

02-为什么dex文件比class文件更适合移动端?
接着上一次https://www.cnblogs.com/webor2006/p/16574474.html的Android面试题继续, 从标题就可以看出,此题是一个比较开放性的,所以咱们发挥的空间也是比较大,根据自己的了解或多或少能回答一些,但是!!!要想答得有理有据,那么要掌握的知识其实还是很多的,下面则来全面剖析一下它。
题面解析:
关于这题,提练核心关键字:
为什么“dex文件”比“class文件”更适合“移动端”?
也就是:dex文件、class文件、移动端。根据这三个关键字,我们就需要有如下了解:
1、dex文件结构的了解;
2、class文件结构的了解;
3、说到移动端,相比服务端而言,它的内存是有限的,而且安装包体积不宜太大,频繁I/O操作会带来卡顿。也就是这块就是涉及到性能相关的点了。
本题得分点:
还是像上次那样,从以下两个角度来看:
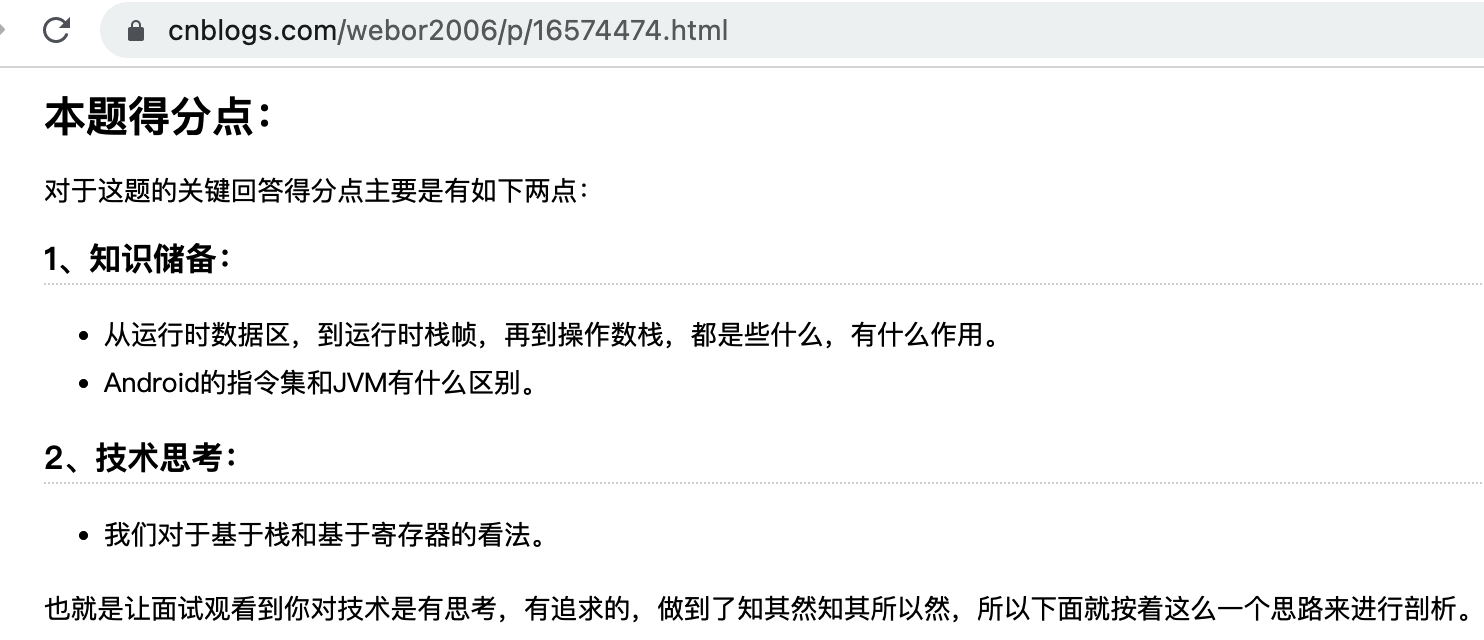
知识储备:
- class文件结构了解
- dex文件结构了解
技术思考:
- 分析各自优劣,以及移动端的特点。
class文件:
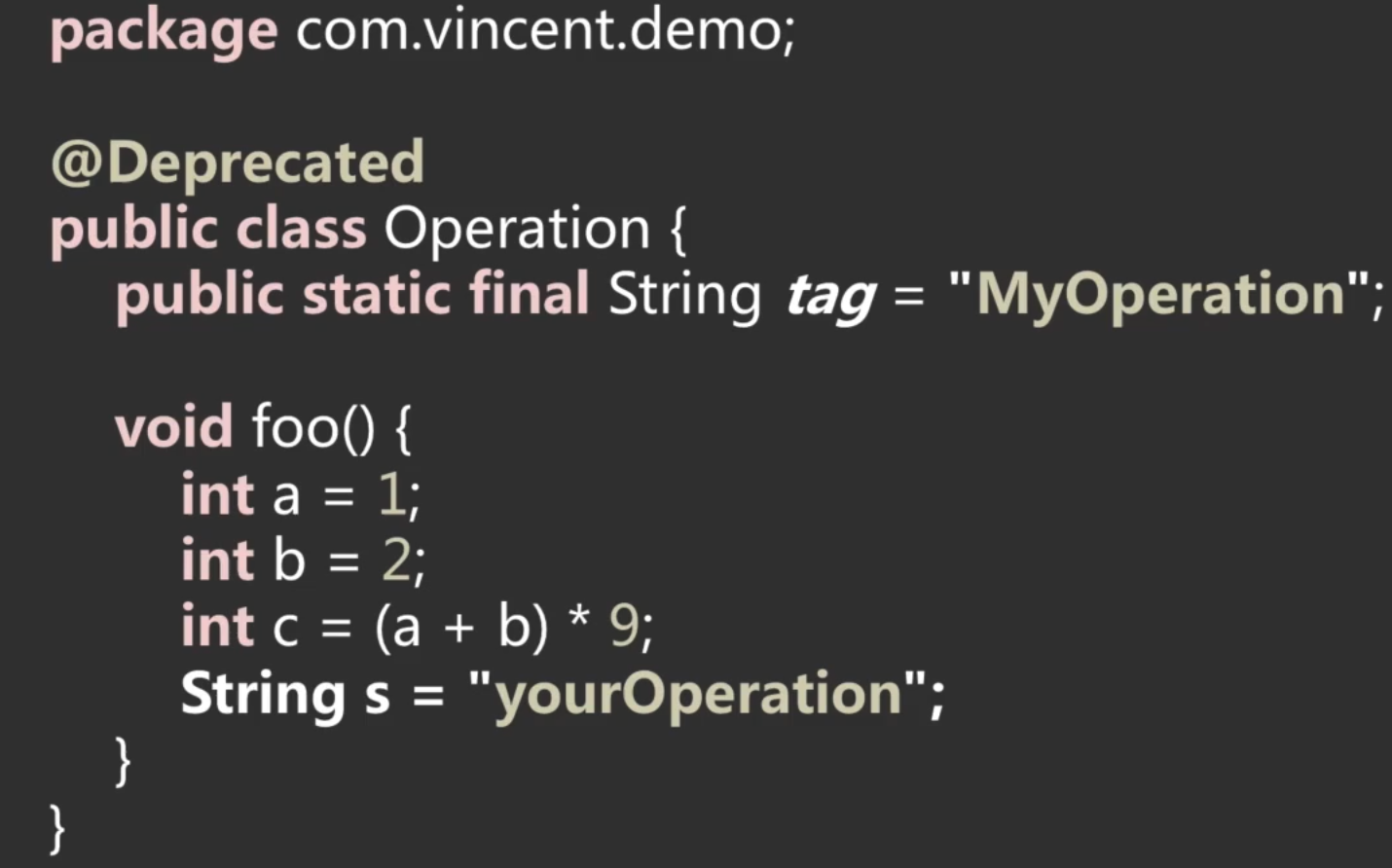
源码:
关于class文件的详细剖析在我之前的JVM学习章节中已经很详细了:![]()
这里整体再来回顾一下,以这么个源码为例:
物理结构:
用javac将其编译成Operation.class,然后用二进制的查看工具,比如当时我学习JVM用的是这个工具:https://hexfiend.com/
打开就会长成这样:

其中“cafebabe”是大家在Java领域所熟知的~~
逻辑结构:
接下来看一下字节码的逻辑结构。
文件头:
它主要是存放着该字节码文件的一些基本信息。 它包含三部分信息:

- 魔数的唯一作用是告诉虚拟机,这是一个可接受的Class文件,固定值为0xCAFEBABE;
- 主版本号代表此Class文件的版本号,比如咱们这个例子是:

它代表JDK1.7.0。
常量池:
常量池其实就是Class文件的资源仓库,占用空间较大。它有如下两部分组成:

由于常量池容量的计数从1开始,所以常量的数量是计数-1,也就是在整个文件的结构来说,跟在2个字节常量池计数后面就是常量池计数-1个cp_info的常量。
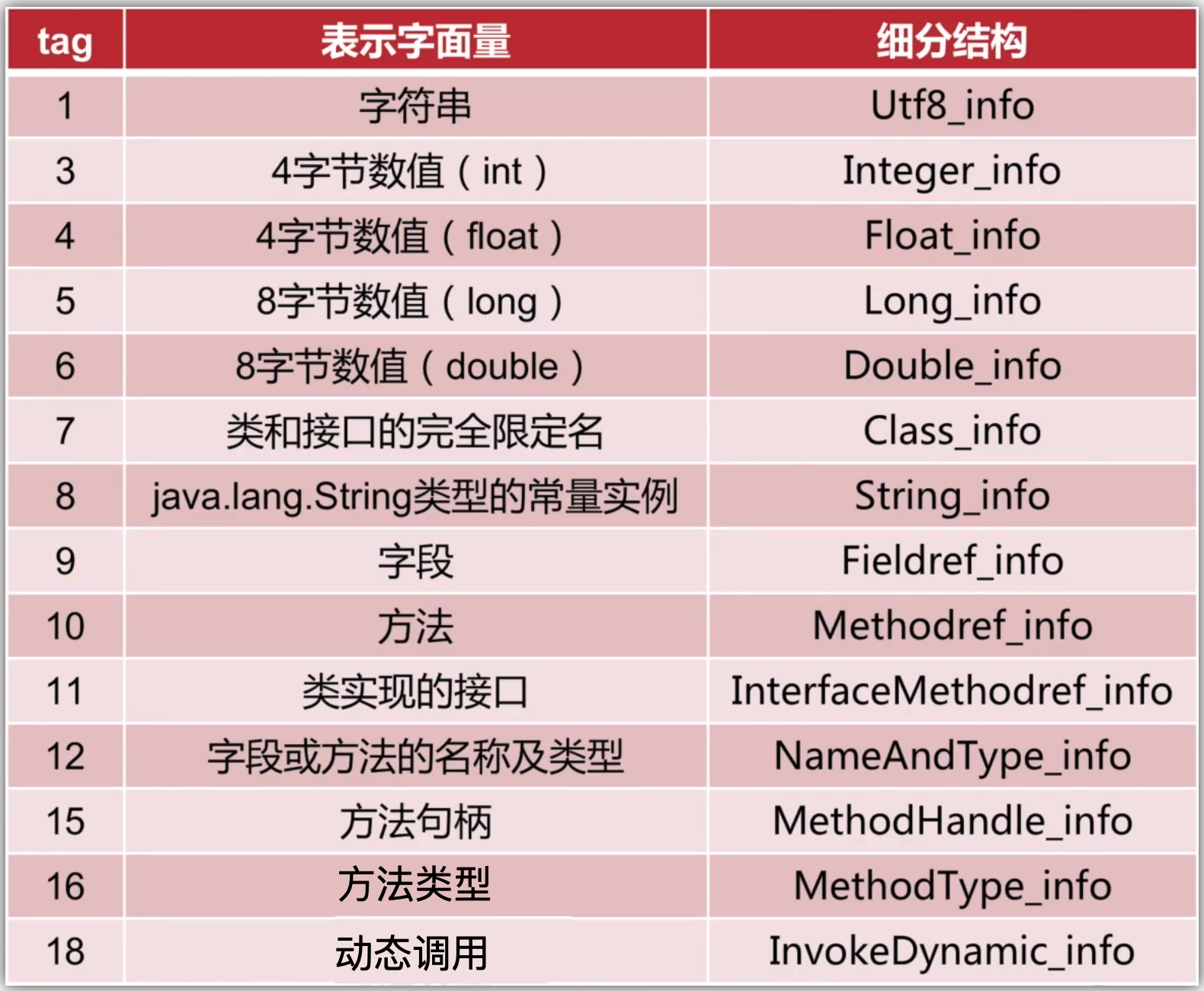
cp_info能容纳哪些内容?
1、字面量:
主要是包括:字符串文本、final常量的值、基本数据类型的值。
2、符号:
主要是包括:类和接口的完全限定名、字段名和类型、方法名和类型。
简言之:字面量可以理解成代码中直接给定的一些量,而符号就是对类、字段以及方法的一个描述。
cp_info的结构:
接下来了解一下cp_info它的结构:

其中tag对应如下18种类型取值范围:
String_info和Utf8_info的区别:
其中比较特殊的是tag 8,它是String_info,表示java.lang.String类型的常量实例,而其它的都是基本数据类型,那它跟基本数据类型的Utf8_info有啥区别呢?

下面来看一下:

其中的u2就是指在某个字符串在常量池中的索引:

而Utf8_Info的结构如下:

其中很明显的区别在于,String_info作为String的一个实例,它木有真正存储字符串的值的而只是一个索引,真正字符串的值是存储在Utf8_Info里。
将class通过javap查看常量池信息:
要想查看class字节码中的常量池信息,可以通过javap -c命令,这里就不演示了,因为在我的JVM当年的学习中已经详细学过了,下面将其对应的常量池信息给贴出来:
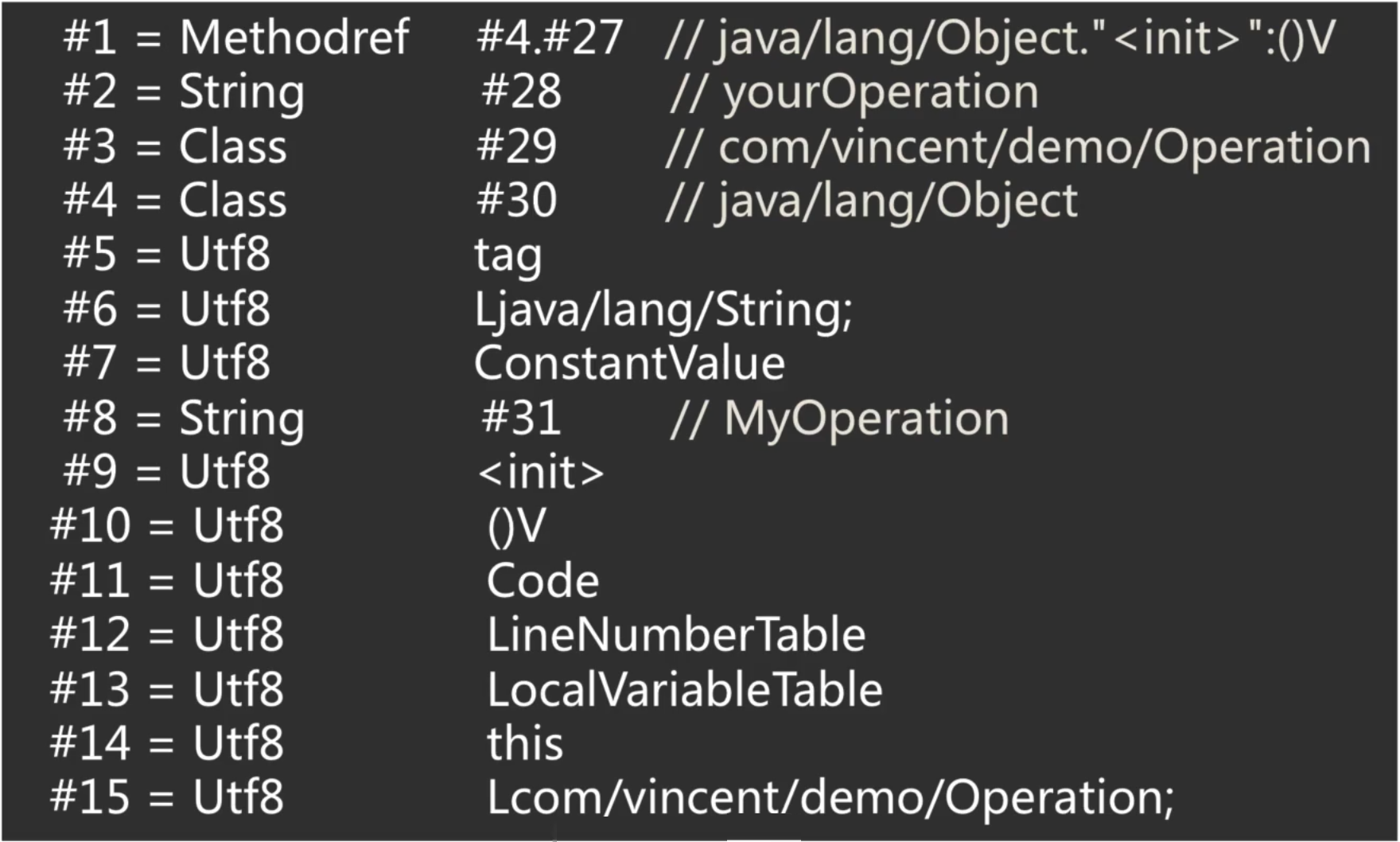
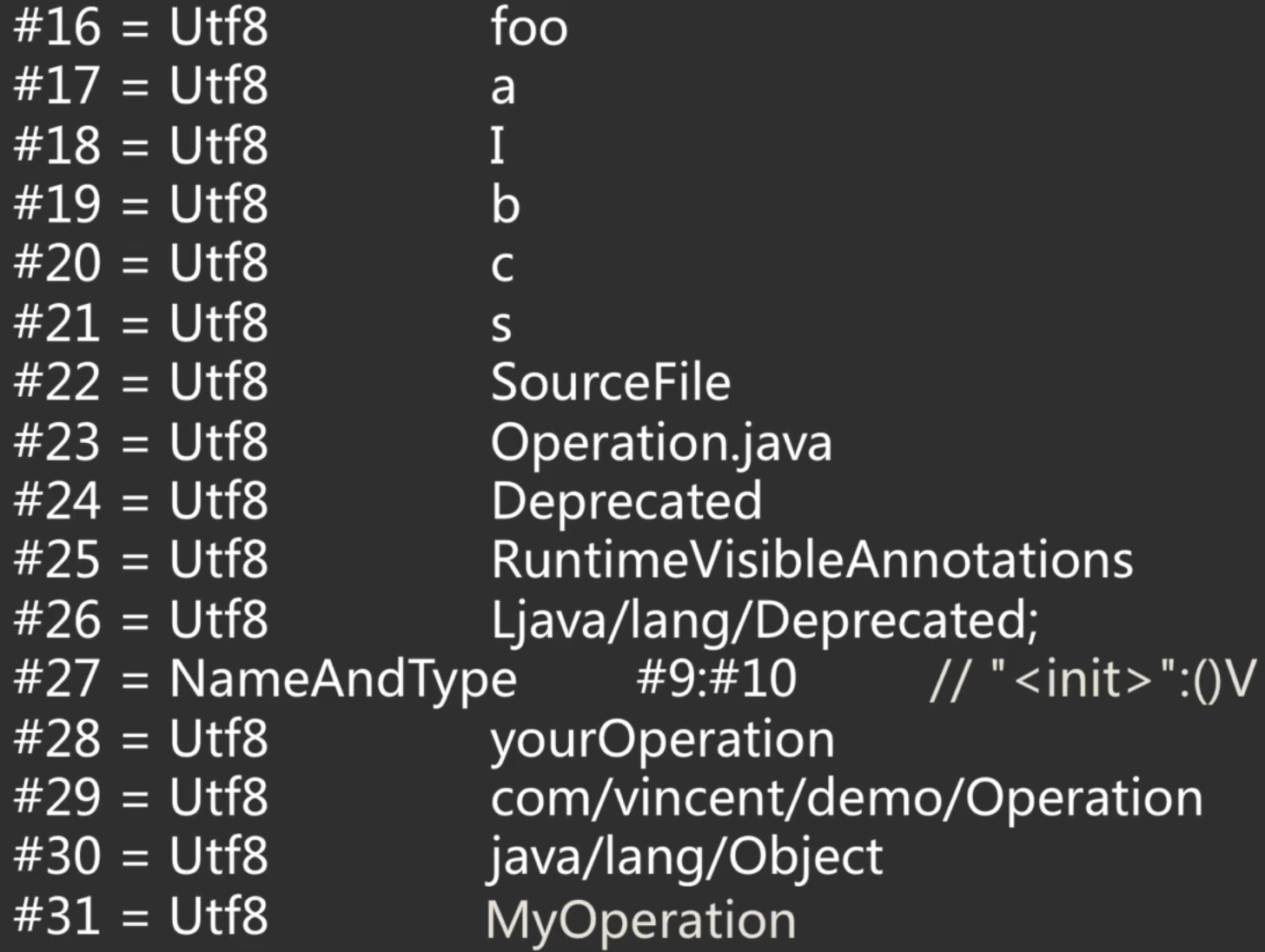
关于这些常量池的具体含义这里就不过多说明了,因为之前学习的JVM已经完整的剖析过了,有兴趣可以参阅以下三篇:
- https://www.cnblogs.com/webor2006/p/9410518.html
- https://www.cnblogs.com/webor2006/p/9416831.html
- https://www.cnblogs.com/webor2006/p/9457722.html
类信息:
它主要是有如下信息:
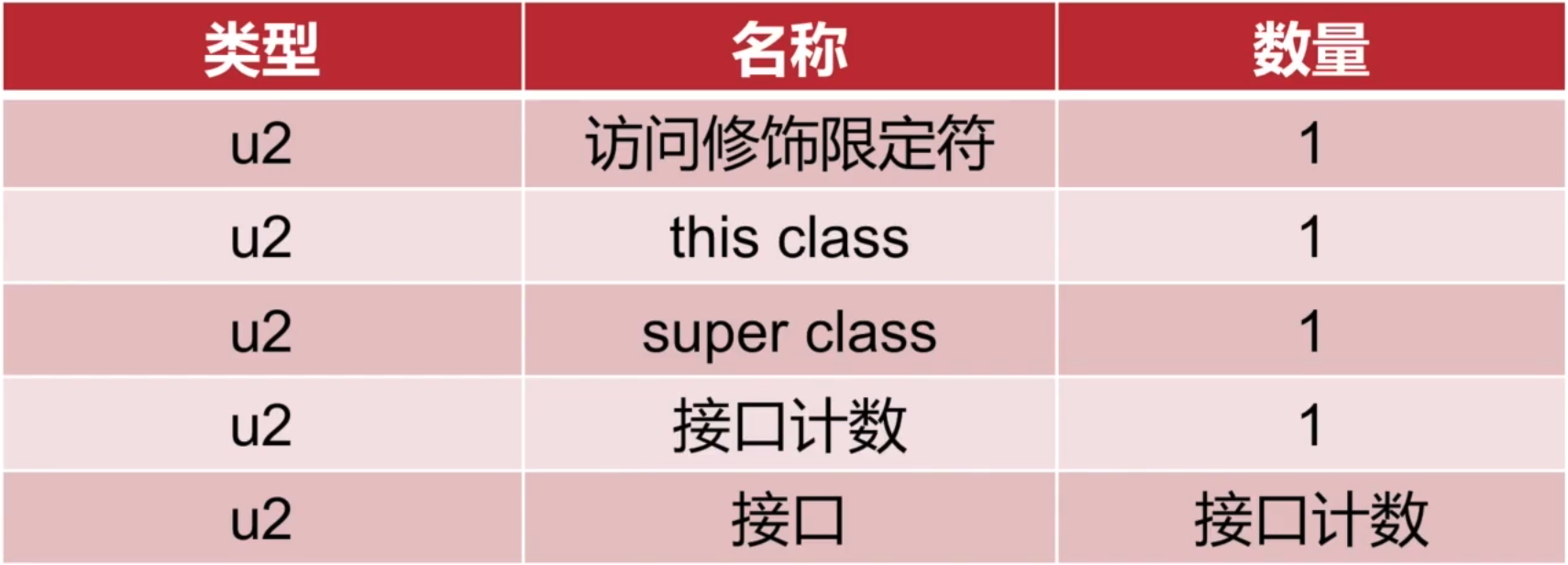
- 访问修饰限定符:这里用2个字节来表示,由于限制符在Java也就那几个,所以2个字节足以容纳所有情况了。
- this class、super class,都是2个字节,指向的是常量池中对类的定义。
- 接口计数,由于Java一个类可以实现多个接口,所以接口计数后面跟着的是接口计数的类所实现的接口在常量池中的引用。
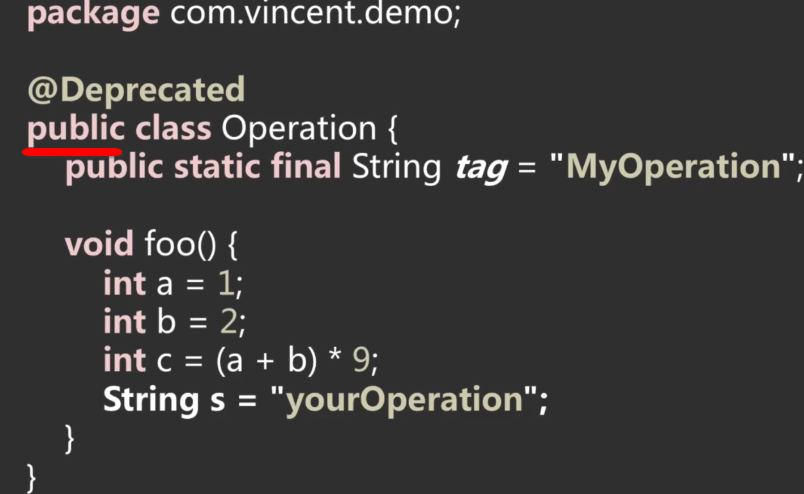
利用javap对class进行执行之后,这块信息就是为信息:

刚好对应咱们的类定义:
字段表:
它的结构为:

这里的字段包括类级别和实例级别的变量,不包括方法内部的局部变量。比如咱们的这个类,有一个常量字段:
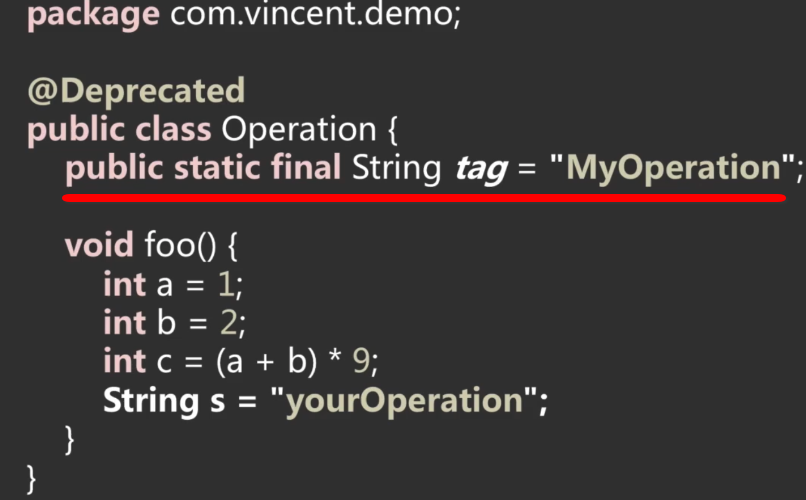
使用javap反编译一下,信息如下:

而对于final类型的常量表示让虚拟机直接把常量池中的字符串对象赋值给这个字段。
方法表:
它的结构为:

主要是存储对方法的描述。 回到咱们的Java代码,有这么一个方法:
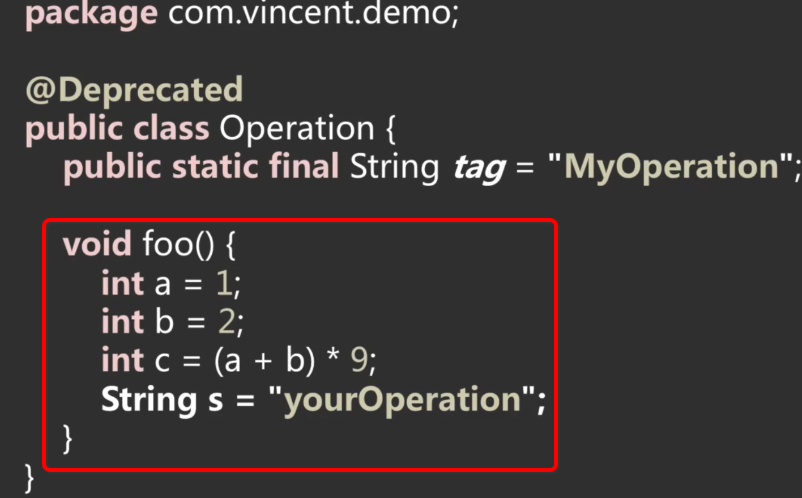
使用javap对源码进行反编译,其方法表相关的信息如下:
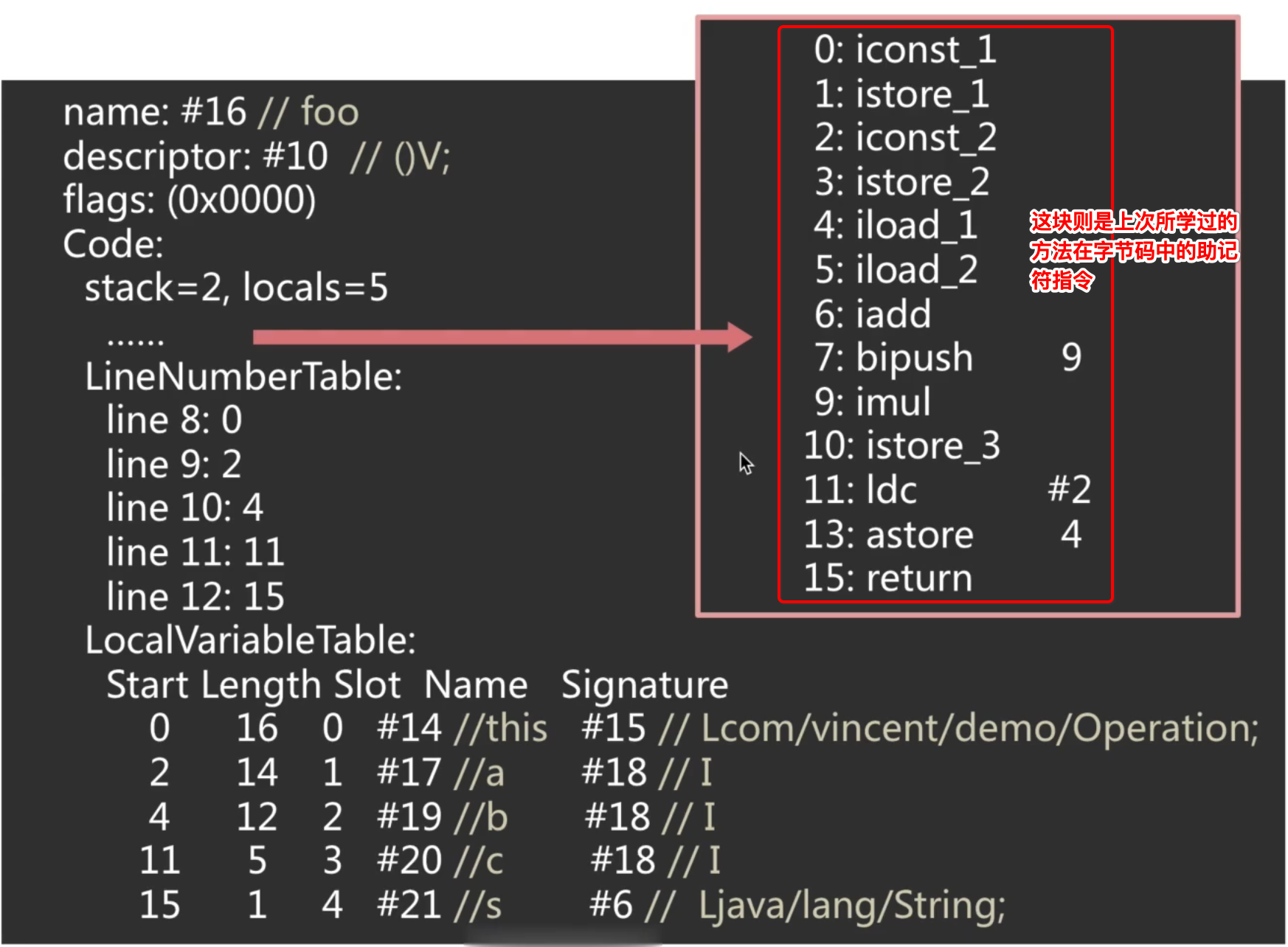
- name:表示方法名在字节码常量池中的索引。
- descriptor:表示方法定义描述名,也是对应于字节码常量池中的索引。
- flags:表示方法访问修饰限定符。
- Code:则是代表方法中的具体代码,这块在上一次https://www.cnblogs.com/webor2006/p/16574474.html中已经详细学习过了。
- LineNumberTable:行号表,它其实表示的字节码的行号与源码的行号的一个对应关系,这也是为啥程序在运行时是用的字节码,但是当程序出异常时能够精准定位到源码的行号,其实原因就在于此,
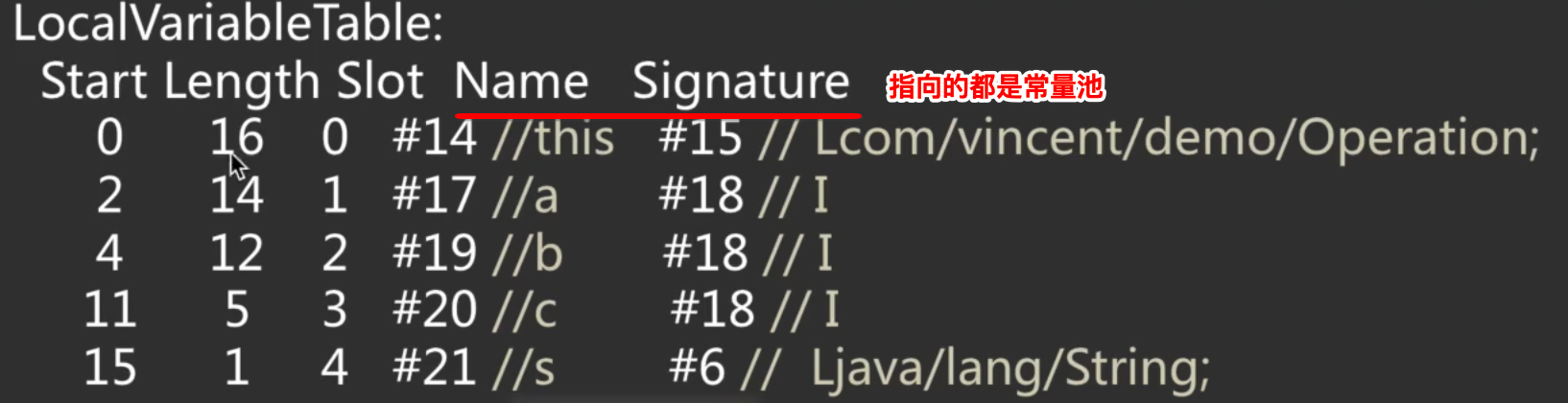
- LocalVariableTable:局部变量表,这里我们定义了四个局部变量,但是还有一个隐含的this,所以一起是5个,其中:
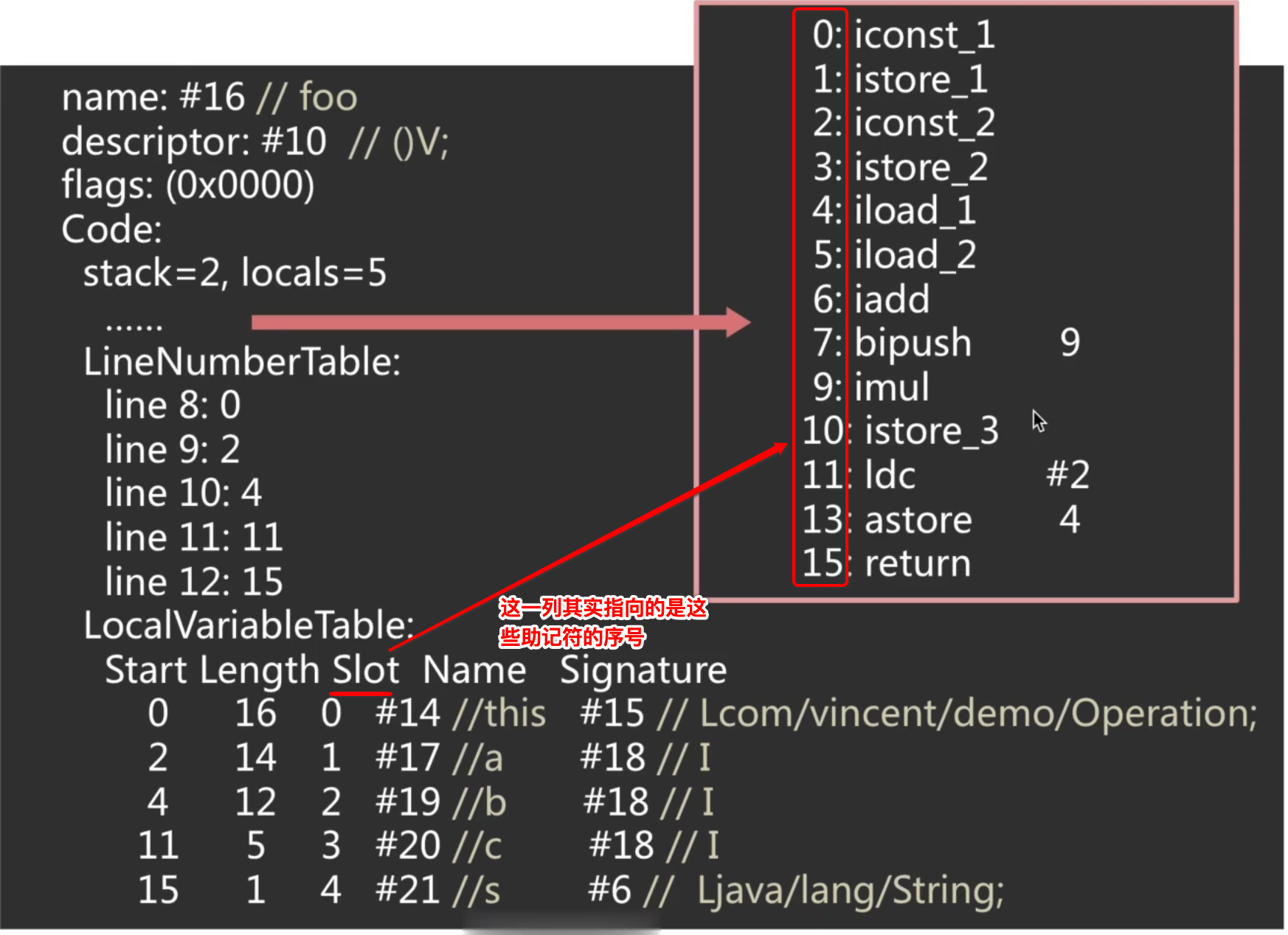
其中比较难理解的是这两列:
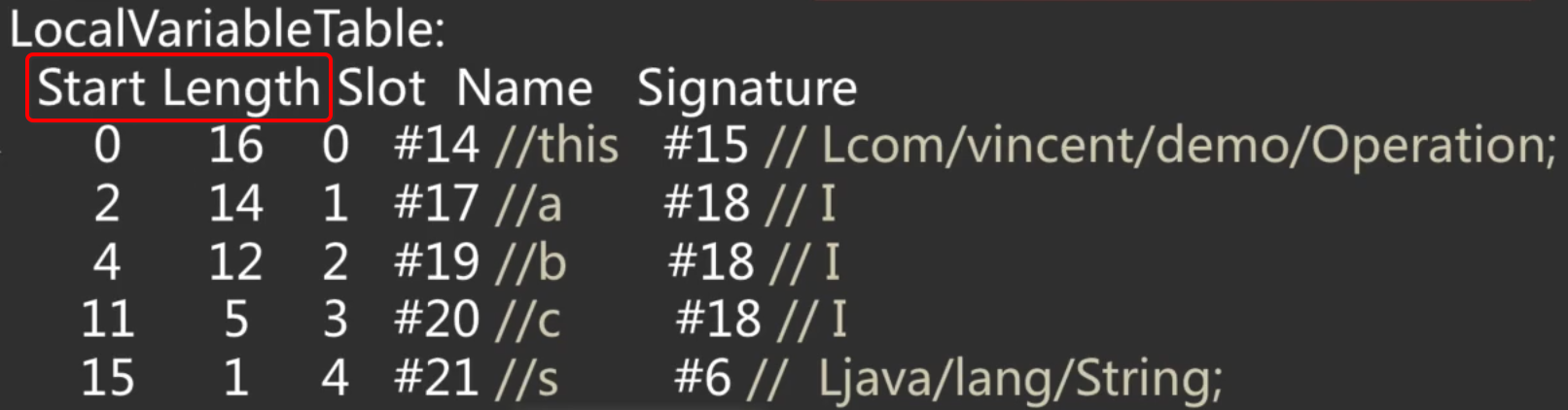
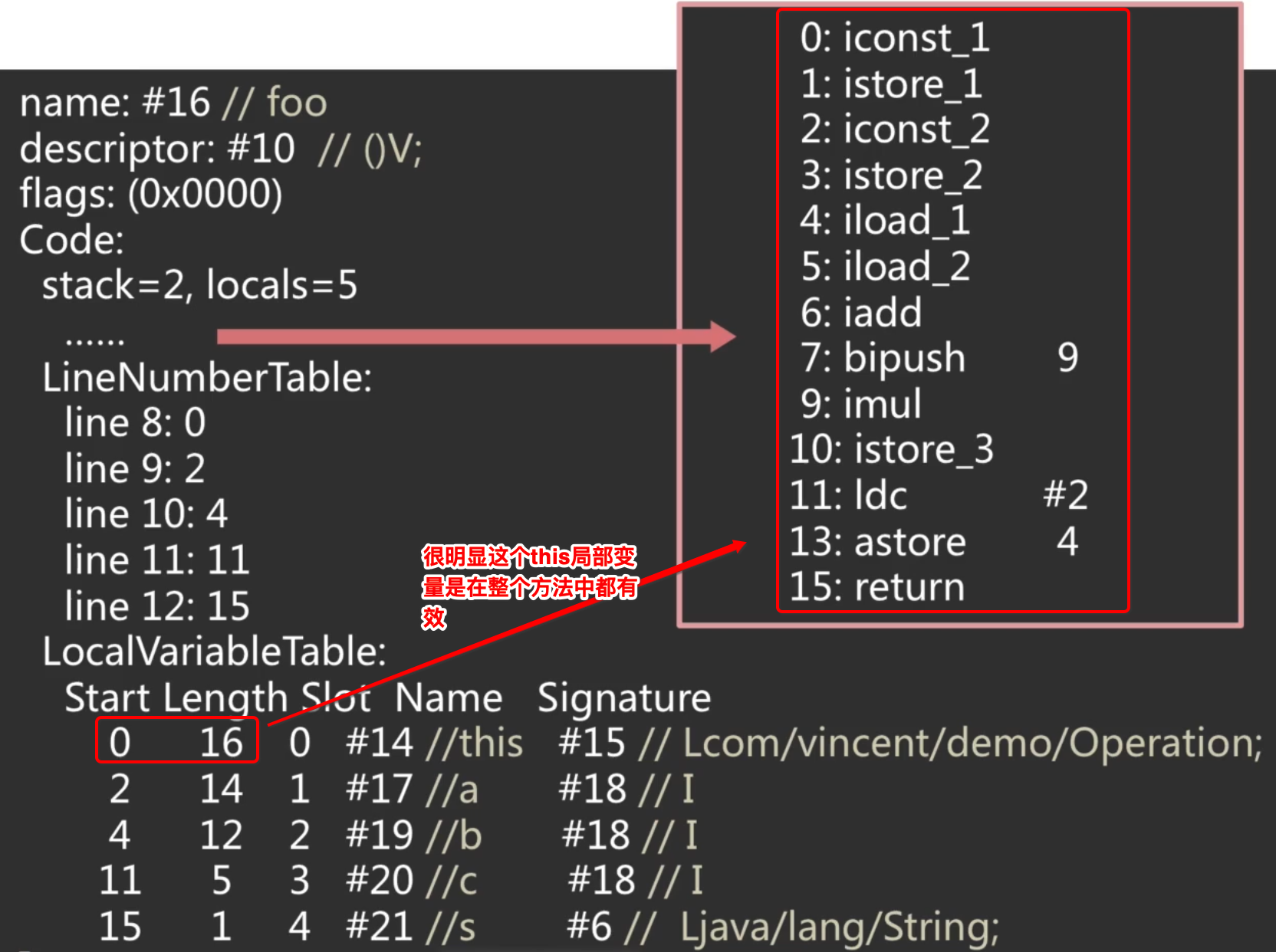
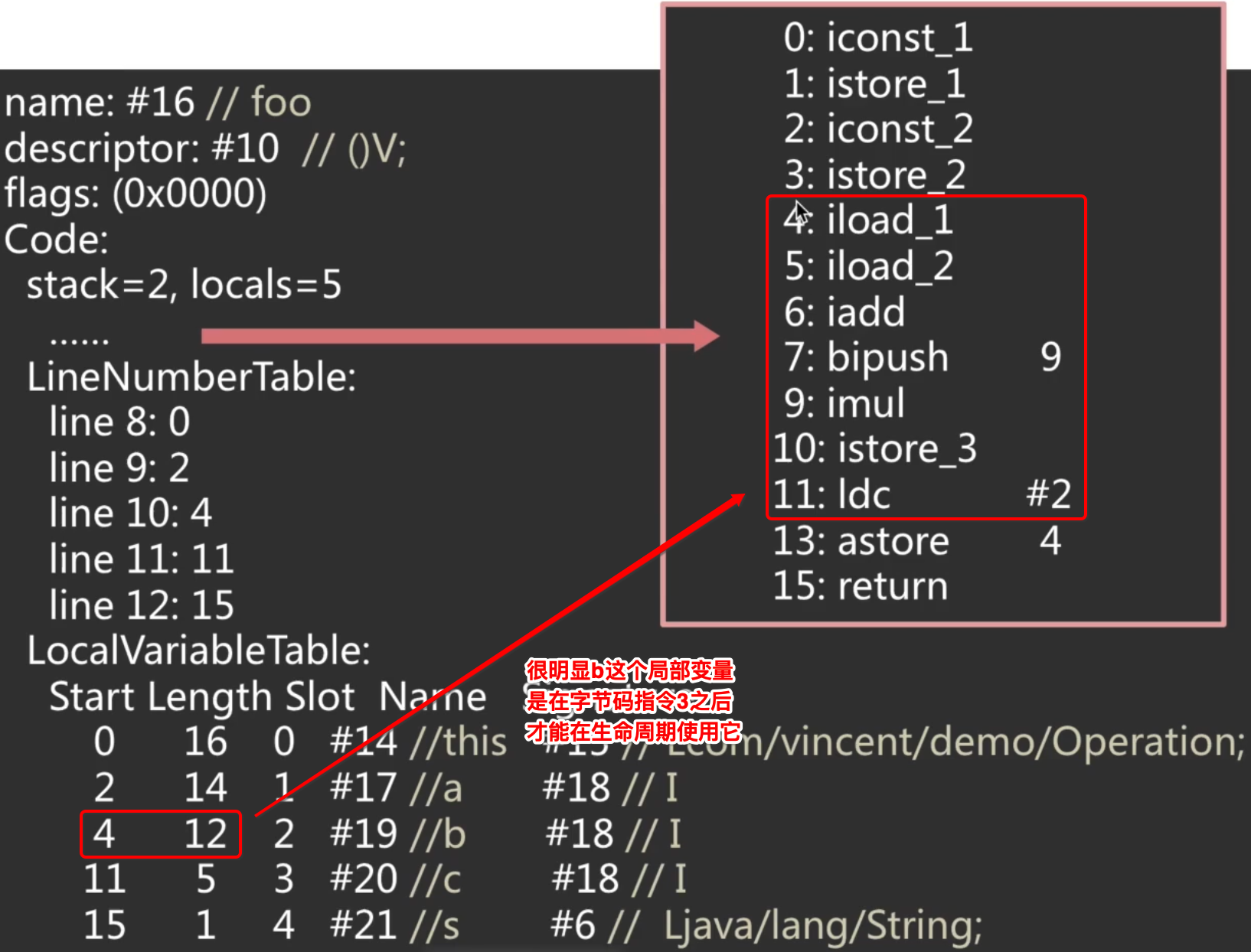
它们并不是表示局部变量本身所占用的长度,而是局部变量的生命周期,也就是表示在程序计数器上这局部变量在生命周期(作用域)开始的行数和持续的行数,啥意思呢?举个例子说明一下:
属性信息:
比如在类上加的一些原注解以及Class定义的一些源文件名等,回到咱们的这个例子,使用javap反编译看到的属性信息如下:

SourceFille:表示java的源文件名;
Deprecated:表示此类是否是被废弃的。
RuntimeVisibleAnnotations:类的元注解,此例我们给类加了Deprecated注解了。
关于方法表和属性表这块的详细知识可以参考我之前所记录的笔记:https://www.cnblogs.com/webor2006/p/9459681.html,这里也能看出,当初学习的JVM就能在某个时刻发挥作用,任何知识它都不是独立存在的,所以要坚信一点:工作中用不到的知识点学了不要觉得浪费时间浪费生命,在某个时刻这些知识就会发挥它的作用,关于这块再举个例子,由于我所在公司会
dex文件:
概述:
在了解了class文件之后,接下来则来了解一下Android所使用的dex文件,它的由来其实如下图: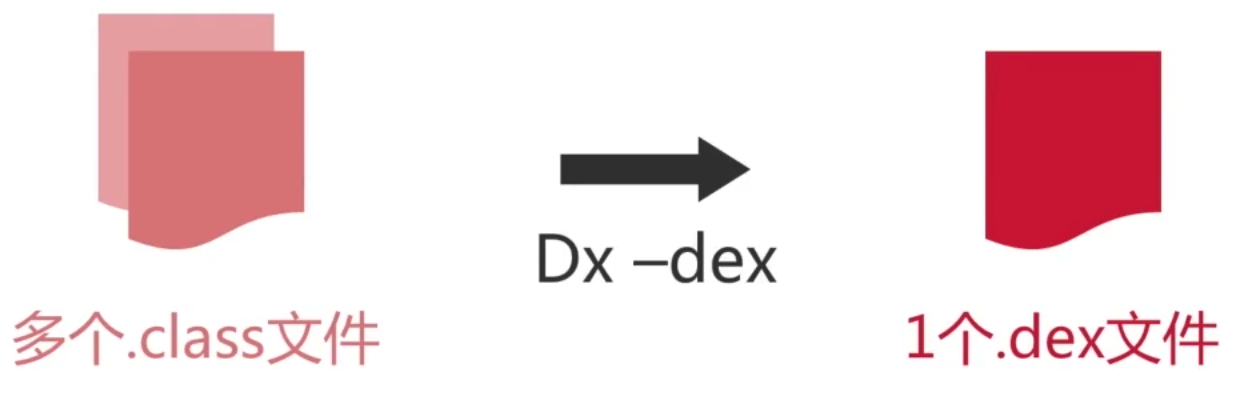
其中这里暂时不考虑multidex多dex的情况。
结构了解:
对于class文件我们知道它是包含在jar中的对吧,也就是:

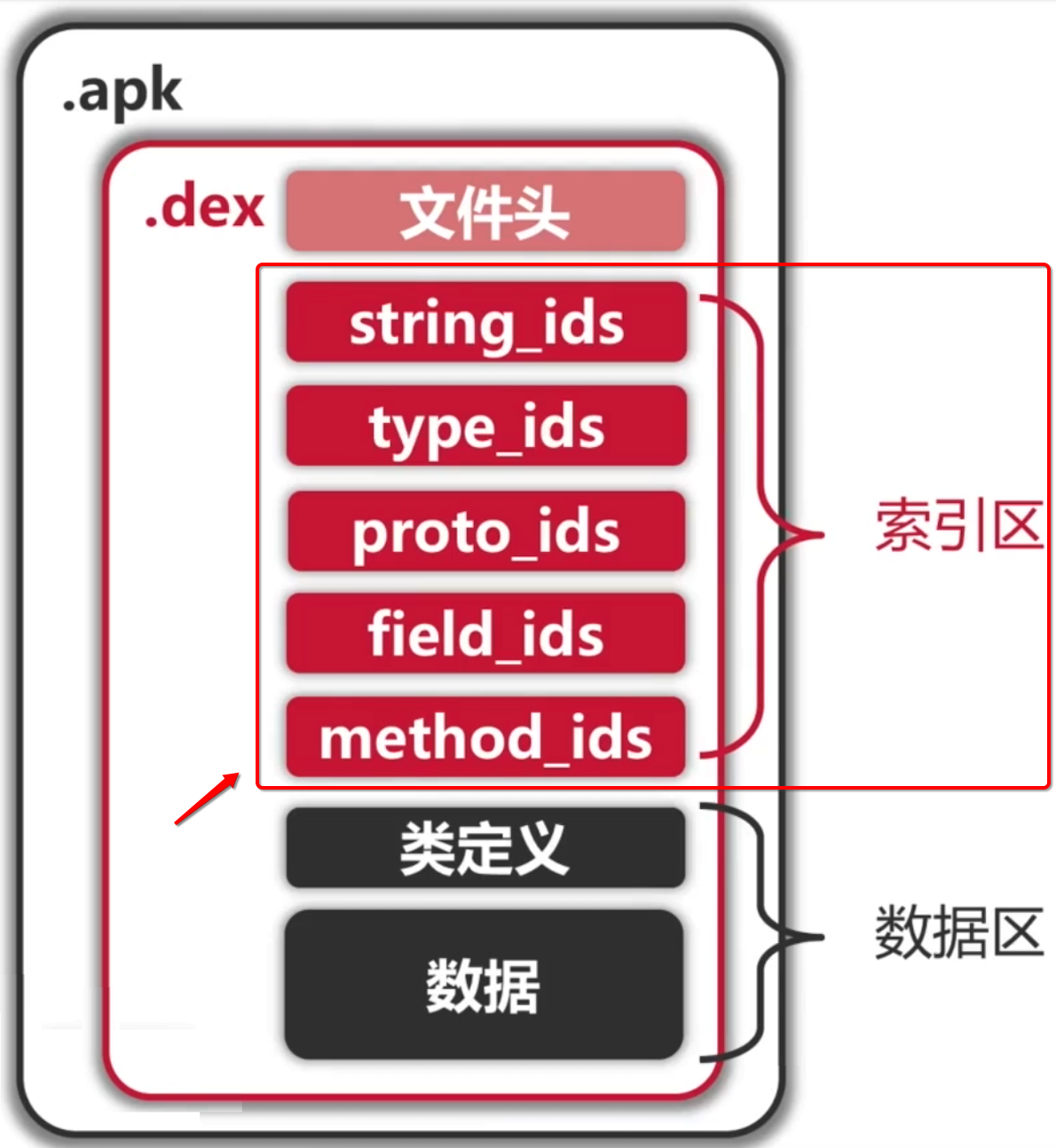
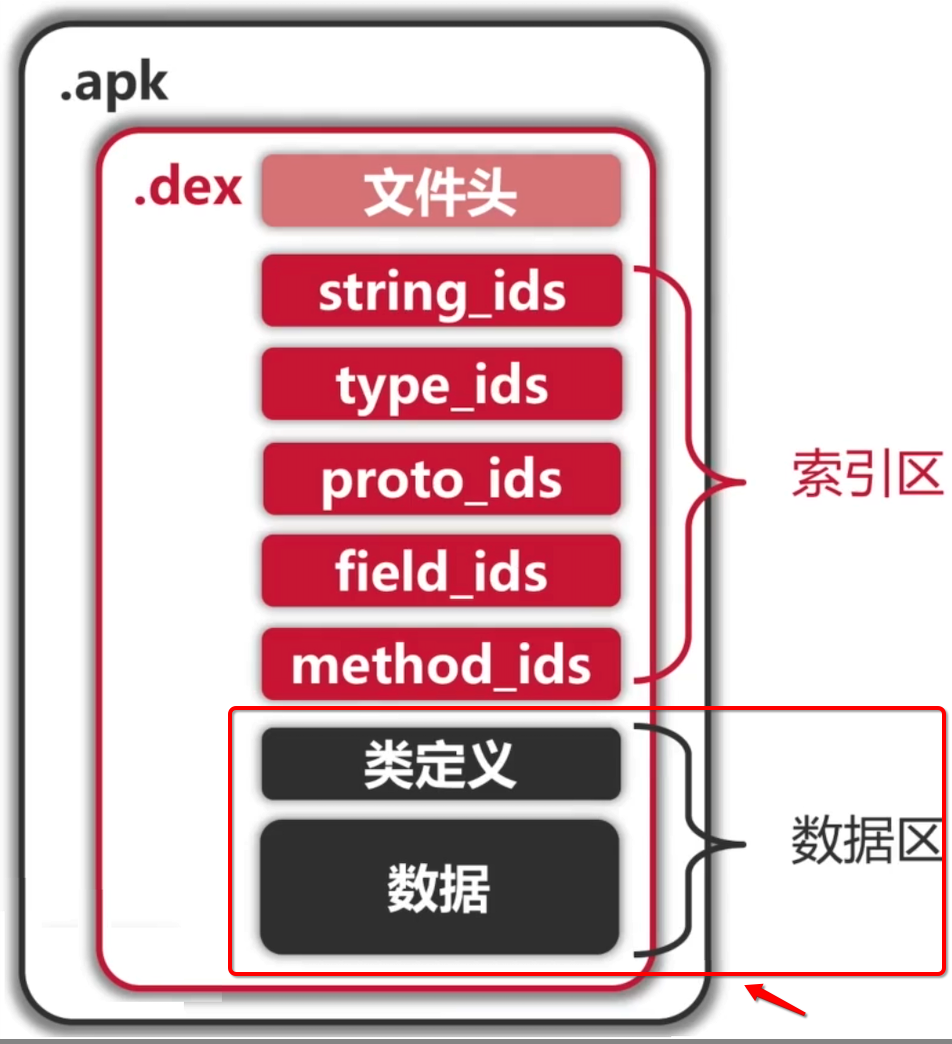
也就是一个类对应一个class,而了解Android的小伙伴也都知道其dex是包含在apk当中的,而dex的结构如下:
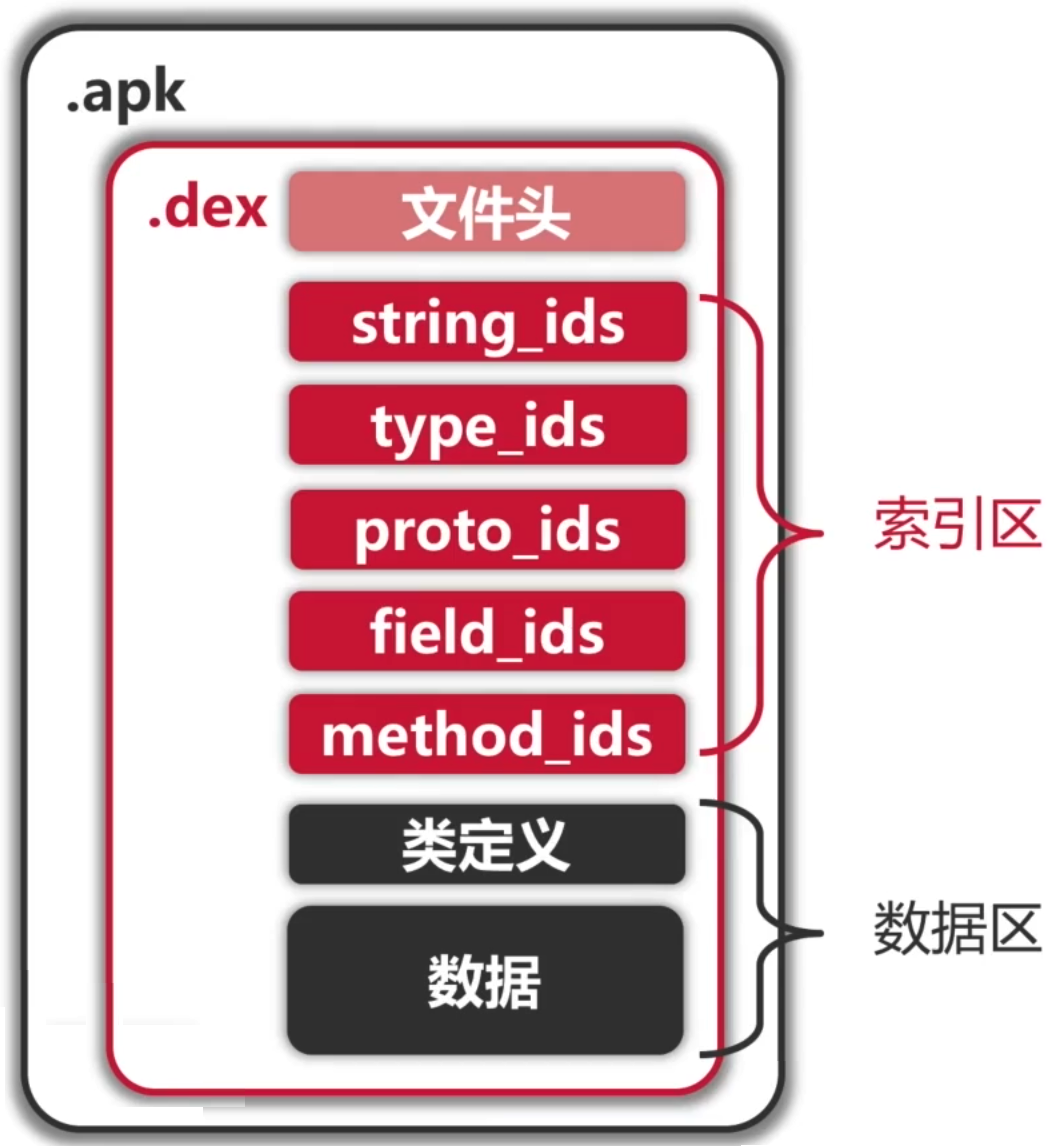
很明显这里并不是一个类对应一个dex,而是一个aar或者apk对应一个dex【注意前提:不考虑multidex的情况】,而且从这张图我们也可以看到一个dex粗略地分是三部分:文件头、索引区、数据区,下面则分别来了解一下。
文件头:
Dex的结构定义在Android源码的这块:dalvik/libdex/DexFile.h
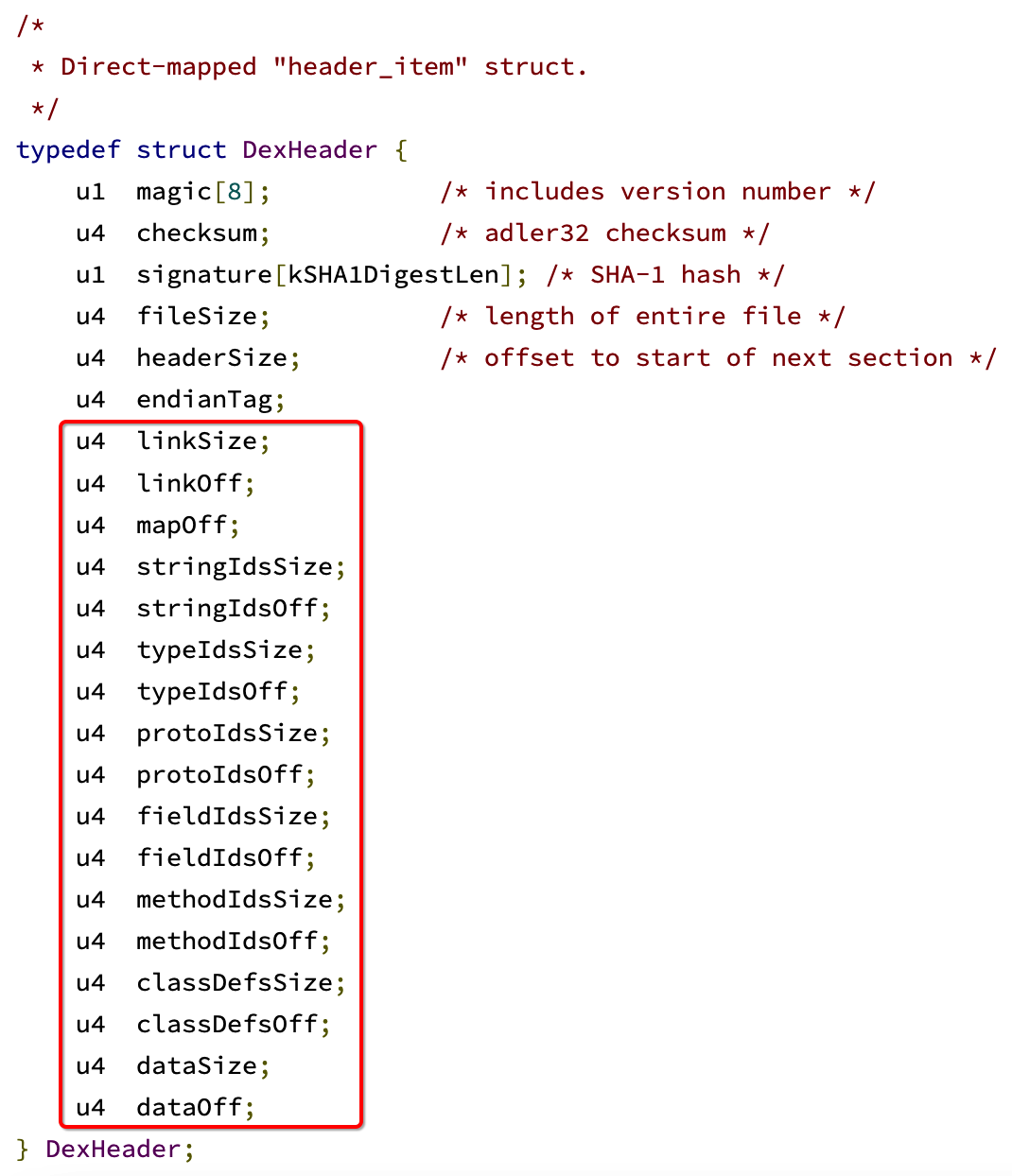
而对应的文件头结构体的定义如下:
/* * Direct-mapped "header_item" struct. */ typedef struct DexHeader { u1 magic[8]; /* 魔数和版本号 */ u4 checksum; /* adler32 算法校验码 */ u1 signature[kSHA1DigestLen]; /* 文件内容签名 */ u4 fileSize; /* 文件总大小 */ u4 headerSize; /* 文件头大小 */ u4 endianTag; /* 字节序【大小端】 */ u4 linkSize; u4 linkOff; u4 mapOff; u4 stringIdsSize; u4 stringIdsOff; u4 typeIdsSize; u4 typeIdsOff; u4 protoIdsSize; u4 protoIdsOff; u4 fieldIdsSize; u4 fieldIdsOff; u4 methodIdsSize; u4 methodIdsOff; u4 classDefsSize; u4 classDefsOff; u4 dataSize; u4 dataOff; } DexHeader;
其中可以看到,在关键信息之后,有大量的xxxSize和xxxOff对吧:
是不是刚好可以用这些信息定义到dex中的这些区域的位置?
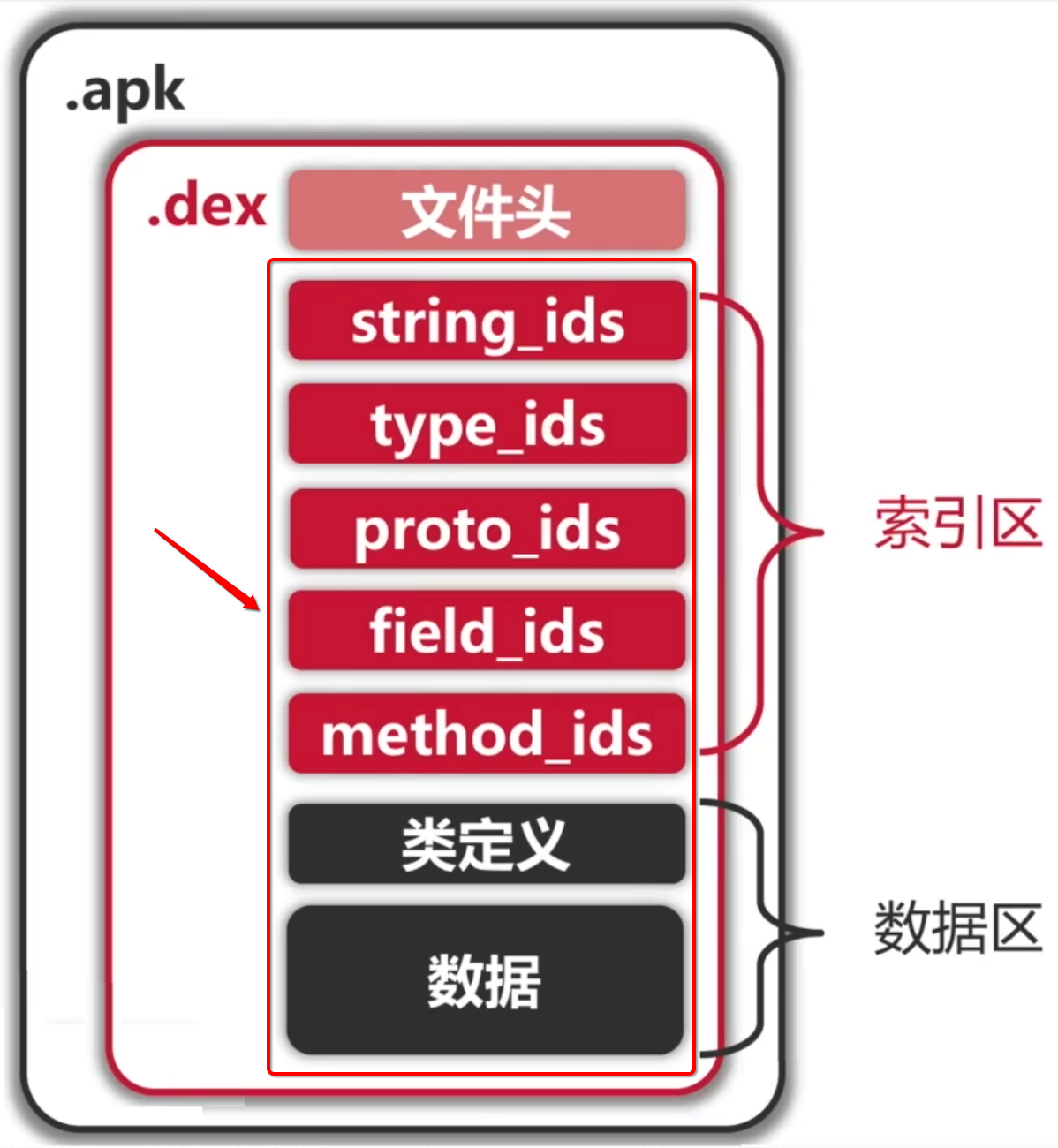
也就是有了这个文件头,我们就可以对dex文件对它进行上图中所述逻辑结构进行一个切割了。
索引区:
接下来则来了解一下索引区,也就是:
string_id_item:
它的结构体定义为:

它指的是某一个字符串在数据区的偏移量,还记得数据区么,也就是它:
type_id_item:
它的结构体定义为:

它指定的是上面DexStringId中的索引。
field_id_item:
它的结构体定义为:

proto_Id_item:
它的结构体定义为:

对于proto原型这里可能比较难理解一点,从这结构可以看出,它有参数、有返回值,但是它木有名字,其实表示一个可被调用的结构,它有啥好处呢?比如:咱们代码中出现了多个参数相同,返回值相同,但是名字不同或者所在类不同,此时我们就可以共用同一个原型了。
method_id_item:
它的结构体定义为:

其中第二个属性则就是引用上面所述的原型。
索引区&数据区:
经过对于索引区的了解,我们可以发现,其实有这么一个关系:
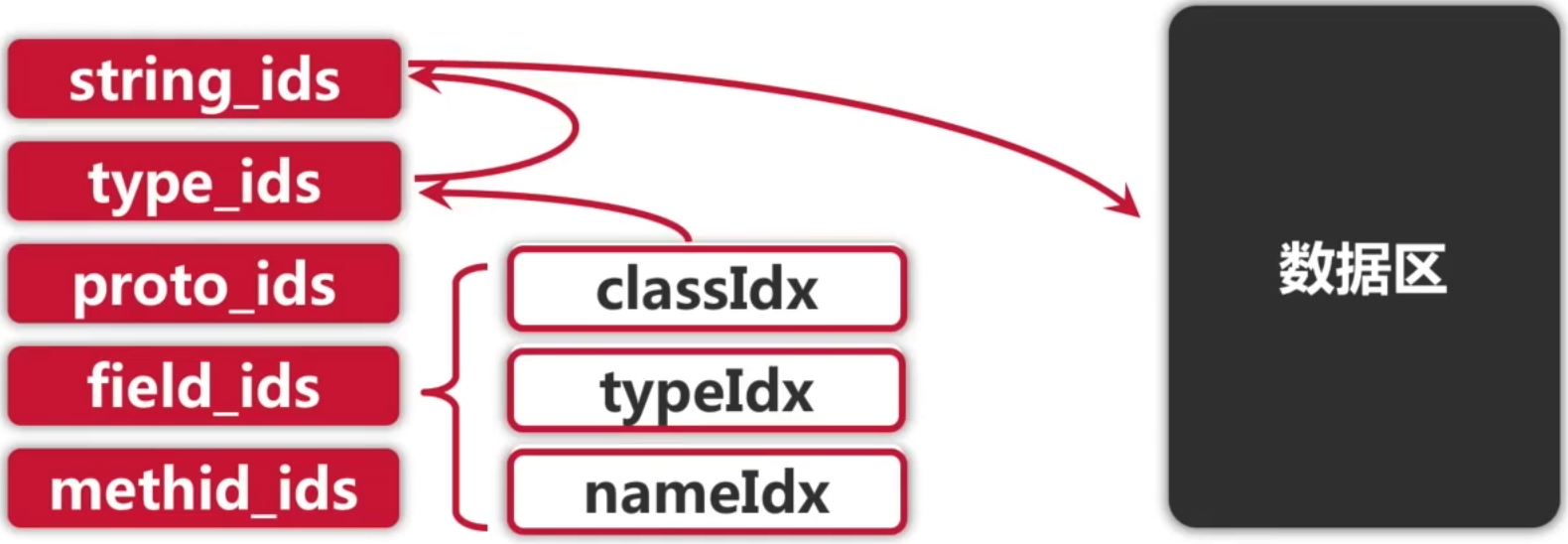
索引可以指向别的索引,也可以指向数据区,而数据区是真正要存放索引字面量地方,而索引区+数据区就起到了一个类似于Class中常量池的作用,也作为整个文件的资源库。
class文件 vs dex文件:
接下来则来对比一下class文件和dex文件的区别:
1、节约移动端安装包体积:
class文件:每个类都有独立的常量池,导致代码冗余。
dex文件:常量记录在数据区,所有类都可以通过索引获取常量的值,相同的常量可以合并,大大降低了代码的冗余。【这一点就可以节约移动端安装包的体积】
2、降低I/O操作开销:
class文件:每个类属于一个class文件。
dex文件:所有类在同一个文件中,即使是multidex,文件总数也远小于class文件。
3、节约内存:
class文件:基于栈的字节码。
dex文件:基于虚拟寄存器的字节码。
关于这个结论如果不太清楚的可以参阅https://www.cnblogs.com/webor2006/p/16574474.html,有详细说明。
解答总结:
问:为什么dex文件比class文件更适合移动端?
答:说到移动端,相比服务端而言,它的内存是有限的,而且安装包体积不宜太大,频繁I/O操作会带来卡顿,而对于dex相比class刚好它的优势就这三点【接下来则说出证据,也就是class文件和dex文件对比区别的那一段】:
1、节约移动端安装包体积:
class文件:每个类都有独立的常量池,导致代码冗余。
dex文件:常量记录在数据区,所有类都可以通过索引获取常量的值,相同的常量可以合并,大大降低了代码的冗余。【这一点就可以节约移动端安装包的体积】
2、降低I/O操作开销:
class文件:每个类属于一个class文件。
dex文件:所有类在同一个文件中,即使是multidex,文件总数也远小于class文件。
3、节约内存:
class文件:基于栈的字节码。
dex文件:基于虚拟寄存器的字节码。
解题套路回顾:
对于这一题,其实解题套路就是:
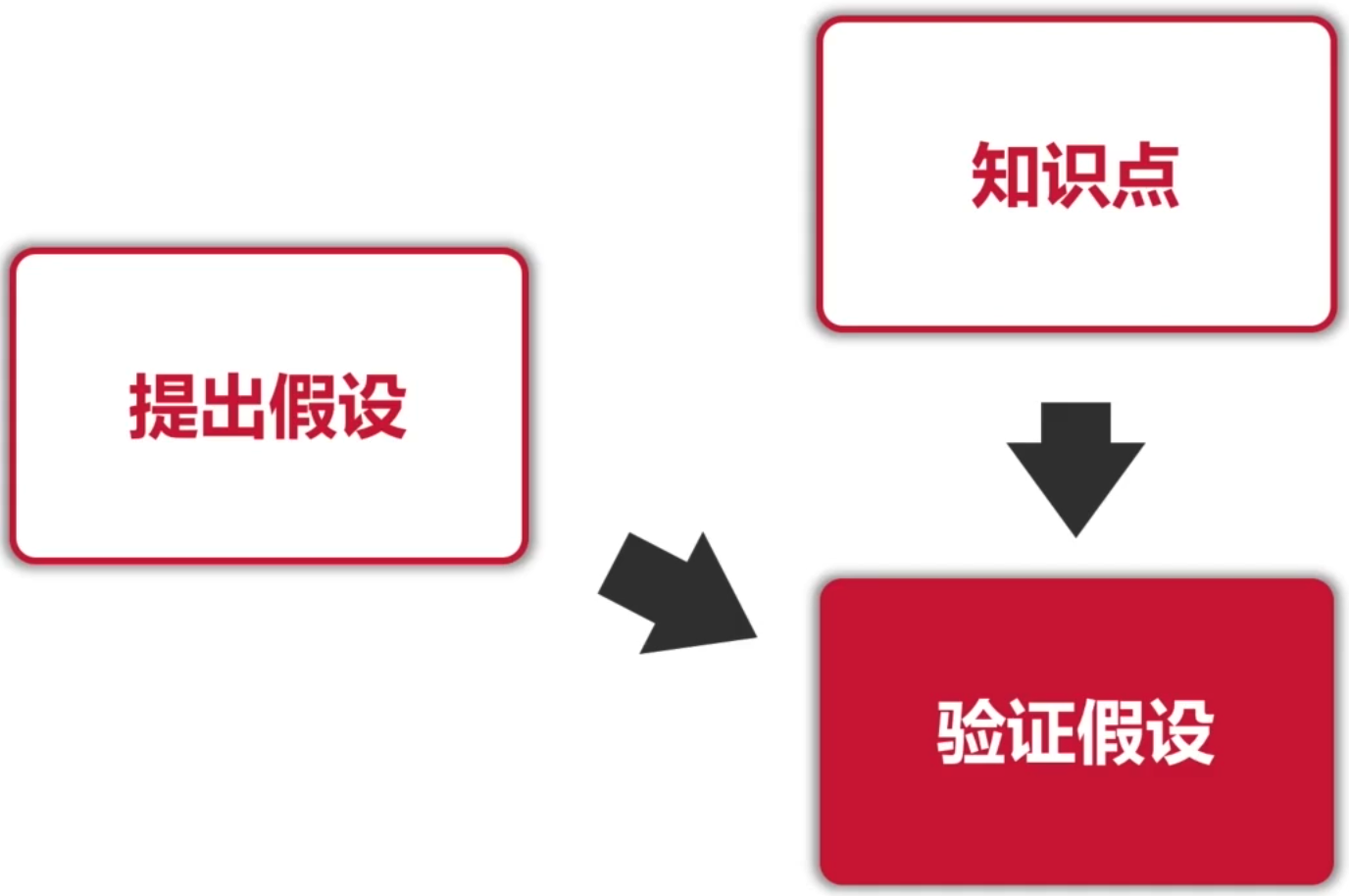
1、先提出假设,也就是:
2、然后用自己预备的知识来验证这么一个假设,当然这块就需要你平时去下功夫了,像对于这道题要想真的答得有理有据,这篇博客的篇幅就可以看出,还是不简单的,如果没有足够的知识储备,只背出结论,这样的回答会显示非常空洞,同时也经不起面试官的推敲。

