二进制码。直接编写101010001这样的二进制,以打孔机为代表
- 总之,编程语言的发展方向是向着人类更加容易理解的方向发展
- 什么是计算机编程语言?
- JAVA语言的发展史:
- JAVA诞生于1995年
- 1995年之前,SUN公司(太阳微电子公司:该公司目前被Oracle(甲骨文:做数据库的)收购)为了占领智能电子消费产品(电冰箱、电饭煲、吸尘器等的内核程序)市场,派James Gosling领导团队开发了一个Oak(橡树)语言
- 1996年,JDK1.0诞生
- Java包括三大块:
- JAVASE(Standard Edition):JAVA标准版
- JAVAEE(Enterprise Edition):JAVA企业版
- JAVAME(Micro Edition):JAVA微型版
- java诞生十周年的时候改了名字原来叫J2SE、J2EE、J2ME是因为在java1.2的时候分成了这几个部分,但后来版本一直升级,所以还叫这个不合适
- JAVA语言的特性:(开源、免费、纯面向对象、跨平台)
- 简单性:相对而言,JAVA不支持多继承,C++支持多继承,多继承比较复杂,JAVA屏蔽了指针的概念,C++有指针,JAVA语言底层是C++实现的(C++/C程序员可以直接用指针操作内存,更灵活,Java中真正操作内存的是JVM)
- 面向对象:JAVA是纯面向对象的,更符合人的思维模式,更容易理解
- 可移植性:JAVA程序可以做到一次编译,到处运行,也就是说JAVA程序可以在Windows操作系统上运行,不做任何修改,同样的JAVA程序也可以放到Linux操作系统上运行,这个被称为JAVA程序的可移植性,或者叫做跨平台性(因为有JVM,不同操作系统有不同版本的JVM,JVM屏蔽了底层操作系统之间的差异,JVM底层是C++编写的)
- windows操作系统的内核和linux操作系统的内核肯定不同,他们这两个操作系统执行指令的方式也是不一样的,所以Java程序不能直接运行在操作系统上
- 生成的字节码文件一样,但jvm不一样,生成的二进制指令不同,操作系统只能识别二进制
- 多线程:java完全/完美支持多线程这种并发机制
- 健壮性:自动垃圾回收机制(GC—garbage collection)有关,JVM负责调用(垃圾回收器并不是有垃圾立马就回收,达到一定程度才会清理,所以缺点就是内存得不到及时的清理,优点是防止内存溢出,C++可能会导致内存泄漏,最终导致内存溢出)
- 安全性:开放源代码,所以有漏洞大家就可以修改,更安全,也会更健壮 ,自动垃圾回收机制,防止了内存的泄露,更安全
- 内存溢出:是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory;比如申请了一个integer,但给它存了long才能存下的数,那就是内存溢出。
- 内存泄漏:是指程序在申请内存后,无法释放已申请的内存空间,最终导致内存溢出,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。
- JVM不能单独安装,JDK、JRE可以单独安装
- JAVA的加载与执行:
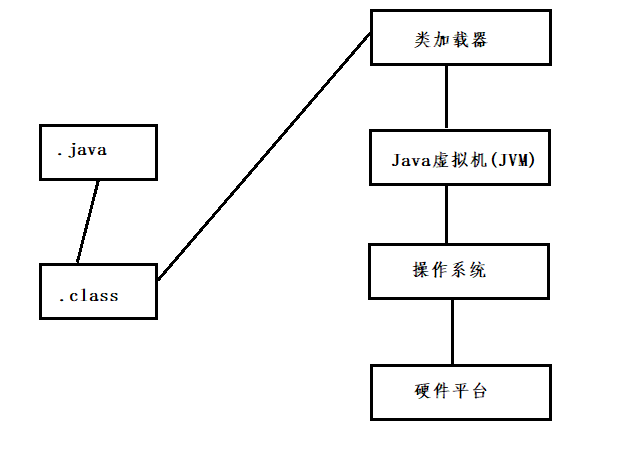
- JAVA程序的运行包括两个非常重要的阶段:
- 编译阶段:
- 编译阶段的任务是检查JAVA源程序是否符合JAVA语法
- 符合JAVA语法则能生成正常的字节码文件
- 不符合JAVA语法规则则无法生成字节码文件
- 字节码文件中不是纯粹的二进制,这种文件无法在操作系统当中直接执行
- javac java源文件的路径
- javac是一个Java的编译器工具
-
JDK = JRE + 开发工具集(例如Javac编译工具等)
JRE = JVM + Java SE标准类库+运行工具集(例如Java运行工具等)
- 编译阶段的任务是检查JAVA源程序是否符合JAVA语法
- 运行阶段
- java 类名(注意:java后面跟的不是文件的名称,是类名)(运行需要先切换到Java字节码文件所在目录)
- java.exe命令会启动java虚拟机(JVM),JVM 会启动类加载器ClassLoader
- ClassLoader会去硬盘上搜索A.class文件,找到该文件则将该字节码文件装载到JVM当中
- JVM对A.class字节码文件进行解释(将字节码解释成101010001这样的二进制)
- 然后操作系统执行二进制和底层硬件平台进行交互
- 编译阶段:
- Windows操作系统是如何搜索硬盘上的某个命令呢
- 首先会从当前目录下搜素
- 当前目录搜索不到,会从环境变量path指定的路径当中搜索某个命令
- 如果都搜索不到,则报错
- 注意:path环境变量和Java语言没有关系,path环境变量是属于windows操作系统的一个知识点,path环境变量是专门给Windows操作系统指路的
- 环境变量改变必须重启DOS命令窗口
- 对于Java的JDK所属的环境变量,有一个叫做JAVA_HOME,但这个Java_HOME目前我们不需要,不配置这个环境变量也不会影响当前程序的运行,但是后期学习到JAVA_WEB的时候需要安装Tomcat服务器,那个时候JAVA_HOME就必须配置了
- 环境变量classpath(大小写无所谓,但必须叫classpath)
- 当classpath环境变量配置为某个指定的路径之后,类加载器只去指定的路径当中加载字节码文件,所以classpath不再配置,这样类加载器会自动从当前路径下加载class字节码文件,所以,每一次执行.class程序时候,需要在DOS命令窗口中先切换到.class字节码文件所在的路径下,然后运行,当然classpath也可以这样配置,classpath=.;otherpath
- classpath是专门为类加载器指路的
- Java源程序当中的注释:(一个好的开发习惯应该是多编写注释,这样程序的可读性增强)
- 注释出现在JAVA源程序当中,对JAVA源代码进行解释说明
- 注释不会被编译到.class字节码文件当中
- 单行注释 // 多行注释/* */ javadoc注释/** * * */
- 文档注释,这种注释是比较专业的,该注释信息会被javadoc.exe工具解析提取并生成帮助文档
-
Java语言中语句一般有两种结束方式:以分号
;或后大括号}结束,以}结束的一般为流程控制语句。 - public class和class的区别:
- 一个Java文件中可以定义多个class
- 一个Java源文件当中public的class不是必须的
- 一个class会生成一个xxx.class字节码文件
- 一个Java源文件当中的定义公开的类的话,只能有一个,并且该类名称必须和Java源文件保持一致
- 每个class当中都可以编写main方法,都可以设定程序的入口,如果没有主方法,会出现运行阶段的错误
- 标识符
- 什么是标识符
- 在Java源程序当中凡是程序员有权利自己命名的单词都是标识符
- 标识符的命名规则:
- 只能由字母(包括中文)(A-Z、a-z)、数字(0-9)、下划线_、美元符号$组成,不能含有其他符号
- 不能数字开头
- 严格区分大小写
- 关键字不能做标识符
- 标识符的命名规范:
- 最好见名知意
- 遵循驼峰命名方式
- 类名、接口名:首字母大写,后面每个单词的首字母大写
- 变量名、方法名:首字母小写,后面每个单词首字母大写
- 常量名:全部大写,单词之间用下划线分开
- 包名:全部小写
- 理论上无长度限制,但最好不要太长
- 什么是标识符
- 关键字:
- 在SUN公司开发Java语言的时候,提前定义好的一些具有特殊含义的单词,这些单词全部小写,具有特殊含义,不能用作标识符
- 字面值:
- 字面值就是字表面的值,包括:整型、浮点型、字符型、字符串型、布尔型
- 字面值就是数据
- 字面值是Java源程序的组成部分之一,包括标识符和关键字他们都是Java源程序的组成部分
- 变量:
- 变量本质上是内存中的一块空间,这块空间有"数据类型"、"名称"、"值"
- 变量是内存中存储数据的最基本的单元
- 变量只有在赋值之后内存空间才开辟出来
- 赋值运算符先计算等号右边的表达式,然后将结果赋值给左边
- 在同一个作用域中,变量不能重名,在不同的作用域中,变量可以重名,类体和方法体属于不同的作用域,但是变量遵循就近原则
- 局部变量只在方法体当中有效,方法执行结束该变量的内存就释放了
- 数据类型的作用:
- 是指导JVM在程序运行的时候给该数据分配多大的内存空间
- 基本数据类型的分类(四大类,八小种):byte、short、int、long、float、double、boolean、char 1、2、4、8、4、8、1、2
- 整型(byte、short、int、long)
- 浮点型(float、double)
- 字符型(char)
- 布尔型(boolean)
- 计算机在任何情况下都只能识别二进制,例如:10101010100101...,现代计算机底层采用交流电的方式,就接通和断开两种方式,所以计算机只识别1和0,其他不认识
- 字符编码:
- 起初的时候计算机不支持文字,只支持科学计算,实际上计算机起初是为了战争而开发的,计算导弹的轨道
- 为了让计算机可以表示现实世界当中的文字,我们需要人为地干涉,需要人负责提前制定好“文字”和“二进制”之间的对照关系,这种对照转换关系被称为“字符编码”
- 计算机最初只支持英文,最先出现的字符编码是:ASCII码 (采用一个字节编码)
- 'A'—65
- 'a'—97 'a'----(按ASCII编码)----01100001 01100001----(按ASCII解码)----'a'
- '0'—48
- 编码和解码采用同一套字典/对照表,不会出现乱码
- 编码和解码采用的不是同一套字典/对照表,会出现乱码
- 随着计算机的发展,后来出现了一种编码方式,是国际化标准组织ISO制定的,这种编码方式支持西欧语言,向上兼容ASCII码,仍然不支持中文,这种编码方式是ISO-8859-1(1字节),又被称为latin-1
- 随着计算机向亚洲的发展,计算机开始支持中文、日文、韩文等国家的文字,其中支持简体中文的编码方式:GB2312<GBK<GB18030(容量关系)
- 支持繁体中文:大五码<big5>
- 后来出现了一种编码方式统一了全球的所有文字,容量较大,这种编码方式叫做:unicode编码,unicode编码方式有多种具体的实现:UTF-8、UTF-16、UTF-32,Java语言源代码采用的是unicode编码方式,所以“标识符”可以写中文
- 数据类型的取值范围:
- byte ——1字节—— -128-127
- short ——2字节—— -32768-32767
- int ——4字节—— -2147483648-2147483647
- char ——2字节—— 0-65535
- boolean——1字节—— true/false
- 注意:short和char所表示的种类总数是一样的,只不过char可以表示更大的正整数,因为char没有负数
- 数据类型的默认值:
- 数据类型 默认值
- ---------------------------------------------------------------
- byte、short、int、long 0
- float、double 0.0
- boolean false(true是1,false是0)
- char \u0000
- 转义字符 \:
- \n 换行符
- \t 制表符
- 转义字符出现在特殊字符之前,会将特殊字符转换为普通字符
- \' 普通的单引号
- \\ 普通的反斜杠(将转义字符转换成普通的反斜杠)
- \'' 普通的双引号
- 补:char a='';//Java中不允许这样编写程序,编译报错
- 补:JDK中自带的native2ascii.exe命令,可以将文字转化成Unicode编码形式
- 补:char a='\u0000',值是0,输出是空白字符
- \u4e2d,反斜杠u联合起来后面一串数字是某个文字的unicode编码,这个编码是十六进制的
- 转义字符单独写后面只能跟这几种,要是跟其他的,必须写成\\转换成普通字符,否则是报错
- println()表示输出之后换行,print()表示输出之后不换行
- 整型
- Java语言当中的“整数型”字面值被默认当做int类型来处理,要让这个“整数型”字面值被当做long类型来处理的话,需要在整数型字面值后面添加l/L,建议使用大写的L(所有数据在计算机内部都是以补码形式存放的)
- 正数的原码、反码、补码都一样,负数的补码等于符号位不变,其他部分按位取反再加一,所以,知道负数的补码求原码,先减一,符号位不变,其它部分按位取反
- Java语言中整数型字面值的四种表示方式:
- 十进制(最常用,缺省默认方式)
- 八进制(以0开始)
- 十六进制(以0x开始)
- 二进制(以0b开始)
- 浮点型
- double的精度太低(相对来说),不适合做财务软件, 财务涉及到钱的问题,要求精度较高,所以SUN在基础SE类库当中为程序员准备了精确度更高的类型,只不过这种类型是一种引用数据类型,不属于基本数据类型,它是java.math.BigDecimal
- SE类库的字节码:D:\app\java\jre\lib\rt.jar
- SE类库源码:D:\app\java\src.zip
- double和float在计算机内部二进制存储的时候存储的都是近似值,在现实世界中有些数字是无限循环的,例如3.333333333.........,但计算机的资源是有限的,用有限的资源存储无限的数据只能存储近似值
- Java语言当中的“浮点型”字面值被默认当作double类型来处理,要想该字面值被当作float类型来处理,需要在字面值后面添加F/f
- double的精度太低(相对来说),不适合做财务软件, 财务涉及到钱的问题,要求精度较高,所以SUN在基础SE类库当中为程序员准备了精确度更高的类型,只不过这种类型是一种引用数据类型,不属于基本数据类型,它是java.math.BigDecimal
- 布尔型
- 在Java语言当中boolean类型只有两个值,true和false,没有其他值,不像C语言当中,0和1可以表示假和真,但其实底层还是0和1
- 关于基本数据类型之间的相互转化,转换规则:
- 八种数据类型当中除了布尔数据类型之外,剩下的7种类型之间都可以进行相互转换
- 小容量向大容量转换,称为自动类型转换,容量从小到大排序:
- byte<short(char)<int<long<float<double
- 任何浮点类型不管占用多少个字节,都比整型容量大
- char和short表示的种类数量相同,但char可以取更大的正整数
- byte<short(char)<int<long<float<double
- 大容量转换成小容量,叫强制类型转换,需要加强制类型转换符,程序才能编译通过,但是在运行阶段可能会损失精度,所以要谨慎使用
- 强制类型转换其实就是将左边砍掉
- 当整数字面值没有超过byte、short、char的取值范围,可以直接赋值给byte、short、char类型的变量
- byte、short、char混合运算的时候,各自先转换成int类型在做运算
- int i=10; byte b=i/3; //错误,因为编译期只检查语法错误,运行的时候才会赋值和运算
- 多种数据类型混合运算,先转换成容量最大的那种类型再做运算
- 运算符(一个表达式当中有多个运算符,运算符有优先级,不确定的加小括号,优先级得到提升)
- 算术运算符 +、-、*、/、++、--、%(求余数,取模)
- 关系运算符 <、<=、>、>=、==、!=
-
-
- 关系运算符的结果一定是布尔类型
- 关系运算符比较的都是值的大小
-
-
- 布尔运算符 &&(短路与)、||、&(逻辑与)、|、!(逻辑非)、^(相同为假,不同为真)(逻辑异或 )
-
-
- 逻辑运算符要求两边的算子都是布尔类型,并且逻辑运算符最终的结果也是一个布尔类型
- 短路与和逻辑与最终运算结果都是相同的,只不过存在短路现象
- 短路或和逻辑或最终运算结果都是相同的,只不过存在短路现象
- 短路与和短路或由于后面的表达式可能不执行,所以执行效率较高,在实际开发中使用较多
-
-
- 位运算符(用来直接操作二进制)
-
-
- &按位与(同真则真,有假则假)
- |按位或(同假则假,有真则真)
- ^按位异或(相同为假,不同为真)
- ~按位非(真则假、假则真)
- >>右移(有符号右移,正数补0,符数补1)
- >>>右移(无符号右移,必须补0)
- <<左移
-
-
- 赋值类运算符 =、+=、-=、*=、/=、%=、^=、&=、|=、<<=、>>=
-
-
- 扩展类的赋值运算符不改变运算结果类型
-
-
- 字符串连接运算符 +
- 条件运算符 ?:
- 其他运算符 instanceof、new
- 控制台上输出的都是字符串
- 控制语句(所有的控制语句都可以嵌套,但注意缩进,大括号里面套的大部分要缩进):
- 控制选择结构语句:
- if(第一种)、if.....else....(第二种)(if语句分支中只有一条java语句,{}可以省略不写)
- 第三种(用区间理解)
- if(布尔表达式){
- 分支1;
- }else if(布尔表达式){
- 分支2;
- }else if(布尔表达式){
- 分支3;
- }
- 第四种
- if(布尔表达式){
- 分支1;
- }else if(布尔表达式){
- 分支2;
- }else if(布尔表达式){
- 分支3;
- }else{
- 分之4
- }
- 例子
-
- 第三种(用区间理解)
- switch(int或String)//byte、short、char也是可以的
- switch(i){
- case 1: case 2: case 3: case 4:
- System.out.println("4");
- break;
- //case合并
- case 5:
- System.out.println("5");
- break;
- default :
- java语句;
- }
- case要顶格写
- JDK6,switch和case后面只能写int
- JDK7之后包括7,switch和case后面可以写int或String
- 区间的判断用if比较合适,固定值用switch比较合适
- if(第一种)、if.....else....(第二种)(if语句分支中只有一条java语句,{}可以省略不写)
- 控制循环结构语句:
- for(初始化表达式;布尔表达式;更新表达式都可以不写,但;必须写)
- 先执行初始化表达式,只执行一次,然后执行布尔表达式,布尔表达式为true,执行循环体,然后执行更新表达式,然后执行布尔表达式,布尔表达式为true,执行循环体
- while
-
- do....while(); //分号一定不能少了
- for(初始化表达式;布尔表达式;更新表达式都可以不写,但;必须写)
- 转向语句(改变控制语句顺序):
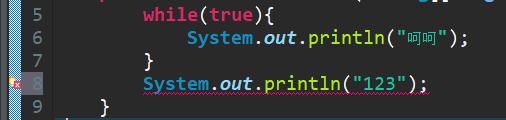
- break
- break+“;”可以成为一个单独的完整的java语句
- break终止的是离他最近的循环,也可以通过给for循环起名字来终止自定义的for
- 可以用来终止switch语句,防止case穿透现象
- return:return所在的方法结束,但不是JVM结束
- continue
- continue+“;”可以成为一个单独的完整的java语句
- continue跳过的是离他最近的循环,也可以通过给for循环起名字来跳过自定义的for
- break
- 控制选择结构语句:
- 定义:某自然数除它本身以外的所有因子之和等于该数,则该数被称为完数。所以1不是完数,最小的完数是6,6=1+2+3
- 接收用户键盘输入:
- java.util.Scanner s = new java.util.Scanner(System.in);//创建键盘扫描器对象
- s.nextInt();//用来输入整数
- s.next();//用来输入字符串
- 在JVM内存划分上有三块主要的内存空间(当然除了这三块还有其他的内存空间)
- 栈内存stack
- 堆内存heap
- 方法区内存
- 关于数据结构
- 程序=数据结构(存储数据的容器)+算法(排序算法、查找算法..........)
- 数据结构反映的是数据的存储形态
- 数据结构是独立的学科,不属于任何编程语言范畴,只不过大多数编程语言中要使用数据结构
- 作为程序员需要提前精通:数据结构+算法
- 常见的数据结构:
- 数组
- 栈
- 队列
- 链表
- 二叉树
- 哈希表/散列表
- 图
- 栈数据结构:
-
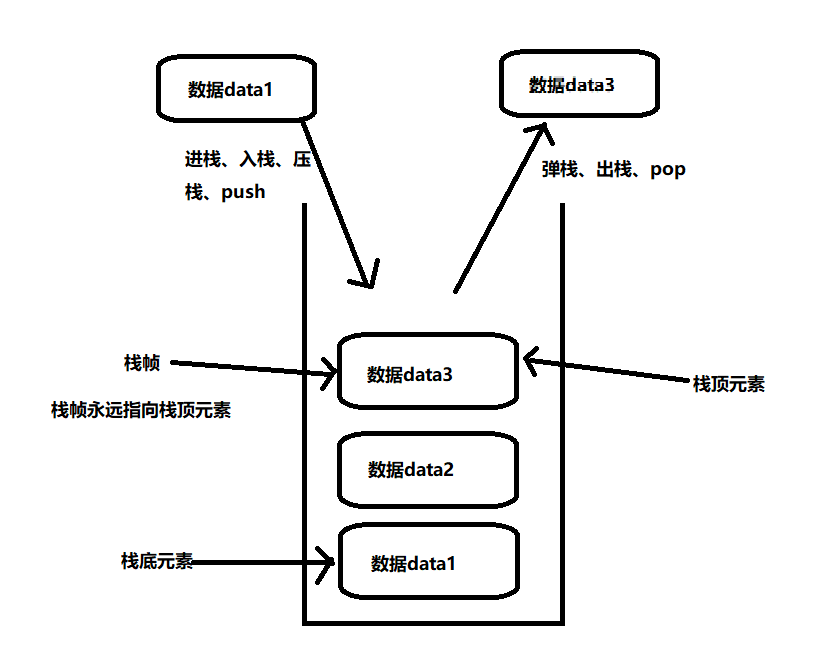
- 栈数据结构的特点:先进后出、后进先出
- 处于栈顶部的元素具有活跃权
- 不管是静态方法、实例方法、构造方法,他们在运行的时候都需要压栈
-
- 方法的本质:方法就是一段代码片段,并且这段代码片段可以完成某个特定的功能,并且可以被重复使用
- 只要带有return关键字的语句执行,return语句所在的方法结束(不是JVM结束,是return所在的方法结束),在同一个域中,return语句下面不能编写任何代码,因为永远执行不到
- 方法只定义不去调用是不会执行的,并且JVM中也不会给该方法分配运行所属的内存空间,只有在调用的时候才会执行,栈内存中分配方法运行的所属内存空间
-
方法代码片段存在哪里?方法执行的时候执行过程的内存在哪里分配?
- 方法代码片段属于.class字节码文件的一部分,字节码文件在类加载的时候被放到方法区当中,所以JVM中的三块主要的内存空间中方法区内存最先有数据、存放了代码片段。
- 代码片段虽然在方法区当中只有一份,但是可以被重复调用,每一次调用这个方法的时候,需要给该方法分配独立的活动场所,在栈内存中分配,方法在调用的瞬间,会给该方法分配内存空间,会在栈中发生压栈动作,方法执行结束之后,给该方法分配的内存空间全部释放,此时发生弹栈动作
- 局部变量在栈中的方法体中分配内存,方法执行结束,局部变量的内存空间就释放了
- 方法重载(overload)
- 什么时候考虑使用方法重载?
- 功能相似的时候,尽可能使用方法重载
- 什么条件满足之后构成方法重载?
- 在同一个类中
- 方法名相同
- 参数列表不同:
- 个数不同
- 顺序不同
- 类型不同
- 方法重载和什么有关系?和什么没有关系?
- 方法重载和方法名+参数列表有关系
- 方法重载和返回值类型无关
- 方法重载和修饰符列表无关
- java支持方法的重载机制,有些不支持,例如以后要学习的JavaScript就不支持
- 什么时候考虑使用方法重载?
- 递归调用
- 什么是递归?
- 递归就是方法自己调用自己
- 递归是很耗费栈内存的,递归算法可以不用的时候尽量别用
- 递归必须有结束条件,没有结束条件一定会发生栈内存溢出错误StackOverflowError,错误发生无法挽回,只有一个结果就是JVM停止工作
- 在实际的开发中,假如有一天你真正遇到了:StackOverflowError,怎么解决这个问题?
- 首先第一步,检查递归的结束条件对不对,如果递归结束条件不对,必须对条件进一步修改,直到正确为止
- 如果条件没问题,就需要手动调整JVM的栈内存的初始化大小,可以将栈内存的初始化调大一些,如果调整了还是出现这个错误,就继续调大
- java -X可以查看堆栈大小的参数
- 在实际的开发中,假如有一天你真正遇到了:StackOverflowError,怎么解决这个问题?
- 递归即使有了结束条件,即使结束条件是正确的,也可能会发生栈内存溢出错误,因为递归的太深了
- 在实际的开发中,不建议轻易选择递归,能用for循环while循环代替的,尽量选择循环来做,因为循环的效率高而且耗费的内存少,递归耗费的内存比较大,另外递归的不当,JVM会死掉,(但在极少数情况下,不用递归,这个程序没法实现),但是有些情况下该功能的实现必须依靠递归方式,例如:目录拷贝
- 什么是递归?
- 太计较变量的数量会有什么后果:(运行效率不会变低)
- 后果一:代码的可读性差
- 后果二:可读性差也会牵连到代码的开发效率
- eclipse快捷键:
- ctrl+/ 单行注释的 注释和取消注释
- ctrl+shift+/ 多行注释 ctrl+shift+\ 多行注释的取消
- ctrl+shift+f 格式化代码
- ctrl+d 删除一行
- 当一个类的成员变量和方法特别多的时候,可以ctrl+o输入要查找的元素快速查找
- ctrl+shift+t 查找类型 查找所有的类
- ctrl+s hift+r 查找资源 查找该项目中的资源,例如db.properties
- ctrl+shift+o 快速导入包的快捷键
- 面向对象
- 面向对象和面向过程的区别
- 面向过程(主要关注的是实现的具体过程,因果关系)耦合度高,扩展力差
- 优点:对于业务逻辑比较简单的程序,可以达到快速开发,前期投入成本低,不需要前期进行对象的提取,模型的建立
- 缺点:采用面向对象的方式开发很难解决非常复杂的业务逻辑,另外面向过程的方式导致元素之间的耦合度非常高,只要其中一环出问题,整个系统受到影响,另外没有独立体的概念,无法达到组件复用
面向对象(主要关注的是对象—独立体能完成哪些功能)耦合度低,扩展力强
- 优点:耦合度低,扩展力强,更容易解决现实世界当中更复杂的业务逻辑,组件复用性强
- 缺点:前期投入成本较高,需要进行独立体的抽取,大量的系统分析与设计
- 面向对象成为主流的原因是面向对象更符合人的思维方式
- 面向过程(主要关注的是实现的具体过程,因果关系)耦合度高,扩展力差
- 面向对象三大特征
- 封装
- 继承
- 多态
- 任何一个面向对象的编程语言都包括这三个特征,python也有
- 采用面向对象的方式开发一个软件,生命周期:
- 面向对象分析:OOA
- 面向对象设计:OOD
- 面向对象编程:OOP
- 对象抽象化成类,类实例化成对象,对象也叫做实例
- 类的结构
- [修饰符列表] class 类名{
- 属性;//描述对象的状态信息,名字,身高,性别,年龄,采用变量的方式来定义
- 方法;//描述对象的动作信息,吃饭,睡觉,学习,采用方法的方式来定义
- }
- 面向对象和面向过程的区别
- 对象的创建和使用
- 不创建对象,成员变量的内存空间不存在,只有创建了对象,成员变量运行时的内存空间才会创建
- 保存的是对象的内存地址的变量,有一个特殊的名字叫引用
- 引用是一个变量,可以是局部变量,也可以是成员变量
- 对于成员变量,没有手动赋值,系统赋默认值:
- byte 0
- short 0
- int 0
- long 0L
- float 0.0F
- double 0.0
- boolean false
- char \u0000
- 引用数据类型 null
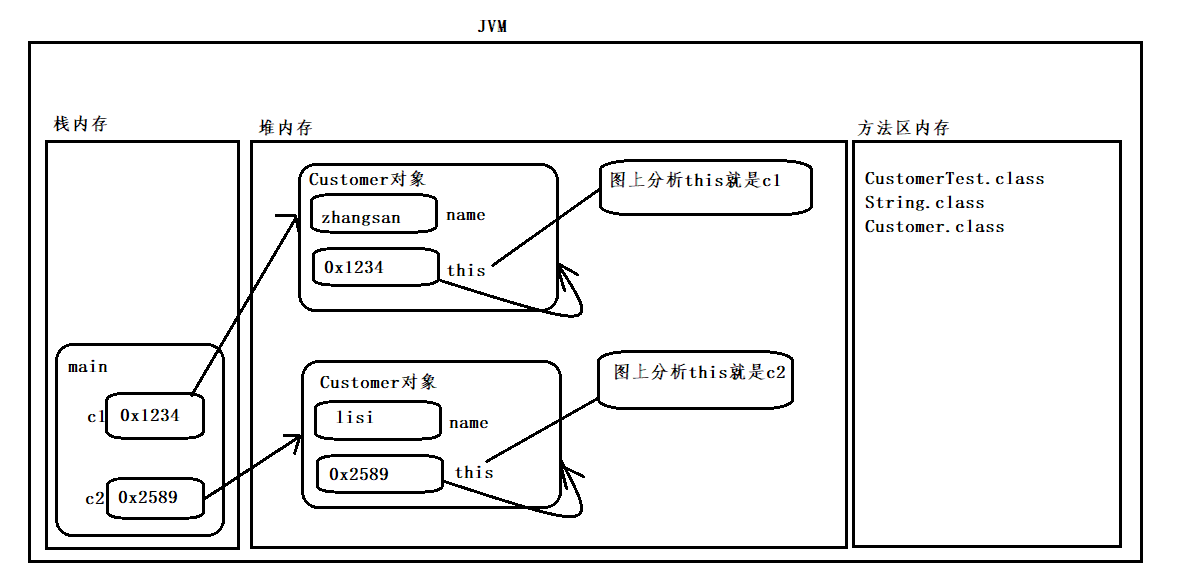
- JVM内存分析
-

-
- 方法区当中的类加载是用到了才会加载,不是一下子全加载
-
空指针异常:空引用访问实例相关的数据时,会发生空指针异常java.lang.NullPointerException
- 实例相关的数据,就是数据访问的时候必须有对象的参与,这种数据就是实例相关的数据
- Java的集成开发环境(集成开发环境简称:IDE):集成开发环境讲究一站式开发,使用这个工具即可,有提示功能,有自动纠错功能
- 集成开发环境可以让软件开发变得更简单、更高效
- 没有IDE工具:
- 需要安装JDK、需要配置环境变量、需要手动的将Java源文件编译生成class字节码文件
- Java源程序出错之后还没有提示
- 代码没有自动提示功能
- 有IDE工具:
- 不需要独立安装JDK、不需要手动手动配置环境变量、不需要使用javac命令对Java源程序进行编译
- Java源程序出错之后马上有提示
- 代码有自动提示功能
- Java中有哪些比较牛的IDE呢?
- eclipse(最多)【日食】
- IBM团队研发的,主要是为了吞并SUN公司,但SUN公司后来被Oracle收购了
- workspace:工作区(工作区当中的基本单元是Project(项目/工程))
- 当myeclipse打开的时候,会提示选择工作区
- 这个工作区可以是已经存在工作区,也可以是新建的工作区
- 选择工作区后,将来编写的Java代码,自动编译的class文件都会在工作区当中找的
- myeclipse可以开启两个甚至更多的会话,每一个会话对应不同的工作区workspace
- workspace中有一个文件夹.metadata,在该文件夹中存储了当前myeclipse的工作状态,将.metadata文件夹删除之后,下一次在进入这个工作区的时候,是一个全新的开始,但是会发现这个IDE工具中所有的项目丢失了,没关系,这里只是丢失了eclipse的项目,硬盘上真是存储的项目不会丢失
- 窗口不小心关闭了,可以再次打开:
- Window->show view->other->输入自己要找的窗口
- 布局乱了可以:window->prespective->Reset prespective
- 工程名一般全部小写
- 重点窗口介绍:
- Package Explore/Navigator/Project Explore:可以看到java源文件
- Console:控制台窗口
- 工作区workspace的基本单元是:Project(工程/项目)
- myeclipse
- myeclipse比eclipse有更多的插件,但收费
- Intellij IDEA(上升的趋势)
- 与eclipse不同,idea的一个工作区可以反复打开
- NetBeans
- JBuilder
- eclipse(最多)【日食】
- 面向对象的封装性
- 封装的好处:
- 1.封装之后,对于那个事物来说,看不到事物比较复杂的那一面,只能看到该事物简单的那一面。复杂性封装,对外提供简单的操作入口
- 2.封装之后,对于事物本身,不能之间访问,提高了安全性
- 封装的步骤:
- 1.属性私有化,使用private关键字修饰,private表示私有的,修饰的所有数据只能在本类中访问
- 2.对外提供简单的操作入口,也就是说以后外部程序要想访问age属性,必须通过这些简单的入口进行访问
- 对外提供两个公开的方法,分别是setXxx()和getXxx()
- 封装的好处:
- 构造函数:
- 对于构造方法来说,返回值类型不需要指定,并且也不能写成void,只要写成void,那么这个方法就成为普通方法了
- 构造方法的方法名必须和类名保持一致
- 构造方法的作用?
- 创建对象(和new连用时,才创建对象)
- 创建对象的同时,初始化实例变量的内存空间
- 构造方法怎么调用?
- 普通方法有static关键字是-类名.方法名(实参列表),没有static关键字是-引用.方法名(实参列表)
- new 构造方法名(实参列表)
- 构造方法执行结束之后有返回值吗?
- 有返回值,返回值是构造方法所在类的类型,但是return 值,这样的语句不需要写,Java程序自动返回值,因为构造方法的返回值类型就是类本身的类型
- 当一个类没有定义任何构造方法,系统默认给该类提供一个默认的构造方法,称为缺省构造器
- 当一个类提供了有参构造方法,系统将不再提供默认的无参构造方法
- 构造方法支持重载机制,在一个类当中编写多个构造方法,这多个构造方法显然已经构成了方法重载
- this
- 在对象内部,有一个关键字叫this,this中保存的是该对象的内存地址,this指向该对象本身
- 当c1去访问这个对象,this就代表c1,当c2去访问这个对象,this就代表c2,this代表当前正在执行这个行为的对象
- this不能使用在带有static的方法当中
- this多数情况下是可以省略的,但是区分局部变量和实例变量时不能省略
- this(实参)表示当前构造方法可以调用本类的其他构造方法,目的是代码复用,并且this(实参)必须出现在构造方法的第一行
- 如果直接输出this,this会自动调用toString方法,但是super不能单独用
- super
- 是一个关键字,全部小写
- super要和this对比着学:
- this
- this能出现在实例方法和构造方法中
- this的语法,this.、this()
- this不能使用在静态方法中
- this.大部分情况下是可以省略的,但在区分局部变量和实例变量的时候不能省略
- this()必须出现在构造方法的第一行,通过当前构造方法,调用本类其他构造方法,目的是代码复用
- super
- super能出现在实例方法和构造方法中
- super的语法,super.、super()
- super不能使用在静态方法中
- super.大部分情况下是可以省略的,但子中有,父中又有(变量和方法),如果想在子中访问父的特征,super.不能省略
- super()必须出现在构造方法的第一行,通过当前构造方法,调用父类的构造方法,目的是代码创建子类型对象的时候,先初始化父类型特征,例如会给父类的成员变量赋初值
- 如果直接输出this,this会自动调用toString方法,但是super不能单独用,因为super不是引用,super也不保存内存地址,super也不指向任何对象,super只是代表当前对象内部的那一块父类型的特征
- 重要结论:
-
当一个构造方法第一行既没有this(),又没有super()的话,默认会有一个super(),表示通过当前子类的构造方法调用父类的无参数构造方法,所以必须保证父类的无参数构造方法是存在的
- Object的无参数构造方法一定会执行
- 子类中定义的成员变量和父类中定义的成员变量相同时,则子类会隐藏父类的成员变量,和方法其实是一样的,此时想访问父类的属性或方法必须加super.
-
- this
- static
- 什么时候成员变量声明为实例变量呢?
- 所有对象都有这个属性,但是这个属性的值会随着对象的变化而变化,不同对象的这个属性具体的值不同
- 什么时候成员变量声明为静态变量呢?
- 所有对象都有这个属性,并且对象的这个属性的值是一样的,建议定义为静态变量,节省内存开销
- 带有static的方法,既可以采用类名的方式访问,也可以采用引用的方式访问,但是即使采用引用的方式访问,实际上执行的时候和引用指向的对象无关,所以eclipse开发的时候,使用引用的方式访问带有static的方法,程序会出现警告,所以还是建议使用类名的方式访问
- 静态代码块/静态语句块:
- static{
- java语句;
- }
- 静态代码块在类加载的时候执行,并且只执行一次
- 静态代码块和静态变量都在类加载的时候执行,时间相同,只能靠代码的顺序来决定
- 静态代码块在一个类中可以编写多个,并且按照自上而下的顺序依次执行
- 例如项目中要求在类加载的时刻/时机执行代码完成日志的记录,那么这段记录日志的代码就可以编写到静态代码块当中,完成日志的记录
- 静态代码块是Java为程序员准备的一个特殊的时刻,这个特殊的时刻被称为“类加载时刻”,若希望在此刻执行一段特殊的程序,这段程序可以直接放到静态代码块当中
- 通常在静态代码块中完成预备工作,先完成数据的准备工具,例如:初始化连接池、解析XML配置文件............
- 实例代码块/实例语句块:
- 实例代码块可以编写多个,也是遵循自上而下的顺序依次执行
- 实例代码块在构造方法执行之前执行,构造方法执行一次,实例代码块对应执行一次
- 实例代码块也是Java语言为程序员准备的一个特殊时机“对象初始化时机”
- 到目前为止,你遇到的所有Java程序,有顺序要求的是哪些?
- 第一,对于方法来说
- 第二:静态代码块1和静态代码块2是有先后顺序的
- 第三:静态代码块和静态变量是有先后顺序的
- 第四:实例变量和实例代码块是有先后顺序的
- 方法什么时候定义为静态?
- 方法描述的是动作,当所有的对象执行这个动作的时候,最终产生的影响是一样的,那么这个动作已经不再属于某一个对象动作了,可以将这个对象提升为类级别的动作
- class 类{
- 静态代码块//类加载时执行
- 实例代码块//构造方法执行之前执行
- 静态变量//类加载时候赋初值
- 实例变量//构造方法执行之前赋初值
- 静态方法//类名.方法名
- 实例方法//引用.方法名
- 构造方法//new 方法名
- }
- 大多数工具类的方法都是静态方法
- 什么时候成员变量声明为实例变量呢?
- 继承(extends):
- 继承的基本作用是代码复用,但是继承最重要的作用是,有了继承,才有了以后的方法的覆盖和多态机制
- 继承也是有缺点的,父类代码修改,子类受到牵连,使得代码耦合度高
- Java语言中的继承只支持单继承,一个类不能同时继承很多类,只能继承一个类,在C++中支持多继承
- 关于继承中的一些术语:
- B类继承A类:
- A类称为:父类、基类、超类、superclass
- B类称为:子类、派生类、扩展类、subclass
- 在Java语言中子类继承父类都继承哪些数据呢?
- 私有的不支持继承
- 构造方法不支持继承
- 其他的都支持继承
- 虽然Java语言当中只支持单继承,但是一个类也可以间接继承其他类,例如:
- C extends B{
- }
- B extends A{
- }
- A extends T{
- }
- C类直接继承B类,但是间接继承A、T类
- Java语言中假设一个类没有显示的继承任何类,该类默认继承JavaSE库当中提供的java.lang.Object类
- 当源码中一个方法以;结尾,并且修饰符列表中有native关键字,表示底层调用C++写的dll程序(dll动态链接库)
- toString方法的Integer.toHexString(hashCode())的值可以等同看作对象在堆内存当中的内存地址,实际上是内存地址经过哈希算法得出的十六进制的结果
- 回顾方法重载(Overload):
- 方法重载什么时候用:
- 当在同一个类中,方法完成的功能是相似的,建议方法名相同,这样方便程序员的编程,就像在调用一个方法似的,代码美观
- 什么条件满足之后构成方法的重载:
- 在同一个类中
- 方法名相同
- 参数列表不同:类型、个数、顺序
- 方法重载和什么无关:
- 和返回值类型无关
- 和方法的修饰符列表无关
- 方法重载什么时候用:
- 方法的覆盖(方法重写Override/Overwrite):
- 什么时候使用方法重写
- 当父类中的方法已经无法满足当前子类的业务需求,子类有必要将父类中继承过来的方法进行重新编写,这个重新编写的过程叫做方法重写
- 什么条件满足之后会发生方法重写呢?【代码满足什么条件之后就构成方法得覆盖呢?】
- 方法重写发生在具有继承关系的父子类之间
- 返回值类型相同,方法名相同,形参列表相同【建议方法重写的时候尽量复制粘贴或者自动生成,不要自己编写,容易出错,导致没有产生覆盖】
- 返回值类型对于基本数据类型必须一样,对于引用数据类型,覆盖之后的类型可以更小(子类)
- 访问权限不能更低,只能更高,
- 抛出异常
- 对于编译时异常如果都是Exception子类时子类不能比父类不能更多。如果父类是Exception,子类是Exception子类时,多少无所谓
- 运行时异常怎么样无所谓
- 注意
- 私有方法不能继承,所以不能覆盖
- 构造方法不能继承,所以不能覆盖
- 静态方法不存在方法的覆盖(因为静态方法和对象没有关系,而且方法覆盖要和多态联合)
- 覆盖只针对方法,不谈属性
- 如果一个方法是重写之后的方法,方法前面会有一个绿色的小箭头
- 什么时候使用方法重写
- 多态
- 关于多态中涉及到的几个概念:
- 向上转型(upcasting):子类型->父类型 又被称为:自动类型转换
- 向下转型(downcasting):父类型->子类型 又被称为:强制类型转换
- 以后在工作中,在和别人聊天时,要专业一些,说向上转型和向下转型,不要说自动类型转换,也不要说强制类型转换,因为自动类型转换和强制类型转换是使用在基本数据类型方面的,在引用类型转换这里只有向上和向下转型
- 无论是向上转型还是向下转型,两种类型之间必须要有继承关系,没有继承关系,程序无法编译通过
- 静态绑定:编译阶段的绑定
- 动态绑定:运行阶段的绑定
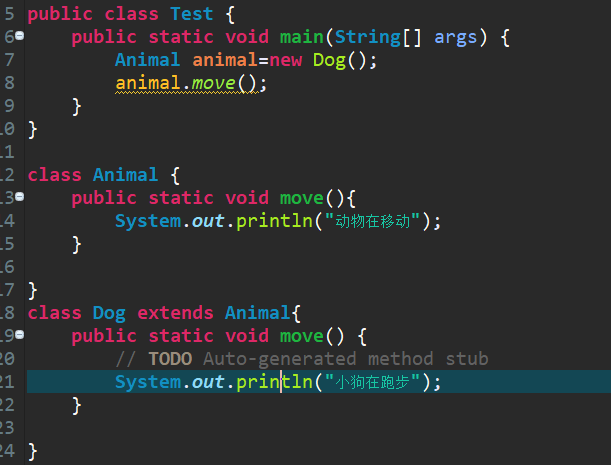
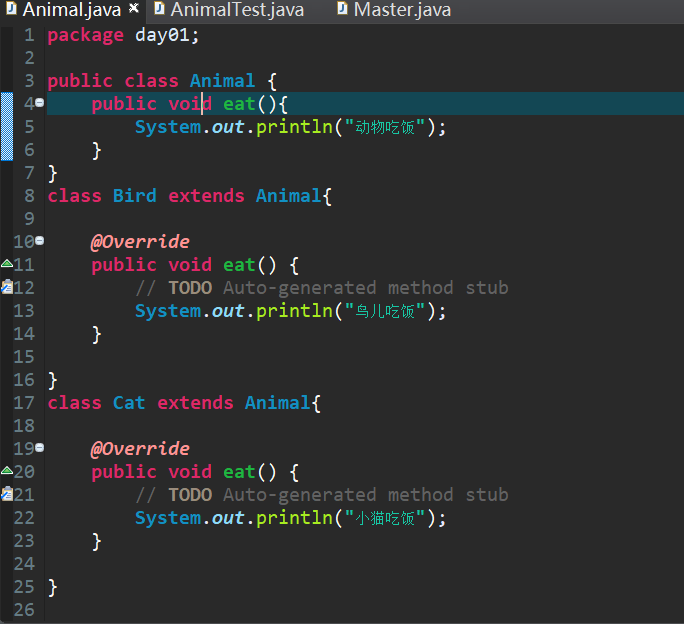
- Animal a=new cat();//父类型引用指向子类型对象,这种程序存在编译阶段绑定和运行阶段绑定两种不同的形态,称为向上转型
- 什么时候进行向下转型
- 当调用的方法是子类型中特有的,在父类型中不存在,必须进行向下转型
- 向上转型,只要编译通过,运行一定不会出问题,Animal a=new Bird();
- 向下转型,编译通过,运行可能出现问题,Animal a=new Bird(); Cat c=(Cat)a;编译时候通过了,但是运行时Bird和Cat没有关系,所以发生异常,ClassCastException
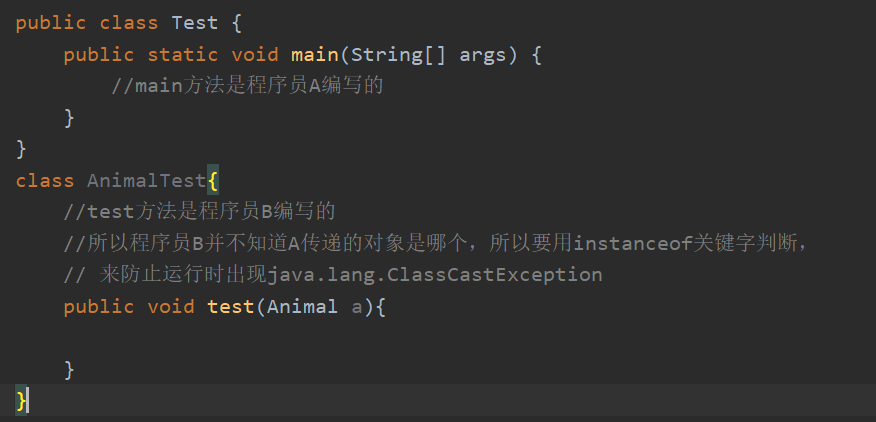
- 怎么避免向下转型出现的ClassCastException呢?
- 使用instanceof关键字可以避免该异常
- instanceof关键字怎么用?
- 引用 instanceof 数据类型名,运算结果可能是true/false
- 既然眼睛可以看出new的是什么对象,为什么还用instanceof关键字呢
-
- 关于运算结果true/false
- 假设(a instanceof Bird)
- true表示a这个引用指向的对象是一个Bird类型
- false表示a这个引用指向的对象不是一个Bird类型
- 方法覆盖需要和多态机制联合起来使用才有意义
- 没有多态机制,方法覆盖可有可无
- 没有多态机制,方法覆盖也可以没有,如果父类的方法无法满足子类的业务需求,子类完全可以定义一个全新的方法
- 关于多态中涉及到的几个概念:
- 调试程序,选中某一行,然后在最左侧双击产生断点,然后鼠标右击,选择Debug As,跳出调试页面,选中的那一行表示,程序执行到这行,但是这行还没执行
- 多态的作用:
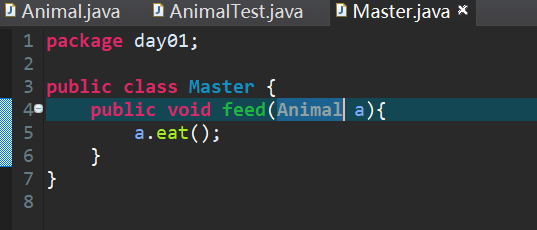
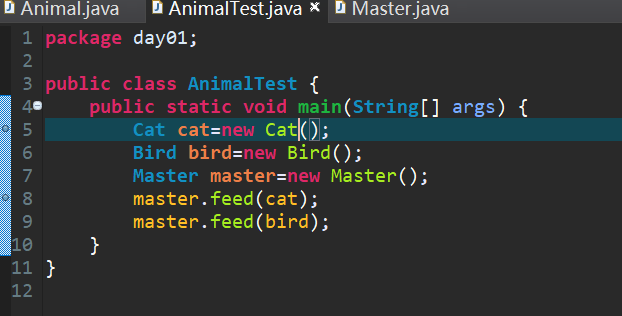
- 降低程序的耦合度,提高程序的扩展力(原来Master和Bird、Cat的耦合度太高,通过增加Animal类,降低了Master和Bird、Cat的耦合度)
- 一定要记住,软件在扩展过程当中,修改的越少越好,修改的越多,系统的稳定性就越差,未知的风险就越多
- 这里涉及到一个软件开发原则
- 软件开发原则有七大原则(不属于java,这个开发原则属于整个软件业):其中有一条最基本的原则:OCP(开闭原则)
- 什么是开闭原则?
- 对扩展开放(可以额外添加),对修改关闭(最好很少的修改现有的程序)
- 这里涉及到一个软件开发原则
- final
- final是一个关键字,表示最终的,不可变的
- final修饰的类无法被继承
- final修饰的方法无法被覆盖
- final修饰的变量一旦赋值之后,不可重新赋值
- final修饰的实例变量,必须手动赋值,不能采用系统的默认值
- 第一种解决方案:final int num=10;
- 第二种解决方案:final int num; public 构造方法名 () { this.num=200; }
- final修饰的引用虽然指向某个对象之后不能指向其他对象,就算赋值null也不行,所以无法被垃圾回收器回收,但是,所指向的对象内部的数据是可以被修改的
- final User user=new User(30);
- user.id=50;
- final修饰的实例变量,必须手动赋值,不能采用系统的默认值
- final修饰的变量,每个对象都有一份,只是值不能改变,存放在堆中,但加上static后,存放在方法区中,所有对象共用一份,节省空间。
- 既有static又有final的叫做常量
- 链接源码:Attach Source
- WorkSpace表示源码在工作空间中
- External File表示源码在压缩包中
- External Folder表示源码在文件夹中
- 大家学习的类库,一般都是包括三个部分的:
- 源码【可以看源码来理解源程序】
- 字节码【程序开发的过程中使用的就是这部分】
- 帮助文档【对源码的解释说明被提取出来,更方便程序的开发】
- javadoc.exe工具会将Java源文件中写的注释提取出来,生成帮助文档
- package和import:
- package(关键字)
- 包又称为package,java中引用package这种语法机制,主要是为了方便程序的维护,不同功能的类被分门别类放到不同的软件包中,查找比较方便,管理比较方便,易维护
- 怎么定义package呢?
- 在Java源程序的第一行编写package语句
- package只能编写一个语句
- 语法结构:package 包名;
- 包名的命名规范:
- 公司域名倒序+项目名+模块名+功能名,采用这种方式重名的几率较低,因为公司域名具有全球唯一性
- 包名要求全部小写
- 包名也是标识符,必须遵守标识符的命名规则
- 一个包对应一个目录
- 使用了package机制之后应该怎么编译?怎么运行?
- 使用了package之后,类名不在叫做Test01了,类名叫做:com.bjpowernode.javase.day11.Test01
- 编译 javac Test01.java
- 运行 java com.bjpowernode.javase.day11.Test01(必须要将编译之后生成的字节码文件放到com.bjpowernode.javase.day11包下面才能运行)
- 另一种方式(编译+运行)
- 带包编译:javac -d 编译之后存放路径 java源文件的路径,eg:javac -d . *.java
- import(关键字)
- 在同一个包中,代码中写全类名的时候,包名可以省略,只写类名,也不需要import,但是不在同一个包中,必须写全类名,或者要import导入
- import java.util.Scanner;或者import java.util.*;
- import需要编写在package语句之下,class语句之上
- java.lang.*;不需要手动引入,Java系统自动引入
- 在同一个包中,代码中写全类名的时候,包名可以省略,只写类名,也不需要import,但是不在同一个包中,必须写全类名,或者要import导入
- package(关键字)
- 访问控制权限修饰符:
- 访问权限修饰符可以变量、方法、类/接口(只能采用public和缺省进行修饰【内部类除外】)
- 访问权限修饰符包括:
- public 表示公开,在任何位置都可以访问
- protected 同包或其他包中的子类
- 缺省 同包
- private 表示私有的,只能在本类中访问
- public>protected>缺省>private
- System.exit(0);终止JVM运行