深度之眼(十四)——Python:文件、异常和模块
文章目录
关于C语言的文件IO,可以看我之前写的文章,有个专栏专门讲了
系统编程 文件IO
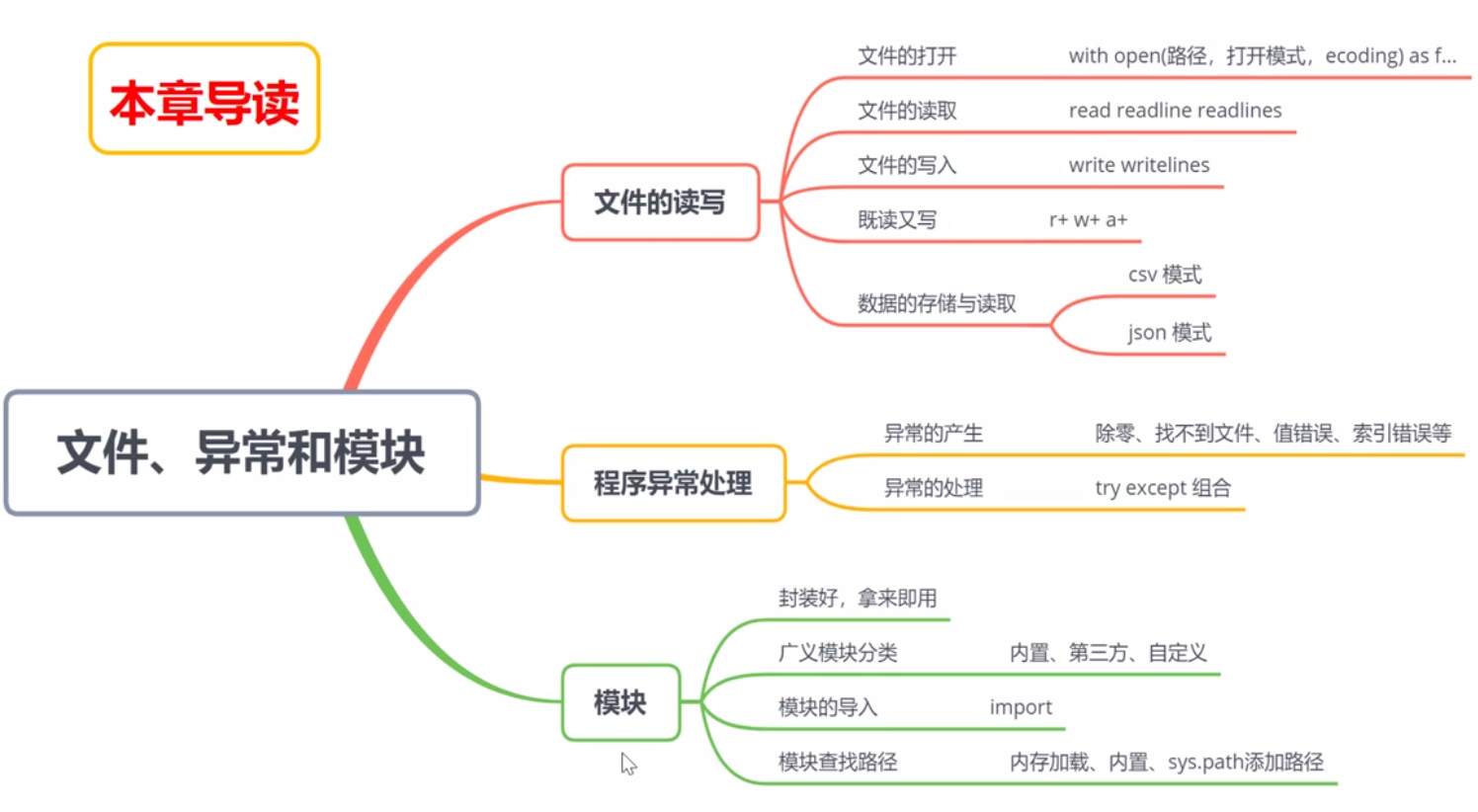
零、导读
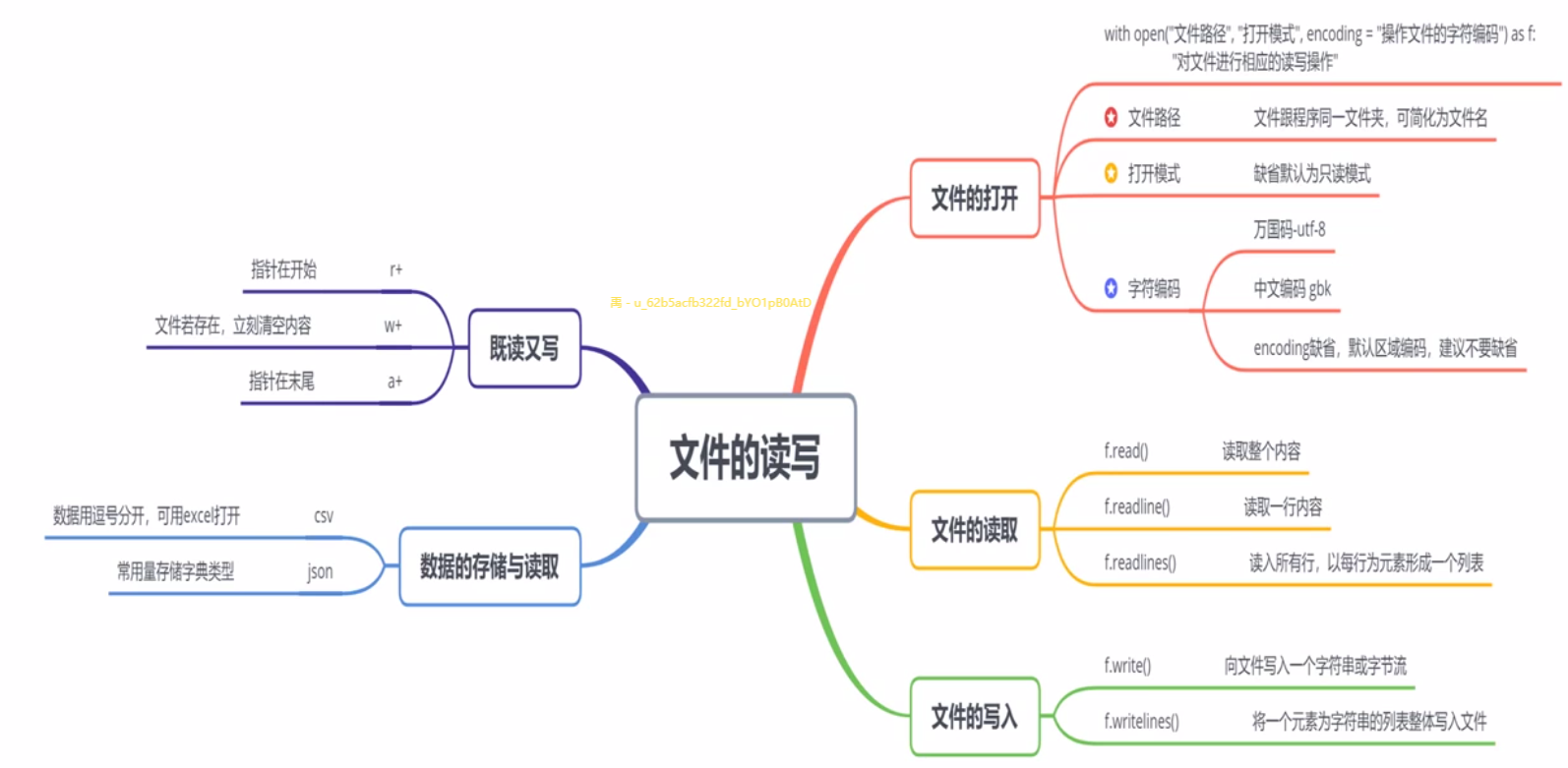
8.1 文件读写
8.1.1 文件的打开
- 文件的打开通用格式
with open("文件路径","打开模式", encoding="操作文件的字符编码")as f:
"对文件进行相应的读写操作"
使用with块的好处,执行完毕后,自动对文件进程close操作
- 例1:一个简单的文件读取
with open("C:/Users/DELL/Desktop/1.txt","r",encoding = "utf-8")as f: #第一步,打开文件
text = f.read() #第二步,读取文件
print(text)
上面是最终版
这里遇到两个问题
问题一:python报错:‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape
解决:在文件夹中复制地址时,文件夹中的地址是用\来分隔不同文件夹的,而Python识别地址时只能识别用/分隔的地址。我一开始是:C:\Users\DELL\Desktop\1.txt所以就报错了
问题二,打印出来的文字时乱码,忽然想起来我的txt是UTF-8模式,不是gbk
解决:修改encoding=UTF-8

1. 文件路径
- 完整路径,如上例
- 程序与文件在同一文件夹,可简化成文件名
with open("1.txt","r",encoding = "utf-8")as f: #第一步,打开文件
text = f.read() #第二步,读取文件
print(text)
2. 打开模式

- ** 打开模式缺省,默认为只读模式**
3. 字符编码
-
万国码 utf-8
包含全世界所有国家需要用到的字符 -
中文编码 gbk
专门解决中文编码问题 -
windoews系统下,如果缺省,则默认为gbk(所在区域编码)
-
为清楚起见,除了处理二进制文件,建议不要缺省encoding
8.1.2 文件的读取
1.读取整个内容——f.read()

2、逐行进行读取——f.readline()
with open("C:/Users/DELL/Desktop/1.txt","r",encoding = "utf-8")as f:
while True:
text = f.readline()
if not text:
break
else:
print(text,end="") #保留原文本的换行,使print()的换行不起作用
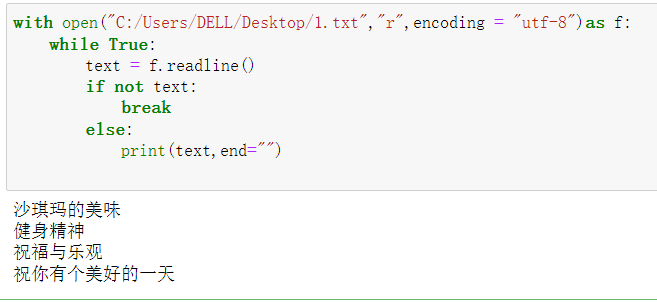
文档中的空行,实际上是有字符的,而文件末尾是没有的
3. 读入所有行,以每行为元素形成一个列表——f.readlines()
with open("C:/Users/DELL/Desktop/1.txt","r",encoding = "utf-8")as f:
text = f.readlines()
print(text)

with open("C:/Users/DELL/Desktop/1.txt","r",encoding = "utf-8")as f:
for text in f.readlines():
print(text)
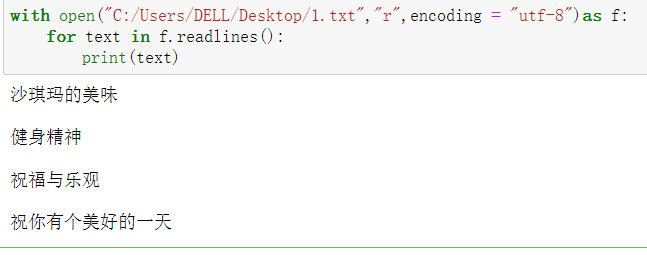
4、文本文件读取小结
文件比较大时,read(和readlines()占用内存过大, 不建议使用
readline用起来又不太方便
with open("C:/Users/DELL/Desktop/1.txt","r",encoding = "utf-8")as f:
for text in f:
print(text)
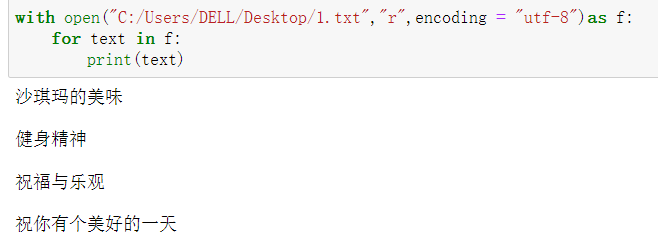
5.二进制文件
with open("C:/Users/DELL/Desktop/1.txt","rb")as f:
print(len(f.readlines()))
4
8.1.3 文件的写入
1、向文件写入一个字符串或字节流(二进制)—— f.write()
with open("C:/Users/DELL/Desktop/1.txt","w",encoding = "utf-8")as f:
f.write("姑娘你别哭泣\n")
f.write("我俩还在一起\n")
f.write("今天的欢乐\n")
f.write("将是明天创痛的回忆\n")
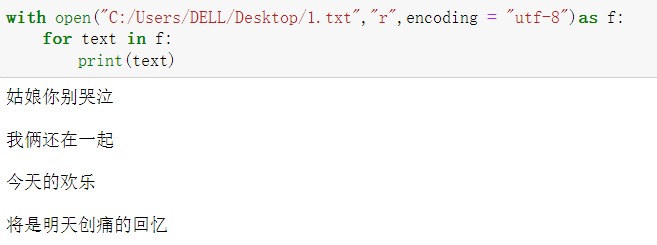
如果文件存在,新写入内容会覆盖掉原内容,一定要注意! ! !
2.追加模式—— “a”
with open("C:/Users/DELL/Desktop/1.txt","a",encoding = "utf-8")as f:
f.write("\n")
f.write("春天刮着风\n")
f.write("秋天下着雨\n")
f.write("春风秋雨多少海誓山盟随风远去\n")

3.将一个元素为字符串的列表整体写入文件——f.writelines()
ls = ['\n','沙琪玛的美味\n', '健身精神\n', '祝福与乐观\n', '祝你有个美好的一天']
with open("C:/Users/DELL/Desktop/1.txt","a",encoding = "utf-8")as f:
f.writelines(ls)

8.1.4 既读又写
- “r+”
![在这里插入图片描述]()
- “w+”
![在这里插入图片描述]()
- “a+”
![在这里插入图片描述]()



8.1.5 数据的存储与读取
通用的数据格式,可以在不同语言中加载和存储
本节简单了解两种数据存储结构csv和json
-
csv格式
由逗号将数据分开的字符序列,可以由excel打开-
读取
![在这里插入图片描述]()
-
写入
![在这里插入图片描述]()
2. json格式
* 写入——dump()
![在这里插入图片描述]()
* 读取——load()  -



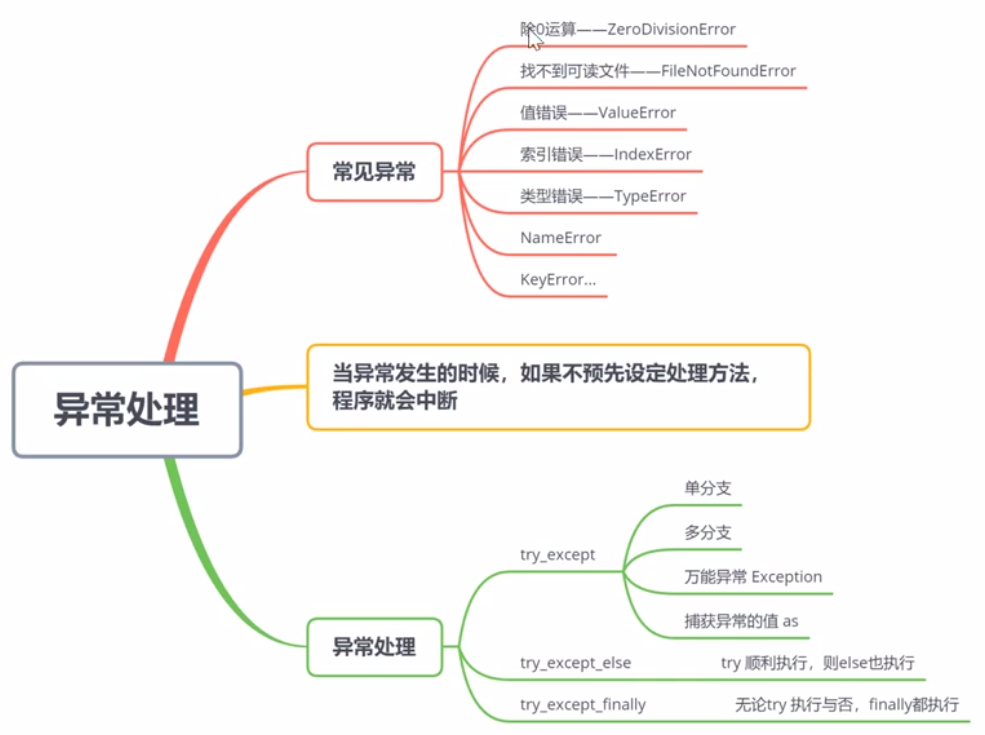
8.2 程序异常处理
8.2.1 常见异常的产生
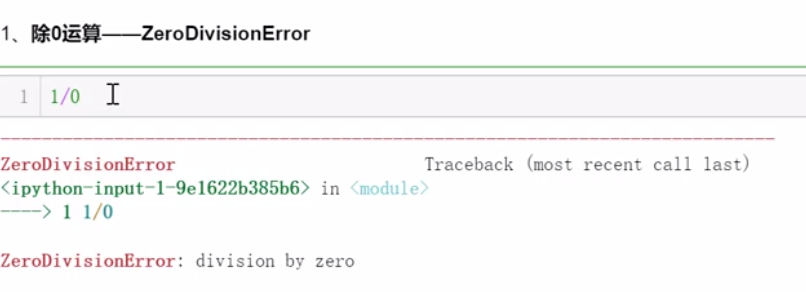
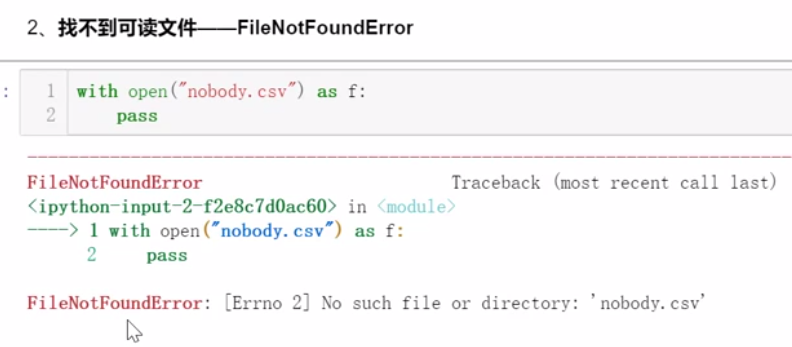
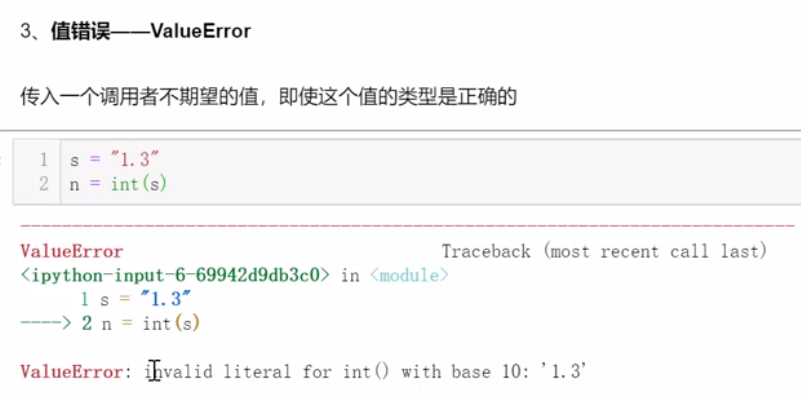
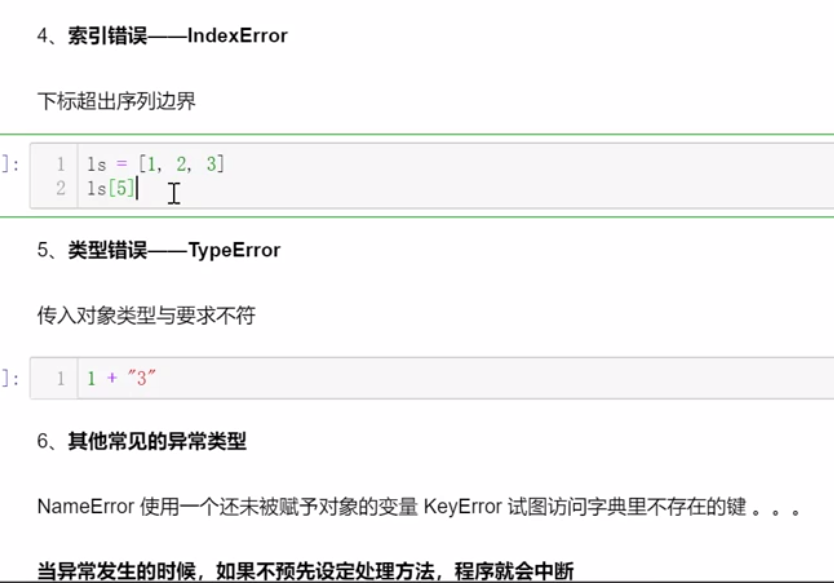
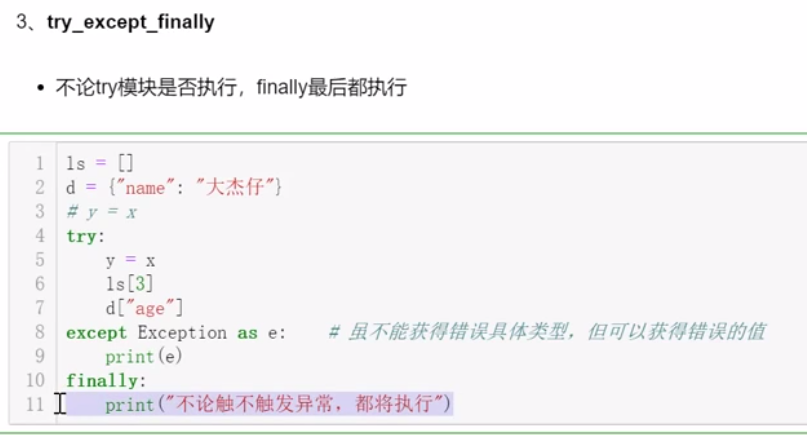
8.2.2 异常的处理





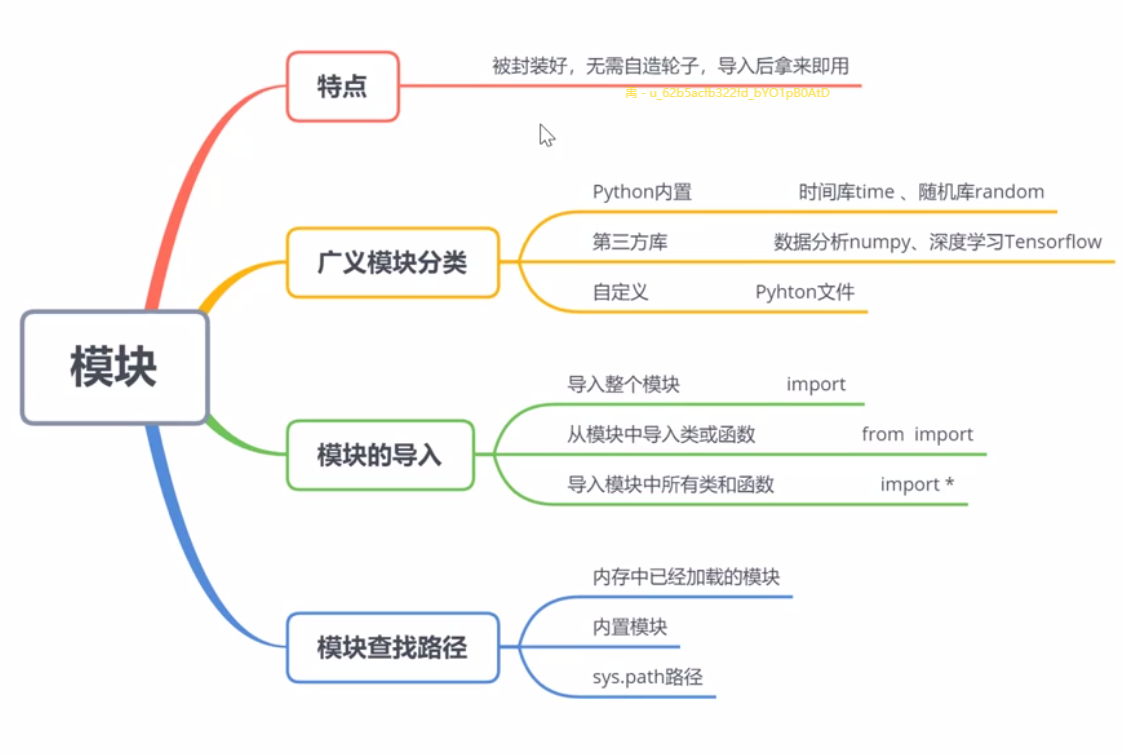
8.3 模块
已经被封装好
无需自己再“造轮子”
声明导入后,拿来即用
8.3.1广义模块分类
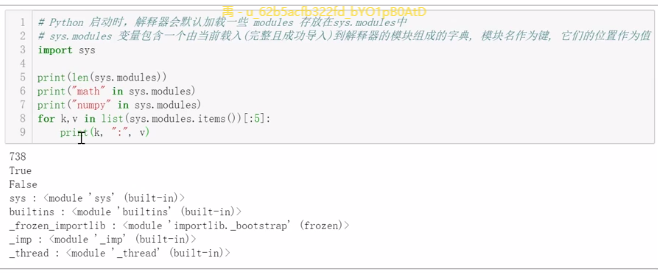
1. Python 内置
时间库time\随机库randoml 容器数据类型collection\迭代器函数itertools
2.第三方库
数据分析numpy. pandas\ 数据可视化matplotib机器学习scikitlearnl深度学习Tensorflow
3、自定义文件
* 单独py文件
* 包一多个py文件
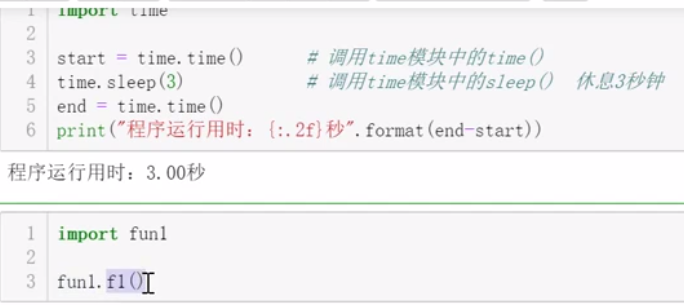
8.3.2 模块的导入
1.导入整个模块一 import 模块名
- 调用方式:模块名.函数名或类名
![在这里插入图片描述]()
2、从模块中导入类或函数一- from 模块import类名或函数名 - 调用方式:函数名或类名
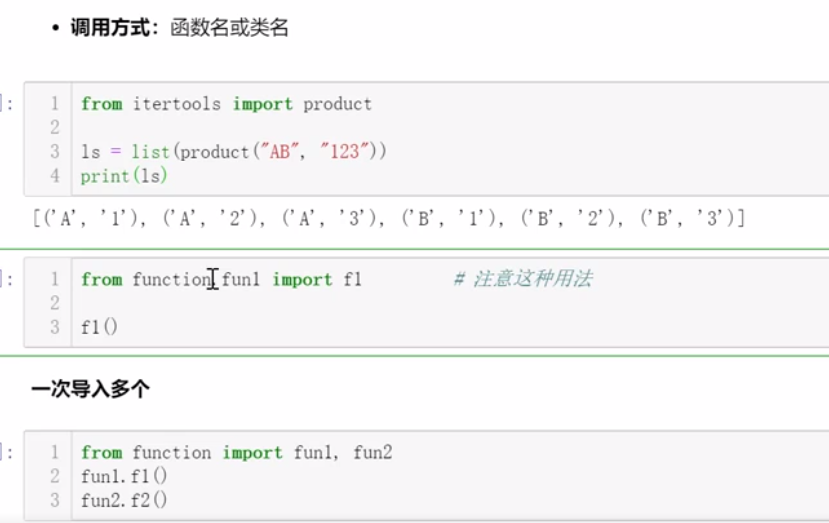
3、导入模块中所有的类和函数一-from 模块import *
●调用方式:函数名或类名

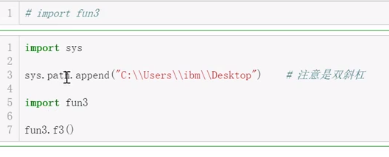
8.3.3 模块的查找路径
模块搜索查找顺序:
1.内存中已经加载的模块

-
内置模块
![在这里插入图片描述]()
-
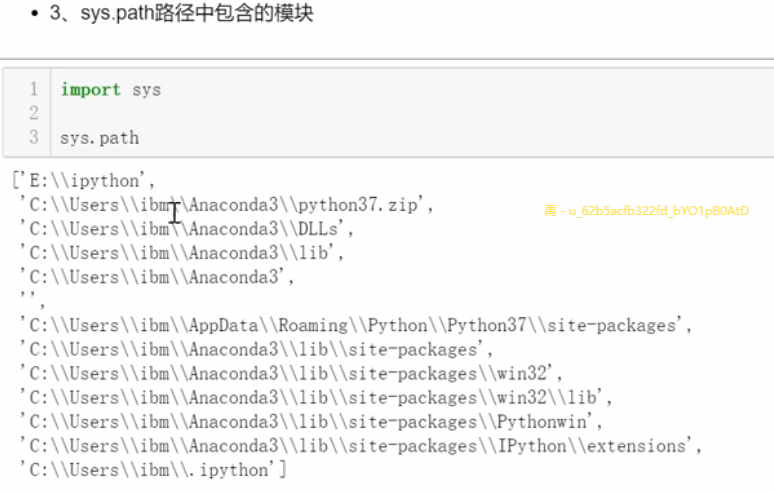
sys.path路径中包含的模块
![在这里插入图片描述]()
![在这里插入图片描述]()
总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号