Java八股文
Java八股文
本文内容主体来自javaguide,有本人根据个人情况的摘抄、改动、增补等。
基础
1.成员变量与局部变量的区别?
- 语法形式:成员变量属于类,局部变量是在代码块或者方法中定义的变量,或者是方法的参数。成员变量可以被
public、private、static等修饰,而局部变量不能被访问控制修饰符及static修饰。但是,成员变量和局部变量都能被final修饰。 - 存储方式:如果成员变量使用static修饰,那么这个成员变量属于类,如果没有被static修饰,则属于实例。实例存在于堆内存,局部变量存在于栈内存。
- 生存时间:成员变量是对象的一部分,随着对象的创建而存在,局部变量随着方法的调用而自动生成,随着方法调用的结束而消亡。
- 默认值:成员变量如果没有被赋初始值,则会被自动赋予默认值,(例外:被final修饰的成员变量也必须显式地赋值);局部变量不会自动赋值。
2.静态方法为什么不能调用非静态成员?
这个需要结合 JVM 的相关知识,主要原因如下:
- 静态方法是属于类的,在类加载的时候就会分配内存,可以通过类名直接访问。而非静态成员属于实例对象,只有在对象实例化之后才存在,需要通过类的实例对象去访问。
- 在类的非静态成员不存在的时候静态方法就已经存在了,此时调用在内存中还不存在的非静态成员,属于非法操作
访问类成员是否存在限制
静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),不允许访问实例成员(即实例成员变量和实例方法),而实例方法不存在这个限制。
3.重载和重写有什么区别?
重载
发生在同一个类中(或者父类和子类之间),方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。
重写
重写发生在运行期,是子类对父类的允许访问的方法的实现过程进行重新编写。
- 方法名、参数列表必须相同,子类方法返回值类型应比父类方法返回值类型更小或相等,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。
- 如果父类方法访问修饰符为
private/final/static 则子类就不能重写该方法,但是被static 修饰的方法能够被再次声明。 - 构造方法无法被重写
综上:重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变。
| 区别 | 重载 | 重写 |
|---|---|---|
| 发生范围 | 同一个类 | 子类 |
| 参数列表 | 必须修改 | 不能修改 |
| 返回类型 | 可修改 | 子类方法返回值类型要比父类的更小或相等 |
| 异常 | 可修改 | 子类方法声明抛出的异常类要比父类的更小或相等 |
| 访问修饰符 | 可修改 | 大于等于父类 |
| 发生阶段 | 编译期 | 运行期 |
方法重写要遵循“两同两小一大”:
- “两同”即方法名相同、形参列表相同;
- “两小”指的是子类方法返回值类型应比父类方法返回值类型更小或相等,子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等;
- “一大”指的是子类方法的访问权限应比父类方法的访问权限更大或相等
如果方法的返回类型是 void 和基本数据类型,则返回值重写时不可修改。但是如果方法的返回值是引用类型,重写时是可以返回该引用类型的子类的。
基本类型与包装类型的区别?
-
成员变量包装类型不赋值就是null,而基本类型有默认值且不是null
-
包装类型可用于泛型,而基本类型不可以
-
存放位置
-
基本类型
- 局部变量存放在java虚拟机栈中的局部变量表中
- 基本类型的成员变量(未被static修饰)存放在jvm的堆中。
-
包装类型属于对象类型,几乎所有对象实例都存在于堆中。
-
-
相比于对象类型,基本类型所占空间较小
为什么说是几乎所有对象实例呢? 这是因为 HotSpot 虚拟机引入了 JIT 优化之后,会对对象进行逃逸分析,如果发现某一个对象并没有逃逸到方法外部,那么就可能通过标量替换来实现栈上分配,而避免堆上分配内存
包装类型的缓存机制了解么?
Java 基本数据类型的包装类型的大部分都用到了缓存机制来提升性能。
Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回 True or False。
如果超出对应范围仍然会去创建新的对象,缓存的范围区间的大小只是在性能和资源之间的权衡。
两种浮点数类型的包装类 Float,Double 并没有实现缓存机制。
下面我们来看一下问题。下面的代码的输出结果是 true 还是 false 呢?
Integer i1 = 40;
Integer i2 = new Integer(40);
System.out.println(i1==i2);
Integer i1=40 这一行代码会发生装箱,也就是说这行代码等价于 Integer i1=Integer.valueOf(40) 。因此,i1 直接使用的是缓存中的对象。而Integer i2 = new Integer(40) 会直接创建新的对象。
因此,答案是 false 。你答对了吗?
记住:所有整型包装类对象之间值的比较,全部使用 equals 方法比较
自动装箱与拆箱了解吗?原理是什么?
- 装箱:将基本类型用它们对应的引用类型包装起来;
- 拆箱:将包装类型转换为基本数据类型
装箱其实就是调用了包装类的valueOf()方法,拆箱其实就是调用了 xxxValue()方法。
因此,
-
Integer i = 10 等价于Integer i = Integer.valueOf(10) -
int n = i 等价于int n = i.intValue();
注意:如果频繁拆装箱的话,也会严重影响系统的性能。我们应该尽量避免不必要的拆装箱操作。
超过 long 整型的数据应该如何表示?
BigInteger 内部使用 int[] 数组来存储任意大小的整形数据。
相对于常规整数类型的运算来说,BigInteger 运算的效率会相对较低
接口和抽象类有什么共同点和区别?
-
interface 和 class 的区别,主要有:
- 接口多实现,类单继承
- 接口的方法是 public abstract 修饰,变量是 public static final 修饰。 abstract class 可以用其他修饰符
-
interface 的方法是更像是一个扩展插件。而 abstract class 的方法是要继承的。
开始我们也提到,interface 新增default和static修饰的方法,为了解决接口的修改与现有的实现不兼容的问题,并不是为了要替代abstract class。在使用上,该用 abstract class 的地方还是要用 abstract class,不要因为 interface 的新特性而将之替换。
记住接口永远和类不一样。
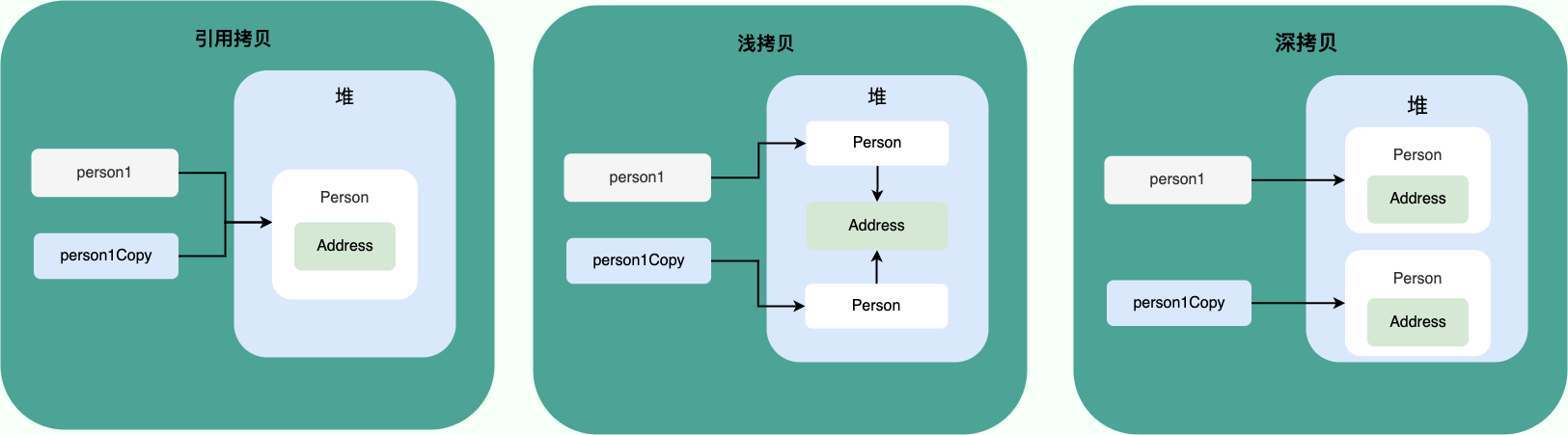
浅拷贝、深拷贝、引用拷贝的区别?
- 浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
- 深拷贝:深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
- 引用拷贝:两个不同的引用指向同一个对象。
为什么重写 equals() 时必须重写 hashCode() 方法?
如果重写equals()方法而不重写hashCode()方法,使用HashMap可能会出现数据丢失或重复的问题。这是因为HashMap是基于散列码来存储和查找键值对的,如果两个对象的equals()方法返回true,但是它们的hashCode()方法返回不同的值,那么它们会被放在不同的散列桶中,导致HashMap无法识别它们的相等性1。
反之,如果两个对象的hashCode()方法返回相同的值,但是它们的equals()方法返回false,那么它们会被放在同一个散列桶中,导致HashMap无法区分它们的差异1。
因此,为了保证HashMap的正确性和一致性,重写equals()方法时必须同时重写hashCode()方法,并且遵循以下原则13:
- 如果两个对象相等(即equals()方法返回true),那么它们的hashCode()方法必须返回相同的值
- 如果两个对象不相等(即equals()方法返回false),那么它们的hashCode()方法尽可能返回不同的值,以提高散列效率
String、StringBuffer、StringBuilder 的区别
-
可扩展性:
- String不可变
-
StringBuilder 与StringBuffer 使用字符数组保存字符串,可以修改, 如append 方法。
-
线程安全性:
-
String的对象不可变,线程安全
-
StringBuffer 线程安全- 对方法加了同步锁或者对调用的方法加了同步锁
-
StringBuilder 非线程安全
-
-
性能:
- 每次对
String 类型进行改变的时候,都会生成一个新的String 对象,然后将指针指向新的String -
StringBuffer 每次都会对StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。 - 相同情况下使用
StringBuilder 相比使用StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
- 每次对
对于三者使用的总结:
- 操作少量的数据: 适用
String - 单线程操作字符串缓冲区下操作大量数据: 适用
StringBuilder - 多线程操作字符串缓冲区下操作大量数据: 适用
StringBuffer
String 为什么是不可变的?
- 保存字符串的数组被
final 修饰且为私有的,并且String 类没有提供/暴露修改这个字符串的方法。 -
String 类被final 修饰导致其不能被继承,进而避免了子类破坏String 不可变
在try-catch-finally中,如果在finally中使用了return,会发生什么?
不要在 finally 语句块中使用 return! 当 try 语句和 finally 语句中都有 return 语句时,try 语句块中的 return 语句会被忽略。这是因为 try 语句中的 return 返回值会先被暂存在一个本地变量中,当执行到 finally 语句中的 return 之后,这个本地变量的值就变为了 finally 语句中的 return 返回值。
如何使用 try-with-resources 代替try-catch-finally?
- 适用范围(资源的定义): 任何实现
java.lang.AutoCloseable或者java.io.Closeable 的对象 - 关闭资源和 finally 块的执行顺序: 在
try-with-resources 语句中,任何 catch 或 finally 块在声明的资源关闭后运行
静态泛型方法的声明
public static < E > void printArray( E[] inputArray ) 一般被称为静态泛型方法
在 java 中泛型只是一个占位符,必须在传递类型后才能使用。类在实例化时才能真正的传递类型参数,由于静态方法的加载先于类的实例化,也就是说类中的泛型还没有传递真正的类型参数,静态的方法的加载就已经完成了,所以静态泛型方法是没有办法使用类上声明的泛型的。只能使用自己声明的 <E>
获取class对象的四种方式
-
知道具体类的情况下:
-
Class alunbarClass = TargetObject.class; - 通过该方式获取class对象不会进行初始化
-
-
通过
Class.forName()传入类的全路径:-
Class alunbarClass1 = Class.forName("cn.javaguide.TargetObject");
-
-
通过对象实例
instance.getClass()获取:-
TargetObject o = new TargetObject(); Class alunbarClass2 = o.getClass();
-
-
通过类加载器
xxxClassLoader.loadClass()传入类路径获取:-
ClassLoader.getSystemClassLoader().loadClass("cn.javaguide.TargetObject"); - 通过类加载器获取 Class 对象不会进行初始化,意味着不进行包括初始化等一系列步骤,静态代码块和静态对象不会得到执行
-
动态代理如何使用
JDK动态代理
- 定义一个接口及其实现类;
- 自定义
InvocationHandler 并重写invoke方法,在invoke 方法中我们会调用原生方法(被代理类的方法)并自定义一些处理逻辑; - 通过
Proxy.newProxyInstance(ClassLoader loader,Class<?>[] interfaces,InvocationHandler h) 方法创建代理对象;
1.定义发送短信的接口
public interface SmsService {
String send(String message);
}
2.实现发送短信的接口
public class SmsServiceImpl implements SmsService {
public String send(String message) {
System.out.println("send message:" + message);
return message;
}
}
3.定义一个 JDK 动态代理类
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
/**
* @author shuang.kou
* @createTime 2020年05月11日 11:23:00
*/
public class DebugInvocationHandler implements InvocationHandler {
/**
* 代理类中的真实对象
*/
private final Object target;
public DebugInvocationHandler(Object target) {
this.target = target;
}
public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException {
//调用方法之前,我们可以添加自己的操作
System.out.println("before method " + method.getName());
Object result = method.invoke(target, args);
//调用方法之后,我们同样可以添加自己的操作
System.out.println("after method " + method.getName());
return result;
}
}
invoke() 方法: 当我们的动态代理对象调用原生方法的时候,最终实际上调用到的是 invoke() 方法,然后 invoke() 方法代替我们去调用了被代理对象的原生方法。
4.获取代理对象的工厂类
public class JdkProxyFactory {
public static Object getProxy(Object target) {
return Proxy.newProxyInstance(
target.getClass().getClassLoader(), // 目标类的类加载
target.getClass().getInterfaces(), // 代理需要实现的接口,可指定多个
new DebugInvocationHandler(target) // 代理对象对应的自定义 InvocationHandler
);
}
}
getProxy():主要通过Proxy.newProxyInstance()方法获取某个类的代理对象
5.实际使用
SmsService smsService = (SmsService) JdkProxyFactory.getProxy(new SmsServiceImpl());
smsService.send("java");
运行上述代码之后,控制台打印出:
before method send
send message:java
after method send
JDK 动态代理有一个最致命的问题是其只能代理实现了接口的类。
为了解决这个问题,我们可以用 CGLIB 动态代理机制来避免。
CGLIB 通过继承方式实现代理。很多知名的开源框架都使用到了CGLIBopen in new window, 例如 Spring 中的 AOP 模块中:如果目标对象实现了接口,则默认采用 JDK 动态代理,否则采用 CGLIB 动态代理。
CGLIB 动态代理类使用步骤
- 定义一个类;
- 自定义
MethodInterceptor 并重写intercept 方法,intercept 用于拦截增强被代理类的方法,和 JDK 动态代理中的invoke 方法类似; - 通过
Enhancer 类的create()创建代理类;
手动添加相关依赖。
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version>
</dependency>
1.实现一个使用阿里云发送短信的类
package github.javaguide.dynamicProxy.cglibDynamicProxy;
public class AliSmsService {
public String send(String message) {
System.out.println("send message:" + message);
return message;
}
}
2.自定义 MethodInterceptor (方法拦截器)
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
/**
* 自定义MethodInterceptor
*/
public class DebugMethodInterceptor implements MethodInterceptor {
/**
* @param o 被代理的对象(需要增强的对象)
* @param method 被拦截的方法(需要增强的方法)
* @param args 方法入参
* @param methodProxy 用于调用原始方法
*/
@Override
public Object intercept(Object o, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
//调用方法之前,我们可以添加自己的操作
System.out.println("before method " + method.getName());
Object object = methodProxy.invokeSuper(o, args);
//调用方法之后,我们同样可以添加自己的操作
System.out.println("after method " + method.getName());
return object;
}
}
3.获取代理类
import net.sf.cglib.proxy.Enhancer;
public class CglibProxyFactory {
public static Object getProxy(Class<?> clazz) {
// 创建动态代理增强类
Enhancer enhancer = new Enhancer();
// 设置类加载器
enhancer.setClassLoader(clazz.getClassLoader());
// 设置被代理类
enhancer.setSuperclass(clazz);
// 设置方法拦截器
enhancer.setCallback(new DebugMethodInterceptor());
// 创建代理类
return enhancer.create();
}
}
4.实际使用
AliSmsService aliSmsService = (AliSmsService) CglibProxyFactory.getProxy(AliSmsService.class);
aliSmsService.send("java");
运行上述代码之后,控制台打印出:
before method send
send message:java
after method send
JDK 动态代理和 CGLIB 动态代理对比
- JDK 动态代理只能代理实现了接口的类或者直接代理接口,而 CGLIB 可以代理未实现任何接口的类。 另外, CGLIB 动态代理是通过生成一个被代理类的子类来拦截被代理类的方法调用,因此不能代理声明为 final 类型的类和方法。
- 就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显。
如何创建BigDecimal对象,而不丢失精度
在使用 BigDecimal 时,为了防止精度丢失,推荐使用它的BigDecimal(String val)构造方法或者 BigDecimal.valueOf(double val) 静态方法来创建对象。

-
equals() 方法不仅仅会比较值的大小(value)还会比较精度(scale) -
compareTo() 方法比较的时候会忽略精度。如果相等就返回 0,如果第 1 个数比第 2 个数大则返回 1,反之返回-1。
为什么要使用堆外内存?
泛型的原理?可能遇到的坑?
原理:
类型擦除
- 当泛型遇到重载时:
public class GenericTypes {
public static void method(List<String> list) {
System.out.println("invoke method(List<String> list)");
}
public static void method(List<Integer> list) {
System.out.println("invoke method(List<Integer> list)");
}
}
上述代码编译不通过。参数List<Integer>和List<String>编译之后都被擦除了,变成了一样的原生类型 List,擦除动作导致这两个方法的特征签名变得一模一样。
- 当泛型遇到 catch时:
泛型的类型参数不能用在 Java 异常处理的 catch 语句中。因为异常处理是由 JVM 在运行时刻来进行的。由于类型信息被擦除,JVM 是无法区分两个异常类型MyException<String>和MyException<Integer>的
- 当泛型内包含静态变量时:
public class StaticTest{
public static void main(String[] args){
GT<Integer> gti = new GT<Integer>();
gti.var=1;
GT<String> gts = new GT<String>();
gts.var=2;
System.out.println(gti.var);
}
}
class GT<T>{
public static int var=0;
public void nothing(T x){}
}
以上代码输出结果为:2!
由于经过类型擦除,所有的泛型类实例都关联到同一份字节码上,泛型类的所有静态变量是共享
自动装箱与拆箱的对象相等比较?
对象相等比较
public static void main(String[] args) {
Integer a = 1000;
Integer b = 1000;
Integer c = 100;
Integer d = 100;
System.out.println("a <span style="font-weight: bold;" class="mark"> b is " + (a </span> b));
System.out.println(("c <span style="font-weight: bold;" class="mark"> d is " + (c </span> d)));
}
输出结果:
a <span style="font-weight: bold;" class="mark"> b is false
c </span> d is true
在 Java 5 中,在 Integer 的操作上引入了一个新功能来节省内存和提高性能。整型对象通过使用相同的对象引用实现了缓存和重用。
适用于整数值区间-128 至 +127。
只适用于自动装箱。使用构造函数创建对象不适用
增强 for 循环时,如果移除元素会抛异常吗?
for (Student stu : students) {
if (stu.getId() == 2)
students.remove(stu);
}
会抛出ConcurrentModificationException异常。
Iterator 是工作在一个独立的线程中,并且拥有一个 mutex 锁。 Iterator 被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,所以按照 fail-fast 原则 Iterator 会马上抛出java.util.ConcurrentModificationException异常。
所以 Iterator 在工作的时候是不允许被迭代的对象被改变的。但你可以使用 Iterator 本身的方法remove()来删除对象,Iterator.remove() 方法会在删除当前迭代对象的同时维护索引的一致性。
java集合知道哪些
两大类接口:
-
Collection:存放单一元素
-
Set接口
-
HashSet
- LinkedHashSet:
LinkedHashMap
- LinkedHashSet:
-
SortedSet
- TreeSet:(红黑树)
-
-
List接口
-
ArrayList:
Object[] 数组 -
Vector:
Object[] 数组- Stack
-
LinkedList:双向链表
-
-
Queue接口
-
PriorityQueue:
Object[] 数组来实现二叉堆 -
Deque接口
- ArrayDeque:
Object[] 数组 + 双指针
- ArrayDeque:
-
-
-
Map:存放键值对
-
HashMap:数组+链表+红黑树。
- LinkedHashMap:
HashMap
- LinkedHashMap:
-
Hashtable:数组+链表
-
SortedMap接口:
- TreeMap:红黑树
-
说说 List, Set, Queue, Map 四者的区别?
-
List: 存储的元素是有序的、可重复的。 -
Set: 存储的元素是无序的、不可重复的。 -
Queue: 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。 -
Map: 使用键值对(key-value)存储,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
arraylist与vector的区别
vector线程安全,ArrayList线程不安全。底层都是Object[]存储
arraylist与linkedlist的区别
-
线程不安全
-
底层数据结构:
ArrayList 底层使用的是Object 数组;LinkedList 底层使用的是 双向链表 数据结构 -
插入和删除是否受元素位置的影响:
-
ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响 -
LinkedList 采用链表存储,所以在头尾插入或者删除元素不受元素位置的影响
-
-
是否支持快速随机访问:
LinkedList 不支持高效的随机元素访问,而ArrayList(实现了RandomAccess 接口) 支持。 -
内存空间占用:
ArrayList 的空间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)
ArrayList 的扩容机制
以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。
扩容机制
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,
//如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
- 扩容后的新容量为原容量的1.5倍(移位运算)
- 如果1.5倍还不够,则直接将新容量设置为最小需要容量
- 如果新容量大于 MAX_ARRAY_SIZE,进入(执行)
hugeCapacity()方法来比较 minCapacity 和 MAX_ARRAY_SIZE - 如果minCapacity大于最大容量,则新容量则为
Integer.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE 即为Integer.MAX_VALUE - 8。
比较重要,但是容易被忽视掉的知识点:
- java 中的
length属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性. - java 中的
length() 方法是针对字符串说的,如果想看这个字符串的长度则用到length() 这个方法. - java 中的
size() 方法是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
-
HashSet、LinkedHashSet 和TreeSet 都是Set 接口的实现类,都能保证元素唯一,都不是线程安全的。 - 主要区别在于底层数据结构不同。
HashSet 的底层数据结构是哈希表(基于HashMap 实现)。LinkedHashSet 的底层数据结构是链表和哈希表,元素的插入和取出顺序满足 FIFO。TreeSet 底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。 - 底层数据结构不同又导致这三者的应用场景不同。
HashSet 用于不需要保证元素插入和取出顺序的场景,LinkedHashSet 用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet 用于支持对元素自定义排序规则的场景。
Queue 与 Deque 的区别
Queue 是单端队列,只能从一端插入元素,另一端删除元素,实现上一般遵循 先进先出(FIFO) 规则。
Queue 扩展了 Collection 的接口,根据 因为容量问题而导致操作失败后处理方式的不同 可以分为两类方法: 一种在操作失败后会抛出异常,另一种则会返回特殊值。
Queue接口 |
抛出异常 | 返回特殊值 |
|---|---|---|
| 插入队尾 | add(E e) | offer(E e) |
| 删除队首 | remove() | poll() |
| 查询队首元素 | element() | peek() |
Deque 是双端队列,在队列的两端均可以插入或删除元素。
Deque 扩展了 Queue 的接口, 增加了在队首和队尾进行插入和删除的方法,同样根据失败后处理方式的不同分为两类:
Deque接口 |
抛出异常 | 返回特殊值 |
|---|---|---|
| 插入队首 | addFirst(E e) | offerFirst(E e) |
| 插入队尾 | addLast(E e) | offerLast(E e) |
| 删除队首 | removeFirst() | pollFirst() |
| 删除队尾 | removeLast() | pollLast() |
| 查询队首元素 | getFirst() | peekFirst() |
| 查询队尾元素 | getLast() | peekLast() |
事实上,Deque 还提供有 push() 和 pop() 等其他方法,可用于模拟栈。
ArrayDeque 与 LinkedList 的区别
ArrayDeque 和 LinkedList 都实现了 Deque 接口,两者都具有队列的功能,但两者有什么区别呢?
-
ArrayDeque 是基于可变长的数组和双指针来实现,而LinkedList 则通过链表来实现。 -
ArrayDeque 不支持存储NULL 数据,但LinkedList 支持。 -
ArrayDeque 是在 JDK1.6 才被引入的,而LinkedList 早在 JDK1.2 时就已经存在。 -
ArrayDeque 插入时可能存在扩容过程, 不过均摊后的插入操作依然为 O(1)。虽然LinkedList 不需要扩容,但是每次插入数据时均需要申请新的堆空间,均摊性能相比更慢。
从性能的角度上,选用 ArrayDeque 来实现队列要比 LinkedList 更好。此外,ArrayDeque 也可以用于实现栈
说一说 PriorityQueue
与 Queue 的区别在于元素出队顺序是与优先级相关的,即总是优先级最高的元素先出队。
-
PriorityQueue 利用了二叉堆的数据结构来实现的,底层使用可变长的数组来存储数据 -
PriorityQueue 通过堆元素的上浮和下沉,实现了在 O(logn) 的时间复杂度内插入元素和删除堆顶元素。 -
PriorityQueue 是非线程安全的,且不支持存储NULL 和non-comparable 的对象。 -
PriorityQueue 默认是小顶堆,但可以接收一个Comparator 作为构造参数,从而来自定义元素优先级的先后。
PriorityQueue 在面试中可能更多的会出现在手撕算法的时候,典型例题包括堆排序、求第 K 大的数、带权图的遍历等,所以需要会熟练使用才行。
HashMap 和 Hashtable 的区别
-
线程是否安全:
-
HashMap 是非线程安全的 -
Hashtable 是线程安全的,因为Hashtable 内部的方法基本都经过synchronized 修饰。(如果你要保证线程安全的话就使用ConcurrentHashMap 吧!);
-
-
效率: 因为线程安全的问题,
HashMap 要比Hashtable 效率高一点。另外,Hashtable 基本被淘汰,不要在代码中使用它; -
对 Null key 和 Null value 的支持:
-
HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个; - Hashtable 不允许有 null 键和 null 值,否则会抛出
NullPointerException。
-
-
初始容量大小和每次扩充容量大小的不同:
- ① 创建时如果不指定容量初始值,
Hashtable 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。 - ② 创建时如果给定了容量初始值,那么
Hashtable 会直接使用你给定的大小,而HashMap 会将其扩充为 2 的幂次方大小(HashMap 中的tableSizeFor()方法保证,下面给出了源代码)。也就是说HashMap 总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。
- ① 创建时如果不指定容量初始值,
-
底层数据结构: JDK1.8 以后的
HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间(后文中我会结合源码对这一过程进行分析)。Hashtable 没有这样的机制。
HashMap 中带有初始容量的构造函数:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
下面这个方法保证了 HashMap 总是使用 2 的幂作为哈希表的大小。
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
HashMap有几种遍历方式?
HashMap 的 7 种遍历方式与性能分析!「修正篇」 (qq.com)
ConcurrentHashMap与HashTable的区别
-
底层数据结构: JDK1.7 的
ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8 的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的; -
实现线程安全的方式(重要):
- 在 JDK1.7 的时候,
ConcurrentHashMap 对整个桶数组进行了分割分段(Segment,分段锁),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 - 到了 JDK1.8 的时候,
ConcurrentHashMap 已经摒弃了Segment 的概念,而是直接用Node 数组+链表+红黑树的数据结构来实现,并发控制使用synchronized 和 CAS 来操作。 -
Hashtable (同一把锁) :使用synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低
- 在 JDK1.7 的时候,
1.8以前:
一个 ConcurrentHashMap 里包含一个 Segment 数组,Segment 的个数一旦初始化就不能改变。 Segment 数组的大小默认是 16,也就是说默认可以同时支持 16 个线程并发写。当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。也就是说,对同一 Segment 的并发写入会被阻塞,不同 Segment 的写入是可以并发执行的。
1.8:
ConcurrentHashMap 取消了 Segment 分段锁,采用 Node + CAS + synchronized 来保证并发安全。数据结构跟 HashMap 1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))。
Java 8 中,锁粒度更细,synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,就不会影响其他 Node 的读写,效率大幅提升。
JDK 1.7 和 JDK 1.8 的 ConcurrentHashMap 实现有什么不同?
- 线程安全实现方式:JDK 1.7 采用
Segment 分段锁来保证安全,Segment 是继承自ReentrantLock。JDK1.8 放弃了Segment 分段锁的设计,采用Node + CAS + synchronized 保证线程安全,锁粒度更细,synchronized 只锁定当前链表或红黑二叉树的首节点。 - Hash 碰撞解决方法 : JDK 1.7 采用拉链法,JDK1.8 采用拉链法结合红黑树(链表长度超过一定阈值时,将链表转换为红黑树)。
- 并发度:JDK 1.7 最大并发度是 Segment 的个数,默认是 16。JDK 1.8 最大并发度是 Node 数组的大小,并发度更大。
说说线程的生命周期和状态?
- NEW: 初始状态,线程被创建出来但没有被调用
start() 。 - RUNNABLE: 运行状态,线程被调用了
start()等待运行的状态。 - BLOCKED:阻塞状态,需要等待锁释放。
- WAITING:等待状态,表示该线程需要等待其他线程做出一些特定动作(通知或中断)。
- TIME_WAITING:超时等待状态,可以在指定的时间后自行返回而不是像 WAITING 那样一直等待。
- TERMINATED:终止状态,表示该线程已经运行完毕
死锁的条件、预防死锁与避免死锁
产生死锁的四个必要条件:
- 互斥条件:该资源任意一个时刻只由一个线程占用。
- 请求与保持条件:一个线程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:线程已获得的资源在未使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待条件:若干线程之间形成一种头尾相接的循环等待资源关系。
如何预防死锁? 破坏死锁的产生的必要条件即可:
- 破坏请求与保持条件:一次性申请所有的资源。
- 破坏不剥夺条件:占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
- 破坏循环等待条件:靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
如何避免死锁?
避免死锁就是在资源分配时,借助于算法(比如银行家算法)对资源分配进行计算评估,使其进入安全状态。
sleep() 方法和 wait() 方法对比
共同点:两者都可以暂停线程的执行。
区别:
- 锁:
sleep() 方法没有释放锁,而 wait() 方法释放了锁 。 - 作用:
wait() 通常被用于线程间交互/通信,sleep()通常被用于暂停执行。 - 自动苏醒:
wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的notify()或者notifyAll() 方法。sleep()方法执行完成后,线程会自动苏醒,或者也可以使用wait(long timeout) 超时后线程会自动苏醒。 - 类别:
sleep() 是Thread 类的静态本地方法,wait() 则是Object 类的本地方法
为什么 wait() 方法不定义在 Thread 中
wait() 是让获得对象锁的线程实现等待,会自动释放当前线程占有的对象锁。每个对象(Object)都拥有对象锁,既然要释放当前线程占有的对象锁并让其进入 WAITING 状态,自然是要操作对应的对象(Object)而非当前的线程(Thread)。
类似的问题:为什么 sleep() 方法定义在 Thread 中?
因为 sleep() 是让当前线程暂停执行,不涉及到对象类,也不需要获得对象锁
可以直接调用 Thread 类的 run 方法吗?
new 一个 Thread,线程进入了新建状态。调用 start()方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。
但是,直接执行 run() 方法,会把 run() 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
总结:调用 start() 方法方可启动线程并使线程进入就绪状态,直接执行 run() 方法的话不会以多线程的方式执行。
volatile关键字的作用
可见性:
- 每次使用它都到主存中进行读取
- 但不能保证数据的原子性。
synchronized 关键字两者都能保证。
禁止指令重排序
- 插入特定的 内存屏障 的方式来禁止指令重排序
单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance <span style="font-weight: bold;" class="mark"> null) {
//类对象加锁
synchronized (Singleton.class) {
if (uniqueInstance </span> null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
- 为
uniqueInstance 分配内存空间 - 初始化
uniqueInstance - 将
uniqueInstance 指向分配的内存地址
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
乐观锁存在的问题
-
ABA 问题:解决思路是在变量前面追加上版本号或者时间戳
-
循环时间长,CPU开销大
- 高并发的场景下,乐观锁相比悲观锁来说,不存在锁竞争造成线程阻塞,也不会有死锁的问题,在性能上往往会更胜一筹。但是,如果冲突频繁发生(写占比非常多的情况),会频繁失败和重试,这样同样会非常影响性能,导致 CPU 飙升。
-
只能保证一个共享变量的原子操作
- CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5 开始,提供了
AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用AtomicReference类把多个共享变量合并成一个共享变量来操作。
- CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5 开始,提供了
- 悲观锁通常多用于写比较多的情况下(多写场景,竞争激烈),这样可以避免频繁失败和重试影响性能,悲观锁的开销是固定的。不过,如果乐观锁解决了频繁失败和重试这个问题的话(比如
LongAdder),也是可以考虑使用乐观锁的,要视实际情况而定。 - 乐观锁通常多于写比较少的情况下(多读场景,竞争较少),这样可以避免频繁加锁影响性能。不过,乐观锁主要针对的对象是单个共享变量(参考
java.util.concurrent.atomic包下面的原子变量类)
乐观锁一般会使用
-
版本号机制
-
CAS 算法
实现。
synchronized 底层原理了解吗?
synchronized 同步语句块的情况
synchronized 同步语句块的实现使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。
字节码中包含一个 monitorenter 指令以及两个 monitorexit 指令,这是为了保证锁在同步代码块代码正常执行以及出现异常的这两种情况下都能被正确释放。
当执行 monitorenter 指令时,线程试图获取锁也就是获取 对象监视器 monitor 的持有权。
在 Java 虚拟机(HotSpot)中,Monitor 是基于 C++实现的,由ObjectMonitoropen in new window实现的。每个对象中都内置了一个
ObjectMonitor对象。另外,
wait/notify等方法也依赖于monitor对象,这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。
在执行monitorenter时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
对象锁的的拥有者线程才可以执行 monitorexit 指令来释放锁。在执行 monitorexit 指令后,将锁计数器设为 0,表明锁被释放,其他线程可以尝试获取锁。
如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
synchronized 修饰方法的的情况
synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令,取得代之的确实是 ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法。JVM 通过该 ACC_SYNCHRONIZED 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
如果是实例方法,JVM 会尝试获取实例对象的锁。如果是静态方法,JVM 会尝试获取当前 class 的锁。
两者的本质都是对对象监视器 monitor 的获取。
自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率
((20221116115373-udk794l "无锁、轻量级锁、偏向锁、重量级锁"))
- 自旋锁:自旋锁是一种乐观锁,它认为获取锁的操作不会发生长时间的等待,所以当一个线程尝试获取锁时,它不会立即阻塞,而是在一个循环中不断地尝试获取锁,直到成功或超过一定的时间限制。自旋锁可以避免线程切换带来的开销,提高性能,但是如果锁的竞争激烈或者持有时间较长,自旋锁会消耗大量的CPU资源,造成性能下降。自旋锁在JDK1.6中默认启用,可以通过-XX:+UseSpinning参数进行调整1。
- 适应性自旋锁:适应性自旋锁是自旋锁的一种改进,它可以根据前一次在同一个锁上的自旋时间以及锁的拥有者的状态来决定本次自旋的时间,避免过长或过短的自旋时间。适应性自旋锁还会根据当前CPU的负载情况做出相应的调整,例如如果CPU处于节电模式或者有超过一半的线程正在自旋,则停止自旋1。
- 锁消除:锁消除是一种编译时优化技术,它可以在运行时检测到某些同步块不可能存在竞争,从而消除这些无用的同步操作,减少开销。例如对于一个局部变量或者一个不会逃逸出方法的对象,它只能被当前线程访问,那么对它加上synchronized就没有必要了2。
- 锁粗化:锁粗化是另一种编译时优化技术,它可以将多个连续的加锁、解锁操作合并为一次,扩大同步块的范围,减少加锁解锁的次数。例如对于一个循环体中反复执行加锁解锁操作的情况,就可以将同步块移到循环体外部2。
- 偏向锁:偏向锁是一种悲观锁,它认为同步块通常只会被一个线程访问,不存在多线程竞争的情况。所以当一个线程第一次获取到一个对象的偏向锁时,它会将对象头中的标志位设置为偏向模式,并记录下自己的线程ID。之后该线程再次访问该对象时,就可以快速地判断出该对象已经被自己持有了,并直接进入同步块。如果出现了其他线程尝试获取该对象的偏向锁,则持有偏向锁的线程会被挂起,偏向锁会被撤销,并升级为轻量级锁3。
- 轻量级锁:轻量级锁也是一种悲观锁,它认为同步块通常不会存在竞争,但也允许其他线程尝试获取锁。当一个线程第一次获取到一个对象的轻量级锁时,它会在栈帧中创建一个锁记录,并将对象头中的标志位设置为轻量级锁模式,并指向锁记录。之后该线程再次访问该对象时,就可以通过比较对象头和锁记录来判断是否已经持有了该对象的锁,并直接进入同步块。如果出现了其他线程尝试获取该对象的轻量级锁,则持有轻量级锁的线程会尝试使用CAS操作将对象头中的标志位设置为重量级锁模式,如果成功,则其他线程会进入阻塞状态,等待锁的释放;如果失败,则表示已经有多个线程竞争该锁,此时持有轻量级锁的线程也会释放锁,并升级为重量级锁3。
- 重量级锁:重量级锁是一种悲观锁,它认为同步块通常会存在竞争,所以当一个线程获取到一个对象的重量级锁时,它会将对象头中的标志位设置为重量级锁模式,并指向一个互斥量(mutex)。之后该线程再次访问该对象时,就可以通过比较对象头和互斥量来判断是否已经持有了该对象的锁,并直接进入同步块。如果出现了其他线程尝试获取该对象的重量级锁,则它们会进入阻塞状态,等待持有重量级锁的线程释放锁,并通过操作系统进行调度3。
静态 synchronized 方法和非静态 synchronized 方法之间的调用互斥么?
静态synchronized方法和非静态synchronized方法之间的调用是否互斥,取决于它们是不是属于同一个类或者同一个对象。如果是同一个类或者同一个对象,那么它们之间的调用是互斥的,因为它们都需要获取相同的锁;如果不是同一个类或者同一个对象,那么它们之间的调用不是互斥的,因为它们获取的锁是不同的。
具体来说,静态synchronized方法是对类加锁,也就是给当前类加锁,会作用于类的所有对象实例1。非静态synchronized方法是对对象加锁,也就是给当前对象实例加锁2。所以,如果两个方法都属于同一个类,并且使用相同的对象实例或者类名来调用,那么它们之间的调用就是互斥的,因为它们都需要获取该类或该对象实例的锁。
synchronized 和 volatile 有什么区别?
synchronized 关键字和 volatile 关键字是两个互补的存在,而不是对立的存在!
-
volatile 关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好 。但是volatile 关键字只能用于变量而synchronized 关键字可以修饰方法以及代码块 。 -
volatile 关键字能保证数据的可见性,但不能保证数据的原子性。synchronized 关键字两者都能保证。 -
volatile关键字主要用于解决变量在多个线程之间的可见性,而synchronized 关键字解决的是多个线程之间访问资源的同步性。
synchronized 和 ReentrantLock 有什么区别?
ReentrantLock 实现了 Lock 接口,是一个可重入且独占式的锁,和 synchronized 关键字类似。不过,ReentrantLock 更灵活、更强大,增加了轮询、超时、中断、公平锁和非公平锁等高级功能。
两者都是可重入锁
synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
synchronized 是依赖于 JVM 实现的, JDK1.6 为 synchronized 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。
ReentrantLock 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
ReentrantLock 比 synchronized 增加了一些高级功能
相比synchronized,ReentrantLock增加了一些高级功能。主要来说主要有三点:
- 等待可中断 :
ReentrantLock提供了一种能够中断等待锁的线程的机制,通过lock.lockInterruptibly() 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。 - 可实现公平锁 :
ReentrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。ReentrantLock默认情况是非公平的,可以通过ReentrantLock类的ReentrantLock(boolean fair)构造方法来制定是否是公平的。 - 可实现选择性通知(锁可以绑定多个条件) :
synchronized关键字与wait()和notify()/notifyAll()方法相结合可以实现等待/通知机制。ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition()方法。
如果你想使用上述功能,那么选择 ReentrantLock 是一个不错的选择。
Condition是 JDK1.5 之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个Lock对象中可以创建多个Condition实例(即对象监视器),线程对象可以注册在指定的Condition中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用notify()/notifyAll() 方法进行通知时,被通知的线程是由 JVM 选择的,用ReentrantLock类结合Condition实例可以实现“选择性通知” ,这个功能非常重要,而且是 Condition 接口默认提供的。而synchronized关键字就相当于整个 Lock 对象中只有一个Condition实例,所有的线程都注册在它一个身上。如果执行notifyAll()方法的话就会通知所有处于等待状态的线程,这样会造成很大的效率问题。而Condition实例的signalAll()方法,只会唤醒注册在该Condition实例中的所有等待线程。
线程持有读锁还能获取写锁吗?
- 在线程持有读锁的情况下,该线程不能取得写锁(因为获取写锁的时候,如果发现当前的读锁被占用,就马上获取失败,不管读锁是不是被当前线程持有)。
- 在线程持有写锁的情况下,该线程可以继续获取读锁(获取读锁时如果发现写锁被占用,只有写锁没有被当前线程占用的情况才会获取失败)
读锁为什么不能升级为写锁
写锁可以降级为读锁,但是读锁却不能升级为写锁。这是因为读锁升级为写锁会引起线程的争夺,毕竟写锁属于是独占锁,这样的话,会影响性能。
另外,还可能会有死锁问题发生。举个例子:假设两个线程的读锁都想升级写锁,则需要对方都释放自己锁,而双方都不释放,就会产生死锁。
ThreadLocal 原理了解吗
ThreadLocal类主要解决的就是让每个线程绑定自己的值,可以将ThreadLocal类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。
ThreadLocal类的set()方法
public void set(T value) {
//获取当前请求的线程
Thread t = Thread.currentThread();
//取出 Thread 类内部的 threadLocals 变量(哈希表结构)
ThreadLocalMap map = getMap(t);
if (map != null)
// 将需要存储的值放入到这个哈希表中
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
最终的变量是放在了当前线程的 ThreadLocalMap 中,并不是存在 ThreadLocal 上,ThreadLocal 可以理解为只是ThreadLocalMap的封装,传递了变量值。ThrealLocal 类中可以通过Thread.currentThread()获取到当前线程对象后,直接通过getMap(Thread t)可以访问到该线程的ThreadLocalMap对象。
每个Thread中都具备一个ThreadLocalMap ,而ThreadLocalMap可以存储以ThreadLocal为 key ,Object 对象为 value 的键值对。
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
//......
}
比如我们在同一个线程中声明了两个 ThreadLocal 对象的话, Thread内部都是使用仅有的那个ThreadLocalMap 存放数据的,ThreadLocalMap的 key 就是 ThreadLocal对象,value 就是 ThreadLocal 对象调用set方法设置的值。
ThreadLocal 数据结构如下图所示:

ThreadLocalMap是ThreadLocal的静态内部类。

ThreadLocal 内存泄露问题是怎么导致的
ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,而 value 是强引用。所以,如果 ThreadLocal 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。
这样一来,ThreadLocalMap 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。
ThreadLocalMap 实现中已经考虑了这种情况,在调用 set()、get()、remove() 方法的时候,会清理掉 key 为 null 的记录。使用完 ThreadLocal方法后最好手动调用remove()方法
线程池的优点,如何创建线程池
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
方式一:通过ThreadPoolExecutor构造函数来创建(推荐)
 通过构造方法实现
通过构造方法实现
方式二:通过 Executor 框架的工具类 Executors 来创建。
我们可以创建多种类型的 ThreadPoolExecutor:
-
FixedThreadPool:该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。 -
SingleThreadExecutor : 该方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。 -
CachedThreadPool : 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。 -
ScheduledThreadPool:该返回一个用来在给定的延迟后运行任务或者定期执行任务的线程池。
为什么不推荐使用内置线程池?
Executors 返回线程池对象的弊端如下
-
FixedThreadPool 和 SingleThreadExecutor:使用的是无界的LinkedBlockingQueue,任务队列最大长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。 -
CachedThreadPool:使用的是同步队列SynchronousQueue, 允许创建的线程数量为Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。 -
ScheduledThreadPool 和 SingleThreadScheduledExecutor : 使用的无界的延迟阻塞队列DelayedWorkQueue,任务队列最大长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。
线程池拒绝策略有哪些?
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,ThreadPoolTaskExecutor 定义一些策略:
-
ThreadPoolExecutor.AbortPolicy : 抛出RejectedExecutionException来拒绝新任务的处理。 -
ThreadPoolExecutor.CallerRunsPolicy : 调用执行自己的线程运行任务,也就是直接在调用execute方法的线程中运行(run)被拒绝的任务。既不会抛弃任务,也不会抛出异常,而是将任务回退给调用者,使用调用者的线程来执行任务 -
ThreadPoolExecutor.DiscardPolicy : 不处理新任务,直接丢弃掉。 -
ThreadPoolExecutor.DiscardOldestPolicy : 此策略将丢弃最早的未处理的任务请求。
线程池常用的阻塞队列有哪些?
- 容量为
Integer.MAX_VALUE 的LinkedBlockingQueue(无界队列):FixedThreadPool 和SingleThreadExector 。由于队列永远不会被放满,因此FixedThreadPool最多只能创建核心线程数的线程。 -
SynchronousQueue(同步队列):CachedThreadPool 。SynchronousQueue 没有容量,不存储元素,目的是保证对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务。也就是说,CachedThreadPool 的最大线程数是Integer.MAX_VALUE ,可以理解为线程数是可以无限扩展的,可能会创建大量线程,从而导致 OOM。 -
DelayedWorkQueue(延迟阻塞队列):ScheduledThreadPool 和SingleThreadScheduledExecutor 。DelayedWorkQueue 的内部元素并不是按照放入的时间排序,而是会按照延迟的时间长短对任务进行排序,内部采用的是“堆”的数据结构,可以保证每次出队的任务都是当前队列中执行时间最靠前的。DelayedWorkQueue 添加元素满了之后会自动扩容原来容量的 1/2,即永远不会阻塞,最大扩容可达Integer.MAX_VALUE,所以最多只能创建核心线程数的线程。
线程池处理任务的流程了解吗?
- 如果当前运行的线程数小于核心线程数,那么就会新建一个线程来执行任务。
- 如果当前运行的线程数等于或大于核心线程数,但是小于最大线程数,那么就把该任务放入到任务队列里等待执行。
- 如果向任务队列投放任务失败(任务队列已经满了),但是当前运行的线程数是小于最大线程数的,就新建一个线程来执行任务。
- 如果当前运行的线程数已经等同于最大线程数了,新建线程将会使当前运行的线程超出最大线程数,那么当前任务会被拒绝,饱和策略会调用
RejectedExecutionHandler.rejectedExecution()方法。
如何设定线程池的大小?
- CPU 密集型任务(N+1): 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1。比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
- I/O 密集型任务(2N): 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。但凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上
什么是AQS
AQS 的全称为 AbstractQueuedSynchronizer ,翻译过来的意思就是抽象队列同步器。
AQS 就是一个抽象类,主要用来构建锁和同步器。
AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 CLH 队列锁 实现的,即将暂时获取不到锁的线程加入到队列中。
CLH(Craig,Landin,and Hagersten) 队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。在 CLH 同步队列中,一个节点表示一个线程,它保存着线程的引用(thread)、 当前节点在队列中的状态(waitStatus)、前驱节点(prev)、后继节点(next)。
Semaphore 的原理是什么?
synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,而Semaphore(信号量)可以用来控制同时访问特定资源的线程数量。
Semaphore 是共享锁的一种实现,它默认构造 AQS 的 state 值为 permits,你可以将 permits 的值理解为许可证的数量,只有拿到许可证的线程才能执行。
调用semaphore.acquire() ,线程尝试获取许可证,如果 state >= 0 的话,则表示可以获取成功。如果获取成功的话,使用 CAS 操作去修改 state 的值 state=state-1。如果 state<0 的话,则表示许可证数量不足。此时会创建一个 Node 节点加入阻塞队列,挂起当前线程。
调用semaphore.release(); ,线程尝试释放许可证,并使用 CAS 操作去修改 state 的值 state=state+1。释放许可证成功之后,同时会唤醒同步队列中的一个线程。被唤醒的线程会重新尝试去修改 state 的值 state=state-1 ,如果 state>=0 则获取令牌成功,否则重新进入阻塞队列,挂起线程。
CountDownLatch是什么?原理?什么场景下使用过?
CountDownLatch 允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。
CountDownLatch 是一次性的,计数器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当 CountDownLatch 使用完毕后,它不能再次被使用。
原理:
CountDownLatch 是共享锁的一种实现,它默认构造 AQS 的 state 值为 count。当线程使用 countDown() 方法时,其实使用了tryReleaseShared方法以 CAS 的操作来减少 state,直至 state 为 0 。当调用 await() 方法的时候,如果 state 不为 0,那就证明任务还没有执行完毕,await() 方法就会一直阻塞,也就是说 await() 方法之后的语句不会被执行。然后,CountDownLatch 会自旋 CAS 判断 state <span style="font-weight: bold;" class="mark"> 0,如果 state </span> 0 的话,就会释放所有等待的线程,await() 方法之后的语句得到执行。
使用场景
CountDownLatch 的两种典型用法:
- 某一线程在开始运行前等待 n 个线程执行完毕 : 将
CountDownLatch 的计数器初始化为 n (new CountDownLatch(n)),每当一个任务线程执行完毕,就将计数器减 1 (countdownlatch.countDown()),当计数器的值变为 0 时,在CountDownLatch 上 await() 的线程就会被唤醒。一个典型应用场景就是启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行。 - 实现多个线程开始执行任务的最大并行性:注意是并行性,不是并发,强调的是多个线程在某一时刻同时开始执行。类似于赛跑,将多个线程放到起点,等待发令枪响,然后同时开跑。做法是初始化一个共享的
CountDownLatch 对象,将其计数器初始化为 1 (new CountDownLatch(1)),多个线程在开始执行任务前首先coundownlatch.await(),当主线程调用countDown() 时,计数器变为 0,多个线程同时被唤醒。
有其他方法实现同步吗?
可以使用 CompletableFuture 类来改进!Java8 的 CompletableFuture 提供了很多对多线程友好的方法,使用它可以很方便地为我们编写多线程程序,什么异步、串行、并行或者等待所有线程执行完任务什么的都非常方便。
CompletableFuture<Void> task1 =
CompletableFuture.supplyAsync(()->{
//自定义业务操作
});
......
CompletableFuture<Void> task6 =
CompletableFuture.supplyAsync(()->{
//自定义业务操作
});
......
CompletableFuture<Void> headerFuture=CompletableFuture.allOf(task1,.....,task6);
try {
headerFuture.join();
} catch (Exception ex) {
//......
}
System.out.println("all done. ");
Java 内存区域和 JMM (内存模型)有何区别
JMM(Java 内存模型)主要定义了对于一个共享变量,当另一个线程对这个共享变量执行写操作后,这个线程对这个共享变量的可见性。
操作系统通过 内存模型(Memory Model) 定义一系列规范来解决内存缓存不一致性问题。无论是 Windows 系统,还是 Linux 系统,它们都有特定的内存模型。
- JVM 内存结构和 Java 虚拟机的运行时区域相关,定义了 JVM 在运行时如何分区存储程序数据,就比如说堆主要用于存放对象实例。
- Java 内存模型和 Java 的并发编程相关,抽象了线程和主内存之间的关系就比如说线程之间的共享变量必须存储在主内存中,规定了从 Java 源代码到 CPU 可执行指令的这个转化过程要遵守哪些和并发相关的原则和规范,其主要目的是为了简化多线程编程,增强程序可移植性的。
happens-before 原则是什么?
JMM 抽象了 happens-before 原则(后文会详细介绍到)来解决这个指令重排序问题。
happens-before 原则的设计思想其实非常简单:
- 为了对编译器和处理器的约束尽可能少,只要不改变程序的执行结果(单线程程序和正确执行的多线程程序),编译器和处理器怎么进行重排序优化都行。
- 对于会改变程序执行结果的重排序,JMM 要求编译器和处理器必须禁止这种重排序。
happens-before 常见规则有哪些?谈谈你的理解
原则:
- 程序顺序规则:一个线程内,按照控制流的顺序,书写在前面的操作先行发生于书写在后面的操作。注意,控制流顺序不是代码顺序。
- 管程锁定规则:一个unlock操作先行发生于后面对同一个锁的lock操作。
- volatile变量规则:对一个 volatile 变量的写操作 happens-before 于后面对这个 volatile 变量的读操作。说白了就是对 volatile 变量的写操作的结果对于发生于其后的任何操作都是可见的。
- 传递规则:如果 A happens-before B,且 B happens-before C,那么 A happens-before C
- 线程启动规则:Thread 对象的
start()方法 happens-before 于此线程的每一个动作。 - 线程终止规则:线程的所有操作都先行发生于此线程的终止检测。
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生。
- 对象终结规则:对象的初始化完成先行发生于它的finalize()方法。
Executor 框架的优点
通过 Executor 来启动线程比使用 Thread 的 start 方法更好,除了更易管理,效率更好(用线程池实现,节约开销)外,还有关键的一点:有助于避免 this 逃逸问题。
this 逃逸是指在构造函数返回之前其他线程就持有该对象的引用,调用尚未构造完全的对象的方法可能引发令人疑惑的错误。
Executor 框架不仅包括了线程池的管理,还提供了线程工厂、队列以及拒绝策略等,Executor 框架让并发编程变得更加简单。
Runnable与Callable的区别
Runnable 接口不会返回结果或抛出检查异常,但是 Callable 接口可以。所以,如果任务不需要返回结果或抛出异常推荐使用 Runnable 接口,这样代码看起来会更加简洁。
execute()与submit()的区别
-
execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否; -
submit()方法用于提交需要返回值的任务。线程池会返回一个Future 类型的对象,通过这个Future 对象可以判断任务是否执行成功,并且可以通过Future 的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法的话,如果在timeout 时间内任务还没有执行完,就会抛出java.util.concurrent.TimeoutException。
shutdown()VSshutdownNow()
-
shutdown() :关闭线程池,线程池的状态变为SHUTDOWN。线程池不再接受新任务了,但是队列里的任务得执行完毕。 -
shutdownNow() :关闭线程池,线程的状态变为STOP。线程池会终止当前正在运行的任务,并停止处理排队的任务并返回正在等待执行的 List。
isTerminated() VS isShutdown()
-
isShutDown 当调用shutdown() 方法后返回为 true。 -
isTerminated 当调用shutdown() 方法后,并且所有提交的任务完成后返回为 true
请你说一下自己对于 AQS 原理的理解
AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是基于 CLH 锁 (Craig, Landin, and Hagersten locks) 实现的。
CLH 锁是对自旋锁的一种改进,是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系),暂时获取不到锁的线程将被加入到该队列中。AQS 将每条请求共享资源的线程封装成一个 CLH 队列锁的一个结点(Node)来实现锁的分配。在 CLH 队列锁中,一个节点表示一个线程,它保存着线程的引用(thread)、 当前节点在队列中的状态(waitStatus)、前驱节点(prev)、后继节点(next)。
Java的四种引用类型
- 强引用:我们常常 new 出来的对象就是强引用类型,只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足的时候
- 软引用:使用 SoftReference 修饰的对象被称为软引用,软引用指向的对象在内存要溢出的时候被回收
- 弱引用:使用 WeakReference 修饰的对象被称为弱引用,只要发生垃圾回收,若这个对象只被弱引用指向,那么就会被回收
- 虚引用:虚引用是最弱的引用,在 Java 中使用 PhantomReference 进行定义。虚引用主要用来跟踪对象被垃圾回收的活动。
虚引用与软引用和弱引用的一个区别在于: 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为软引用可以加速 JVM 对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生。
ThreadLocal的 key 是弱引用,那么在 ThreadLocal.get()的时候,发生GC之后,key 是否为null?
ThreadLocal中ThreadLocalMap的数据结构?
ThreadLocalMap有点类似HashMap的结构,只是HashMap是由数组+链表实现的,而ThreadLocalMap中并没有链表结构。
ThreadLocalMap的Hash 算法?
ThreadLocal中有一个属性为HASH_INCREMENT = 0x61c88647
每当创建一个ThreadLocal对象,这个ThreadLocal.nextHashCode 这个值就会增长 0x61c88647 。
这个值很特殊,它是斐波那契数 也叫 黄金分割数。hash增量为 这个数字,带来的好处就是 hash分布非常均匀。
ThreadLocalMap中Hash 冲突如何解决?
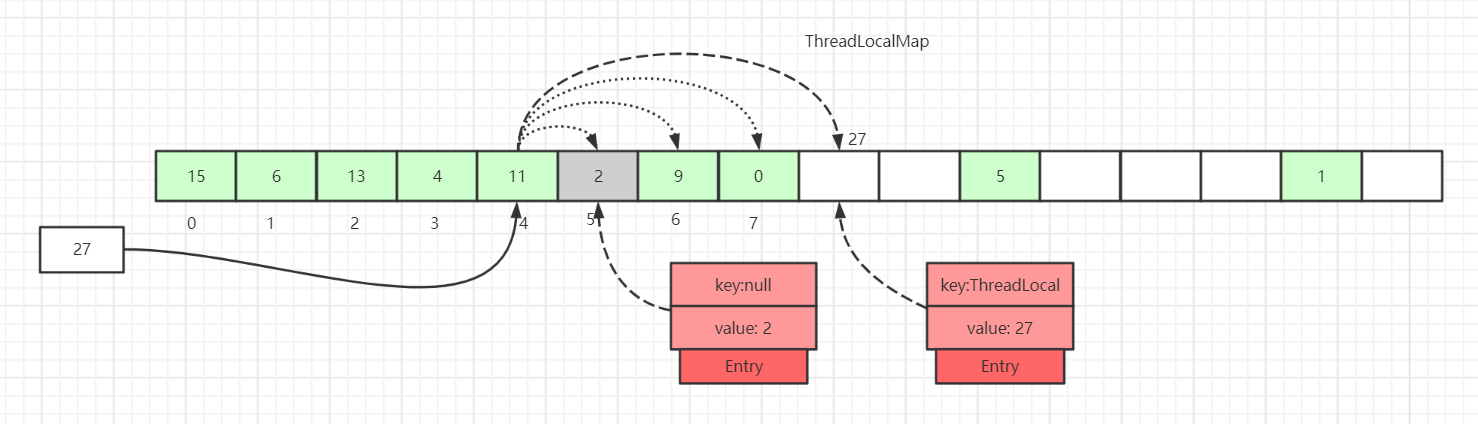 如上图所示,如果我们插入一个
如上图所示,如果我们插入一个value=27的数据,通过 hash 计算后应该落入槽位 4 中,而槽位 4 已经有了 Entry 数据。
此时就会线性向后查找,一直找到 Entry 为 null 的槽位才会停止查找,将当前元素放入此槽位中。当然迭代过程中还有其他的情况,比如遇到了 Entry 不为 null 且 key 值相等的情况,还有 Entry 中的 key 值为 null 的情况等等都会有不同的处理,后面会一一详细讲解。
这里还画了一个Entry中的key为null的数据(Entry=2 的灰色块数据),因为key值是弱引用类型,所以会有这种数据存在。在set过程中,如果遇到了key过期的Entry数据,实际上是会进行一轮探测式清理操作的,具体操作方式后面会讲到。
ThreadLocal中的set:
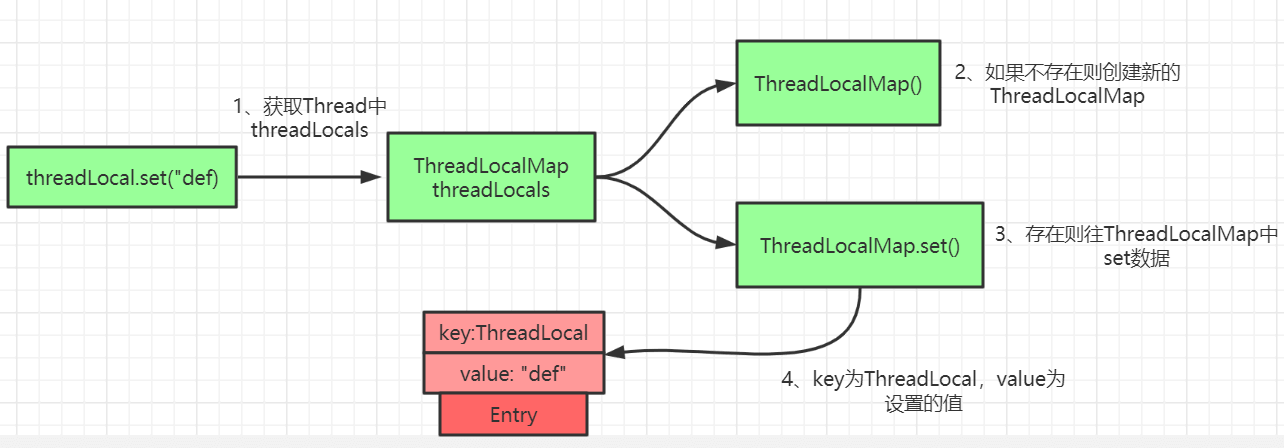
ThreadLocal中的set方法原理如上图所示,很简单,主要是判断ThreadLocalMap是否存在,然后使用ThreadLocal中的set方法进行数据处理。
代码如下:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
ThreadLocalMap.set()方法实现原理?
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
for循环中的逻辑:
- 遍历当前
key值对应的桶中Entry数据为空,这说明散列数组这里没有数据冲突,跳出for循环,直接set数据到对应的桶中 - 如果
key值对应的桶中Entry数据不为空
2.1 如果k = key,说明当前set操作是一个替换操作,做替换逻辑,直接返回
2.2 如果key = null,说明当前桶位置的Entry是过期数据,执行replaceStaleEntry()方法(核心方法),然后返回 -
for循环执行完毕,继续往下执行说明向后迭代的过程中遇到了entry为null的情况
3.1 在Entry为null的桶中创建一个新的Entry对象
3.2 执行++size操作 - 调用
cleanSomeSlots()做一次启发式清理工作,清理散列数组中Entry的key过期的数据
4.1 如果清理工作完成后,未清理到任何数据,且size超过了阈值(数组长度的 2/3),进行rehash()操作
4.2rehash()中会先进行一轮探测式清理,清理过期key,清理完成后如果size >= threshold - threshold / 4,就会执行真正的扩容逻辑(扩容逻辑往后看)
java.lang.ThreadLocal.ThreadLocalMap.replaceStaleEntry():
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
int slotToExpunge = staleSlot;
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
if (k <span style="font-weight: bold;" class="mark"> null && slotToExpunge </span> staleSlot)
slotToExpunge = i;
}
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
slotToExpunge表示开始探测式清理过期数据的开始下标,默认从当前的staleSlot开始。以当前的staleSlot开始,向前迭代查找,找到没有过期的数据,for循环一直碰到Entry为null才会结束。如果向前找到了过期数据,更新探测清理过期数据的开始下标为 i,即slotToExpunge=i
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len)){
if (e.get() == null){
slotToExpunge = i;
}
}
接着开始从staleSlot向后查找,也是碰到Entry为null的桶结束。 如果迭代过程中,碰到 k key,这说明这里是替换逻辑,替换新数据并且交换当前staleSlot位置。如果slotToExpunge </span> staleSlot,这说明replaceStaleEntry()一开始向前查找过期数据时并未找到过期的Entry数据,接着向后查找过程中也未发现过期数据,修改开始探测式清理过期数据的下标为当前循环的 index,即slotToExpunge = i。最后调用cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);进行启发式过期数据清理。
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
cleanSomeSlots()和expungeStaleEntry()方法后面都会细讲,这两个是和清理相关的方法,一个是过期key相关Entry的启发式清理(Heuristically scan),另一个是过期key相关Entry的探测式清理。
如果 k != key则会接着往下走,k <span style="font-weight: bold;" class="mark"> null说明当前遍历的Entry是一个过期数据,slotToExpunge </span> staleSlot说明,一开始的向前查找数据并未找到过期的Entry。如果条件成立,则更新slotToExpunge 为当前位置,这个前提是前驱节点扫描时未发现过期数据。
if (k <span style="font-weight: bold;" class="mark"> null && slotToExpunge </span> staleSlot)
slotToExpunge = i;
往后迭代的过程中如果没有找到k == key的数据,且碰到Entry为null的数据,则结束当前的迭代操作。此时说明这里是一个添加的逻辑,将新的数据添加到table[staleSlot] 对应的slot中。
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
最后判断除了staleSlot以外,还发现了其他过期的slot数据,就要开启清理数据的逻辑:
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
ThreadLocalMap过期 key 的探测式清理与启发式清理流程
探测式清理,也就是expungeStaleEntry方法,遍历散列数组,从开始位置向后探测清理过期数据,将过期数据的Entry设置为null,沿途中碰到未过期的数据则将此数据rehash后重新在table数组中定位,如果定位的位置已经有了数据,则会将未过期的数据放到最靠近此位置的Entry=null的桶中,使rehash后的Entry数据距离正确的桶的位置更近一些。
实现源代码:
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
这里我们还是以staleSlot=3 来做示例说明,首先是将tab[staleSlot]槽位的数据清空,然后设置size-- 接着以staleSlot位置往后迭代,如果遇到k==null的过期数据,也是清空该槽位数据,然后size--
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
}
如果key没有过期,重新计算当前key的下标位置是不是当前槽位下标位置,如果不是,那么说明产生了hash冲突,此时以新计算出来正确的槽位位置往后迭代,找到最近一个可以存放entry的位置。
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
这里是处理正常的产生Hash冲突的数据,经过迭代后,有过Hash冲突数据的Entry位置会更靠近正确位置,这样的话,查询的时候 效率才会更高。
启发式清理:
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null) {
n = len;
removed = true;
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1) != 0);
return removed;
}
ThreadLocalMap的get()方法实现原理?
java.lang.ThreadLocal.ThreadLocalMap.getEntry():
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get();
if (k <span style="font-weight: bold;" class="mark"> key)
return e;
if (k </span> null)
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
第一种情况: 通过查找key值计算出散列表中slot位置,然后该slot位置中的Entry.key和查找的key一致,则直接返回
第二种情况: slot位置中的Entry.key和要查找的key不一致:向后遍历,如果遇到key为null的entry,则进行探测式清理,然后继续遍历,直到找到。
ThreadLocalMap的扩容
在ThreadLocalMap.set()方法的最后,如果执行完启发式清理工作后,未清理到任何数据,且当前散列数组中Entry的数量已经达到了列表的扩容阈值(len*2/3),就开始执行rehash()逻辑:
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
接着看下rehash()具体实现:
private void rehash() {
expungeStaleEntries();
if (size >= threshold - threshold / 4)
resize();
}
private void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j < len; j++) {
Entry e = tab[j];
if (e != null && e.get() == null)
expungeStaleEntry(j);
}
}
这里首先是会进行探测式清理工作,从table的起始位置往后清理,上面有分析清理的详细流程。清理完成之后,table中可能有一些key为null的Entry数据被清理掉,所以此时通过判断size >= threshold - threshold / 4 也就是size >= threshold * 3/4 来决定是否扩容。
我们还记得上面进行rehash()的阈值是size >= threshold,所以当面试官套路我们ThreadLocalMap扩容机制的时候 我们一定要说清楚这两个步骤:
- 先进行探测式清理
- 判断size >= threshold - threshold / 4;是,则resize()
resize()
扩容后的tab的大小为oldLen * 2,然后遍历老的散列表,重新计算hash位置,然后放到新的tab数组中,如果出现hash冲突则往后寻找最近的entry为null的槽位,遍历完成之后,oldTab中所有的entry数据都已经放入到新的tab中了。重新计算tab下次扩容的阈值,具体代码如下:
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
} else {
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}
InheritableThreadLocal
我们使用ThreadLocal的时候,在异步场景下是无法给子线程共享父线程中创建的线程副本数据的。
为了解决这个问题,JDK 中还有一个InheritableThreadLocal类,我们来看一个例子:
public class InheritableThreadLocalDemo {
public static void main(String[] args) {
ThreadLocal<String> ThreadLocal = new ThreadLocal<>();
ThreadLocal<String> inheritableThreadLocal = new InheritableThreadLocal<>();
ThreadLocal.set("父类数据:threadLocal");
inheritableThreadLocal.set("父类数据:inheritableThreadLocal");
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("子线程获取父类ThreadLocal数据:" + ThreadLocal.get());
System.out.println("子线程获取父类inheritableThreadLocal数据:" + inheritableThreadLocal.get());
}
}).start();
}
}
打印结果:
子线程获取父类ThreadLocal数据:null
子线程获取父类inheritableThreadLocal数据:父类数据:inheritableThreadLocal
实现原理是子线程是通过在父线程中通过调用new Thread()方法来创建子线程,Thread#init方法在Thread的构造方法中被调用。在init方法中拷贝父线程数据到子线程中:
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc,
boolean inheritThreadLocals) {
if (name == null) {
throw new NullPointerException("name cannot be null");
}
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
this.stackSize = stackSize;
tid = nextThreadID();
}
但InheritableThreadLocal仍然有缺陷,一般我们做异步化处理都是使用的线程池,而InheritableThreadLocal是在new Thread中的init()方法给赋值的,而线程池是线程复用的逻辑,所以这里会存在问题。
常用字符编码所占字节数
utf8 :英文占 1 字节,中文占 3 字节,unicode:任何字符都占 2 个字节,gbk:英文占 1 字节,中文占 2 字节
有哪些常见的 IO 模型?
Unix系统下,有五种:同步阻塞 I/O、同步非阻塞 I/O、I/O 多路复用、信号驱动 I/O 和异步 I/O。
Java中,有3中常见IO模型:
-
BIO (Blocking I/O):BIO 属于同步阻塞 IO 模型 。
- 同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。
-
NIO (Non-blocking/New I/O):可以看作是 I/O 多路复用模型。通过减少无效的系统调用,减少了对 CPU 资源的消耗。
-
AIO (Asynchronous I/O):异步 IO 模型。基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
介绍下 Java 内存区域(运行时数据区)
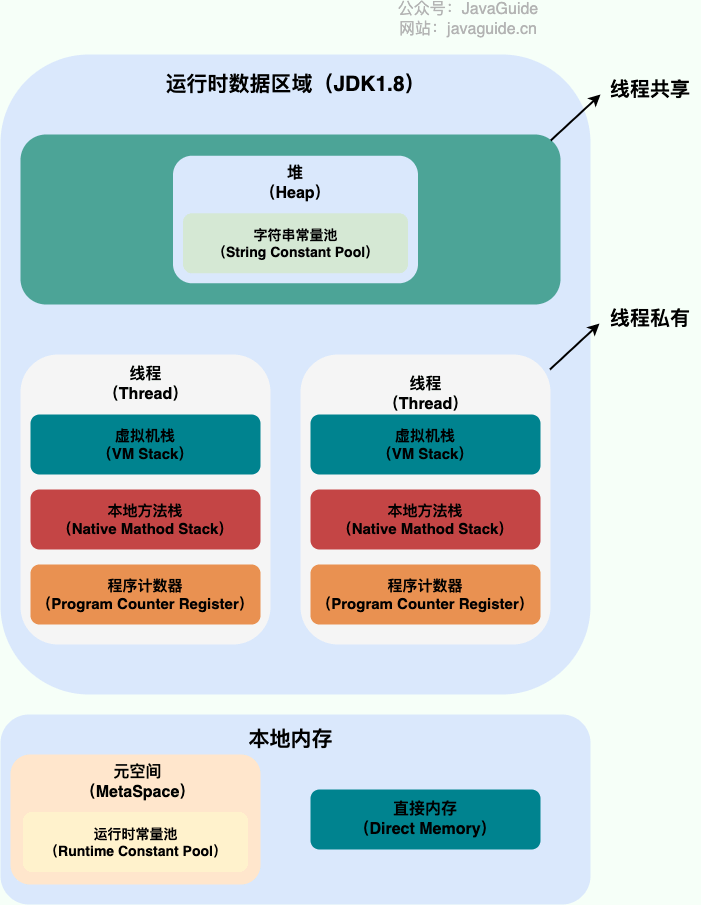 虚拟机栈
虚拟机栈
除了一些 Native 方法调用是通过本地方法栈实现的(后面会提到),其他所有的 Java 方法调用都是通过栈来实现的(也需要和其他运行时数据区域比如程序计数器配合)。
栈由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法返回地址。和数据结构上的栈类似,两者都是先进后出的数据结构,只支持出栈和入栈两种操作。
局部变量表 主要存放了编译期可知的各种数据类型(boolean、byte、char、short、int、float、long、double)、对象引用
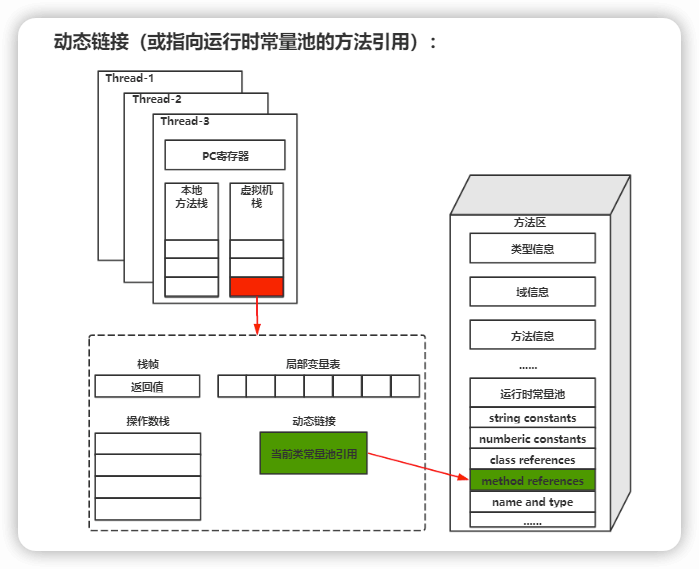
操作数栈 主要作为方法调用的中转站使用,用于存放方法执行过程中产生的中间计算结果。另外,计算过程中产生的临时变量也会放在操作数栈中。
动态链接 动态链接的作用就是为了将符号引用转换为调用方法的直接引用。
Java 方法有两种返回方式,一种是 return 语句正常返回,一种是抛出异常。不管哪种返回方式,都会导致栈帧被弹出。也就是说, 栈帧随着方法调用而创建,随着方法结束而销毁。无论方法正常完成还是异常完成都算作方法结束。
简单总结一下程序运行中栈可能会出现两种错误:
-
StackOverFlowError : 若栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出StackOverFlowError 错误。 -
OutOfMemoryError : 如果栈的内存大小可以动态扩展, 如果虚拟机在动态扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常。
本地方法栈
虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务
堆
Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。
Java 堆是垃圾收集器管理的主要区域,因此也被称作 GC 堆
由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆还可以细分为:新生代和老年代;再细致一点有:Eden、Survivor、Old 等空间。
在 JDK 7 版本及 JDK 7 版本之前,堆内存被通常分为下面三部分:
- 新生代内存(Young Generation)
- 老生代(Old Generation)
- 永久代(Permanent Generation)
JDK 8 版本之后 PermGen(永久代) 已被 Metaspace(元空间) 取代,元空间使用的是本地内存。
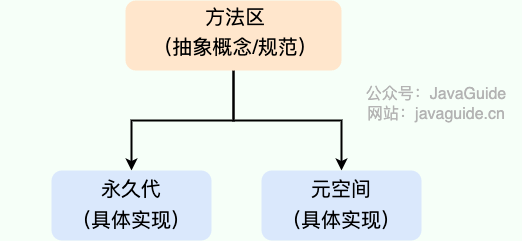
方法区:
方法区属于是 JVM 运行时数据区域的一块逻辑区域,是各个线程共享的内存区域。
当虚拟机要使用一个类时,它需要读取并解析 Class 文件获取相关信息,再将信息存入到方法区。方法区会存储已被虚拟机加载的 类信息、字段信息、方法信息、常量、静态变量、即时编译器编译后的代码缓存等数据
元空间是方法区的实现。
JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是本地内存。下面是一些常用参数:
-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)
-XX:MaxMetaspaceSize=N //设置 Metaspace 的最大大小
与永久代很大的不同就是,如果不指定大小的话,随着更多类的创建,虚拟机会耗尽所有可用的系统内存
运行时常量池:
Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有用于存放编译期生成的各种字面量(Literal)和符号引用(Symbolic Reference)的 常量池表(Constant Pool Table) 。
直接内存
直接内存是一种特殊的内存缓冲区,并不在 Java 堆或方法区中分配的,而是通过 JNI 的方式在本地内存上分配的。
直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 OutOfMemoryError 错误出现。
JDK1.4 中新加入的 NIO(Non-Blocking I/O,也被称为 New I/O) ,引入了一种基于通道(Channel) 与缓存区(Buffer) 的 I/O 方式,它可以直接使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆之间来回复制数据。
直接内存的分配不会受到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace) 呢?
1、整个永久代有一个 JVM 本身设置的固定大小上限,无法进行调整,而元空间使用的是本地内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小
2、元空间里面存放的是类的元数据,这样加载多少类的元数据就不由 MaxPermSize 控制了, 而由系统的实际可用空间来控制,这样能加载的类就更多了。
3、在 JDK8,合并 HotSpot 和 JRockit 的代码时, JRockit 从来没有一个叫永久代的东西, 合并之后就没有必要额外的设置这么一个永久代的地方了。
对象的访问定位的两种方式(句柄和直接指针两种方式)
句柄:
如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与对象类型数据各自的具体地址信息。

直接指针
如果使用直接指针访问,reference 中存储的直接就是对象的地址。

这两种对象访问方式各有优势。使用句柄来访问的最大好处是 reference 中存储的是稳定的句柄地址,在对象被移动时只会改变句柄中的实例数据指针,而 reference 本身不需要修改。使用直接指针访问方式最大的好处就是速度快,它节省了一次指针定位的时间开销。
HotSpot 虚拟机主要使用的就是这种方式来进行对象访问
Java 对象的创建过程
-
类加载检查
- 虚拟机遇到一条new指令时,首先去检查这条指令的参数能否在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已经被加载、解析和初始化过。
- 如果没有,那必须先执行相应的类加载过程。
-
分配内存
-
在类加载检查通过后,虚拟机将为新生对象分配内存。对象所需的内存大小在类加载完成后即可确认,为对象分配空间等同于把一块确定大小的内存从Java堆中划分出来。
-
分配方式有指针碰撞和空闲列表两种,选择哪种分配方式由Java堆是否规整决定,Java堆是否规整由所采用的垃圾收集器是否带有压缩整理功能决定。
-
指针碰撞:
- 试用场景:堆内存规整(即没有内存碎片)
- 原理 :用过的内存全部整合到一边,没有用过的内存放在另一边,中间有一个分界指针,只需要向着没用过的内存方向将该指针移动对象内存大小位置即可。
- 使用该分配方式的 GC 收集器:Serial, ParNew
-
空闲列表:
- 适用场合 : 堆内存不规整的情况下。
- 原理 :虚拟机会维护一个列表,该列表中会记录哪些内存块是可用的,在分配的时候,找一块儿足够大的内存块儿来划分给对象实例,最后更新列表记录。
- 使用该分配方式的 GC 收集器:CMS
-
选择以上两种方式中的哪一种,取决于 Java 堆内存是否规整。而Java 堆内存是否规整,取决于 GC 收集器的算法是"标记-清除",还是"标记-整理"(也称作"标记-压缩"),值得注意的是,复制算法内存也是规整的。
-
-
内存分配并发问题:创建对象的过程中需要保证线程安全,虚拟机采用两种方式保证:
-
CAS+失败重试:
虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。
-
TLAB:
为每一个线程预先在 Eden 区分配一块儿内存,JVM 在给线程中的对象分配内存时,首先在 TLAB 分配,当对象大于 TLAB 中的剩余内存或 TLAB 的内存已用尽时,再采用上述的 CAS 进行内存分配
-
-
-
初始化零值
内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包含对象头),这一步保证了对象的实例字段在Java代码中可以不赋初始值就直接使用。
-
设置对象头
初始化零值完成之后,虚拟机要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息。 这些信息存放在对象头中。 另外,根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
-
执行init方法
在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,
<init> 方法还没有执行,所有的字段都还为零。所以一般来说,执行 new 指令之后会接着执行<init> 方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
对象的内存布局
HotSpot虚拟机中,对象在内存中的布局可以分为3块区域:对象头、实例数据、对齐填充
-
对象头:包括两部分信息
- 第一部分,用于存储对象自身的运行时数据(哈希码、GC分代年龄、锁状态标志等等)
- 另一部分是类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
-
实例数据:对象真正存储的有效信息,也就是在程序中所定义的各种类型的字段内容。
-
对齐填充:仅起到占位的作用。
因为 Hotspot 虚拟机的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,换句话说就是对象的大小必须是 8 字节的整数倍。而对象头部分正好是 8 字节的倍数(1 倍或 2 倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
如何判断对象是否死亡(两种方法)。
引用计数法
给对象中添加一个引用计数器:
- 每当有一个地方引用它,计数器就加 1;
- 当引用失效,计数器就减 1;
- 任何时候计数器为 0 的对象就是不可能再被使用的。
缺点:难以解决对象之间循环引用的问题。
可达性分析法
通过一系列的称为 “GC Roots” 的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的,需要被回收。
要真正宣告一个对象死亡,至少要经历两次标记过程;可达性分析法中不可达的对象被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行 finalize 方法。当对象没有覆盖 finalize 方法,或 finalize 方法已经被虚拟机调用过时,虚拟机将这两种情况视为没有必要执行。
被判定为需要执行的对象将会被放在一个队列中进行第二次标记,除非这个对象与引用链上的任何一个对象建立关联,否则就会被真的回收。
哪些对象可以作为 GC Roots 呢?
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 本地方法栈(Native 方法)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 所有被同步锁持有的对象
如何判断一个常量是废弃常量
没有任何对象引用的常量,在发生内存回收时会被清理掉。
如何判断一个类是无用的类
类需要同时满足下面 3 个条件才能算是 “无用的类” :
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的
ClassLoader 已经被回收。 - 该类对应的
java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
垃圾收集有哪些算法,各自的特点?
标记清除:首先标记出所有不需要回收的对象,在标记完成后统一回收掉所有没有被标记的对象。
-
- 效率问题:标记和清除两个过程效率都不高。
- 空间问题:标记清除后会产生大量不连续的内存碎片。
标记复制:将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。
- 可用内存变小:可用内存缩小为原来的一半。
- 不适合老年代:如果存活对象数量比较大,复制性能会变得很差
标记整理: 标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
- 多了整理这一步,因此效率也不高,适合老年代这种垃圾回收频率不是很高的场景。
分代收集
- 新生代:标记复制
- 老年代:标记清除或标记整理
HotSpot 为什么要分为新生代和老年代?
分代收集算法的需要
一般将 Java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
比如在新生代中,每次收集都会有大量对象死去,所以可以选择”标记-复制“算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
常见的垃圾回收器有哪些?
Serial(串行)收集器
是一个单线程收集器了。它的 “单线程” 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( "Stop The World" ),直到它收集结束。
新生代采用标记-复制算法,老年代采用标记-整理算法。
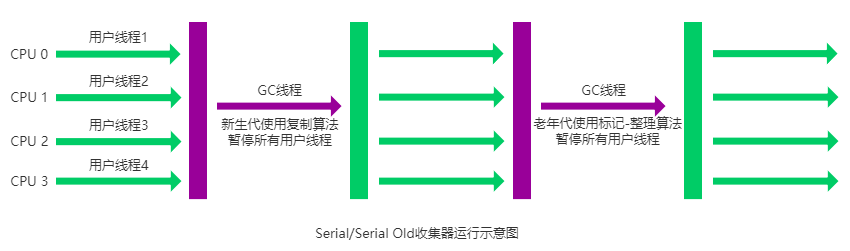 简单而高效(与其他收集器的单线程相比) 。Serial 收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial 收集器对于运行在 Client 模式下的虚拟机来说是个不错的选择。
简单而高效(与其他收集器的单线程相比) 。Serial 收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial 收集器对于运行在 Client 模式下的虚拟机来说是个不错的选择。
ParNew 收集器
是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。
新生代采用标记-复制算法,老年代采用标记-整理算法。
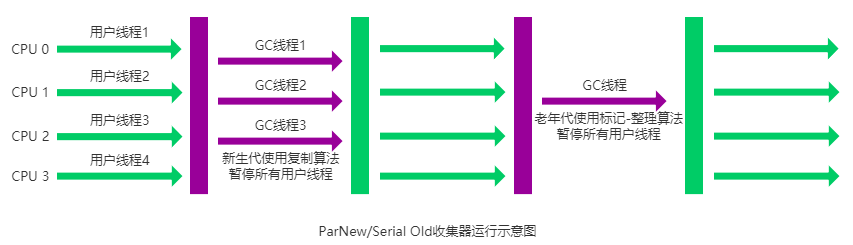
它是许多运行在 Server 模式下的虚拟机的首要选择,除了 Serial 收集器外,只有它能与 CMS 收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
Parallel Scavenge 收集器
使用标记-复制算法的多线程收集器,它看上去几乎和 ParNew 都一样。 那么它有什么特别之处呢?
-XX:+UseParallelGC
使用 Parallel 收集器+ 老年代串行
-XX:+UseParallelOldGC
使用 Parallel 收集器+ 老年代并行
Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。 Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解,手工优化存在困难的时候,使用 Parallel Scavenge 收集器配合自适应调节策略,把内存管理优化交给虚拟机去完成也是一个不错的选择。
新生代采用标记-复制算法,老年代采用标记-整理算法。

这是 JDK1.8 默认收集器
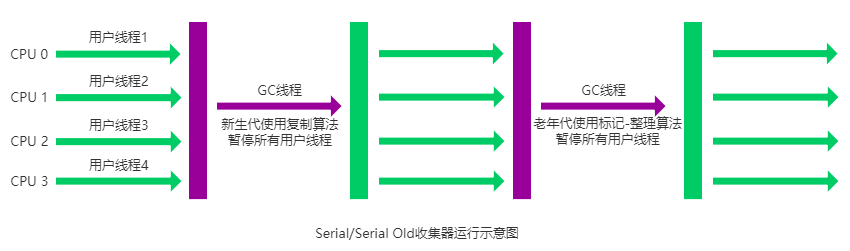
Serial Old 收集器
Serial 收集器的老年代版本,它同样是一个单线程收集器。它主要有两大用途:一种用途是在 JDK1.5 以及以前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途是作为 CMS 收集器的后备方案。
Parallel Old 收集器
Parallel Scavenge 收集器的老年代版本。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
CMS 收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用。
CMS(Concurrent Mark Sweep)收集器是 HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。
从名字中的Mark Sweep这两个词可以看出,CMS 收集器是一种 “标记-清除”算法实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
- 初始标记: 暂停所有的其他线程,并记录下直接与 root 相连的对象,速度很快 ;
- 并发标记: 同时开启 GC 和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以 GC 线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
- 重新标记: 重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
- 并发清除: 开启用户线程,同时 GC 线程开始对未标记的区域做清扫。
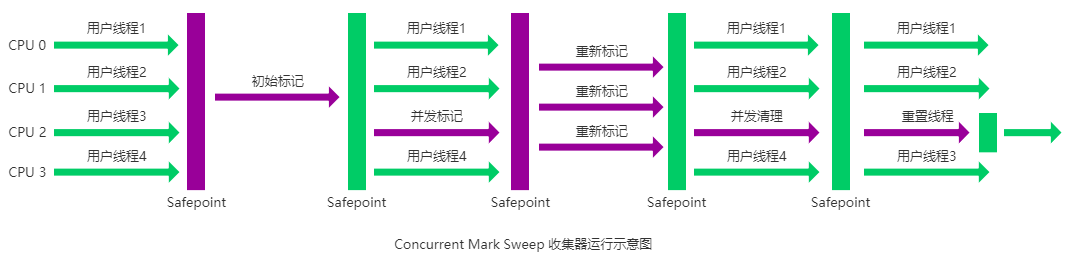
从它的名字就可以看出它是一款优秀的垃圾收集器,主要优点:并发收集、低停顿。但是它有下面三个明显的缺点:
- 对 CPU 资源敏感;
- 无法处理浮动垃圾;
- 它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生。
G1 收集器
G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.
被视为 JDK1.7 中 HotSpot 虚拟机的一个重要进化特征。它具备以下特点:
- 并行与并发:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
- 分代收集:虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但是还是保留了分代的概念。
- 空间整合:与 CMS 的“标记-清除”算法不同,G1 从整体来看是基于“标记-整理”算法实现的收集器;从局部上来看是基于“标记-复制”算法实现的。
- 可预测的停顿:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在垃圾收集上的时间不得超过 N 毫秒。
G1 收集器的运作大致分为以下几个步骤:
- 初始标记
- 并发标记
- 最终标记
- 筛选回收
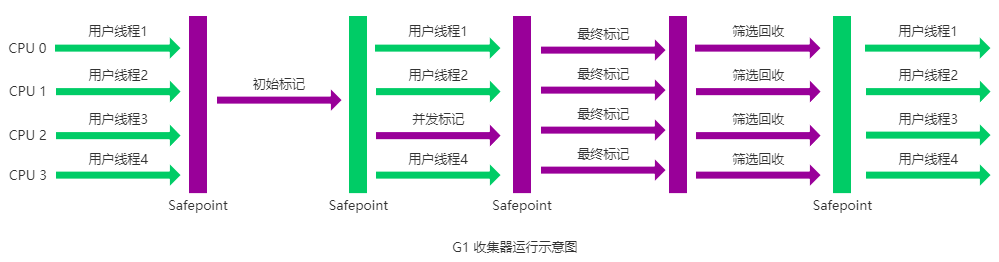
G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的 Region(这也就是它的名字 Garbage-First 的由来) 。这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了 G1 收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
从 JDK9 开始,G1 垃圾收集器成为了默认的垃圾收集器。
ZGC 收集器
与 CMS 中的 ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。
在 ZGC 中出现 Stop The World 的情况会更少!
介绍一下 CMS,G1 收集器。
Minor Gc 和 Full GC 有什么不同呢?
简单总结一下双亲委派模型的执行流程
- 在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载(每个父类加载器都会走一遍这个流程)。
- 类加载器在进行类加载的时候,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成(调用父加载器
loadClass()方法来加载类)。这样的话,所有的请求最终都会传送到顶层的启动类加载器BootstrapClassLoader 中。 - 只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载(调用自己的
findClass() 方法来加载类)。
双亲委派模型的好处
- 避免类被重复加载
- 保证了Java核心API不会被修改
如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 java.lang.Object 类的话,那么程序运行的时候,系统就会出现两个不同的 Object 类。双亲委派模型可以保证加载的是 JRE 里的那个 Object 类,而不是你写的 Object 类。这是因为 AppClassLoader 在加载你的 Object 类时,会委托给 ExtClassLoader 去加载,而 ExtClassLoader 又会委托给 BootstrapClassLoader,BootstrapClassLoader 发现自己已经加载过了 Object 类,会直接返回,不会去加载你写的 Object 类。
打破双亲委派模型的方法
自定义加载器,继承 ClassLoader 。
如果我们不想打破双亲委派模型,就重写 ClassLoader 类中的 findClass() 方法即可,无法被父类加载器加载的类最终会通过这个方法被加载。
但是,如果想打破双亲委派模型则需要重写 loadClass() 方法。
为什么是重写 loadClass() 方法打破双亲委派模型呢?双亲委派模型的执行流程已经解释了:
类加载器在进行类加载的时候,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成(调用父加载器
loadClass()方法来加载类)。
我们比较熟悉的 Tomcat 服务器为了能够优先加载 Web 应用目录下的类,然后再加载其他目录下的类,就自定义了类加载器 WebAppClassLoader 来打破双亲委托机制。这也是 Tomcat 下 Web 应用之间的类实现隔离的具体原理。
JVM 判定两个 Java 类是否相同的具体规则
JVM 不仅要看类的全名是否相同,还要看加载此类的类加载器是否一样。只有两者都相同的情况,才认为两个类是相同的。即使两个类来源于同一个 Class 文件,被同一个虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相同。
数据库
数据库的范式了解吗
- 1NF(第一范式):属性不可再分
- 2NF:1NF基础上,消除了非主属性(所有候选码的属性称为主属性。不包含在任何候选码中的属性称为非主属性或非码属性)对于码(能唯一标识实体的属性,对应表中的列)的部分函数依赖。^(如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号);)^
- 3NF:2NF基础上,消除了非主属性对于码的传递函数依赖^(在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。)^。
数据库的范式是指关系数据库中的关系满足一定的要求,以减少数据冗余和异常。目前有六种范式,分别是第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF)。12
-
第一范式(1NF)要求每个属性都是不可分割的原子值,即数据项不可分。1
-
第二范式(2NF)要求每个非主属性完全函数依赖于任何一个候选码^( 若关系中的某一属性组的值能唯一地标识一个元组,而其子集不能,则称该属性组为候选码。若一个关系中有多个候选码,则选定其中一个为主码)^,即消除了部分函数依赖。1
- 理解: 第二范式是指每个表必须有一个(有且仅有一个)数据项作为关键字或主键(primary key),其他数据项与关键字或者主键一一对应,即其他数据项完全依赖于关键字或主键。由此可知单主属性的关系均属于第二范式。
-
第三范式(3NF)要求每个非主属性既不传递依赖于码,也不部分依赖于码,即消除了传递函数依赖。1
-
巴斯-科德范式(BCNF)要求每个决定因素都包含码,即消除了对非码的函数依赖。1
-
第四范式(4NF)要求消除了非平凡且非函数依赖的多值依赖。1
-
第五范式(5NF)要求表可以分解为较小的表,除非那些表在逻辑上拥有与原始表相同的主键。1
一般来说,数据库只需满足第三范式(3NF)就可以了
为什么不推荐使用外键与级联?
阿里巴巴开发手册:
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
说明: 以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群; 级联更新是强阻塞,存在数据库更新风暴的风 险; 外键影响数据库的插入速度
- 增加了复杂性: a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
- 增加了额外工作:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
- 对分库分表不友好:因为分库分表下外键是无法生效的。
- ......
我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
- 保证了数据库数据的一致性和完整性;
- 级联操作方便,减轻了程序代码量;
- ......
所以说,不要一股脑的就抛弃了外键这个概念,既然它存在就有它存在的道理,如果系统不涉及分库分表,并发量不是很高的情况还是可以考虑使用外键的。
drop、delete 与 truncate 区别?
用法不同
-
drop(丢弃数据):drop table 表名 ,直接将表都删除掉,在删除表的时候使用。 -
truncate (清空数据) :truncate table 表名 ,只删除表中的数据,再插入数据的时候自增长 id 又从 1 开始,在清空表中数据的时候使用。 -
delete(删除数据) :delete from 表名 where 列名=值,删除某一行的数据,如果不加where 子句和truncate table 表名作用类似。
truncate 和不带 where子句的 delete、以及 drop 都会删除表内的数据,但是 truncate 和 delete 只删除数据不删除表的结构(定义),执行 drop 语句,此表的结构也会删除,也就是执行drop 之后对应的表不复存在。
属于不同的数据库语言
truncate 和 drop 属于 DDL(数据定义语言)语句,操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。而 delete 语句是 DML (数据库操作语言)语句,这个操作会放到 rollback segment 中,事务提交之后才生效。
DML 语句和 DDL 语句区别:
- DML 是数据库操作语言(Data Manipulation Language)的缩写,是指对数据库中表记录的操作,主要包括表记录的插入、更新、删除和查询,是开发人员日常使用最频繁的操作。
- DDL (Data Definition Language)是数据定义语言的缩写,简单来说,就是对数据库内部的对象进行创建、删除、修改的操作语言。它和 DML 语言的最大区别是 DML 只是对表内部数据的操作,而不涉及到表的定义、结构的修改,更不会涉及到其他对象。DDL 语句更多的被数据库管理员(DBA)所使用,一般的开发人员很少使用。
另外,由于select不会对表进行破坏,所以有的地方也会把select单独区分开叫做数据库查询语言 DQL(Data Query Language)。
执行速度不同
一般来说:drop > truncate > delete(这个我没有设计测试过)。
-
delete命令执行的时候会产生数据库的binlog日志,而日志记录是需要消耗时间的,但是也有个好处方便数据回滚恢复。 -
truncate命令执行的时候不会产生数据库日志,因此比delete要快。除此之外,还会把表的自增值重置和索引恢复到初始大小等。 -
drop命令会把表占用的空间全部释放掉。
数据库设计通常分为哪几步?
- 需求分析 : 分析用户的需求,包括数据、功能和性能需求。
- 概念结构设计 : 主要采用 E-R 模型进行设计,包括画 E-R 图。
- 逻辑结构设计 : 通过将 E-R 图转换成表,实现从 E-R 模型到关系模型的转换。
- 物理结构设计 : 主要是为所设计的数据库选择合适的存储结构和存取路径。
- 数据库实施 : 包括编程、测试和试运行
- 数据库的运行和维护 : 系统的运行与数据库的日常维护
数据库中使用触发器的优点与缺点
使用触发器的优点:
- SQL 触发器提供了另一种检查数据完整性的方法。
- SQL 触发器可以捕获数据库层中业务逻辑中的错误。
- SQL 触发器提供了另一种运行计划任务的方法。通过使用 SQL 触发器,您不必等待运行计划任务,因为在对表中的数据进行更改之前或之后会自动调用触发器。
- SQL 触发器对于审计表中数据的更改非常有用。
使用触发器的缺点:
- SQL 触发器只能提供扩展验证,并且不能替换所有验证。必须在应用程序层中完成一些简单的验证。例如,您可以使用 JavaScript 在客户端验证用户的输入,或者使用服务器端脚本语言(如 JSP,PHP,ASP.NET,Perl)在服务器端验证用户的输入。
- 从客户端应用程序调用和执行 SQL 触发器是不可见的,因此很难弄清楚数据库层中发生了什么。
- SQL 触发器可能会增加数据库服务器的开销。
MySQL 有什么优点?
- 成熟稳定,功能完善。
- 开源免费。
- 文档丰富,既有详细的官方文档,又有非常多优质文章可供参考学习。
- 开箱即用,操作简单,维护成本低。
- 兼容性好,支持常见的操作系统,支持多种开发语言。
- 社区活跃,生态完善。
- 事务支持优秀, InnoDB 存储引擎默认使用 REPEATABLE-READ 并不会有任何性能损失,并且,InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的。
- 支持分库分表、读写分离、高可用
MYSQL基础架构,由哪几部分组成?
- 连接器: 身份认证和权限相关(登录 MySQL 的时候)。
- 查询缓存: 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
- 分析器: 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
- 优化器: 按照 MySQL 认为最优的方案去执行。
- 执行器: 执行语句,然后从存储引擎返回数据。 执行语句之前会先判断是否有权限,如果没有权限的话,就会报错。
- 插件式存储引擎:主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎
MySQL 存储引擎架构了解吗?
MySQL 存储引擎采用的是 插件式架构 ,支持多种存储引擎,我们甚至可以为不同的数据库表设置不同的存储引擎以适应不同场景的需要。存储引擎是基于表的,而不是数据库。
并且,你还可以根据 MySQL 定义的存储引擎实现标准接口来编写一个属于自己的存储引擎。这些非官方提供的存储引擎可以称为第三方存储引擎,区别于官方存储引擎。像目前最常用的 InnoDB 其实刚开始就是一个第三方存储引擎,后面由于过于优秀,其被 Oracle 直接收购了。
MyISAM 和 InnoDB 有什么区别?
1.是否支持行级锁
MyISAM 只有表级锁(table-level locking),而 InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
2.是否支持事务
MyISAM 不提供事务支持。
InnoDB 提供事务支持,实现了 SQL 标准定义了四个隔离级别,具有提交(commit)和回滚(rollback)事务的能力。并且,InnoDB 默认使用的 REPEATABLE-READ(可重读)隔离级别是可以解决幻读问题发生的(基于 MVCC 和 Next-Key Lock)。
关于 MySQL 事务的详细介绍,可以看看我写的这篇文章:MySQL 事务隔离级别详解。
3.是否支持外键
MyISAM 不支持,而 InnoDB 支持。
外键对于维护数据一致性非常有帮助,但是对性能有一定的损耗。因此,通常情况下,我们是不建议在实际生产项目中使用外键的,在业务代码中进行约束即可!
4.是否支持数据库异常崩溃后的安全恢复
MyISAM 不支持,而 InnoDB 支持。
使用 InnoDB 的数据库在异常崩溃后,数据库重新启动的时候会保证数据库恢复到崩溃前的状态。这个恢复的过程依赖于 redo log 。
5.是否支持 MVCC
MyISAM 不支持,而 InnoDB 支持。
讲真,这个对比有点废话,毕竟 MyISAM 连行级锁都不支持。MVCC 可以看作是行级锁的一个升级,可以有效减少加锁操作,提高性能。
6.索引实现不一样。
虽然 MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是两者的实现方式不太一样。
InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。
详细区别,推荐你看看我写的这篇文章:MySQL 索引详解。
7.性能有差别。
InnoDB 的性能比 MyISAM 更强大,不管是在读写混合模式下还是只读模式下,随着 CPU 核数的增加,InnoDB 的读写能力呈线性增长。MyISAM 因为读写不能并发,它的处理能力跟核数没关系
MySQL 中常见的日志有哪些?
-
错误日志 (error log)
-
二进制日志(bin log)
- 主要记录更改数据库数据的SQL语句
-
一般查询日志 (general query log)
-
慢查询日志 (slow query log)
-
事务日志 (redo log 和 undo log)
- 重做日志、回滚日志
-
中继日志 (relay log)
-
DDL日志 (metadata log)
慢查询日志有什么用?
慢查询日志记录了执行时间超过 long_query_time (默认是 10s)的所有查询,在我们解决 SQL 慢查询(SQL 执行时间过长)问题的时候经常会用到。
开启:
SET GLOBAL slow_query_log=ON
查看:
SHOW VARIABLES LIKE '%long_query_time%'
binlog 主要记录了什么?
主要记录了 MySQL 数据库中数据的所有变化(数据库执行的所有 DDL 和DML 语句)
binlog 有一个比较常⻅的应用场景就是主从复制,MySQL 主从复制依赖于 binlog。另外,常⻅的一些同步 MySQL 数据到其他数据源的工具(比如 canal)的底层一般也是依赖 binlog 。
binlog 通过追加的方式进行写入,大小没有限制。并且,我们可以通过 max_binlog_size 参数设置每个 binlog 文件的最大容量,当文件大小达到给定值之后,会生成新的 binlog 文件来保存日志,不会出现前面写的日志被覆盖的情况
redo log 如何保证事务的持久性?
我们知道 InnoDB 存储引擎是以⻚为单位来管理存储空间的,我们往 MySQL 插入的数据最终都是存在于⻚中的,准确点来说是数据⻚这种类型。为了减少磁盘 IO开销,还有一个叫做 Buffer Pool(缓冲池) 的区域,存在于内存中。当我们的数据对应的⻚不存在于 Buffer Pool 中的话, MySQL 会先将磁盘上的⻚缓存到Buffer Pool 中,这样后面我们直接操作的就是 Buffer Pool 中的⻚,这样大大提高了读写性能。
一个事务提交之后,我们对 Buffer Pool中对应的⻚的修改可能还未持久化到磁盘。这个时候,如果 MySQL 突然宕机的话,这个事务的更改是不是直接就消失了呢?
很显然是不会的,如果是这样的话就明显违反了事务的持久性。
MySQL InnoDB 引擎使用 redo log 来保证事务的持久性。redo log 主要做的事情就是记录⻚的修改,比如某个⻚面某个偏移量处修改了几个字节的值以及具体被修改的内容是什么。redo log 中的每一条记录包含了表空间号、数据⻚号、偏移量、具体修改的数据,甚至还可能会记录修改数据的⻓度(取决于 redo log 类型)。
在事务提交时,我们会将 redo log 按照刷盘策略刷到磁盘上去,这样即使MySQL 宕机了,重启之后也能恢复未能写入磁盘的数据,从而保证事务的持久性。也就是说,redo log 让 MySQL 具备了崩溃回复能力。
不过,我们也要注意设置正确的刷盘策略 innodb_flush_log_at_trx_commit ,根据 MySQL 配置的刷盘策略的不同,MySQL 宕机之后可能会存在轻微的数据丢失问题。
刷盘策略 innodb_flush_log_at_trx_commit 的默认值为 1,设置为 1 的时候才不会丢失任何数据。为了保证事务的持久性,我们必须将其设置为 1。
redo log 采用循环写的方式进行写入,大小固定,当写到结尾时,会回到开头循环写日志,会出现前面写的日志被覆盖的情况
页修改之后为什么不直接刷盘呢?
很多人可能要问了:为什么每次修改Buffer Pool 中的⻚之后不直接刷盘呢?这样不就不需要 redo log 了嘛!
这种方式必然是不行的,性能非常差。最大的问题就是 InnoDB ⻚的大小一般为16KB,而⻚又是磁盘和内存交互的基本单位。这就导致即使我们只修改了⻚中的几个字节数据,一次刷盘操作也需要将16KB 大小的⻚整个都刷新到磁盘中。而且,这些修改的⻚可能并不相邻,也就是说这还是随机 IO。
采用 redo log 的方式就可以避免这种性能问题,因为 redo log 的刷盘性能很好。首先,redo log 的写入属于顺序IO。 其次,一行 redo log 记录只占几十个字节。另外,Buffer Pool 中的⻚(脏⻚)在某些情况下(比如 redo log 快写满了)也会进行刷盘操作。不过,这里的刷盘操作会合并写入,更高效地顺序写入到磁盘
binlog 和 redolog 有什么区别?
- binlog 主要用于数据库还原,属于数据级别的数据恢复,主从复制是binlog 最常⻅的一个应用场景。
redolog 主要用于保证事务的持久性,属于事务级别的数据恢复。 - redolog 属于 InnoDB 引擎特有的,binlog 属于所有存储引擎共有的,因为 binlog 是 MySQL 的 Server 层实现的。
- redolog 属于物理日志,主要记录的是某个⻚的修改。binlog 属于逻辑日志,主要记录的是数据库执行的所有DDL 和 DML 语句。
- binlog 通过追加的方式进行写入,大小没有限制。redo log 采用循环写的方式进行写入,大小固定,当写到结尾时,会回到开头循环写日志
- binlog和redolog的刷盘时机不同,binlog由sync_binlog参数控制,可以设置每次提交事务或者每N个事务才刷盘,而redolog由innodb_flush_log_at_trx_commit参数控制,可以设置每次提交事务、每秒或者不刷盘
undo log 如何保证事务的原子性?
每一个事务对数据的修改都会被记录到undo log ,当执行事务过程中出现错误或者需要执行回滚操作的话,MySQL 可以利用 undo log 将数据恢复到事务开始之前的状态。
undo log 属于逻辑日志,记录的是 SQL语句,比如说事务执行一条 DELETE 语句,那 undo log 就会记录一条相对应的INSERT 语句。
MySQL 的隔离级别是基于锁实现的吗?
MySQL 的隔离级别基于锁和 MVCC 机制共同实现的。
SERIALIZABLE 隔离级别是通过锁来实现的,READ-COMMITTED 和 REPEATABLE-READ 隔离级别是基于 MVCC 实现的。不过, SERIALIZABLE 之外的其他隔离级别可能也需要用到锁机制,就比如 REPEATABLE-READ 在当前读情况下需要使用加锁读来保证不会出现幻读
MVCC 在 MySQL 中实现所依赖的手段主要是: 隐藏字段、read view、undo log。
- undo log : undo log 用于记录某行数据的多个版本的数据。
- read view 和 隐藏字段 : 用来判断当前版本数据的可见性。
表级锁和行级锁了解吗?有什么区别
表级锁和行级锁对比:
- 表级锁: MySQL 中锁定粒度最大的一种锁(全局锁除外),是针对非索引字段加的锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。不过,触发锁冲突的概率最高,高并发下效率极低。表级锁和存储引擎无关,MyISAM 和 InnoDB 引擎都支持表级锁。
- 行级锁: MySQL 中锁定粒度最小的一种锁,是 针对索引字段加的锁 ,只针对当前操作的行记录进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。行级锁和存储引擎有关,是在存储引擎层面实现的。
行级锁的使用有什么注意事项?
InnoDB 的行锁是针对索引字段加的锁,表级锁是针对非索引字段加的锁。当我们执行 UPDATE、DELETE 语句时,如果 WHERE条件中字段没有命中唯一索引或者索引失效的话,就会导致扫描全表对表中的所有行记录进行加锁。这个在我们日常工作开发中经常会遇到,一定要多多注意!!!
InnoDB 有哪几类行锁?
InnoDB 行锁是通过对索引数据页上的记录加锁实现的,MySQL InnoDB 支持三种行锁定方式:
- 记录锁(Record Lock) :也被称为记录锁,属于单个行记录上的锁。
- 间隙锁(Gap Lock) :锁定一个范围,不包括记录本身。
- 临键锁(Next-Key Lock) :Record Lock+Gap Lock,锁定一个范围,包含记录本身,主要目的是为了解决幻读问题(MySQL 事务部分提到过)。记录锁只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁。
在 InnoDB 默认的隔离级别 REPEATABLE-READ 下,行锁默认使用的是 Next-Key Lock。但是,如果操作的索引是唯一索引或主键,InnoDB 会对 Next-Key Lock 进行优化,将其降级为 Record Lock,即仅锁住索引本身,而不是范围
意向锁有什么作用?
意向锁可以快速判断是否可以对某个表使用表锁。
意向锁是表级锁,共有两种:
- 意向共享锁(Intention Shared Lock,IS 锁) :事务有意向对表中的某些记录加共享锁(S 锁),加共享锁前必须先取得该表的 IS 锁。
- 意向排他锁(Intention Exclusive Lock,IX 锁) :事务有意向对表中的某些记录加排他锁(X 锁),加排他锁之前必须先取得该表的 IX 锁。
意向锁是由数据引擎自己维护的,用户无法手动操作意向锁,在为数据行加共享/排他锁之前,InooDB 会先获取该数据行所在在数据表的对应意向锁。
意向锁之间是互相兼容的。
| IS 锁 | IX 锁 | |
|---|---|---|
| IS 锁 | 兼容 | 兼容 |
| IX 锁 | 兼容 | 兼容 |
意向锁和共享锁和排它锁互斥(这里指的是表级别的共享锁和排他锁,意向锁不会与行级的共享锁和排他锁互斥)。
| IS 锁 | IX 锁 | |
|---|---|---|
| S 锁 | 兼容 | 互斥 |
| X 锁 | 互斥 | 互斥 |
当前读和快照读有什么区别?
快照读(一致性非锁定读)就是单纯的 SELECT 语句,但不包括下面这两类 SELECT 语句:
SELECT ... FOR UPDATE
SELECT ... LOCK IN SHARE MODE
快照即记录的历史版本,每行记录可能存在多个历史版本(多版本技术)。
快照读的情况下,如果读取的记录正在执行 UPDATE/DELETE 操作,读取操作不会因此去等待记录上 X 锁的释放,而是会去读取行的一个快照。
只有在事务隔离级别 RC(读取已提交) 和 RR(可重读)下,InnoDB 才会使用一致性非锁定读:
- 在 RC 级别下,对于快照数据,一致性非锁定读总是读取被锁定行的最新一份快照数据。
- 在 RR 级别下,对于快照数据,一致性非锁定读总是读取本事务开始时的行数据版本。
快照读比较适合对于数据一致性要求不是特别高且追求极致性能的业务场景。
当前读 (一致性锁定读)就是给行记录加 X 锁或 S 锁。
当前读的一些常见 SQL 语句类型如下:
# 对读的记录加一个X锁
SELECT...FOR UPDATE
# 对读的记录加一个S锁
SELECT...LOCK IN SHARE MODE
# 对修改的记录加一个X锁
INSERT...
UPDATE...
DELETE...
如何分析 SQL 的性能?
我们可以使用 EXPLAIN 命令来分析 SQL 的 执行计划 。执行计划是指一条 SQL 语句在经过 MySQL 查询优化器的优化会后,具体的执行方式。
EXPLAIN 并不会真的去执行相关的语句,而是通过 查询优化器 对语句进行分析,找出最优的查询方案,并显示对应的信息。
EXPLAIN 适用于 SELECT, DELETE, INSERT, REPLACE, 和 UPDATE语句,我们一般分析 SELECT 查询较多。
我们这里简单来演示一下 EXPLAIN 的使用。
EXPLAIN 的输出格式如下:
mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| 1 | SIMPLE | cus_order | NULL | ALL | NULL | NULL | NULL | NULL | 997572 | 100.00 | Using filesort |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
各个字段的含义如下:
| 列名 | 含义 |
|---|---|
| id | SELECT 查询的序列标识符 |
| select_type | SELECT 关键字对应的查询类型 |
| table | 用到的表名 |
| partitions | 匹配的分区,对于未分区的表,值为 NULL |
| type | 表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际用到的索引 |
| key_len | 所选索引的长度 |
| ref | 当使用索引等值查询时,与索引作比较的列或常量 |
| rows | 预计要读取的行数 |
| filtered | 按表条件过滤后,留存的记录数的百分比 |
| Extra | 附加信息 |
篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:SQL 的执行计划这篇文章。
B树、B+树、Hash和红黑树
B树、B+树、Hash和红黑树是不同的数据结构,它们都可以用于存储和查找数据,但是它们也有各自的特点和适用场景:
- B树是一种平衡的多路查找树,它的每个节点可以有多个关键字和子节点,关键字按照递增的顺序排列,子节点的值在父节点的关键字之间。B树可以减少树的高度,从而提高查找效率。B树主要用于文件系统和数据库中做索引1。
- B+树是B树的一种变形,它的每个非叶子节点只存储关键字,不存储数据,数据都存储在叶子节点中,并且叶子节点之间有一个链表相连。B+树相比B树,可以存储更多的关键字,降低树的高度,而且查询速度更稳定,因为每次查找都要到达叶子节点。B+树也主要用于文件系统和数据库中做索引12。
- Hash是一种将任意长度的输入映射为固定长度的输出的函数,它可以快速地判断两个输入是否相等,或者将输入分配到有限的桶中。Hash可以用于实现散列表,散列表是一种以空间换时间的数据结构,它可以在平均情况下实现常数时间的插入、删除和查找操作。Hash和散列表广泛应用于编程语言中,比如Java中的HashMap3。
- 红黑树是一种自平衡的二叉查找树,它的每个节点有一个颜色属性,红色或者黑色,并且满足以下性质:根节点是黑色的;每个叶子节点是黑色的;如果一个节点是红色的,那么它的两个子节点都是黑色的;从任意节点到其后代叶子节点的简单路径上,均包含相同数目的黑色节点。红黑树可以保证在最坏情况下,查找、插入和删除操作的时间复杂度都是O(logn)。红黑树被广泛应用在C++ STL中,比如map和set,Java中的TreeMap23。
B 树& B+树两者有何异同呢?
- B 树的所有节点既存放键(key) 也存放 数据(data),而 B+树只有叶子节点存放 key 和 data,其他内节点只存放 key。
- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
聚簇索引与非聚簇索引的区别?MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,其实现方式有何不同?
在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。
MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引(非聚集索引) ”。
InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“聚簇索引(聚集索引) ”,而其余的索引都作为 辅助索引 ,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
聚簇索引的优缺点
优点:
- 查询速度非常快:聚簇索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
- 对排序查找和范围查找优化:聚簇索引对于主键的排序查找和范围查找速度非常快。
缺点:
- 依赖于有序的数据:因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
- 更新代价大:如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚簇索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
非聚簇索引介绍
非聚簇索引(Non-Clustered Index)即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
非聚簇索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
非聚簇索引的优缺点
优点:
更新代价比聚簇索引要小 。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的
缺点:
- 依赖于有序的数据:跟聚簇索引一样,非聚簇索引也依赖于有序的数据
- 可能会二次查询(回表) :这应该是非聚簇索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
MySQL 8.x 中实现的索引新特性:
- 隐藏索引:也称为不可见索引,不会被优化器使用,但是仍然需要维护,通常会软删除和灰度发布的场景中使用。主键不能设置为隐藏(包括显式设置或隐式设置)。
- 降序索引:之前的版本就支持通过 desc 来指定索引为降序,但实际上创建的仍然是常规的升序索引。直到 MySQL 8.x 版本才开始真正支持降序索引。另外,在 MySQL 8.x 版本中,不再对 GROUP BY 语句进行隐式排序。
- 函数索引:从 MySQL 8.0.13 版本开始支持在索引中使用函数或者表达式的值,也就是在索引中可以包含函数或者表达式
最左前缀匹配原则
最左前缀匹配原则指的是,在使用联合索引时,MySQL 会根据联合索引中的字段顺序,从左到右依次到查询条件中去匹配
如果查询条件中存在与联合索引中最左侧字段相匹配的字段,则就会使用该字段过滤一批数据,直至联合索引中全部字段匹配完成,或者在执行过程中遇到范围查询(如 > 、 < )才会停止匹配。
对于 >= 、 <= 、BETWEEN、like 前缀匹配的范围查询,并不会停止匹配。所以,我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
索引失效有哪些情况?
- 使用
SELECT * 进行查询; - 创建了组合索引,但查询条件未遵守最左匹配原则;
- 在索引列上进行计算、函数、类型转换等操作;
- 以
% 开头的 LIKE 查询比如like '%abc'; - 查询条件中使用 or,且 or 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
- 发生隐式转换;
Spring事务失效有哪些情况?
binlog日志有哪些记录格式?
binlog 日志有三种格式,可以通过binlog_format参数指定。
- statement
- row
- mixed
指定statement,记录的内容是SQL语句原文,比如执行一条update T set update_time=now() where id=1,记录的内容如下。
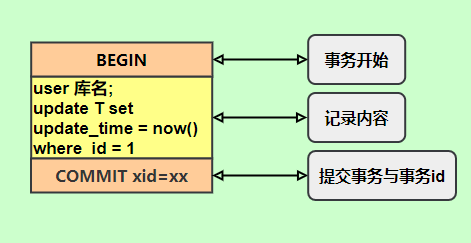
同步数据时,会执行记录的SQL语句,但是有个问题,update_time=now()这里会获取当前系统时间,直接执行会导致与原库的数据不一致。
为了解决这种问题,我们需要指定为row,记录的内容不再是简单的SQL语句了,还包含操作的具体数据,记录内容如下。
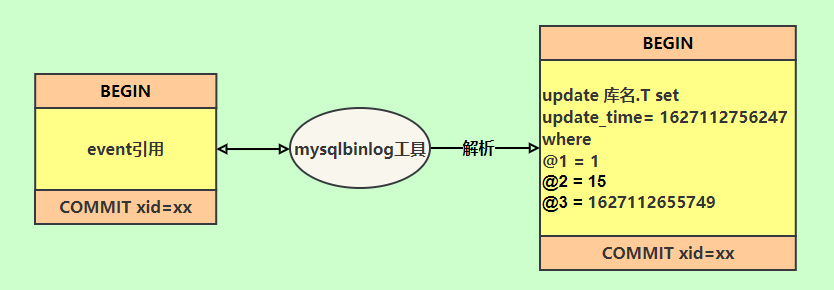
row格式记录的内容看不到详细信息,要通过mysqlbinlog工具解析出来。
update_time=now()变成了具体的时间update_time=1627112756247,条件后面的@1、@2、@3 都是该行数据第 1 个~3 个字段的原始值(假设这张表只有 3 个字段)。
这样就能保证同步数据的一致性,通常情况下都是指定为row,这样可以为数据库的恢复与同步带来更好的可靠性。
但是这种格式,需要更大的容量来记录,比较占用空间,恢复与同步时会更消耗IO资源,影响执行速度。
所以就有了一种折中的方案,指定为mixed,记录的内容是前两者的混合。
MySQL会判断这条SQL语句是否可能引起数据不一致,如果是,就用row格式,否则就用statement格式。
redo log为什么要采用两阶段提交?
在执行语句更新的过程中,会记录redo log与bin log日志,并且redo log与bin log的写入时机不同,redo log在事务执行过程中持续写入,bin log在事务提交时才写入。
因此,如果在记录完redo log后、写bin log之前,mysql发生故障。重启后恢复数据时,会出现redo log与bin log不一致的情况。
为了解决redo log与bin log不一致的情况,InnoDB采用了两阶段提交方案。
将redo log的写入拆分成prepare与commit两个步骤。
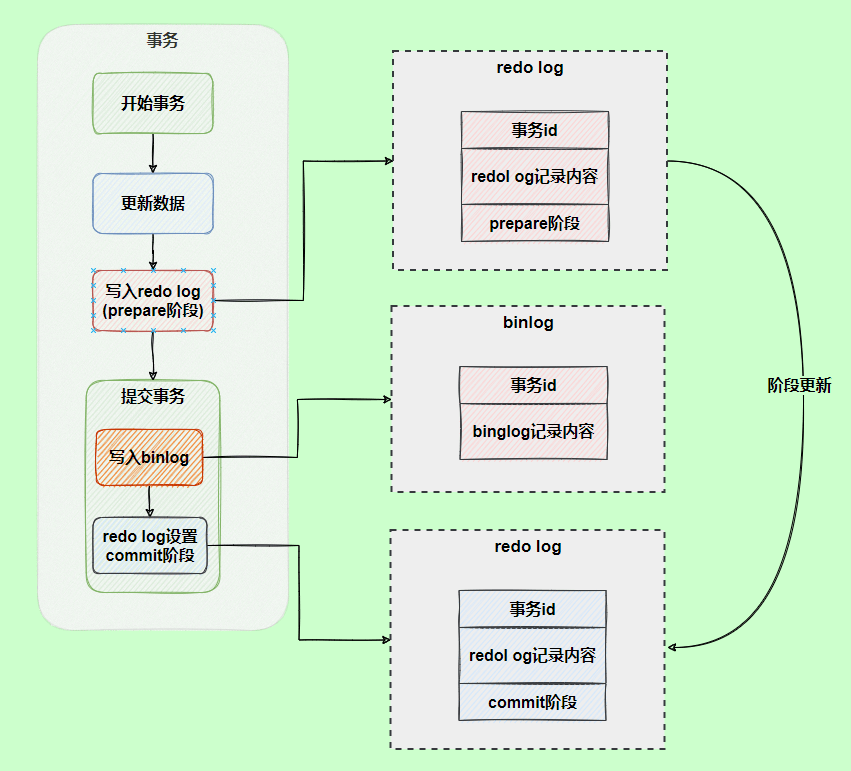
使用两阶段提交后,写入binlog时发生异常也不会有影响,因为MySQL根据redo log日志恢复数据时,发现redo log还处于prepare阶段,并且没有对应binlog日志,就会回滚该事务。
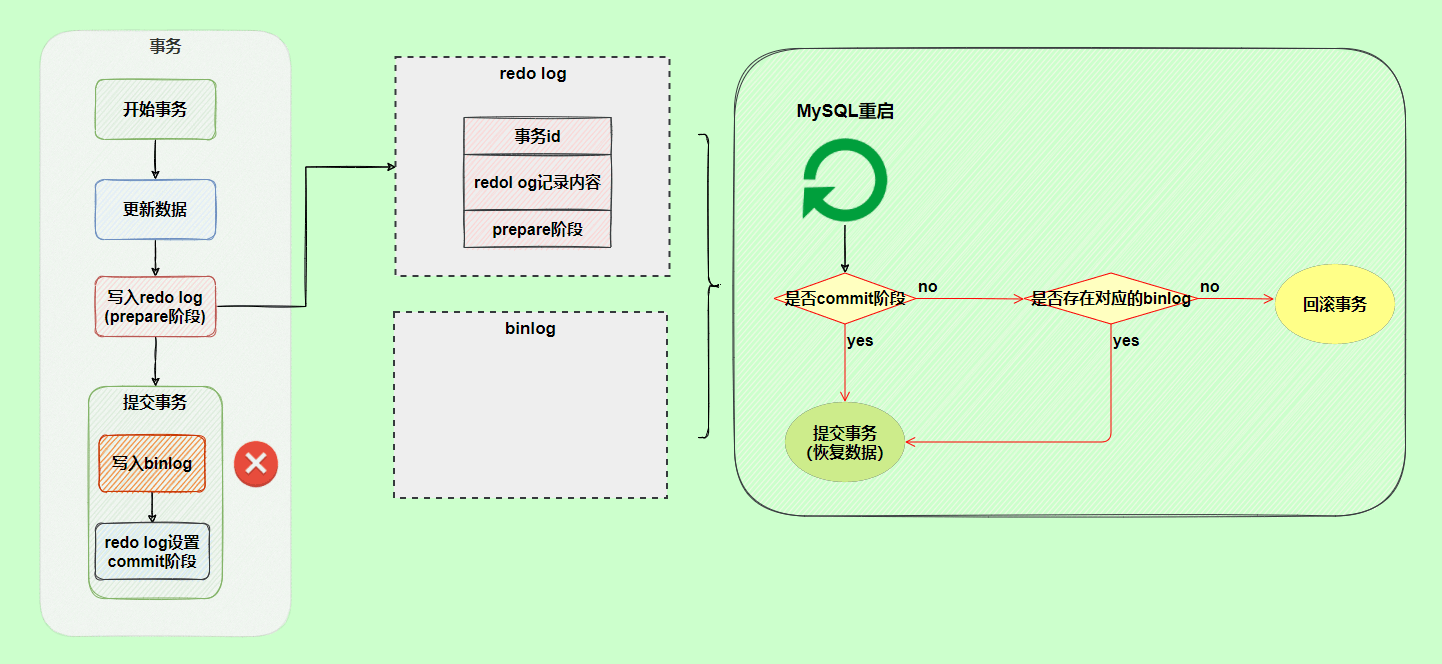
再看一个场景,redo log设置commit阶段发生异常,那会不会回滚事务呢?
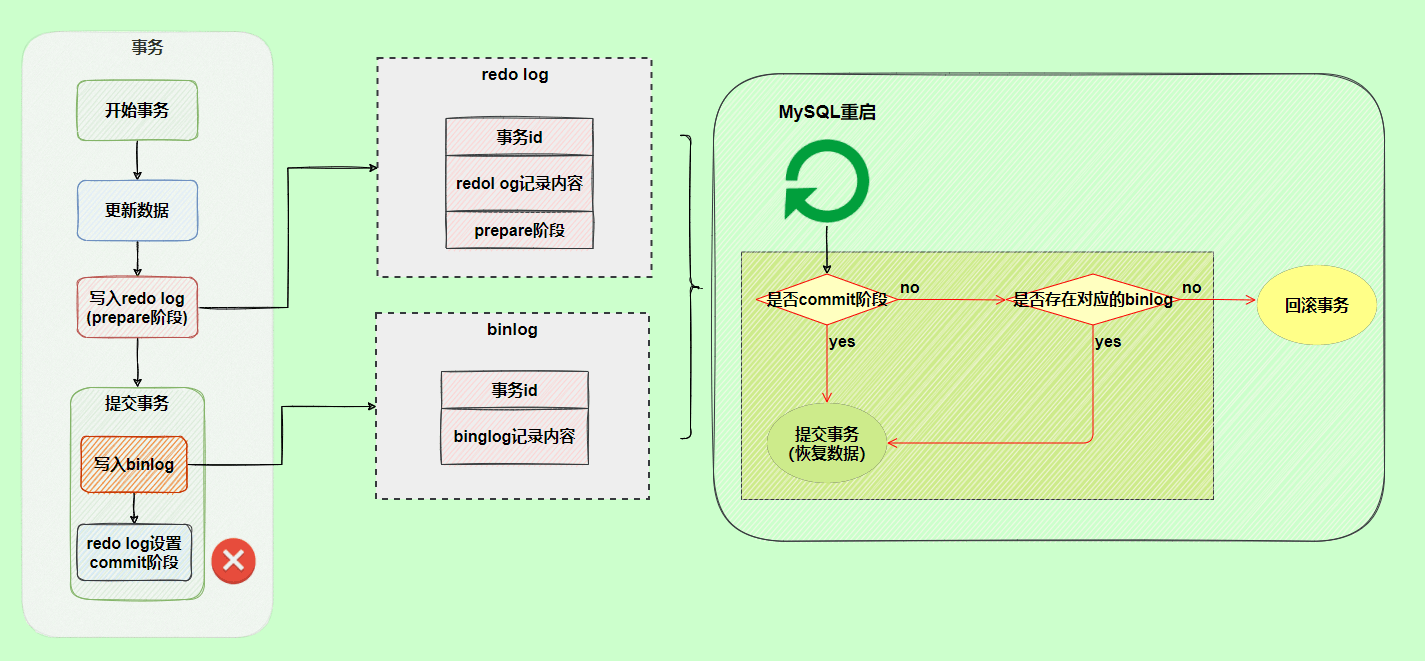
并不会回滚事务,它会执行上图框住的逻辑,虽然redo log是处于prepare阶段,但是能通过事务id找到对应的binlog日志,所以MySQL认为是完整的,就会提交事务恢复数据
undo log日志的作用
- 当事务回滚时用于将数据恢复到修改前的样子
- 另一个作用是
MVCC ,当读取记录时,若该记录被其他事务占用或当前版本对该事务不可见,则可以通过undo log 读取之前的版本数据,以此实现非锁定读
如果想要保证事务的原子性,就需要在异常发生时,对已经执行的操作进行回滚,在 MySQL 中,恢复机制是通过 回滚日志(undo log) 实现的,所有事务进行的修改都会先记录到这个回滚日志中,然后再执行相关的操作。如果执行过程中遇到异常的话,我们直接利用 回滚日志 中的信息将数据回滚到修改之前的样子即可!并且,回滚日志会先于数据持久化到磁盘上。这样就保证了即使遇到数据库突然宕机等情况,当用户再次启动数据库的时候,数据库还能够通过查询回滚日志来回滚将之前未完成的事务。
另外,MVCC 的实现依赖于:隐藏字段、Read View、undo log。在内部实现中,InnoDB 通过数据行的 DB_TRX_ID 和 Read View 来判断数据的可见性,如不可见,则通过数据行的 DB_ROLL_PTR 找到 undo log 中的历史版本。每个事务读到的数据版本可能是不一样的,在同一个事务中,用户只能看到该事务创建 Read View 之前已经提交的修改和该事务本身做的修改
可重复读隔离级别存在什么问题?InnoDB如何解决该问题?
REPEATABLE-READ(可重复读)是不可以防止幻读的。
但是!InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的,主要有下面两种情况:
- 快照读:由 MVCC 机制来保证不出现幻读。
- 当前读:使用 Next-Key Lock 进行加锁来保证不出现幻读,Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的结合,行锁只能锁住已经存在的行,为了避免插入新行,需要依赖间隙锁。
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 READ-COMMITTED ,但是你要知道的是 InnoDB 存储引擎默认使用 REPEATABLE-READ 并不会有任何性能损失。
MVCC➕Next-key-Lock 防止幻读
InnoDB存储引擎在 RR 级别下通过 MVCC和 Next-key Lock 来解决幻读问题:
1、执行普通 select ,此时会以 MVCC 快照读的方式读取数据
在快照读的情况下,RR 隔离级别只会在事务开启后的第一次查询生成 Read View ,并使用至事务提交。所以在生成 Read View 之后其它事务所做的更新、插入记录版本对当前事务并不可见,实现了可重复读和防止快照读下的 “幻读”
2、执行 select...for update/lock in share mode、insert、update、delete 等当前读
在当前读下,读取的都是最新的数据,如果其它事务有插入新的记录,并且刚好在当前事务查询范围内,就会产生幻读!InnoDB 使用 Next-key Lock 来防止这种情况。当执行当前读时,会锁定读取到的记录的同时,锁定它们的间隙,防止其它事务在查询范围内插入数据。只要我不让你插入,就不会发生幻读
窗口函数dense_rank()与rank()的区别
1112. 每位学生的最高成绩
表:Enrollments
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| student_id | int |
| course_id | int |
| grade | int |
+---------------+---------+
(student_id, course_id) 是该表的主键。
编写一个 SQL 查询,查询每位学生获得的最高成绩和它所对应的科目,若科目成绩并列,取 course_id 最小的一门。查询结果需按 student_id 增序进行排序。
select student_id, course_id, grade
from
(select *,
dense_rank() over (partition by student_id order by grade desc, course_id) rk
from enrollments) t
where rk=1
Dense_rank 与rank 的区别
相同点:相同的数值赋予相同的排序
不同点:rank 的排序是不连续的
Dense_rank的排序是连续的
举例子:一组数据 10,10,11,12,13
用rank 排序 1 1 3 4 5。有两个1,没有2。
用dense_rank排序 1 1 2 3 4。有两个1,但是是有2。
计算机网络
TCP/IP网络模型有哪几层?
应用层、传输层、网络层、链路层
-
应用层:应用软件在该层实现。应用层只需要专注于为用户提供应用功能,比如 HTTP、FTP、Telnet、DNS、SMTP等。应用层是工作在操作系统中的用户态,传输层及以下则工作在内核态。
-
传输层:TCP 和 UDP协议在该层。传输层的报文中会携带端口号,因此接收方可以识别出该报文是发送给哪个应用。传输层作为应用间数据传输的媒介,帮助实现应用到应用的通信,而实际的传输功能交给网络层。
- TCP 的全称叫传输控制协议,大部分应用使用的正是 TCP 传输层协议,比如 HTTP 应用层协议。TCP 相比 UDP 多了很多特性,比如流量控制、超时重传、拥塞控制等,这些都是为了保证数据包能可靠地传输给对方。
- UDP :简单到只负责发送数据包,不保证数据包是否能抵达对方,但它实时性相对更好,传输效率也高。当然,UDP 也可以实现可靠传输,把 TCP 的特性在应用层上实现就可以,不过要实现一个商用的可靠 UDP 传输协议,也不是一件简单的事情。
-
网络层:最常使用的是 IP 协议,IP 协议会将传输层的报文作为数据部分,再加上 IP 包头组装成 IP 报文,如果 IP 报文大小超过 MTU(以太网中一般为 1500 字节)就会再次进行分片,得到一个即将发送到网络的 IP 报文。
-
网络接口层:
 网络接口层的传输单位是帧(frame),IP 层的传输单位是包(packet),TCP 层的传输单位是段(segment),HTTP 的传输单位则是消息或报文(message)。
网络接口层的传输单位是帧(frame),IP 层的传输单位是包(packet),TCP 层的传输单位是段(segment),HTTP 的传输单位则是消息或报文(message)。
怎样根据IP地址计算网络地址和主机地址?
对于 IPv4 协议, IP 地址共 32 位,分成了四段(比如,192.168.100.1),每段是 8 位。
IP 地址分成两种意义:
- 一个是网络号,负责标识该 IP 地址是属于哪个「子网」的;
- 一个是主机号,负责标识同一「子网」下的不同主机;
怎么分的呢?这需要配合子网掩码才能算出 IP 地址 的网络号和主机号。
举个例子,比如 10.100.122.0/24,后面的/24表示就是 255.255.255.0 子网掩码,255.255.255.0 二进制是「11111111-11111111-11111111-00000000」,有 24 个1,为了简化子网掩码的表示,用/24代替255.255.255.0。
将 10.100.122.2 和 255.255.255.0 进行按位与运算,就可以得到网络号。
将 255.255.255.0 取反后与IP地址进行进行按位与运算,就可以得到主机号。
键入网址,到显示网页,期间发生了什么?
-
浏览器解析URL,确定web服务器域名和文件名,生成HTTP请求信息。
-
查询服务器域名对应的IP地址:浏览器会先看自身有没有对这个域名的缓存,如果有,就直接返回,如果没有,就去问操作系统,操作系统也会去看自己的缓存,如果有,就直接返回,如果没有,再去 hosts 文件看,也没有,才会去问「本地 DNS 服务器」。
-
通过 DNS 获取到 IP 后,浏览器通过调用Socket库,把 HTTP 的传输工作交给操作系统中的协议栈:TCP、UDP、IP等
-
与服务器建立TCP连接。TCP 报文中的数据部分就是存放 HTTP 头部 + 数据,组装好 TCP 报文之后,就需交给下面的网络层处理。
-
IP 模块将数据封装成IP数据包发送给通信对象。
-
在IP数据包前加上MAC头部,形成网络包
-
网卡驱动获取网络包之后,会将其复制到网卡内的缓存区中,接着会在其开头加上报头和起始帧分界符,在末尾加上用于检测错误的帧校验序列。最后网卡会将包转为电信号,通过网线发送出去。
-
电信号到达网线接口,交换机里的模块进行接收,接下来交换机里的模块将电信号转换为数字信号。然后通过包末尾的
FCS 校验错误,如果没问题则放到缓冲区。交换机的端口不具有 MAC 地址。交换机根据 MAC 地址表查找 MAC 地址,然后将信号发送到相应的端口。如果MAC地址表没有该MAC地址,则将包发送到除了源端口之外的所有端口。 -
网络包经过交换机之后,现在到达了路由器,并在此被转发到下一个路由器或目标设备。
- 路由器是基于 IP 设计的,俗称三层网络设备,路由器的各个端口都具有 MAC 地址和 IP 地址;
- 而交换机是基于以太网设计的,俗称二层网络设备,交换机的端口不具有 MAC 地址。
-
在网络包传输的过程中,源 IP 和目标 IP 始终是不会变的,一直变化的是 MAC 地址,因为需要 MAC 地址在以太网内进行两个设备之间的包传输。
域名解析的流程?
- 客户端首先会发出一个 DNS 请求,问 www.server.com 的 IP 是啥,并发给本地 DNS 服务器(也就是客户端的 TCP/IP 设置中填写的 DNS 服务器地址)。
- 本地域名服务器收到客户端的请求后,如果缓存里的表格能找到 www.server.com,则它直接返回 IP 地址。如果没有,本地 DNS 会去问它的根域名服务器:“老大, 能告诉我 www.server.com 的 IP 地址吗?” 根域名服务器是最高层次的,它不直接用于域名解析,但能指明一条道路。
- 根 DNS 收到来自本地 DNS 的请求后,发现后置是 .com,说:“www.server.com 这个域名归 .com 区域管理”,我给你 .com 顶级域名服务器地址给你,你去问问它吧。”
- 本地 DNS 收到顶级域名服务器的地址后,发起请求
- 顶级域名服务器将负责 www.server.com 区域的权威 DNS 服务器的地址回复给本地DNS
- 本地 DNS 转向询问权威 DNS 服务器。 server.com 的权威 DNS 服务器,它是域名解析结果的原出处。为啥叫权威呢?就是我的域名我做主。
- 权威 DNS 服务器查询后将对应的 IP 地址 X.X.X.X 告诉本地 DNS。
- 本地 DNS 再将 IP 地址返回客户端,客户端和目标建立连接。
七层与四层网络模型?
OSI七层:
- 应用层,负责给应用程序提供统一的接口;
- 表示层,负责把数据转换成兼容另一个系统能识别的格式;
- 会话层,负责建立、管理和终止表示层实体之间的通信会话;
- 传输层,负责端到端的数据传输;
- 网络层,负责数据的路由、转发、分片;
- 数据链路层,负责数据的封帧和差错检测,以及 MAC 寻址;
- 物理层,负责在物理网络中传输数据帧;
TCP/IP 网络模型共有 4 层,分别是应用层、传输层、网络层和网络接口层,每一层负责的职能如下:
- 应用层,负责向用户提供一组应用程序,比如 HTTP、DNS、FTP 等;
- 传输层,负责端到端的通信,比如 TCP、UDP 等;
- 网络层,负责网络包的封装、分片、路由、转发,比如 IP、ICMP 等;
- 网络接口层,负责网络包在物理网络中的传输,比如网络包的封帧、 MAC 寻址、差错检测,以及通过网卡传输网络帧等;
Linux使用TCP发送网络数据时,涉及到几次内存拷贝?
第一次,调用发送数据的系统调用的时候,内核会申请一个内核态的 sk_buff 内存,将用户待发送的数据拷贝到 sk_buff 内存,并将其加入到发送缓冲区。
第二次,在使用 TCP 传输协议的情况下,从传输层进入网络层的时候,每一个 sk_buff 都会被克隆一个新的副本出来。副本 sk_buff 会被送往网络层,等它发送完的时候就会释放掉,然后原始的 sk_buff 还保留在传输层,目的是为了实现 TCP 的可靠传输,等收到这个数据包的 ACK 时,才会释放原始的 sk_buff 。
第三次,当 IP 层发现 sk_buff 大于 MTU 时才需要进行。会再申请额外的 sk_buff,并将原来的 sk_buff 拷贝为多个小的 sk_buff。
HTTP是什么?
HTTP 是超文本传输协议。HTTP 是一个在计算机世界里专门在「两点」之间「传输」文字、图片、音频、视频等「超文本」数据的「约定和规范」。
HTTP 常见的状态码有哪些?

1xx 类状态码属于提示信息,是协议处理中的一种中间状态,实际用到的比较少。
2xx 类状态码表示服务器成功处理了客户端的请求
- 「200 OK」是最常见的成功状态码,表示一切正常。如果是非
HEAD 请求,服务器返回的响应头都会有 body 数据。 - 「204 No Content」也是常见的成功状态码,与 200 OK 基本相同,但响应头没有 body 数据。
- 「206 Partial Content」是应用于 HTTP 分块下载或断点续传,表示响应返回的 body 数据并不是资源的全部,而是其中的一部分,也是服务器处理成功的状态。
3xx 类状态码表示客户端请求需要重定向。
- 「301 Moved Permanently」表示永久重定向,说明请求的资源已经不存在了,需改用新的 URL 再次访问。
- 「302 Found」表示临时重定向,说明请求的资源还在,但暂时需要用另一个 URL 来访问。
301 和 302 都会在响应头里使用字段 Location,指明后续要跳转的 URL,浏览器会自动重定向新的 URL。
- 「304 Not Modified」不具有跳转的含义,表示资源未修改,重定向已存在的缓冲文件,也称缓存重定向,也就是告诉客户端可以继续使用缓存资源,用于缓存控制。
4xx 类状态码表示客户端发送的报文有误,服务器无法处理,也就是错误码的含义。
- 「400 Bad Request」表示客户端请求的报文有错误,但只是个笼统的错误。
- 「403 Forbidden」表示服务器禁止访问资源,并不是客户端的请求出错。
- 「404 Not Found」表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端。
5xx 类状态码表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码。
- 「500 Internal Server Error」与 400 类型,是个笼统通用的错误码,服务器发生了什么错误,我们并不知道。
- 「501 Not Implemented」表示客户端请求的功能还不支持,类似“即将开业,敬请期待”的意思。
- 「502 Bad Gateway」通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。
- 「503 Service Unavailable」表示服务器当前很忙,暂时无法响应客户端,类似“网络服务正忙,请稍后重试”的意思。
计算机的主要端口及对应的服务
计算机的主要端口及对应的服务有以下几种:
- 端口号为21的是FTP(文件传输协议) ,用于在计算机之间传输文件。
- 端口号为22的是SSH(安全外壳协议) ,用于在计算机之间进行安全的远程登录和命令执行。
- 端口号为23的是Telnet(远程登录协议) ,用于在计算机之间进行不安全的远程登录和命令执行。
- 端口号为25的是SMTP(简单邮件传输协议) ,用于在计算机之间发送和接收电子邮件。
- 端口号为53的是DNS(域名系统) ,用于将域名解析为IP地址。
- 端口号为80的是HTTP(超文本传输协议) ,用于在计算机之间传输网页和其他资源。
- 端口号为110的是POP3(邮局协议版本3) ,用于从邮件服务器下载电子邮件到本地计算机。
- 端口号为143的是IMAP(互联网消息访问协议) ,用于从邮件服务器访问和管理电子邮件。
- 端口号为443的是HTTPS(超文本传输安全协议) ,用于在计算机之间传输加密和认证的网页和其他资源。
操作系统
数据结构
算法
Maven
Maven 的主要作用主要有哪些?
- 项目构建:提供标准的、跨平台的自动化项目构建方式。
- 依赖管理:方便快捷的管理项目依赖的资源(jar 包),避免资源间的版本冲突问题。
- 统一开发结构:提供标准的、统一的项目结构。
Maven有哪些依赖范围
classpath 用于指定 .class 文件存放的位置,类加载器会从该路径中加载所需的 .class 文件到内存中。
Maven 在编译、执行测试、实际运行有着三套不同的 classpath:
- 编译 classpath:编译主代码有效
- 测试 classpath:编译、运行测试代码有效
- 运行 classpath:项目运行时有效
Maven 的依赖范围如下:
- compile:编译依赖范围(默认),使用此依赖范围对于编译、测试、运行三种都有效,即在编译、测试和运行的时候都要使用该依赖 Jar 包。
- test:测试依赖范围,从字面意思就可以知道此依赖范围只能用于测试,而在编译和运行项目时无法使用此类依赖,典型的是 JUnit,它只用于编译测试代码和运行测试代码的时候才需要。
- provided:此依赖范围,对于编译和测试有效,而对运行时无效。比如
servlet-api.jar 在 Tomcat 中已经提供了,我们只需要的是编译期提供而已。 - runtime:运行时依赖范围,对于测试和运行有效,但是在编译主代码时无效,典型的就是 JDBC 驱动实现。
- system:系统依赖范围,使用 system 范围的依赖时必须通过 systemPath 元素显示地指定依赖文件的路径,不依赖 Maven 仓库解析,所以可能会造成建构的不可移植。
maven依赖冲突的解决方法
-
类型相同但是版本不同的依赖,只会引入后一个声明的依赖
-
当同一个项目的两个依赖同时引入了某个依赖时:
-
最短路径优先:
-
依赖链路一:A -> B -> C -> X(1.0) // dist = 3 依赖链路二:A -> D -> X(2.0) // dist = 2依赖链路二的路径最短,因此,X(2.0)会被解析使用。当路径长度相同时:
-
-
声明顺序优先:
- 在依赖路径长度相等的前提下,在
pom.xml 中依赖声明的顺序决定了谁会被解析使用,顺序最前的那个依赖优胜。如果 B 的依赖声明在 D 之前,那么 B就会被解析使用。
- 在依赖路径长度相等的前提下,在
-
Spring
Spring,Spring MVC,Spring Boot 之间什么关系?
-
Spring 包含了多个功能模块,其中最重要的是 Spring-Core(主要提供 IoC 依赖注入功能的支持) 模块, Spring 中的其他模块(比如 Spring MVC)的功能实现基本都需要依赖于该模块。
-
Spring MVC 是 Spring 中的一个很重要的模块,主要赋予 Spring 快速构建 MVC 架构的 Web 程序的能力。MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。
-
使用 Spring 进行开发各种配置过于麻烦比如开启某些 Spring 特性时,需要用 XML 或 Java 进行显式配置。于是,Spring Boot 诞生了!
Spring 旨在简化 J2EE 企业应用程序开发、简化 Spring 开发(减少配置文件,开箱即用!)。
Spring Boot 只是简化了配置,如果你需要构建 MVC 架构的 Web 程序,你还是需要使用 Spring MVC 作为 MVC 框架,只是说 Spring Boot 帮你简化了 Spring MVC 的很多配置,真正做到开箱即用!
谈谈自己对于 Spring IoC 的了解
IoC(Inversion of Control:控制反转) 是一种设计思想,而不是一个具体的技术实现。
IoC 的思想就是将原本在程序中手动创建对象的控制权,交由 Spring 框架来管理。不过, IoC 并非 Spring 特有,在其他语言中也有应用。
将对象之间的相互依赖关系交给 IoC 容器来管理,并由 IoC 容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。 IoC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。
在 Spring 中, IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器实际上就是个 Map(key,value),Map 中存放的是各种对象。
Spring 时代我们一般通过 XML 文件来配置 Bean,后来开发人员觉得 XML 文件来配置不太好,于是 SpringBoot 注解配置就慢慢开始流行起来。
什么是 Spring Bean?
Bean 代指的就是那些被 IoC 容器所管理的对象。
可以通过XML 文件、注解或者 Java 配置类来定义bean
将一个类声明为 Bean 的注解有哪些?
-
@Component:通用的注解,可标注任意类为Spring 组件。如果一个 Bean 不知道属于哪个层,可以使用@Component 注解标注。 -
@Repository : 对应持久层即 Dao 层,主要用于数据库相关操作。 -
@Service : 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao 层。 -
@Controller : 对应 Spring MVC 控制层,主要用于接受用户请求并调用Service 层返回数据给前端页面
@Component 和 @Bean 的区别是什么?
-
@Component 注解作用于类,而@Bean注解作用于方法。 -
@Component通常是通过类路径扫描来自动侦测以及自动装配到 Spring 容器中(我们可以使用@ComponentScan 注解定义要扫描的路径从中找出标识了需要装配的类自动装配到 Spring 的 bean 容器中)。@Bean 注解通常是我们在标有该注解的方法中定义产生这个 bean,@Bean告诉了 Spring 这是某个类的实例,当我需要用它的时候还给我。 -
@Bean 注解比@Component 注解的自定义性更强,而且很多地方我们只能通过@Bean 注解来注册 bean。比如当我们引用第三方库中的类需要装配到Spring容器时,则只能通过@Bean来实现。
@Bean注解使用示例:
@Configuration
public class AppConfig {
@Bean
public TransferService transferService() {
return new TransferServiceImpl();
}
}
上面的代码相当于下面的 xml 配置
<beans>
<bean id="transferService" class="com.acme.TransferServiceImpl"/>
</beans>
下面这个例子是通过 @Component 无法实现的。
@Bean
public OneService getService(status) {
case (status) {
when 1:
return new serviceImpl1();
when 2:
return new serviceImpl2();
when 3:
return new serviceImpl3();
}
}
注入 Bean 的注解有哪些?
Spring 内置的 @Autowired 以及 JDK 内置的 @Resource 和 @Inject 都可以用于注入 Bean。
@Autowired 和 @Resource 的区别是什么?
Autowired 属于 Spring 内置的注解,默认的注入方式为byType(根据类型进行匹配),也就是说会优先根据接口类型去匹配并注入 Bean (接口的实现类)。
这会有什么问题呢? 当一个接口存在多个实现类的话,byType这种方式就无法正确注入对象了,因为这个时候 Spring 会同时找到多个满足条件的选择,默认情况下它自己不知道选择哪一个。
这种情况下,注入方式会变为 byName(根据名称进行匹配),这个名称通常就是类名(首字母小写)。就比如说下面代码中的 smsService 就是我这里所说的名称,这样应该比较好理解了吧。
// smsService 就是我们上面所说的名称
@Autowired
private SmsService smsService;
举个例子,SmsService 接口有两个实现类: SmsServiceImpl1和 SmsServiceImpl2,且它们都已经被 Spring 容器所管理。
// 报错,byName 和 byType 都无法匹配到 bean
@Autowired
private SmsService smsService;
// 正确注入 SmsServiceImpl1 对象对应的 bean
@Autowired
private SmsService smsServiceImpl1;
// 正确注入 SmsServiceImpl1 对象对应的 bean
// smsServiceImpl1 就是我们上面所说的名称
@Autowired
@Qualifier(value = "smsServiceImpl1")
private SmsService smsService;
我们还是建议通过 @Qualifier 注解来显式指定名称而不是依赖变量的名称。
@Resource属于 JDK 提供的注解,默认注入方式为 byName。如果无法通过名称匹配到对应的 Bean 的话,注入方式会变为byType。
@Resource 有两个比较重要且日常开发常用的属性:name(名称)、type(类型)。
public @interface Resource {
String name() default "";
Class<?> type() default Object.class;
}
如果仅指定 name 属性则注入方式为byName,如果仅指定type属性则注入方式为byType,如果同时指定name 和type属性(不建议这么做)则注入方式为byType+byName。
// 报错,byName 和 byType 都无法匹配到 bean
@Resource
private SmsService smsService;
// 正确注入 SmsServiceImpl1 对象对应的 bean
@Resource
private SmsService smsServiceImpl1;
// 正确注入 SmsServiceImpl1 对象对应的 bean(比较推荐这种方式)
@Resource(name = "smsServiceImpl1")
private SmsService smsService;
简单总结一下:
-
@Autowired 是 Spring 提供的注解,@Resource 是 JDK 提供的注解。 -
Autowired 默认的注入方式为byType(根据类型进行匹配),@Resource默认注入方式为byName(根据名称进行匹配)。 - 当一个接口存在多个实现类的情况下,
@Autowired 和@Resource都需要通过名称才能正确匹配到对应的 Bean。Autowired 可以通过@Qualifier 注解来显式指定名称,@Resource可以通过name 属性来显式指定名称。
Bean 的作用域有哪些?
Spring 中 Bean 的作用域通常有下面几种:
- singleton : IoC 容器中只有唯一的 bean 实例。Spring 中的 bean 默认都是单例的,是对单例设计模式的应用。
- prototype : 每次获取都会创建一个新的 bean 实例。也就是说,连续
getBean() 两次,得到的是不同的 Bean 实例。 - request (仅 Web 应用可用): 每一次 HTTP 请求都会产生一个新的 bean(请求 bean),该 bean 仅在当前 HTTP request 内有效。
- session (仅 Web 应用可用) : 每一次来自新 session 的 HTTP 请求都会产生一个新的 bean(会话 bean),该 bean 仅在当前 HTTP session 内有效。
- application/global-session (仅 Web 应用可用):每个 Web 应用在启动时创建一个 Bean(应用 Bean),该 bean 仅在当前应用启动时间内有效。
- websocket (仅 Web 应用可用):每一次 WebSocket 会话产生一个新的 bean。
如何配置 bean 的作用域呢?
xml 方式:
<bean id="..." class="..." scope="singleton"></bean>
注解方式:
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public Person personPrototype() {
return new Person();
}
单例 Bean 的线程安全问题了解吗?
单例 Bean 存在线程问题,主要是因为当多个线程操作同一个对象的时候是存在资源竞争的。
常见的有两种解决办法:
- 在 Bean 中尽量避免定义可变的成员变量。
- 在类中定义一个
ThreadLocal 成员变量,将需要的可变成员变量保存在ThreadLocal 中(推荐的一种方式)。
不过,大部分 Bean 实际都是无状态(没有实例变量)的(比如 Dao、Service),这种情况下, Bean 是线程安全的。
((20221116113507-5ux9blp "Bean 的生命周期"))了解么?
- Bean 容器找到配置文件中 Spring Bean 的定义。
- Bean 容器利用 Java Reflection API 创建一个 Bean 的实例。
- 如果涉及到一些属性值 利用
set()方法设置一些属性值。 - 如果 Bean 实现了
BeanNameAware 接口,调用setBeanName()方法,传入 Bean 的名字。 - 如果 Bean 实现了
BeanClassLoaderAware 接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。 - 如果 Bean 实现了
BeanFactoryAware 接口,调用setBeanFactory()方法,传入BeanFactory对象的实例。 - 与上面的类似,如果实现了其他
*.Aware接口,就调用相应的方法。 - 如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor 对象,执行postProcessBeforeInitialization() 方法 - 如果 Bean 实现了
InitializingBean接口,执行afterPropertiesSet()方法。 - 如果 Bean 在配置文件中的定义包含 init-method 属性,执行指定的方法。
- 如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor 对象,执行postProcessAfterInitialization() 方法 - 当要销毁 Bean 的时候,如果 Bean 实现了
DisposableBean 接口,执行destroy() 方法。 - 当要销毁 Bean 的时候,如果 Bean 在配置文件中的定义包含 destroy-method 属性,执行指定的方法。
图示:
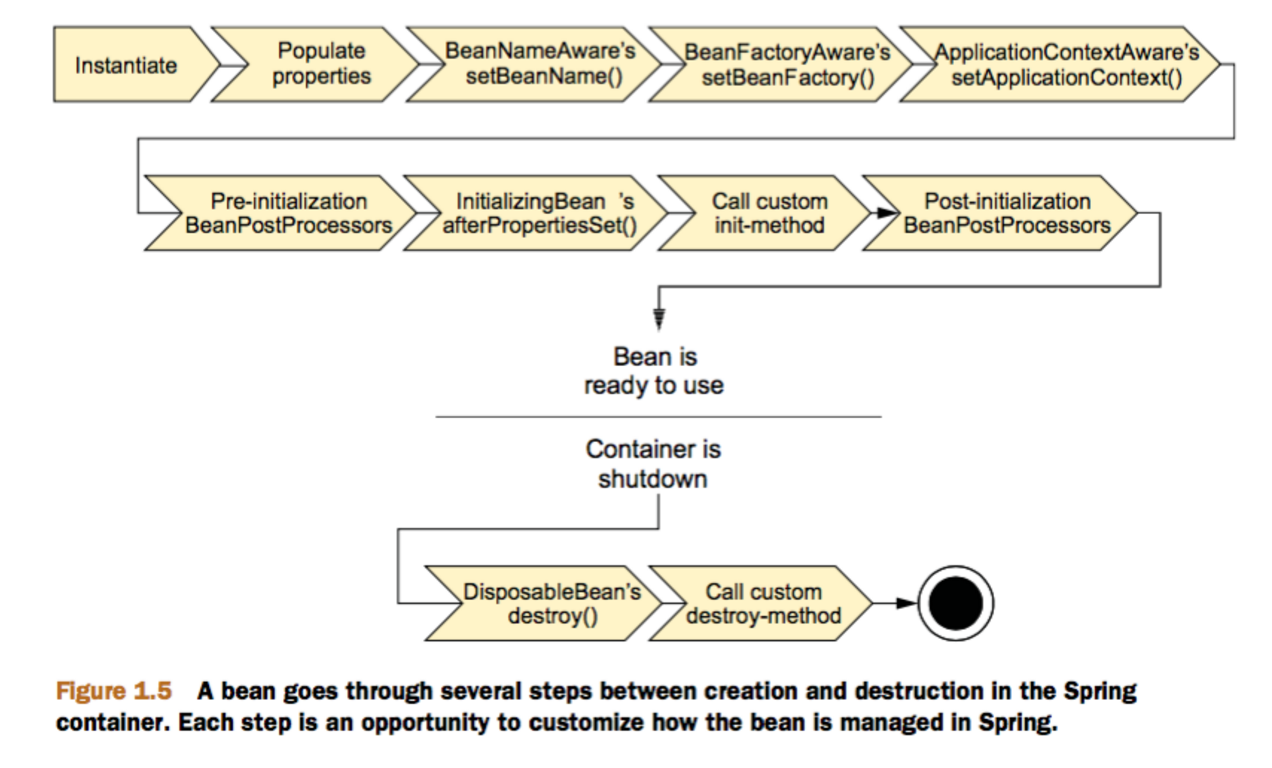
Spring Bean 生命周期
与之比较类似的中文版本:
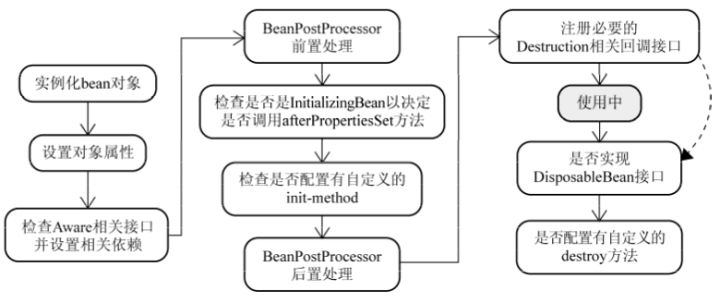
Spring Bean 生命周期
谈谈自己对于 AOP 的了解
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
Spring AOP 是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理,如下图所示:
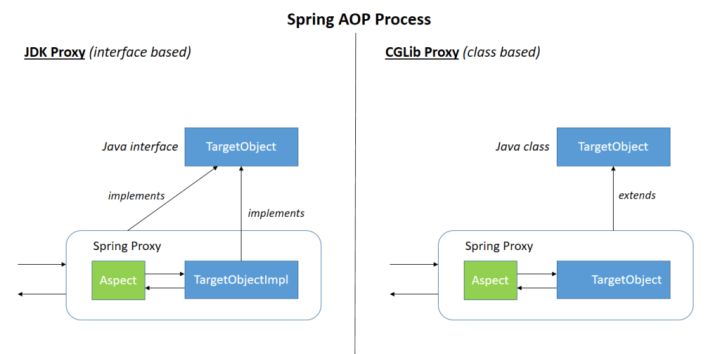
当然你也可以使用 AspectJ !Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了
AOP 切面编程设计到的一些专业术语:
| 术语 | 含义 |
|---|---|
| 目标(Target) | 被通知的对象 |
| 代理(Proxy) | 向目标对象应用通知之后创建的代理对象 |
| 连接点(JoinPoint) | 目标对象的所属类中,定义的所有方法均为连接点 |
| 切入点(Pointcut) | 被切面拦截 / 增强的连接点(切入点一定是连接点,连接点不一定是切入点) |
| 通知(Advice) | 增强的逻辑 / 代码,也即拦截到目标对象的连接点之后要做的事情 |
| 切面(Aspect) | 切入点(Pointcut)+通知(Advice) |
| Weaving(织入) | 将通知应用到目标对象,进而生成代理对象的过程动作 |
Spring AOP 和 AspectJ AOP 有什么区别?
Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。
Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation)。
Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。AspectJ 相比于 Spring AOP 功能更加强大,但是 Spring AOP 相对来说更简单,
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比 Spring AOP 快很多。
AspectJ 定义的通知类型有哪些?
- Before(前置通知):目标对象的方法调用之前触发
- After (后置通知):目标对象的方法调用之后触发
- AfterReturning(返回通知):目标对象的方法调用完成,在返回结果值之后触发
- AfterThrowing(异常通知):目标对象的方法运行中抛出 / 触发异常后触发。AfterReturning 和 AfterThrowing 两者互斥。如果方法调用成功无异常,则会有返回值;如果方法抛出了异常,则不会有返回值。
- Around (环绕通知):编程式控制目标对象的方法调用。环绕通知是所有通知类型中可操作范围最大的一种,因为它可以直接拿到目标对象,以及要执行的方法,所以环绕通知可以任意的在目标对象的方法调用前后搞事,甚至不调用目标对象的方法
多个切面的执行顺序如何控制?
1、通常使用@Order 注解直接定义切面顺序
// 值越小优先级越高
@Order(3)
@Component
@Aspect
public class LoggingAspect implements Ordered {
2、实现Ordered 接口重写 getOrder 方法。
@Component
@Aspect
public class LoggingAspect implements Ordered {
// ....
@Override
public int getOrder() {
// 返回值越小优先级越高
return 1;
}
}
说说自己对于 Spring MVC 了解?
MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。
MVC 是一种设计模式,Spring MVC 是一款很优秀的 MVC 框架。Spring MVC 可以帮助我们进行更简洁的 Web 层的开发,并且它天生与 Spring 框架集成。Spring MVC 下我们一般把后端项目分为 Service 层(处理业务)、Dao 层(数据库操作)、Entity 层(实体类)、Controller 层(控制层,返回数据给前台页面)。
Spring MVC 的核心组件有哪些?
记住了下面这些组件,也就记住了 SpringMVC 的工作原理。
-
DispatcherServlet:核心的中央处理器,负责接收请求、分发,并给予客户端响应。 -
HandlerMapping:处理器映射器,根据 uri 去匹配查找能处理的Handler ,并会将请求涉及到的拦截器和Handler 一起封装。 -
HandlerAdapter:处理器适配器,根据HandlerMapping 找到的Handler ,适配执行对应的Handler; -
Handler:请求处理器,处理实际请求的处理器。 -
ViewResolver:视图解析器,根据Handler 返回的逻辑视图 / 视图,解析并渲染真正的视图,并传递给DispatcherServlet 响应客户端
SpringMVC 工作原理了解吗?
Spring MVC 原理如下图所示:
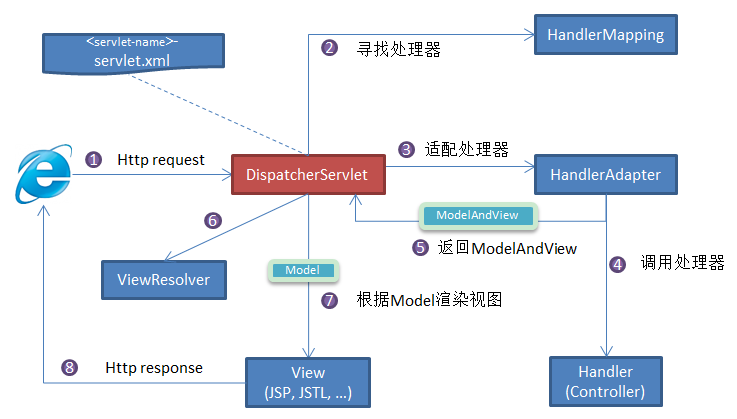
流程说明(重要):
- 客户端(浏览器)发送请求,
DispatcherServlet拦截请求。 -
DispatcherServlet 根据请求信息调用HandlerMapping 。HandlerMapping 根据 uri 去匹配查找能处理的Handler(也就是我们平常说的Controller 控制器) ,并会将请求涉及到的拦截器和Handler 一起封装。 -
DispatcherServlet 调用HandlerAdapter适配执行Handler 。 -
Handler 完成对用户请求的处理后,会返回一个ModelAndView 对象给DispatcherServlet,ModelAndView 顾名思义,包含了数据模型以及相应的视图的信息。Model 是返回的数据对象,View 是个逻辑上的View。 -
ViewResolver 会根据逻辑View 查找实际的View。 -
DispaterServlet 把返回的Model 传给View(视图渲染)。 - 把
View 返回给请求者(浏览器)
url和uri的区别
URL(Uniform Resource Locator)是统一资源定位符,是一种用于定位互联网上资源的地址,比如网页、图片、视频、文件等。URL包含了一个协议类型(比如http、ftp、mailto等)、服务器名、路径和文件名等信息,例如: http://www.example.com/index.html 。
URI(Uniform Resource Identifier)是统一资源标识符,是一个用于标识抽象或物理资源的字符串名称,包括URL和URN两种形式。URI只是资源的标识符,并没有具体指向该资源的路径,例如:urn:isbn:9781449331818。
因此,URL是URI的一种特殊形式,可以通过URL访问到实际资源或文件,而URI只是对资源的标识符
统一异常处理怎么做?
推荐使用注解的方式统一异常处理,具体会使用到 @ControllerAdvice + @ExceptionHandler 这两个注解 。
@ControllerAdvice
@ResponseBody
public class GlobalExceptionHandler {
@ExceptionHandler(BaseException.class)
public ResponseEntity<?> handleAppException(BaseException ex, HttpServletRequest request) {
//......
}
@ExceptionHandler(value = ResourceNotFoundException.class)
public ResponseEntity<ErrorReponse> handleResourceNotFoundException(ResourceNotFoundException ex, HttpServletRequest request) {
//......
}
}
这种异常处理方式下,会给所有或者指定的 Controller 织入异常处理的逻辑(AOP),当 Controller 中的方法抛出异常的时候,由被@ExceptionHandler 注解修饰的方法进行处理。
ExceptionHandlerMethodResolver 中 getMappedMethod 方法决定了异常具体被哪个被 @ExceptionHandler 注解修饰的方法处理异常。
@Nullable
private Method getMappedMethod(Class<? extends Throwable> exceptionType) {
List<Class<? extends Throwable>> matches = new ArrayList<>();
//找到可以处理的所有异常信息。mappedMethods 中存放了异常和处理异常的方法的对应关系
for (Class<? extends Throwable> mappedException : this.mappedMethods.keySet()) {
if (mappedException.isAssignableFrom(exceptionType)) {
matches.add(mappedException);
}
}
// 不为空说明有方法处理异常
if (!matches.isEmpty()) {
// 按照匹配程度从小到大排序
matches.sort(new ExceptionDepthComparator(exceptionType));
// 返回处理异常的方法
return this.mappedMethods.get(matches.get(0));
}
else {
return null;
}
}
从源代码看出:getMappedMethod() 会首先找到可以匹配处理异常的所有方法信息,然后对其进行从小到大的排序,最后取最小的那一个匹配的方法(即匹配度最高的那个)
Spring 框架中用到了哪些设计模式?
关于下面这些设计模式的详细介绍,可以看我写的 Spring 中的设计模式详解open in new window 这篇文章。
- 工厂设计模式 : Spring 使用工厂模式通过
BeanFactory、ApplicationContext 创建 bean 对象。 - 代理设计模式 : Spring AOP 功能的实现。
- 单例设计模式 : Spring 中的 Bean 默认都是单例的。
- 模板方法模式 : Spring 中
jdbcTemplate、hibernateTemplate 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。 - 包装器设计模式 : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
- 观察者模式: Spring 事件驱动模型就是观察者模式很经典的一个应用。
- 适配器模式 : Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配
Controller。
Spring 事务中哪几种事务传播行为?
事务传播行为是为了解决业务层方法之间互相调用的事务问题。
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。
正确的事务传播行为可能的值如下:
1.TransactionDefinition.PROPAGATION_REQUIRED
使用的最多的一个事务传播行为,我们平时经常使用的@Transactional注解默认使用就是这个事务传播行为。如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
2.TransactionDefinition.PROPAGATION_REQUIRES_NEW
创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,Propagation.REQUIRES_NEW修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
3.TransactionDefinition.PROPAGATION_NESTED
如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
4.TransactionDefinition.PROPAGATION_MANDATORY
如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)这个使用的很少。
若是错误的配置以下 3 种事务传播行为,事务将不会发生回滚:
-
TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。 -
TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。 -
TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常
Spring 事务中的隔离级别有哪几种?
-
TransactionDefinition.ISOLATION_DEFAULT :使用后端数据库默认的隔离级别,MySQL 默认采用的REPEATABLE_READ 隔离级别, Oracle 默认采用的READ_COMMITTED 隔离级别. -
TransactionDefinition.ISOLATION_READ_UNCOMMITTED :最低的隔离级别,使用这个隔离级别很少,因为它允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读 -
TransactionDefinition.ISOLATION_READ_COMMITTED : 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生 -
TransactionDefinition.ISOLATION_REPEATABLE_READ : 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。 -
TransactionDefinition.ISOLATION_SERIALIZABLE : 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别
@Transactional(rollbackFor = Exception.class)注解了解吗?
在 @Transactional 注解中如果不配置rollbackFor属性,那么事务只会在遇到RuntimeException的时候才会回滚,加上 rollbackFor=Exception.class,可以让事务在遇到非运行时异常时也回滚
Exception 分为运行时异常 RuntimeException 和非运行时异常。事务管理对于企业应用来说是至关重要的,即使出现异常情况,它也可以保证数据的一致性。
当 @Transactional 注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。如果类或者方法加了这个注解,那么这个类里面的方法抛出异常,就会回滚,数据库里面的数据也会回滚。
如何使用 JPA 在数据库中非持久化一个字段?
如果我们想让secrect 这个字段不被持久化,也就是不被数据库存储怎么办?我们可以采用下面几种方法:
static String transient1; // not persistent because of static
final String transient2 = "Satish"; // not persistent because of final
transient String transient3; // not persistent because of transient
@Transient
String transient4; // not persistent because of @Transient
一般使用后面两种方式比较多,我个人使用注解的方式比较多。
Spring事务失效的情景?
八种:
-
抛出检查异常^(IOException:输入输出异常,包括文件读写、网络通信等操作时可能抛出的异常。 SQLException:数据库异常,包括对数据库进行操作时可能抛出的异常。 ClassNotFoundException:类未找到异常,当尝试加载不存在的类时抛出的异常。 InterruptedException:线程中断异常,当线程在等待或休眠状态下被中断时抛出的异常。)^导致事务不能正常回滚
- 原因:Spring默认只回滚非检查异常
- 解法:配置
@Transactional(rollbackFor=Exception.class)
-
业务方法内自己try-catch异常,导致事务无法正确回滚
-
事务通知只有捕获到目标抛出的异常,才能进行后续的回滚处理,如果目标自己处理了异常,事务通知无法捕获
-
解法1:异常原样抛出
- 在catch块添加
throw new RuntimeException(e)
- 在catch块添加
-
解法2:手动设置TransactionStatus.setRollbackOnly()
- 在catch块添加
TransactionInterceptor.currentTransactionStatus().setRollbackOnly()
- 在catch块添加
-
-
AOP切面顺序导致事务不能正确回滚
- 原因:事务切面优先级最低,如果自定义切面优先级与事务切面一样,则自定义切面在内层,如果此时自定义切面没有正确
- 解法1-2:同情况2
- 解法3:调整自定义切面顺序@Order(Ordered.LOWEST_PRECEDENCE-1)
-
非Public方法导致事务失效
- 原因:Spring只为Public方法创建代理、添加事务通知。
- 解法:改为Public方法
-
父子容器导致事务失效
- 原因:子容器扫描范围过大,把未加事务配置的Service也扫描了
- 解法1:各扫各的
- 解法2:不使用父子容器,所有bean放在同一容器
-
调用本类方法导致传播行为失效
- 原因:本类方法调用不经过代理,因此无法进行增强
- 解法1:依赖注入自己(代理)来调用
- 解法2:通过AopContext拿到代理对象,来调用
-
@Transactional没有保证原子行为
- 原因:事务的原子性仅涵盖insert、update、delete、select...for update语句,select方法并不阻塞
-
@Transactional方法导致的synchronized失效
- 原因:synchronized仅保证目标方法的原子性,环绕目标方法的还有commit等操作,它们未处于sync块
- 解法1:synchronized范围扩大至代理方法调用
- 解法2:使用select...for update替换select
SpringBoot
简单介绍一下Spring?有何缺点?
Spring是重量级企业开发框架Enterprise JavaBean (EJB)的替代品。
Spring为企业级Java开发提供了一种相对简单的方法,通过依赖注入与面向切面编程,用简单的Java对象(POJO)实现了EJB的功能。
虽然Spring的组件代码是轻量级的,但是它的配置确实重量级的,需要大量的XML配置。
为此,Spring2.5引入了基于注解的组件扫描,消除了大量针对应用程序自身组件的显式XML配置。Spring3.0引入了基于Java的配置,这是一种类型安全的可重构配置方式,可以替代XML。
尽管如此,在开启某些Spring特性时,例如事务管理和SpringMVC,还是需要用XML或Java进行显式配置。启用第三方库时也需要显式配置,如基于Thymeleaf的Web视图。配置Servlet和过滤器(如Spring的DispatcherServlet)同样需要再web.xml或Servlet初始化代码里进行显式配置。组件扫描减少了配置量,Java配置使其更加简洁,但是Spring还是需要不少配置。
除了大量XML配置,相关库的依赖也很麻烦。不用库之间的版本冲突非常常见。
为什么要有SpringBoot
Spring旨在简化J2EE企业应用程序的开发。SpringBoot旨在简化Spring开发(减少配置文件,开箱即用)。
说说使用SpringBoot的主要优点
- 开发基于Spring的应用程序很容易。
- SpringBoot项目所需的开发或工程时间明显减少,通常会提高整体生产力。
- 不需要编写大量样板代码、XML配置和注释。
- SpringBoot应用程序可以很容易地与Spring生态系统集成,如SpringJDBC、SpringORM、SpringData、SpringSecurity等。
- SpringBoot遵循“固执己见的默认配置”,以减少开发工作(默认配置可以修改)
- 提供嵌入式HTTP服务器,如Tomcat和Jetty,可以轻松地开发和测试web应用程序。
- 提供命令行接口(CLI)工具,用于开发和测试SpringBoot应用程序,如Java或Groovy
- 提供了多种插件,可以使用内置工具(如Maven或Gradle)开发和测试。
什么是Spring Boot Starters
SpringBootStarters是一系列依赖关系的集合,因为它的存在,项目的依赖关系变得更加简单。
举个例子:在没有Spring Boot Starters之前,我们开发REST 服务或 Web应用程序时;我们需要使用像Spring MVC,Tomcat和Jackson这样的库,这些依赖我们需要手动一个一个添加。但是,有了Spring Boot Starters我们只需要一个只需添加一个spring-boot-starter-web一个依赖就可以了,这个依赖包含的子依赖中包含了我们开发REST 服务需要的所有依赖。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
SpringBoot支持哪些内嵌的Servlet容器?
tomcat
jetty
undertow
如何在SpringBoot中使用Jetty而不是Tomcat
默认使用Tomcat,如果想用Jetty,只需要修改pom.xml。
<!--从Web启动器依赖中排除Tomcat-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--添加Jetty依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency>
介绍一下@SpringBootApplication注解
package org.springframework.boot.autoconfigure;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(excludeFilters = {
@Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
......
}
package org.springframework.boot;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Configuration
public @interface SpringBootConfiguration {
}
可以把@SpringBootApplication看作是
@Configuration、@EnableAutoConfiguration、@ComponentScan注解的集合。
- @EnableAutoConfiguration 启动SpringBoot的自动配置机制
- @ComponentScan: 扫描被@Component(@Service,@Controller)注解的bean,注解默认会扫描该类所在包下所有的类。
- @Configuration: 允许在上下文中注册额外的bean或导入其他配置类。
Spring Boot的自动配置是如何实现的
(重点掌握) 这个是因为@SpringBootApplication 注解的原因,在上一个问题中已经提到了这个注解。我们知道 @SpringBootApplication 看作是 @Configuration、@EnableAutoConfiguration、@ComponentScan 注解的集合。
- @EnableAutoConfiguration:启用 SpringBoot 的自动配置机制
- @ComponentScan: 扫描被@Component (@Service,@Controller)注解的bean,注解默认会扫描该类所在的包下所有的类。
- @Configuration:允许在上下文中注册额外的bean或导入其他配置类
@EnableAutoConfiguration是启动自动配置的关键,源码如下(可以采用debug进行断点调试):
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage
@Import(EnableAutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {
/**
* Exclude specific auto-configuration classes such that they will never be applied.
* @return the classes to exclude
*/
Class<?>[] exclude() default {};
/**
* Exclude specific auto-configuration class names such that they will never be
* applied.
* @return the class names to exclude
* @since 1.3.0
*/
String[] excludeName() default {};
}
@EnbaleAutoConfiguration注解通过Spring提供@Import注解导入EnableAutoConfigurationImportSelector类(@Import 注解可以导入配置类或者Bean到当前类中)
/**
* Return the auto-configuration class names that should be considered. By default
* this method will load candidates using {@link SpringFactoriesLoader} with
* {@link #getSpringFactoriesLoaderFactoryClass()}.
* @param metadata the source metadata
* @param attributes the {@link #getAttributes(AnnotationMetadata) annotation
* attributes}
* @return a list of candidate configurations
*/
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata,
AnnotationAttributes attributes) {
return SpringFactoriesLoader.loadFactoryNames(
getSpringFactoriesLoaderFactoryClass(), getBeanClassLoader());
}
EnableAutoConfigurationImportSelector类中getCandidateConfigurations方法会将所有自动配置类的信息以List的形式返回。这些配置信息会被Spring容器做bean来管理。
自动配置信息就有了,自动配置呢?
@Conditional注解。@ConditionalOnClass(指定的类必须存在于类路径下),@ConditionalOnBean(容器中是否有指定的Bean)等等都是对@Conditional注解的扩展。
拿 Spring Security 的自动配置举个例子:
SecurityAutoConfiguration中导入了WebSecurityEnablerConfiguration类,WebSecurityEnablerConfiguration源代码如下:
@Configuration
@ConditionalOnBean(WebSecurityConfigurerAdapter.class)
@ConditionalOnMissingBean(name = BeanIds.SPRING_SECURITY_FILTER_CHAIN)
@ConditionalOnWebApplication(type = ConditionalOnWebApplication.Type.SERVLET)
@EnableWebSecurity
public class WebSecurityEnablerConfiguration {
}
WebSecurityEnablerConfiguration类中使用@ConditionalOnBean指定了容器中必须还有WebSecurityConfigurerAdapter 类或其实现类。所以,一般情况下 Spring Security 配置类都会去实现 WebSecurityConfigurerAdapter,这样自动将配置就完成了。
开发RESTful WEB服务常用的注解有哪些?
Spring Bean相关:
-
@Autowired:自动导入对象到类中,被注入进的类同样要被Spring容器管理 -
@RestController:该注解是@Controller和@ResponseBody的合集,表示这是一个控制器Bean,并且是将函数的返回值直接填入HTTP响应体中,是Rest风格的控制器。 -
@Component:通用的注解,可标注任意类为Spring组件,如果不知道一个Bean属于哪一层,可以使用@Component注解标注。 -
@Repository:对应持久层即Dao层,主要用于数据库相关操作。 -
@Service:对应服务层,主要涉及一些复杂的逻辑,需要用到Dao 层。 -
@Controller:对应 Spring MVC控制层,主要用于接受用户请求并调用Service层返回数据给前端页面。
处理常见HTTP请求类型:
- GetMapping : GET请求、
- @PostMapping : POST请求。
- @PutMapping : PUT请求。
- @DeleteMapping : DELETE请求。
前后端传值:
-
@RequestParam以及@Pathvairable :@PathVariable用于获取路径参数,@RequestParam用于获取查询参数。 -
@RequestBody:用于读取Request请求(可能是POST,PUT,DELETE,GET请求)的body部分并且Content-Type为application/json格式的数据,接收到数据之后会自动将数据绑定到Java对象上去。系统会使用HttpMessageConverter或者自定义的HttpMessageConverter将请求的body中的json字符串转换为java对象。
SpringBoot常用的两种配置文件
application.properties
application.yml
什么是yaml?yaml配置的优势在哪里
yaml是一种人类可读的数据序列化语言。通常用于配置文件。与属性文件相比,如果想要在配置文件中添加复杂的属性,yaml文件就更加结构化,清晰明了,具有分层配置数据的特点。
但是yaml配置的方式有一个缺点,不支持@PropertySource注解导入自定义的yaml配置。
SpringBoot常用的读取配置文件的方式有哪些?
- 通过@value读取比较简单的配置信息
使用 @Value 注解,可以直接读取配置文件中的属性值,例如 @Value("${server.port}")
不推荐使用这种方式,建议使用下面几种
- 通过@ConfigurationProperties读取并与bean绑定
使用 @ConfigurationProperties 注解,可以将配置文件中的属性映射到一个实体类中,例如 @ConfigurationProperties(prefix="spring.user")。
#===application.properties文件
spring.profiles.active=dev
#===application-dev.properties文件
server.port=8088
#user的属性配置
spring.user.name=wahaha
spring.user.age=30
@Data
@Configuration
@ConfigurationProperties(prefix="spring.user")
public class User {
private String name;
private String age;
}
--------------------------------
@RestController
public class ConfigController {
//读取配置方式一
@Autowired
private Environment env;
//读取配置方式二,8080为默认值
@Value("${server.port:8080}")
private String port;
//读取配置第三种方式,将属性注入到实体类中
// @ConfigurationProperties
@Autowired
private User user;
@GetMapping("/config")
public Object config() {
Map<String, Object> config = new HashMap<>();
config.put("profiles", env.getProperty("spring.profiles.active"));
config.put("port", port);
config.put("user.name", user.getName());
config.put("user.age", user.getAge());
return config;
}
}
-
通过@PropertySource读取指定的properties文件
- @PropertySource注解不支持加载yaml文件,支持properties文件
- 从Spring 4.3开始,@PropertySource带有factory属性。 可以利用它来提供PropertySourceFactory的自定义实现,该实现将处理YAML文件处理
public class YamlPropertySourceFactory implements PropertySourceFactory {
@Override
public PropertySource<?> createPropertySource(String name, EncodedResource encodedResource)
throws IOException {
YamlPropertiesFactoryBean factory = new YamlPropertiesFactoryBean();
factory.setResources(encodedResource.getResource());
Properties properties = factory.getObject();
return new PropertiesPropertySource(encodedResource.getResource().getFilename(), properties);
}
}
正如上面,实现一个createPropertySource方法就足够了。
在自定义实现中,首先,使用YamlPropertiesFactoryBean将YAML格式的资源转换为java.util.Properties对象。
然后,简单地返回了PropertiesPropertySource的新实例,该实例是一个包装,允许Spring读取解析的属性。
首先,创建一个简单的YAML文件– foo.yml:
yaml:
name: foo
aliases:
- abc
- xyz
接下来,使用@ConfigurationProperties创建一个属性类,并使用的自定义YamlPropertySourceFactory:
@Configuration
@ConfigurationProperties(prefix = "yaml")
@PropertySource(value = "classpath:foo.yml", factory = YamlPropertySourceFactory.class)
@Data
public class YamlFooProperties {
private String name;
private List<String> aliases;
}
最后,验证属性是否已正确注入:
@RunWith(SpringRunner.class)
@SpringBootTest
public class YamlFooPropertiesIntegrationTest {
@Autowired
private YamlFooProperties yamlFooProperties;
@Test
public void whenFactoryProvidedThenYamlPropertiesInjected() {
assertThat(yamlFooProperties.getName()).isEqualTo("foo");
assertThat(yamlFooProperties.getAliases()).containsExactly("abc", "xyz");
}
}
SpringBoot加载配置文件的优先级了解吗?
以上是按照优先级从高到低(1-4)的顺序,所有位置的文件都会被加载,高优先级配置内容会覆盖低优先级配置内容。
以下优先级从高到底加载顺序:
1.命令行参数
2.来自java:comp/env的JNDI属性
3.Java系统属性(System.getProperties())
4.操作系统环境变量
5.RandomValuePropertySource配置的random.*属性值
6.jar包外部的application-{profile}.properties或application.yml(带spring.profile)配置文件
7.jar包内部的application-{profile}.properties或application.yml(带spring.profile)配置文件
8.jar包外部的application.properties或application.yml(不带spring.profile)配置文件
9.jar包内部的application.properties或application.yml(不带spring.profile)配置文件
Note: 由jar包外向jar包内进行寻找,优先加载带profile的,再加载不带profile的。
10.@Configuration注解类上的@PropertySource
11.通过SpringApplication.setDefaultProperties指定的默认属性
properties配置优先级 > YAML配置优先级
如何使用SpringBoot实现全局异常处理?
SpringBoot中,@ControllerAdvice 即可开启全局异常处理,使用该注解表示开启了全局异常的捕获,我们只需在自定义一个方法使用@ExceptionHandler注解然后定义捕获异常的类型即可对这些捕获的异常进行统一的处理。
自定义全局异常类
@ControllerAdvice
public class MyExceptionHandler {
@ExceptionHandler(value =Exception.class)
@ResponseBody
public String exceptionHandler(Exception e){
System.out.println("全局异常捕获>>>:"+e);
return "全局异常捕获,错误原因>>>"+e.getMessage();
}
}
手动抛出异常
@GetMapping("/getById/{userId}")
public CommonResult<User> getById(@PathVariable Integer userId){
// 手动抛出异常
int a = 10/0;
return CommonResult.success(userService.getById(userId));
}
测试打印


说说常见的SpringBoot注解
@SpringBootApplication
创建项目时默认加载主类上。
可以看做是@Configuration、@EnableAutoConfiguration、@ComponentScan注解的集合
-
@EnableAutoConfiguration:启用 SpringBoot 的自动配置机制 -
@ComponentScan:扫描被@Component (@Repository,@Service,@Controller)注解的 bean,注解默认会扫描该类所在的包下所有的类。 -
@Configuration:允许在 Spring 上下文中注册额外的 bean 或导入其他配置类
Spring Bean 相关
@Autowired
自动导入对象到类中,被注入的类要被Spring容器管理。
@Component,@Repository,@Service, @Controller
我们一般使用 @Autowired 注解让 Spring 容器帮我们自动装配 bean。要想把类标识成可用于 @Autowired 注解自动装配的 bean 的类,可以采用以下注解实现:
-
@Component:通用的注解,可标注任意类为Spring 组件。如果一个 Bean 不知道属于哪个层,可以使用@Component 注解标注。 -
@Repository : 对应持久层即 Dao 层,主要用于数据库相关操作。 -
@Service : 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao 层。 -
@Controller : 对应 Spring MVC 控制层,主要用于接受用户请求并调用 Service 层返回数据给前端页面。
@RestController
@RestController注解是@Controller和@ResponseBody的合集,表示这是个控制器 bean,并且是将函数的返回值直接填入 HTTP 响应体中,是 REST 风格的控制器。
@RestController只返回对象,对象数据直接以 JSON 或 XML 形式写入 HTTP 响应(Response)中,这种情况属于 RESTful Web服务,这也是目前日常开发所接触的最常用的情况(前后端分离)。
Guide:现在都是前后端分离,说实话我已经很久没有用过 @Controller 。如果你的项目太老了的话,就当我没说。
单独使用 @Controller 不加 @ResponseBody的话一般是用在要返回一个视图的情况,这种情况属于比较传统的 Spring MVC 的应用,对应于前后端不分离的情况。@Controller +@ResponseBody 返回 JSON 或 XML 形式数据
@Scope
声明 Spring Bean 的作用域,使用方法:
@Bean
@Scope("singleton")
public Person personSingleton() {
return new Person();
}
四种常见的 Spring Bean 的作用域:
- singleton : 唯一 bean 实例,Spring 中的 bean 默认都是单例的。
- prototype : 每次请求都会创建一个新的 bean 实例。
- request : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP request 内有效。
- session : 每一个 HTTP Session 会产生一个新的 bean,该 bean 仅在当前 HTTP session 内有效。
@Configuration
一般用来声明配置类,可以使用 @Component注解替代,不过使用@Configuration注解声明配置类更加语义化。
@Configuration
public class AppConfig {
@Bean
public TransferService transferService() {
return new TransferServiceImpl();
}
}
处理常见的 HTTP 请求类型
5 种常见的请求类型:
- GET:请求从服务器获取特定资源。举个例子:
GET /users(获取所有学生) - POST:在服务器上创建一个新的资源。举个例子:
POST /users(创建学生) - PUT:更新服务器上的资源(客户端提供更新后的整个资源)。举个例子:
PUT /users/12(更新编号为 12 的学生) - DELETE:从服务器删除特定的资源。举个例子:
DELETE /users/12(删除编号为 12 的学生) - PATCH:更新服务器上的资源(客户端提供更改的属性,可以看做作是部分更新),使用的比较少,这里就不举例子了。
@GetMapping("users") 等价于@RequestMapping(value="/users",method=RequestMethod.GET)
@PostMapping("users") 等价于@RequestMapping(value="/users",method=RequestMethod.POST)
@PutMapping("/users/{userId}") 等价于@RequestMapping(value="/users/{userId}",method=RequestMethod.PUT)
@DeleteMapping("/users/{userId}")等价于@RequestMapping(value="/users/{userId}",method=RequestMethod.DELETE)
一般实际项目中,我们都是 PUT 不够用了之后才用 PATCH 请求去更新数据。
@PatchMapping("/profile")
public ResponseEntity updateStudent(@RequestBody StudentUpdateRequest studentUpdateRequest) {
studentRepository.updateDetail(studentUpdateRequest);
return ResponseEntity.ok().build();
}
前后端传值
@PathVariable 和 @RequestParam
@PathVariable用于获取路径参数,@RequestParam用于获取查询参数。
举个简单的例子:
@GetMapping("/klasses/{klassId}/teachers")
public List<Teacher> getKlassRelatedTeachers(
@PathVariable("klassId") Long klassId,
@RequestParam(value = "type", required = false) String type ) {
...
}
如果我们请求的 url 是:/klasses/123456/teachers?type=web
那么我们服务获取到的数据就是:klassId=123456,type=web
@RequestBody
用于读取 Request 请求(可能是 POST,PUT,DELETE,GET 请求)的 body 部分并且Content-Type 为 application/json 格式的数据,接收到数据之后会自动将数据绑定到 Java 对象上去。系统会使用HttpMessageConverter或者自定义的HttpMessageConverter将请求的 body 中的 json 字符串转换为 java 对象。
我用一个简单的例子来给演示一下基本使用!
我们有一个注册的接口:
@PostMapping("/sign-up")
public ResponseEntity signUp(
@RequestBody @Valid UserRegisterRequest userRegisterRequest)
{
userService.save(userRegisterRequest);
return ResponseEntity.ok().build();
}
UserRegisterRequest对象:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class UserRegisterRequest {
@NotBlank
private String userName;
@NotBlank
private String password;
@NotBlank
private String fullName;
}
我们发送 post 请求到这个接口,并且 body 携带 JSON 数据:
{ "userName": "coder", "fullName": "shuangkou", "password": "123456" }
这样我们的后端就可以直接把 json 格式的数据映射到我们的 UserRegisterRequest 类上。
需要注意的是:一个请求方法只可以有一个 @RequestBody ,但是可以有多个 @RequestParam和 @PathVariable。 如果你的方法必须要用两个 @RequestBody来接受数据的话,大概率是你的数据库设计或者系统设计出问题了
如何读取配置信息
很多时候我们需要将一些常用的配置信息比如阿里云 oss、发送短信、微信认证的相关配置信息等等放到配置文件中。
下面我们来看一下 Spring 为我们提供了哪些方式帮助我们从配置文件中读取这些配置信息。
我们的数据源application.yml内容如下:
wuhan2020: 2020年初武汉爆发了新型冠状病毒,疫情严重,但是,我相信一切都会过去!武汉加油!中国加油!
my-profile:
name: Guide哥
email: koushuangbwcx@163.com
library:
location: 湖北武汉加油中国加油
books:
- name: 天才基本法
description: 二十二岁的林朝夕在父亲确诊阿尔茨海默病这天,得知自己暗恋多年的校园男神裴之即将出国深造的消息——对方考取的学校,恰是父亲当年为她放弃的那所。
- name: 时间的秩序
description: 为什么我们记得过去,而非未来?时间“流逝”意味着什么?是我们存在于时间之内,还是时间存在于我们之中?卡洛·罗韦利用诗意的文字,邀请我们思考这一亘古难题——时间的本质。
- name: 了不起的我
description: 如何养成一个新习惯?如何让心智变得更成熟?如何拥有高质量的关系? 如何走出人生的艰难时刻?
@Value(常用)
使用 @Value("${property}") 读取比较简单的配置信息:
@Value("${wuhan2020}")
String wuhan2020;
@ConfigurationProperties(常用)
通过@ConfigurationProperties读取配置信息并与 bean 绑定。
@Component
@ConfigurationProperties(prefix = "library")
class LibraryProperties {
@NotEmpty
private String location;
private List<Book> books;
@Setter
@Getter
@ToString
static class Book {
String name;
String description;
}
省略getter/setter
......
}
你可以像使用普通的 Spring bean 一样,将其注入到类中使用。
@PropertySource(不常用)
@PropertySource读取指定 properties 文件
@Component
@PropertySource("classpath:website.properties")
class WebSite {
@Value("${url}")
private String url;
省略getter/setter
......
}
更多内容请查看:《10 分钟搞定 SpringBoot 如何优雅读取配置文件?》open in new window
如何进行参数校验
数据的校验的重要性就不用说了,即使在前端对数据进行校验的情况下,我们还是要对传入后端的数据再进行一遍校验,避免用户绕过浏览器直接通过一些 HTTP 工具直接向后端请求一些违法数据。
JSR(Java Specification Requests) 是一套 JavaBean 参数校验的标准,它定义了很多常用的校验注解,我们可以直接将这些注解加在我们 JavaBean 的属性上面,这样就可以在需要校验的时候进行校验了,非常方便!
校验的时候我们实际用的是 Hibernate Validator 框架。
更新版本的 spring-boot-starter-web 依赖中不再有 hibernate-validator 包(如 2.3.11.RELEASE),需要自己引入 spring-boot-starter-validation 依赖。
具体可以查看我的这篇文章:《如何在 Spring/Spring Boot 中做参数校验?你需要了解的都在这里!open in new window》。
需要注意的是:所有的注解,推荐使用 JSR 注解,即javax.validation.constraints ,而不是org.hibernate.validator.constraints
一些常用的字段验证的注解
-
@NotEmpty 被注释的字符串的不能为 null 也不能为空 -
@NotBlank 被注释的字符串非 null,并且必须包含一个非空白字符 -
@Null 被注释的元素必须为 null -
@NotNull 被注释的元素必须不为 null -
@AssertTrue 被注释的元素必须为 true -
@AssertFalse 被注释的元素必须为 false -
@Pattern(regex=,flag=)被注释的元素必须符合指定的正则表达式 -
@Email 被注释的元素必须是 Email 格式。 -
@Min(value)被注释的元素必须是一个数字,其值必须大于等于指定的最小值 -
@Max(value)被注释的元素必须是一个数字,其值必须小于等于指定的最大值 -
@DecimalMin(value)被注释的元素必须是一个数字,其值必须大于等于指定的最小值 -
@DecimalMax(value) 被注释的元素必须是一个数字,其值必须小于等于指定的最大值 -
@Size(max=, min=)被注释的元素的大小必须在指定的范围内 -
@Digits(integer, fraction)被注释的元素必须是一个数字,其值必须在可接受的范围内 -
@Past被注释的元素必须是一个过去的日期 -
@Future 被注释的元素必须是一个将来的日期 - ......
验证请求体(RequestBody)
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Person {
@NotNull(message = "classId 不能为空")
private String classId;
@Size(max = 33)
@NotNull(message = "name 不能为空")
private String name;
@Pattern(regexp = "((^Man$|^Woman$|^UGM$))", message = "sex 值不在可选范围")
@NotNull(message = "sex 不能为空")
private String sex;
@Email(message = "email 格式不正确")
@NotNull(message = "email 不能为空")
private String email;
}
我们在需要验证的参数上加上了@Valid注解,如果验证失败,它将抛出MethodArgumentNotValidException。
@RestController
@RequestMapping("/api")
public class PersonController {
@PostMapping("/person")
public ResponseEntity<Person> getPerson(
@RequestBody @Valid Person person) {
return ResponseEntity.ok().body(person);
}
}
验证请求参数(Path Variables 和 Request Parameters)
一定一定不要忘记在类上加上 @Validated 注解了,这个参数可以告诉 Spring 去校验方法参数。
@RestController
@RequestMapping("/api")
@Validated
public class PersonController {
@GetMapping("/person/{id}")
public ResponseEntity<Integer> getPersonByID
(@Valid @PathVariable("id") @Max(value = 5,message = "超过 id 的范围了") Integer id) {
return ResponseEntity.ok().body(id);
}
}
更多关于如何在 Spring 项目中进行参数校验的内容,请看《如何在 Spring/Spring Boot 中做参数校验?你需要了解的都在这里!open in new window》这篇文章
如何全局处理 Controller 层异常
介绍一下我们 Spring 项目必备的全局处理 Controller 层异常。
相关注解:
-
@ControllerAdvice :注解定义全局异常处理类 -
@ExceptionHandler :注解声明异常处理方法
如何使用呢?拿我们在第 5 节参数校验这块来举例子。如果方法参数不对的话就会抛出MethodArgumentNotValidException,我们来处理这个异常。
@ControllerAdvice
@ResponseBody
public class GlobalExceptionHandler {
/**
* 请求参数异常处理
*/
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResponseEntity<?> handleMethodArgumentNotValidException(MethodArgumentNotValidException ex, HttpServletRequest request) {
......
}
}
更多关于 Spring Boot 异常处理的内容 :
如何自己实现一个spring boot starter?
实现自定义线程池
第一步,创建threadpool-spring-boot-starter工程
第二步,引入 Spring Boot 相关依赖
第三步,创建ThreadPoolAutoConfiguration
第四步,在threadpool-spring-boot-starter工程的 resources 包下创建META-INF/spring.factories文件
最后新建工程引入threadpool-spring-boot-starter
测试通过!!!
SpringBoot 自动装配原理?
Spring Boot 通过@EnableAutoConfiguration开启自动装配,通过 SpringFactoriesLoader 最终加载META-INF/spring.factories中的自动配置类实现自动装配,自动配置类其实就是通过@Conditional按需加载的配置类,想要其生效必须引入spring-boot-starter-xxx包实现起步依赖
-
通过
@SpringBootApplication中的@EnableAutoConfiguration开启自动装配 -
EnableAutoConfiguration 通过@Import导入AutoConfigurationImportSelector类。 -
AutoConfigurationImportSelector 类实现了ImportSelector接口,也就实现了这个接口中的selectImports方法,该方法主要用于获取所有符合条件的类的全限定类名,这些类需要被加载到 IoC 容器中。 -
selectImports方法通过调用getAutoConfigurationEntry()方法加载自动配置类- 第一步,判断自动装配开关是否打开。默认
spring.boot.enableautoconfiguration=true,可在application.properties 或application.yml 中设置 - 第二步,获取
EnableAutoConfiguration注解中的exclude 和excludeName - 第三步,获取需要自动装配的所有配置类,读取
META-INF/spring.factories。所有 Spring Boot Starter 下的META-INF/spring.factories都会被读取到 - 第四步,筛选,
@ConditionalOnXXX 中的所有条件都满足,该类才会生效。
- 第一步,判断自动装配开关是否打开。默认
MyBatis
#{} 和 ${} 的区别是什么?
#{}是预编译处理,${}是字符串替换。
Mybatis在处理{}时,会将sql中的{}替换为?号,调用PreparedStatement的set方法来赋值;
Mybatis在处理${}时,就是把${}替换成变量的值。
使用#{}可以有效的防止SQL注入,提高系统安全性。
-
${}是 Properties 文件中的变量占位符,它可以用于标签属性值和 sql 内部,属于静态文本替换,比如${driver}会被静态替换为com.mysql.jdbc. Driver。 -
#{}是 sql 的参数占位符,MyBatis 会将 sql 中的#{}替换为? 号,在 sql 执行前会使用 PreparedStatement 的参数设置方法,按序给 sql 的? 号占位符设置参数值,比如 ps.setInt(0, parameterValue),#{item.name} 的取值方式为使用反射从参数对象中获取 item 对象的 name 属性值,相当于param.getItem().getName()
通常不会采用${}的方式传值。
一个特定的适用场景是:通过Java程序动态生成数据库表,表名部分需要Java程序通过参数传入;而JDBC对于表名部分是不能使用问号占位符的,此时只能使用${}。
xml 映射文件中,除了常见的 select、insert、update、delete 标签之外,还有哪些标签?
注:这道题是京东面试官面试我时问的。
答:还有很多其他的标签, <resultMap>、 <parameterMap>、 <sql>、 <include>、 <selectKey> ,加上动态 sql 的 9 个标签, trim|where|set|foreach|if|choose|when|otherwise|bind 等,其中 <sql> 为 sql 片段标签,通过 <include> 标签引入 sql 片段, <selectKey> 为不支持自增的主键生成策略标签。
怎样在插入数据后获取自增主键的值?
通过在sql标签中添加useGeneratedKeys="true" keyProperty="pojo中对应的属性"
<!-- int insertEmployee(Employee employee); -->
<!-- useGeneratedKeys属性字面意思就是“使用生成的主键” -->
<!-- keyProperty属性可以指定主键在实体类对象中对应的属性名,Mybatis会将拿到的主键值存入这个属性 -->
<insert id="insertEmployee" useGeneratedKeys="true" keyProperty="empId">
insert into t_emp(emp_name,emp_salary)
values(#{empName},#{empSalary})
</insert>
而对于不支持自增型主键的数据库(例如 Oracle),则可以使用 selectKey 子元素:selectKey 元素将会首先运行,id 会被设置,然后插入语句会被调用
<insert id="insertEmployee" parameterType="com.atguigu.mybatis.beans.Employee" databaseId="oracle">
<selectKey order="BEFORE" keyProperty="id" resultType="integer">
select employee_seq.nextval from dual
</selectKey>
insert into orcl_employee(id,last_name,email,gender) values(#{id},#{lastName},#{email},#{gender})
</insert>
或者是
<insert id="insertEmployee" parameterType="com.atguigu.mybatis.beans.Employee" databaseId="oracle">
<selectKey order="AFTER" keyProperty="id" resultType="integer">
select employee_seq.currval from dual
</selectKey>
insert into orcl_employee(id,last_name,email,gender) values(employee_seq.nextval,#{lastName},#{email},#{gender})
</insert>
数据库表字段和实体类属性有哪几种对应方式?
①别名
将字段的别名设置成和实体类属性一致。
<!-- 编写具体的SQL语句,使用id属性唯一的标记一条SQL语句 -->
<!-- resultType属性:指定封装查询结果的Java实体类的全类名 -->
<select id="selectEmployee" resultType="com.atguigu.mybatis.entity.Employee">
<!-- Mybatis负责把SQL语句中的#{}部分替换成“?”占位符 -->
<!-- 给每一个字段设置一个别名,让别名和Java实体类中属性名一致 -->
select emp_id empId,emp_name empName,emp_salary empSalary from t_emp where emp_id=#{maomi}
</select>
关于实体类属性的约定:
getXxx()方法、setXxx()方法把方法名中的get或set去掉,首字母小写。
②全局配置自动识别驼峰式命名规则
在Mybatis全局配置文件加入如下配置:
<!-- 使用settings对Mybatis全局进行设置 -->
<settings>
<!-- 将xxx_xxx这样的列名自动映射到xxXxx这样驼峰式命名的属性名 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
SQL语句中可以不使用别名
<!-- Employee selectEmployee(Integer empId); -->
<select id="selectEmployee" resultType="com.atguigu.mybatis.entity.Employee">
select emp_id,emp_name,emp_salary from t_emp where emp_id=#{empId}
</select>
③使用resultMap
使用resultMap标签定义对应关系,再在后面的SQL语句中引用这个对应关系
<!-- 专门声明一个resultMap设定column到property之间的对应关系 -->
<resultMap id="selectEmployeeByRMResultMap" type="com.atguigu.mybatis.entity.Employee">
<!-- 使用id标签设置主键列和主键属性之间的对应关系 -->
<!-- column属性用于指定字段名;property属性用于指定Java实体类属性名 -->
<id column="emp_id" property="empId"/>
<!-- 使用result标签设置普通字段和Java实体类属性之间的关系 -->
<result column="emp_name" property="empName"/>
<result column="emp_salary" property="empSalary"/>
</resultMap>
<!-- Employee selectEmployeeByRM(Integer empId); -->
<select id="selectEmployeeByRM" resultMap="selectEmployeeByRMResultMap">
select emp_id,emp_name,emp_salary from t_emp where emp_id=#{empId}
</select>
对一:
<!-- 创建resultMap实现“对一”关联关系映射 -->
<!-- id属性:通常设置为这个resultMap所服务的那条SQL语句的id加上“ResultMap” -->
<!-- type属性:要设置为这个resultMap所服务的那条SQL语句最终要返回的类型 -->
<resultMap id="selectOrderWithCustomerResultMap" type="com.atguigu.mybatis.entity.Order">
<!-- 先设置Order自身属性和字段的对应关系 -->
<id column="order_id" property="orderId"/>
<result column="order_name" property="orderName"/>
<!-- 使用association标签配置“对一”关联关系 -->
<!-- property属性:在Order类中对一的一端进行引用时使用的属性名 -->
<!-- javaType属性:一的一端类的全类名 -->
<association property="customer" javaType="com.atguigu.mybatis.entity.Customer">
<!-- 配置Customer类的属性和字段名之间的对应关系 -->
<id column="customer_id" property="customerId"/>
<result column="customer_name" property="customerName"/>
</association>
</resultMap>
<!-- Order selectOrderWithCustomer(Integer orderId); -->
<select id="selectOrderWithCustomer" resultMap="selectOrderWithCustomerResultMap">
SELECT order_id,order_name,c.customer_id,customer_name
FROM t_order o
LEFT JOIN t_customer c
ON o.customer_id=c.customer_id
WHERE o.order_id=#{orderId}
</select>
在“对一”关联关系中,我们的配置比较多,但是关键词就只有:association和javaType
对多:
<!-- 配置resultMap实现从Customer到OrderList的“对多”关联关系 -->
<resultMap id="selectCustomerWithOrderListResultMap"
type="com.atguigu.mybatis.entity.Customer">
<!-- 映射Customer本身的属性 -->
<id column="customer_id" property="customerId"/>
<result column="customer_name" property="customerName"/>
<!-- collection标签:映射“对多”的关联关系 -->
<!-- property属性:在Customer类中,关联“多”的一端的属性名 -->
<!-- ofType属性:集合属性中元素的类型 -->
<collection property="orderList" ofType="com.atguigu.mybatis.entity.Order">
<!-- 映射Order的属性 -->
<id column="order_id" property="orderId"/>
<result column="order_name" property="orderName"/>
</collection>
</resultMap>
<!-- Customer selectCustomerWithOrderList(Integer customerId); -->
<select id="selectCustomerWithOrderList" resultMap="selectCustomerWithOrderListResultMap">
SELECT c.customer_id,c.customer_name,o.order_id,o.order_name
FROM t_customer c
LEFT JOIN t_order o
ON c.customer_id=o.customer_id
WHERE c.customer_id=#{customerId}
</select>
在“对多”关联关系中,同样有很多配置,但是提炼出来最关键的就是:“collection”和“ofType”
Mybatis的分步查询怎样实现
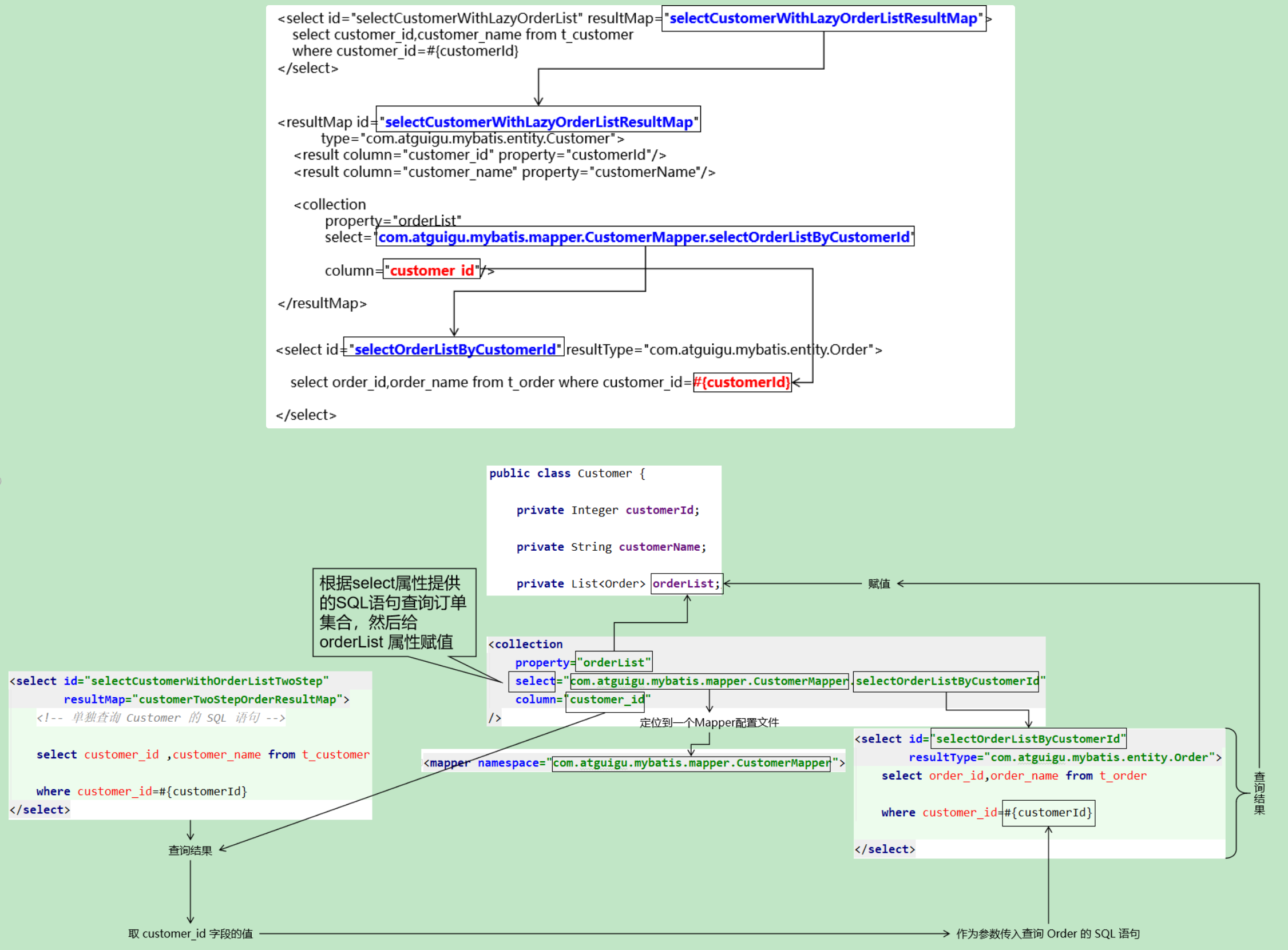
mybatis-config.xml中,官方给出的标签,及其排列顺序?
<configuration> • <properties> • <settings> • <typeAliases> • <typeHandlers> • <objectFactory> • <plugins> • <environments> • <environment> • <transactionManager> • <dataSource> • <databaseIdProvider> • <mapper>
mybatis配置总结
| 关联关系 | 配置项关键词 | 所在配置文件和具体位置 |
|---|---|---|
| 对一 | association标签/javaType属性 | Mapper配置文件中的resultMap标签内 |
| 对多 | collection标签/ofType属性 | Mapper配置文件中的resultMap标签内 |
| 对一分步 | association标签/select属性/column属性 | Mapper配置文件中的resultMap标签内 |
| 对多分步 | collection标签/select属性/column属性 | Mapper配置文件中的resultMap标签内 |
| 延迟加载 3.4.1版本前 |
lazyLoadingEnabled设置为true aggressiveLazyLoading设置为false |
Mybatis全局配置文件中的settings标签内 |
| 延迟加载 3.4.1版本后 |
lazyLoadingEnabled设置为true | Mybatis全局配置文件中的settings标签内 |
动态sql
if和where
- where标签会自动去掉“标签体内前面多余的and/or”
- 使用if标签,让我们可以有选择的加入SQL语句的片段。这个SQL语句片段是否要加入整个SQL语句,就看if标签判断的结果是否为true
- 在if标签的test属性中,可以访问实体类的属性,不可以访问数据库表的字段
- 在if标签内部,需要访问接口的参数时还是正常写#{}
<!-- List<Employee> selectEmployeeByCondition(Employee employee); -->
<select id="selectEmployeeByCondition" resultType="com.atguigu.mybatis.entity.Employee">
select emp_id,emp_name,emp_salary from t_emp
<where>
<if test="empName != null">
or emp_name=#{empName}
</if>
<if test="empSalary > 2000">
or emp_salary>#{empSalary}
</if>
<!--
第一种情况:所有条件都满足 WHERE emp_name=? or emp_salary>?
第二种情况:部分条件满足 WHERE emp_salary>?
第三种情况:所有条件都不满足 没有where子句
-->
</where>
</select>
set
只更新部分字段时使用set
- 使用set标签动态管理set子句,并且动态去掉两端多余的逗号
<!-- void updateEmployeeDynamic(Employee employee) -->
<update id="updateEmployeeDynamic">
update t_emp
<!-- set emp_name=#{empName},emp_salary=#{empSalary} -->
<set>
<if test="empName != null">
emp_name=#{empName},
</if>
<if test="empSalary < 3000">
emp_salary=#{empSalary},
</if>
</set>
where emp_id=#{empId}
<!--
第一种情况:所有条件都满足 SET emp_name=?, emp_salary=?
第二种情况:部分条件满足 SET emp_salary=?
第三种情况:所有条件都不满足 update t_emp where emp_id=?
没有set子句的update语句会导致SQL语法错误
-->
</update>
trim
使用trim标签控制条件部分两端是否包含某些字符
-
prefix属性指定要动态添加的前缀
-
suffix属性指定要动态添加的后缀
-
prefixOverrides属性指定要动态去掉的前缀,使用“|”分隔有可能的多个值
-
suffixOverrides属性指定要动态去掉的后缀,使用“|”分隔有可能的多个值
-
当前例子用where标签实现更简洁,但是trim标签更灵活,可以用在任何有需要的地方
<!-- List<Employee> selectEmployeeByConditionByTrim(Employee employee) -->
<select id="selectEmployeeByConditionByTrim" resultType="com.atguigu.mybatis.entity.Employee">
select emp_id,emp_name,emp_age,emp_salary,emp_gender
from t_emp
<trim prefix="where" suffixOverrides="and|or">
<if test="empName != null">
emp_name=#{empName} and
</if>
<if test="empSalary > 3000">
emp_salary>#{empSalary} and
</if>
<if test="empAge <= 20">
emp_age=#{empAge} or
</if>
<if test="empGender=='male'">
emp_gender=#{empGender}
</if>
</trim>
</select>
choose、when、otherwise
在多个分支条件中,仅执行一个。
- 从上到下依次执行条件判断
- 遇到的第一个满足条件的分支会被采纳
- 被采纳分支后面的分支都将不被考虑
- 如果所有的when分支都不满足,那么就执行otherwise分支
<!-- List<Employee> selectEmployeeByConditionByChoose(Employee employee) -->
<select id="selectEmployeeByConditionByChoose" resultType="com.atguigu.mybatis.entity.Employee">
select emp_id,emp_name,emp_salary from t_emp
where
<choose>
<when test="empName != null">emp_name=#{empName}</when>
<when test="empSalary < 3000">emp_salary < 3000</when>
<otherwise>1=1</otherwise>
</choose>
<!--
第一种情况:第一个when满足条件 where emp_name=?
第二种情况:第二个when满足条件 where emp_salary < 3000
第三种情况:两个when都不满足 where 1=1 执行了otherwise
-->
</select>
foreach
1、基本用法
用批量插入举例
-
collection属性:要遍历的集合
-
item属性:遍历集合的过程中能得到每一个具体对象,在item属性中设置一个名字,将来通过这个名字引用遍历出来的对象
-
separator属性:指定当foreach标签的标签体重复拼接字符串时,各个标签体字符串之间的分隔符
-
open属性:指定整个循环把字符串拼好后,字符串整体的前面要添加的字符串
-
close属性:指定整个循环把字符串拼好后,字符串整体的后面要添加的字符串
-
index属性:这里起一个名字,便于后面引用
- 遍历List集合,这里能够得到List集合的索引值
- 遍历Map集合,这里能够得到Map集合的key
<foreach collection="empList" item="emp" separator="," open="values" index="myIndex">
<!-- 在foreach标签内部如果需要引用遍历得到的具体的一个对象,需要使用item属性声明的名称 -->
(#{emp.empName},#{myIndex},#{emp.empSalary},#{emp.empGender})
</foreach>
2、批量更新时需要注意
上面批量插入的例子本质上是一条SQL语句,而实现批量更新则需要多条SQL语句拼起来,用分号分开。也就是一次性发送多条SQL语句让数据库执行。此时需要在数据库连接信息的URL地址中设置:
atguigu.dev.url=jdbc:mysql://192.168.198.100:3306/mybatis-example?allowMultiQueries=true
对应的foreach标签如下:
<!-- int updateEmployeeBatch(@Param("empList") List<Employee> empList) -->
<update id="updateEmployeeBatch">
<foreach collection="empList" item="emp" separator=";">
update t_emp set emp_name=#{emp.empName} where emp_id=#{emp.empId}
</foreach>
</update>
3、关于foreach标签的collection属性
如果没有给接口中List类型的参数使用@Param注解指定一个具体的名字,那么在collection属性中默认可以使用collection或list来引用这个list集合。这一点可以通过异常信息看出来:
Parameter 'empList' not found. Available parameters are [arg0, collection, list]
在实际开发中,为了避免隐晦的表达造成一定的误会,建议使用@Param注解明确声明变量的名称,然后在foreach标签的collection属性中按照@Param注解指定的名称来引用传入的参数。
sql标签
1、抽取重复的SQL片段
<!-- 使用sql标签抽取重复出现的SQL片段 -->
<sql id="mySelectSql">
select emp_id,emp_name,emp_age,emp_salary,emp_gender from t_emp
</sql>
2、引用已抽取的SQL片段
<!-- 使用include标签引用声明的SQL片段 -->
<include refid="mySelectSql"/>
缓存策略
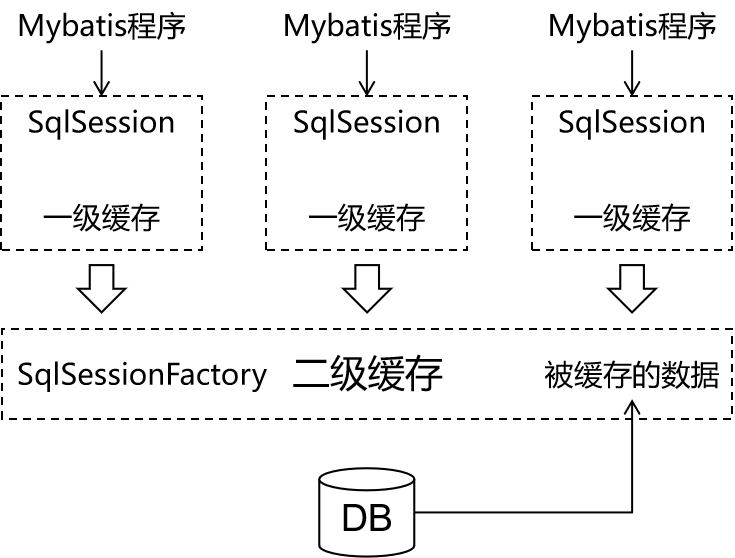
查询的顺序是:
- 先查询二级缓存,因为二级缓存中可能会有其他程序已经查出来的数据,可以拿来直接使用。
- 如果二级缓存没有命中,再查询一级缓存
- 如果一级缓存也没有命中,则查询数据库
- SqlSession关闭之前,一级缓存中的数据会写入二级缓存
效用范围
- 一级缓存:SqlSession级别
- 二级缓存:SqlSessionFactory级别
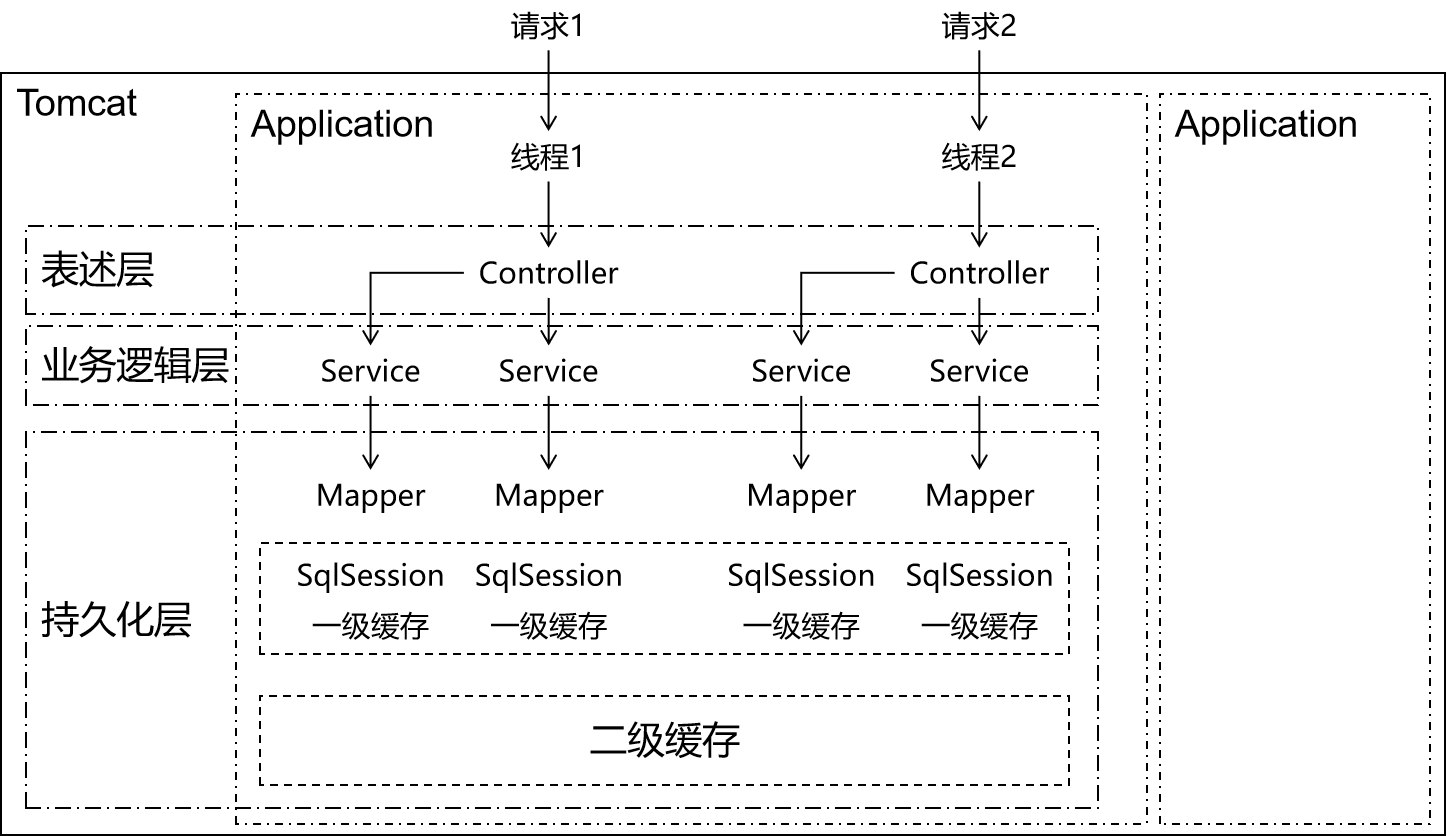
它们之间范围的大小参考下面图:
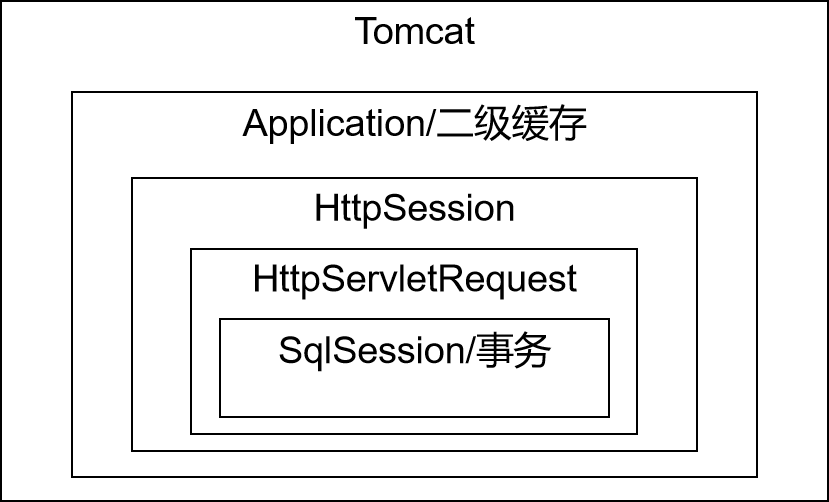
一级缓存失效的情况
- 不是同一个SqlSession
- 同一个SqlSession但是查询条件发生了变化
- 同一个SqlSession两次查询期间执行了任何一次增删改操作
- 同一个SqlSession两次查询期间手动清空了缓存
- 同一个SqlSession两次查询期间提交了事务
Dao接口的工作原理是什么
一个xml映射文件对应一个Dao接口,Dao接口也就是Mapper接口。
接口的全限名,就是映射文件中的namespace的值
接口的方法名,就是映射文件中MappedStatement的id值
接口方法内的参数,就是传递给sql的参数
Mapper接口没有对应的实现类,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement。
在Mybatis中,每个<select>、<insert>、<update>、<delete>标签,都会被解析为一个MappedStatement
Dao接口里的方法、参数不同时,方法能重载吗
Dao 接口里的方法可以重载,但是 Mybatis 的 xml 里面的 ID 不允许重复。
Dao 接口的工作原理是 JDK 动态代理,MyBatis 运行时会使用 JDK 动态代理为 Dao 接口生成代理 proxy 对象,代理对象 proxy 会拦截接口方法,转而执行 MappedStatement 所代表的 sql,然后将 sql 执行结果返回。
补充:
Dao 接口方法可以重载,但是需要满足以下条件:
- 仅有一个无参方法和一个有参方法
- 多个有参方法时,参数数量必须一致。且使用相同的
@Param ,或者使用param1 这种
MyBatis 是如何进行分页的?分页插件的原理是什么?
三种方法:
(1) MyBatis 使用 RowBounds 对象进行分页,它是针对 ResultSet 结果集执行的内存分页,而非物理分页;
(2) 可以在 sql 内直接书写带有物理分页的参数来完成物理分页功能,
(3) 也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用 MyBatis 提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的 sql,然后重写 sql,根据 dialect 方言,添加对应的物理分页语句和物理分页参数。
举例:select _ from student ,
拦截 sql 后重写为:select t._ from (select * from student)t limit 0,10
简述 MyBatis 的插件运行原理,以及如何编写一个插件
答:MyBatis 仅可以编写针对 ParameterHandler、 ResultSetHandler、 StatementHandler、 Executor 这 4 种接口的插件,MyBatis 使用 JDK 的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这 4 种接口对象的方法时,就会进入拦截方法,具体就是 InvocationHandler 的 invoke() 方法,当然,只会拦截那些你指定需要拦截的方法。 实现 MyBatis 的 Interceptor 接口并复写 intercept() 方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件。
MyBatis 动态 sql 是做什么的?都有哪些动态 sql?能简述一下动态 sql 的执行原理不?
答:MyBatis 动态 sql 可以让我们在 xml 映射文件内,以标签的形式编写动态 sql,完成逻辑判断和动态拼接 sql 的功能。
其执行原理为,使用 OGNL 从 sql 参数对象中计算表达式的值,根据表达式的值动态拼接 sql,以此来完成动态 sql 的功能。
MyBatis 提供了 9 种动态 sql 标签:
-
<if></if> -
<where></where>(trim,set) -
<choose></choose>(when, otherwise) -
<foreach></foreach> -
<bind/>
MyBatis 是如何将 sql 执行结果封装为目标对象并返回的?都有哪些映射形式?
-
当列名和封装查询结果的类的属性名一一对应时:这时MyBatis 有自动映射功能,将查询的记录封装到resultType 指定的类的对象中去。
-
当列名和封装查询结果的类的属性名不对应时:有两种方法:
- 使用resultMap 标签,在标签中配置属性名和列名的映射关系。
- 使用sql 列的别名功能,将列的别名书写为对象属性名,也可以做到映射关系。比如 T_NAME AS NAME,对象属性名一般是 name,小写,但是列名不区分大小写,MyBatis 会忽略列名大小写
有了列名与属性名的映射关系后,MyBatis 通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的
MyBatis 能执行一对一、一对多的关联查询吗?都有哪些实现方式,以及它们之间的区别
MyBatis 能执行一对一、一对多的关联查询,主要有两种实现方式:
- 分步查询:先查询主表,再根据主表的外键查询从表,最后将从表的结果封装到主表的对象中。这种方式需要多次执行 SQL 语句,效率较低,但是可以避免数据冗余和重复。
- 单步查询:直接使用联合查询或子查询,将主表和从表的数据一次性查询出来,然后通过 resultType 或 resultMap 的 association 或 collection 标签来映射一对一或一对多的关系。这种方式只需要执行一次 SQL 语句,效率较高,但是可能会产生数据冗余和重复。
它们之间的区别主要在于 SQL 语句的复杂度和执行次数,以及结果集的大小和冗余程度。具体选择哪种方式要根据实际情况和需求来决定。
去重复的原理是 <resultMap> 标签内的 <id> 子标签,指定了唯一确定一条记录的 id 列,MyBatis 根据 <id> 列值来完成 100 条记录的去重复功能, <id> 可以有多个,代表了联合主键的语意。
同样主对象的关联对象,也是根据这个原理去重复的,尽管一般情况下,只有主对象会有重复记录,关联对象一般不会重复。
MyBatis 是否支持延迟加载?如果支持,它的实现原理是什么?
MyBatis 仅支持 association 关联对象和 collection 关联集合对象的延迟加载,association 指的就是一对一,collection 指的就是一对多查询。在 MyBatis 配置文件中,可以配置是否启用延迟加载 lazyLoadingEnabled=true|false
Mybatis使用CGLib生成目标对象a的代理对象,当我们在测试方法里调用a.getB()方法时,结果为null,不可行。于是,Mybatis调用拦截器方法,使用事先在resultMap中的association或collection标签里设定好的select查询语句来获取数据库中的数据并映射到对象b上,此时b不再为null,a.getB().getName()顺利调用,实现了按需加载、延迟加载,节省了宝贵的计算资源。
MyBatis 的 xml 映射文件中,不同的 xml 映射文件,id 是否可以重复?
不同的 xml 映射文件,如果配置了 namespace,那么 id 可以重复;如果没有配置 namespace,那么 id 不能重复;毕竟 namespace 不是必须的,只是最佳实践而已。
原因就是 namespace+id 是作为 Map<String, MappedStatement> 的 key 使用的,如果没有 namespace,就剩下 id,那么,id 重复会导致数据互相覆盖。有了 namespace,自然 id 就可以重复,namespace 不同,namespace+id 自然也就不同。
MyBatis 都有哪些 Executor 执行器?它们之间的区别是什么?
MyBatis 有三种基本的 Executor 执行器:
-
SimpleExecutor : 每执行一次 update 或 select,就开启一个 Statement 对象,用完立刻关闭 Statement 对象。 -
ReuseExecutor : 执行 update 或 select,以 sql 作为 key 查找 Statement 对象,存在就使用,不存在就创建,用完后,不关闭 Statement 对象,而是放置于 Map<String, Statement>内,供下一次使用。简言之,就是重复使用 Statement 对象。 -
BatchExecutor:执行 update(没有 select,JDBC 批处理不支持 select),将所有 sql 都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个 Statement 对象,每个 Statement 对象都是 addBatch()完毕后,等待逐一执行 executeBatch()批处理。与 JDBC 批处理相同。
作用范围:Executor 的这些特点,都严格限制在 SqlSession 生命周期范围内。
MyBatis 中如何指定使用哪一种 Executor 执行器?
在 MyBatis 配置文件中,可以指定默认的 ExecutorType 执行器类型,
也可以手动给 DefaultSqlSessionFactory 的创建 SqlSession 的方法传递 ExecutorType 类型参数。
MyBatis 是否可以映射 Enum 枚举类?
MyBatis 可以映射枚举类,不单可以映射枚举类,MyBatis 可以映射任何对象到表的一列上。映射方式为自定义一个 TypeHandler ,实现 TypeHandler 的 setParameter() 和 getResult() 接口方法。 TypeHandler 有两个作用:
- 一是完成从 javaType 至 jdbcType 的转换;
- 二是完成 jdbcType 至 javaType 的转换,体现为
setParameter() 和getResult() 两个方法,分别代表设置 sql 问号占位符参数和获取列查询结果。
MyBatis 映射文件中,如果 A 标签通过 include 引用了 B 标签的内容,请问,B 标签能否定义在 A 标签的后面,还是说必须定义在 A 标签的前面?
虽然 MyBatis 解析 xml 映射文件是按照顺序解析的,但是,被引用的 B 标签依然可以定义在任何地方,MyBatis 都可以正确识别。
原理是,MyBatis 解析 A 标签,发现 A 标签引用了 B 标签,但是 B 标签尚未解析到,尚不存在,此时,MyBatis 会将 A 标签标记为未解析状态,然后继续解析余下的标签,包含 B 标签,待所有标签解析完毕,MyBatis 会重新解析那些被标记为未解析的标签,此时再解析 A 标签时,B 标签已经存在,A 标签也就可以正常解析完成了。
简述 MyBatis 的 xml 映射文件和 MyBatis 内部数据结构之间的映射关系?
MyBatis 将所有 xml 配置信息都封装到 All-In-One 重量级对象 Configuration 内部。在 xml 映射文件中, <parameterMap> 标签会被解析为 ParameterMap 对象,其每个子元素会被解析为 ParameterMapping 对象。 <resultMap> 标签会被解析为 ResultMap 对象,其每个子元素会被解析为 ResultMapping 对象。每一个 <select>、<insert>、<update>、<delete> 标签均会被解析为 MappedStatement 对象,标签内的 sql 会被解析为 BoundSql 对象。
为什么说 MyBatis 是半自动 ORM 映射工具?它与全自动的区别在哪里?
Hibernate 属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。而 MyBatis 在查询关联对象或关联集合对象时,需要手动编写 sql 来完成,所以,称之为半自动 ORM 映射工具。
Netty
Epoll事件轮询模型
epoll_create:在selector内部创建一个epoll实例
epoll实例调用epoll_ctl方法监听channel,有事件发生则放入就绪事件列表rdlist
epoll_wait方法监听就绪事件列表,有事件则处理,没有则阻塞
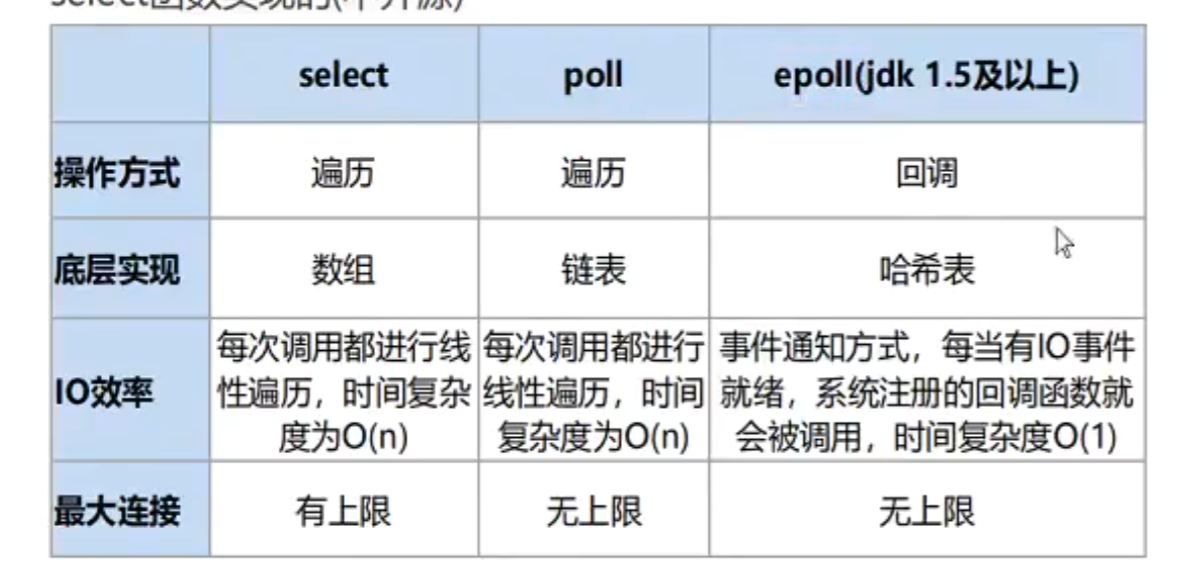
BIO,NIO和AIO有什么区别?
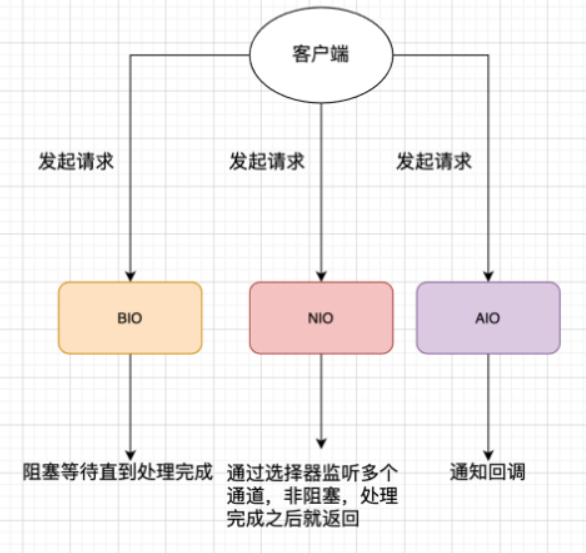
- BIO (Blocking I/O): 同步阻塞 I/O 模式,数据的读取写入必须阻塞在一个线程内
等待其完成。在客户端连接数量不高的情况下,是没问题的。但是,当面对十万
甚至百万级连接的时候,传统的 BIO 模型是无能为力的。 - NIO (Non-blocking/New I/O): NIO 是一种同步非阻塞的 I/O 模型,于 Java 1.4
中引入,对应 java.nio 包,提供了 Channel , Selector , Buffer
等抽象。NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它支持面向缓
冲的,基于通道的 I/O 操作方法。 NIO 提供了与传统 BIO 模型中的 Socket
和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChann
el 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。对于高
负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发 - AIO (Asynchronous I/O): AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版
NIO 2,它是异步非阻塞的 IO 模型。异步 IO 是基于事件和回调机制实现的,也就
是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通
知相应的线程进行后续的操作。AIO 是异步 IO 的缩写,虽然 NIO 在网络操作中,
提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的
业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操
作,IO 操作本身是同步的。Netty 之前也尝试使用过 AIO,不过又放弃了
Netty是什么?
- Netty 是一个 基于 NIO 的 client-server(客户端服务器)框架,使用它可以快速简
单地开发网络应用程序。 - 它极大地简化并优化了 TCP 和 UDP 套接字服务器等网络编程,并且性能、安全
性等很多方面甚至都要更好。 - 支持多种协议 如 FTP,SMTP,HTTP 以及各种二进制和基于文本的传统协议。
用官方的总结就是:Netty 成功地找到了一种在不妥协可维护性和性能的情况下实现易
于开发,性能,稳定性和灵活性的方法。
为什么要用 Netty 呢?
因为 Netty 具有下面这些优点,并且相比于直接使用 JDK 自带的 NIO 相关的
API 来说更加易用。
- 统一的 API,支持多种传输类型,阻塞和非阻塞的。
- 简单而强大的线程模型。
- 自带编解码器解决 TCP 粘包/拆包问题。
- 自带各种协议栈。
- 真正的无连接数据包套接字支持。
- 比直接使用 Java 核心 API 有更高的吞吐量、更低的延迟、更低的资源消耗和更少
的内存复制。 - 安全性不错,有完整的 SSL/TLS 以及 StartTLS 支持。
- 社区活跃
- 成熟稳定,经历了大型项目的使用和考验,而且很多开源项目都使用到了
Netty, 比如我们经常接触的 Dubbo、RocketMQ 等等。 - .....
Netty为啥不直接用 NIO 呢
主要是因为 NIO 的编程模型复杂而且存在一些 BUG,并且对编程功底要求比较高
而且,NIO 在面对断连重连、包丢失、粘包等问题时处理过程非常复杂。Netty 的出现
正是为了解决这些问题,更多关于 Netty 的特点可以看下面的内容
能不能通俗地说一下使用 Netty 可以做什么事情
netty的应用场景?
理论上来说,NIO 可以做的事情 ,使用Netty 都可以做并且更好。Netty 主要用来做网络通信 :
- 作为 RPC 框架的网络通信工具 : 我们在分布式系统中,不同服务节点之间经常
需要相互调用,这个时候就需要 RPC 框架了。不同服务节点的通信是如何做的
呢?可以使用 Netty 来做。比如我调用另外一个节点的方法的话,至少是要让对
方知道我调用的是哪个类中的哪个方法以及相关参数吧! - 实现一个自己的 HTTP 服务器 :通过 Netty 我们可以自己实现一个简单的 HTTP
服务器,这个大家应该不陌生。说到 HTTP 服务器的话,作为 Java 后端开发,我
们一般使用 Tomcat 比较多。一个最基本的 HTTP 服务器可要以处理常见的
HTTP Method 的请求,比如 POST 请求、GET 请求等等。 - 实现一个即时通讯系统 : 使用 Netty 我们可以实现一个可以聊天类似微信的即时
通讯系统,这方面的开源项目还蛮多的,可以自行去 Github 找一找。 - 实现消息推送系统 :市面上有很多消息推送系统都是基于 Netty 来做的。
那些开源项目用到了 Netty?
Dubbo、RocketMQ、Elasticsearch、gRPC 等等都用到了Netty
Netty 核心组件有哪些?分别有什么作用
Bytebuf(字节容器)
网络通信最终都是通过字节流进行传输的。 ByteBuf 就是 Netty 提供的一个字节容器,其内部是一个字节数组。 当我们通过 Netty 传输数据的时候,就是通过 ByteBuf 进行的
我们可以将 ByteBuf 看作是 Netty 对 Java NIO 提供了 ByteBuffer 字节容器的封装和抽象。
为什么不直接使用 Java NIO 提供的 ByteBuffer呢?
因为 ByteBuffer 这个类使用起来过于复杂和繁琐。
Bootstrap 和 ServerBootstrap(启动引导类)
Bootstrap 是客户端的启动引导类/辅助类,具体使用方法如下:
ServerBootstrap 是服务端的启动引导类/辅助类,具体使用方法如下:
从上面的示例中,我们可以看出:
- Bootstrap 通常使用 connect() 方法连接到远程的主机和端口,作为一
个 Netty TCP 协议通信中的客户端。另外, Bootstrap 也可以通过 bind()
方法绑定本地的一个端口,作为 UDP 协议通信中的一端。 - ServerBootstrap 通常使用 bind() 方法绑定本地的端口上,然后等待客
户端的连接。 - Bootstrap 只需要配置一个线程组— EventLoopGroup ,而 ServerBoo
tstrap 需要配置两个线程组— EventLoopGroup ,一个用于接收连接,一
个用于具体的 IO 处理。
Channel(网络操作抽象类)
Channel 接口是 Netty 对网络操作抽象类。通过 Channel 我们可以进行 I/O 操
作。
一旦客户端成功连接服务端,就会新建一个 Channel 同该用户端进行绑定,示例代
码如下:
比较常用的 Channel 接口实现类是 :
NioServerSocketChannel (服务端)
NioSocketChannel (客户端)
这两个 Channel 可以和 BIO 编程模型中的 ServerSocket 以及 Socket 两个
概念对应上。
EventLoop(事件循环)
这么说吧! EventLoop (事件循环)接口可以说是 Netty 中最核心的概念了!
《Netty 实战》这本书是这样介绍它的:
EventLoop定义了 Netty 的核心抽象,用于处理连接的生命周期中所发生的事
件
EventLoop 的主要作用实际就是责监听网络事件并调用事件处理器进行相关 I/O 操作(读写)的处理。
那 Channel 和 EventLoop 直接有啥联系呢?
Channel 为 Netty 网络操作(读写等操作)抽象类, EventLoop 负责处理注册到
其上的 Channel 的 I/O 操作,两者配合进行 I/O 操作。
EventLoopGroup 包含多个 EventLoop (每一个 EventLoop 通常内部包含
一个线程),它管理着所有的 EventLoop 的生命周期。
并且, EventLoop 处理的 I/O 事件都将在它专有的 Thread 上被处理,即 Thr
ead 和 EventLoop 属于 1 : 1 的关系,从而保证线程安全。
下图是 Netty NIO 模型对应的 EventLoop 模型。通过这个图应该可以将 Eventlo
opGroup 、 EventLoop 、 Channel 三者联系起来
ChannelHandler(消息处理器) 和 ChannelPipeline(ChannelHandler 对象链表)
ChannelHandler 是消息的具体处理器,主要负责处理客户端/服务端接收和发送的数据。
当 Channel 被创建时,它会被自动地分配到它专属的 ChannelPipeline 。 一个 Channel 包含一个 ChannelPipeline 。 ChannelPipeline 为 ChannelHandler 的链,一个 pipeline 上可以有多个 ChannelHandler 。我们可以在 ChannelPipeline 上通过 addLast() 方法添加一个或者多个 ChannelHandler (一个数据或者事件可能会被多个 Handler 处理) 。当一个 ChannelHandler 处理完之后就将数据交给下一个 ChannelHandler 。当 ChannelHandler 被添加到的 ChannelPipeline 它得到一个 ChannelHandlerContext ,它代表一个 ChannelHandler 和 ChannelPipeline 之间的“绑定”。 ChannelPipeline 通过 ChannelHandlerContext 来间接管理 ChannelHandler
ChannelFuture(操作执行结果)
Netty 中所有的 I/O 操作都为异步的,我们不能立刻得到操作是否执行成功。
不过,你可以通过 ChannelFuture 接口的 addListener() 方法注册一个 ChannelFutureListener ,当操作执行成功或者失败时,监听就会自动触发返回结果。
并且,你还可以通过 ChannelFuture 的 channel() 方法获取连接相关联的 Channel 。
另外,我们还可以通过 ChannelFuture 接口的 sync() 方法让异步的操作编程同步的
NioEventLoopGroup 默认的构造函数会起多少线程?
Reactor 线程模型
Netty 线程模型了解么
Netty 服务端和客户端的启动过程了解么?
什么是 TCP 粘包/拆包?有什么解决办法呢
什么是 TCP 粘包/拆包?有什么解决办法呢
Netty 的零拷贝了解么?
附加补充









为什么SpringBoot项目不需要安装而外的Tomcat?
源码阅读
String
Integer
ArrayList
LinkedList
HashMap
TreeMap
LinkedHashMap
ConcurrentHashMap

 浙公网安备 33010602011771号
浙公网安备 33010602011771号