
Java字节码常量池深入剖析
继续来分析Java字节码,上一节分析了魔数的规则,接下来继续往下分析,其上次总结的规则也一起贴出来:
1、使用javap -verbose命令分析一个字节码文件时,将会分析该字节码文件的魔数、版本号、常量池、类信息、类的构造方法、类中的方法信息、类变量与成员变量等信息。
2、魔数:所有的.class字节码文件的前4个字节都是魔数,魔数值为固定值:0xCAFEBABE。
3、魔数之后的4个字节为版本信息,前两个字节表示minor version(次版本号),后两上字节表示major version(主版本号),所以这里的版本号为“00 00 00 34”,如下:
换算成十进制,表示次版本号为0,主版本号为52,正如咱们用javap -verbose所看到的:

那这个版本信息的值有啥意义呢?其中主版本号52代表JDK1.8,而51表示JDK1.7,往前递减依此类推,所以该文件的版本号为:1.8.0,其中1.8为主版本号,而后面的0为次版本号,怎么来验证这一点呢,当然查看java的版本既可嘛,如下:

我们知道Java是一个向后兼容的语言,对应到字节码上,如果JVM是1.8的, 则它可以正常加载并运行1.8以及1.8jdk所编译出来的字节码文件, 但是反过来则不行。
4、版本号之后的字节则为常量池(constant pool):紧接着主版本号之后的就是常量池入口。一个Java类中定义的很多信息都是由常量池来维护和描述的,可以将常量池看作是Class文件的资源仓库,比如说Java类中定义的方法和变量信息,都是存储在常量池中,常量池中主要存储两类变量:字面量和符号引用。字面量如文本字符串,Java中声明为final的常量值等,而符号引用如类和接口的全局限定名,字段的名称和描述符,方法的名称和描述符等。其中符号引用在之前的复习总结中也有提到过,回顾一下: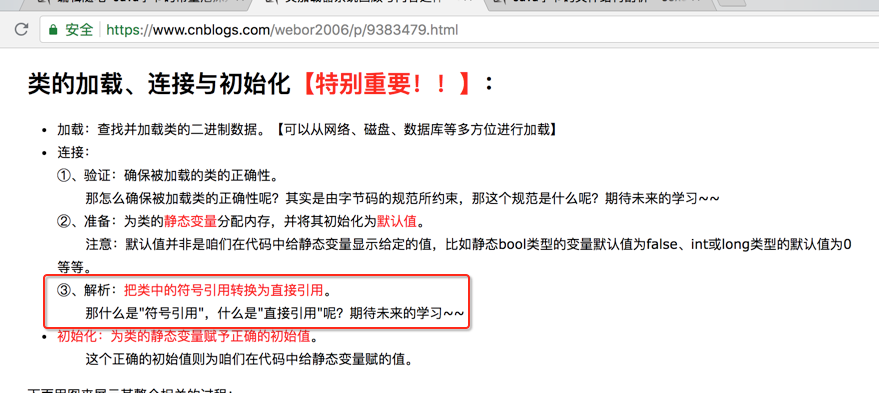
【注意】:常量池千万不要理解成它里面只能存不变的常量值,里面也可以有变量相关的信息。
5、常量池的总体结构:Java类所对应的常量池主要由常量池数量与常量池数组这两部分共同构成。常量池数量紧跟在主版本号后面,占据2个字节;常量池数组则紧跟常量池数组之后,常量池数组与一般的数组不同的是,常量池数组中不同的元素的类型、结构都是不同的,长度当然也就不同,但是每一种元素的第一个数据都是一个u1类型,该字节是一个标志位,占据1个字节,JVM在解析常量池时,会根据这个u1类型来获取元素的具体类型。好下面依照该规则来真实查看一下字节码文件:
“常量池数量紧跟在主版本号后面,占据2个字节”,所以我看样一下该字节码文件的常量池数量是?
那咱们来看一下javap -verbose输出的结果来验证一下咱们在字节文件中看到的:
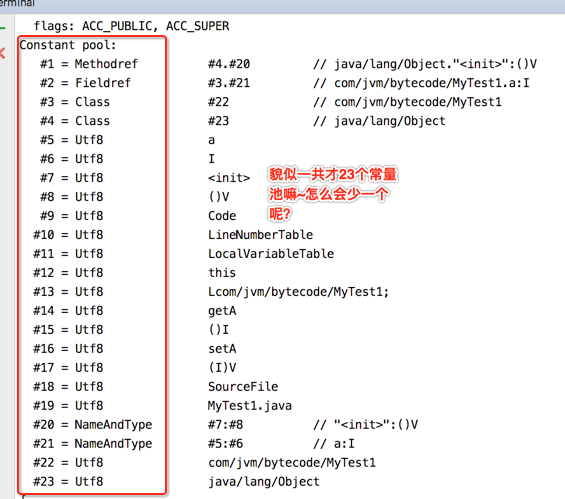
这是因为常量池数组【又叫常量表】中的元素的个数 = 常量池数 - 1(其中0暂时不使用)。 目的是满足某些常量池索引值的数据在特定情况下需要表达【不引用任何一个常量池】的含义;根本原因在于,索引为0也是一个常量(保留常量),只不过它不位于常量表中,这个常量就对应null值;所以常量池的索引从1而非0开始。

好,那具体常量池中的常量都是如何分配的呢,下面需要了解一个图,非常之重要:
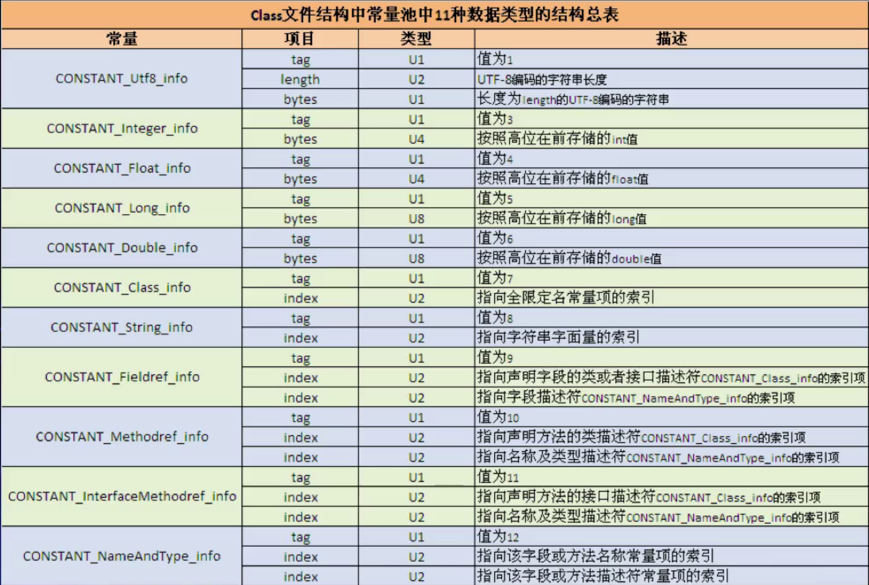
可以发现所有常量名都是以CONSTANT开头,以info结尾, 另外下面具体的来说明一下该表怎么来看:

其中第一个tag也就是上面我们描述的“每一个元素的第一个数据都是U1类型”,当它的值为1时,表示是CONSTANT_utf8_info类型的常量,而第二个length为u2类型,占两个字节,表示UTF-8编译的字符串长度,而第三个bytes为u1类型点一个字节,表示长度为length的UTF-8编译的字符串内容,也就是根据length来读多少个字节就刚好将这个常量给读完。好接下来继续往下来看:
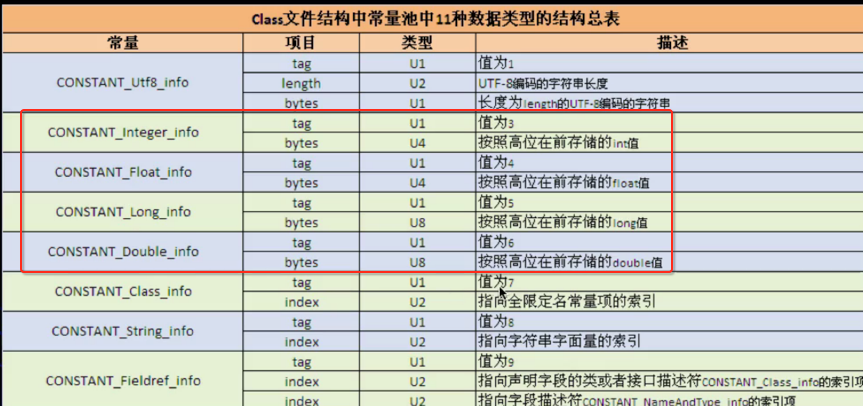
拿CONSTANT_Integer_info来说明,第一个tag占一个字节,其值是3,其需要读4个字节的内容则为该Integer常量的值,其它的Floast、Long、Double都类似,就不多说了。
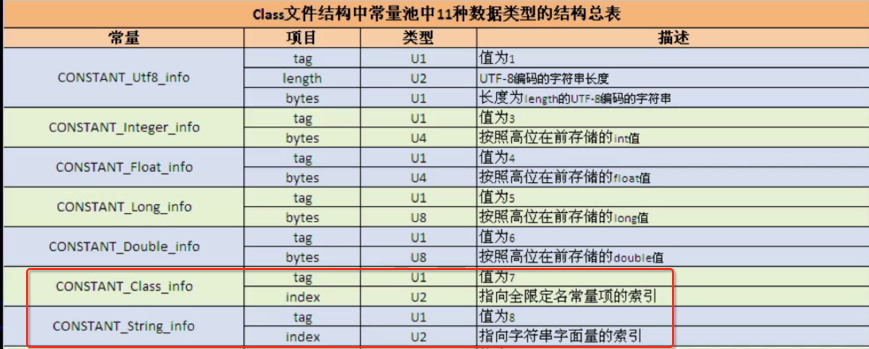
如果tag为7表示类常量,而紧接碰上2个字节表示指向全限定名常量项的索引。
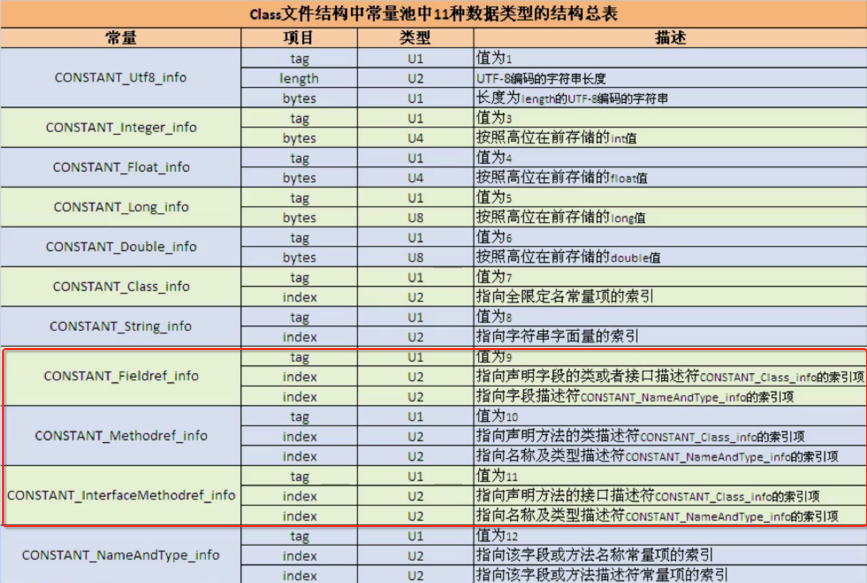
这三个常量稍复杂一点,之后会详细介绍,这里先简单的看一下,也就是对于字段和方法都需要先指定类的,然后再到具体的字段或方法。
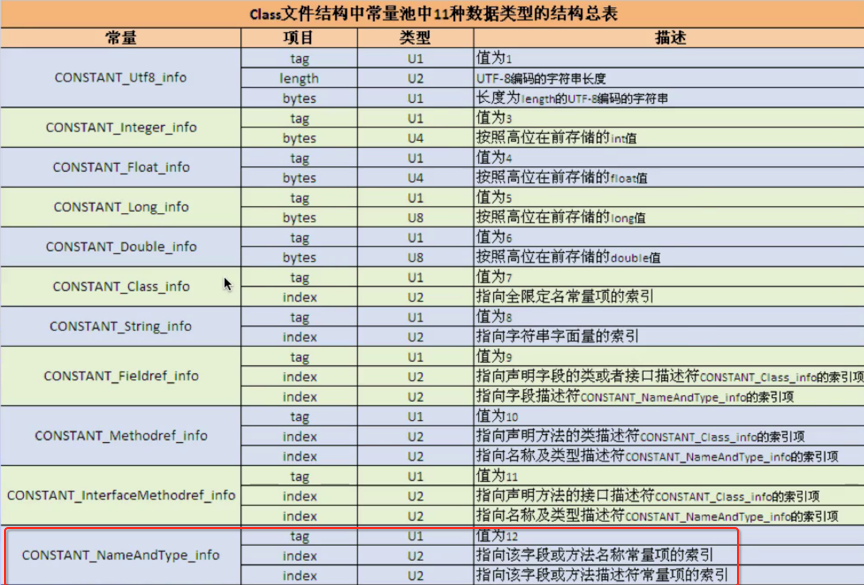
反正不晓得讲什么,云里雾里的,没关系,下一次会完完整整的将字节码中的常量池全部按照上表格的描述规则分析一趟,最终会跟用javap -verbose常量池的输出完全对应上,如下:
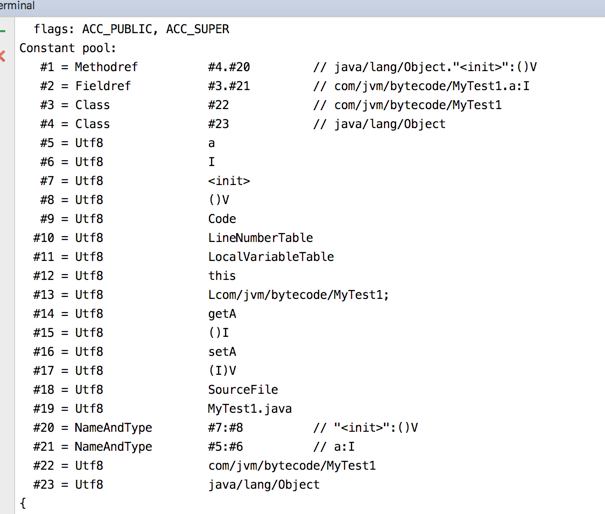
到那时再回过头来看这张表就会觉得非常之亲切啦~~

