java8学习之流的短路与并发流
并发流:
从api的角度来看,其实跟咱们之前一直在用的stream()方式差不多,但是底层是有明显的不同,所以这里初步先对并发流有一个基本的认识, 说到串行与并行,最直观的感受就是效率的不同,所以下面以一个相同条件下用串行流与并行流实现看具体耗时为例,来直观的感受一下它们两者在时间效率上的不同,如下:
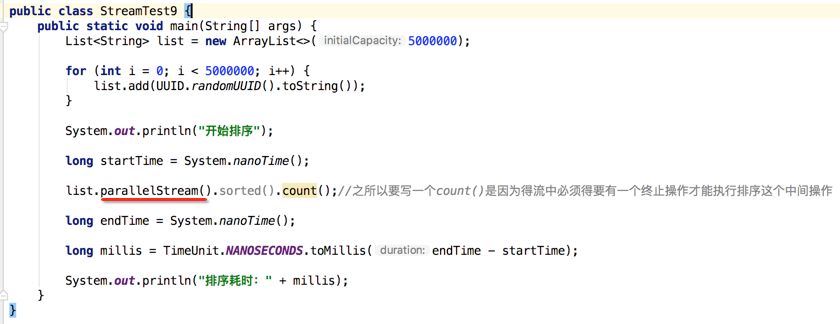
生成500万个UUID,然后对其进行排序,最后看一下排序在串行与并行流中的耗时时间,具体做法如下:

这时执行时间是比较长的,接着则开始对写入的UUID进行排序,主要是对比排序的耗时时间,所以在开始排序前记录一下当前时间,然后在排序完之后再记录下当前时间,再算一下这两个时间总共的耗时长,先来看下串行流的方式:
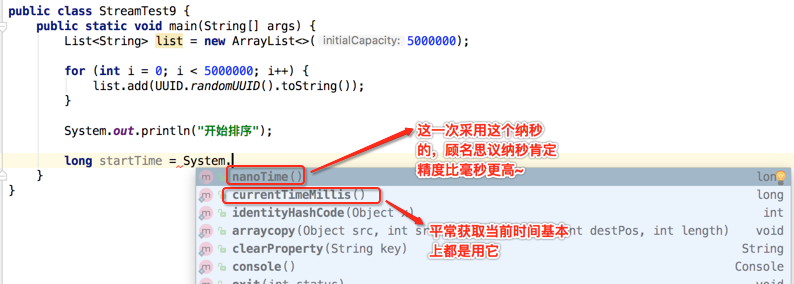
接下来则利用串行流对其UUID集合元素进行排序,如下:
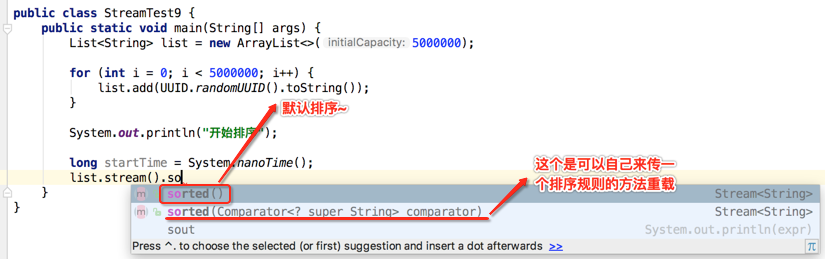
这里直接采用默认的排序,并打上时间字段看耗时如下:

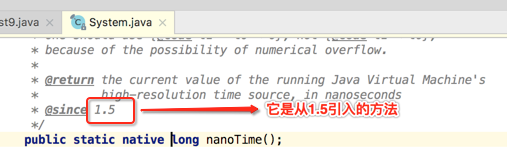
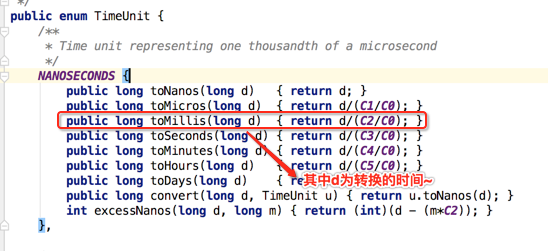
对于上面标问号的部份算是一个新的写法,其中TimeUnit也是在1.5出来的辅助类:



那结合起来看:
d / (C2 / C0) = d / ((1000L * 1000L) / 1000L) = d / 1000L,那不就是将纳秒转换成了微秒了么?
下面来执行一下看用串行流排序会耗多少时间,由于比较耗时就不截动态图了,直接看执行结果:

这时再换成并行流,改一个方法既可:
运行看一下它的时间耗了多久:

如我们的预期并行流的方式明显比串行流的方式要快,根据原因是串行流是单线程去执行的,而并行流则是多线程去执行的,采用fork-join的方式去执行,这里有个感性的认识,关于串行流和并行流的底层的实现之后再去探讨它。
流的短路:
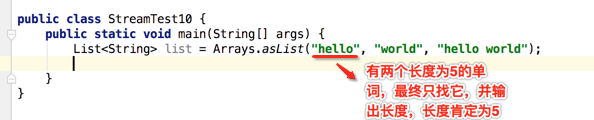
下面继续再看代码,对于一个字符串的集合,找出长度为5的单词,并且只找到第一个,并将其长度打出来,如下:
如何实现呢?下面开始:
既然最终是找的单词的长度,那可以将单词映射成长度,当然采用map操作喽,如下:

但是需要注意一下细节,既然知道映射之后的类型为int,那这里就最好用具化的map接口,mapToInt(),如下:

为什么要注意这个小细节,因为可以避勉装箱和拆箱,接着就是从集合中找出长度=5的元素,则需要对它进行过滤如下:

接着只找第一个,如下:

既然是Optional,那最佳写法应该是:

接着改一下元素的值,将其改成都没有长度为5的单词,看输出:

对于这个例子本身其实没啥意义,但是~~是为了说明下面的一个问题,下面对其进行进一步改造,如下:
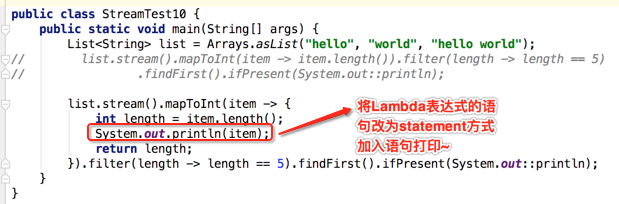
那最终会输出啥呢?先来分析一下结果:
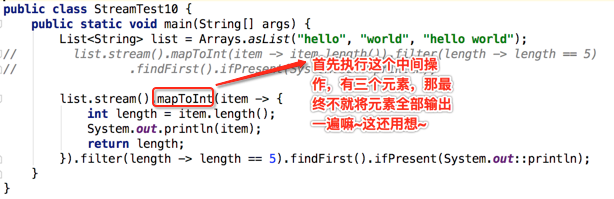
下面运行看一下是否如我们所想:
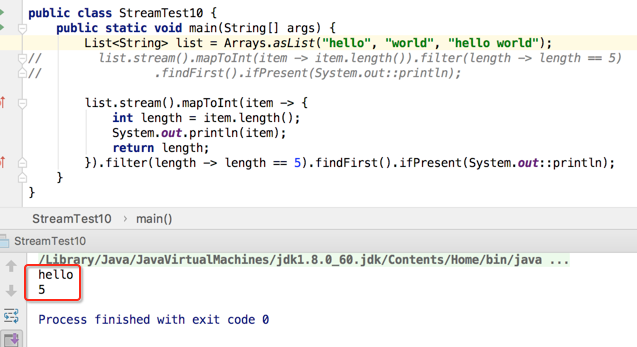
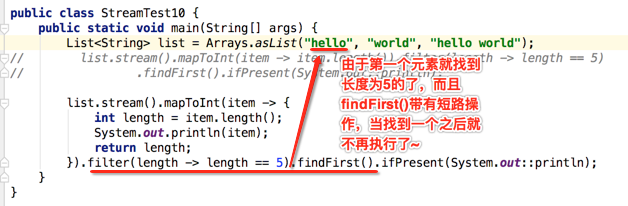
呃~~什么鬼~~那为啥只打印出了一个元素呢?下面解释一下:因为流的若干个中间操作是针对每一个元素的,意思也就是说当处理元素时会针对每一个元素应用这若干个操作,而且会将这些操作串行化,如mapToInt()执行完之后就会执行filter(),每个无素都会按这种串行的操作去执行,而非一个操作应用在各元素之后再应用其它操作,而且操作里面还存在一些短路的情况,结合咱们这个例子:
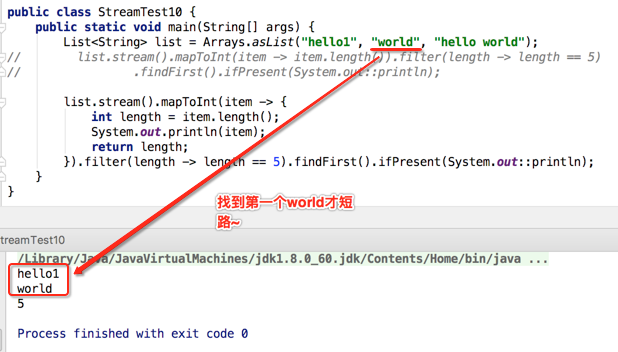
如果说将第一个元素改成长度不是5,再看打印:

stream.flatMap()应用:
接下来再来举例:对于如下集合:

找出所有的单词,并写将重复的单词给去重掉,那对于上面这个集合其结果应该为:hello、world、welcome。
那下面来实现下:
首先将单词以空格进行拆分,如下:

然后对单词去重:

接着编译运行:
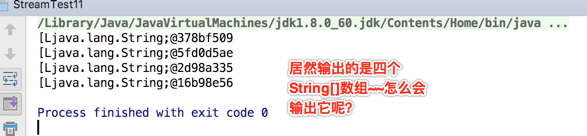
分析一下原因:

那对数组进行去重那肯定就有问题啦,咱们可以将代码拆分一下验证下:
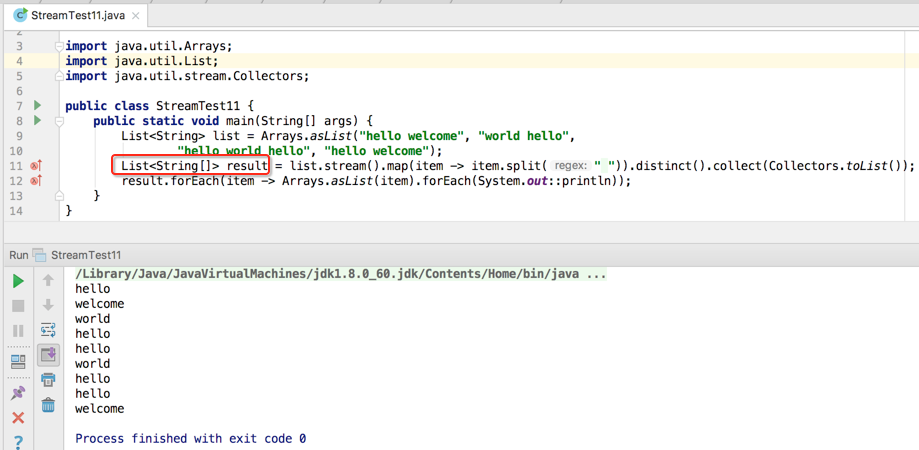
解决之道:再map()之后加上flatMap(),这个flatMap()我们在之前也已经接触过了,就是将元素打平成一个Stream,也就是Stream<String>,对单词进行去重得针对这种类型的Stream才行,所以代码修改为:

具体使用如下:

具体使用如下:

对于四个String[]的集合当然对应四个Stream啦,而flatMap操作实际就是将这四个Stream打平变成一个Stream,最后再去复打印如下:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号