
java8学习之收集器枚举特性深度解析与并行流原理
首先先来找出上一次【http://www.cnblogs.com/webor2006/p/8353314.html】在最后举的那个并行流报错的问题,如下:
在来查找出上面异常的原因之前,当然得要一点点去排查,所以下面会做实验一步步来为找到这个问题而努力。
下面咱们将循环次数只为1次,先来观察日志输出,如下:

接下来把这个并行特性去掉,同样的代码再次看累加这块的日志输出,发现元素明显变少啦:

那很显然这个并发特性对于并行流来说显然是能起到一定作用的,那咱们先来读一下这个特性代码的含义是什么:

那如果不设置并行特性,对于并行流来说那就意味着多个线程操作的是多个结果容器,接下来根据这个特性就要开始推理啦:既然加了并行特性的并发流是多个线程操作的是同一个结果容器,那是不是说combiner()函数就不会调用了,因为只有一个结果容器还合啥合;同理如果不加这个并行特性那明显会调用combiner()函数嘛,因为存在多个结果容器,这个在之后实验会得到论证滴。
下面再回到这个异常的情况,如果说将累加器函数中的日志打印中的这个去掉,其它的代码都维持现状的话:

public class MySetCollector2<T> implements Collector<T, Set<T>, Map<T, T>> { @Override public Supplier<Set<T>> supplier() { System.out.println("supplier invoked!"); return HashSet<T>::new; } @Override public BiConsumer<Set<T>, T> accumulator() { System.out.println("accumulator invoked!"); return (set, item) -> { System.out.println("accumulator: " + ", " + Thread.currentThread().getName()); set.add(item); }; } @Override public BinaryOperator<Set<T>> combiner() { System.out.println("combiner invoked!"); return (set1, set2) -> { set1.addAll(set2); return set1; }; } @Override public Function<Set<T>, Map<T, T>> finisher() { System.out.println("finisher invoked!"); return set -> { Map<T, T> map = new TreeMap<>(); set.stream().forEach(item -> map.put(item, item)); return map; }; } @Override public Set<Characteristics> characteristics() { System.out.println("characteristics invoked!"); return Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.UNORDERED, Characteristics.CONCURRENT)); } public static void main(String[] args) { for (int i = 0; i < 100; i++) { List<String> list = Arrays.asList("hello", "world", "welcome", "hello", "a", "b", "c", "d", "e", "f", "g"); Set<String> set = new HashSet<>(); set.addAll(list); System.out.println(set); Map<String, String> map = set.parallelStream().collect(new MySetCollector2<>()); System.out.println(map); } } }
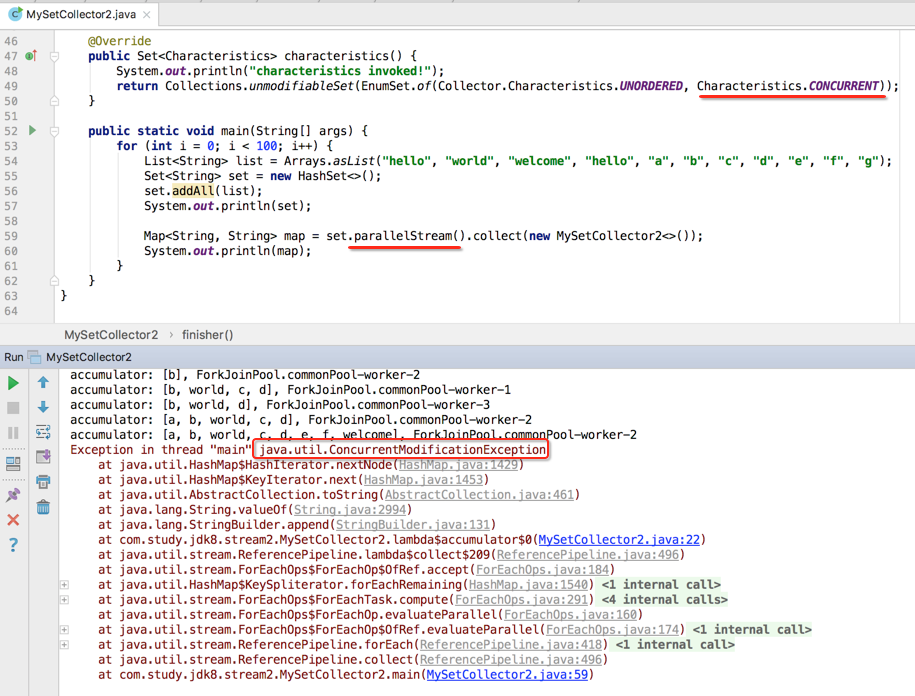
这时再运行:
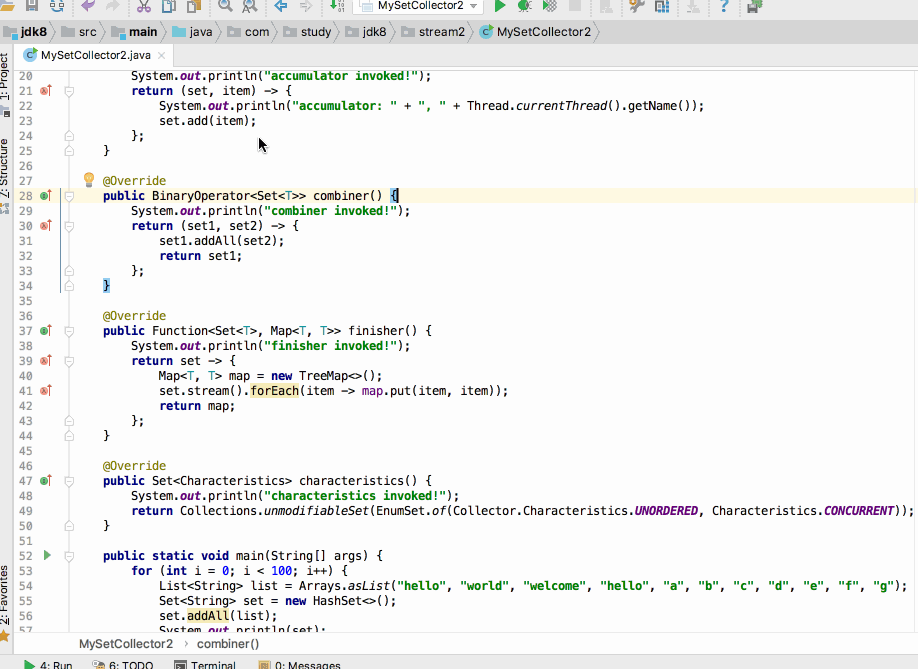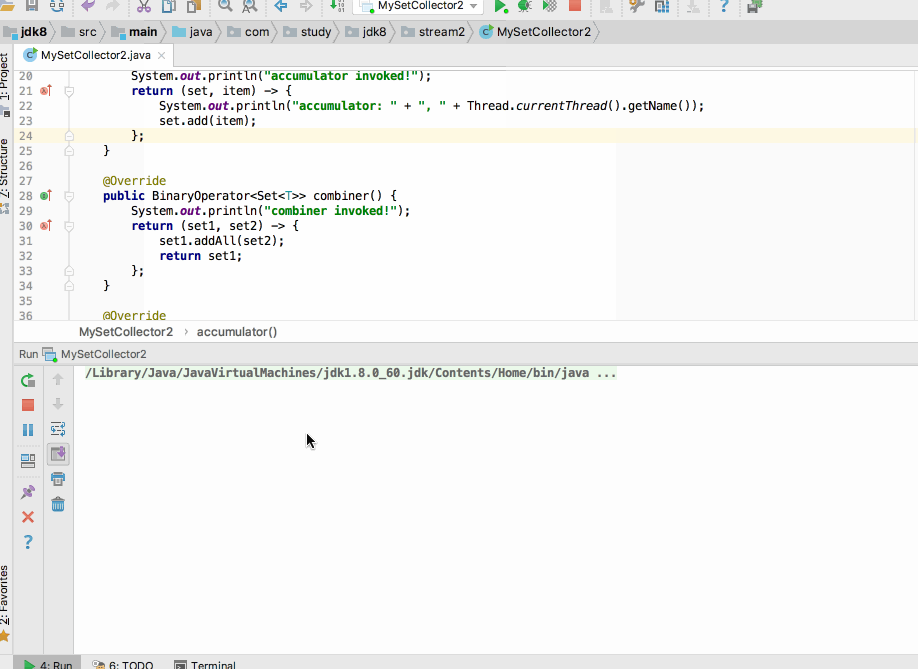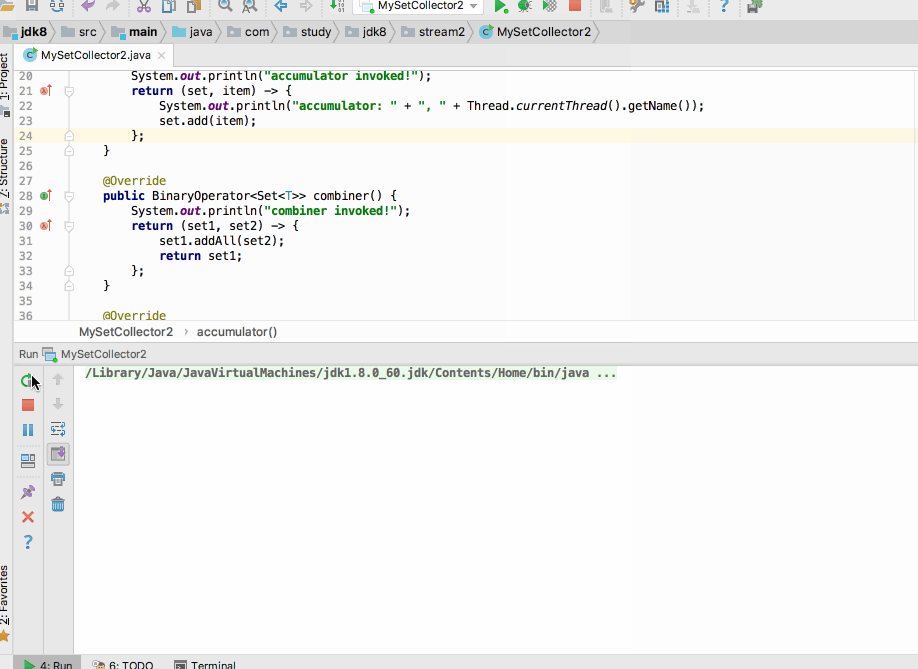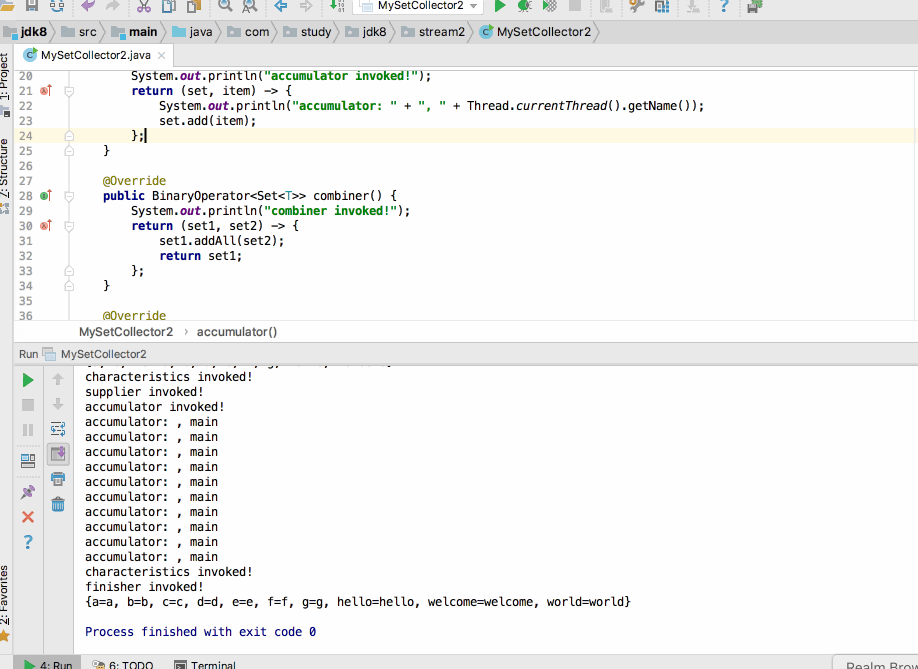
居然在带有并行特性的并行流当中运行不出错了,这就奇怪了~居然报错与否还跟咱们的打印日志不同有关,接下来咱们来分析一下这是为什么,先将出错的那个打印日志还原,根据异常信息来找线索,如下:
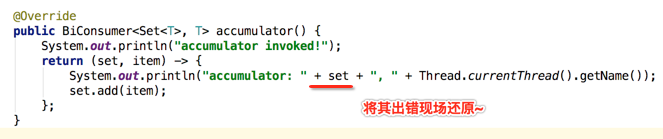
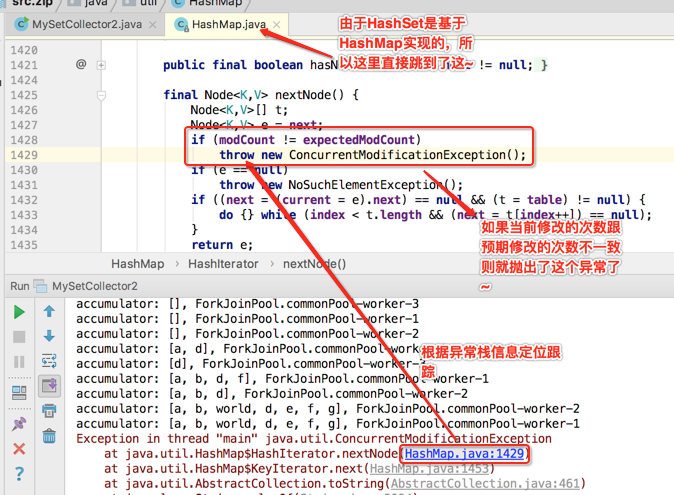
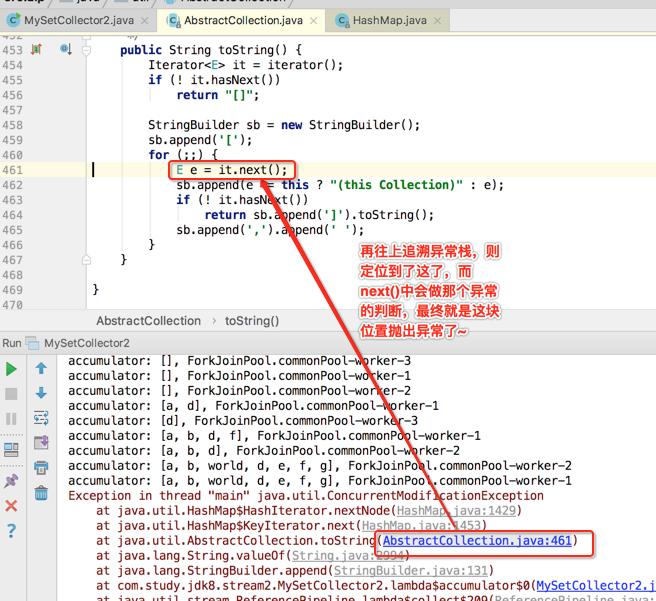
那为啥会调用toString()方法呢?因为咱们日志中直接打印了Set元素,当然会调用集合的toString()啦,如下:

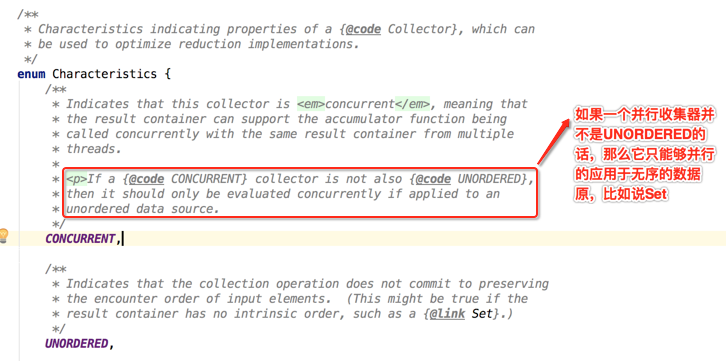
那咱们看一下这个并行修改异常类的javadoc去寻找一些出错线索:

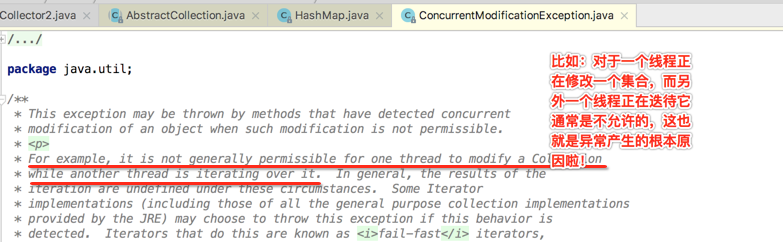
带着上面的线索回到咱们的程序,来分析一下出错的具体原因:
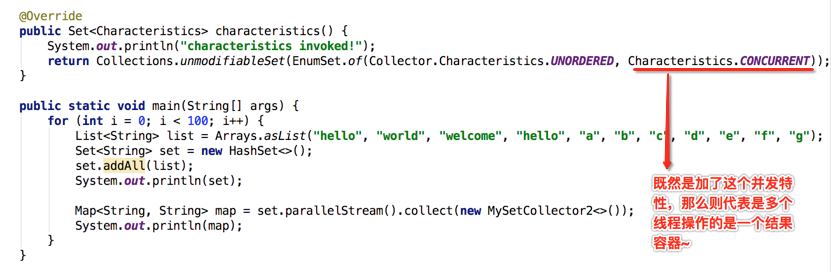
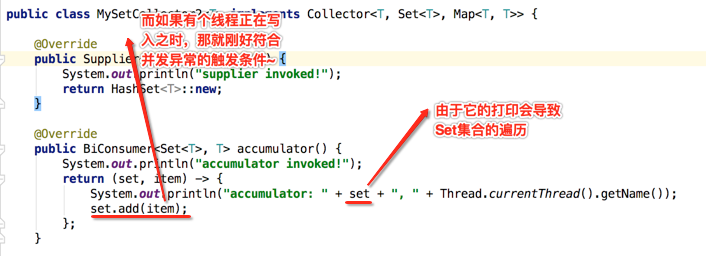
当然~~这个不是必现的,因为如果上面的条件木有触发那当然就不会出现啦。所以原因已经彻底清楚了,通过这个问题需要知道的是:如果在一个并行流中增加了并行特性,在累加函数中一定不要对集合进行的印,因为它会触发集合的遍历操作容易导致并发修改异常。
另外如果在目前的程序中将并发特性去掉一切就正常运行的原因就是会生成多个结果容器,不同的线程操作各自的那一份,互不干扰,当然也就不会存在并行修改异常情况啦,那!!怎么来证明加了并行特性多个线程操作的只是一个结果容器而如果去掉了并行特性多个线程操作的是多个结果容器呢?用combiner()来证明,证明理由:如果只有一个结果容器那就没必要进行合并了,也就是此函数就不会被调用,而如果有多个结果容器当然就会调用此函数进行结果合并啦,所以下面咱们在这个函数中加一点日志实验一下:

编译运行:
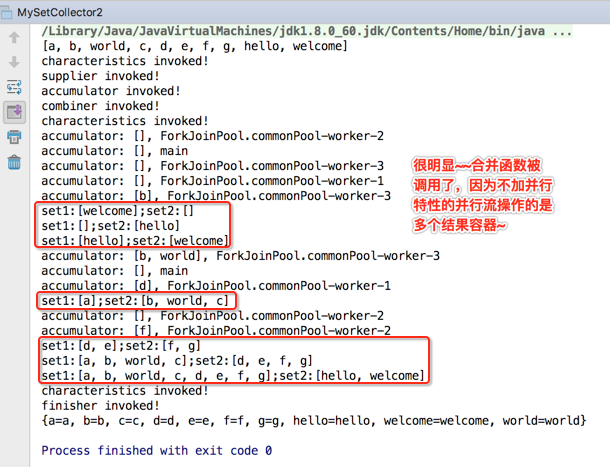
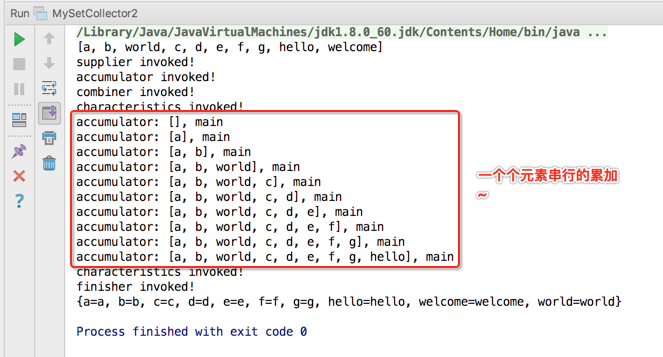
接下来则是加上并行特性喽:
这时看结果:

通过上面的实验咱们就已经彻彻底底对收集器的另一个并行特性完全理解透了。
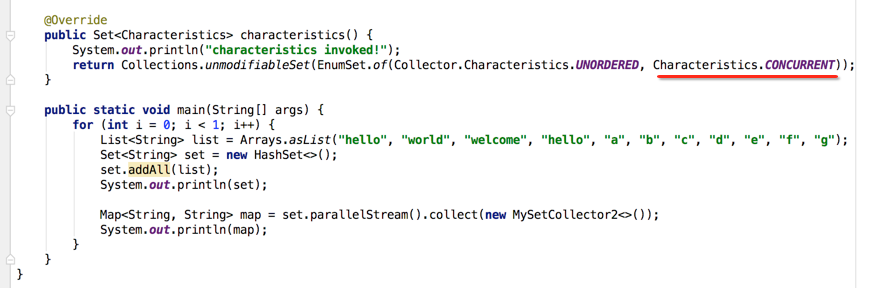
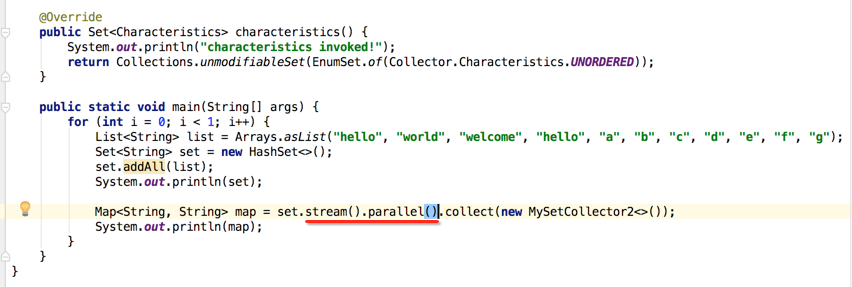
对于并行流咱们可以通过parallelStream()方式来获取,其实还可以用另外一个api来获取,如下:
当然也有串行流的获取新方式啦:
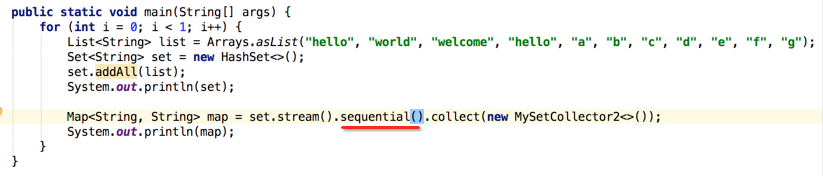
这时可以运行看一下串行的打印,可以看到非常整齐:
下面做个无聊的游戏:

下面运行一下:

并行流,说明不管写了多少次串并行,以最终结束的那个为准,如:

那这两种不同类型的调用方式有啥区别呢?比如"parallelStream()"和"stream().sequential()",其它它们是一回事,为什么?看源码便知:

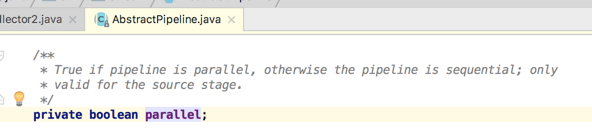
而如果是另外一种形式来看:

追溯其根源如下:
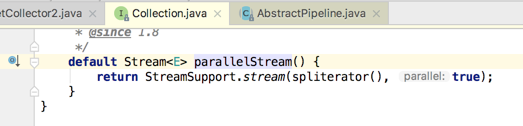
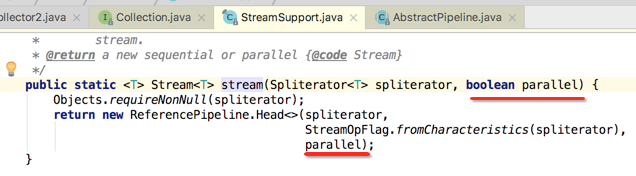
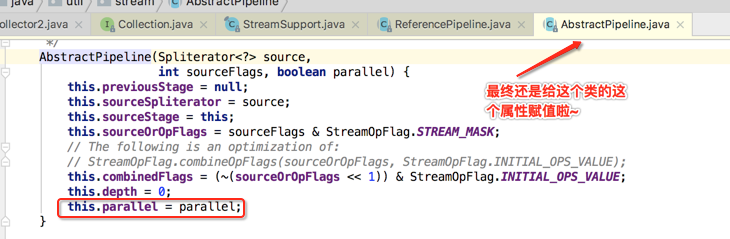
是不是本质是一样的。
接下来继续折腾,对于不加并行特性的并行流,那看这个地方:

要验证也很简单,这里将方法引用的方式改为Lambda表达式就就可看出来了,如下:

编译运行:

那如果改为串行流呢?

其实这个特性在最早读Collector的javadoc时就已经有说明了,这里扒出来再来回顾一下:
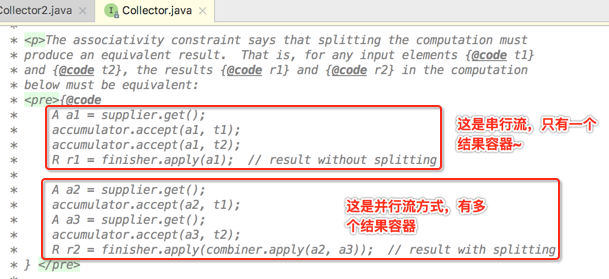
接着再来思考一个问题:对于并行流,那它会生成多少个线程来处理呢?咱们先来数一数刚才对于并行流生成了多少个结果容器:

那就意味着产生了8个线程,对于多线程编程来说,并非线程越多效率越高,因为有线程切换的开销,而比如好的方式是CPU有多少个核心就生成多少个线程,充分发挥其CPU的多核的特性,所以对于咱们这个串行流来说,其实就是按cpu的核心数来生成线程个数的,那问题来了,目前运行的这台机器是2核的,如下:
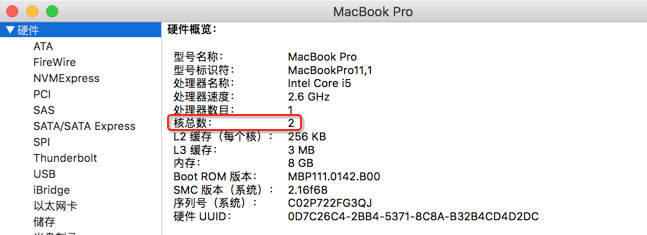
照理应该只生成2个线程呀,其实这里有一个cpu超线程概念,通常CPU会虚拟出来核数,经常会听说虚拟几核几核的,其实关于核数可以通过程序来打印出来,如下:

而目前并行流是生成了8个线程,说明并非生成线程数是完全遵照cpu的核心数来的,只是说一个好的建议。
至此!咱们就已经彻底的掌握了这三个特性的作用了,同时关于Java8收集器相关的东东就已经完全学习完啦,既然已经完全了解了收集器,那对于系统实现在Collectors里面很常用的各种收集器是否要去分析一下其实现的细节呢?当然啦!!所以接下来会仔细对Collector里面的源代码进行分析。


