
基于Docker Desktop搭建Kafka集群并使用Java编程开发
一、引言
前段时间因课业要求使用Docker Desktop 部署Kafka集群并编写生产者消费者程序,折磨了我好几天,在查找大量资料后终于是把整个集群搭建完成了。现在我想要分享其中搭建的历程,希望能为大家解决问题。
二、Docker集群构建
安装环境:
Windows 10
2.1 启用或关闭windows功能中勾选适用于linux的子系统,重启机器

启用或关闭windows功能
2.2 windows power shell 中检查wsl的更新:
wsl --update
2.3 Docker官网下载Docker Desktop Installer
(下载链接:https://docs.docker.com/desktop/install/windows-install/)
2.4 Docker 安装
在power shell中下载存放Docker Desktop Installer.exe 路径下执行以下命令: (如果直接点击exe安装它会给你默认会安装到C盘)
"Docker Desktop Installer.exe" install --installation-dir=<path>
注意: <path>替换为你需要安装Docker Desktop的路径
Docker Desktop启动界面
2.5 Docker相关配置
设置Docker 的镜像存储位置
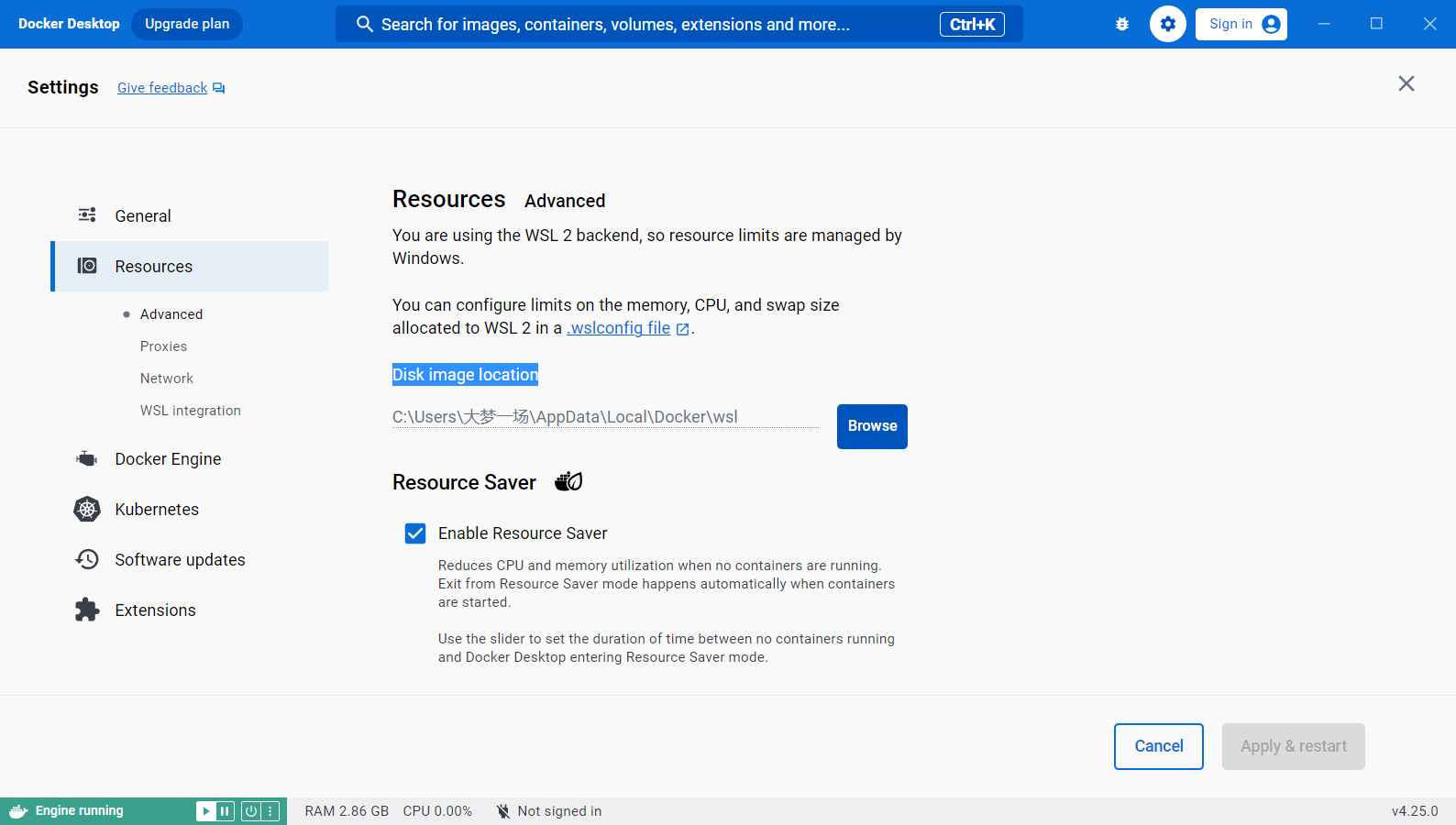 Docker 的镜像存储位置
Docker 的镜像存储位置
路径:Settings/Resources/Advanced
设置Dock 镜像源
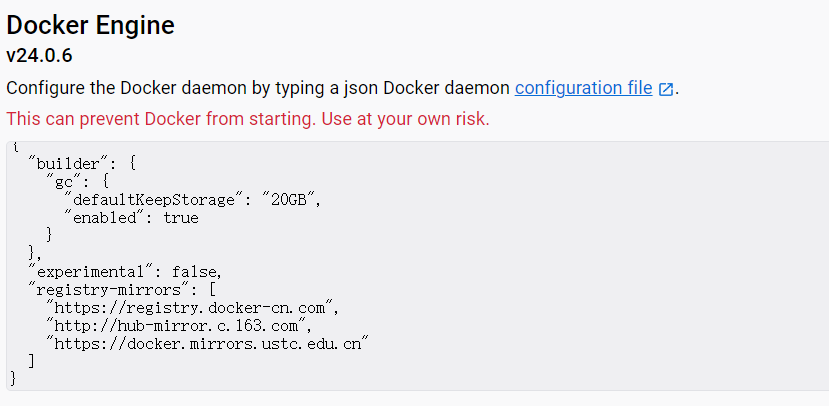 Docker Desktop镜像仓库
Docker Desktop镜像仓库
"registry-mirrors": [
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn"
]
路径:Settings/Docker Engine
三、Kafka集群构建
3.1 创建docker 网络 (在不指定参数的情况下创建的是bridge网络)
docker network create zk-net
查看创建的docker 网络
docker network ls
3.2 编写kafka 与 zookeeper的yml文件
kafka.yml文件的编写
version: "3"
networks:
zk-net:
external:
name: zk-net
services:
zoo1:
image: 'zookeeper:3.8.2'
container_name: zoo1
hostname: zoo1
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=0.0.0.0:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
ALLOW_ANONYMOUS_LOGIN: "yes"
networks:
- zk-net
ports: #端口映射
- 2181:2181
- 8081:8080
volumes: #挂载文件
- /E/Kcluster/zookeeper/zoo1/data:/data
- /E/Kcluster/zookeeper/zoo1/datalog:/datalog
zoo2:
image: 'zookeeper:3.8.2'
container_name: zoo2
hostname: zoo2
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=0.0.0.0:2888:3888;2181 server.3=zoo3:2888:3888;2181
ALLOW_ANONYMOUS_LOGIN: "yes"
networks:
- zk-net
ports:
- 2182:2181
- 8082:8080
volumes:
- /E/Kcluster/zookeeper/zoo2/data:/data
- /E/Kcluster/zookeeper/zoo2/datalog:/datalog
zoo3:
image: 'zookeeper:3.8.2'
container_name: zoo3
hostname: zoo3
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=0.0.0.0:2888:3888;2181
ALLOW_ANONYMOUS_LOGIN: "yes"
networks:
- zk-net
ports:
- 2183:2181
- 8083:8080
volumes:
- /E/Kcluster/zookeeper/zoo3/data:/data
- /E/Kcluster/zookeeper/zoo3/datalog:/datalog
kafka01:
image: 'bitnami/kafka:2.7.0'
restart: always
container_name: kafka01
hostname: kafka01
ports:
- '9093:9093'
environment:
- ALLOW_NONE_AUTHENTICATION=yes
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_BROKER_ID=1
- KAFKA_CFG_LISTENERS=PLAINTEXT://0.0.0.0:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka01:9093
- KAFKA_CFG_ZOOKEEPER_CONNECT=zoo1:2181,zoo2:2181,zoo3:2181
volumes:
- /E/Kcluster/kafka/kafka1:/bitnami/kafka
networks:
- zk-net
kafka02:
image: 'bitnami/kafka:2.7.0'
restart: always
container_name: kafka02
hostname: kafka02
ports:
- '9094:9094'
environment:
- ALLOW_NONE_AUTHENTICATION=yes
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_BROKER_ID=2
- KAFKA_CFG_LISTENERS=PLAINTEXT://0.0.0.0:9094
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka02:9094
- KAFKA_CFG_ZOOKEEPER_CONNECT=zoo1:2181,zoo2:2181,zoo3:2181
volumes:
- /E/Kcluster/kafka/kafka2:/bitnami/kafka
networks:
- zk-net
kafka03:
image: 'bitnami/kafka:2.7.0'
restart: always
container_name: kafka03
hostname: kafka03
ports:
- '9095:9095'
environment:
- ALLOW_NONE_AUTHENTICATION=yes
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_BROKER_ID=3
- KAFKA_CFG_LISTENERS=PLAINTEXT://0.0.0.0:9095
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka03:9095 #kafka真正bind的地址
- KAFKA_CFG_ZOOKEEPER_CONNECT=zoo1:2181,zoo2:2181,zoo3:2181 #暴露给外部的listeners,如果没有设置,会用listeners
volumes:
- /E/Kcluster/kafka/kafka3:/bitnami/kafka
networks:
- zk-net
需要注意的是,后续的Java API 的使用依赖于 KAFKA_CFG_ADVERTISED_LISTENERS
如果你使用的是 KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka03:9095 这种格式 需要在 C:\Windows\System32\drivers\etc 路径下修改host文件加入
127.0.0.1 kafka01 127.0.0.1 kafka02 127.0.0.1 kafka03
如果使用IP地址则不需要
3.3 拉取Kafka搭建需要的镜像,这里我选择zookeeper 和 kafka 镜像版本为:
zookeeper:3.8.2
bitnami/kafka:2.7.0
键入命令拉取镜像:
docker pull zookeeper:3.8.2 docker pull bitnami/kafka:2.7.0
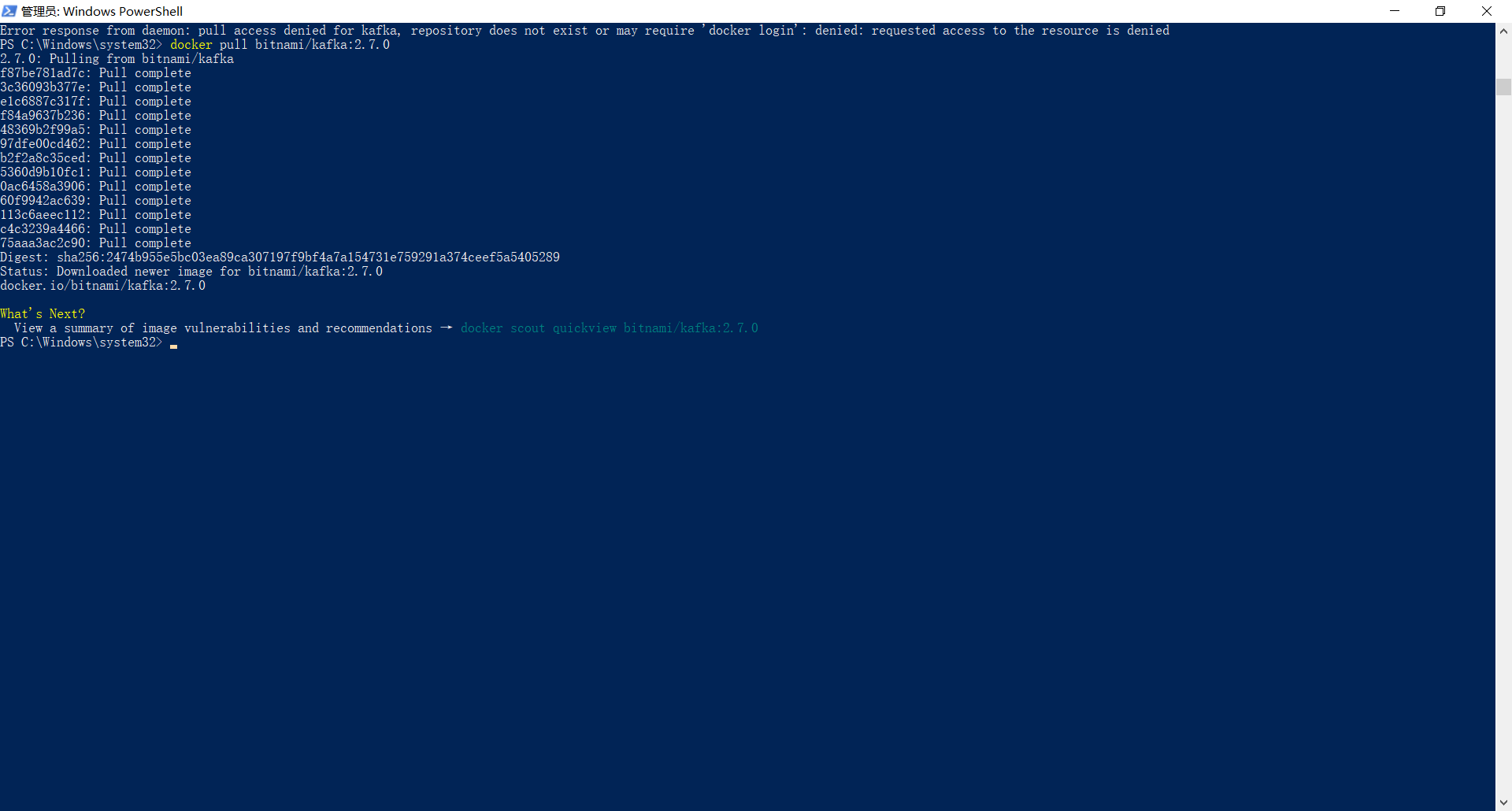
kafka镜像拉取
3.4 使用docker-compose 构建集群
在power shell中执行以下命令:
docker-compose -f E:\Kcluster\docker-compose_kafka.yml up -d

docker-compose 构建集群
图中可以看到kafka集群已经被创建起来了:

kafka集群 展示
启动集群:
docker-compose -f E:\Kcluster\docker-compose_kafka.yml start
停止集群:
docker-compose -f E:\Kcluster\docker-compose_kafka.yml stop
删除集群:
docker-compose -f E:\Kcluster\docker-compose_kafka.yml down
四、Kafka Java API
4.1 相关环境的配置
新建一个maven 项目 在xml中配置如下:
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
</dependencies>
拉取依赖
4.2 编写生产者代码
新建类:KafkaTest.class
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class KafkaTest { public static void main(String[] args) { Properties props = new Properties(); //参数设置 //1.指定Kafaka集群的ip地址和端口号 props.put("bootstrap.servers", "kafka01:9093,kafka02:9094,kafka03:9095"); //2.等待所有副本节点的应答 props.put("acks", "all"); //3.消息发送最大尝试次数 props.put("retries", 1); //4.指定一批消息处理次数 props.put("batch.size", 16384); //5.指定请求延时 props.put("linger.ms", 1); //6.指定缓存区内存大小 props.put("buffer.memory", 33554432); //7.设置key序列化 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //8.设置value序列化 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 9、生产数据 KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props); for (int i = 0; i < 50; i++) { producer.send(new ProducerRecord<String, String>("mytopic", Integer.toString(i), "hello kafka-" + i)); System.out.println(i); } producer.close(); } }
注意,props.put("bootstrap.servers", "kafka01:9093,kafka02:9094,kafka03:9095");
如果是按上述yml配置,不需修改。如果你使用ip地址 替换kafka01,kafka02,kafka03 则使用IP地址:端口号
具体原因可见:
Kafka学习理解-listeners配置 - 孙行者、 - 博客园 (cnblogs.com)
docker 部署kafka,listeners配置 - 我的天啊~ - 博客园 (cnblogs.com)
4.3 编写消费者代码
新建类:ConsumerDemo.class
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.time.Duration; import java.util.Collections; import java.util.Objects; import java.util.Properties; public class ConsumerDemo{ public static void main(String[] args) { Properties properties=new Properties(); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"kafka01:9093,kafka02:9094,kafka03:9095"); properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //配置消费者组(必须) properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group1"); properties.put("enable.auto.commit", "true"); // 自动提交offset,每1s提交一次 properties.put("auto.commit.interval.ms", "1000"); properties.put("auto.offset.reset","earliest "); properties.put("client.id", "zy_client_id"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties); // 订阅test1 topic consumer.subscribe(Collections.singletonList("mytopic")); while(true) { // 从服务器开始拉取数据 ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); if(Objects.isNull(records)){ continue; } for(ConsumerRecord<String,String> record : records){ System.out.printf("topic=%s,offset=%d,key=%s,value=%s%n", record.topic(), record.offset(), record.key(), record.value()); } } } }
运行结果如下:
生产者:
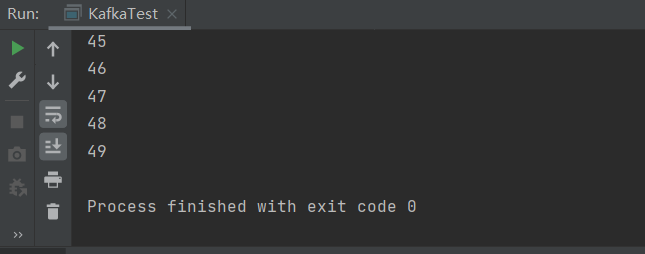
消费者:
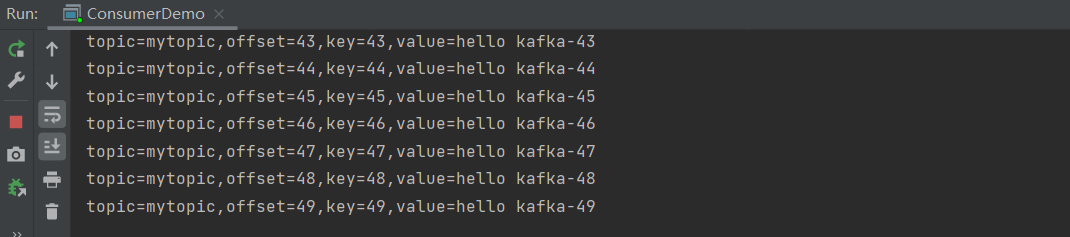
至此整个集群的构建与测试结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号