
Ollama环境搭建
首先我们需要安装Ollama,Ollama是一个用于本地管理和运行大模型的工具,能够简化模型的下载和调度操作。
进入Ollama官网(https://ollama.com)。
https://www.ollama.com/
https://github.com/ollama/ollama/releases/download/v0.5.7/OllamaSetup.exe
下载ollama框架
选择要安装的模型
接着返回Ollama官网,点击右上角的【Models】,再选择【deepseek-r1】。
然后命令行下载ollama模型中的deepseek-r1
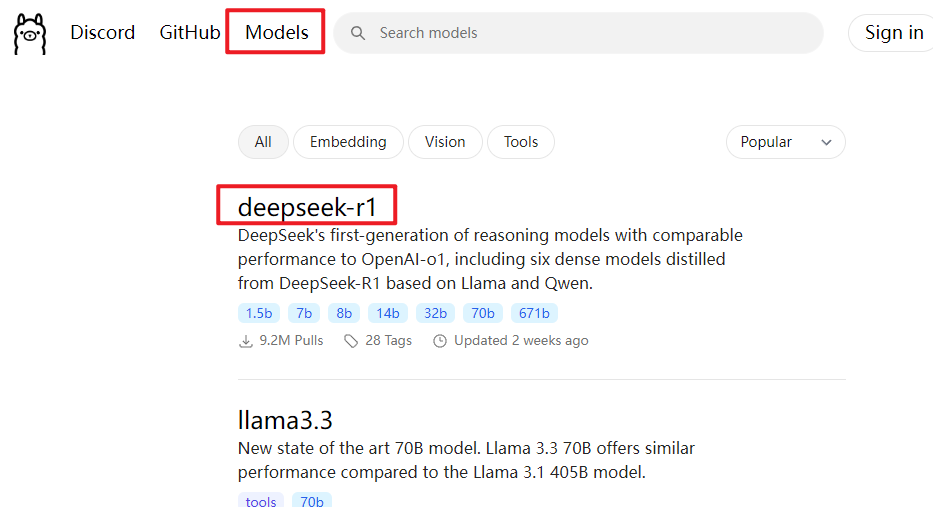
下拉可以看到多个参数版本,数字越大,模型参数越多,性能越强,对显存要求越高。
安装模型
在Windows系统中,按下【Win+R】弹出如下窗口👇
输入【cmd】,点击【确定】,打开命令行
在命令行中粘贴刚才复制的命令,按下回车键后,系统会自动开始下载模型。
等待下载完成即可。
下载过程中若发现速度突然变慢,试着关闭命令行再重新打开。
模型默认存储在c:\user\用户\.ollama|下面
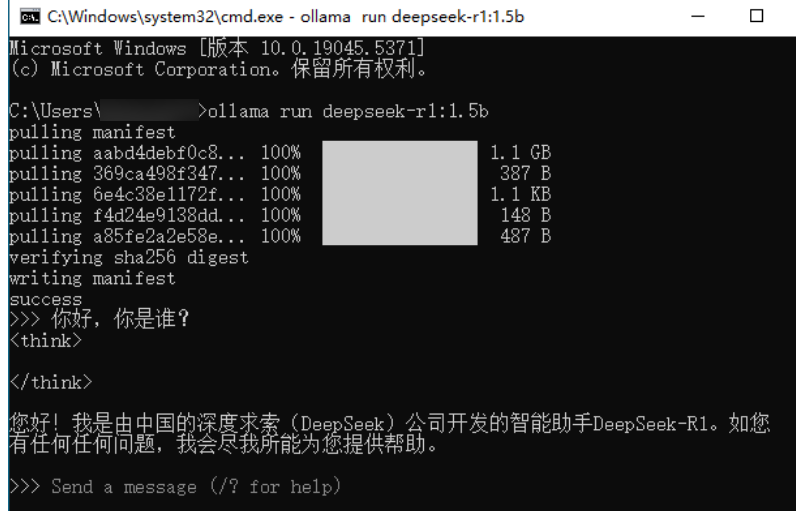
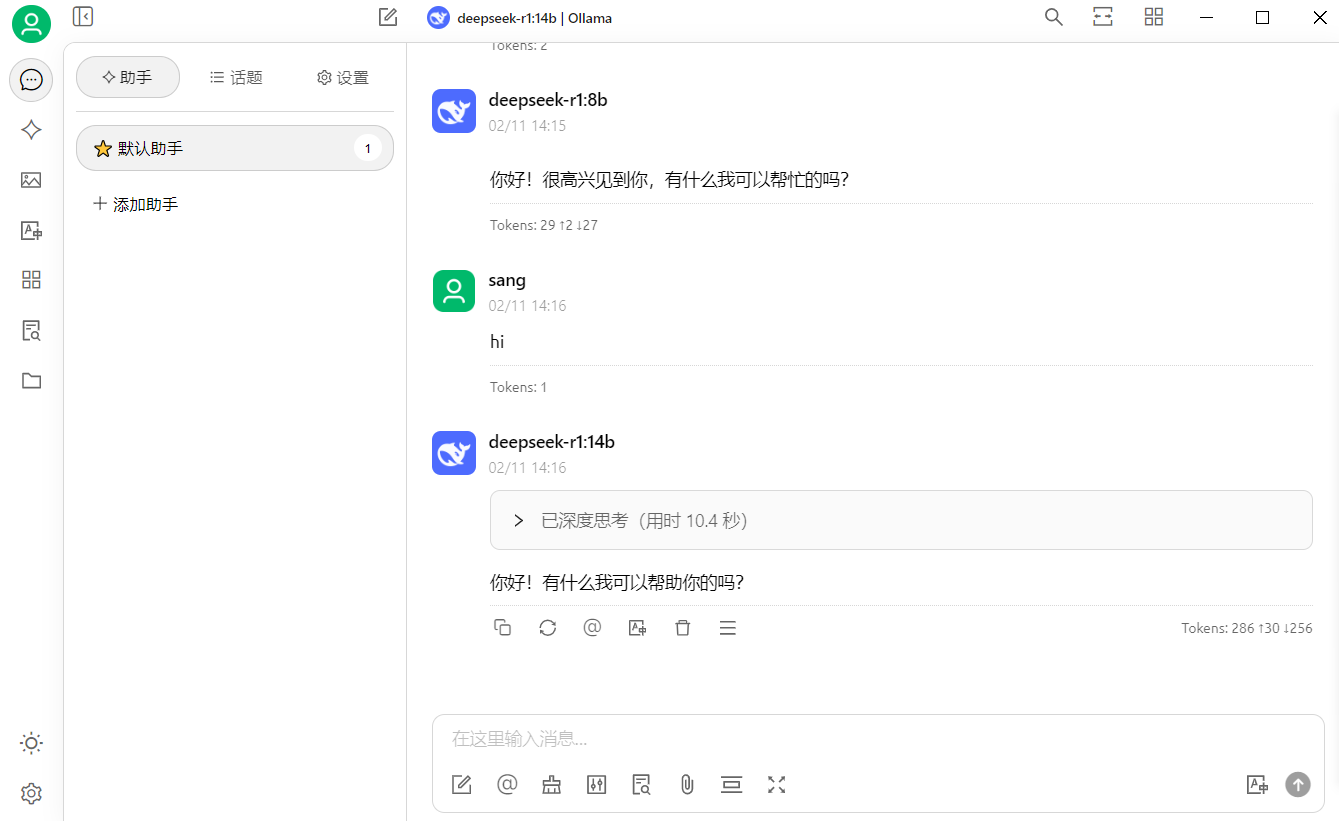
已经可以开始对话了
接下来可以考虑安装 Open-WebUI(需要docker环境)、安装 cherry-ai.com/download 、安装 https://anythingllm.com/desktop 三种都可以选择
cherry-ai.com
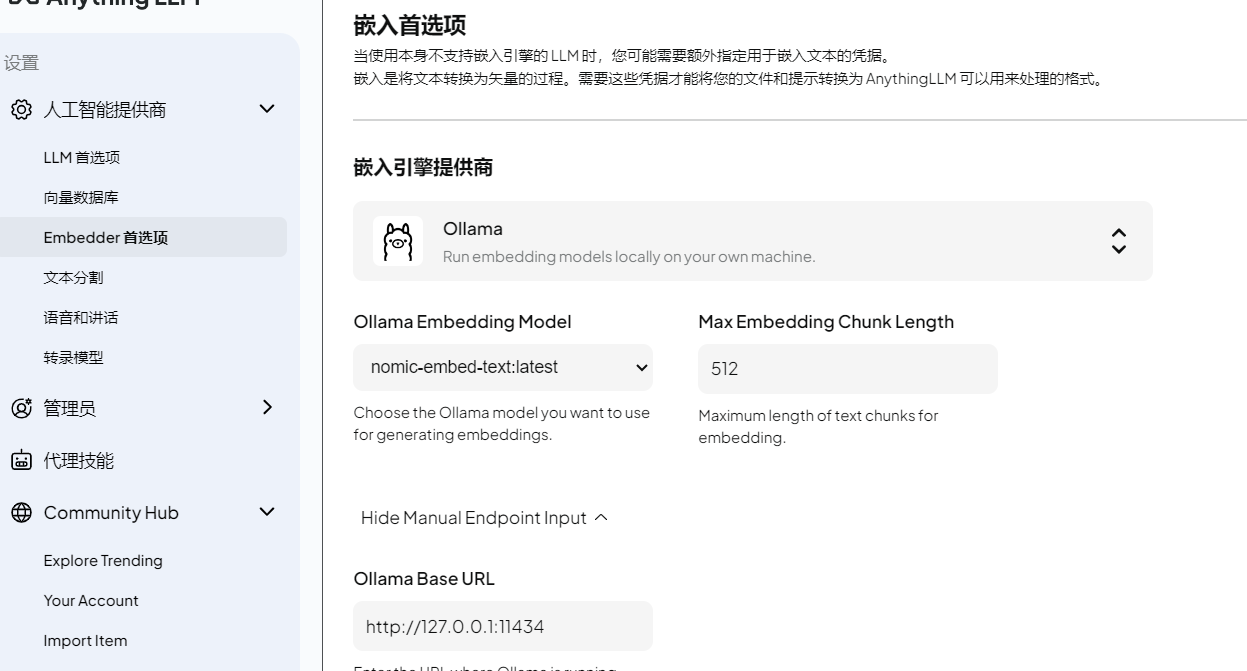
可以添加自己的知识库 ollama pull shaw/dmeta-embedding-zh
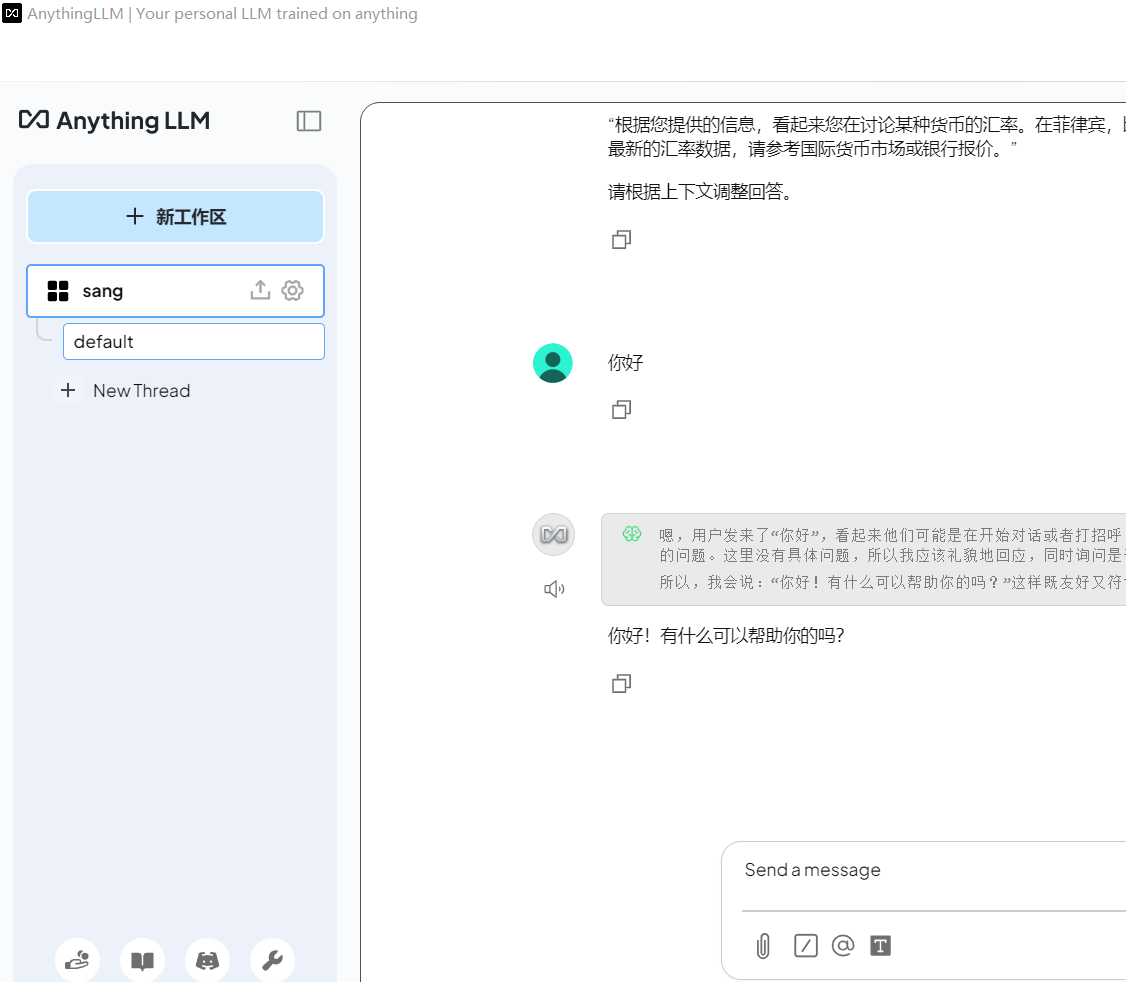
anythingllm
Ollama Embedding Model 选择 nomic-embed-text:latest

 浙公网安备 33010602011771号
浙公网安备 33010602011771号