

基于栈的指令集与基于寄存器的指令集详细比对及JVM执行栈指令集实例剖析
基于栈的指令集与基于寄存器的指令集详细比对:
这次来学习一些新的概念:关于Java字节码的解释执行的一种方式,当然啦是一些纯理论的东东,但很重要,在之后会有详细的实验来对理论进行巩固滴,下面来了解一下:
现在JVM在执行Java代码的时候,通常都会将解释执行与编译执行二者结合起来进行。所谓解释执行,就是通过解释器来读取字节码,遇到相应的指令就去执行该指令。所谓编译执行,是通过既时编译器(Just In Time,JIT)将字节码转换为本地机器码来执行;现在JVM会根据代码热点【就是指一堆代码中执行频次比较高的代码】来生成相应的本地机器码。
基于栈的指令集与基于寄存器的指令集之间的关系:
1、JVM执行指令时所采取的方式是基于栈的指令集。
2、基于栈的指令集主要的操作有入栈与出栈两种。
3、基于栈的指令集的优势在于它可以在不同平台之间移植,而基于寄存器的指令集是与硬件架构紧密关联的,无法做到可移值。
4、基于栈的指令集的缺点在于完成相同的操作,指令数据通常要比基于寄存器的指令集数量要多;基于栈的指令集是在同存中完成操作的,而基于寄存器的指令集是直接由CPU来执行的,它是在高速缓冲区中进行执行的,速度要快很多。虽然虚拟机可以采用一些优化手段,但总体来说,基于栈的指令集的执行速度要慢一些。
下面简单举一个例子:
拿“2-1”这个数学运算来说,对于JVM基于栈的指令集来说其实该操作涉及到以下几条指令:
1、iconst_1:也就是将数字1压入到栈顶。
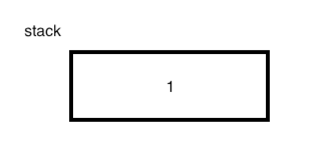
2、iconst_2:也就是将数字2压放到栈顶,此时栈的情况为:
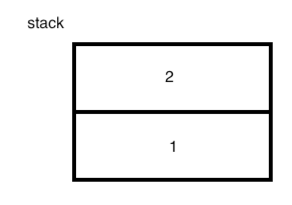
3、isub:将栈中的“2”和“1”从栈中弹出来,此时栈就为空了,然后执行“2-1”,将结果“1”再压回到栈中,此时栈中就只有一个结果元素了,如下:
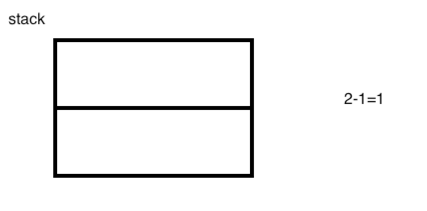
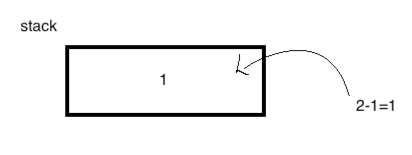
4、istore_0:就栈中的1元素存储在局部变量的0位置的slot上。
5、return,将整个方法返回。
而如果采用基于寄存器的架构方式执行的话,就只有两条指令,如下:
1、将2放到一个寄存器当中,可能涉及到一个汇编指令:MOV。
2、在同一个寄存器当中调用减法指令Sub 1,然后再将结果再放回到寄存器当中。
从上面简单的对比就可以能感受到两者的差别,由于JVM采用的是基于栈的指令集来解释的,所以接下来以一个实际的例子从头到尾分析字节码的角度来感受一下这种指令集的一个完整流程。
JVM执行栈指令集实例剖析:
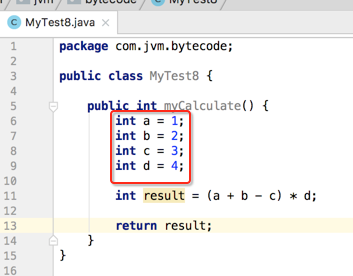
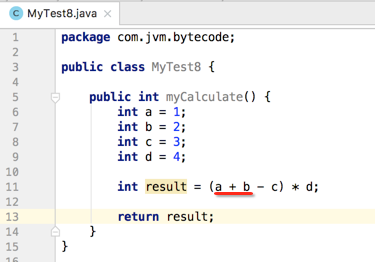
先来看个简单的代码:
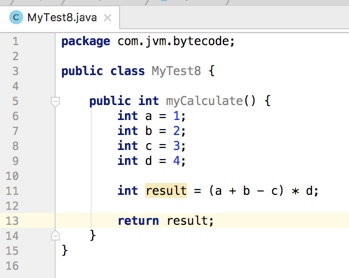
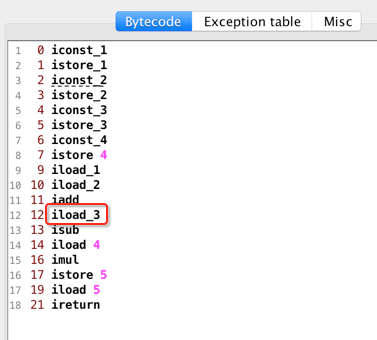
就是简单的数学运算,接着编译一下然后用jclasslib查看一下该方法的字节码信息:

其中有一个东东需要结合的看一下,也就是javap -verbose显示的这块信息,如下:
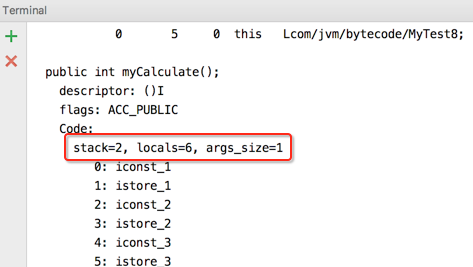
之前对于这个也只是从概念上稍加过了一下,这次通过彻底分析这个字节码的同时,顺带着来对这块的东东也加以巩固,先来简单回忆一下这三个的主要含义:
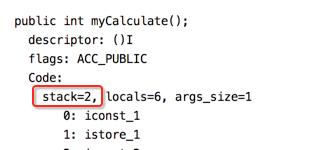
stack=2:表示最大栈的深度是2,意思就是说栈最多能容纳2个元数,为啥?待下面分析字节码时自然而然就能得到答案。
locals=6:表示最大的局部变量有6个,为啥?也待分析字析可以得到答案。
args_size=1,表示myCalculate()方法有一个参数,因为它是一个实例方法,所以就是隐藏的this,比较好理解。
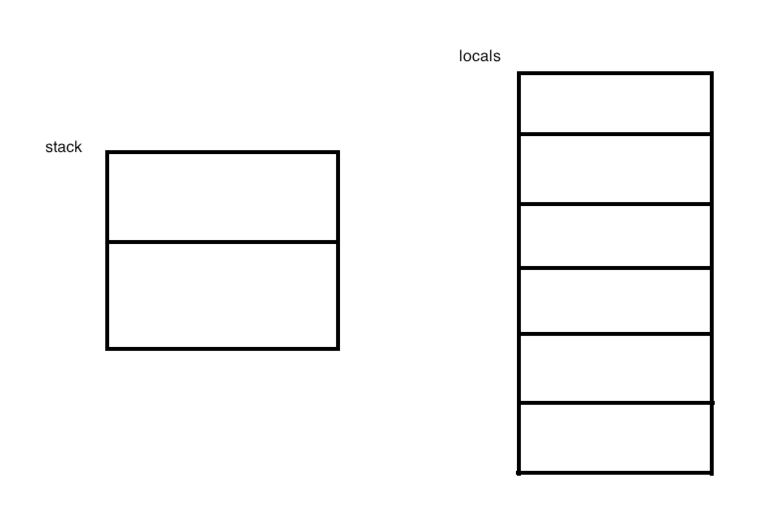
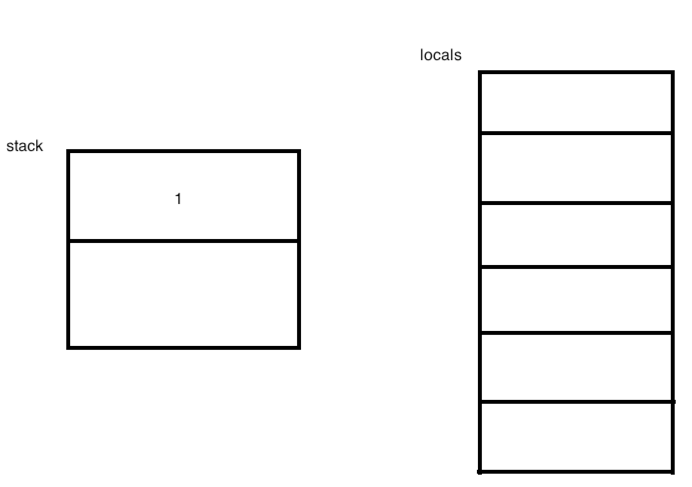
接下来咱们开始逐行来分析字节码指令,并且会把整个过程给画出来,因为最大栈的深度是2,最大局部变量的个数是6个,所以先画一画占个位:
先看第一个助记符指令:
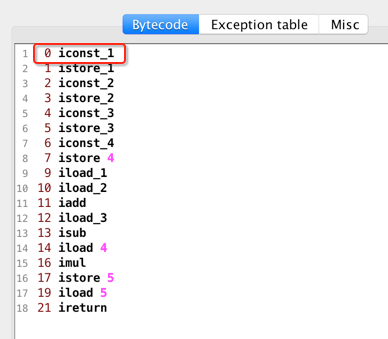
先来看一下官网对它的解释:
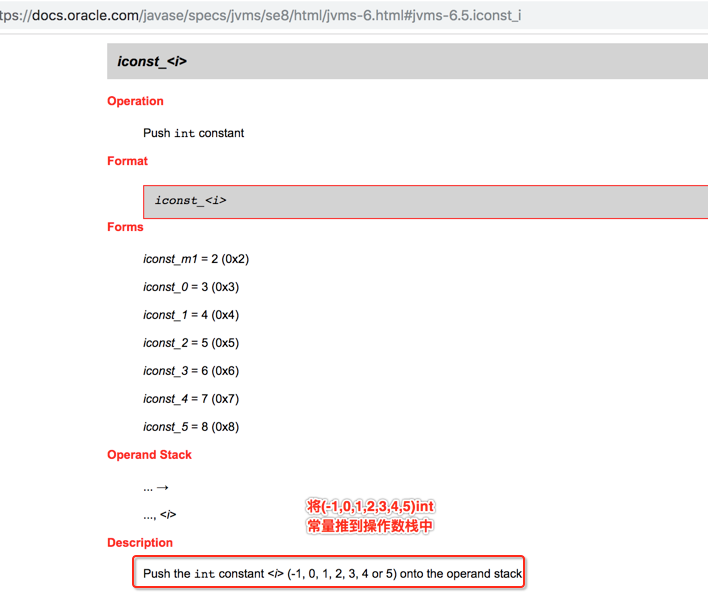

意思是说对于iconst_1=bipush 1,也就是JVM定义了前5个常用的数字指令,对于其它数字就得用bipush来弄了。既然将数放到了操作数栈的栈顶了,所以栈的情况为:
继续看第二的指令:
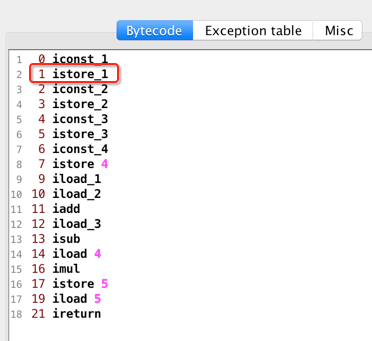
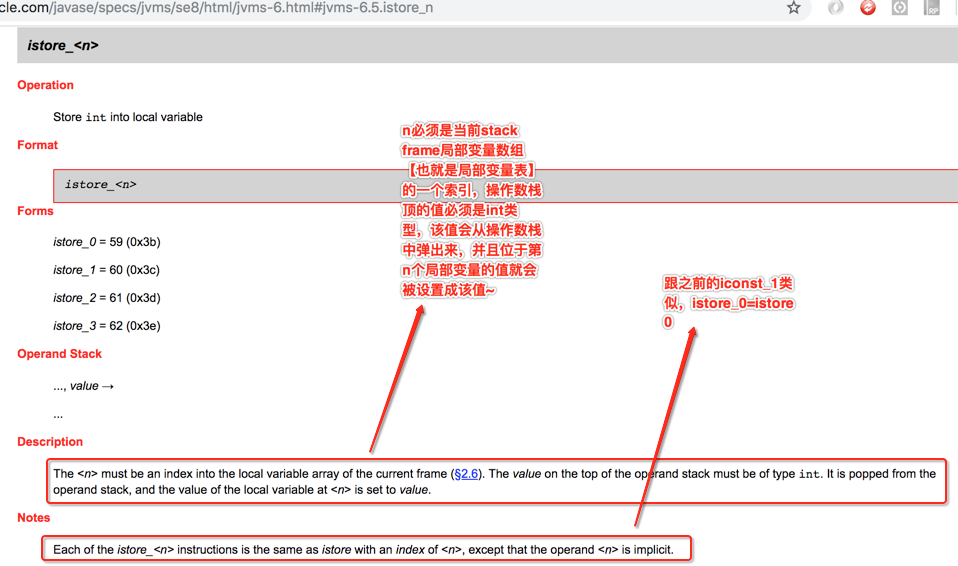
所以照官方的解释,istore_1就表示将栈顶的值弹出来并放到索引为1的局部变量处,所以,此时的图就变为:
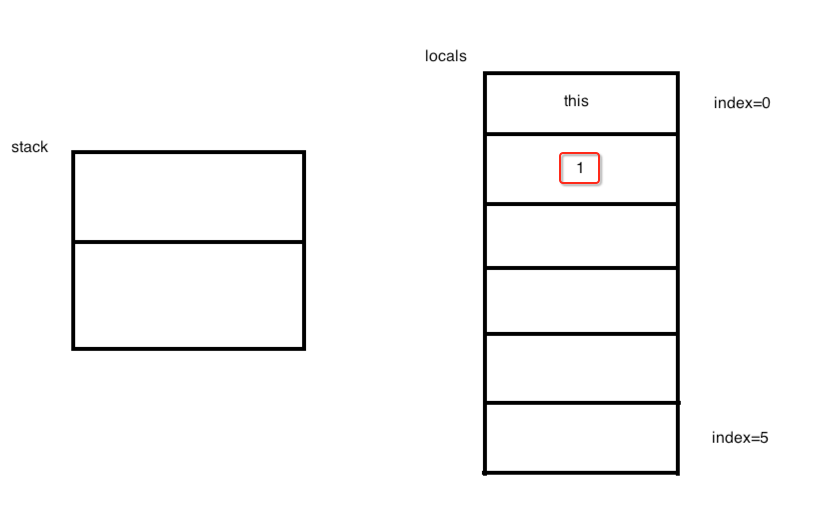
接着继续:
理解了iconst_1之后,它就比较简单了,也就是目前栈顶的元素为2了,图如:

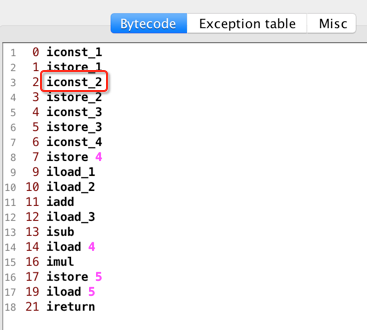
接着再往下:

也不多解释了,它的意思就是将栈顶的元素弹出来之后存放在局部变量为2的地方,所以:
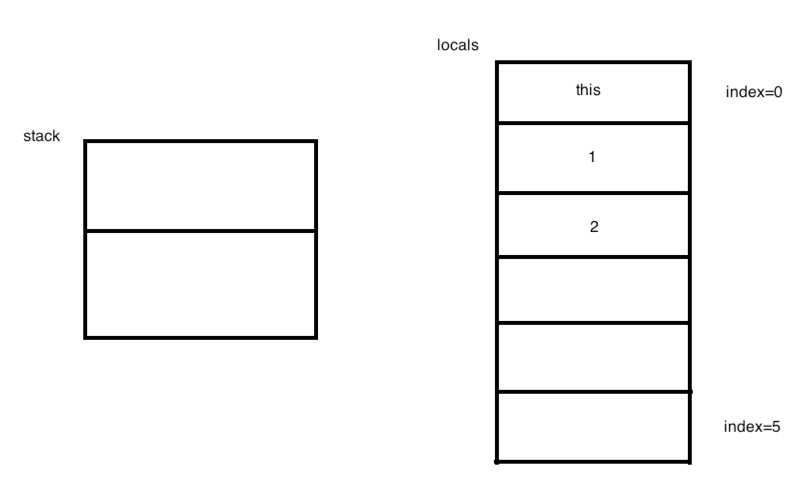
接下来直接再来看2个指令:
然后此时的图又变为:
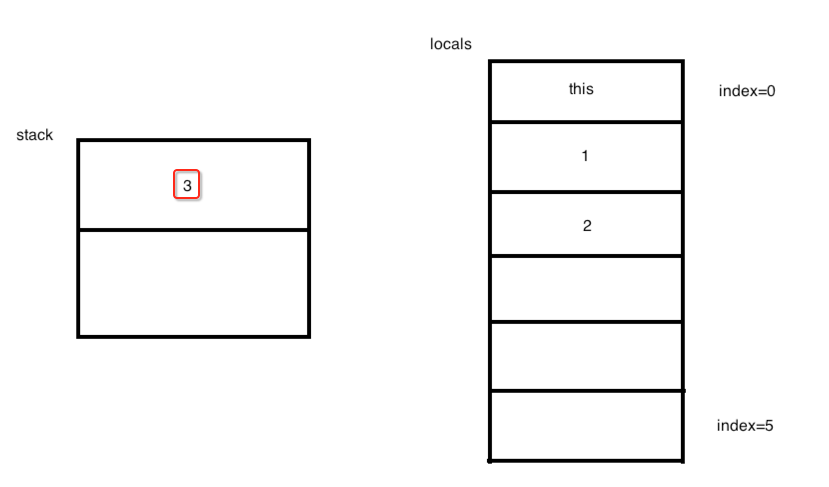
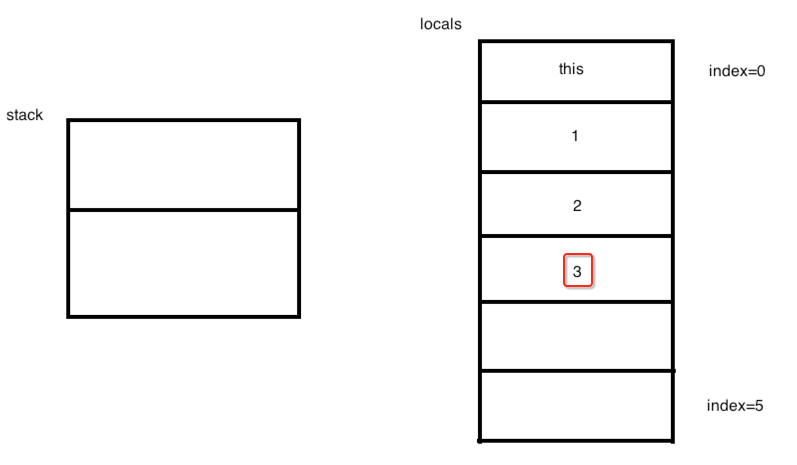
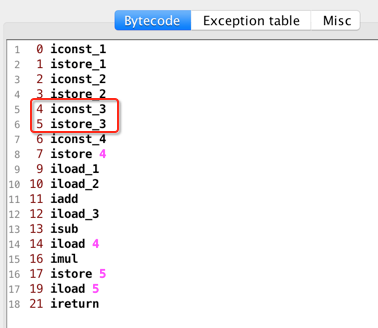
再往下两个指令,基本类似:
此时的图变为:
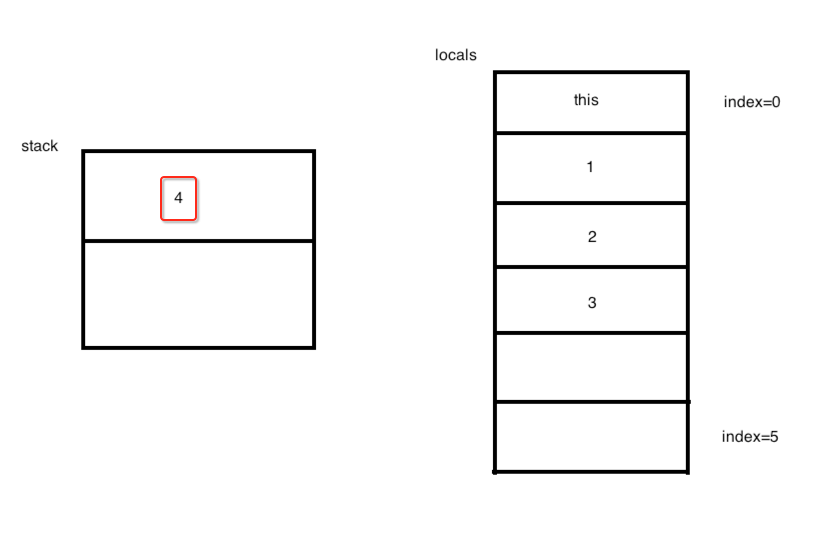
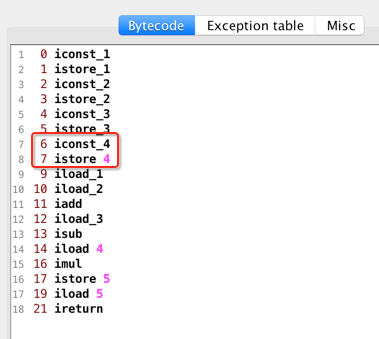
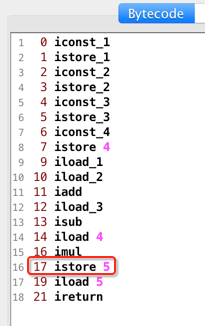
此时需要注意此时不是istore_4了,而是istore 4:
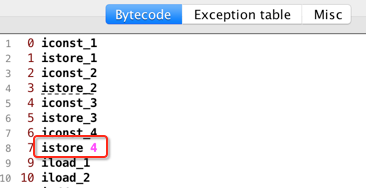
为什么?因为istore下划线就到3:

所以到4就得用它的本质指令istore 4,其实本质是一样的,所以此时图又变化为:
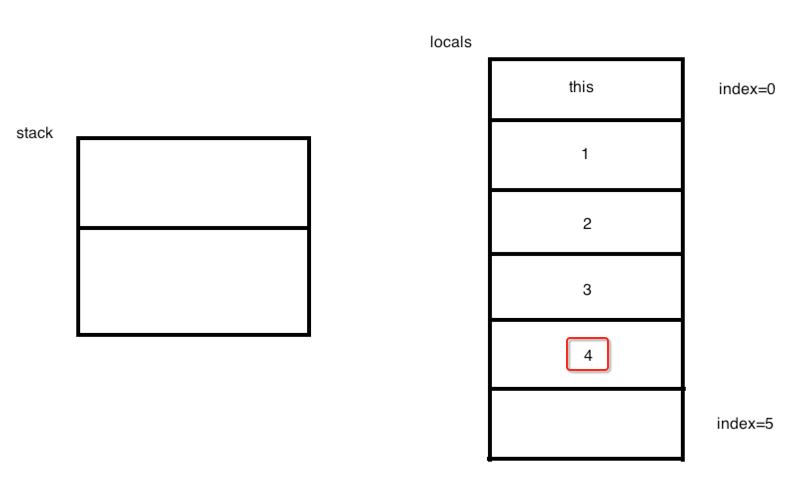
到此数据准备阶段已经完毕,对应的字节也就是这些:

刚好也对应于源代码:
接下来的指令则是为了运算用的,如下:

继续一一来分析:
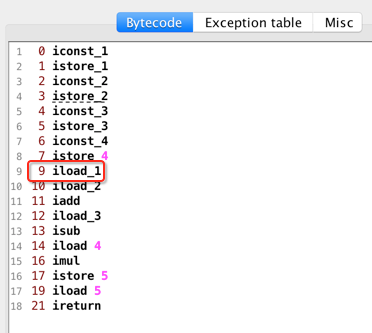
看一下官方解释:

通谷的说就是将局部变量索引为1的元素的值推送到栈顶,图就会发生如下变化:
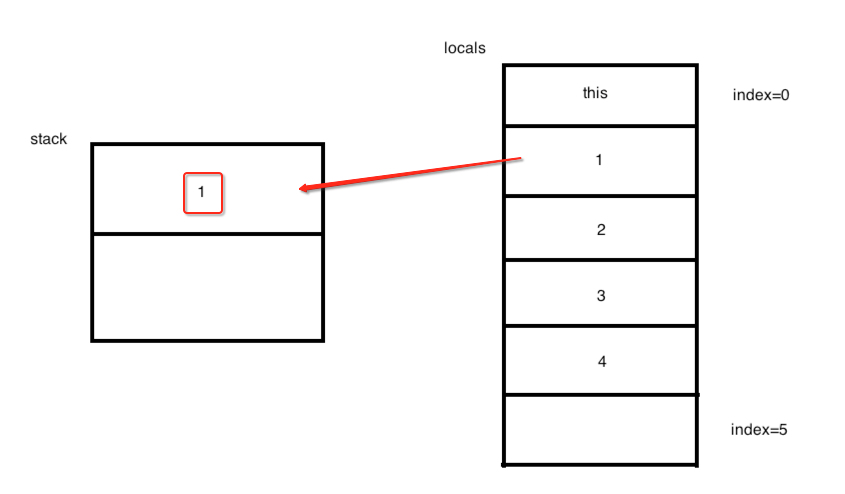
继续往下:
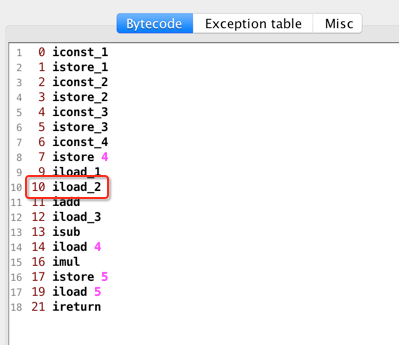
同样的,会将局部变量索引为2的元素的值推送到栈顶,那之前栈中的“1”就会被挤下去,如下:

此时是不是可以发现栈的最在深度目前已经为2了,当然现在还没有分析完,但其实最终深度也就是2,这也就是为什么在javap -verbose中所看到的:
好,继续:
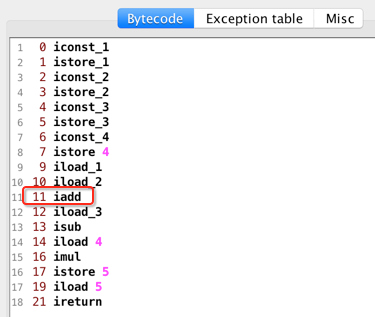
很明显就是执行的加法操作嘛,看一下官网对它的解释:
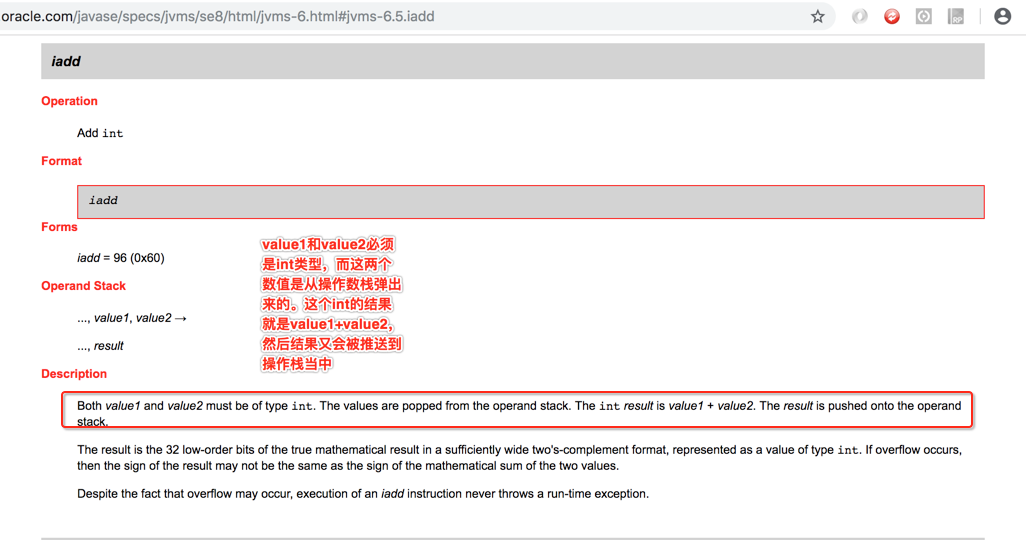

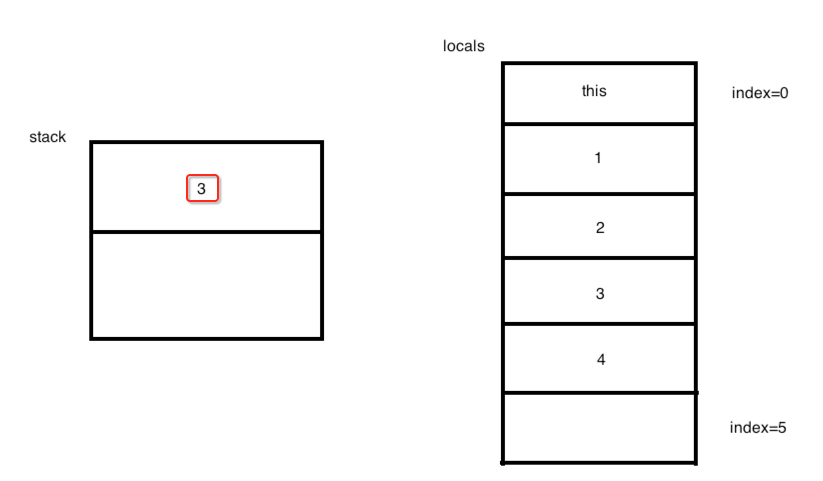
言外之意就是说将栈中的两个元素“2”和“1”从栈中弹出,然后执行“2” + “1”=“3”,然后再将结果3压回到栈顶,所以此时的图为:
其实此时的操作就对应源码:
好,继续:
同样的是将局部变量为3处的值压入到栈顶,所以:
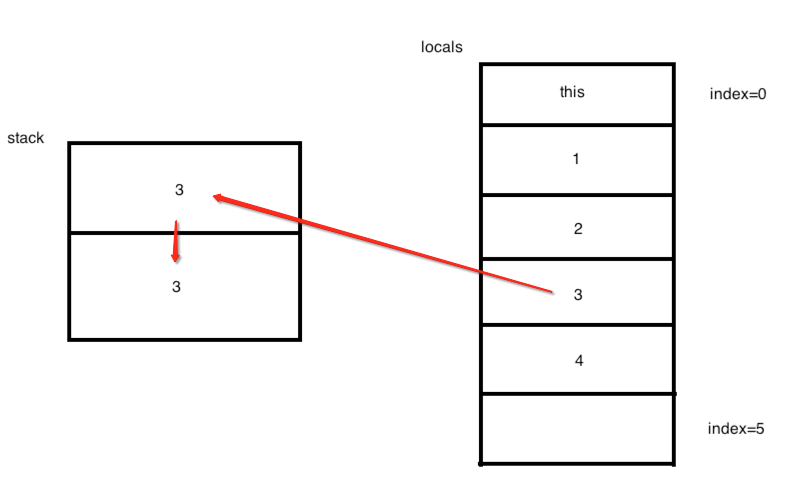
再往下:
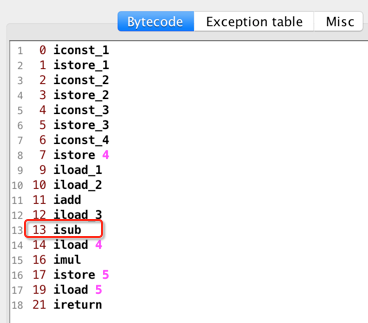
很显然是执行了相减操作,也就对应于源码:

看下官网对该指令的解释:
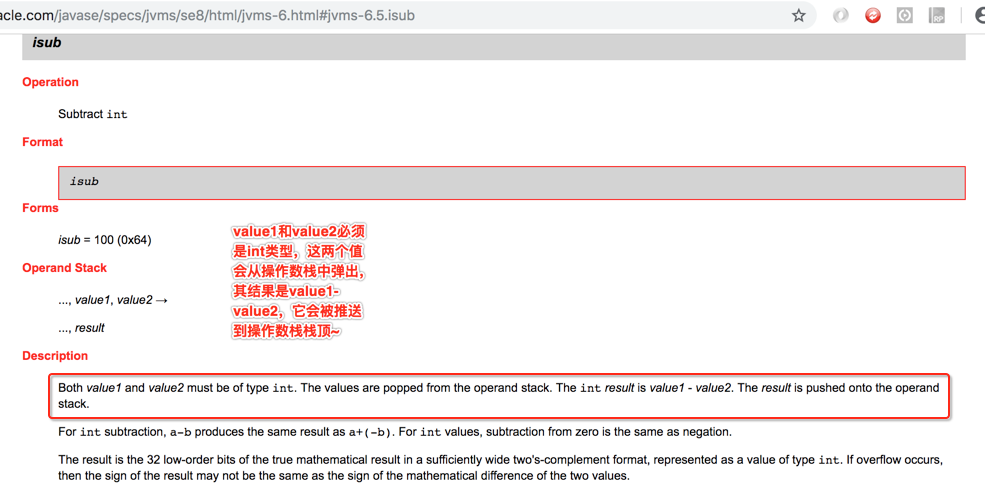
所以图就会变为:
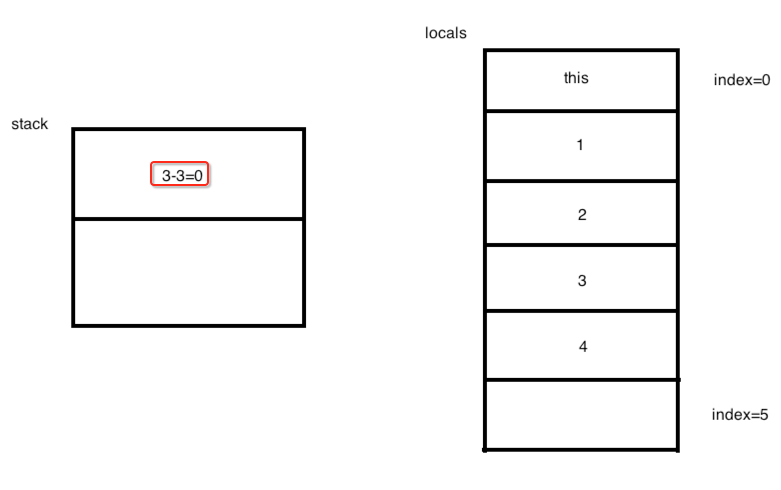
接着往下:
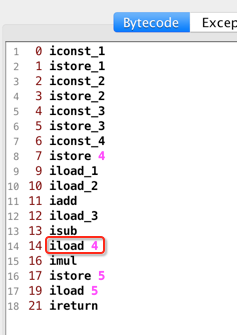
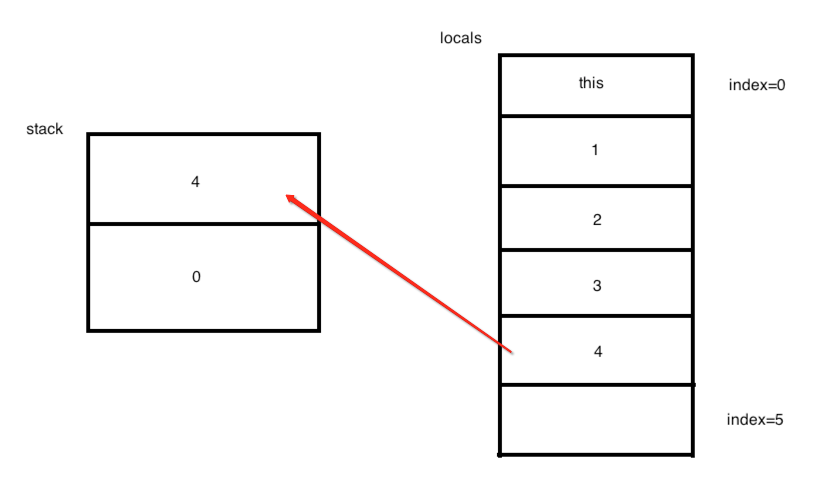
也就是从局部变量位置4位置的值压入到栈顶中,所以图就会变为:
然后再看下一个指令:
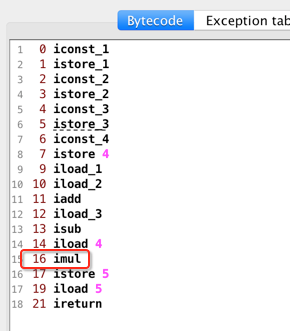
其实跟isub类似,看一下:
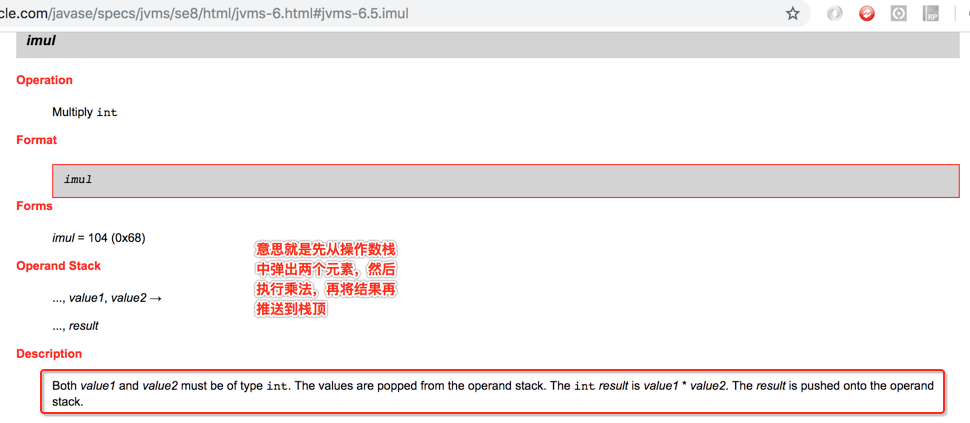
所以图又发生了变化:
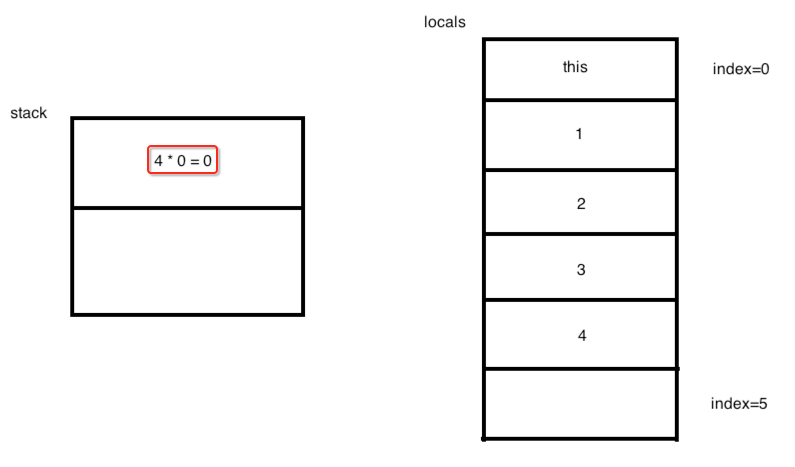
再往下:
也就是将栈顶的元素的值弹出来并存放到局部变量位于5的位置,如下:
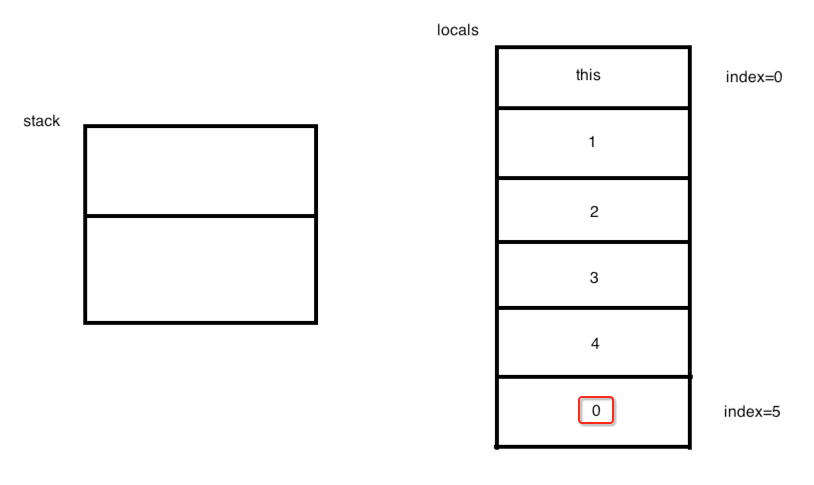
从这是不是就可以看到局部变量的最大个数就是为6,正应证了:

好,再往下:

将局部变量为5位置的值放到栈顶,所以图变为:

还剩最后一个指令啦:

看一下官网的解释:
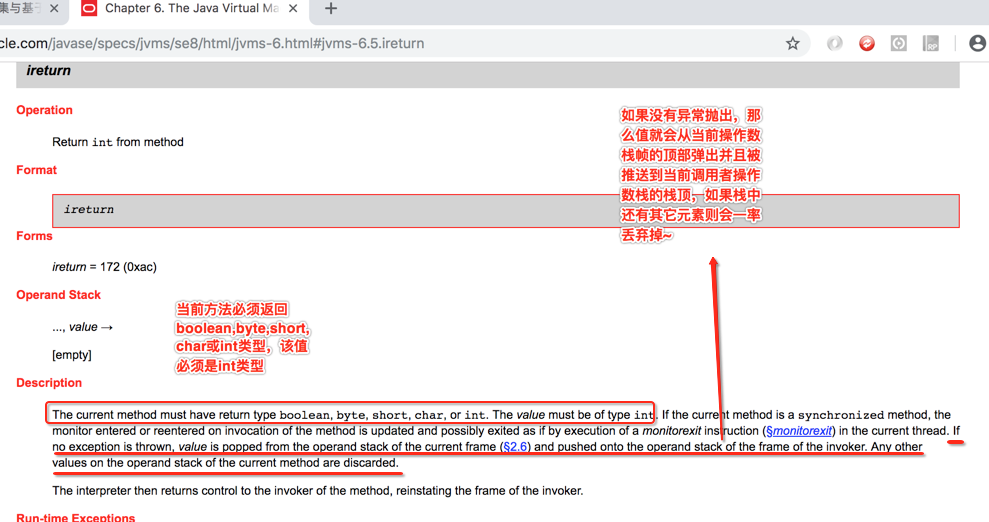
言外之意就是说会将栈顶的元素弹出来做为方法的最终结果,如果操作数栈还有其它值则会一率丢弃掉,目前栈中只有一个0,所以就会将它弹出做为整个方法的执行结果,刚好跟我们的预期结果相吻和。
通过详细的字节码分析之后,应该是对基于栈的指令集的一个整体的流程有了一个非常深刻的认识。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步