Zookeeper01——Zookeeper及其基本原理
本文开始将为各位带来 Zookeeper 方面的知识,由于个人计划原因,最近这几天写的知识点会很杂。但是仍会保证系列文章内的顺序性。关注我的公众号「Java面典」,每天 10:24 和你一起了解更多 Java 相关知识点。
什么是 Zookeeper
Zookeeper 是一个分布式协调服务。Zookeeper 提供了一个类似于 Linux 文件系统的树形结构(可认为是轻量级的内存文件系统,但只适合存少量信息,完全不适合存储大量文件或者大文件),同时提供了对于每个节点的监控与通知机制。可用于服务发现,分布式锁,分布式领导选举,配置管理等。
Zookeeper 角色
Zookeeper 集群是一个基于主从复制的高可用集群,每个服务器承担如下三种角色中的一种:
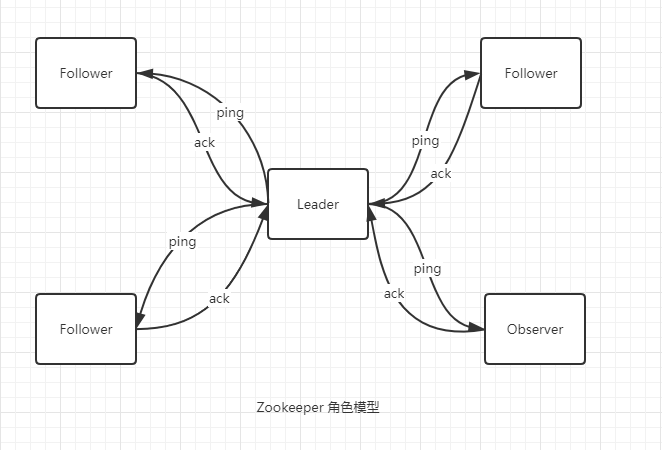
Leader
- 一个 Zookeeper 集群同一时间只会有一个实际工作的 Leader,它会发起并维护与各 Follwer 及 Observer 间的心跳;
- 所有的写操作必须要通过 Leader 完成再由 Leader 将写操作广播给其它服务器。只要有超过半数节点(不包括 observeer 节点)写入成功,该写请求就会被提交(类 2PC 协议)。
Follower
- 一个 Zookeeper 集群可能同时存在多个 Follower,它会响应 Leader 的心跳;
- Follower 可直接处理并返回客户端的读请求,同时会将写请求转发给 Leader 处理;
- 并且负责在 Leader 处理写请求时对请求进行投票。
Observer
Zookeeper 需保证高可用和强一致性,为了支持更多的客户端,需要增加更多 Server;Server 增多,投票阶段延迟增大,影响性能,所以引入了 Observer,Observer 不参与投票。
- 角色与 Follower 类似,但是无投票权;
- Observers 接受客户端的连接,并将写请求转发给 leader 节点。
工作原理
- Zookeeper 的核心是原子广播,这个机制保证了各个 Server 之间的同步。实现这个机制的协议叫做 Zab 协议。Zab 协议有两种模式,它们分别是恢复模式和广播模式;
- 当服务启动或者在 Leader 崩溃后,Zab 就进入了恢复模式,当新的 Leader 被选举出来,且大多数的 Server 完成了和 Leader 的状态同步以后,恢复模式就结束了(状态同步保证了 Leader 和 Server 具有相同的系统状态);
- 一旦 Leader 已经和多数的 Follower 进行了状态同步后,他就可以开始广播消息了,即进入广播状态。这时候当一个 Server 加入 Zookeeper 服务中,它会在恢复模式下启动,发现 Leader,并和 Leader 进行状态同步。待到同步结束,它也参与消息广播。Zookeeper 服务一直维持在 Broadcast 状态,直到 Leader 崩溃了或者 Leader 失去了大部分的 Follower 支持;
- 广播模式需要保证 proposal 被按顺序处理,因此 Zookeeper 采用了递增的事务 id 号(zxid)来保证。所有的提议(proposal)都在被提出的时候加上了 zxid;
- 实现中 zxid 是一个 64 为的数字,它高 32 位是 epoch 用来标识 Leader 关系是否改变,每次一个 Leader 被选出来,它都会有一个新的 epoch。低 32 位是个递增计数;
- 当 Leader 崩溃或者 Leader 失去大多数的 Follower,这时候 Zookeeper 进入恢复模式,恢复模式需要重新选举出一个新的 Leader,让所有的 Server 都恢复到一个正确的状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号