v14.02 鸿蒙内核源码分析(内存汇编篇) | 谁是虚拟内存实现的基础 | 百篇博客分析OpenHarmony源码
子曰:“居上不宽,为礼不敬,临丧不哀,吾何以观之哉?”《论语》:八佾篇

百篇博客系列篇.本篇为:
v14.xx 鸿蒙内核源码分析(内存汇编篇) | 谁是虚拟内存实现的基础
内存管理相关篇为:
- v11.03 鸿蒙内核源码分析(内存分配) | 内存有哪些分配方式
- v12.04 鸿蒙内核源码分析(内存管理) | 虚拟内存全景图是怎样的
- v14.02 鸿蒙内核源码分析(内存汇编) | 谁是虚拟内存实现的基础
- v15.03 鸿蒙内核源码分析(内存映射) | 虚拟内存虚在哪里
- v16.02 鸿蒙内核源码分析(内存规则) | 内存管理到底在管什么
- v17.04 鸿蒙内核源码分析(物理内存) | 怎么管理物理内存
ARM-CP15协处理器
ARM处理器使用协处理器15(CP15)的寄存器来控制cache、TCM和存储器管理。CP15的寄存器只能被MRC和MCR(Move to Coprocessor from ARM Register )指令访问,包含16个32位的寄存器,其编号为0~15。本篇重点讲解其中的 C7,C2,C13三个寄存器。
先拆解一段汇编代码
上来看段汇编,读懂内核源码不会点汇编是不行的 , 但不用发怵,没那么恐怖,由浅入深, 内核其实挺好玩的。见于 arm.h,里面全是这些玩意。
#define DSB __asm__ volatile("dsb" ::: "memory")
#define ISB __asm__ volatile("isb" ::: "memory")
#define DMB __asm__ volatile("dmb" ::: "memory")
STATIC INLINE VOID OsArmWriteBpiallis(UINT32 val)
{
__asm__ volatile("mcr p15, 0, %0, c7,c1,6" ::"r"(val));
__asm__ volatile("isb" ::: "memory");
}

这句汇编的指令字面意思是: 将ARM寄存器R0的数据写到CP15中编号为7的寄存器中,值由外面传进来。
例如 OsArmWriteBpiallis(0) 做了4个动作
1.把0值写入R0寄存器,注意这个寄存器是ARM即CPU的寄存器,::"r"(val) 意思代表向编译器声明,会修改R0寄存器的值,改之前提前打好招呼,都是绅士文明人。其实编译器的功能是非常强大的,不仅仅是大家普遍认为的只是编译代码的工具而已。
2.volatile的意思还是告诉编译器,不要去优化这段代码,原封不动的生成目标指令。
3."isb" ::: "memory" 还是告诉编译器内存的内容可能被更改了,需要无效所有Cache,并访问实际的内容,而不是Cache!
4.再把R0的值写入到C7中,C7是CP15协处理器的寄存器。C7寄存器是负责什么的?对照下面的表。
CP15有哪些寄存器
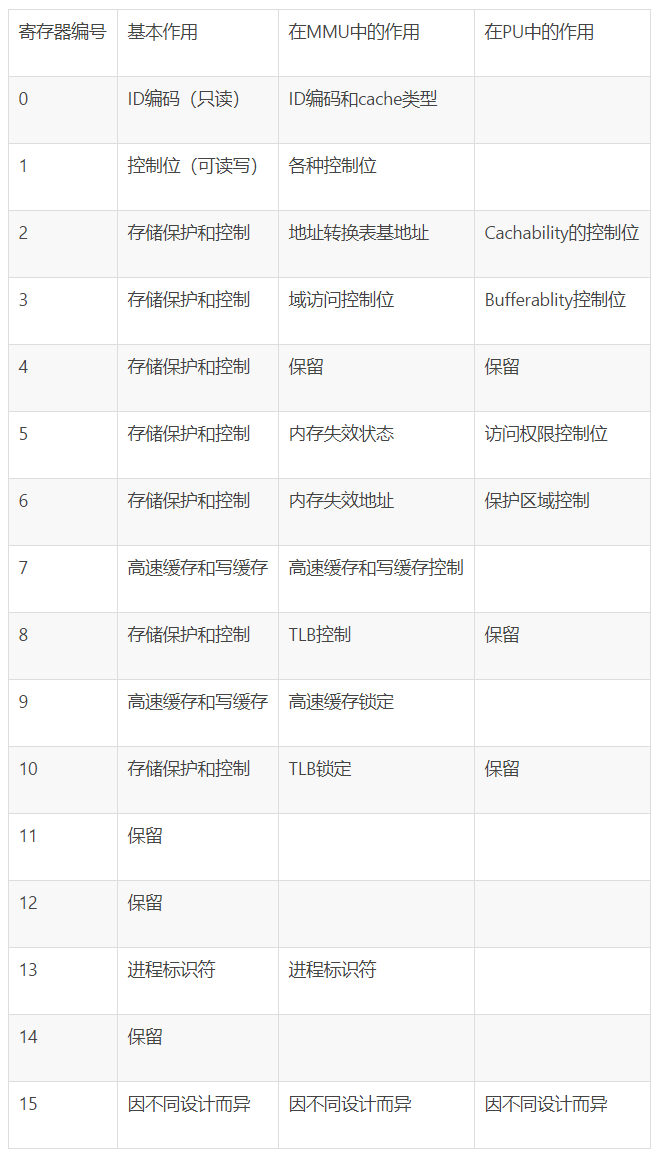
这句话真正的意思是:关闭高速缓存和写缓存控制!,其他部分寄存器下面会讲,先有个大概印象。
mmu从哪里获取 page table 的信息?答案是: TTB
TTB寄存器(Translation table base)
参考上表可知TTB寄存器是CP15协处理器的C2寄存器,存页表的基地址,即一级映射描述符表的基地址。围绕着TTB鸿蒙提供了以下读取函数。简单说就是内核从外面不断的修改和读取寄存器值,而MMU只会直接通过硬件读取这个寄存器的值,以达到MMU获取不一样的页表进行进程虚拟地址和物理地址的转换。还记得吗?每个进程的页表都是独立的!
那么什么情况下会修改里面的值呢?换页表意味着 mmu在进行上下文的切换!还是直接看代码吧。
mmu上下文
只被LOS_ArchMmuContextSwitch调用。毫无疑问它是关键函数。
typedef struct ArchMmu {
LosMux mtx; /**< arch mmu page table entry modification mutex lock */
VADDR_T *virtTtb; /**< translation table base virtual addr */
PADDR_T physTtb; /**< translation table base phys addr */
UINT32 asid; /**< TLB asid */
LOS_DL_LIST ptList; /**< page table vm page list */
} LosArchMmu;
// mmu 上下文切换
VOID LOS_ArchMmuContextSwitch(LosArchMmu *archMmu)
{
UINT32 ttbr;
UINT32 ttbcr = OsArmReadTtbcr();//读取TTB寄存器的状态值
if (archMmu) {
ttbr = MMU_TTBRx_FLAGS | (archMmu->physTtb);//进程TTB物理地址值
/* enable TTBR0 */
ttbcr &= ~MMU_DESCRIPTOR_TTBCR_PD0;//使能TTBR0
} else {
ttbr = 0;
/* disable TTBR0 */
ttbcr |= MMU_DESCRIPTOR_TTBCR_PD0;
}
/* from armv7a arm B3.10.4, we should do synchronization changes of ASID and TTBR. */
OsArmWriteContextidr(LOS_GetKVmSpace()->archMmu.asid);//这里先把asid切到内核空间的ID
ISB;
OsArmWriteTtbr0(ttbr);//通过r0寄存器将进程页面基址写入TTB
ISB;
OsArmWriteTtbcr(ttbcr);//写入TTB状态位
ISB;
if (archMmu) {
OsArmWriteContextidr(archMmu->asid);//通过R0寄存器写入进程标识符至C13寄存器
ISB;
}
}
// c13 asid(Adress Space ID)进程标识符
STATIC INLINE VOID OsArmWriteContextidr(UINT32 val)
{
__asm__ volatile("mcr p15, 0, %0, c13,c0,1" ::"r"(val));
__asm__ volatile("isb" ::: "memory");
}
再看下那些地方会调用 LOS_ArchMmuContextSwitch,下图一目了然。
有四个地方会切换mmu上下文
第一:通过调度算法,被选中的进程的空间改变了,自然映射页表就跟着变了,需要切换mmu上下文,还是直接看代码。代码不是很多,就都贴出来了,都加了注释,不记得调度算法的可去系列篇中看 鸿蒙内核源码分析(调度机制篇),里面有详细的阐述。
//调度算法-进程切换
STATIC VOID OsSchedSwitchProcess(LosProcessCB *runProcess, LosProcessCB *newProcess)
{
if (runProcess == newProcess) {
return;
}
#if (LOSCFG_KERNEL_SMP == YES)
runProcess->processStatus = OS_PROCESS_RUNTASK_COUNT_DEC(runProcess->processStatus);
newProcess->processStatus = OS_PROCESS_RUNTASK_COUNT_ADD(newProcess->processStatus);
LOS_ASSERT(!(OS_PROCESS_GET_RUNTASK_COUNT(newProcess->processStatus) > LOSCFG_KERNEL_CORE_NUM));
if (OS_PROCESS_GET_RUNTASK_COUNT(runProcess->processStatus) == 0) {//获取当前进程的任务数量
#endif
runProcess->processStatus &= ~OS_PROCESS_STATUS_RUNNING;
if ((runProcess->threadNumber > 1) && !(runProcess->processStatus & OS_PROCESS_STATUS_READY)) {
runProcess->processStatus |= OS_PROCESS_STATUS_PEND;
}
#if (LOSCFG_KERNEL_SMP == YES)
}
#endif
LOS_ASSERT(!(newProcess->processStatus & OS_PROCESS_STATUS_PEND));//断言进程不是阻塞状态
newProcess->processStatus |= OS_PROCESS_STATUS_RUNNING;//设置进程状态为运行状态
if (OsProcessIsUserMode(newProcess)) {//用户模式下切换进程mmu上下文
LOS_ArchMmuContextSwitch(&newProcess->vmSpace->archMmu);//新进程->虚拟空间中的->Mmu部分入参
}
#ifdef LOSCFG_KERNEL_CPUP
OsProcessCycleEndStart(newProcess->processID, OS_PROCESS_GET_RUNTASK_COUNT(runProcess->processStatus) + 1);
#endif /* LOSCFG_KERNEL_CPUP */
OsCurrProcessSet(newProcess);//将进程置为 g_runProcess
if ((newProcess->timeSlice == 0) && (newProcess->policy == LOS_SCHED_RR)) {//为用完时间片或初始进程分配时间片
newProcess->timeSlice = OS_PROCESS_SCHED_RR_INTERVAL;//重新分配时间片,默认 20ms
}
}
这里再啰嗦一句,系列篇中已经说了两个上下文切换了,一个是这里的因进程切换引起的mmu上下文切换,还一个是因task切换引起的CPU的上下文切换,还能想起来吗?
第二:是加载ELF文件的时候会切换mmu,一个崭新的进程诞生了,具体将在 鸿蒙内核源码分析(启动加载篇) 会细讲,敬请关注系列篇动态。
其余是虚拟空间回收和刷新空间的时候,这个就自己看代码去吧。
mmu是如何快速的通过虚拟地址找到物理地址的呢?答案是:TLB ,注意上面还有个TTB,一个是寄存器, 一个是cache,别搞混了。
TLB(translation lookaside buffer)
TLB是硬件上的一个cache,因为页表一般都很大,并且存放在内存中,所以处理器引入MMU后,读取指令、数据需要访问两次内存:首先通过查询页表得到物理地址,然后访问该物理地址读取指令、数据。为了减少因为MMU导致的处理器性能下降,引入了TLB,可翻译为“地址转换后援缓冲器”,也可简称为“快表”。简单地说,TLB就是页表的Cache,其中存储了当前最可能被访问到的页表项,其内容是部分页表项的一个副本。只有在TLB无法完成地址翻译任务时,才会到内存中查询页表,这样就减少了页表查询导致的处理器性能下降。详细看

照着图说吧,步骤是这样的。
1. 图中的page table的基地址就是上面TTB寄存器值,整个page table非常大,有多大接下来会讲,所以只能存在内存里,TTB中只是存一个开始位置而已。
2. 虚拟地址是程序的地址逻辑地址,也就是喂给CPU的地址,必须经过MMU的转换后变成物理内存才能取到真正的指令和数据。
3. TLB是page table的迷你版,MMU先从TLB里找物理页,找不到了再从page table中找,从page table中找到后会放入TLB中,注意这一步非常非常的关键。因为page table是属于进程的会有很多个,而TLB只有一个,不放入就会出现多个进程的page table都映射到了同一个物理页框而不自知。一个物理页同时只能被一个page table所映射。但除了TLB的唯一性外,要做到不错乱还需要了一个东西,就是进程在映射层面的唯一标识符 - asid。
asid寄存器
asid(Adress Space ID) 进程标识符,属于CP15协处理器的C13号寄存器,ASID可用来唯一标识进程,并为进程提供地址空间保护。当TLB试图解析虚拟页号时,它确保当前运行进程的ASID与虚拟页相关的ASID相匹配。如果不匹配,那么就作为TLB失效。除了提供地址空间保护外,ASID允许TLB同时包含多个进程的条目。如果TLB不支持独立的ASID,每次选择一个页表时(例如,上下文切换时),TLB就必须被冲刷(flushed)或删除,以确保下一个进程不会使用错误的地址转换。
TLB页表中有一个bit来指明当前的entry是global(nG=0,所有process都可以访问)还是non-global(nG=1,only本process允许访问)。如果是global类型,则TLB中不会tag ASID;如果是non-global类型,则TLB会tag上ASID,且MMU在TLB中查询时需要判断这个ASID和当前进程的ASID是否一致,只有一致才证明这条entry当前process有权限访问。
看到了吗?如果每次mmu上下文切换时,把TLB全部刷新已保证TLB中全是新进程的映射表,固然是可以,但效率太低了!!!进程的切换其实是秒级亚秒级的,地址的虚实转换是何等的频繁啊,怎么会这么现实呢,真实的情况是TLB中有很多很多其他进程占用的物理内存的记录还在,当然他们对物理内存的使用权也还在。所以当应用程序 new了10M内存以为是属于自己的时候,其实在内核层面根本就不属于你,还是别人在用,只有你用了1M的那一瞬间真正1M物理内存才属于你,而且当你的进程被其他进程切换后,很大可能你用的那1M也已经不在物理内存中了,已经被置换到硬盘上了。明白了吗?只关注应用开发的同学当然可以说这关我鸟事,给我的感觉有就行了,但想熟悉内核的同学就必须要明白,这是每分每秒都在发生的事情。
最后一个函数留给大家,asid是如何分配的?
/* allocate and free asid */
status_t OsAllocAsid(UINT32 *asid)
{
UINT32 flags;
LOS_SpinLockSave(&g_cpuAsidLock, &flags);
UINT32 firstZeroBit = LOS_BitmapFfz(g_asidPool, 1UL << MMU_ARM_ASID_BITS);
if (firstZeroBit >= 0 && firstZeroBit < (1UL << MMU_ARM_ASID_BITS)) {
LOS_BitmapSetNBits(g_asidPool, firstZeroBit, 1);
*asid = firstZeroBit;
LOS_SpinUnlockRestore(&g_cpuAsidLock, flags);
return LOS_OK;
}
LOS_SpinUnlockRestore(&g_cpuAsidLock, flags);
return firstZeroBit;
}
百篇博客分析.深挖内核地基
- 给鸿蒙内核源码加注释过程中,整理出以下文章。内容立足源码,常以生活场景打比方尽可能多的将内核知识点置入某种场景,具有画面感,容易理解记忆。说别人能听得懂的话很重要! 百篇博客绝不是百度教条式的在说一堆诘屈聱牙的概念,那没什么意思。更希望让内核变得栩栩如生,倍感亲切.确实有难度,自不量力,但已经出发,回头已是不可能的了。 😛
- 与代码有bug需不断debug一样,文章和注解内容会存在不少错漏之处,请多包涵,但会反复修正,持续更新,v**.xx 代表文章序号和修改的次数,精雕细琢,言简意赅,力求打造精品内容。
按功能模块:
百万汉字注解.精读内核源码
四大码仓中文注解 . 定期同步官方代码

鸿蒙研究站( weharmonyos ) | 每天死磕一点点,原创不易,欢迎转载,请注明出处。若能支持点赞更好,感谢每一份支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号