

01-Android平台的虚拟机是基于栈的吗?
前言:
这里打算开一个新的专栏,就是关于Android面试相关的一些知识点的学习,其实前几年已经有相关专栏了:
![]()
只是未对外开放,我记得当时本来是开放着的,但是因为当时去某厂去面试【很遗憾,至今未能进大厂】时被一面试官给了个建议,说博客上别把面试准备相关的东东放上面,这样会让人看了你的博客之后对你的印象大打折扣的【言外之意就是太low,没有含金量】,听了之后回来我就把这个专栏给隐藏了,可能当时觉得对方讲得有点道理,但是!!!如今的想法已经完全不一样了,走自己的路让别人去说,写博客对于我来说就是让自己摒弃浮躁,让学习有输出的一个比较好的方式,不管是输出的啥,对我有用就成,毕竟成人的世界都是自己对自己负责。那既然已经有这个专栏了,干嘛还要再加一个全新的呢?现在是2022年了,距离当时建立的这个专栏已经过去N年了,所以想基于一个全新的视角来建立Android面试相关的知识体系,另外还是那句话,对于吃饭的技术,没有任何理由不对它进行精进专研,别光顾着横向其它领域的扩展,毕竟它是生存之根本。
大纲:
这次要梳理的知识点的大纲如下:

内存类相关:
- Android平台的虚拟机是基于栈的吗?
- 为什么dex文件比class文件更适合移动端?
- 你能不能自己写一个叫做java.lang.Object的类?
- 所有被new出来的实例,都是放在堆中的吗?
- GC为什么会导致应用程序卡顿?
- Android平台虚拟机中的CG又是怎样的?
- 双重检测的单例,为什么还要加volatile关键字?

关于Java和Kotlin语言相关:
- String的intern方法,使用场景是什么?
- String的hashCode为什么乘数是31
- HashMap的容量为什么一定是2的n次幂?
- Java的数组为什么不支持泛型?
- 如何在运行时获得泛型类型?
- 匿名内部类使用的外部变量,为什么一定要加final?
- Java语言中有闭包吗?
- 都是编译成字节码,为什么Kotlin能支持Java中没有的特性?
- Kotlin如何通过中间代码添加来实现新特性?
- Kotlin如何通过元注解和Metadata来实现新特性?
- 如何理解面向对象的编程原则?
- 你遇到过哪些经典的设计模式使用案例?
- 如何理解Kotlin中的函数式编程特性?
- 函数式编程中也有设计模式吗?
从Androd平台本身出发,去剖析、容错与优化相关:
- 你做过哪些内存治理相关的工作?
- Android中,如何进行堆内存治理
- Android中,如何进行线程和FD治理?
- 如何实现一个能加载海量数据的列表?
- 当我们点击应用图标时,系统都做了什么?
- AMS,是如何帮助App启动Activity的?
- 启动Activity之前,是如何为它分配任务栈的?
- Activity是如何显示在屏幕上的?
- Android中的屏幕刷新机制是怎样的?
- 在SQLite中,without rowid的使用场景是什么?
- Parcelable为什么速度优于 Serializable ?
关于架构方面的相关:
- 为什么一定要有分层架构?
- MVP为什么比MVC更适合Android开发?
- MVVM就是MVP再加上DataBinding吗?
- Jetpack给架构模式带来了怎样的改变?
- Compose给MVVM带来了怎样的改变?
- Room给MVVM带来了怎样的改变?
- 你做过组件化吗?是如何实现的呢?
gradle相关:
- Android工程的构建过程是怎样的?
- Gradle在构建阶段都做了什么?
- Gradle中的Task是什么?
- AndroidGradlePlugin的工作原理
- 如何用工程手段,提高写代码的生产力?
- 如何用字节码手段,实现热修复?
以上,你能详细地回答几个出来呢?反正此时此刻,我很多是答不上来的,虽说在Android上已经深耕多年了,因为实际工作中你不会专门总结这些问题,所以在平常就得花时间来慢慢总结梳理,当然可能还有其它一些Android面试的痛点,但是!!!目前的目标就是把上述的这些大纲给梳理完,这个已经不容易了,如果真的每个问题都搞得很透彻的话,相信自己如果在面试上的自信感绝对是倍增的,所以,唯一希望的就是自己能坚持,别放弃。
JVM知识体系梳理:
概述:
首先开篇就是JVM的东东,是不是处处都体现着“卷”~~关于这块的基础知识其实我在前几年已经花了很大的篇幅在上面了,需要补基础的可以参考下:
![]()
当然细节已经忘得差不多了,好在有烂笔头记录着,所以不怕遗忘,其实当时学习的视角是以java语言本身而言,而非Android的角度,所以这里有必要对它的知识体系再简单梳理梳理,同时也是一个温故知新的一个非常好的机会。
为什么要学习JVM?
可能有些人会说:为了装逼~~在早些年你如果会点JVM确实是可以达到这种效果,但是!!!如今已经是处在卷王的时代,所以面试时被问到它的相关知识点还是非常之大的,而且学习它确实是有实际意义的,下面列几点:
1、JVM学习了能够让你对Java语言本身了解得更加深入,比如常量池、异常、类加载流程、静态代码块、构造方法、方法重载、垃圾回收等,是不是基本都是我们学习Java语言本身都会面临的知识点?
2、是否能够定位内存泄漏、异常编程等方面的问题?内存泄漏主要是指JVM的垃圾回收机制的了解,异常编程相关的就是锁相关的。
3、对JVM进行调优,这块对于移动端来说基本上用不到,可能对于Java后端的是有意义,但是!!!了解相关的调优手段,对于眼界的扩展有益无害。
学习JVM时容易遇到的问题?
其实学习过JVM的人,应该都有如下问题:
1、概念性知识点偏多,涉及到实际操作较少,没有记忆点,基本上是学过就忘,所以烂笔头可以解决遗忘的问题,就像我之前所学;
2、知识点过于多,以至于很容易胡子眉毛一把抓,本身JVM就是一个非常庞大的体系,你看我当时学习那块记录了94篇博客,如果哪天你要复习这块的知识,是不是都得花不少时间来回忆?
3、靠背概念准备面试,经不住面试官的深入追问,我想这是一大痛点。
那。。很明显这次是想要解决这些痛点,则需要换一个角度来总结JVM相关的知识体系,而且采用面试真题的方式,将JVM的理解藏在这些真题的背后,这样也不会这么枯燥,其实在上面的大纲中就可以看出:

这很明显就变得有意思了,因为把这些面试题剖析完之后,其实间接的就把你的JVM的知识体系给考验了一把,这其实也更加真实,对于Android面试,往往不一定直接很生硬的问你JVM中的哪个知识点的,所以这次的学习就是专门解决面试痛点的。
JVM概述:
接一下来则开始对JVM的知识体系进行一个重新的梳理,当然,先来对JVM有一个简单的了解:
Java虚拟机,它其实是一种规范,是个抽象的概念,也就是:
1、它并不是一个真正的“机器”,而是由软件实现的;
2、可以有多种不同的实现方式:
- HotSpot VM(Sun JDK、Open JDK)
- JRockit (BEA公司,已被整合进HotSpot),据说是最快的JVM
- J9 VM(IBM公司)
- Dalvik VM、ART(Google公司,不是严格意义上的JVM),也就是Android上所使用的,重点需要探讨的。
JVM的职责:
看一张图就明白了:
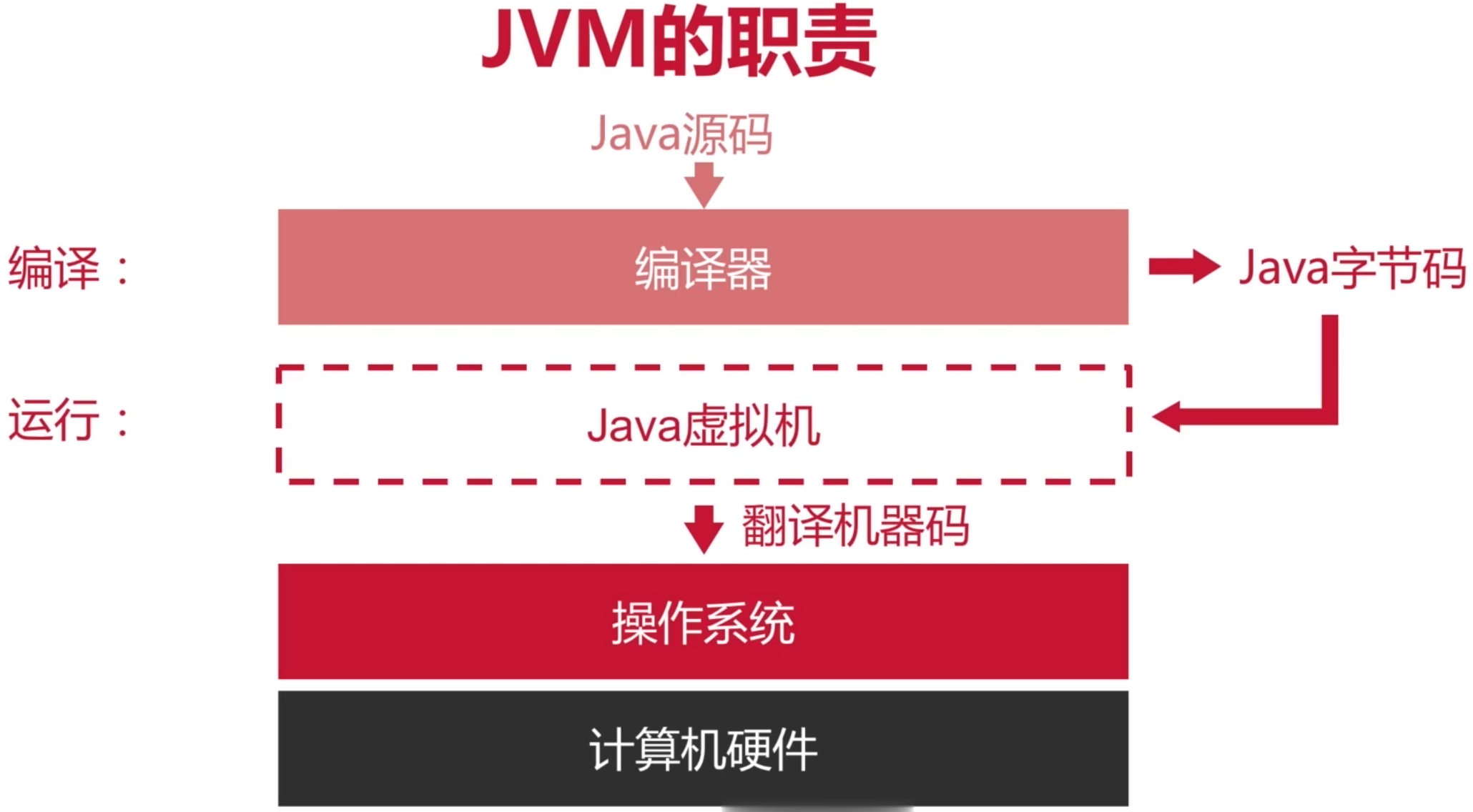
用一句话来总结它的职责就是:在硬件上运行JVM语言(可以编译成Java字节码的语言,如Java、Groovy、Kotlin[虽说它可以不在JVM中运行,但是在Android平台还是会被编译成字节码交由Android的虚拟机来运行的])
而要想运行字节码,其实是需要有以下几个点:
1、执行字节码指令;
2、加载字节码中的Class结构;
3、分配和回收代码运行时的内存。
而这三点,其实就是咱们要来梳理的JVM知识体系,下面就来阐述它。
JVM的知识体系:
这里就是根据上面的三点来进行阐述了。
1、执行字节码指令;【JVM与字节码】
a、执行引擎:
- 解释执行
- 指令集
b、运行时栈帧:
- 局部变量表
- 操作数栈
- 动态链接
- 返回地址
c、异步:
- 这里就涉及到JMM(Java Memory Model)相关的知识点:8大原子操作、一致性协议
- Java常见锁
2、加载字节码中的Class结构;【JVM与类】
a、class文件:
- 编译过程
- 文件结构
- 修改(字节码编程:ASM/Javassist)
b、类:
- 加载(方法区、java.lang.Class)
- 生命周期(加载、验证、准备、解析、初始化、使用、卸载)
c、ClassLoader:
- 双亲委派模型(Java中、Android中)
- 沙箱安全
3、分配和回收代码运行时的内存。【JVM与实例】
a、运行时数据区:
- 线程私有:虚拟机栈、本地方法栈、程序计数器
- 线程共有:java堆、方法区
b、堆垃圾回收:
- 策略:分代回收(年轻代、老年代)、分区回收
- 检测算法:引用计数、可达性分析:GC Roots
- 回收算法:标记清除、标记复制、标记整理
c、堆调优:
- 回收器:CMS、G1、Serial、Parallel Scavegen
4、Dalvik & ART:【Android平台】
ART(Android RunTime)的职责:
这个是咱们关注的重点,跟JVM的职责其实差不多:

而这块对应的JVM的知识体系有:
a、Dex文件:
- Dex文件结构
- Dex字节码
b、虚拟寄存器:
- 基于栈 vs 基于寄存器
c、Java堆:
- 结构:Zygote堆、Activie堆、Card Table、Heap Bitmap、...
- 回收算法:标记清除、部分标记清除、粘性标记清除
d、JIT & AOT:
- Just In Time(既时编译)
- Ahead Of Time(提前编译)
总结:
最后用一张图来对上面的体系做一个总结:
Android平台的虚拟机是基于栈的吗?
对于这个题,也基本能猜出来答案---不是!!!那如果面试这么回答,基本上是要挂的节奏,其实也就是给自己挖坑,因为此时面试官很显然会再问下“为什么?”,与其让面试官来问,如果自己比较擅长的题主动说全一些,这样时间拉长了之后,反而让面试官问你不擅长的东东的时间变少了,化被动为主动,当然,前提是你比较擅长的话题,不过,对于江湖老司机,这块都懂的。其实要回到好这个问题,提前要了解的东东还是挺多的,下面开始。
题面分析:
先来对题面进行一个分析,看能挖掘出哪些信息?其实题面有两个关键字:
![]()
而从这俩关键字可以引出很多的信息:
1、Android平台的虚拟机有两种:Dalvik 和 ART,所以你有必要了解一下。
2、基于栈:它是基于栈的虚拟机?还是操作数栈?
3、而上面两种栈又涉及到一个东东:运行时栈帧。
4、栈上运行的是字节码,所以还需了解字节码指令集。
5、既然Android平台的虚拟机不是基于栈的,那它是基于寄存器的,那么就有必要了解基于寄存器 vs 基于栈。并且需要知道它们各自的好处是什么?
6、最后,咱们还可以聊一聊,Android平台,为什么要这样选择?
这么一梳理,是不是要回答好这个问题涉及到的前置基础还是相当多的,如果你不准备,那只有挂的可能。
本题得分点:
对于这题的关键回答得分点主要是有如下两点:
1、知识储备:
- 从运行时数据区,到运行时栈帧,再到操作数栈,都是些什么,有什么作用。
- Android的指令集和JVM有什么区别。
2、技术思考:
- 我们对于基于栈和基于寄存器的看法。
也就是让面试观看到你对技术是有思考,有追求的,做到了知其然知其所以然,所以下面就按着这么一个思路来进行剖析。
JVM运行时数据区:
关于这块其实网上有相关的一些图,这里也先把整个运行时数据区的结构贴一下:

看图说话:
1、class文件通过ClassLoader被加载;
2、字节码执行引擎会在运行时执行字节码;
3、而运行时数据区其实就是指的字节码在运行时的时候在内存中的一个状态,其中它分为线程共享的和线程私有的区域:

堆:是存放实例类型的数据【也就是new出来的】,这块人人皆知,也是JVM垃圾回收主要是针对的这部分。
方法区: 存放的主要是从字节码中加载的类信息,关于这块更详细的可以参考我之前jvm的笔记https://www.cnblogs.com/webor2006/p/9876493.html:

非程序共享的区域:也就是每个线程独有的,有程序计数器、虚拟机栈、本地方法栈,关于这块的知识在之后会有说明。
栈:
在了解了运行时数据区结构之后,按照上面梳理的,接下来则需要了解它了:
其中出现了“栈”这个词,先来简单复习一下栈这个数据结构的特点:FILO(先进后出,First In Last Out),其入栈出栈过程如下面这个动图:

也就是像一个杯子一样,只有一个出口和入口,而这种结构可以跟如下两个应用联系起来:
1、方法的调用:后调用的方法最先结束,最早调用的方法最后结束;
2、Activity的任务栈:同一时间只能有一个Activity显示,如果其它Activity想要显示则需要上面的Activity先出栈,这里不考虑各种Activity的LaunchMode,简单的往这个栈的结构靠一下;
运行时栈帧:
概述:
好,在了解了栈的数据结构之后,就可以对运行时栈帧进行一下理解了,它涉及到两个概念:
虚拟机栈:而在JVM中,它是用来表达方法调用的栈。【上面对于栈的复习中也说到了最容易联想到的一个例子就是方法调用】
栈帧:栈中的元素,对应每一个方法的执行情况。
理解:
下面用一个形象的例子来理解一下,比如一段kotlin代码如下:

当程序被执行到main()方法时,则它就会入栈,所以:

然后再执行foo()方法,接着它又会入栈,此时它处于栈顶元素:
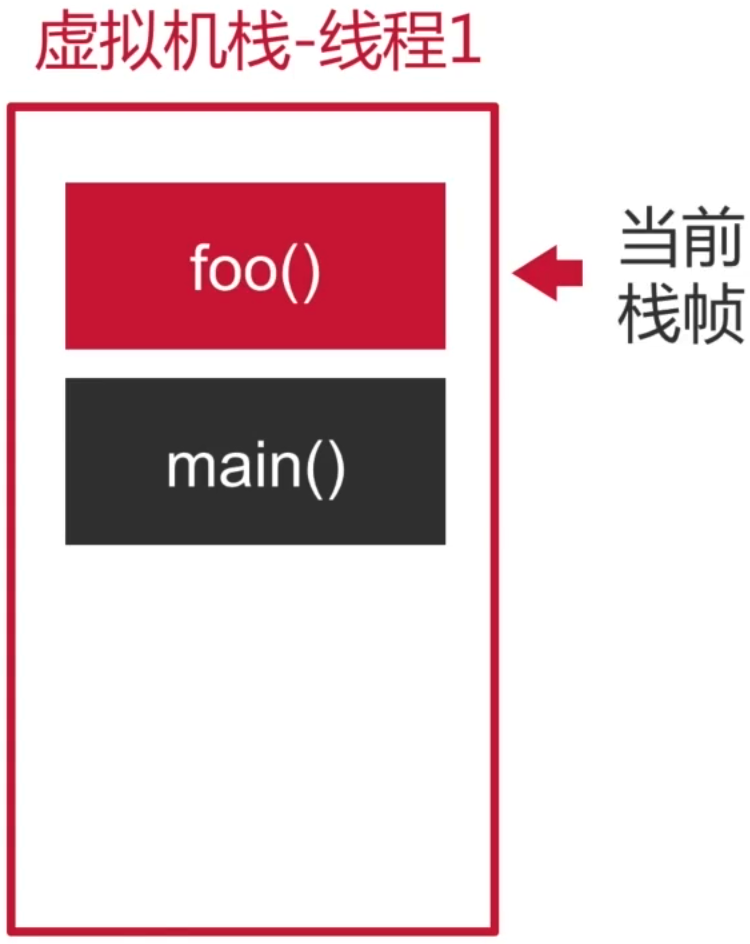
而当foo()方法执行完之后则会出栈,并且释放它所有的局部变量,这也是为啥虚拟机栈不需要垃圾回收而堆需要垃圾回收的原因。
关于这块其实都比较了解,这里要强调的是,这个虚拟机栈是线程独有的,再回忆一下图:
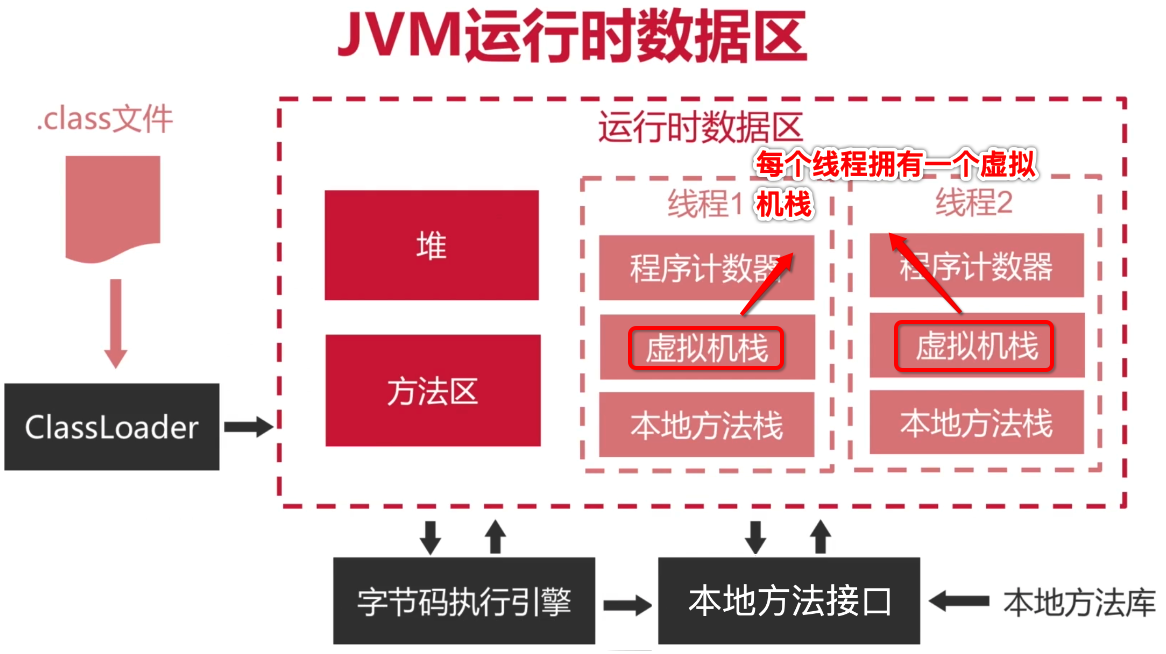
它是怎么来记录方法运行状态的?【比较麻烦,尽量要理解它】
在上面我们调用了foo()方法对吧,而假设它的代码如下:

接下来咱们来看一下运行时栈帧是如何来记录这个方法的状态的【用简单的方法来举例更容易理解】:
1、局部变量表:
首先栈帧里头会用一个局部变量表来记录方法中涉及到的三个局部变量,如下:
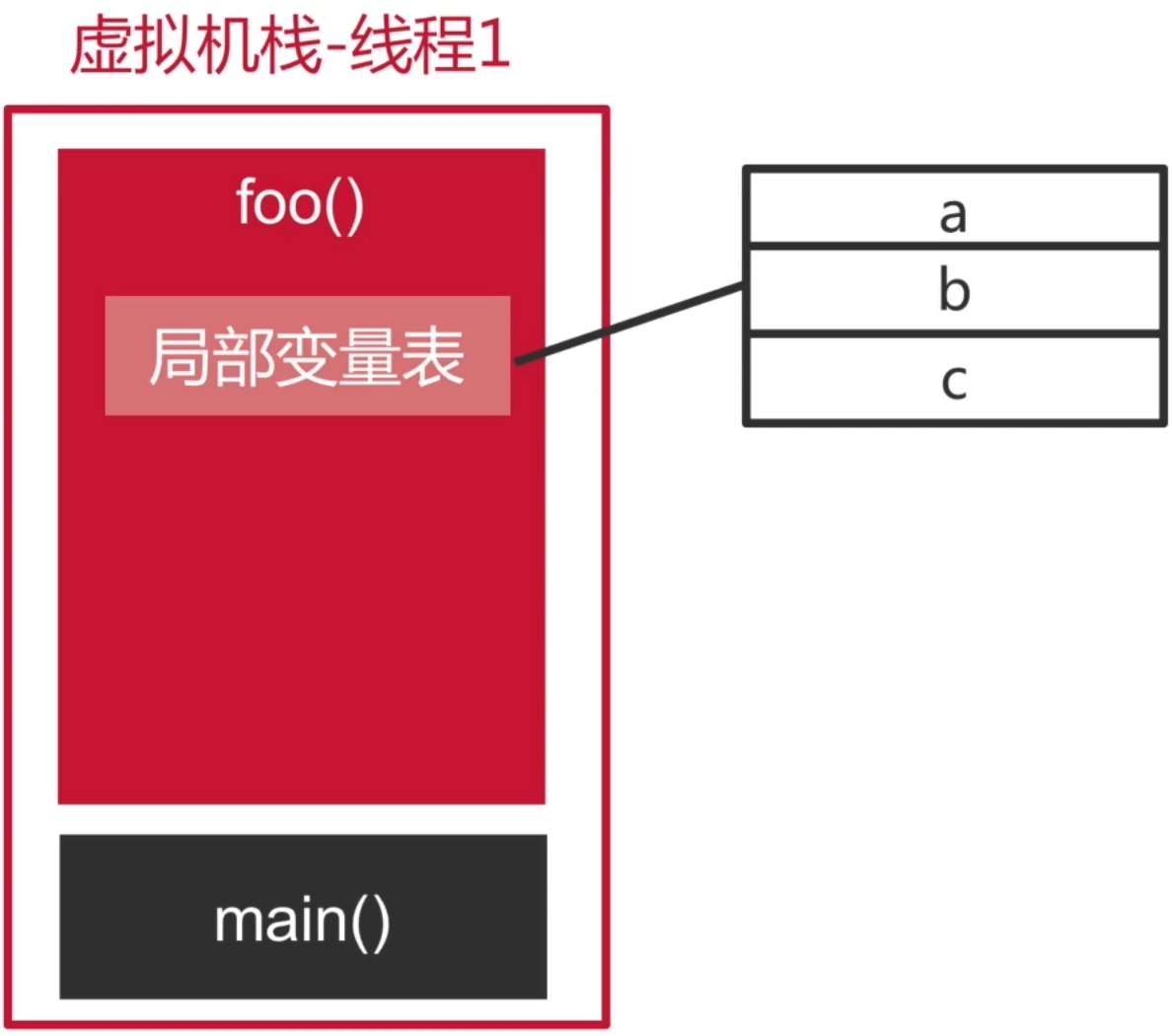
其实应该还有一个局部变量,就是隐藏的this,关于这个就没画在里面了,因为不影响例子的理解,你知道有个隐藏的this既可。
2、操作数栈:
它其实就是用于字节码执行时处理一些中间状态的一块内存区域,在这个例子中,操作数栈的容量是两个,如下:
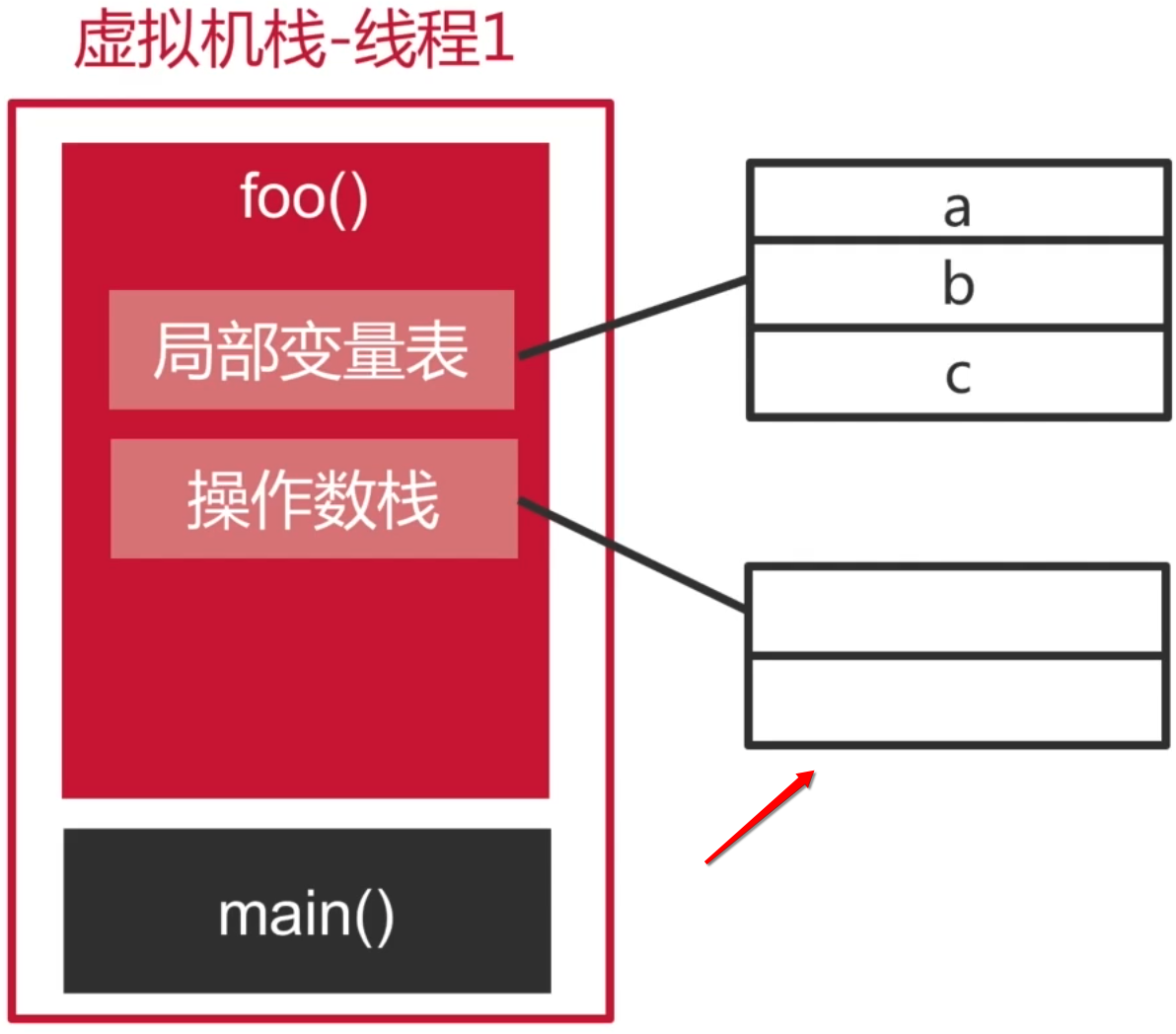
为啥容量是2个?这块之后随着流程的梳理就会明白的,反正它是编译期间根据方法代码的逻辑推算出来的,这块我们在之后再来验证一下是否只需要2个容量既可,
注意:对于这个面试题中的“基于栈实现”:
![]()
中的“栈”其实指的就是操作数栈,不是前面我们所说的“虚拟机栈”,这个一定要注意!!!
3、方法出口:
方法出口是指该方法应该返回给谁,以及返回什么:
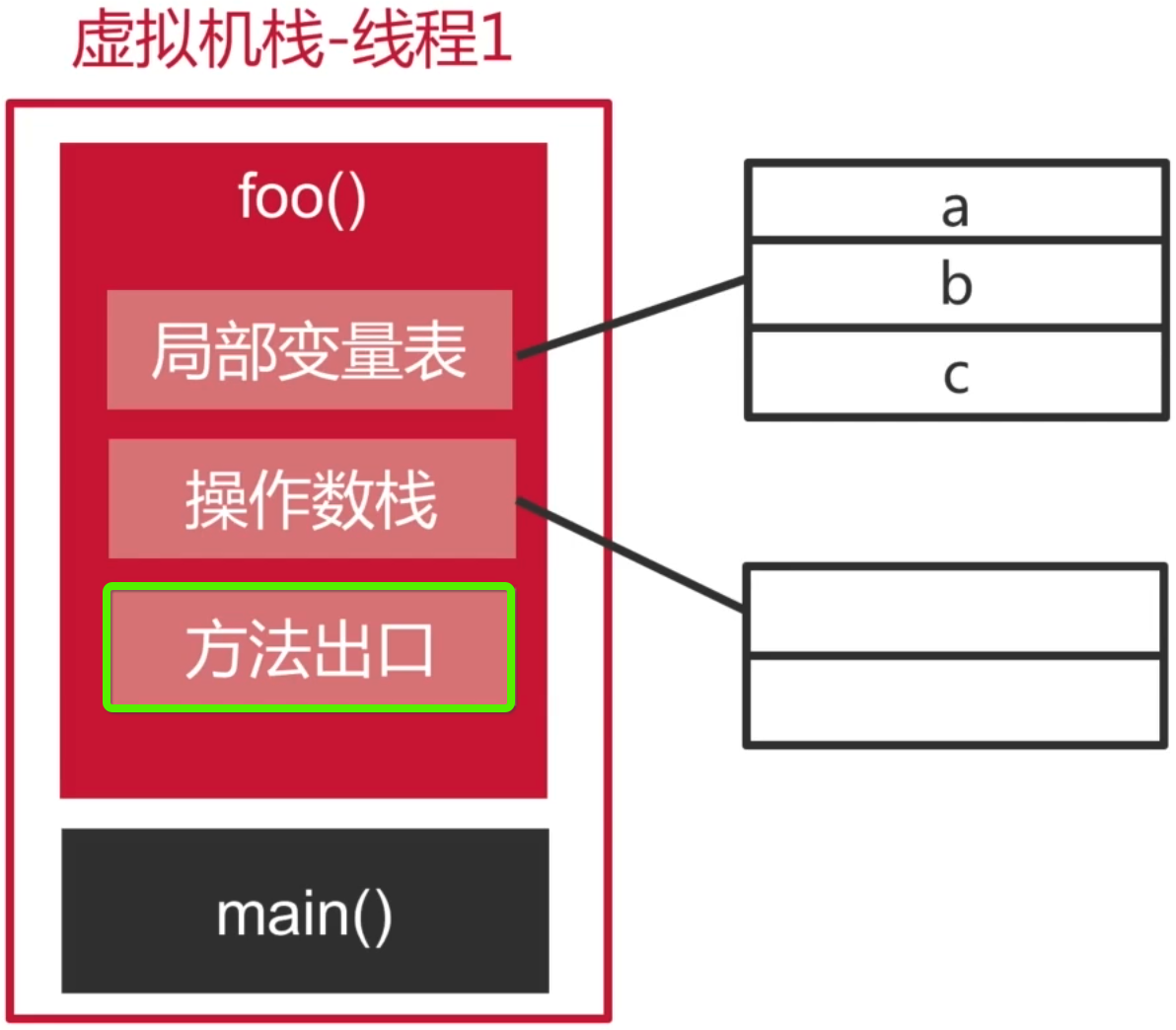
4、程序计数器:
它能帮助我们记录当前执行的字节码是哪一行:
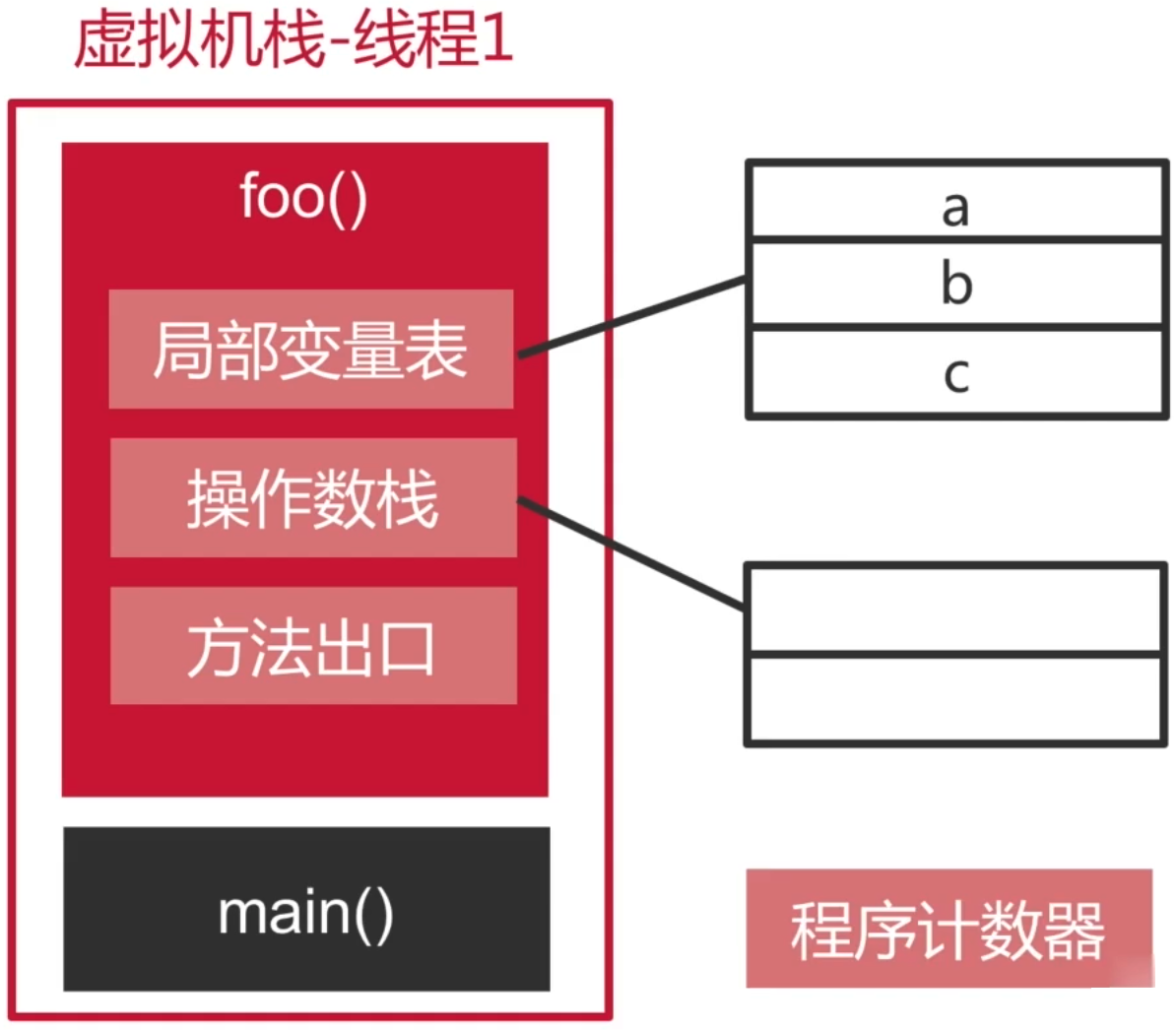
基于栈的虚拟机:
下面咱们就来看一下基于栈的虚拟机是如何执行字节码的。
1、将java代码转换成字节码:
既然JVM执行的是字节码,所以需要将java或kotlin代码转成字节码才行,如何转换呢?关于这块的基础可以参考https://www.cnblogs.com/webor2006/p/9404249.html,也就是用javap命令就可以,将上述的foo()方法转换成字节码如下:
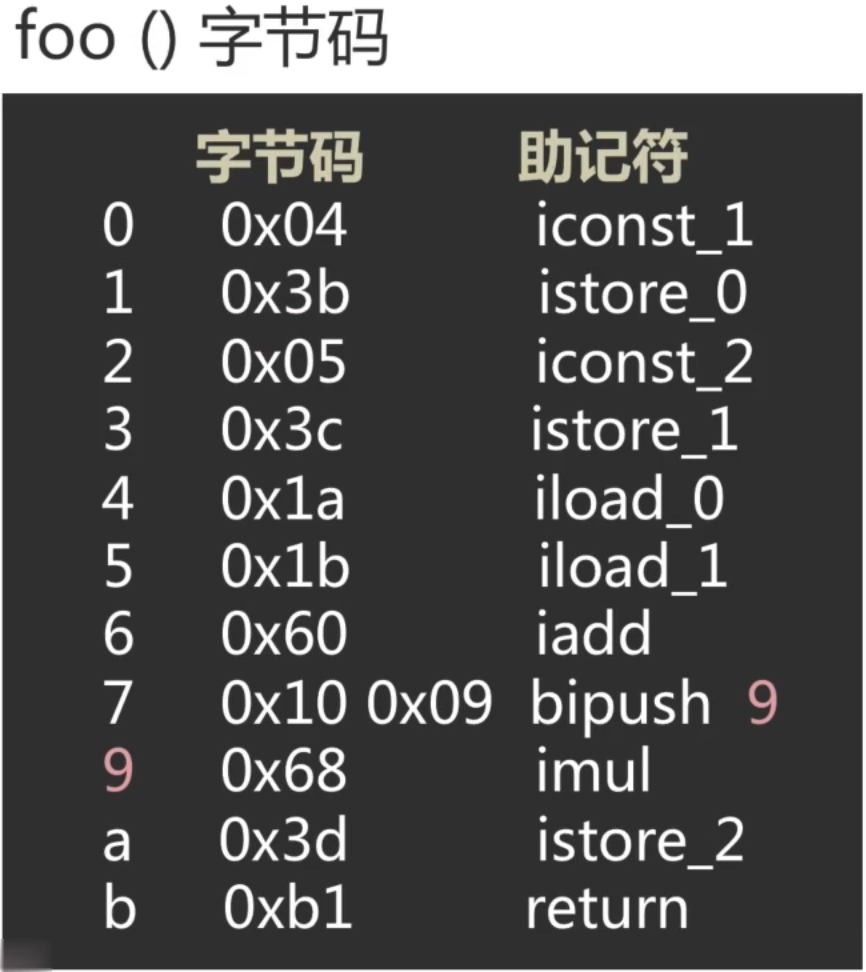
其中字节码列代表的是一个字节单元,有的指令是一个单元,也有些是两个单元,比如第7行就占用了两个字节单元;助记符列是帮助我们记录字节码含义的符号,关于这些细节在我的jvm系列博客中都有详细的说明,这里就不过多啰嗦了。
好,接下来一行行指令进行执行,然后通过图来理解下整个执行的流程。
2、将int型1推送至栈顶:
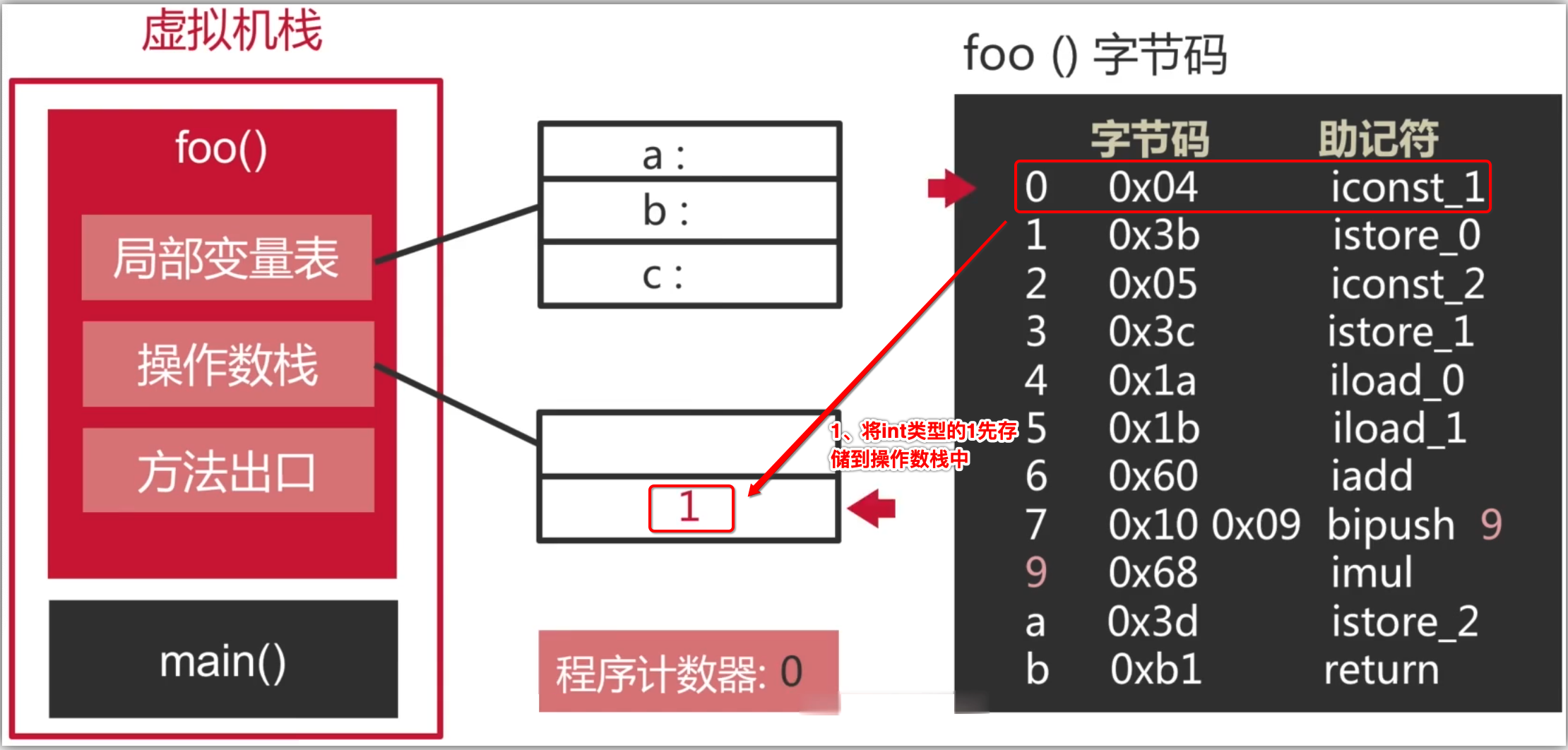
其中可以看到程序计数器指向的是第0行。
3、将栈顶的int型数值存入第一个本地变量:
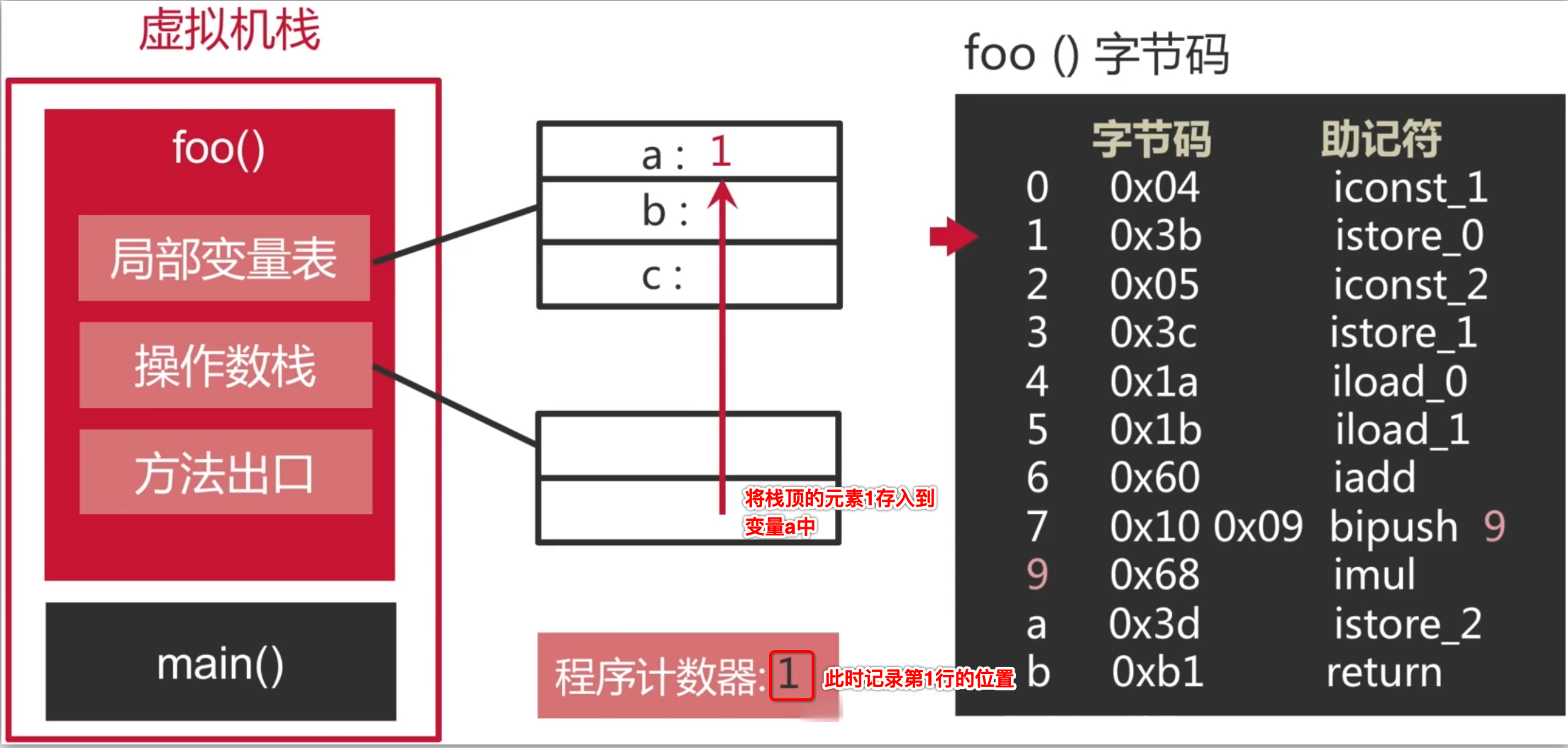
经过这两步,其实就是这句代码的含义:

4、将int类型2推送至栈顶:

5、将栈顶的int型数值存入第二个本地变量:
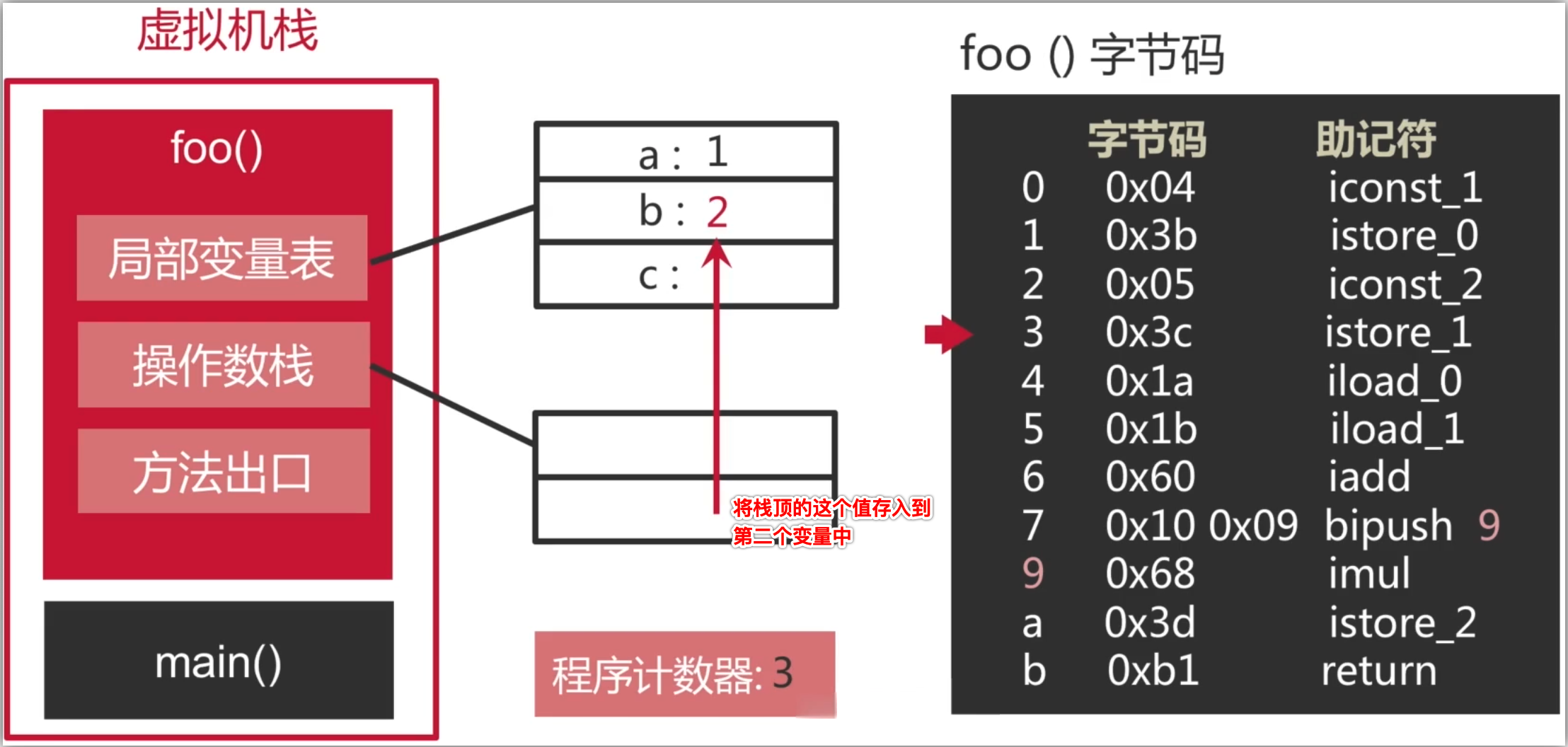
也就是执行了这句代码:

6、将第一个int型本地变量推送至操作数栈顶:
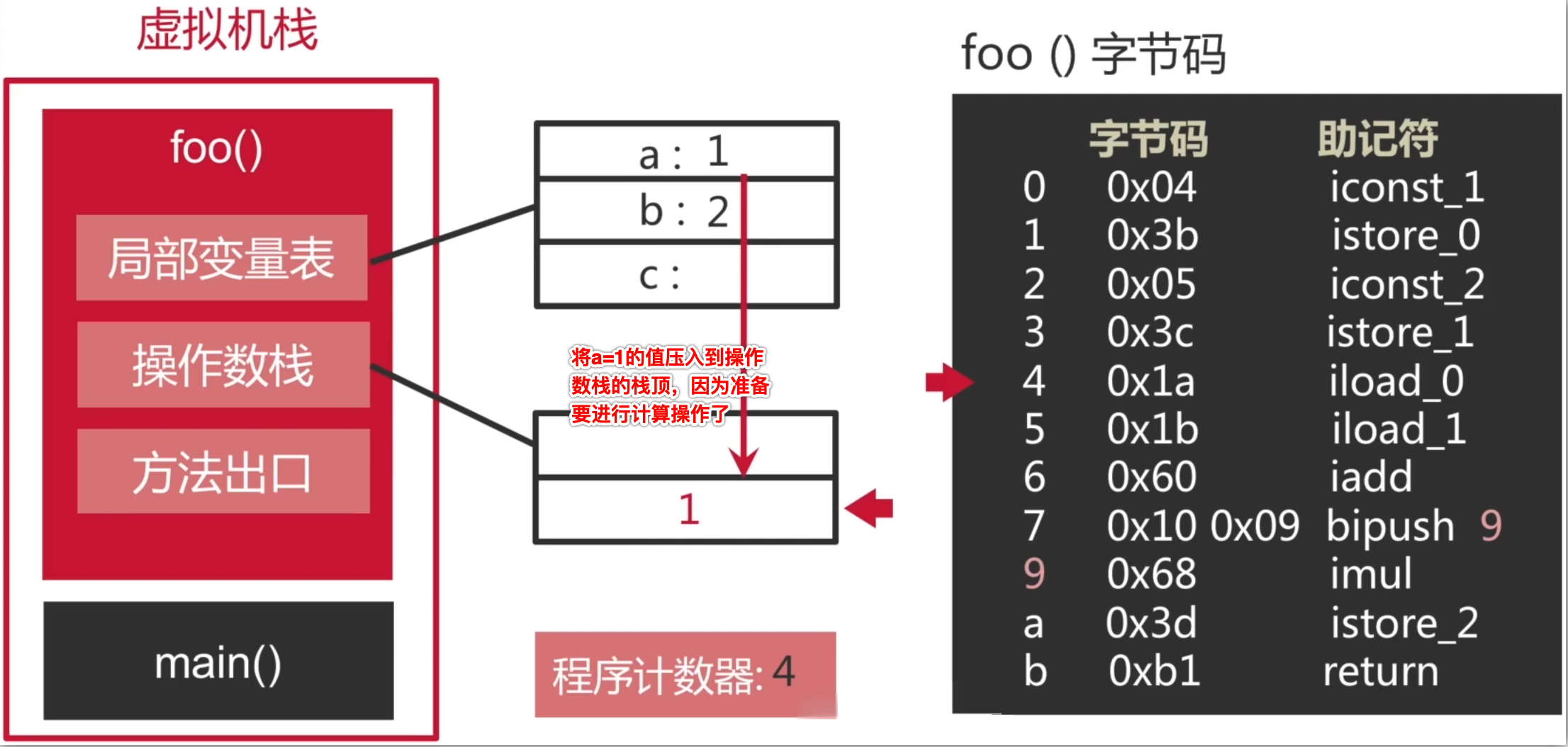
7、将第二个int型本地变量推送至操作数栈顶:
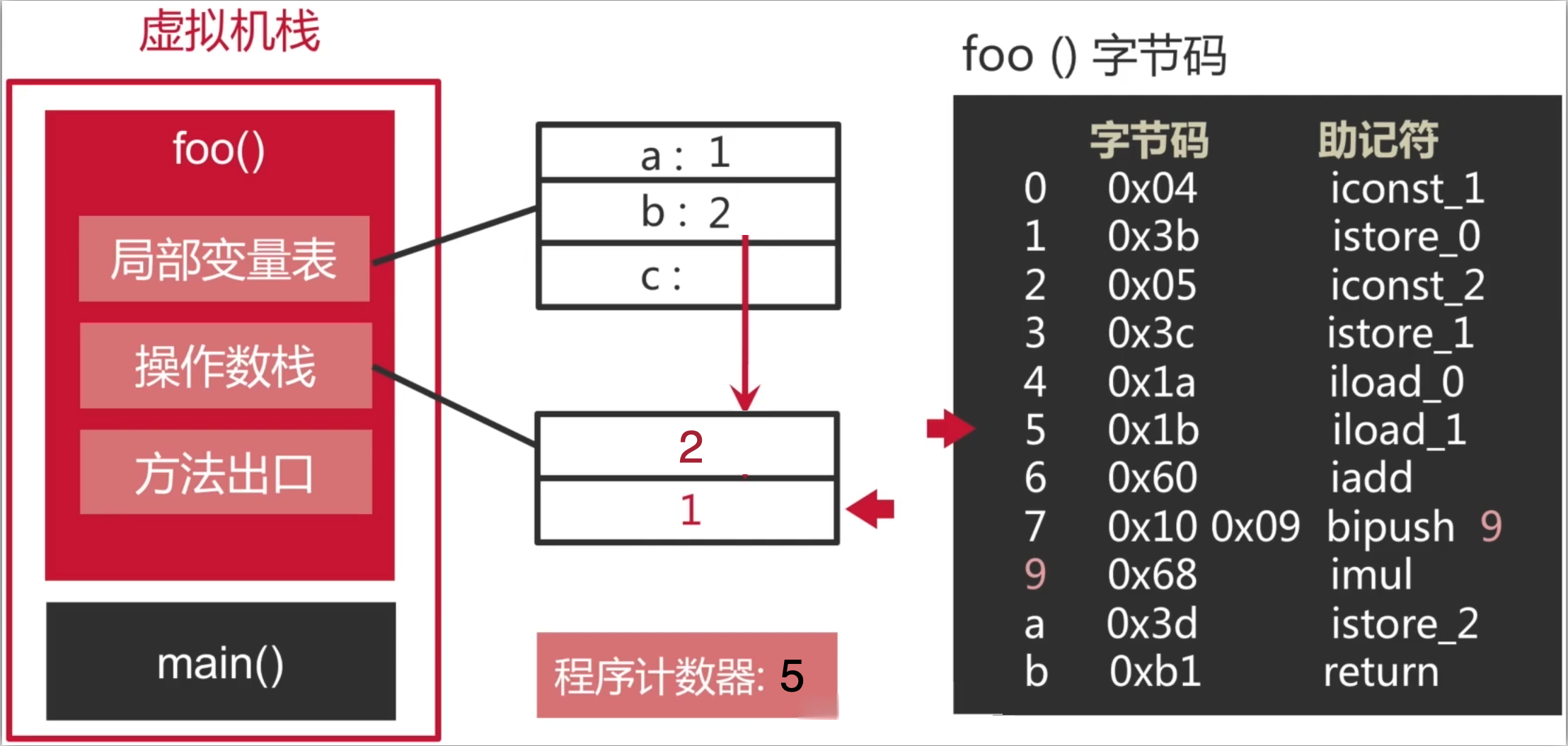
8、 将栈顶的两个int型数值相加并将结果压入栈顶:

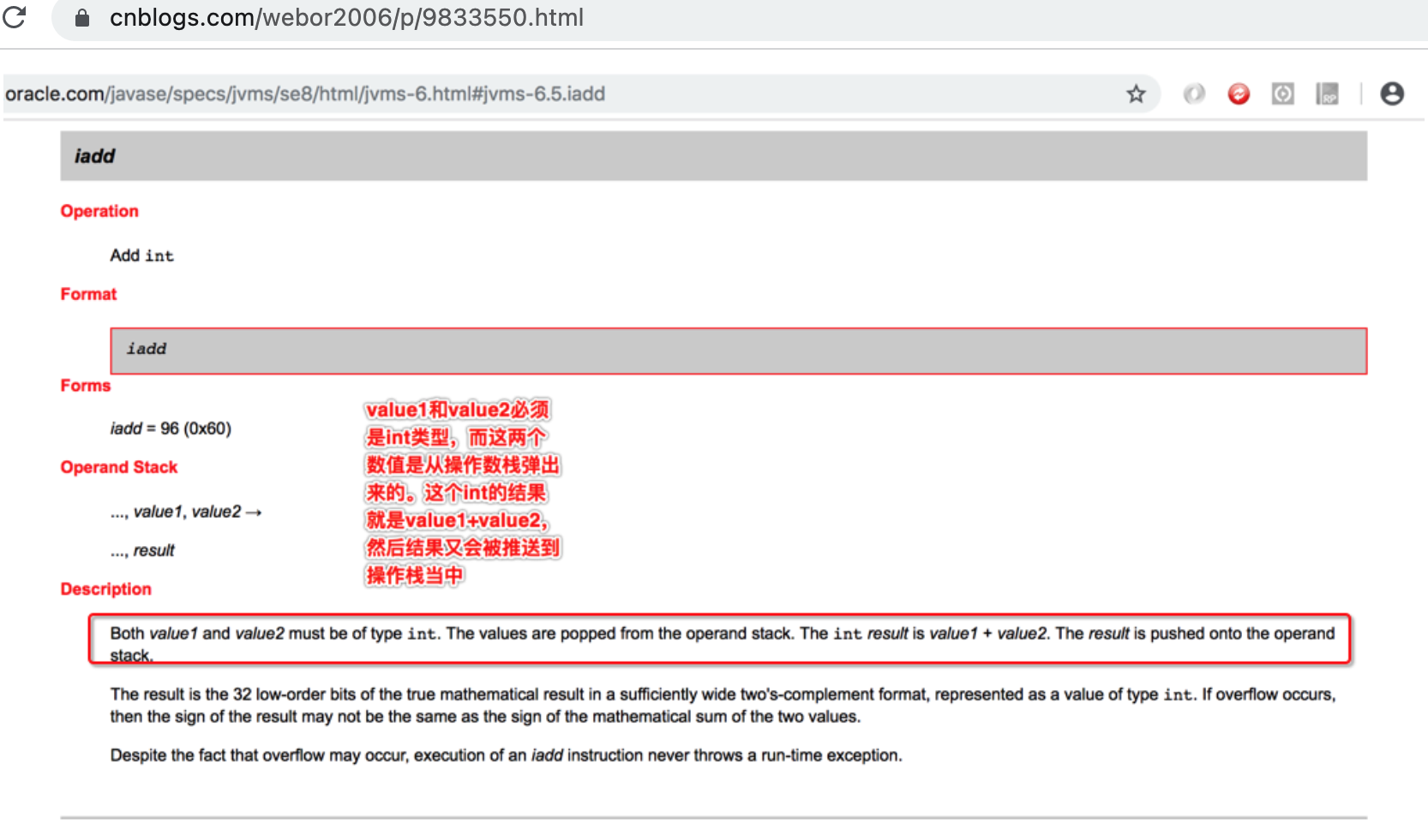
那。。你为啥就知道iadd助记符就是从操作数栈中先将两个数弹出,再把相加的结果又压入到操作数栈中呢?关于这块可以参考我之前的笔记https://www.cnblogs.com/webor2006/p/9833550.html,里面有详细的说明,这里贴一下:
9、将单字节的常量值(-128 ~ -127)推送到栈顶:

10、 将栈顶的两个int型数值相加并将结果压入栈顶:

看一下imul的官方解释:

11、将栈顶int型数值存入第三个本地变量:
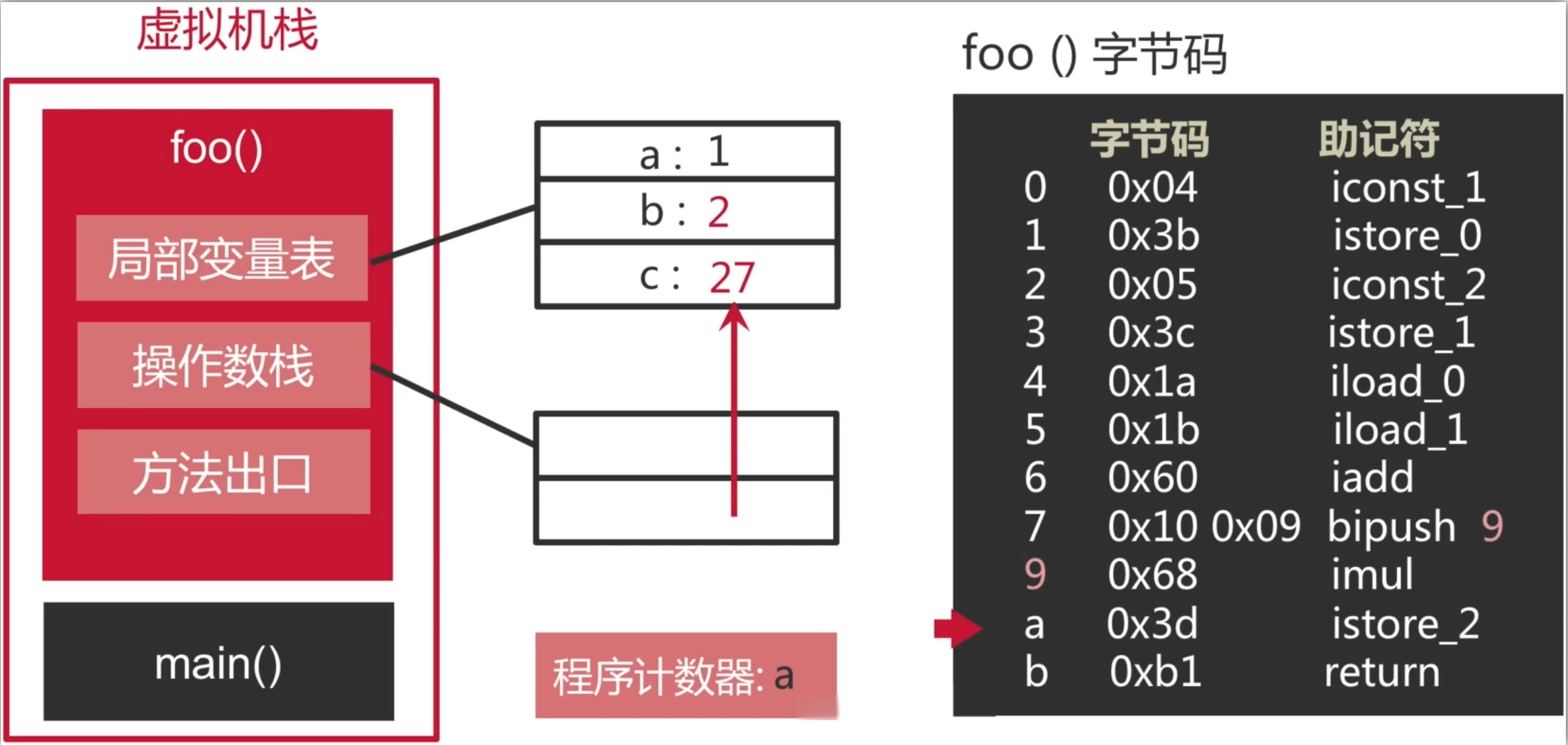

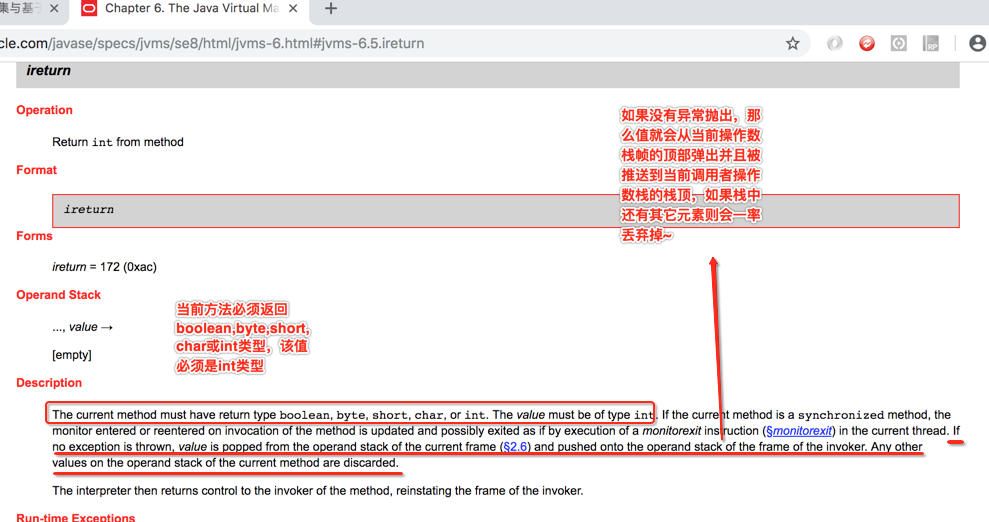
12、整个函数返回:

而ireturn助记符【图中貌似写错了,应该是ireturn】的含义这里也贴一下:
总结:
至此,这里就完整的将基于栈的虚拟机在运行字节码时的流程给走了一遍,有木有感觉到这么一点:每初始化一个变量,或者每做一步运算之前,都要把数据先放到操作数栈的栈顶,所有的指令都是来操作这个操作数栈,这就是基于栈的虚拟机的一个基本思路。
Dalvik虚拟寄存器:
虚拟寄存器:
既然不是基于栈的虚拟机,那就木有操作数栈了,取而代之的是虚拟寄存器:
而虚拟寄存器它模拟的硬件中的寄存器,而它所提供的数据插槽【也就是它的容量】,也是在编译其计算出来的,还记得上面基于栈的虚拟机的操作数栈的大小是不是也是编译期动态计算的?回忆一下:

而对于咱们的这个程序,也只需要数据插槽就可以了。另外基于寄存器的虚拟机也有“程序计数器”,作用也是一样的,记录当前运行字节码的行号。
下面咱们再来看一下Dalvik虚拟寄存器【也就是Android平台的虚拟机】是如何执行字节码的。
1、将java代码转换成dex字节码:
还是以同样的代码进行dex字节码的转换:

2、将给定字面量移到指定第一个寄存器中:

也就是对应于这句代码:

是不是可以直观的感受到,使用这种寄存器它的便捷之处,相对于基于栈的虚拟器来说,要少了好多步骤~~
2、将给定字面量移到指定第二个寄存器中:

也就是执行了这一句:

3、对两个源寄存器执行已确定的二元运算,并将结果存储到第一个源寄存器中:

也就是:

4、对指定的寄存器和字面量值执行指定的二元运算,并将结果存储在目标寄存器中:

最后程序返回。
问题:
这里来看一下最后执行结果:
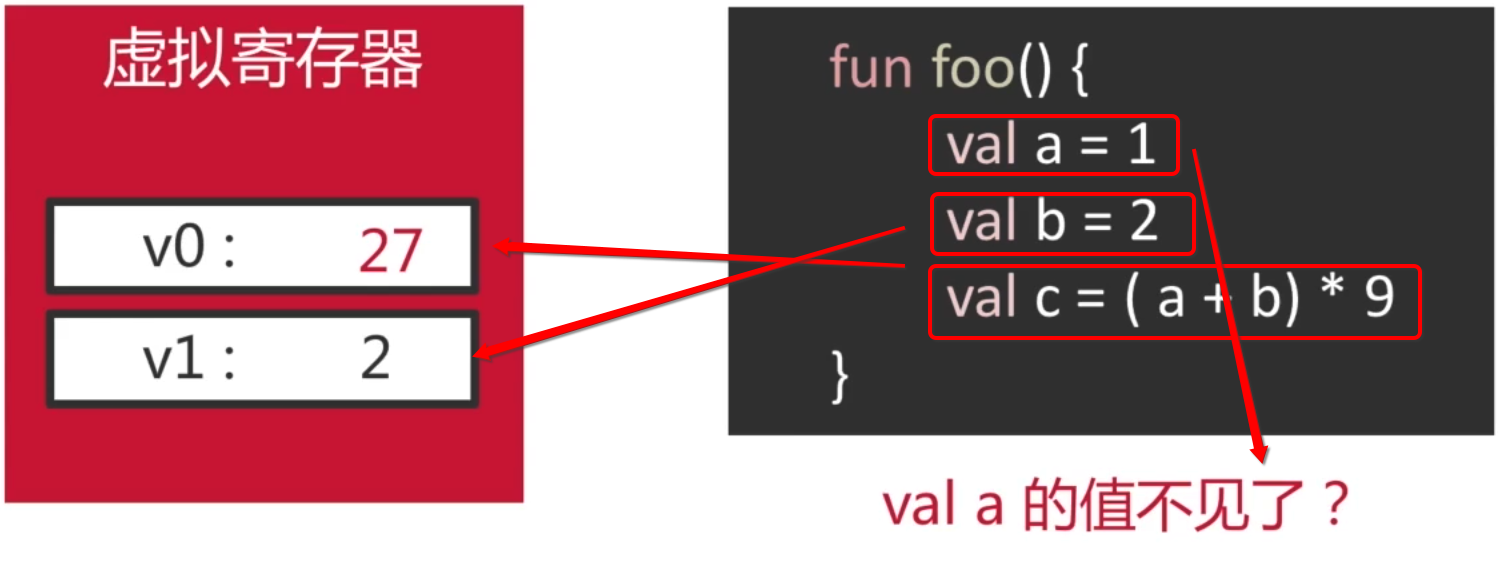
其实这是编译器的优化机制:以使用最少寄存器为前提,不改变语意,优化掉无用的代码,这样就可以节省内存插槽,节约内存。由于a在计算之后在这个程序中是木有意义了,所以寄存器中不保留它的结果也不会影响整个程序的执行。那假如程序在之后又要使用a这个值咋办?这里不用担心,编译器会帮我们申请第三个寄存器插槽的。
各自特点:
好,接下来用一个表格来看一下这两种类型虚拟机各自的一些特点:

如何看待基于栈的虚拟机设计?
1、JVM基于栈去设计的初衷之一,是压缩代码体积:
- Java设计之初最重要的一个特性就是跨平台,支持嵌入式设备和手持设备(J2ME)。因为当时的设备都没有特别大的内存及存储空间,所以要压缩代码的体积。
- Java设计之初,另一个特性是,支持远程传输执行字节码,要降低传输开销。
2、 基于栈的虚拟机,字节码实现简单:
- 这个简单是指生成字节码的过程简单,而不是虚拟机本身简单,或者说是编译器的实现简单。
- 操作时,不用考虑寄存器的地址(绝对位置),只需要把想要操作的数据出栈、入栈、然后再实现如何针对栈进行操作就可以了。
3、基于栈的虚拟机,可移槙性高:
- 为了提高效率,虚拟寄存器要映射到真实机器的寄存器,增加移植难度。
- 代码移植到其他硬件平台的时候,不用考虑真实机器寄存器的差异,因为操作栈的指令是通用的。
如何看待Android平台基于寄存器的设计?
这个才是面试官最最想听到的内容,下面来总结下。
1、更快!更省内存!
- 指令条数少!
- 数据移动次数少、临时结果存放次数少
- 映射真实机器的寄存器。
2、Android不需要解决移植性问题
- 因为Android平台的操作系统是统一的。
3、用其他方式解决了代码体积问题
- dex文件优化:
我们知道对于栈的虚拟器它有一个好处是能够压缩代码的体积,那么Android平台的代码就不需要压缩代码的体积了么?其实Android是通过对dex文件优化对字节码文件进行了压缩,这块之后也会进一步学到,先有个了解。
解答总结:
问:Android平台的虚拟机是基于栈的吗?
答:这块完全根据上面题面分析的思路来回答既可。
1、不是,Android平台的虚拟机有两种,一个是Dalvik和ART,它们都是基于寄存器的。
2、这里的基于栈:它是指的运行时栈帧中的操作数栈,它里面运行的是字节码指令集。
3、而对于基于栈的虚拟机的设计特点可以说一说:
4、那Android平台为啥要选择基于寄存器的虚拟机呢?这里就可以把上面的这段说一下:

经过这么一回答,绝对能够镇住面试官,说明你对此问题是知其然知其所以然的。
解题套路:
对于一个好的回答,通常是按如下几个步骤来进行说明的:
知识点-----》客观对比 -----》主观看法
其中“主观看法”是最为打动面试观的,所以说,主观看法的前提是前两步骤,需要你花时间去研究的。
总结:
以上是针对这个问题的剖析,是不是内容还是挺多的,接下来都会按照这么一个步骤,详细的对Android面试中的痛点进行全方面的梳理,相信等把篇头所列的所有大纲上的问题都解决了之后,在Android面试上绝对会大大地增强自信心,加油!!!

