
深度之眼(二十三)——Python:Sklearn库
文章目录
零、导读
scikit-learn库是当今最流行的机器学习算法库之一
可用来解决分类与回归问题
本章以鸢尾花数据集为例,简单了解八大传统机器学习分类算法的sk-learn实现
欲深入了解传统机器算法的原理和公式推导,请继续学习《统计学习方法》或《西瓜书》
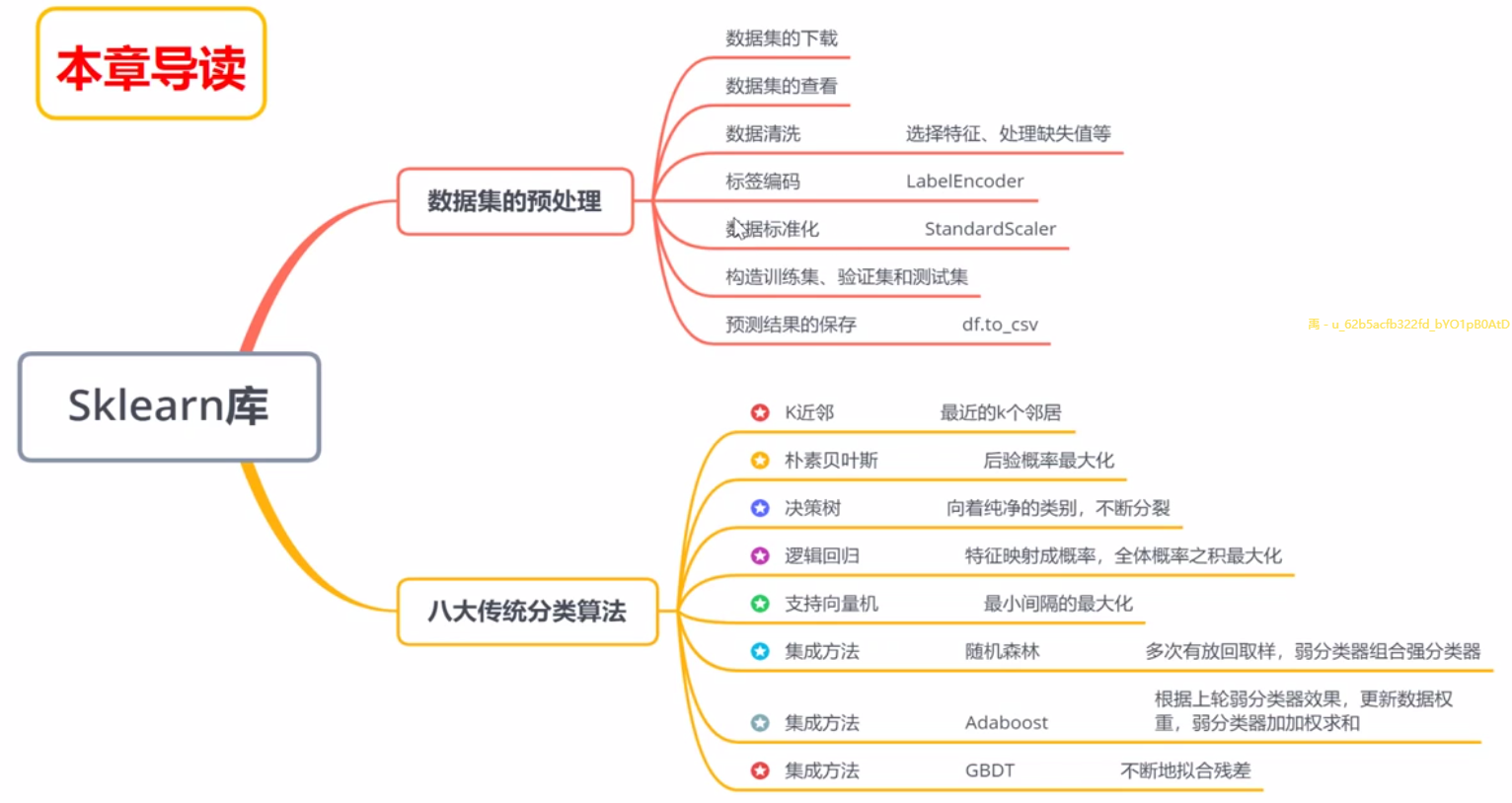
一、数据集的预处理(鸢尾花数据集为例)
(1)下载数据集
iris = sns.load_dataset("iris")
iris.head()
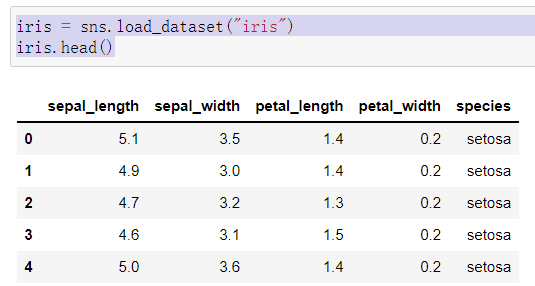
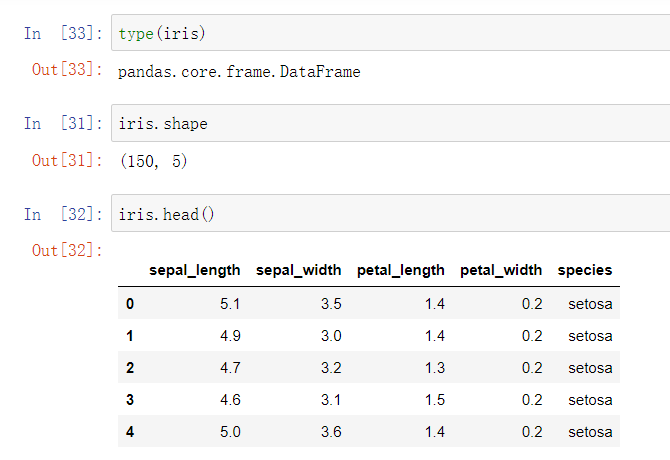
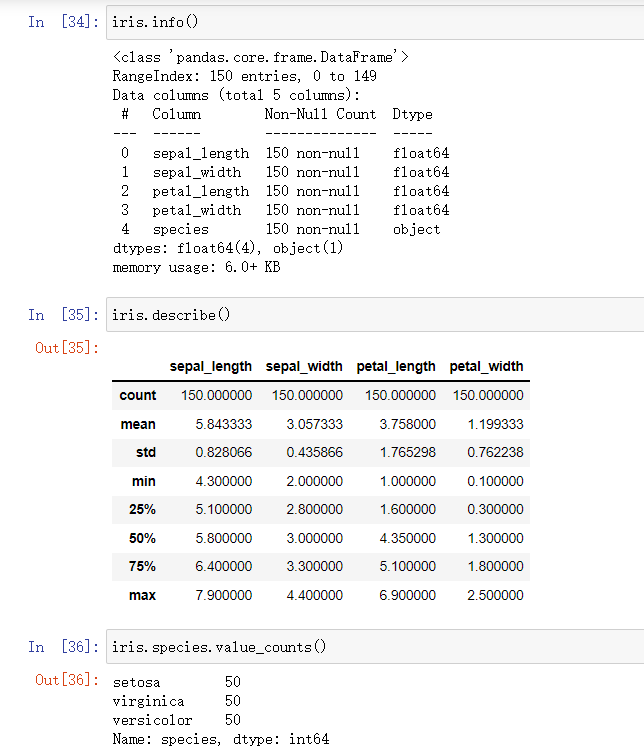
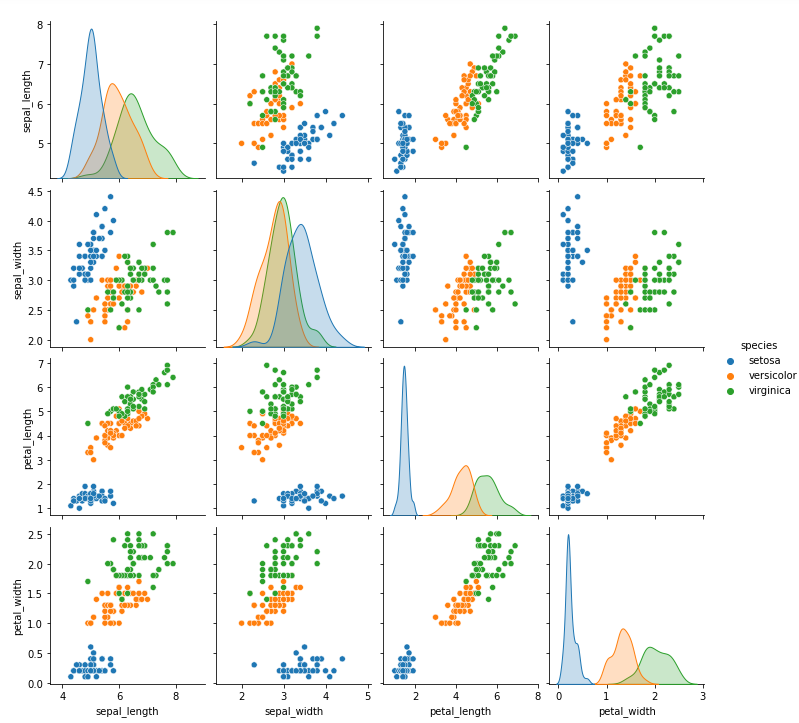
(2)查看数据集
sns.pairplot(data=iris,hue="species")
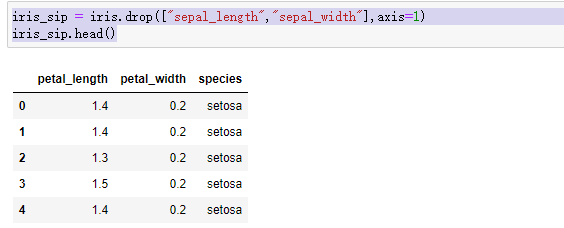
(3)标签清洗
iris_sip = iris.drop(["sepal_length","sepal_width"],axis=1)
iris_sip.head()
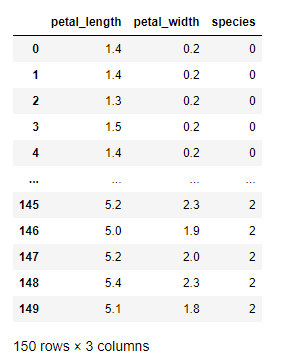
(4)标签编码
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
iris_sip["species"] = encoder.fit_transform(iris_sip["species"])
iris_sip
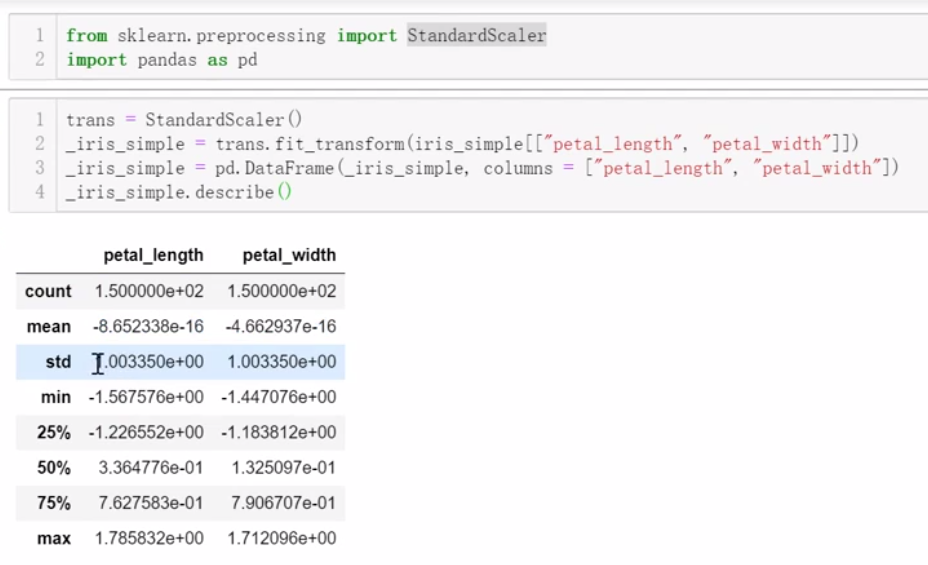
(5)数据集的标准化
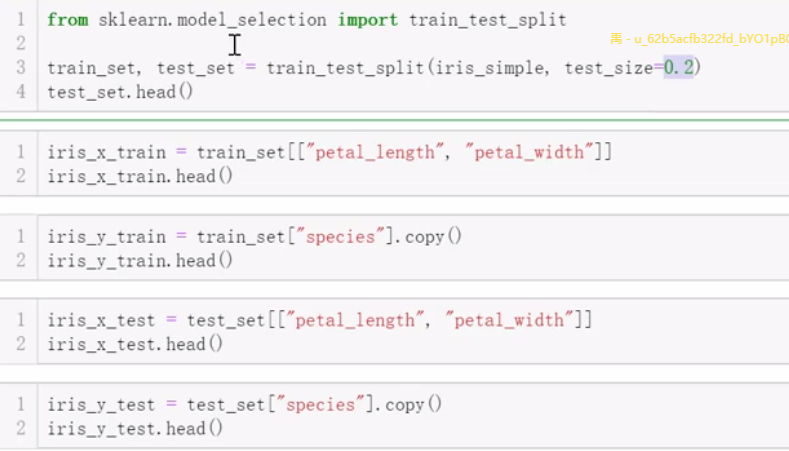
(6)构建训练集和测试集
80% 是训练集
20% 是测试集
将x和y分开
二、八大传统分类算法
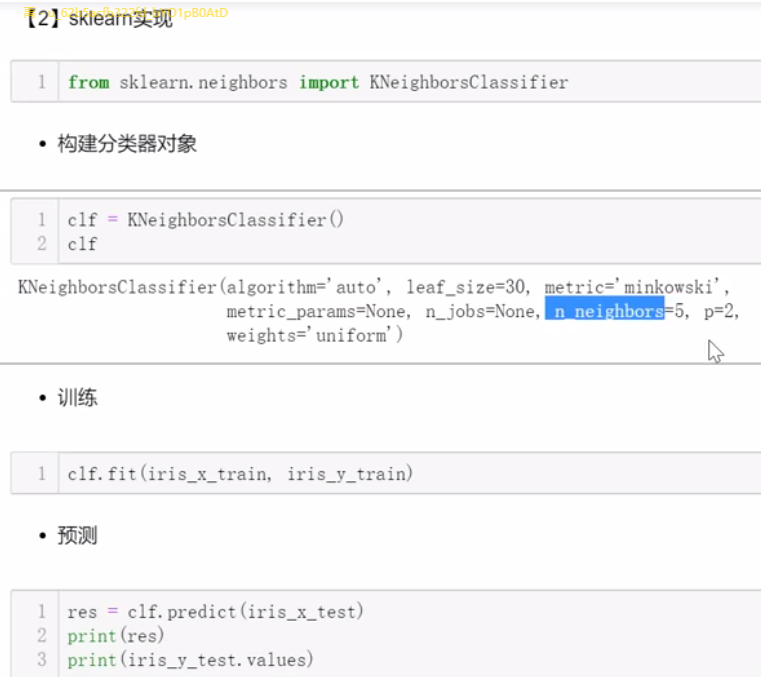
2.1 K邻近
[1]基本思想
与待预测点最近的训练数据集中的k个邻居
把k个近邻中最常见的类别预测为带预测点的类别
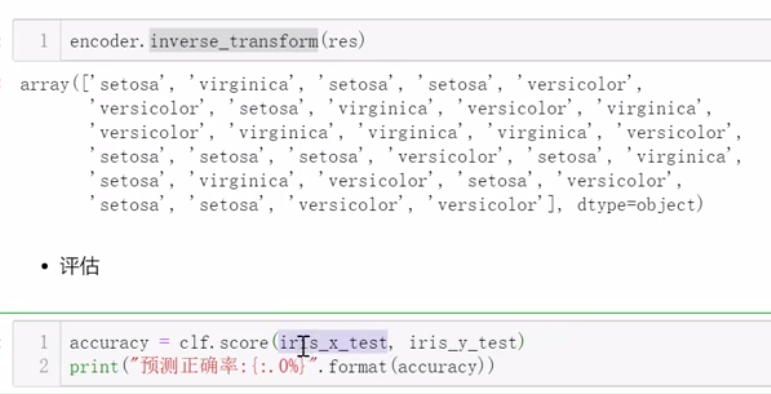

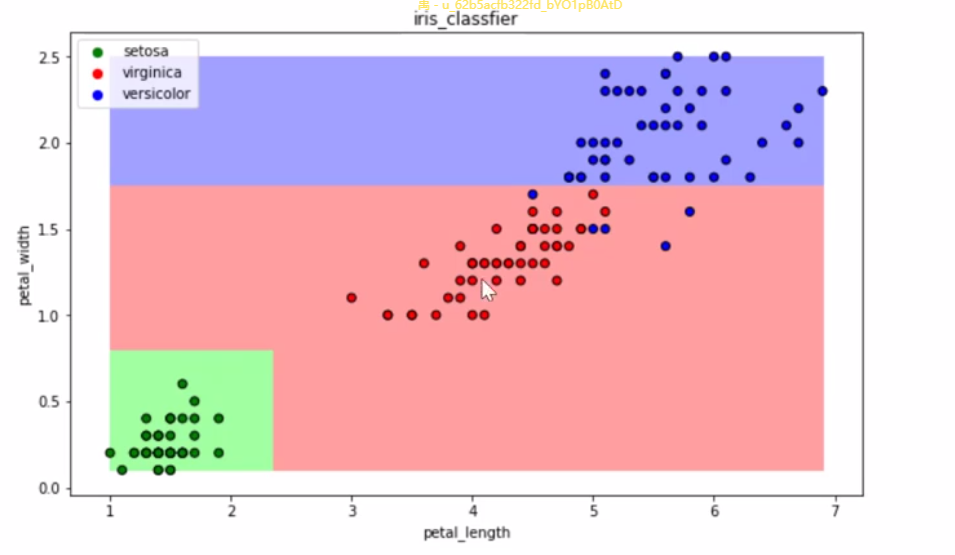
(5)可视化

2.2 朴素贝叶斯
[1]基本思想
当X=(x1, x2)发生的时候,哪一一个yk发生的概率最大
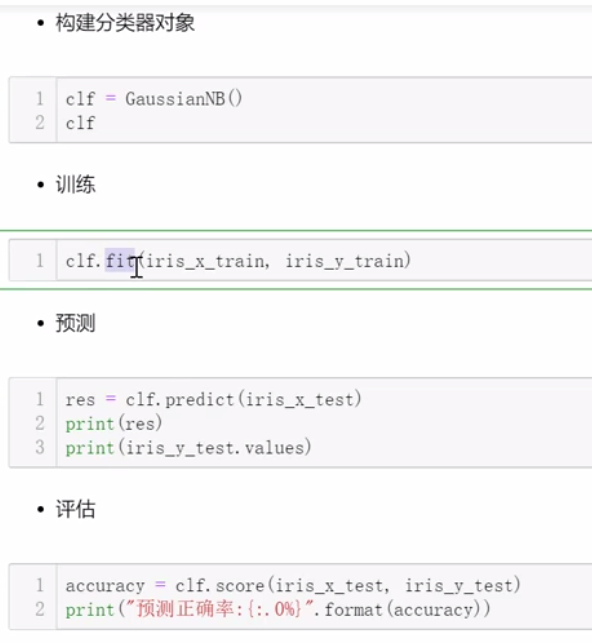
可视化
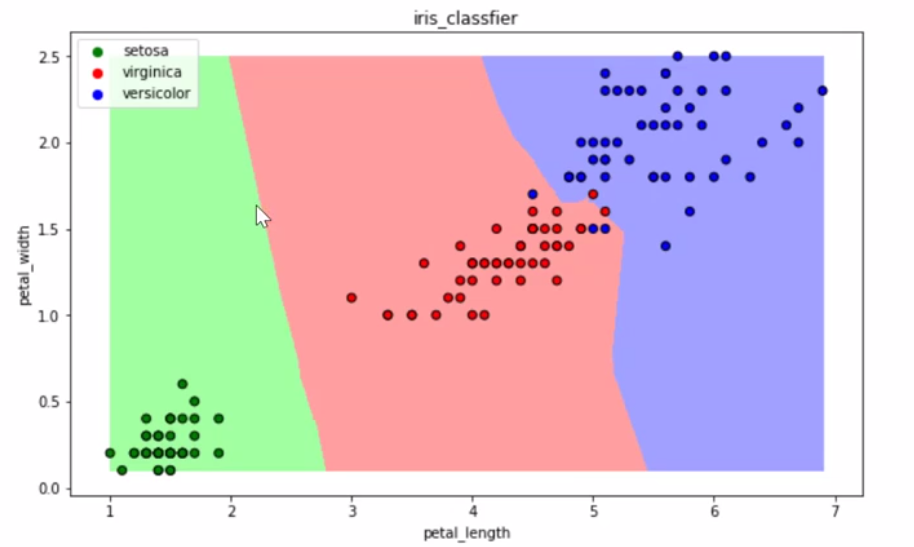
2.3 决策树
[1]基本思想
CART算法:每次通过一个特征,将数据尽可能的分为纯净的两类,递归的分下去
如果全部分开,会过拟合
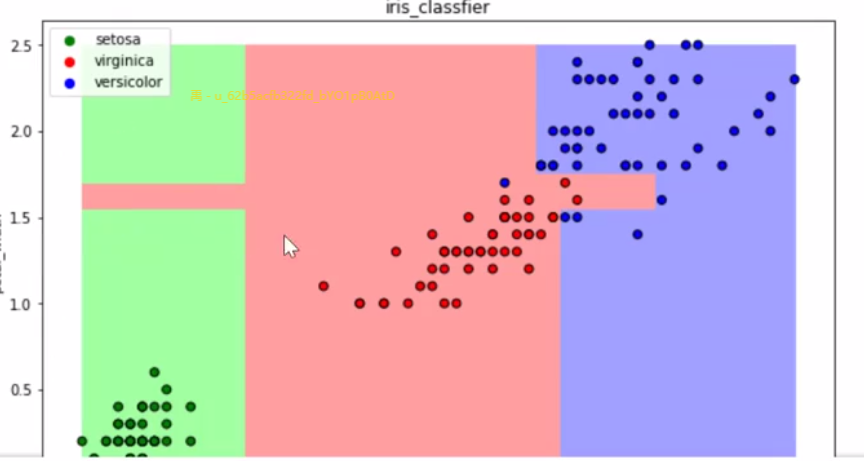
可视化
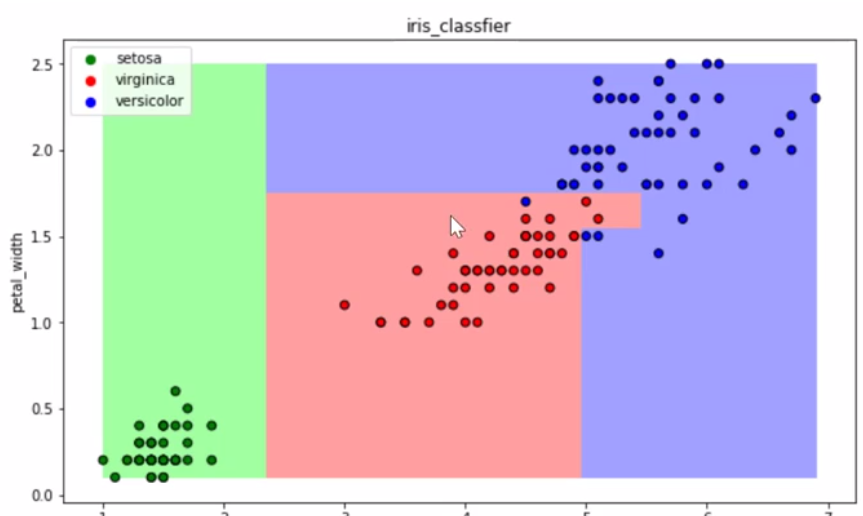
2.4 逻辑回归
[1]基本思想
一种解释:
训练:通过一个映射方式,将特征X= (x1, x2)映射成P(y=ck),求使得所有概率之积最大化的映射方式里的参数
预测:计算p(y=ck) 取概率最大的那个类别作为预测对象的分类
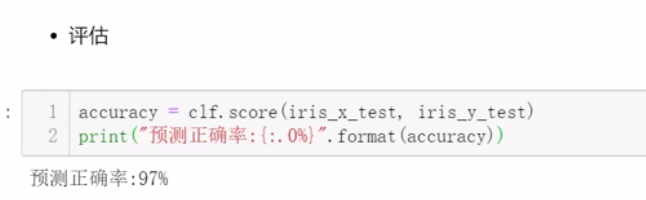
2.5 支持向量机
[1]基本思想
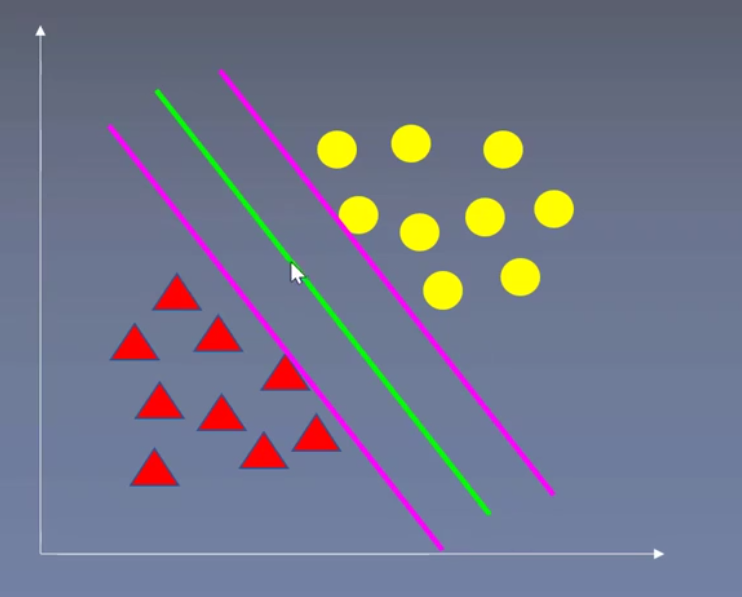
以二分类为例,假设数据可用完全分开:
用一个超平面将两类数据完全分开,且最近点到平面的距离最大
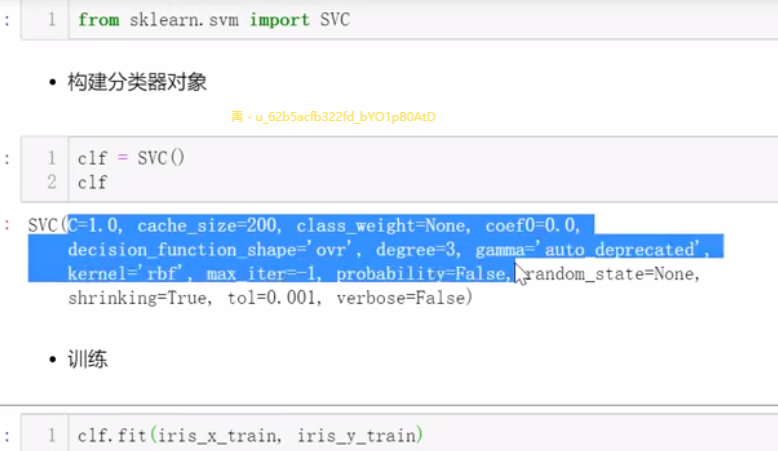
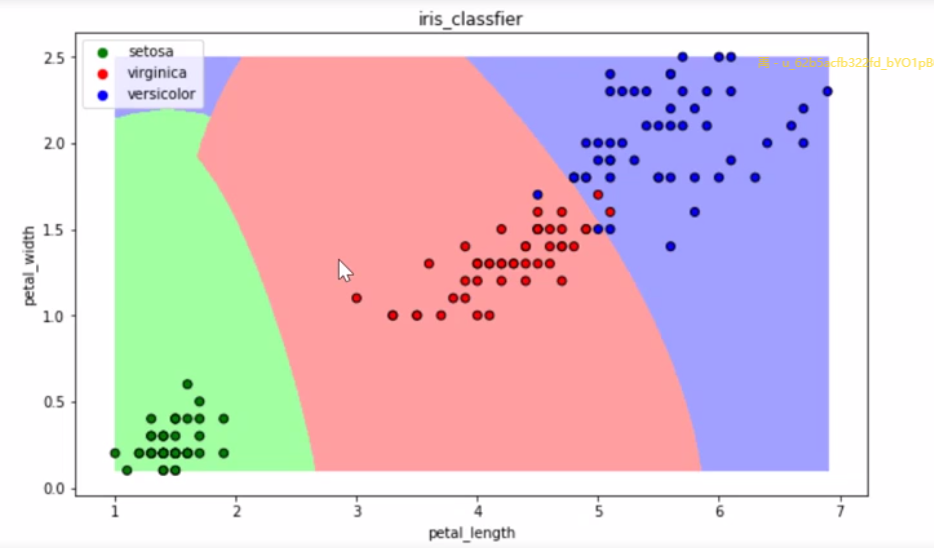
2.6 集成方法
2.6.1 随机森林
[1]基本思想
训练集m,有放回的随机抽取m个数据,构成一组,共抽取n组采样集
n组采样集训练得到n个弱分类器弱分类器-般用决策树或神经网络
将n个弱分类器进行组合得到强分类器
方法跟上面一样
2.6.2 Adaboost
[1]基本思想
训练集m,用初始数据权重训练得到第一个弱分类器, 根据误差率计算弱分类器系数,更新数据的权重
使用新的权重训练得到第二个弱分类器,以此类推
根据各自系数,将所有弱分类器加权求和获得强分类器
2.6.3 梯度提升树GBDT
[1]基本思想
训练集m,获得第一个弱分类歇,获得残差,然后不断地拟合残差
所有弱分类器相加得到强分类器

三、大杀器
[1] xgboost
GBDT的损失函数只对误差部分做负梯度(- -阶泰勒)展开
XGBoost损失函数对误差部分做二阶泰勒展开,更加准确,更快收敛
[2] lightgbm
微软:快速的,分布式的,高性能的基于决策树算法的梯度提升框架
速度更快
[3] stacking
堆叠或者叫模型融合
先建立几个简单的模型进行训练,第二级学习器会基于前级模型的预测结果进行再训练
[4]神经网络
自己看看网络文章吧
四、总结



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理