
java8学习之自定义收集器深度剖析与并行流陷阱
自定义收集器深度剖析:
在上次【http://www.cnblogs.com/webor2006/p/8342427.html】中咱们自定义了一个收集器,这对如何使用收集器Collector是极有帮助的,这次基于它再来进一步,争取彻底理解收集器的所有概念,这里再定义一个新的收集器,其实现如下需求:
对于一个Set<String>这样一个集合,通过收集器将其转换成Map<String,String>,比如对于["hello", "world", "hello world"]这个Set集合,最后通过咱们的收集器要输出成:[{"hello", "hello"}, {"world", "world"}, {"hello world", "hello world"}]。
下面先来新建一个类,然后实现Collector接口:

接下来重写Collector的五个关键方法:
接下来具体来一个个实现:
supplier():
比较简单,就是创建一个中间累加结果容器,这里是用的HashSet,如下:

accumulator():
这个也比较简单,返回的BiConsumer对象中的第一个参数表示中间累加的结果容器,第二个参数表示下一个要累加的元素,所以:

combiner():
这个合并方法是针对并行流的,串行流是不会调用它的,其需要的BinaryOperator的两个参数都是Set<T>类型的,具体实现如下:

finisher():
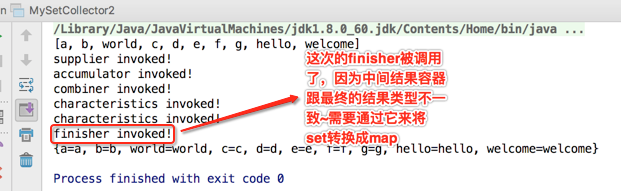
这个方法的回调需要依赖于收集器的特性,如果设置了IDENTITY_FINISH这个特性那此回调则不会调用了,这次中间结果容器类型(Set<T>)跟最终结果的类型(Map<T,T>)很明显是不一样的,所以此方法针对咱们这个例子一定得要调用,不然就会有问题,具体实现如下:

characteristics():
这里先只加上一个无序的特性,因为咱们用的是Set嘛,显然就是无序的:

至此收集器就已经定义完啦,接下来就来使用一下下喽~先构造一个集合:

接着咱们自定义的这个收集器来将Set<String>转换成Map<String, String>,如下:

其结果如预期,其中看一下日志输出这块的打印:

接下来咱们就要来改造程序啦,用来彻底搞明白收集器里面的一些关系,首先先看一下这个特性:

咱们如果给收集器加上上面这个特性,那会有什么现象呢?下面试下:

这里解释其原因从读这个特性的介绍开始:

那它具体是在哪里进行转换的呢?其实上一节中也进行说明过,在这:

所以说只要设置了"IDENTITY_FINISH"这个特性,则编译器就认为收集器的中间结果和最终结果的类型是一模一样的,则直接强转,在实际使用时需要根据实际的场景来正确的设置相应的特性,当然啦正确设置特性的前提是你对这里面的每个特性枚举值的具体含义彻底理解才行,所以通过这个实验咱们就对这个Characteristics.IDENTITY_FINISH特性彻底理解了。
接下来咱们将结果放到一个TreeMap()中,这样收集的结果就是带排序的了:

并行流陷阱:
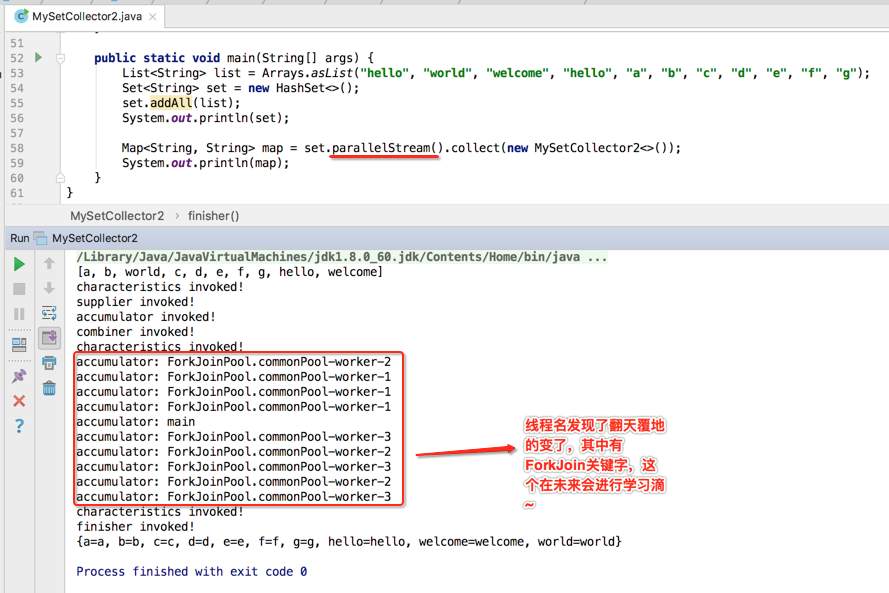
接下来则将程序改造成一个并行流,不过在改并行流之前先来看一下串行流的线程情况,这里先在accumulator()函数中打印一下线程的名字,如下:

接下来则改用并行流,再来看一下输出:
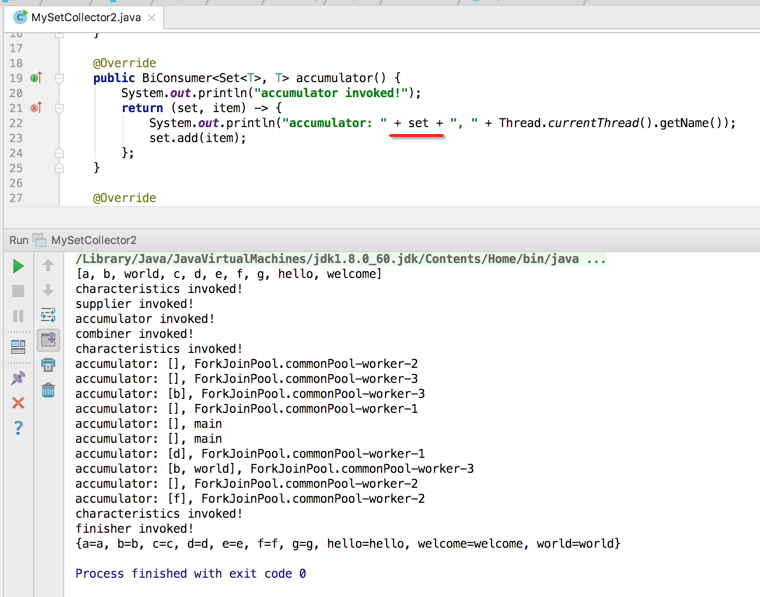
接下来咱们再来修改一下日志输出语句,如下:
既然是并行流,那完全可以给收集器加一个并行的特性啦,所以说干就干:
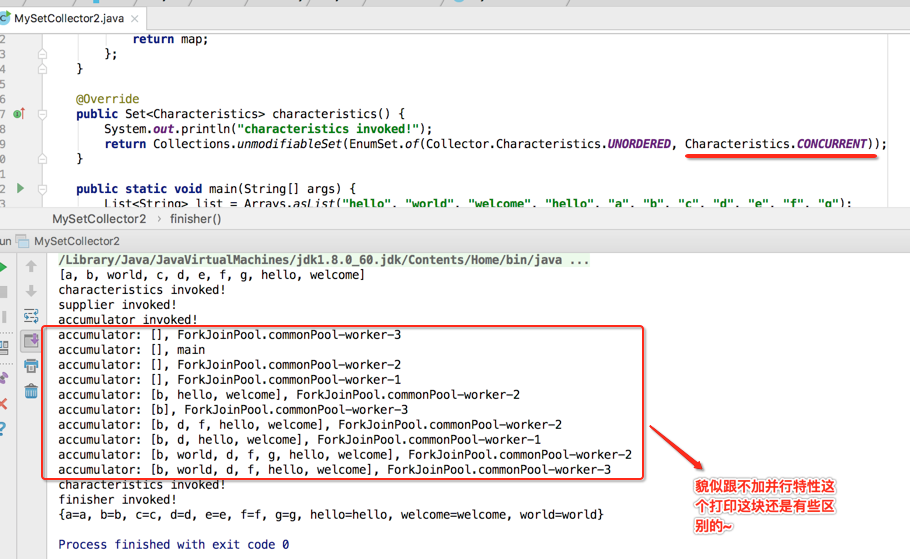
貌似也没啥区别,都正常打印了嘛,接下来再次运行,会出现如下异常:

目前单个运行这种异常显现可能是偶然的,但是!!如果加个循环收集那这个异常就成必然的了,如下:

走你:
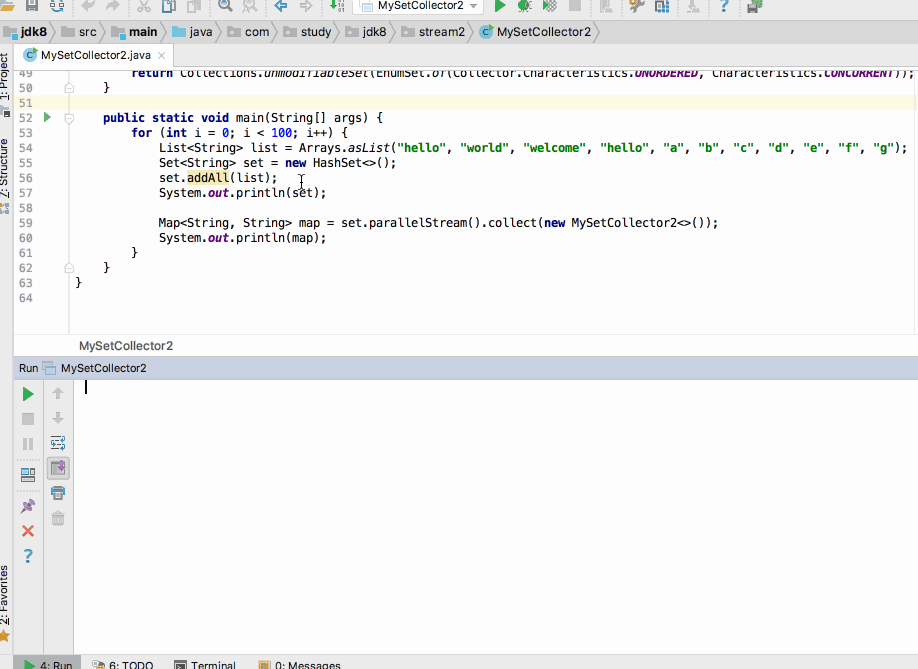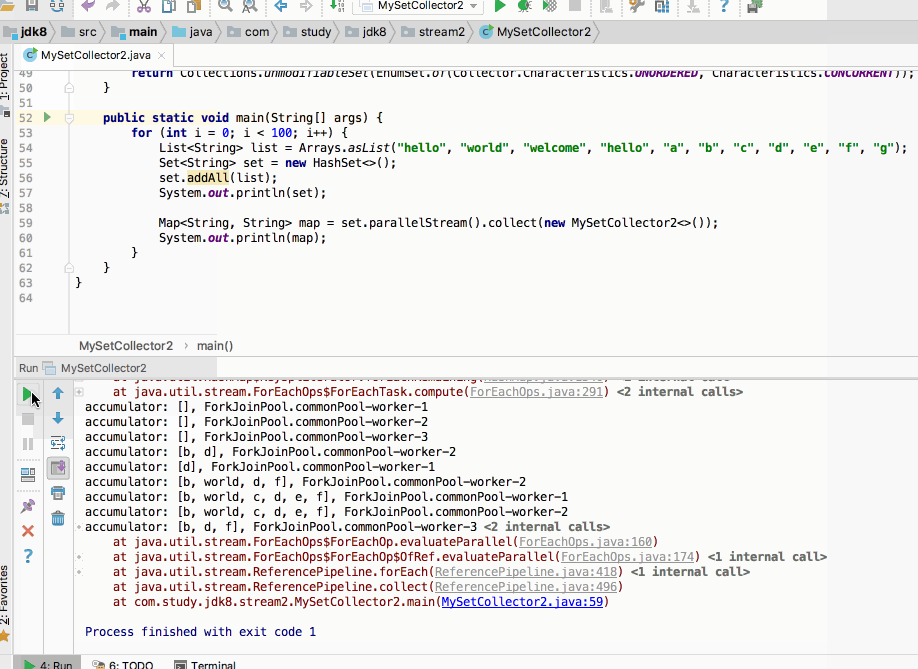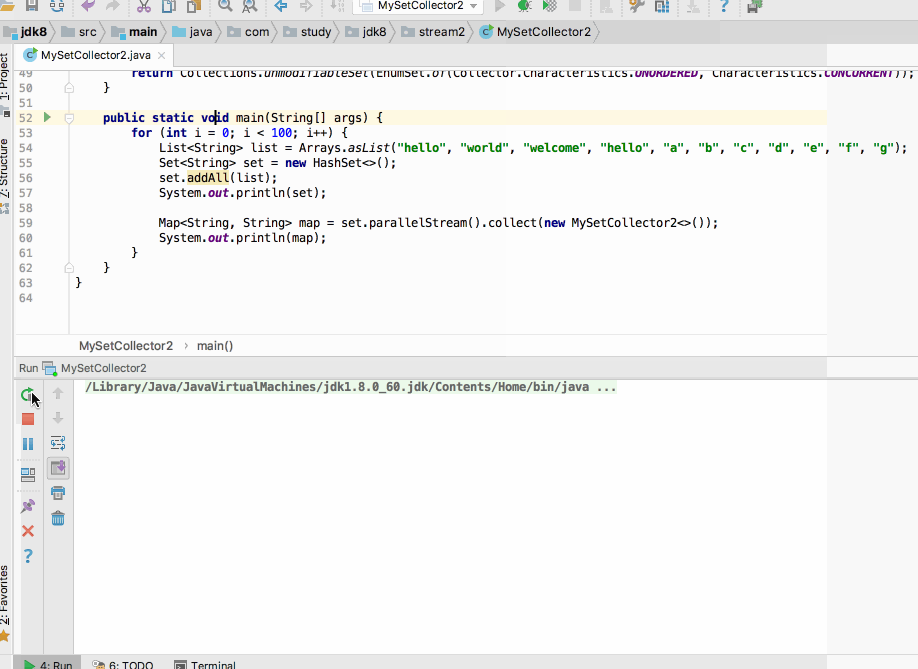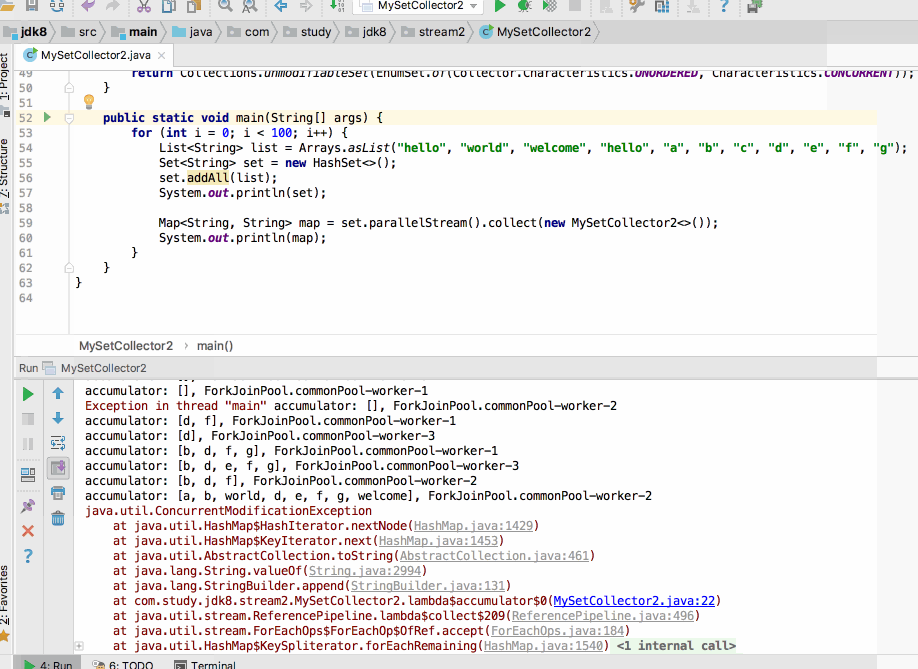
如果将并行特性去掉呢?

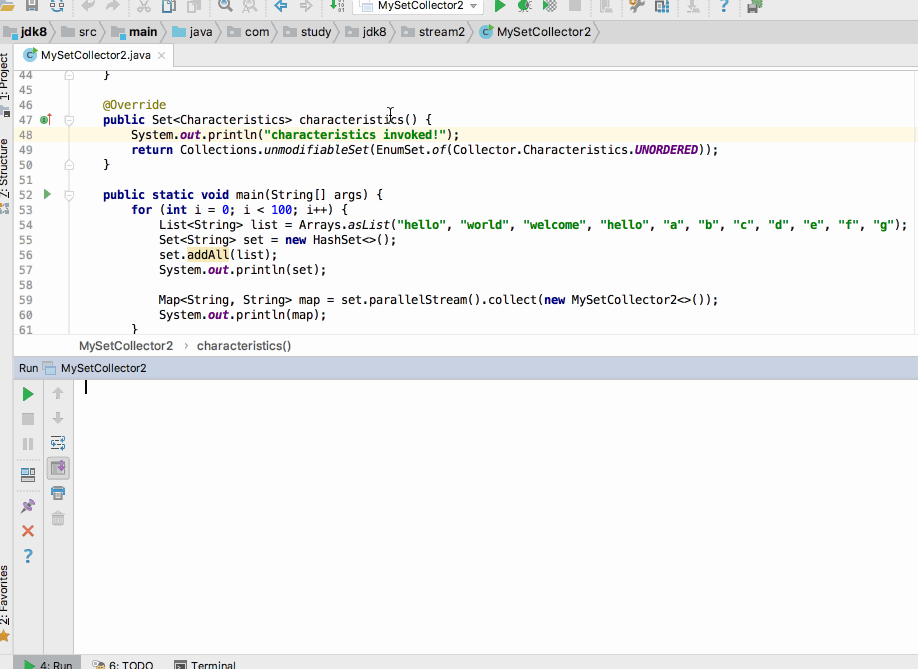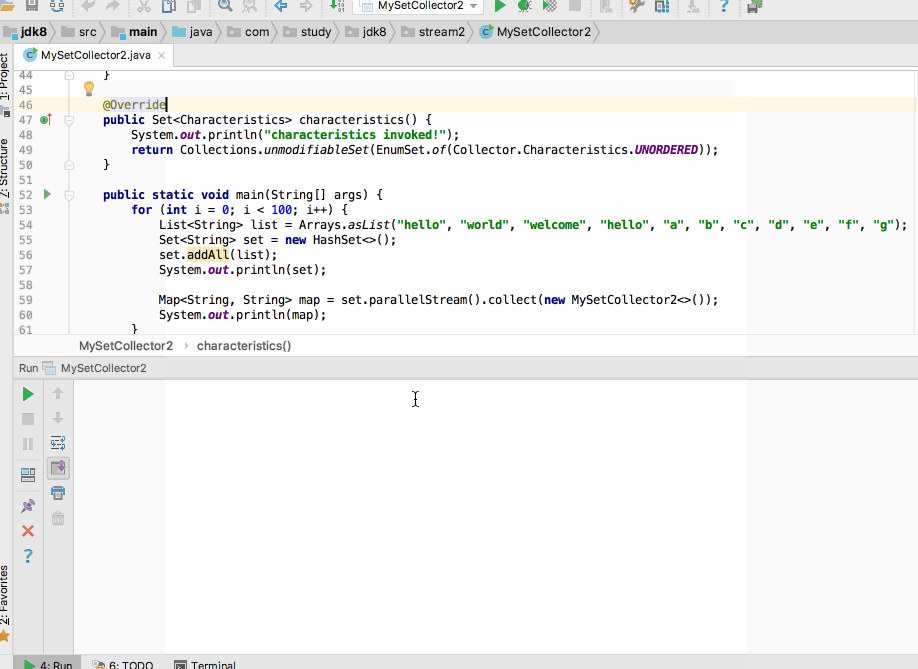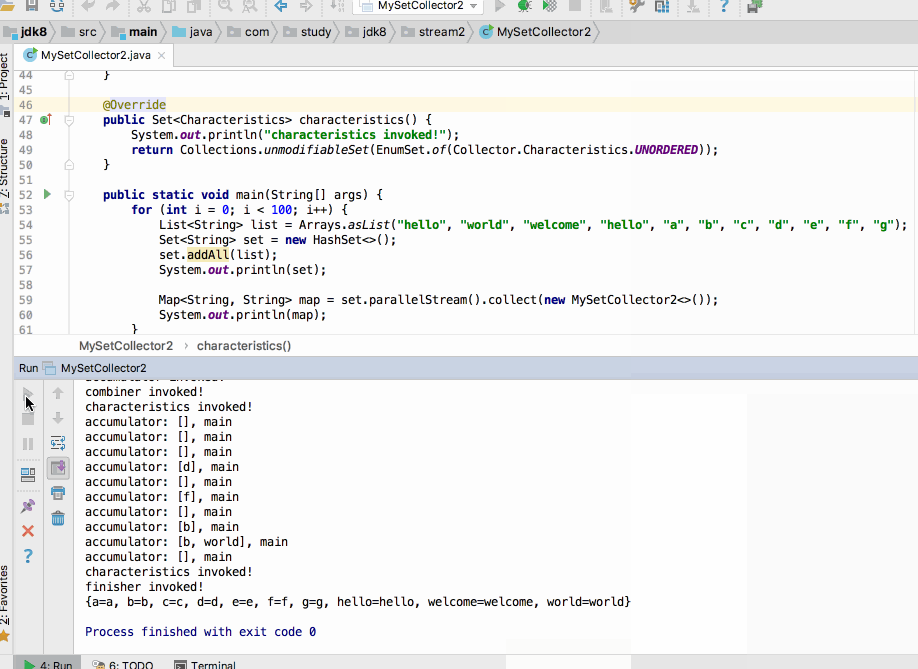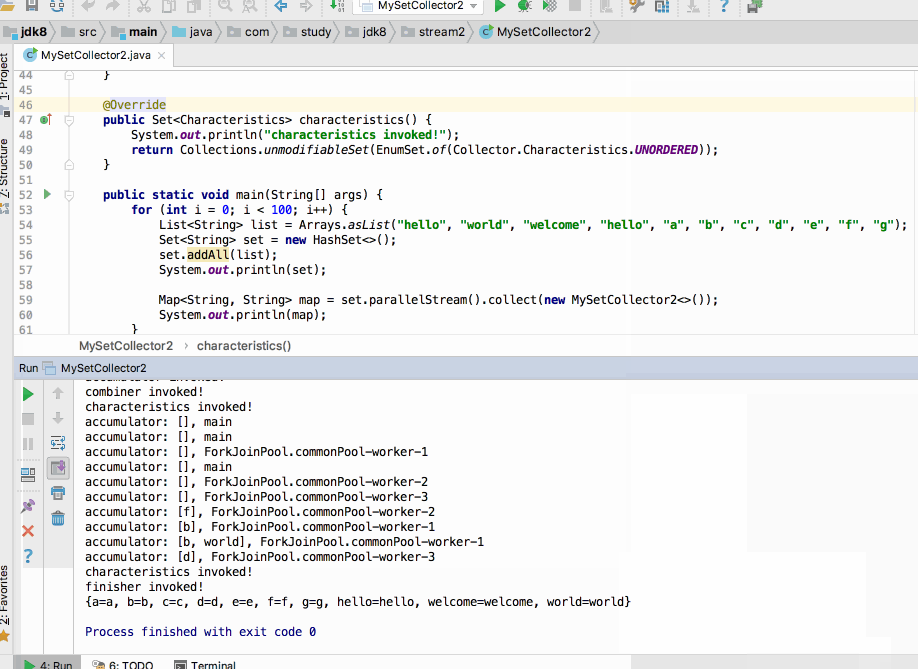
居然木有报异常,好奇怪呀~~为啥加了并行特性与否其造成的结果还不一样呢?下次再来分析原因。


