

ios从入门到放弃之C基础巩固-----函数、进制转换、位运算、变量内存存储原理、类型说明符
距离上一次https://www.cnblogs.com/webor2006/p/13745410.htmlios的学习又过去大半年了,真的就是要放弃的节奏,这样的节奏可能再学个几年也不一定能学会,木关系,反正我目前不靠它维持生计,人生漫漫,学到天荒地老都是可以的~~把它当一种兴趣学到哪算哪,不轻易言败,不过关于C语言的巩固这里会加快一下,只复习自己不太熟悉的知识点,不然老是停留在这上面走不出也挺影响激情的。
函数:
声明和实现:
概述:
-
-
如果想把函数的定义写在main函数后面,而且main函数能正常调用这些函数,那就必须在main函数的前面进行函数的声明。
- 函数的声明格式:
返回值类型 被调函数名( 类型, 类型...);
比如:
int max( int a, int b ); int max( int, int );
实践:
接下来从代码角度来看一下该问题,先定义一个函数:
#include <stdio.h> void printRose() { printf(" {@}\n"); printf(" |\n"); printf(" \\|/\n");// 在C语言中\有特殊的函数, 它是一个转义字符 printf(" |\n"); } int main(int argc, const char * argv[]) { printRose(); return 0; }
运行:

而假如咱们将该函数放到main()下面:
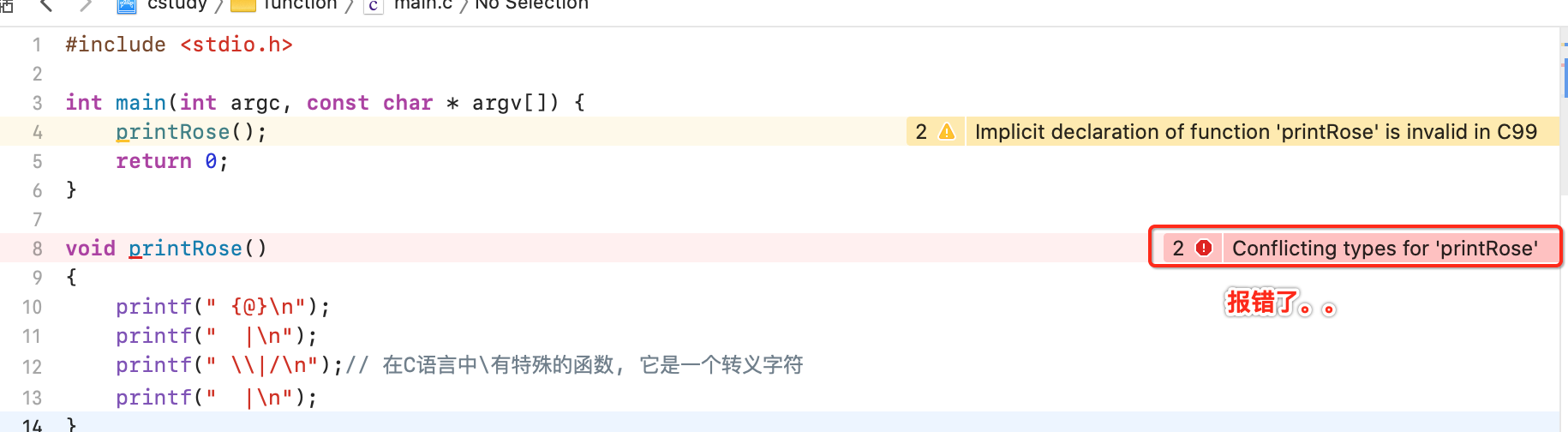
这个在java中是木有这个顺序问题的,但在C中是讲究顺序的,此时要想能正常运行,就需要再加一个函数的声明,如下:
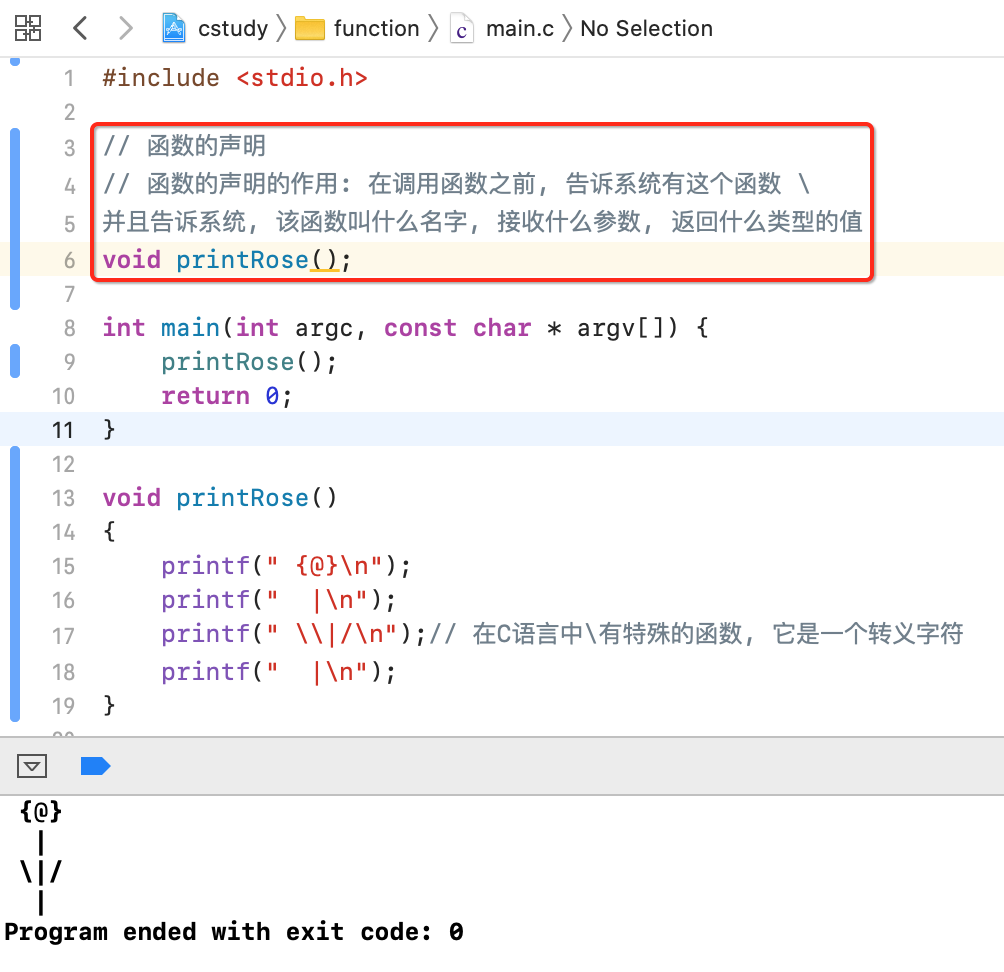
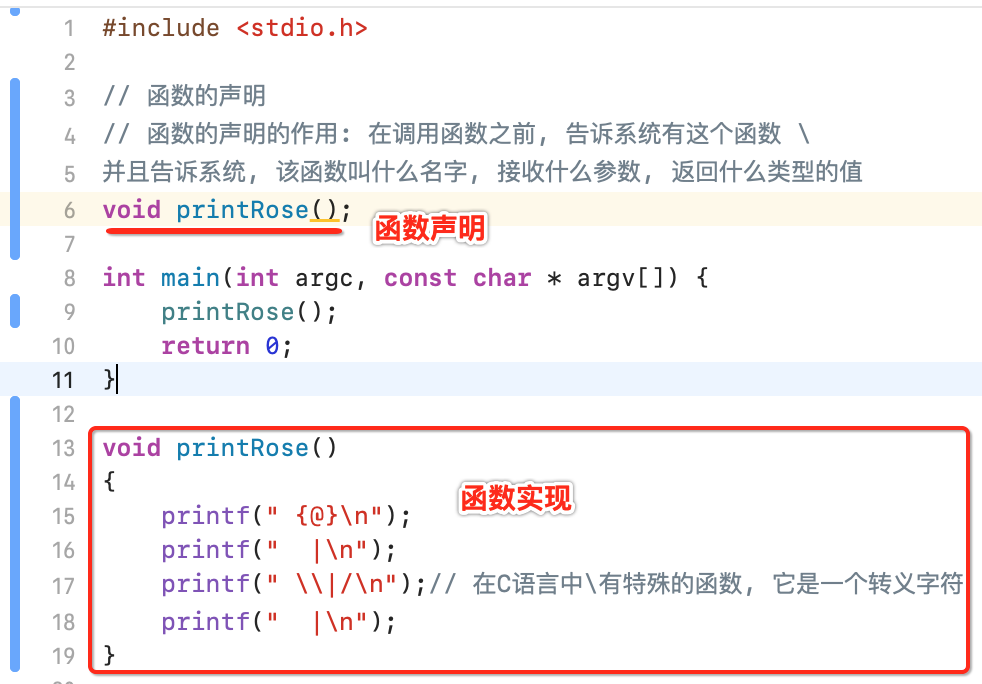
其中:
如果被调函数的返回值是整型时,可以不对被调函数作说明,而直接调用。这时系统将自动对被调函数返回值按整型处理。下面来演示一下:
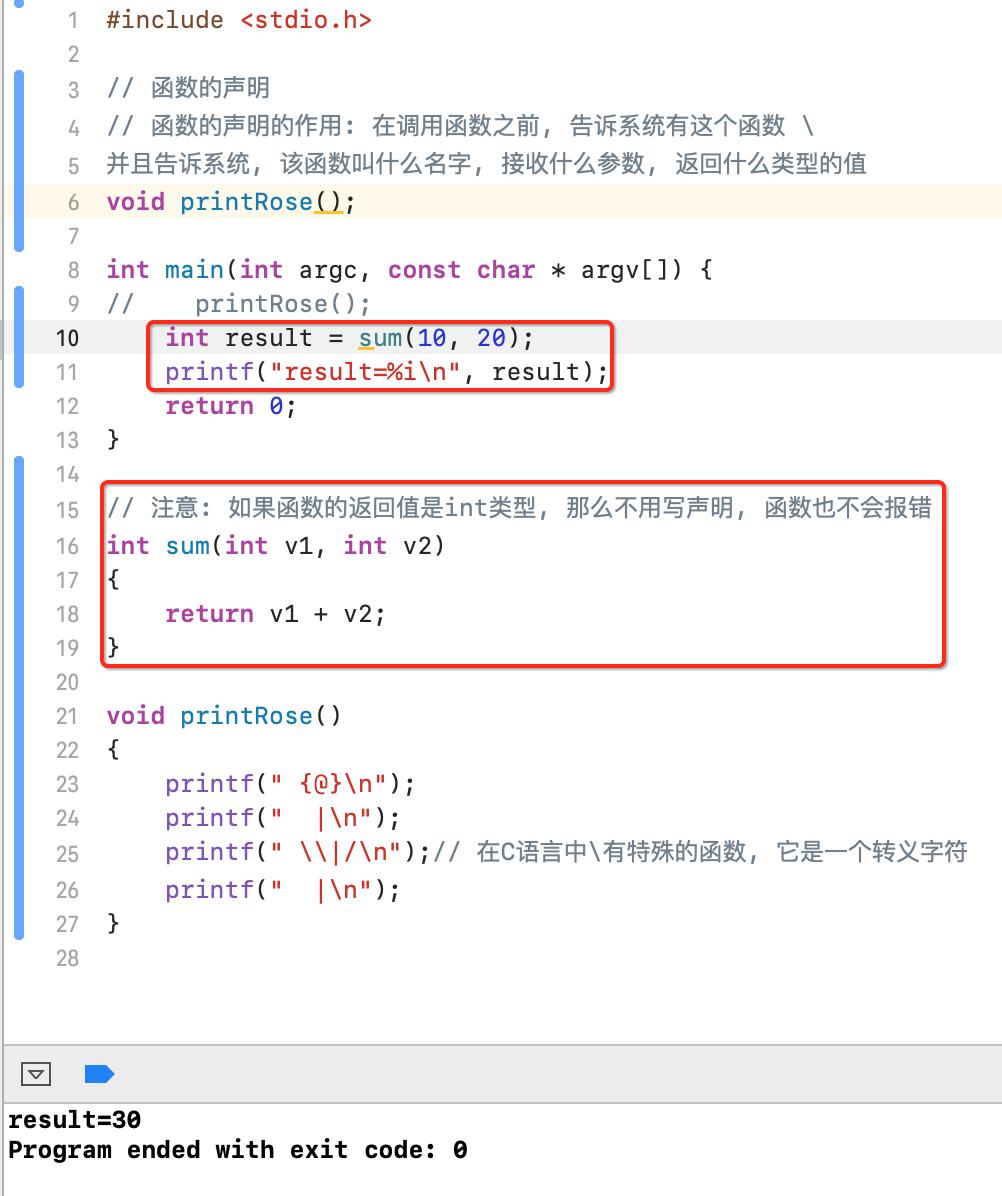
但是如果是double就又不行了:
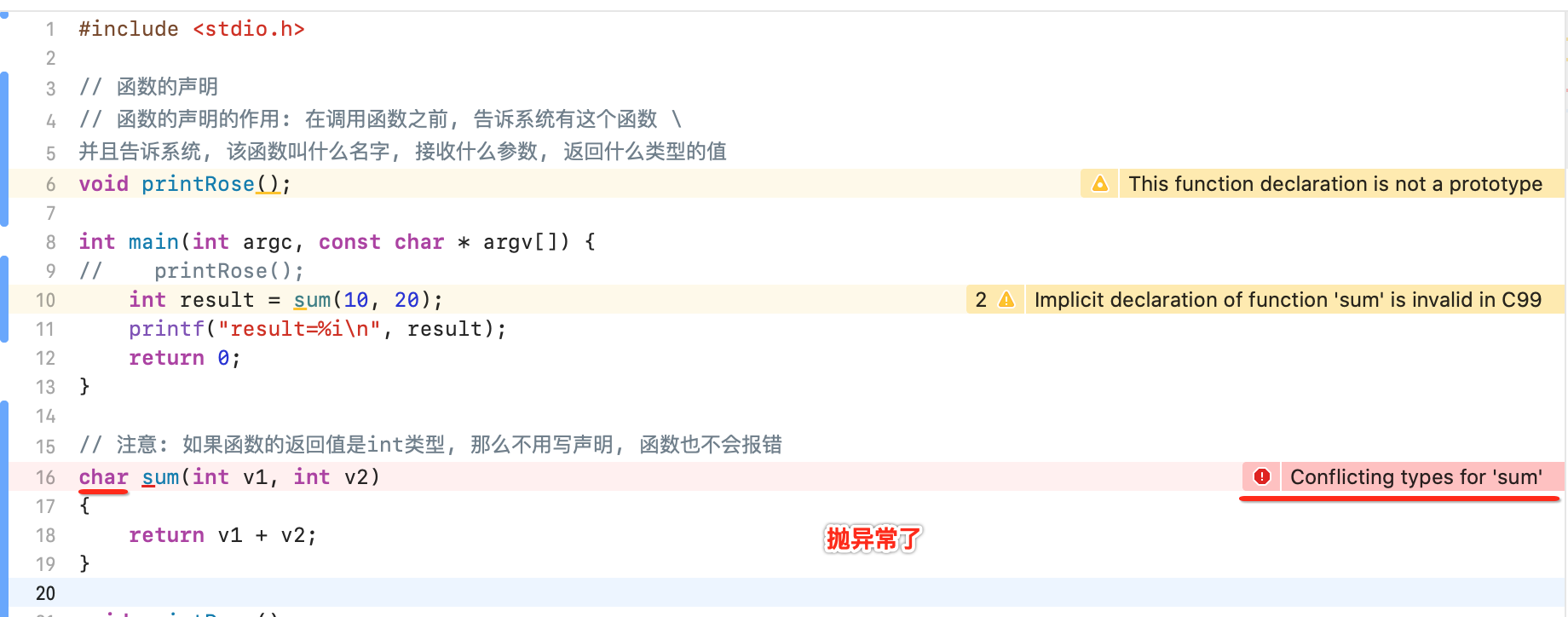
虽说int类型的函数如果定义在main()之后可以不声明,但是!!!建议也先声明一下形成一个良好的习惯:
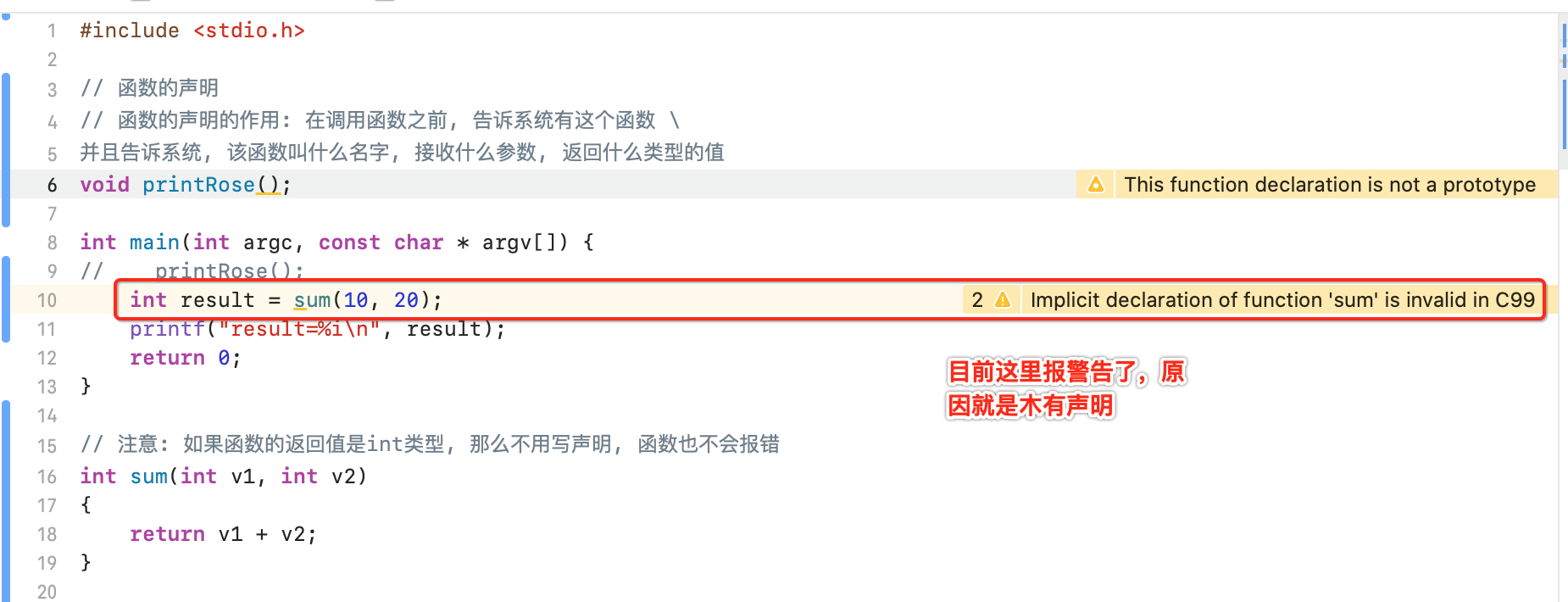
声明之后就不会有警告了:
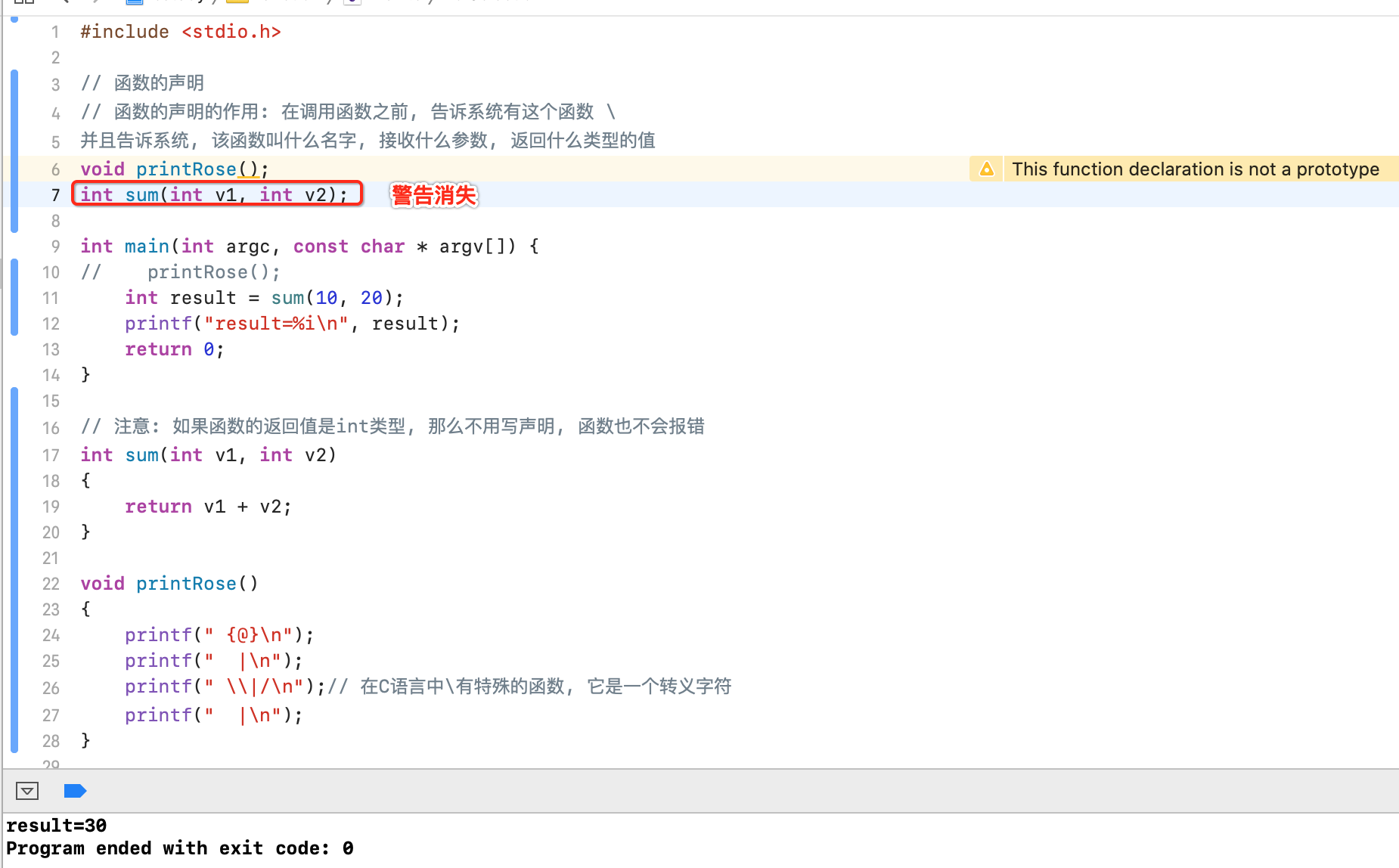
声明的其它写法:
1、实参去掉:
另外在函数声明时可以将具体的变量【实参】去掉,本身函数声明就是告诉系统函数的名字是啥,它的参数是啥类型,参数个数有多少,所以:
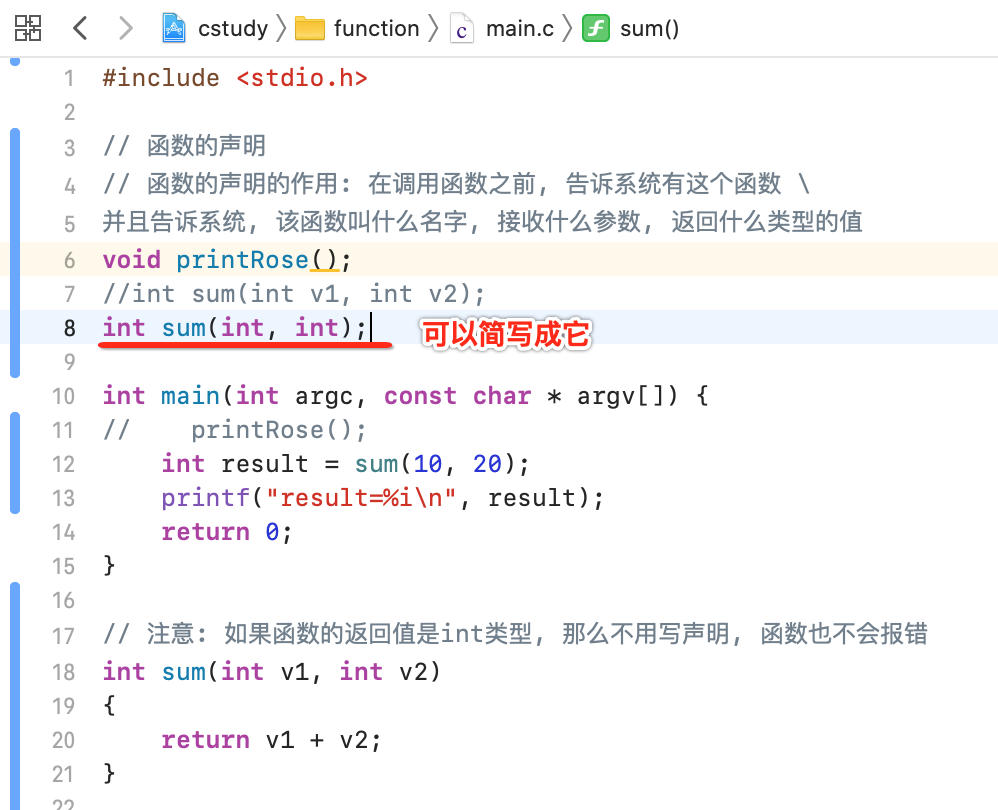
2、函数声明入函数内:
另外函数的声明, 只需要在函数被使用之前告知系统就可以了, 它可以写在函数的外面也可以写在函数的里面,比如:
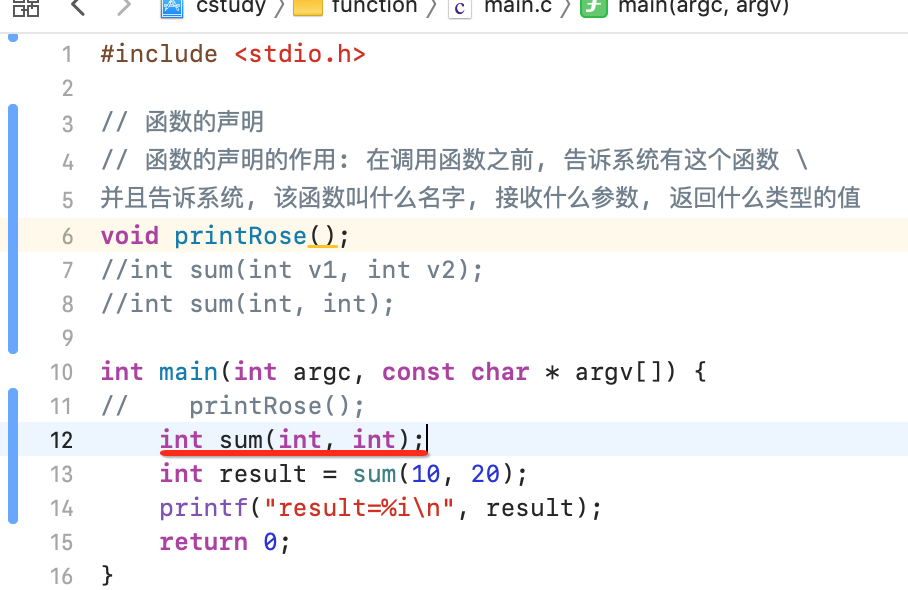
3、函数声明可以重复声明:
像这样:
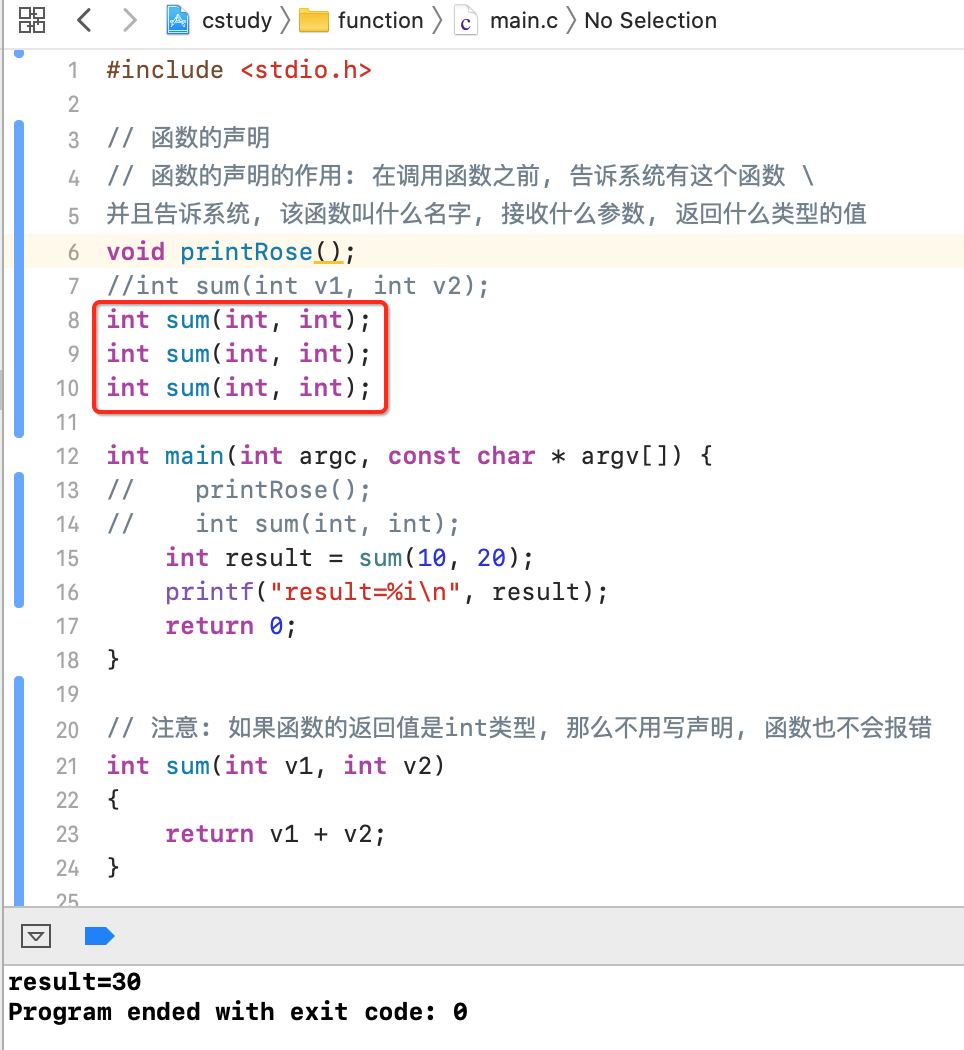
但是!!!函数的实现是不能重复的,比如:

疑问:为啥要将函数定义在main()函数之后呢?
既然将函数声明在main()之前就可以不进行函数声明,那可以不要函数声明了呀,其实之所有存在函数定义在main()之后,是为了提高代码的可读性,因为对于main()这么核心的函数肯定是要将它放到最前面,让阅读者打开代码首先引入眼帘的就是它,而将它所依赖的函数全放到后面,此时就必须要有声明的场景出现了。
main函数分析【了解】:
接下来对于咱们练习每天都在使用的main进行一个简单的分析:
返回值:
0 : 返回给操作系统, 如果返回0, 代表程序整除结束, 如果返回其它值代表程序非正常结束。而软件在运行时都会有一些运行日志,其中就会根据这个返回值来进行日志记录。
参数:
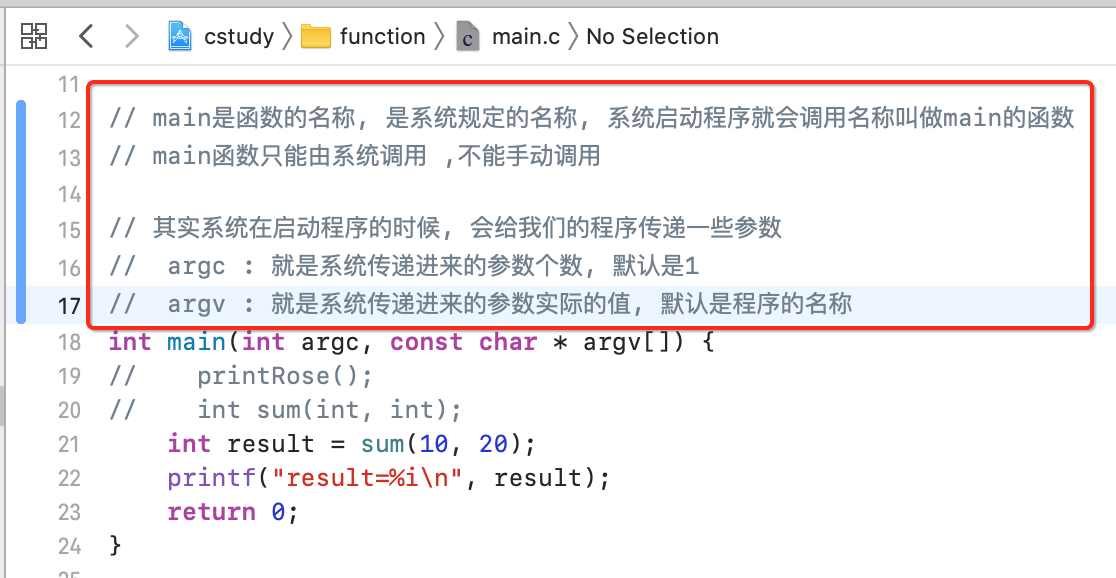
下面咱们来打印一下参数值:
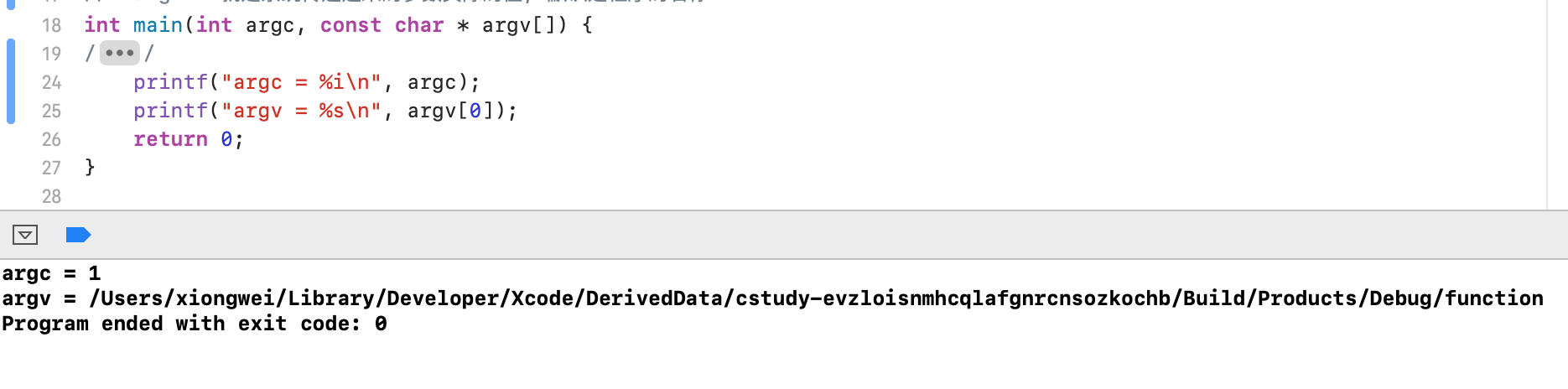
如果想更改main()函数的参数个数,可以在IDE中这么弄:
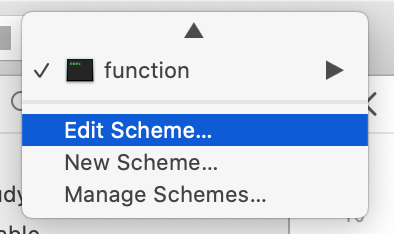
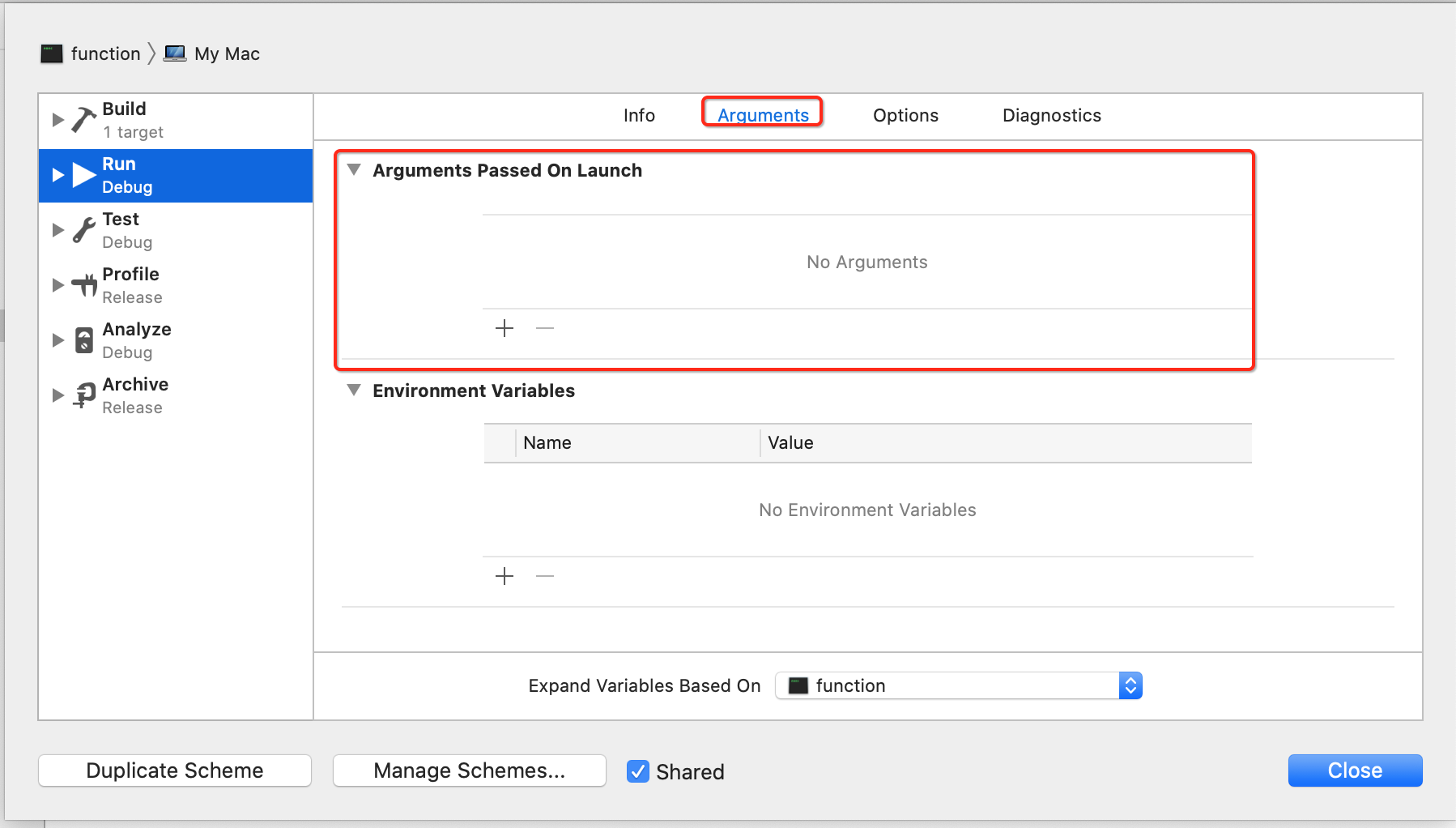
此时咱们就可以手动添加点参数:
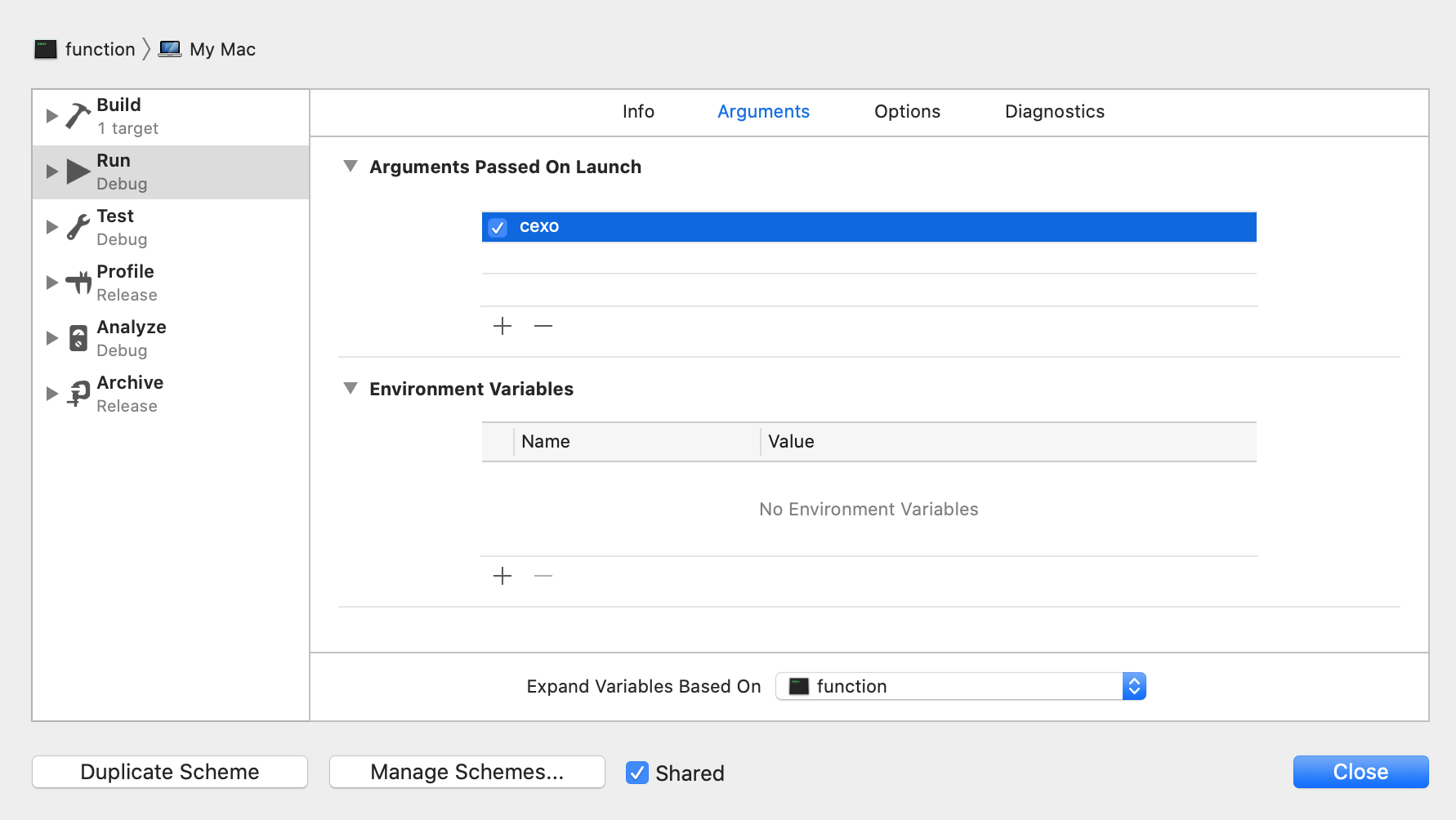
此时运行就有2个参数了,如下:
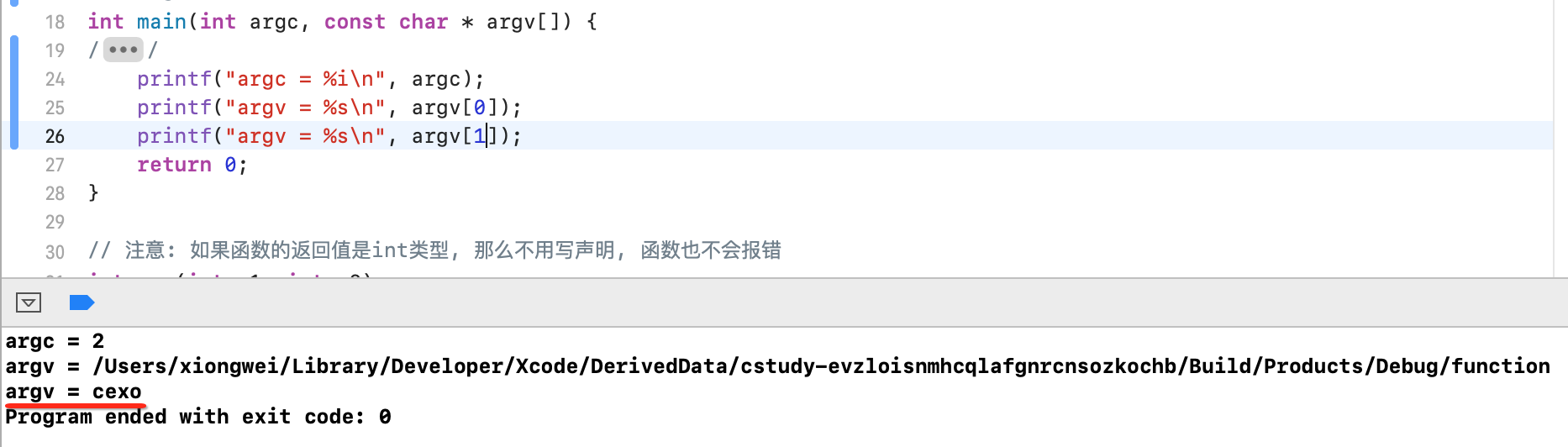
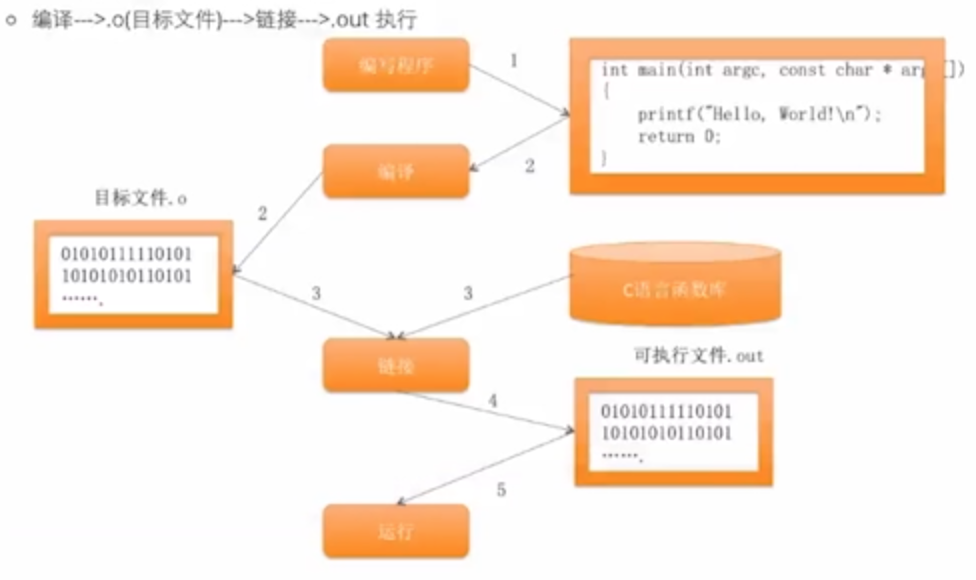
Xcode的运行原理:
当我们点击运行后xcode自动帮我们做如下事情:
include指令:
基本概念:
-
-
#include 指令后面会跟着一个文件名,预处理器发现 #include 指令后,就会根据文件名去查找文件,并把这个文件的内容包含到当前文件中。被包含文件中的文本将替换源文件中的 #include 指令,就像你把被包含文件中的全部内容拷贝到这个 #include 指令所在的位置一样。所以第一行指令的作用是将stdio.h文件里面的所有内容拷贝到第一行中。
比如这段代码: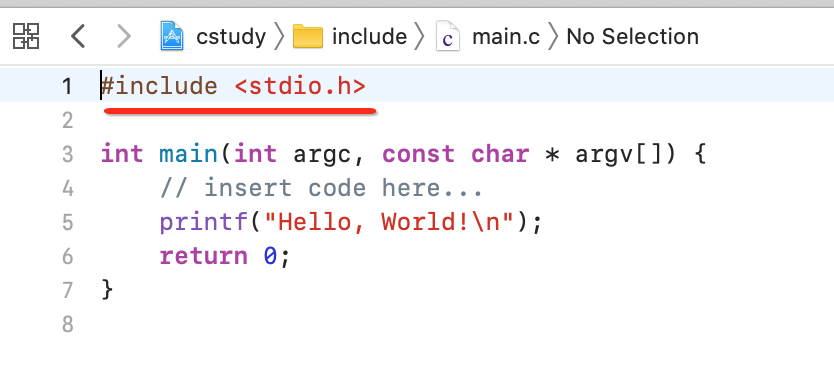
它就是告诉系统printf函数是存在的, 告诉系统printf函数的格式(声明printf函数),也就是printf()的函数声明就定义在这个头文件中: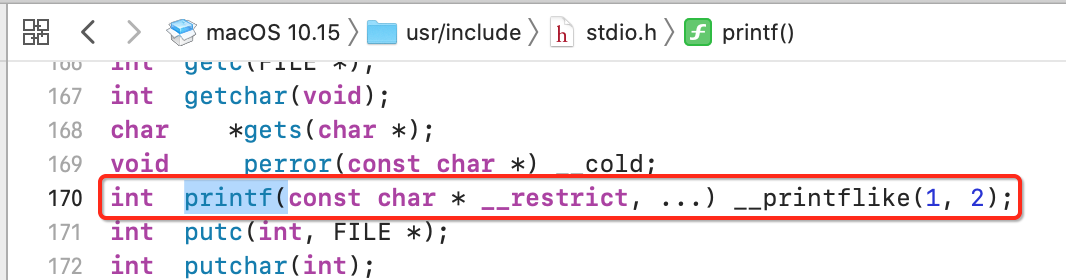
而include的作用其实就是将include右边的文件拷贝到当前文件中,为了验证这一点,咱们新建一个文本文件:
其中文本文件的内容为:
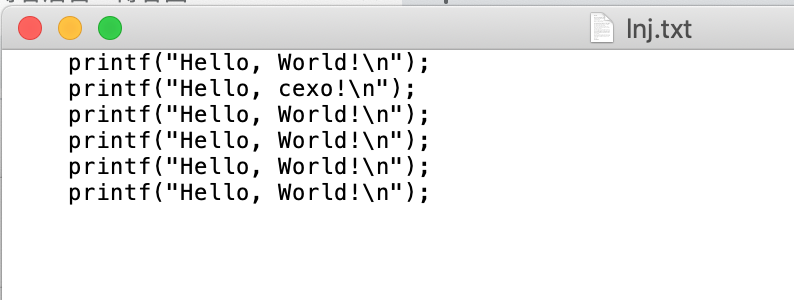
好,然后咱们可以这样写:
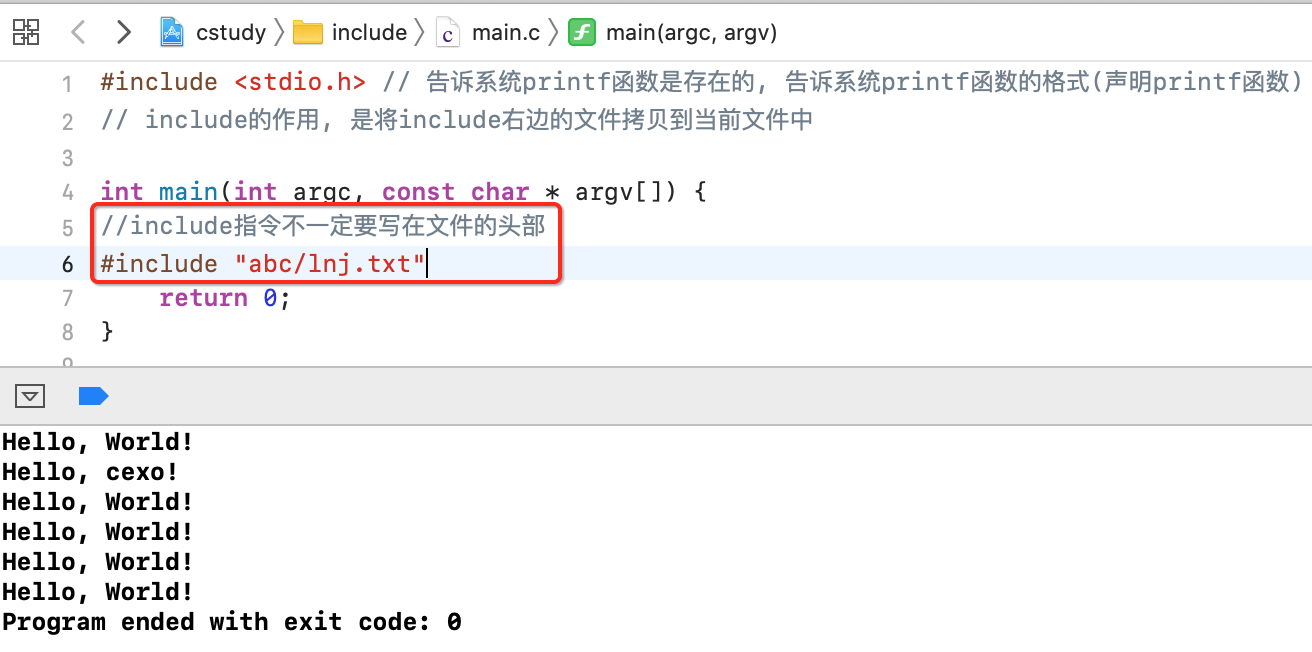
是不是深刻地能体会到它就是把文件中的内容拷贝到当前代码中对吧?
-
如果被包含的文件拓展名为.h,我们称之为"头文件"(Header File),头文件可以用来声明函数,要想使用这些函数,就必须先用 #include 指令包含函数所在的头文件
-
#include 指令不仅仅限于.h头文件,可以包含任何编译器能识别的C/C++代码文件,包括.c、.hpp、.cpp等,甚至.txt、.abc等等都可以
文件包含的格式:
当包含我们自己写的文件就是使用 #include "" 当包含系统供头文件的时候,就是用#include <>,比如:
#include <stdio.h> #include <math.h> #include "one.h"
#include<>和#include ""的区别:
-
-
对于使用双引号""来include文件,搜索的时候按以下顺序:
-
先在这条include指令的父文件所在文件夹内搜索,所谓的父文件,就是这条include指令所在的文件
-
如果上一步找不到,则在父文件的父文件所在文件夹内搜索;
-
如果上一步找不到,则在编译器设置的include路径内搜索;
-
如果上一步找不到,则在系统的include环境变量内搜索
-
-
对于使用尖括号<>来include文件,搜索的时候按以下顺序:
-
在编译器设置的include路径内搜索;
-
如果上一步找不到,则在系统的include环境变量内搜索
-
其中上面所说的“编译器Xcode的include”又具体指的哪呢?可以到这里查看一下:
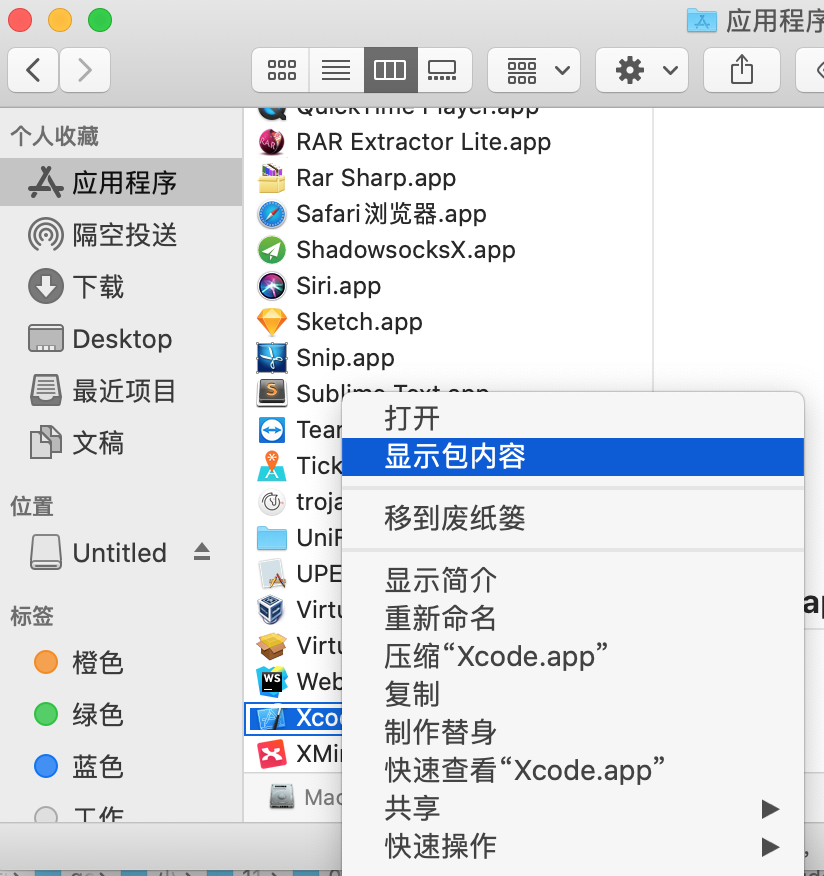
具体路径在:/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.10.sdk/usr/include/
![]()
那系统的include又在哪呢?如果是在mac电脑则是在:/usr/include。
多文件开发【重要】:
模块化编程的概念:
-
在编写第一个C程序的时候已经提到:我们编写的所有C语言代码都保存在拓展名为.c的源文件中,编写完毕后就进行编译、链接,最后运行程序。
-
在前面的学习过程中,由于代码比较少,因此所有的代码都保存在一个.c源文件中。但是,在实际开发过程中,项目做大了,源代码肯定非常多,很容易就上万行 代码了,甚至上十万、百万都有可能。这个时候如果把所有的代码都写到一个.c源文件中,那么这个文件将会非常庞大,也非常恶心,你可以想象一下,一个文件 有十几万行文字,不要说调试程序了,连阅读代码都非常困难。
-
而且,公司里面都是以团队开发为主,如果多个开发人员同时修改一个源文件,那就会带来很多麻烦的问题,比如张三修改的代码很有可能会抹掉李四之前添加的代码。
-
因此,为了模块化开发,一般会将不同的功能写到不同的.c源文件中,这样的话,每个开发人员都负责修改不同的源文件,达到分工合作的目的,能够大大提高开发效率。也就是说,一个正常的C语言项目是由多个.c源文件构成。
-
所谓模块化编程(多文件开发),就是多文件(.c文件)编程,一个 .c 文件和一个 .h 文 件可以被称为一个模块。
在以下场景中会使用头文件:
-
-
在很多场合,源代码不便(或不准)向用户公布,只要向用户提供头文件和二进制的库即可。用户只需要按照头文件中的接口声明来调用库功能,而不必关心接口怎么实现的。
-
-
多文件编译。
-
将稍大的项目分成几个文件实现,通过头文件将其他文件的函数声明引入到当前文件。
-
-
头文件能加强类型安全检查。
-
如果某个接口被实现或被使用时,其方式与头文件中的声明不一致,编译器就会指出错误, 这一简单的规则能大大减轻程序员调试、改错的负担。
-
多文件开发实现:
比如要计算两个人使用的电费,可以定义如下函数:
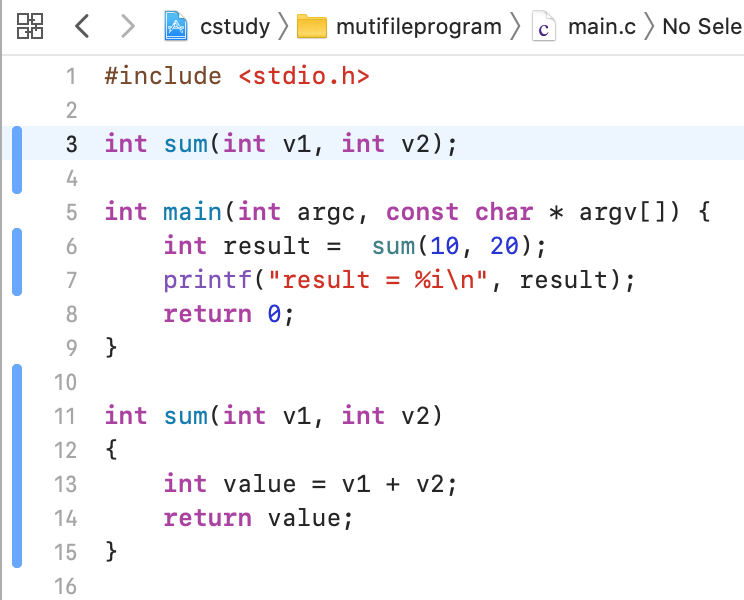
而接下来将这个求电费的抽离出去,新建一个文件:
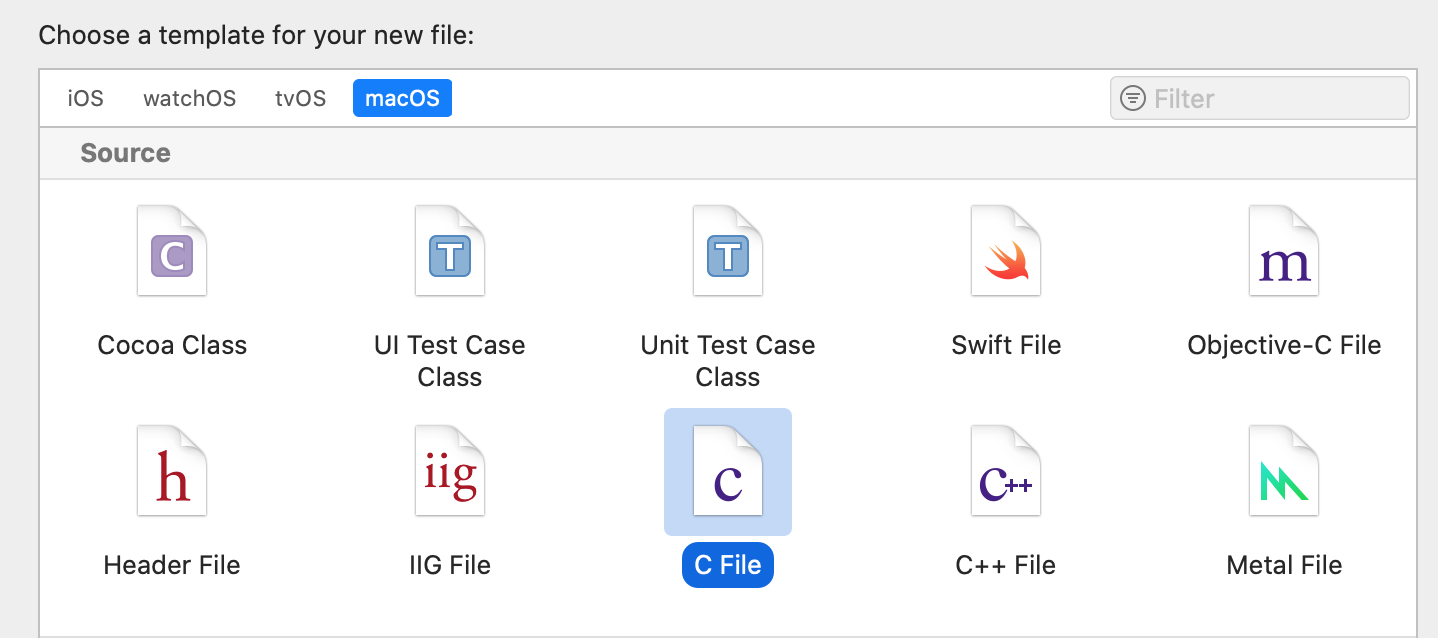
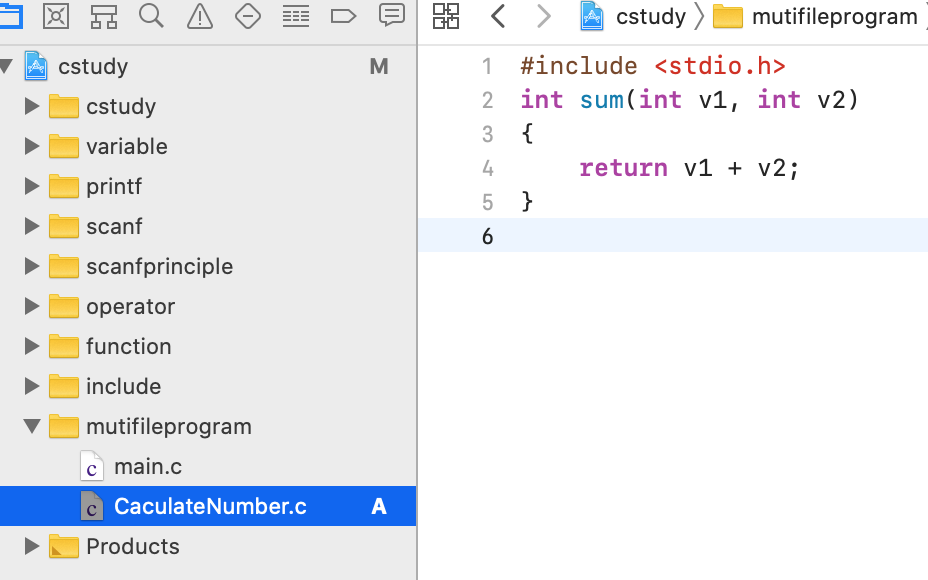
此时在main()中只需要声明一下:
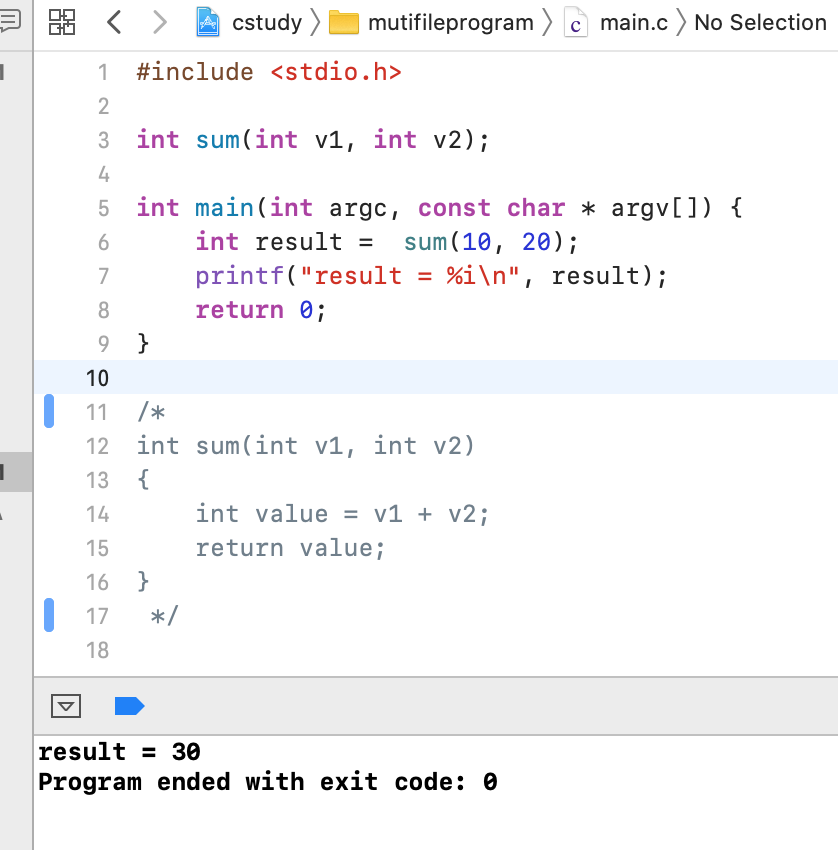
接下来可以再多定义一些函数:
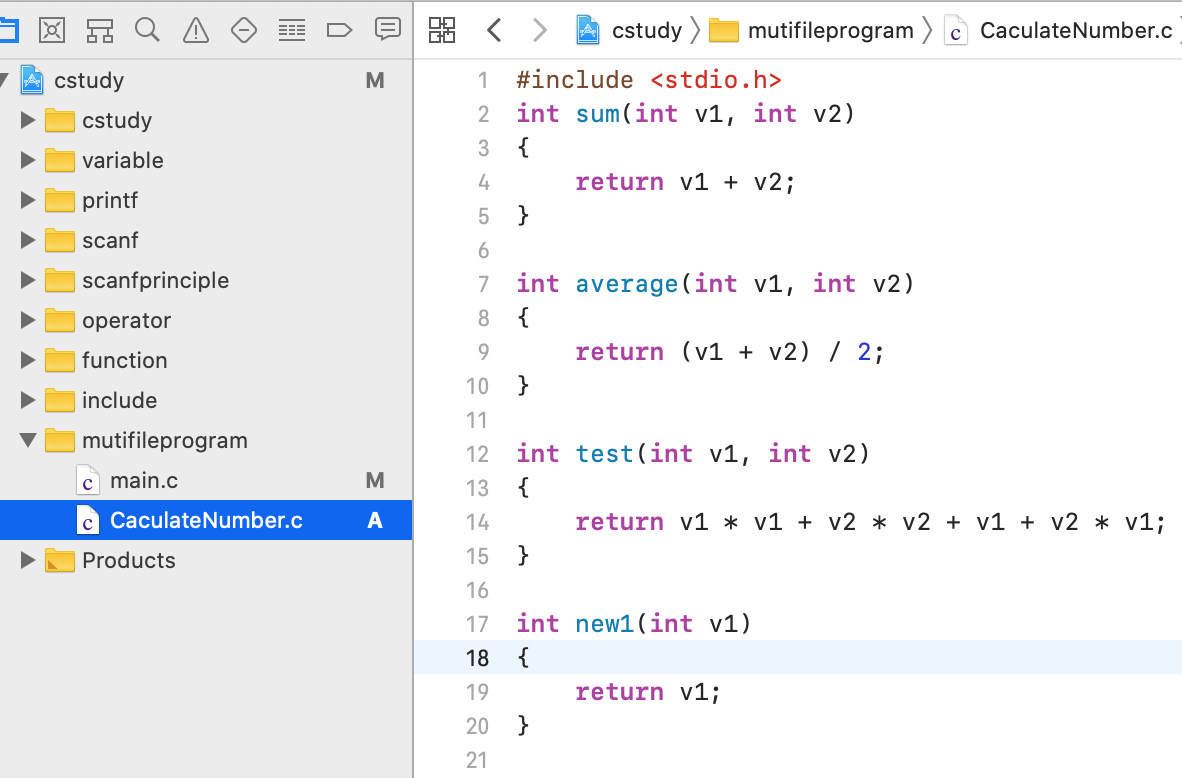
此时调用时,则可以这样:
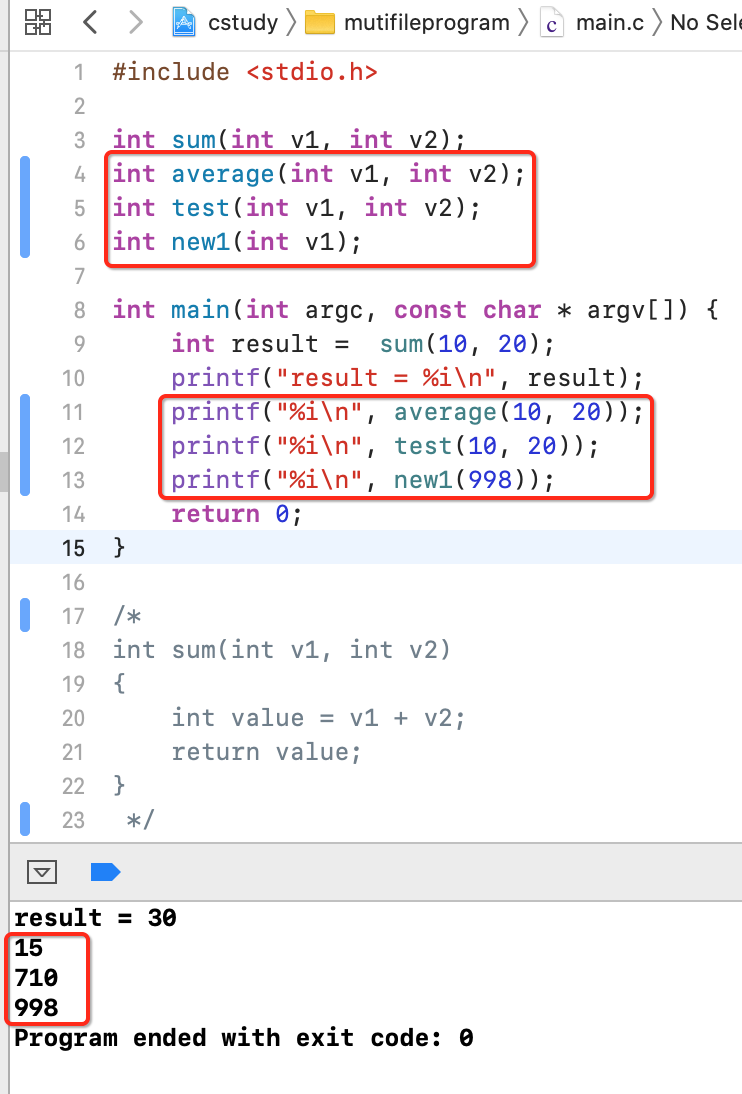
现在的问题来了,每次在调用其它文件实现的函数时我都得要在自己的文件中进行一个相同函数的声明才能使用,太麻烦了,因为我还得在其它文件的函数实现中来找函数声明,解决之道就是引入头文件。将这些函数声明都放到一个头文件中,如下:
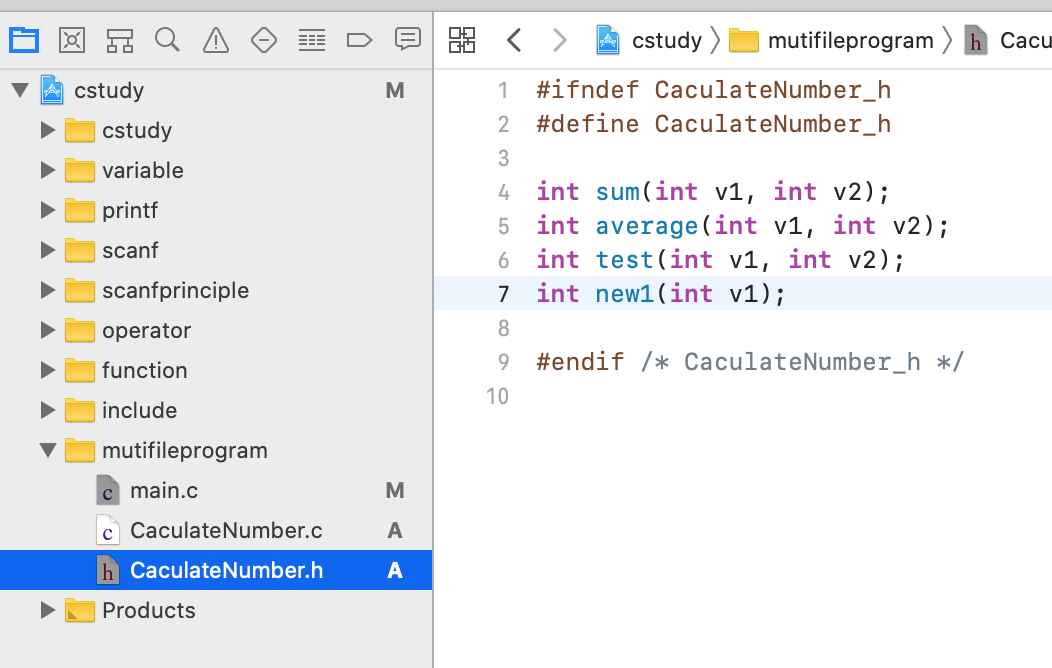
此时在调用方就只需要引入这个头文件既可,还记得include的含义么?其实就是类似于代码copy,如下:
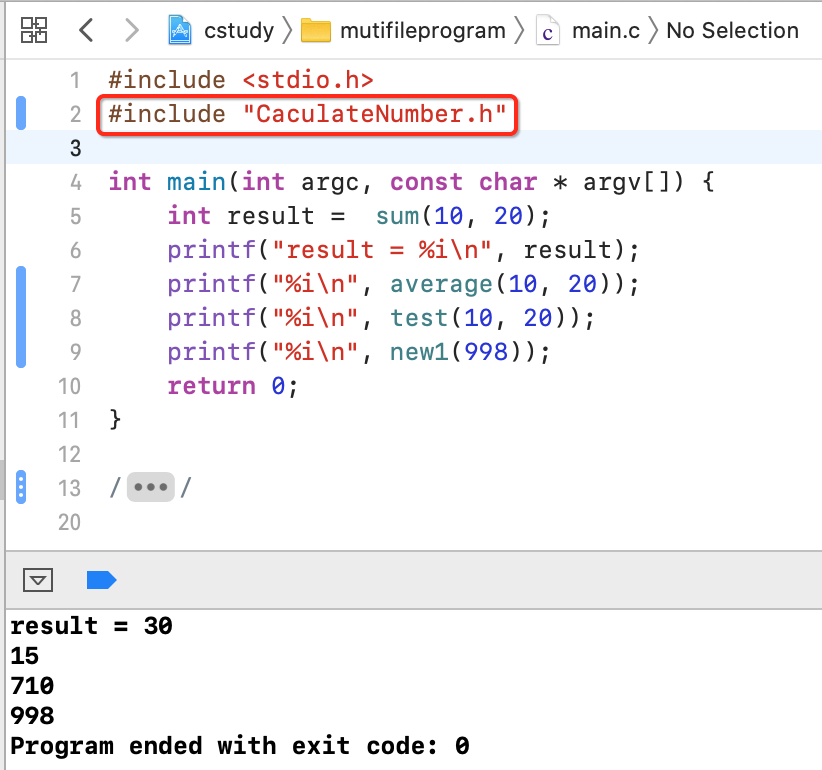
此时对于调用方而言就不用关心函数的实现,只需要看函数的声明既可,而且函数的声明也不会太长,因为不是具体实现,简单明了。
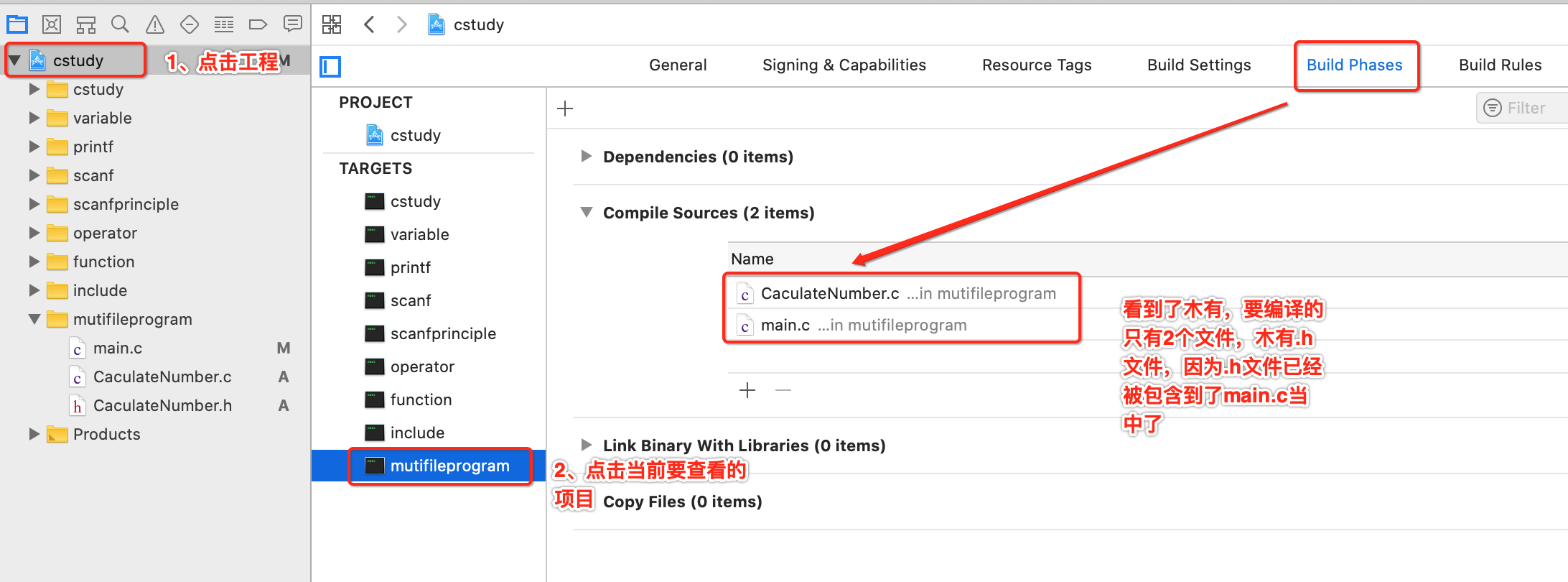
其中要知道的是:这个.h文件是专门用来被拷贝的,不会参考编译。如何来证明呢?其实可以在XCode中看到:
多文件开发的注意事项:
-
-
可以声明函数, 不可以定义函数
-
可以声明常量, 不可以定义变量
-
可以“定义”一个宏函数。注意:宏函数很象函数,但却不是函数。其实还是一个申明。
-
结构的定义、自定义数据类型一般也放在头文件中。
-
多文件编程时,只能有一个文件包含 main() 函数,因为一个工程只能有一个入口函数。我们 把包含 main() 函数的文件称为主文件。
-
为了更好的组织各个文件,一般情况下一个 .c 文件对应一个 .h 文件,并且文件名要相同, 例如 fun.c 和 fun.h。
-
头文件要遵守幂等性原则,即可以多次包含相同的头文件,但效果与只包含一次相同。
-
防止重复包含的措施
进制转换:
进制输出:
关于进制转换的概念就不过多说明了,计算机的基础,这里主要是来演练一下在C中各个进制的输出是如何做的。
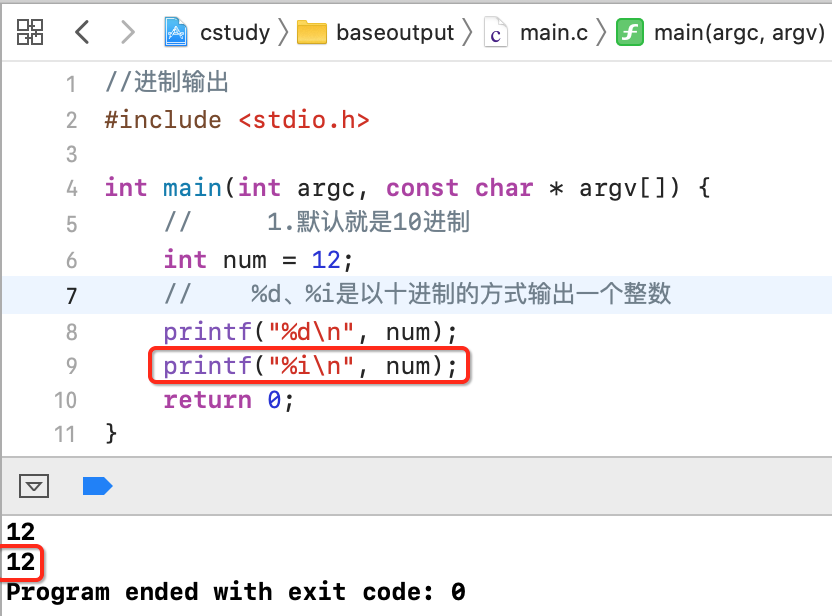
十进制:
默认输出就是十进制,如下:
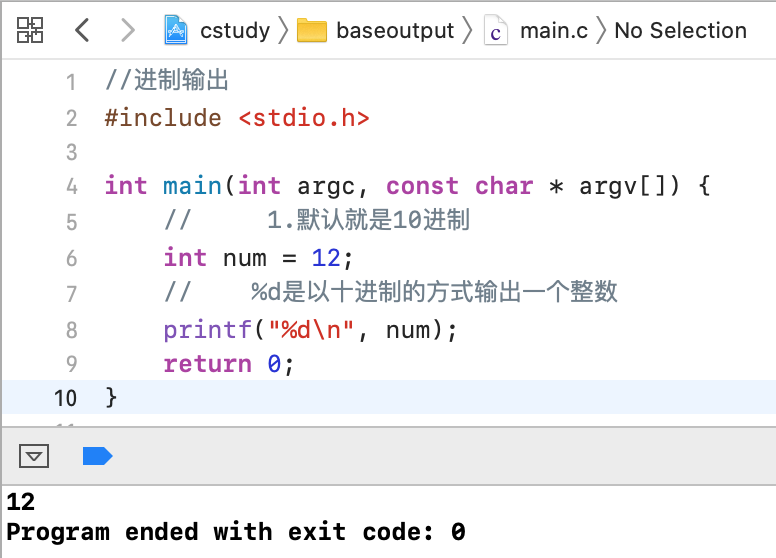
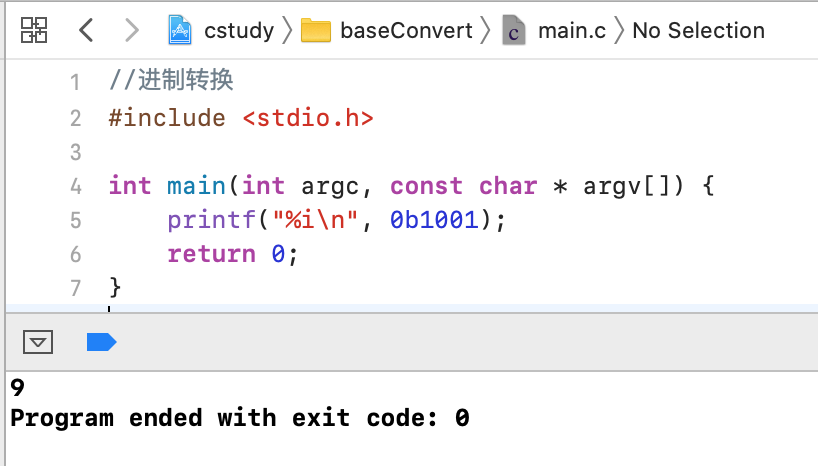
其中%i也可以表示输出十进制:
二进制:

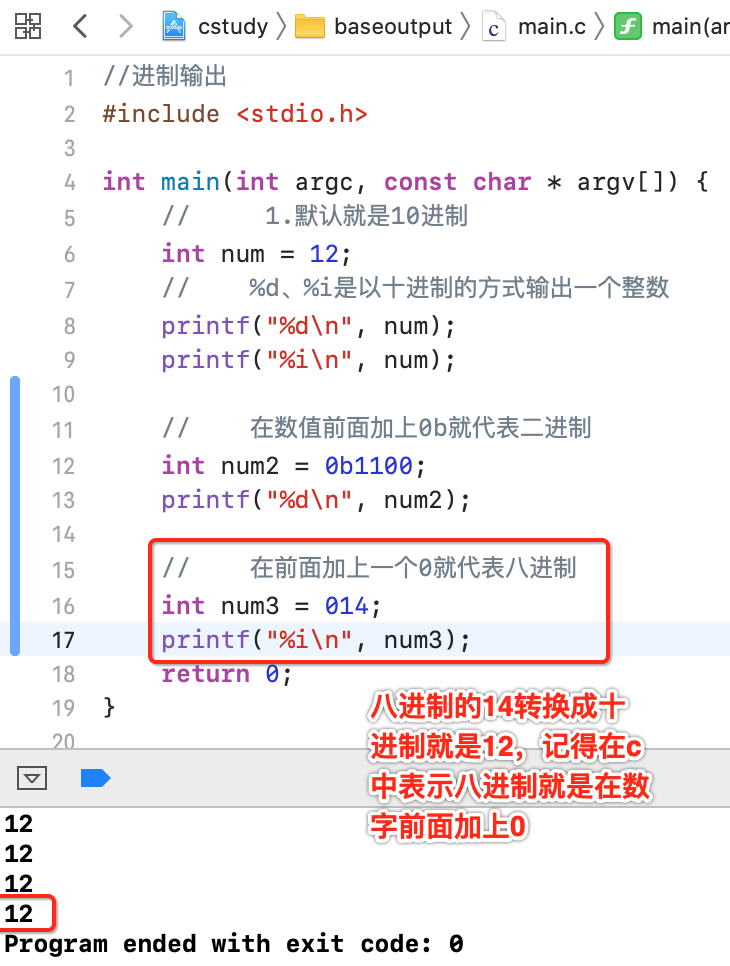
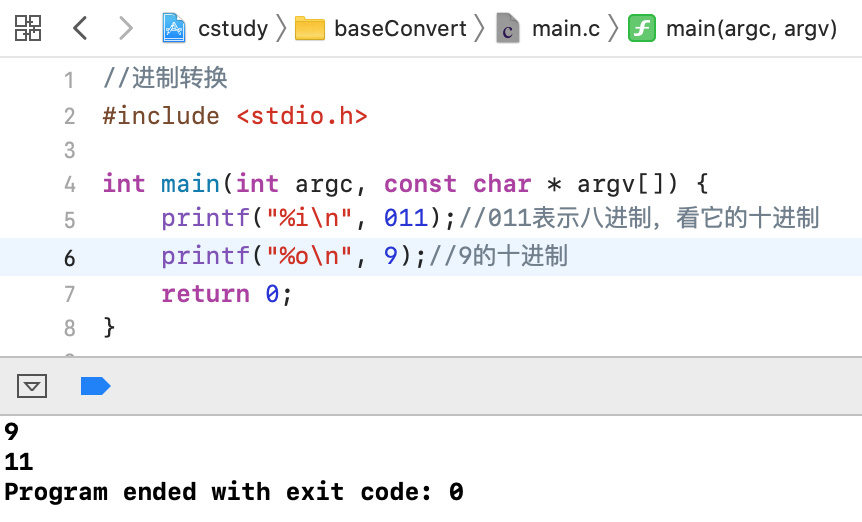
八进制:
在C中表示八进制如下:
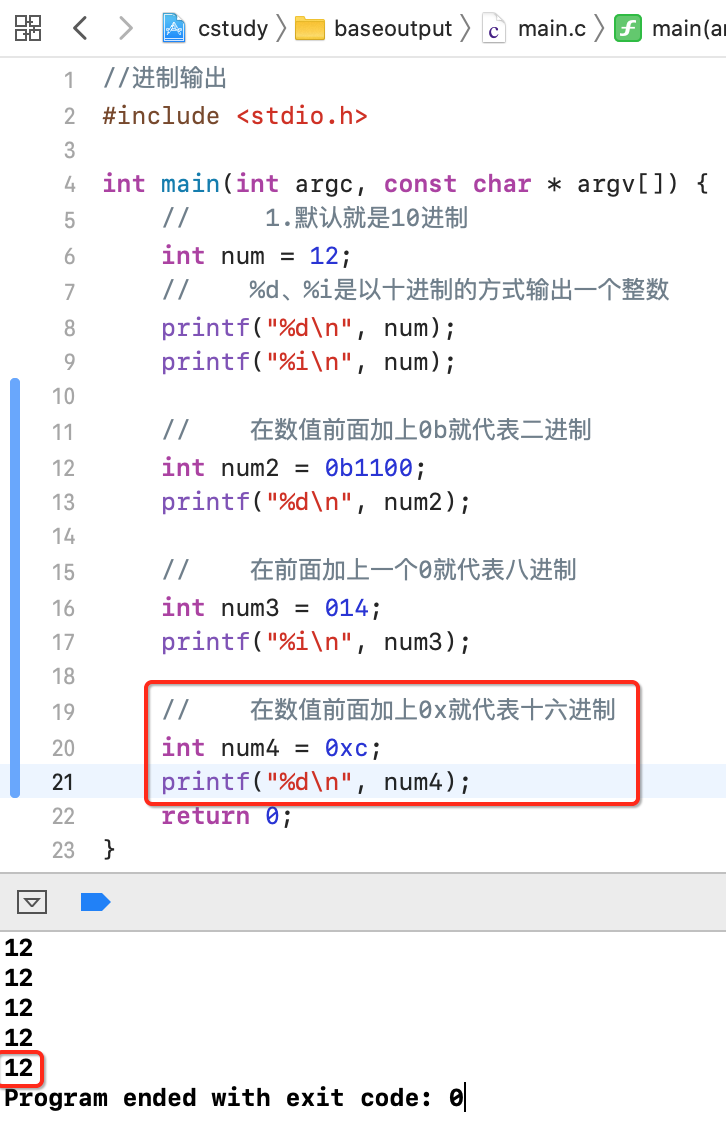
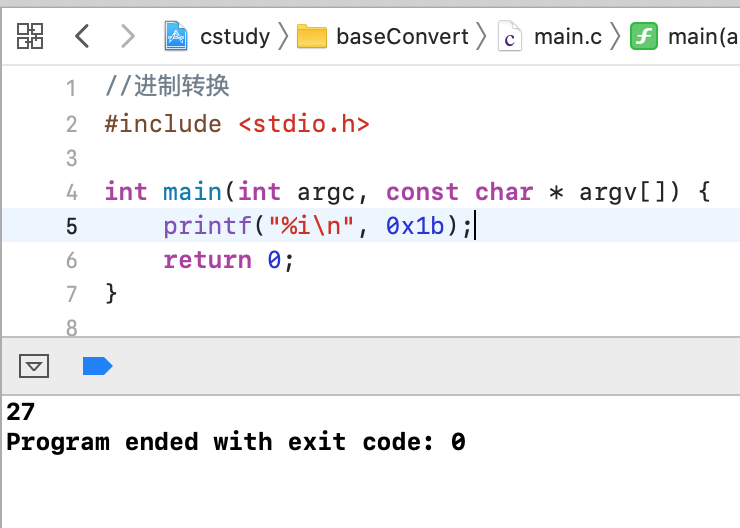
十六进制:
这个应该比较熟,做过跟串口相关的基本上都要跟它打交道,如下:
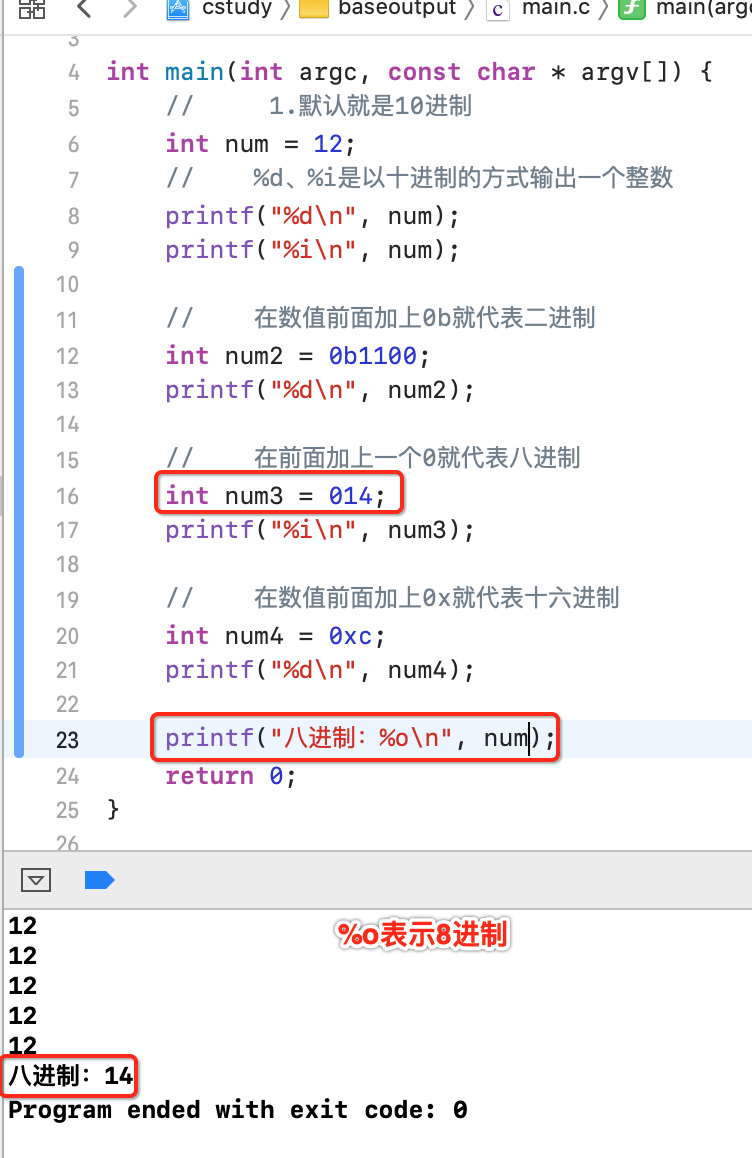
以上都是先用代码表示进制数,然后再输出十进制的方式来验证进制的正确性,那下面可以返过来,直接在输出时来指定进制,如下:
接下来看十六进制输出:
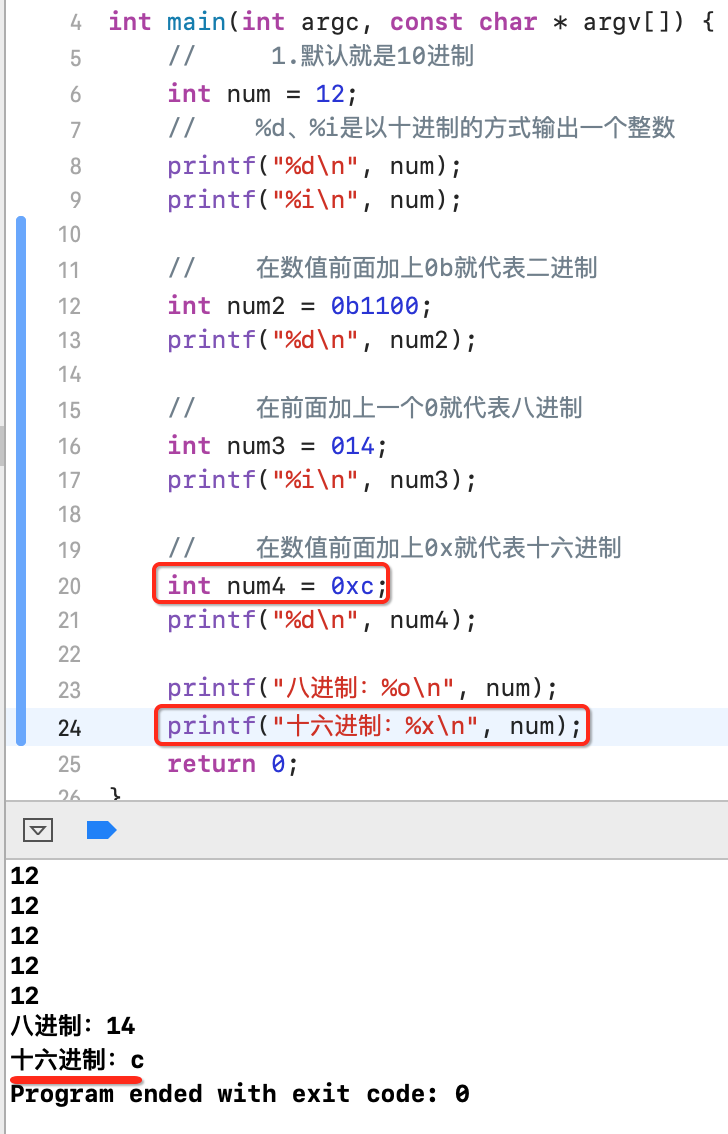
注意:在C中木有以二进制输出的的占位符,不过在之后会写一个方法来达到此目的。
进制转换:
转换原理:
这里就当复习一下计算机基础:除2取余 倒序读取,比如十进制的9要转成2进制,转换过程如下:
9/2 4 1 4/2 2 0 2/2 1 0 1/2 0 1 9 --> 1001[余数倒着取]
实践:
那下面用程序来验证一下所计算的:
2 进制转 10 进制:
转换原理:
从低位数开始,用低位数乘以2的幂数(幂数从0开始), 然后相加,比如:求二进制1001的十进制,计算过程如下:
1 * 2(0) = 1 0 * 2(1) = 0 0 * 2(2) = 0 1 * 2(3) = 8 1 + 0 + 0 + 8 = 9
N位二进制的取值范围:
先找规律:
1、1位二进制,可表示0、1,所以它表示的取值范围是:0~1;
2、2位二进制,可表示01、10、11,所以它表示的取值范围是:0~3;
3、3位二进制,可表示001、010、100、101、110、111,所以它表示的取值范围是:0~7;
以上就可以找到规律了,其实对于N位二进制,它的取值范围是:0~2(n)-1。
2 进制转 8 进制:
转换原理:
三个二进制位代表一个八进制位【因为3位的最大取值是7 而八进制是逢八进一】,只需要将3个二进制位转换为十进制,之后再将所有的结果连接起来。
实践:
还是以二进制1001为例,将它转换成8进制的过程为:
![]()
三位一分,然后再算出十进制,再连接起来就o了,下面来验证一下是否如此:
8进制转2进制:
转换原理:
将所有位求出的值相加,比如:
027 = 7 * 8^0 + 2 * 8^1 = 7 * 1 + 2 * 8 = 23
2 进制转 16 进制:
转换原理:
四个二进制位代表一个十六进制位【因为4位的最大取值是15, 而十六进制是逢十六进一】,只需要将4个二进制位转换成10进制,之后再将所有的结果连接起来。
实践:
比如将二进制11011转换成十六进制,如下:
![]()
验证一下:
16 进制转 2 进制:
转换原理:
0x25 =0b 0010 0101 =0b100101
原码补码反码【了解】:
关于这块的内容其实在老早https://www.cnblogs.com/webor2006/p/3426152.html就学习过,不过已经忘得差不多了,借此机会再回忆一下。
基本概念:
-
-
数据分为有符号数和无符号数
-
无符号数都为正数,由十进制直接转换到二进制直接存储(其实也是该十进制的补码)即可。 有符号数用在计算机内部是以补码的形式储存的。( 正数的最高位是符号位0,负数的最高位是 符号位1。 对于正数:反码==补码==原码。 对于负数:反码==除符号位以外的各位取反。补码=反码+1)
也就是说,对于上面的数字“9”,它是一个正数,也就意味着它的三码是合一的(也就是反码=补码=原码)。而如果是“-9”,它是一个负数,它的三码就不一样了,下面先将它转换成二进制,也是00000000 00000000 00000000 00001001,而因为它是负数,第1位是符号位为1,所以整个二进制就为:10000000 00000000 00000000 00001001,这就是“-9”的原码,而它的反码按如上规则所示:“除符号位以外的各位取反”,所以此时“-9”的反码为:11111111 11111111 11111111 11110110,而负数补码的规则就是“反码+1”,所以为:
所以最终“-9”这个数字在内存中存储的二进制就为“1111 1111 1111 1111 1111 1111 1111 0111”。 -
正数的首位地址为0,其源码是由十进制数转换到的二进制数字
-
负数的首位地址为1,其源码后面的位也为10进制数转换过去的二进制数字,都是用补码方式表示 有符号数的。
-
-
在探求为何机器要使用补码之前, 让我们先了解原码, 反码和补码的概念.对于一个数, 计算机要使用一定的编码方式进行存储. 原码, 反码, 补码是机器存储一个具体数字的编码方式. 原码, 反码, 补码是计算机原理的术语。说白了就是为了理解计算机2进制用的。对于C/C++来说,是和数据类型有关的。
-
为啥要有原码、补码、反码呢?其实主要还是为了方便计算机进行计算效率更高,主要有如下几点:
1、由于最高位是符号位,如果是0就代表是整数,如果是1就代表是负数;
2、所以如果直接存储的是原码,计算机在计算的时候还需要先判断最高位才能进行计算,效率比较低;
3、为了方便计算机进行计算,所以有了反码和补码,有了反码和补码之后,以后计算机计算时就不需要判断最高位了,直接计算就可以了。
深入了解:
这里再来进一步理解这几个码的意义。下面用推理的过程来道出为啥要引入原码和被码。
-
按照原码的样式来计算,结果就如:1 - 1 = 1 + (-1) = [00000001]原 + [10000001]原 = [10000010]原 = -2
很显然+ 如果用原码表示, 让符号位也参与计算, 显然对于减法来说, 结果是不正确的.这也就是为何计算机内部不使用原码表示一个数。
-
1 - 1 = 1 + (-1) = [0000 0001]原 + [1000 0001]原 = [0000 0001]反 + [1111 1110]反 = [1111 1111]反 = [1000 0000]原 (原码的计算方式就是:1111 1111,符号位不变,其他为逐位取反) = -0
+ 发现用反码计算减法, 结果的真值部分是正确的【真值就是指除了符号位之外的二进制所对应的值】. 而唯一的问题其实就出现在"0"这个特殊的数值 上. 虽然人们理解上+0和-0是一样的, 但是0带符号是没有任何意义的. 而且会有[0000 0000]原和 [1000 0000]原两个编码表示0。
-
1-1 = 1 + (-1) = [0000 0001]原 + [1000 0001]原 = [0000 0001]补 + [1111 1111]补 = [0000 0000]补 = [0000 0000]原
+ 这样0用[0000 0000]表示, 而以前出现问题的-0则不存在了.而且可以用[1000 0000]表示-128:
以上这块做个了解既可,实际编程中基本上用不到,但是!!!可能会出现在变态的面试中,所以了解它们也是很有必要的。
位运算:
关于位运算老早就在学,但是呢实际编程中巧用位运算还是不多的,而且每次看到位运算的代码就有点抵触情绪,因为一是用得少,二是掌握得不好,所以对它再来巩固是很有必要的。
什么是位运算符?
位运算符与:
-
-
只有对应的两个二进位均为1时,结果位才为1,否则为0
-
口诀: 同1为1
- 示例:
下面运行看一下:9&5 = 1 1001 &0101 ------ 0001
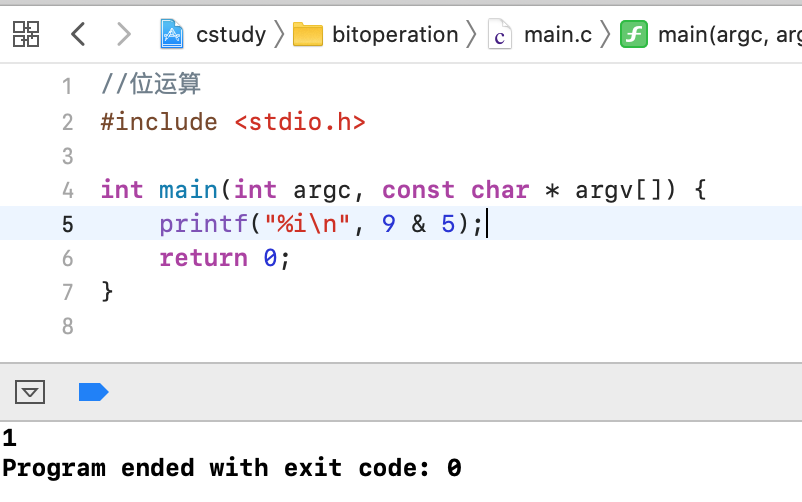
- 规律:
-
-
-
判断奇偶: 将变量a与1做位与运算,若结果是1,则 a是奇数;若结果是0,则 a是偶数。
-
任何数和1进行&操作,得到这个数的最低位。
1001 & 0001 ------------ 0001
+ 想把某一个位置变为0,可以:
11111111 & 11111011 ------------ 11111011
-
位运算符或:
-
-
只要对应的二个二进位有一个为1时,结果位就为1,否则为0。
- 示例:
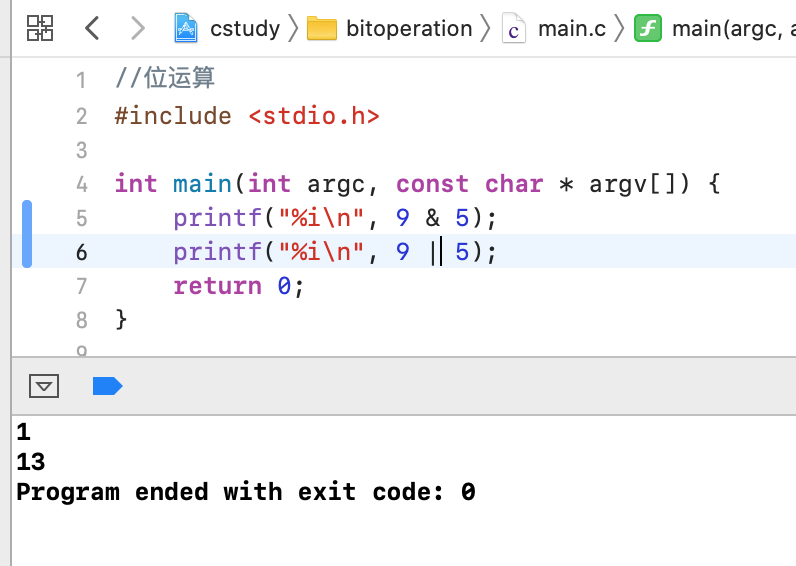
9|5 = 13 1001 |0101 ------ 1101
运行一下:
位运算符异或:
-
-
当对应的二进位相异(不相同)时,结果为1,否则为0。
- 示例:
9^5 = 12 1001 ^0101 ------ 1100
- 规律:
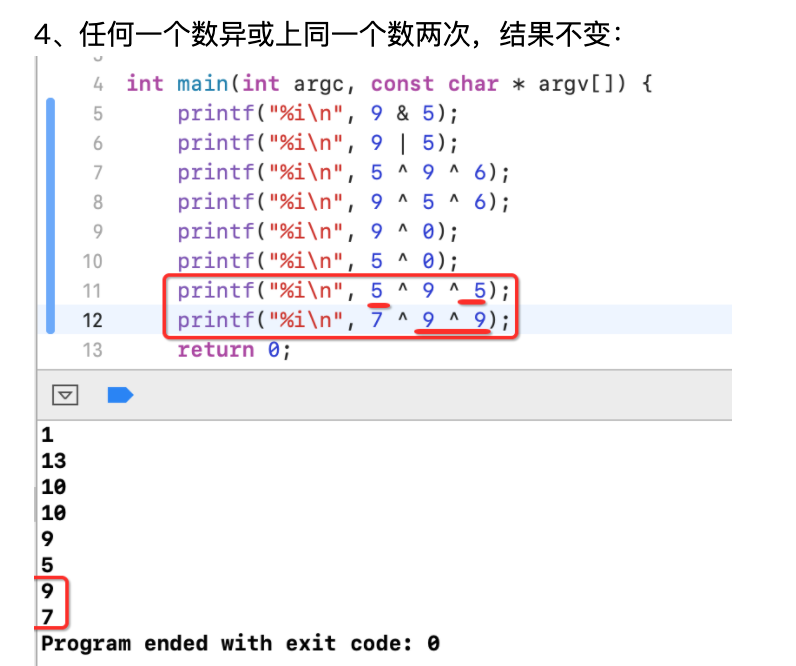
1、相同整数相^的结果是0。比如5^5=0。
2、异或的结果和参与运算的顺序是没有关系的: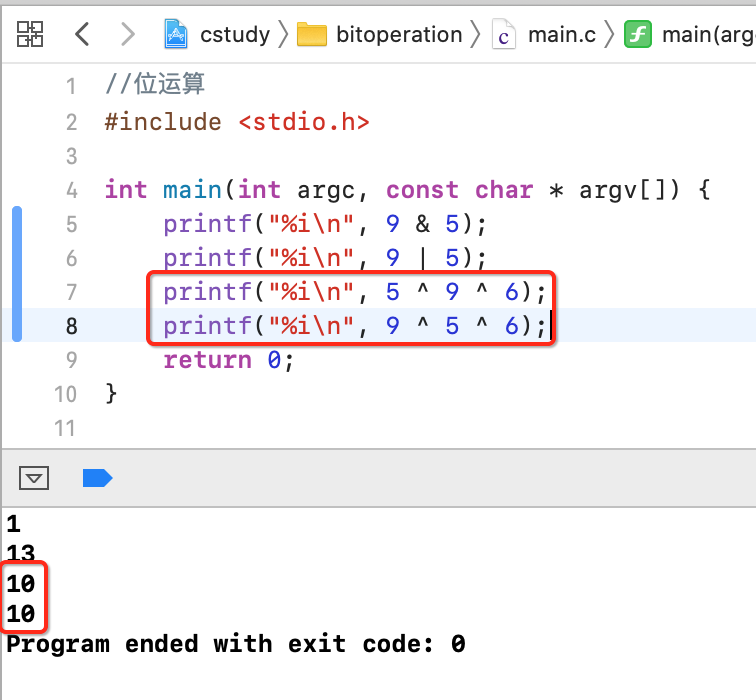
3、任何一个数异或上0结果不变: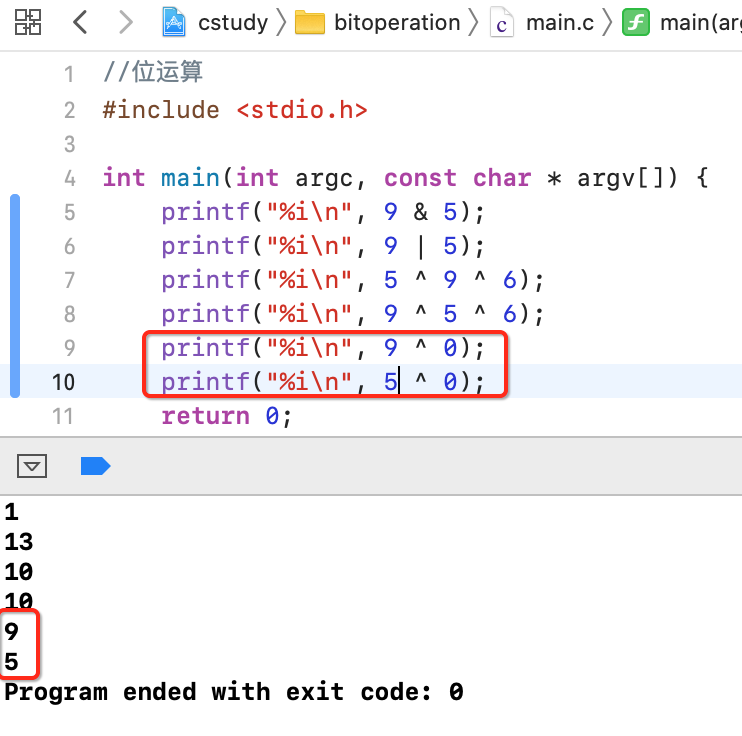
4、任何一个数异或上同一个数两次,结果不变: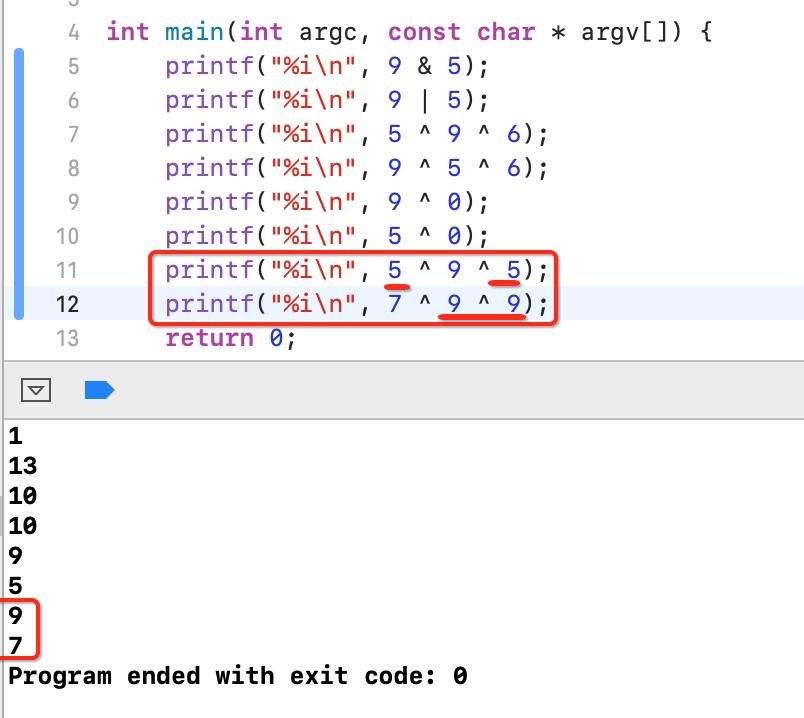
位运算符取反:
-
-
各二进位进行取反(0变1,1变0)
-
-
示例
~9 =-10 9的原码:0000 0000 0000 0000 0000 1001 反码:1111 1111 1111 1111 1111 0110 知道补码求原码:也是符号位不变,其他各位取反+1 1111 1111 1111 1111 1111 0110 取反 1000 0000 0000 0000 0000 1001 +1 1000 0000 0000 0000 0000 1010 // -10
这里要明白已知补码,求原码的方法:

左移右移:
左移运算符:
-
-
由于左移是丢弃最高位,0补最低位,所以符号位也会被丢弃,左移出来的结果值可能会改变正负性
-
比如:
2<<1; //相当于 2 *= 2 // 4 2<<2; //相当于 2 *= 2^2; // 8
练一下:
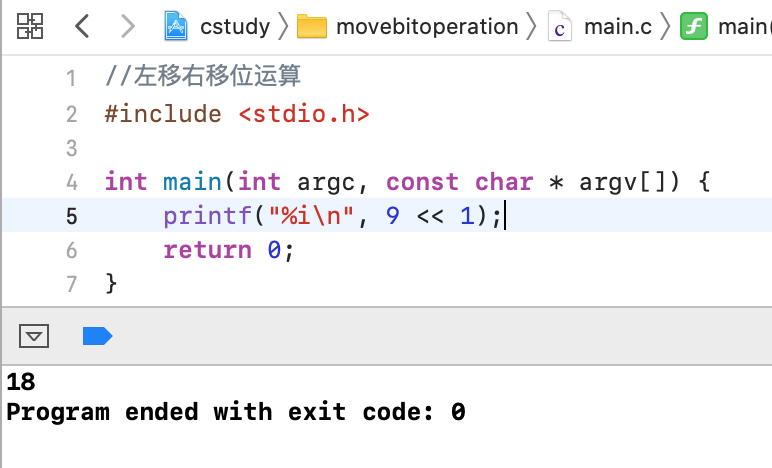
以二进制的角度来对这个左移运算进行一个分解,先将9转换成二进制如下:

接下来它要左移1位,所以此时就变为了:

此时左边高位多出的直接截掉,右边低位则用0补齐,此时就为:

此时转换成十进制就是18。
应用场景:
右移位运算符:
-
-
为正数时, 符号位为0,最高位补0
-
为负数时,符号位为1,最高位是补0或是补1
-
取决于编译系统的规定
比如:
2>>1; //相当于 2 /= 2 // 1 4>>2; //相当于 4 /= 2^2 // 1
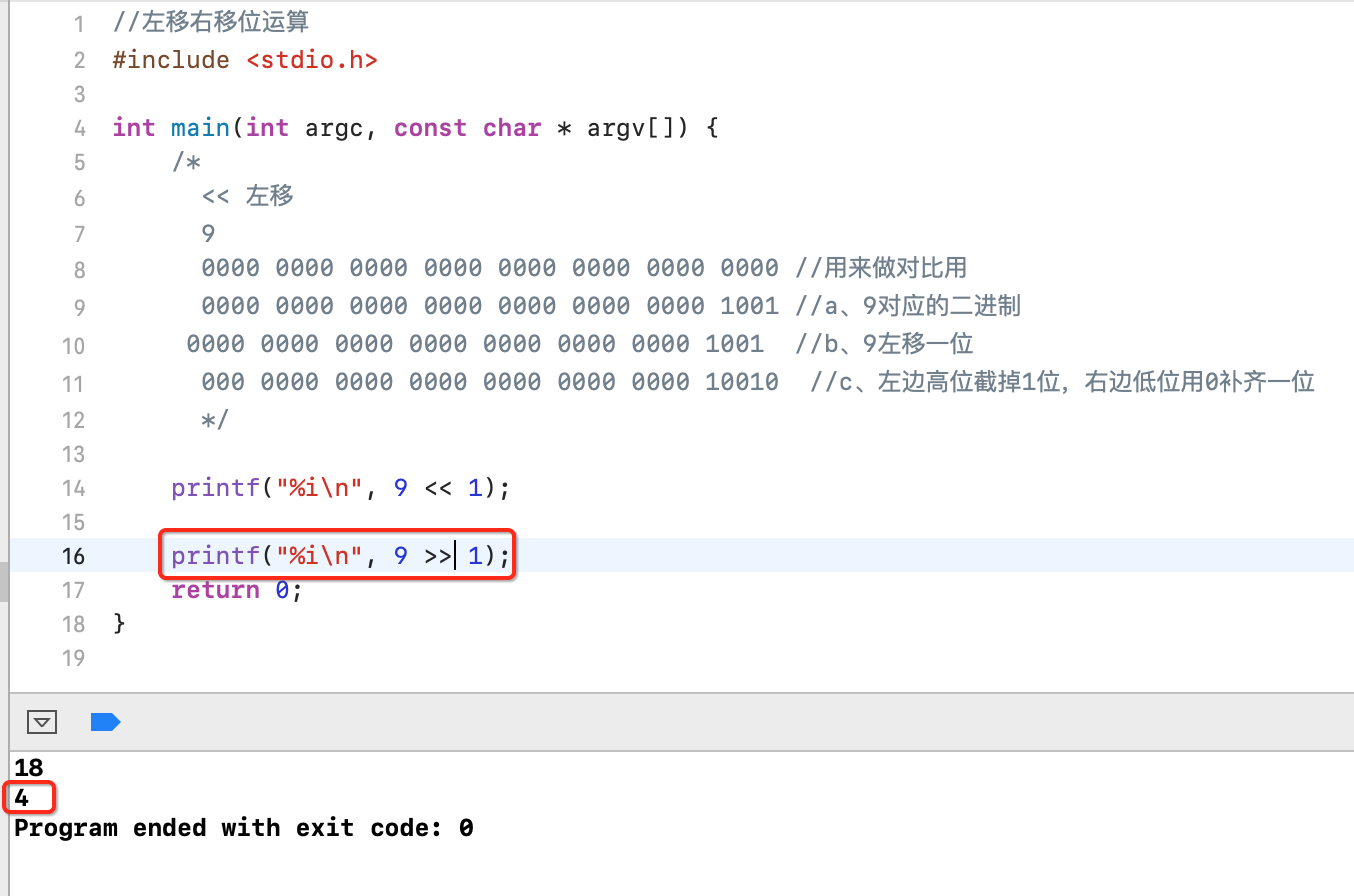
也来以二进制的角度来剖析一下:

其中右边低位多出的截掉,左边高位的补0,跟左移是相反的:

转换成十进制就是4了。
下面再来看一个负数的右移情况:
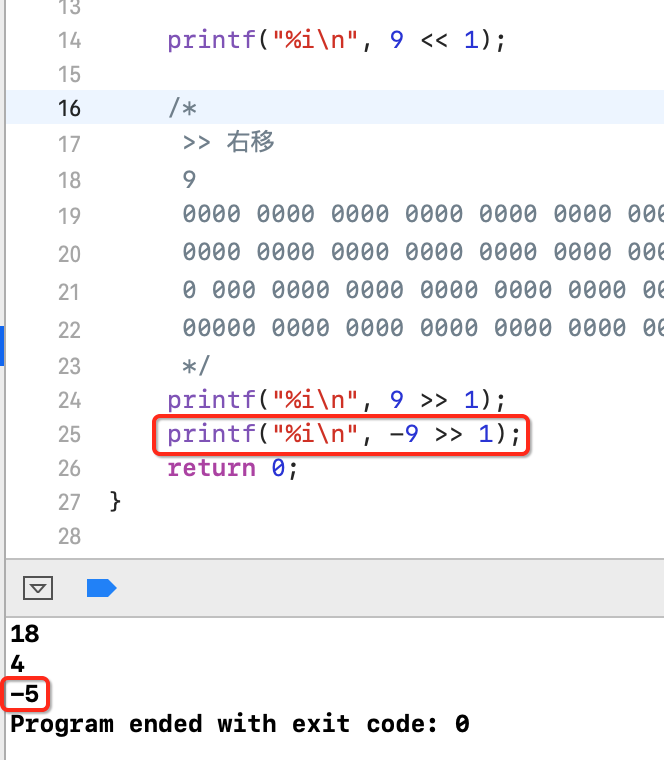
以二进制的角度来分析一下:

此时注意啦,由于负数在内存中存储的是补码,所以此时需要先将它转成补码的二进制,然后再做移位哟,这一点一定要注意,先将原码转成反码为:
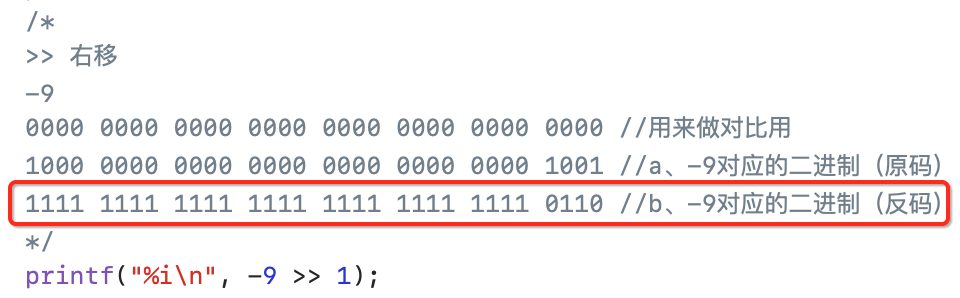
也就是原码取反,符号位不变,接下来再将反码转换成补码,让反码+1既可,如下:
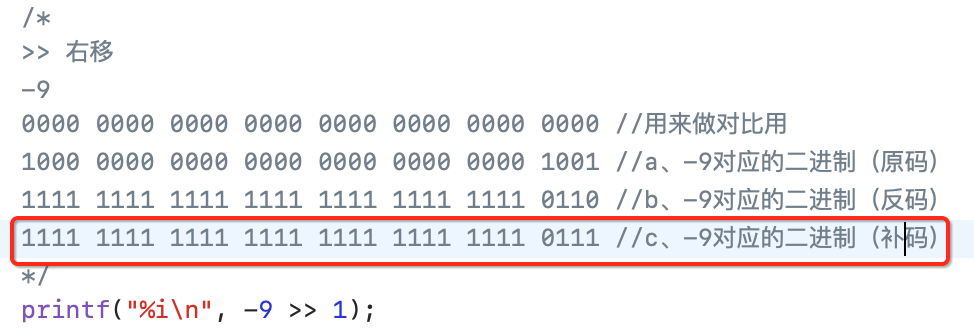
此时再进行向右移一位的操作,为:
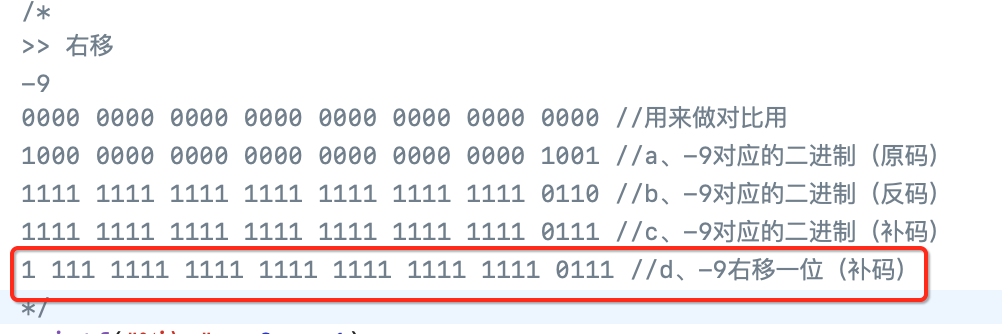
此时要注意了,高位空缺的用符号位补齐,也就是1,而右边低位的多出的直接截掉,所以就变为了:

此时要计算出结果,则又需要将补码转成原码,按照之前总结的公式:
先将其转换成反码:

再取反求得原码:

所以说,对于负数的情况就比较复杂了,还是得提前了解三码的作用才行。
应用场景:
位运算练习:
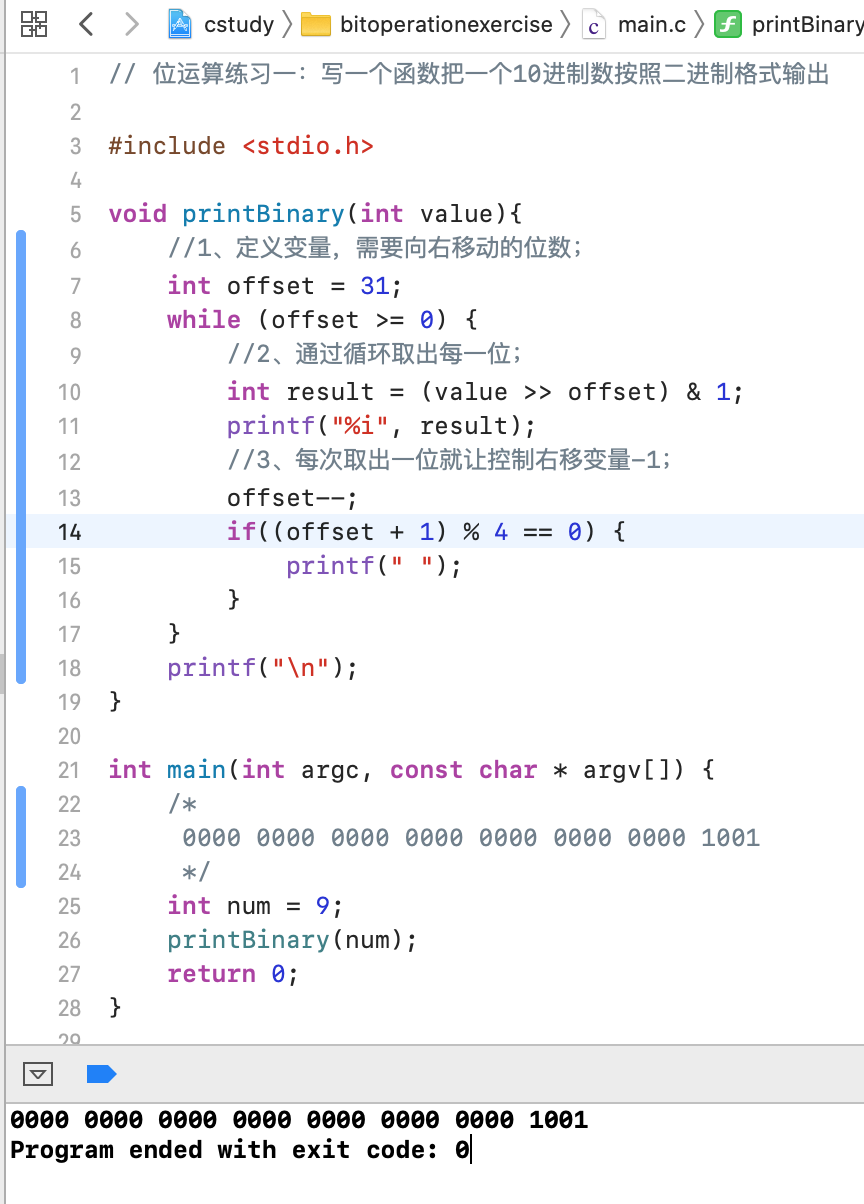
1、写一个函数把一个10进制数按照二进制格式输出:
由于C中木有直接输出二进制的方式,所以这里正好利用位运算来实现一下,先定义一下函数:

分析:
那怎么来实现呢?其实思路很简单,会用到位与运算,比如对于十进制9对应的二进制为:
0000 0000 0000 0000 0000 0000 0000 1001
而接下来就是按位来把上面的一个个打印出来就可以了,此时就可以使用&位与运算了,为了方便,每次都是从左往右进行取,所以首先这里将上面的二进制右移31位,然后再与1进行与:

此时就把9对应的二进制的第一位取出来了,0,然后输出,接下来再让9对应的二进制移30位,准备取第二位,如下:
![]()
同样的,再打印第三位,则让9对应的二进制移29位,准备取第三位,如下:

以此类推,直到0位置。
实现:
接下来则来实现一下:
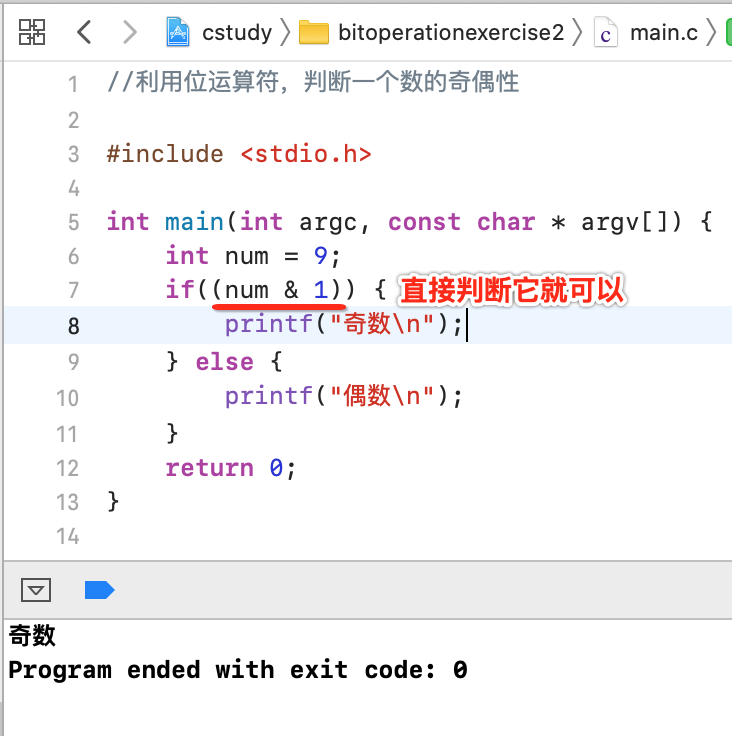
2、利用位运算符,判断一个数的奇偶性:
判断奇偶性这里有n种方法,当然这里为了操练,肯定是使用位运算了,具体如何做呢?先来观察几个数字的二进制:

其中最后一位是1的都是奇数,最后一位是0的则为偶数,所以代码可以这么实现:

有一个简化的写法:
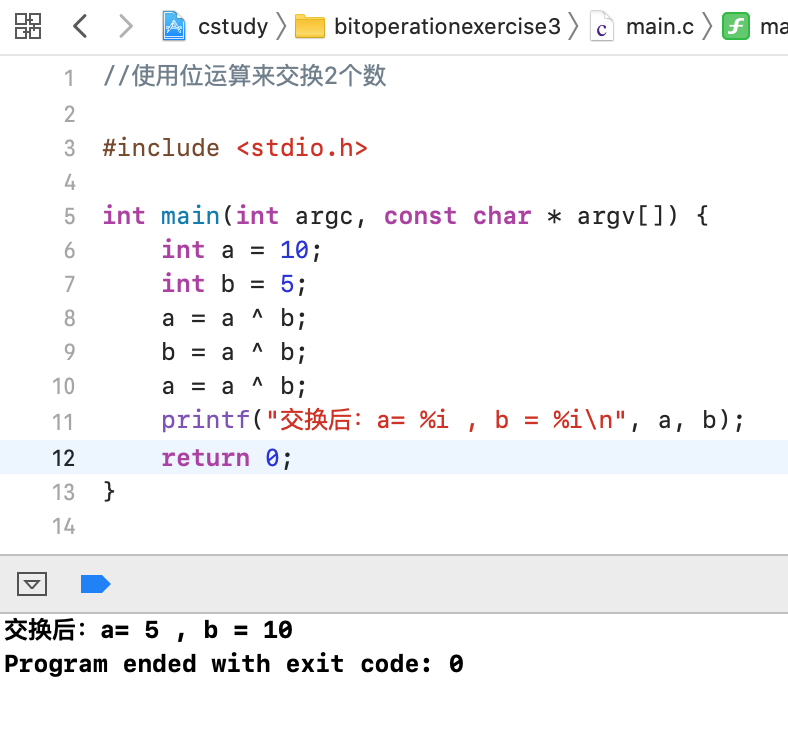
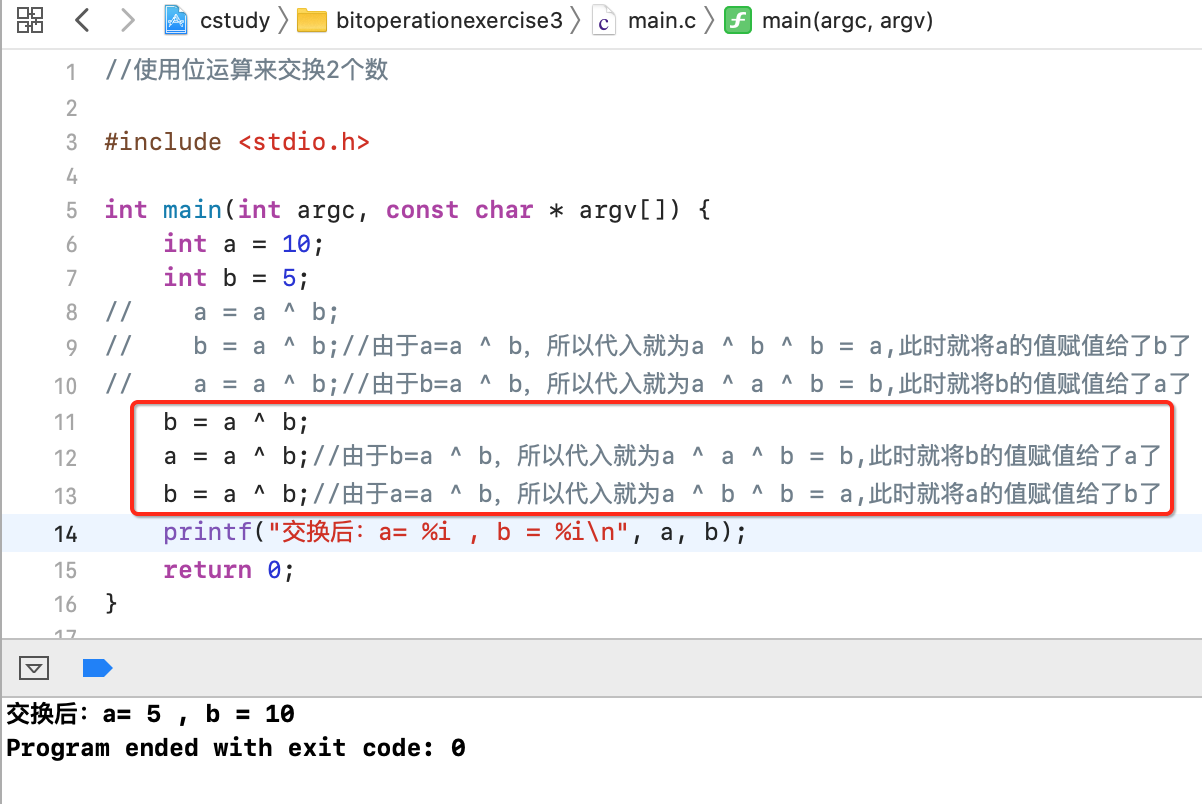
3、交换两个变量的值:
关于这个其实在https://www.cnblogs.com/webor2006/p/11408110.html学习算法时有接触过,这里再来温习一下,直接给出用位运算实现的代码:
解析一下,其实也很好理解,好理解的前提是一定要知道上面有这么个公式:
下面来看一下:
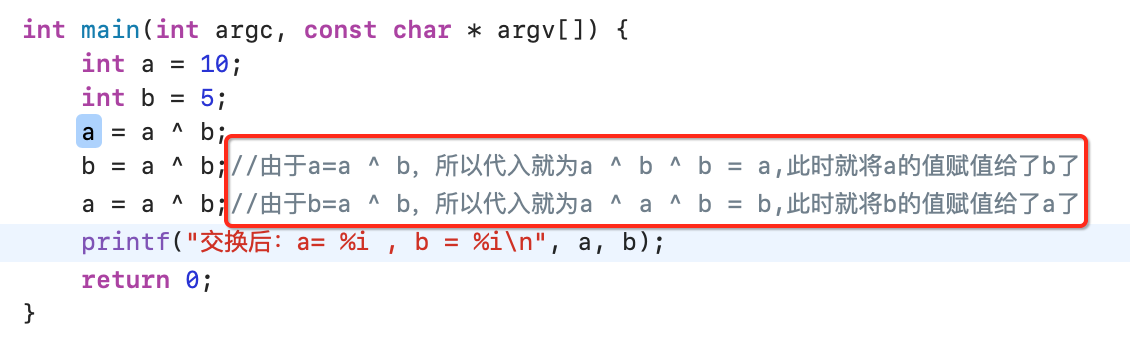
同理,这样写也可以:
4、可以进行数据加密:
这里演示一个非常简单的加密,通过异或位运算,如下:
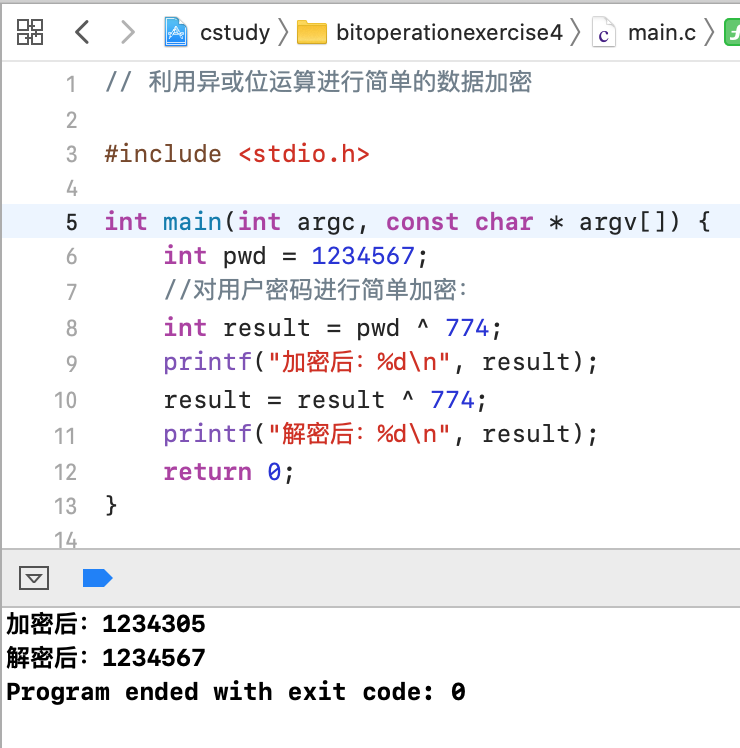
其根本原理还是它:
变量内存分析:
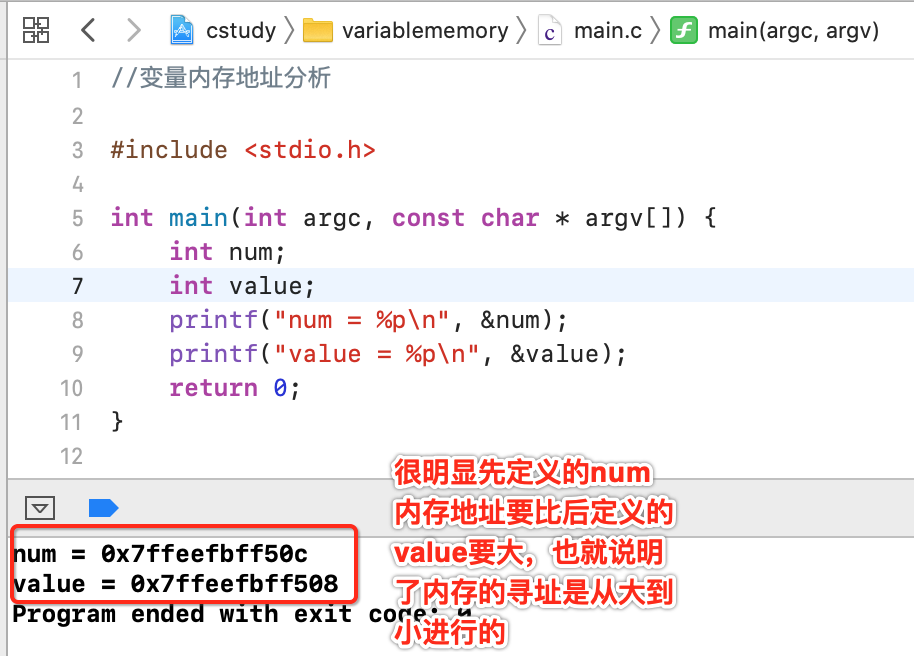
变量内存寻址:
-
因为内存寻址是由大到小,所以先定义的变量的内存地址会比后定义的大。
关于这块其实在上一次https://www.cnblogs.com/webor2006/p/13468408.html已经详细分析过了。下面可以定义两个变量,打印一下地址就可以清楚的看到内存寻址是由大到小的,如下:
变量内存存储:
既然变量内存的寻址是从大到小的顺序进行的,其实它的存储也是按从高位到低位的顺序存储的,比如要存一个变量9:
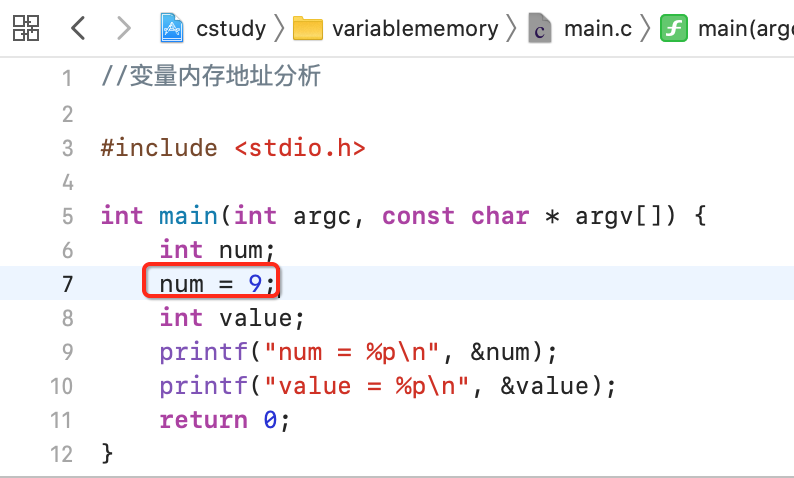
内存中存储的是变量二进制的补码,由于9是正数,所以三码合一,也就是内存中存储的二进制为:“00000000 00000000 00000000 00001001”,那么它存到内存中是按二进制从左到右的顺序存还是从右到左呢?答案是从左到右,因为左是二进制的高位,而右是二进制的低位,用一个形象的图来表示就是:
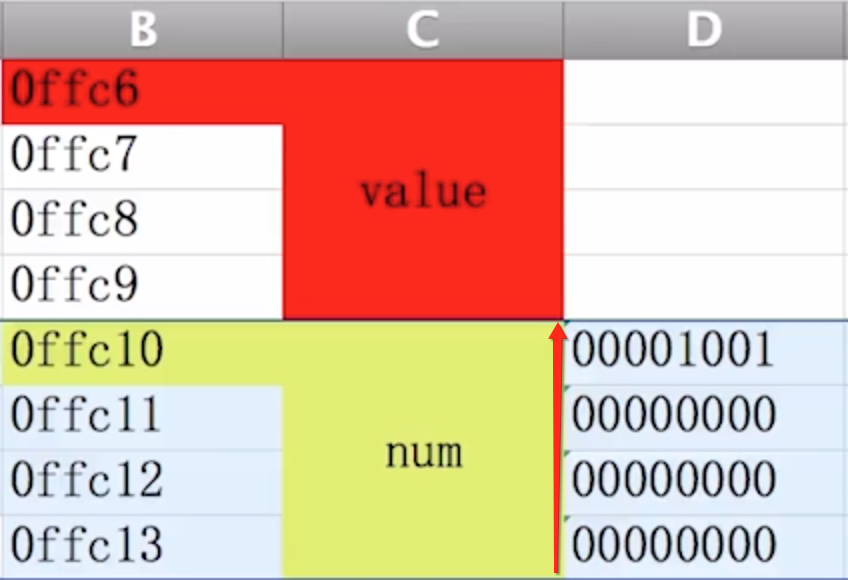
那怎么用代码来验证咱们所分析的呢?下面看代码:
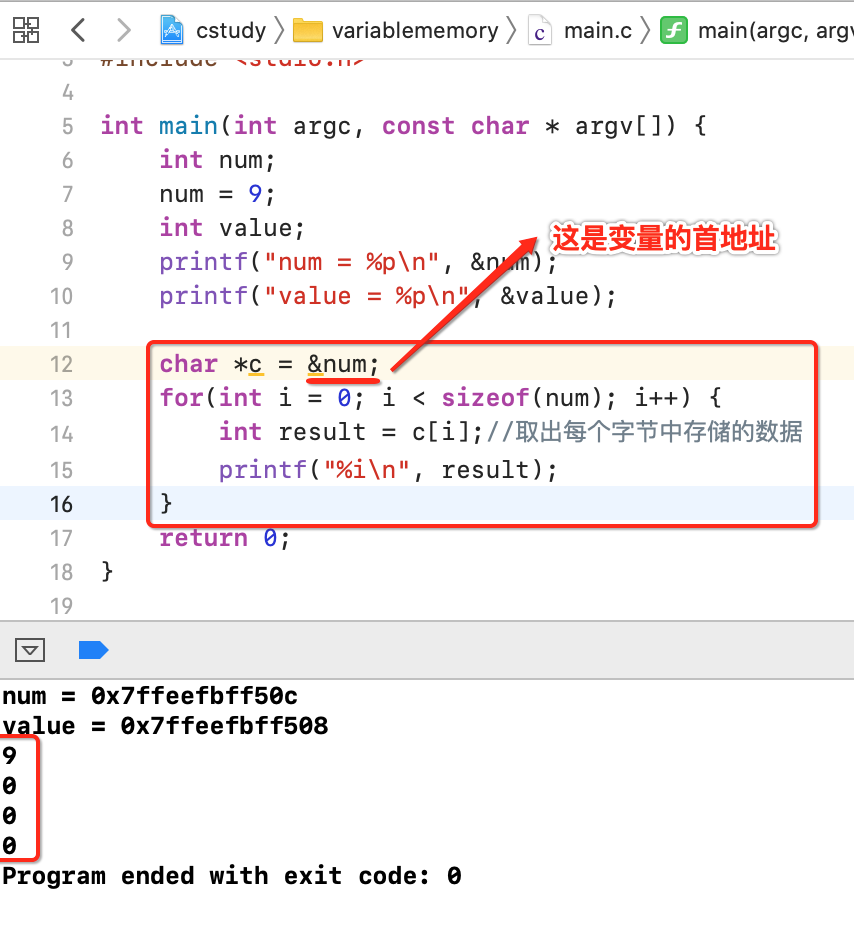
而回到图中验证,刚好也符合:

确实是按从高到低的顺序进行存储的。
char类型:
存储原理:
这里定义一个char:
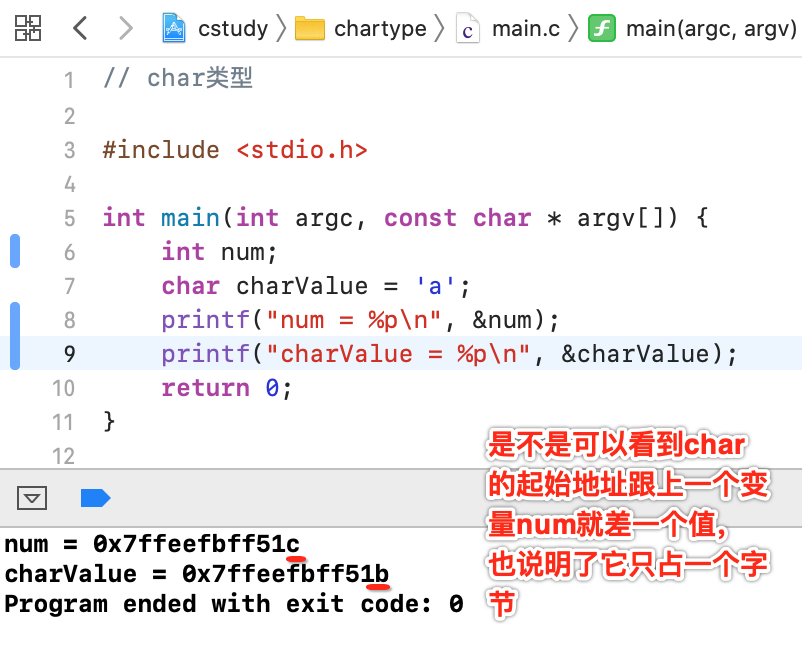
对于它的使用就不多说了,比较简单,主要是研究一下它是如何存储的,我们都知道它是占1个字节,那从内存寻址上来验证可以是:
这是占用空间大小问题,另外还有一个就是目前的charValue赋值的是'a',那它在计算机中是如何存储的呢?当然是存的二进制呀,是的,那'a'对应的二进制又是多少呢?此时熟知的ASCII码表就出来了:
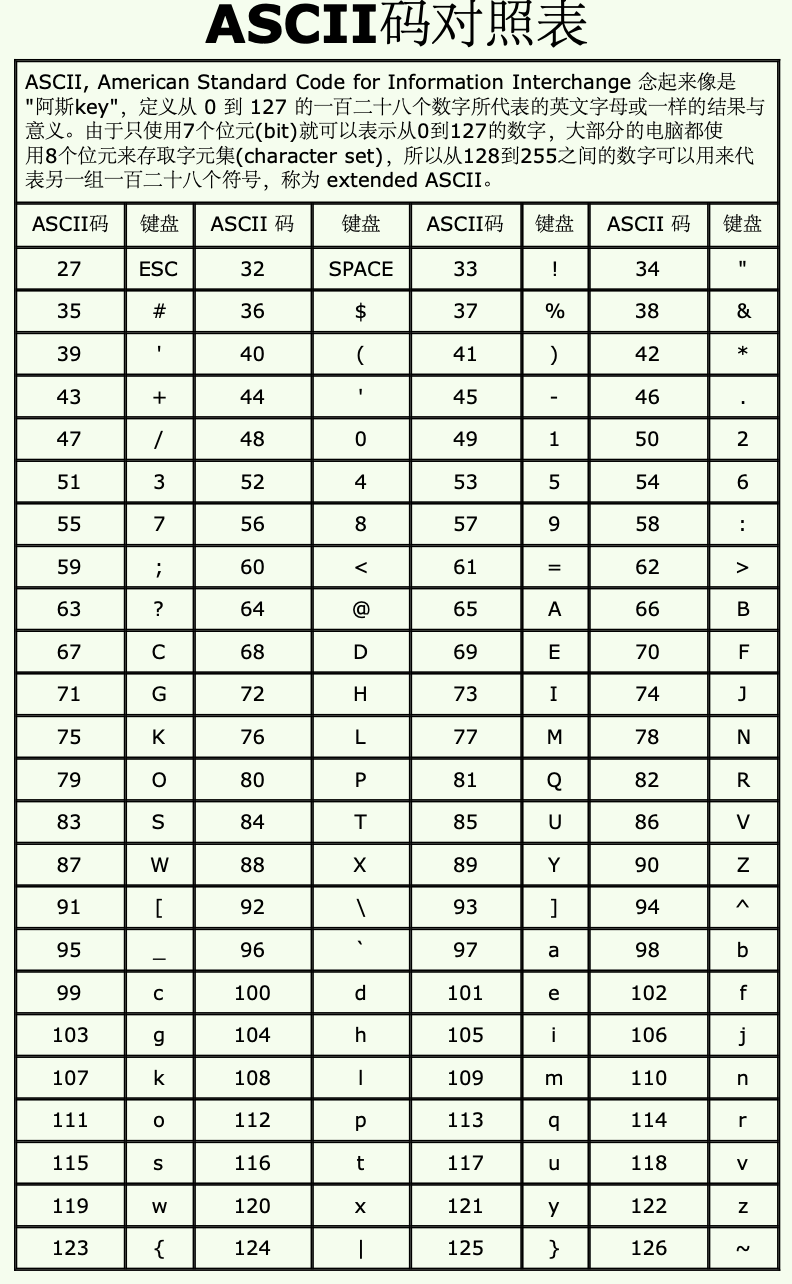
回到咱们所要解决的问题上来,‘a’在ASCII表中对应:
![]()
也就是内存当中存储的其实就是97所对应的二进制,也就是char的本质还是整型【这就是在之前学习算术运算符时提到过char类型会自动提升为int类型的原因之所在】,所以对于此char类型的值存储就是将97转换为二进制为:00000000 00000000 00000000 01100001,注意:此时因为它只占一个字节,所以应该是01100001,下面用程序来验证一下:
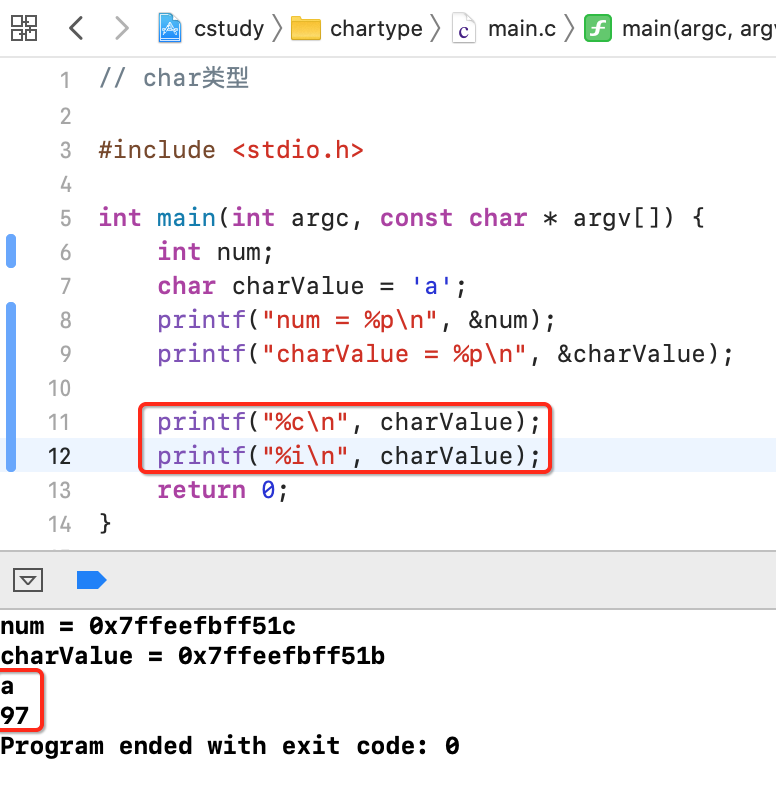
下面再来看一个代码:
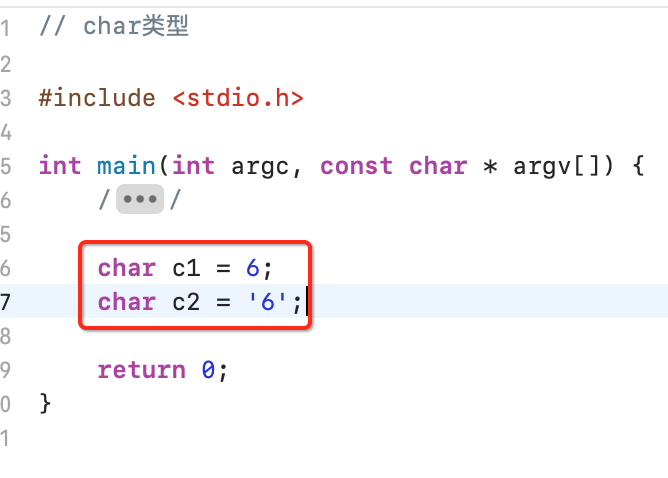
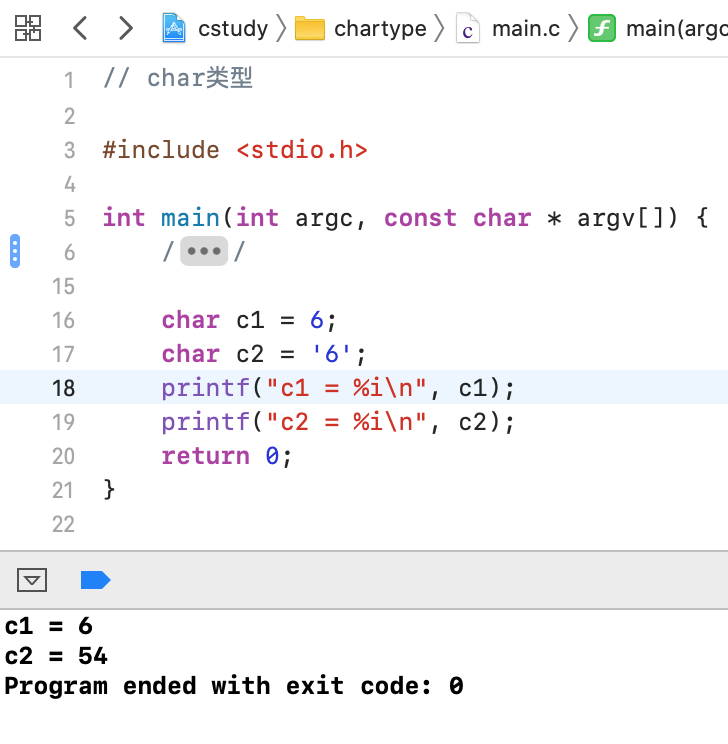
这俩是一样的么?很显然不是一样的,第一个代表数字6,内存存储的二进制为00000110,第二个代表字符6,而字符6对应的ASCII表中数字为:
![]()
所以它在内存存储的二进制为00110110,下面打印一下就知道了:
char当整型用的注意事项【了解】:
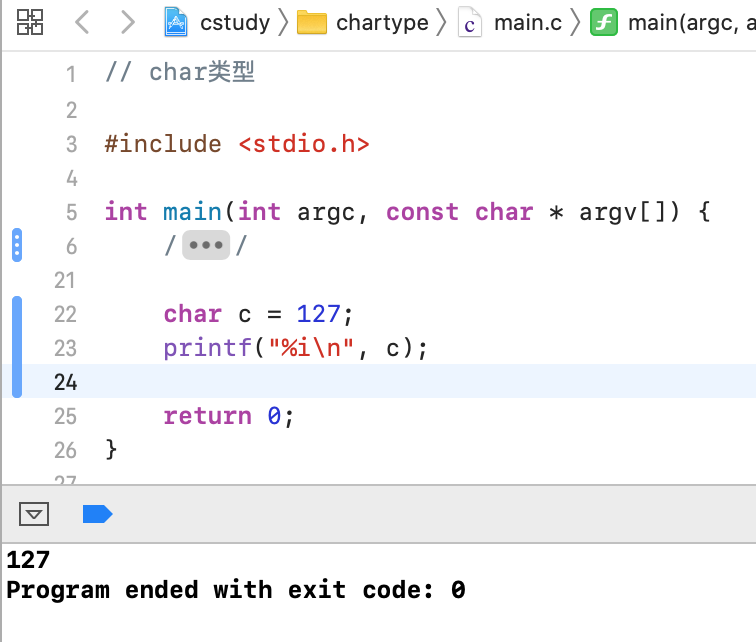
这样有啥意义呢?省内存呀,如果对内存要求特别严格,而且需要存储的整数不超过char类型的取值范围就可以用char类型来表示【不过如今的内存都很大,所以对于这种用法实际比较少,有个了解既可】,那如果超过范围了会怎样呢?试一下:
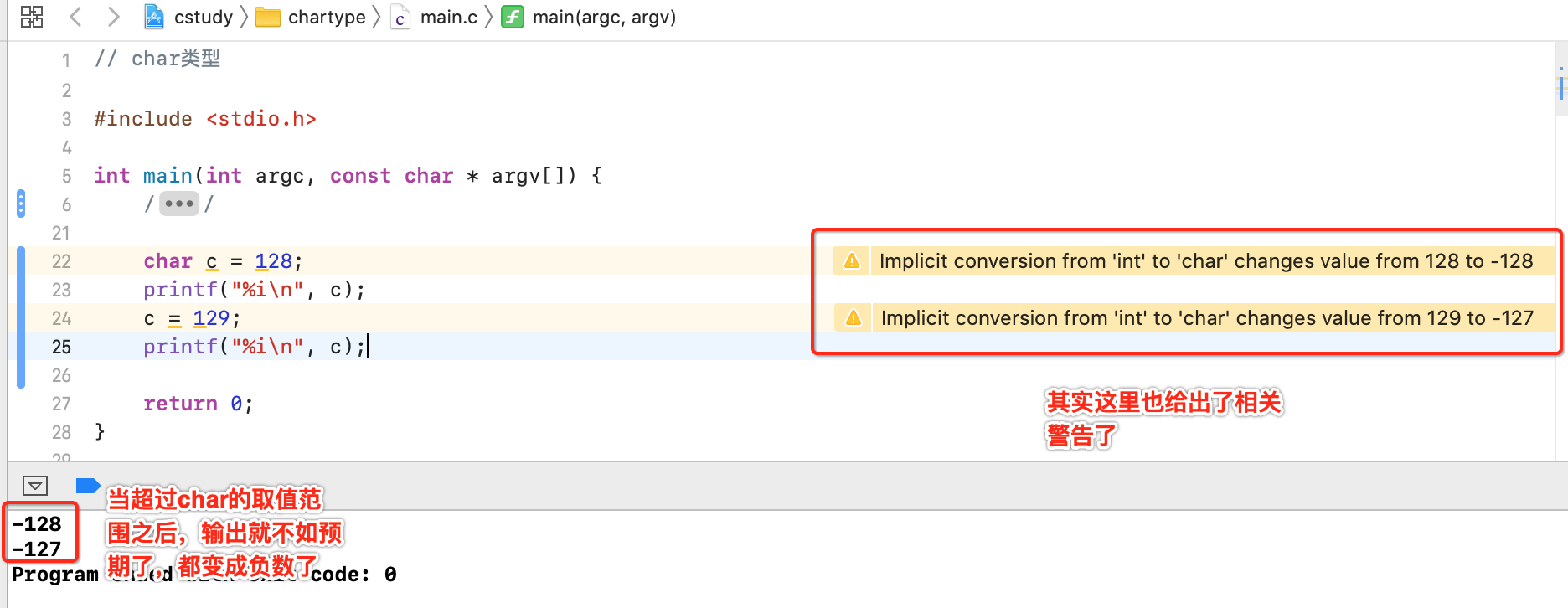
128超过取值范围之后为啥显示的是负数呢?可以将128转成二进制瞅一下为:101000,其中高位是不是1,就转为负数了。
练习:
接下来小练一下char,要求:a ....z 对应ASCII表中的值97...122,而A 65和a 97 差了32,所以如果输的值不是小写,则加上这个差值就可以了,所以实现也比较简单了,如下:
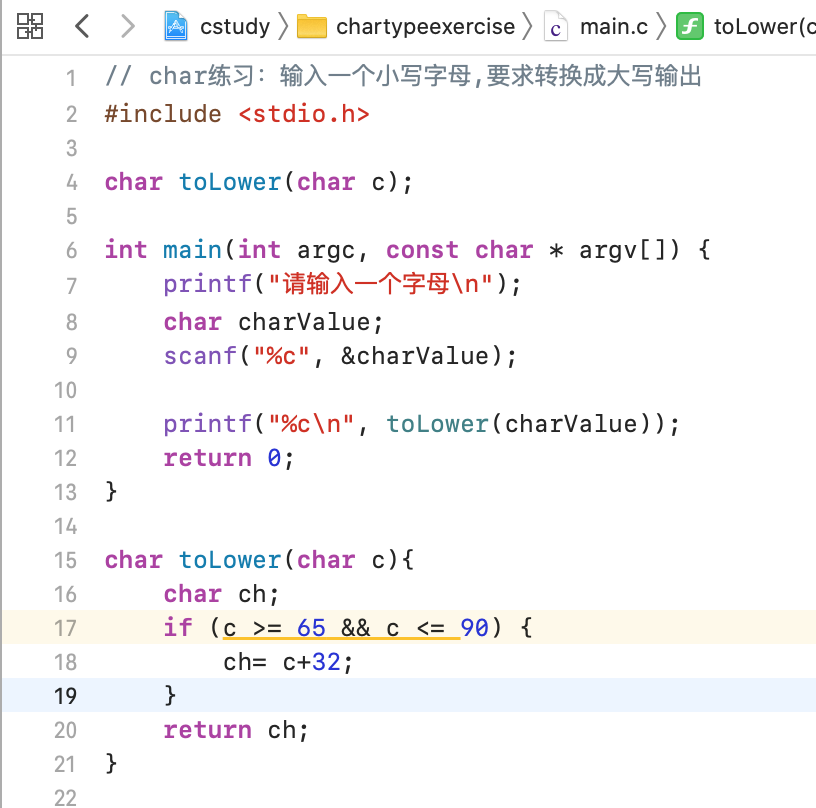
运行:
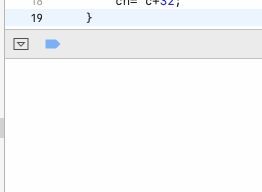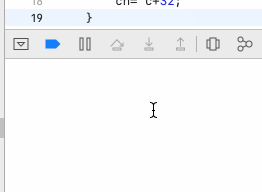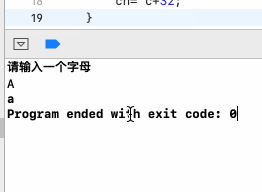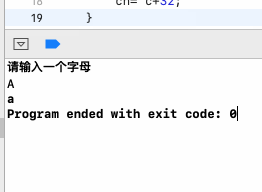
不过目前这代码需要优化一下,出现了魔鬼数字:


另外差值32也可以改一下:

类型说明符:
基本概念:
short 短型 等价于 short int
long 长型 等价于 long int
long long,等价于long long int
signed 有符号型:
unsigned 无符号型:
这些说明符一般就是用来修饰int类型的,所以在使用时可以省略int。
short和long:
-
-
在64bit编译器环境下,int占用4个字节(32bit),取值范围是-2^31~2^31-1;
-
short占用2个字节(16bit),取值范围是-2^15~2^15-1;
-
long占用8个字节(64bit),取值范围是-2^63~2^63-1
-
-
总结一下:在64位编译器环境下:
-
short占2个字节(16位)
-
int占4个字节(32位)
-
long占8个字节(64位)。
-
因此,如果使用的整数不是很大的话,可以使用short代替int,这样的话,更节省内存开销。
-
-
世界上的编译器有很多,不同编译器环境下,int、short、long的取值范围和占用的长度又是不一样的。比如在16bit编译器环境下,long只占用4个字节。不过幸运的是,ANSI \ ISO制定了以下规则:
-
short跟int至少为16位(2字节)
-
long至少为32位(4字节)
-
short的长度不能大于int,int的长度不能大于long
-
char一定为为8位(1字节),毕竟char是我们编程能用的最小数据类型
-
-
可以连续使用2个long,也就是long long。一般来说,long long的范围是不小于long的,比如在32bit编译器环境下,long long占用8个字节,long占用4个字节。不过在64bit编译器环境下,long long跟long是一样的,都占用8个字节。
-
long long int等价于long long
-
下面回到代码中来看一下,比如定义一个正常的int:
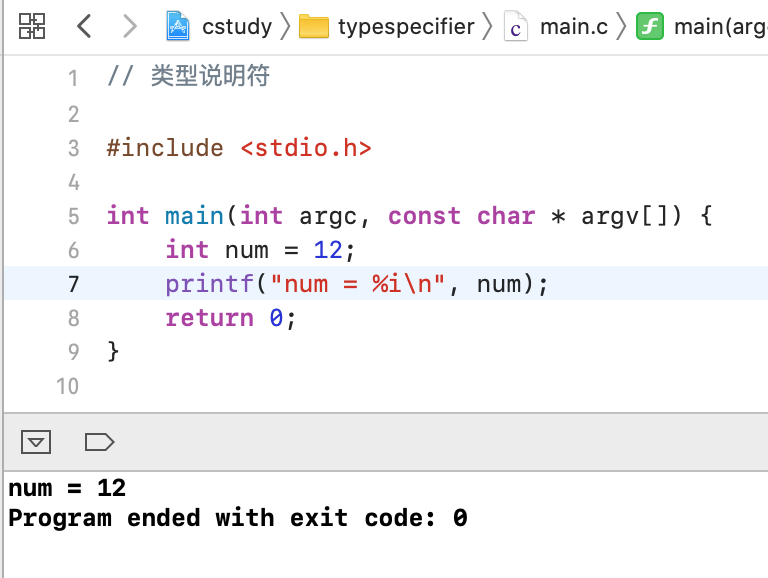
那如果定义一个超出范围的数呢?输出肯定就不正常了:
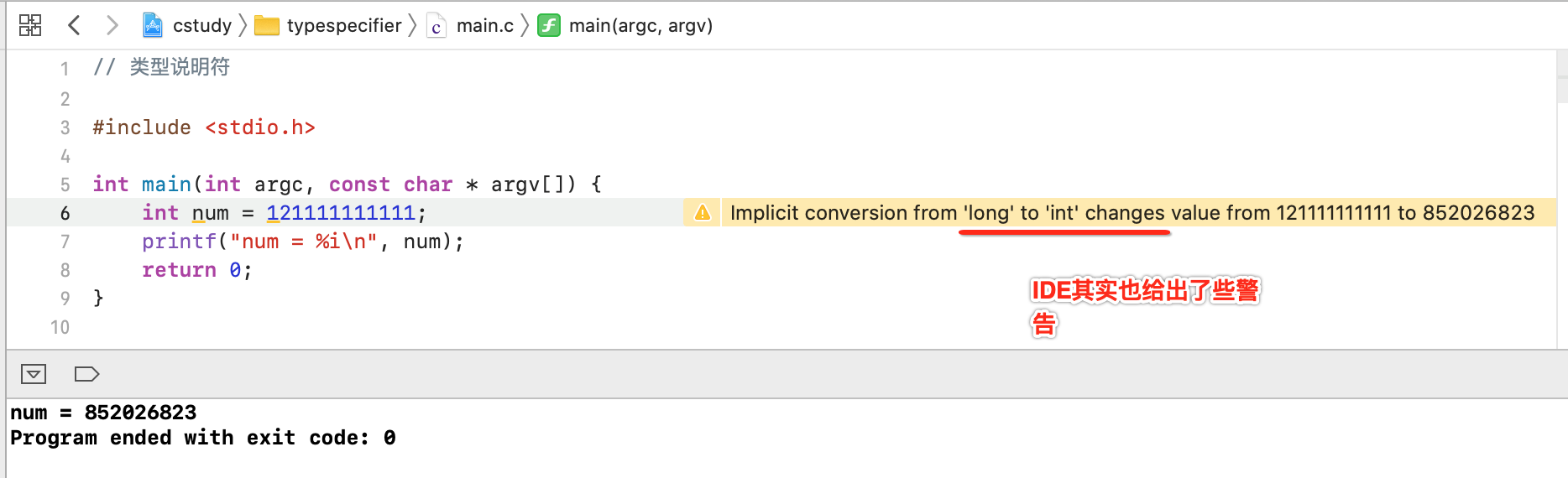
此时就可以将其改为容纳范围更广的long类型,如下:
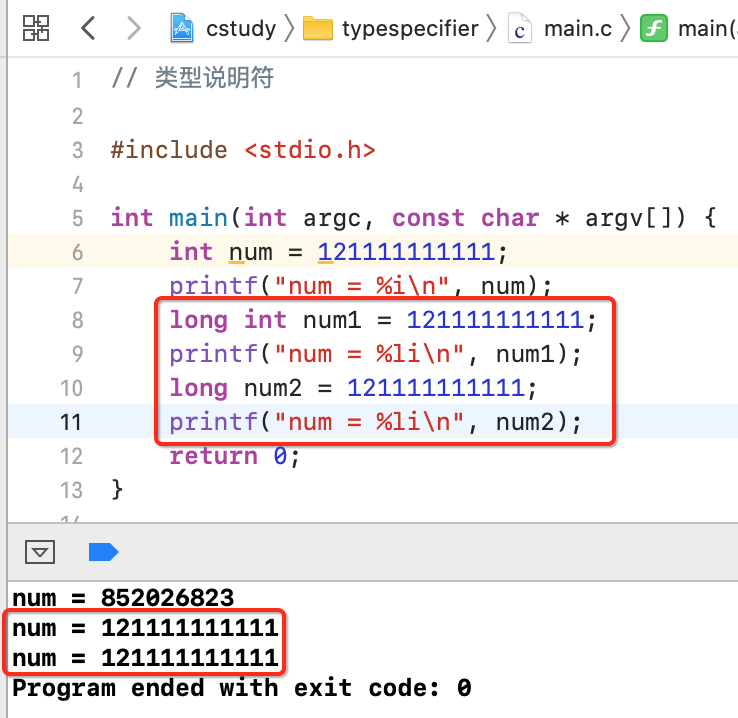
当然用long long也可以容纳:
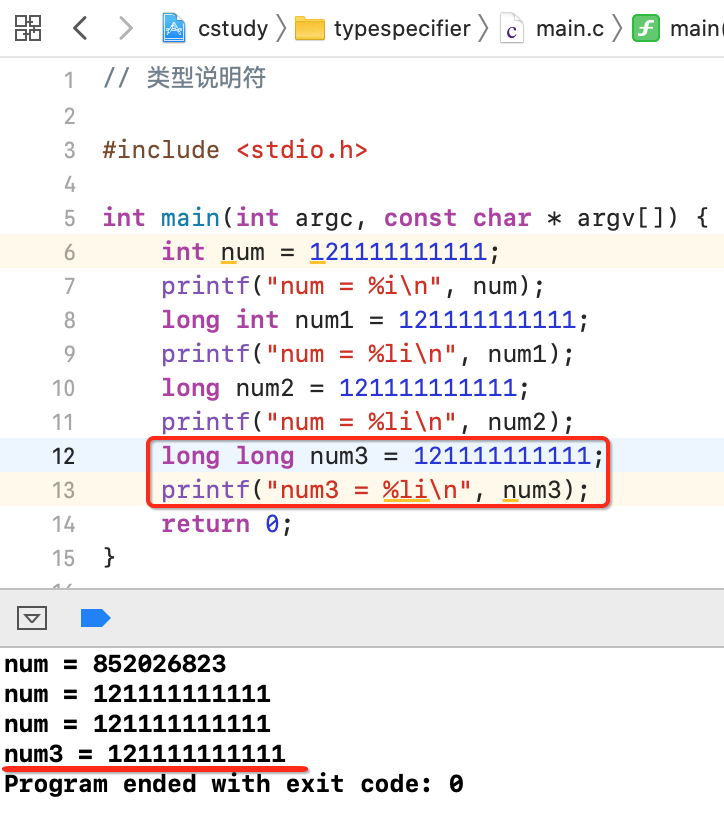
那long和long long的区别就是在不同cpu编译器下位数是不一样的,如上也描述了:"在32bit编译器环境下,long long占用8个字节,long占用4个字节。不过在64bit编译器环境下,long long跟long是一样的,都占用8个字节。",那下面用程序来验证一下:
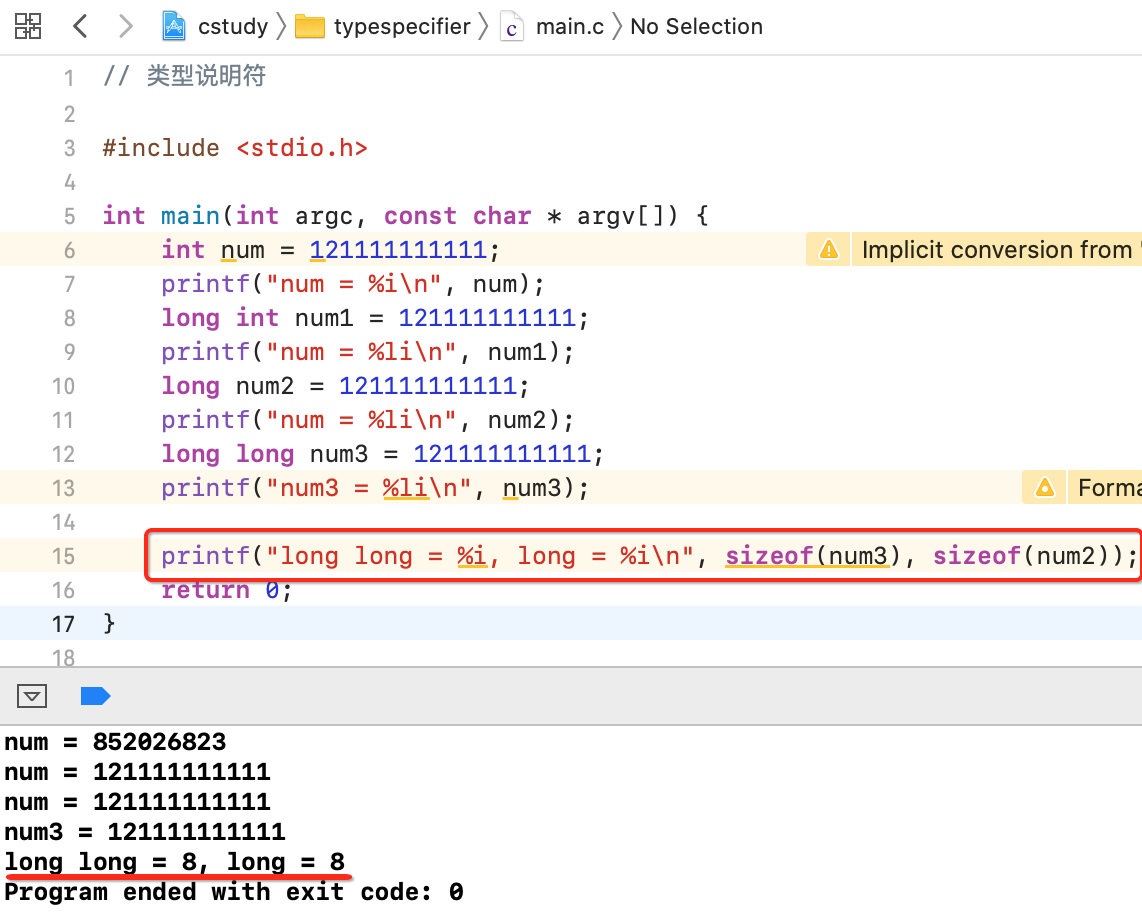
这因为是在64位编译器下运行的,怎么能看出是在64位编译器下呢?其实在项目设置这块可以看到:
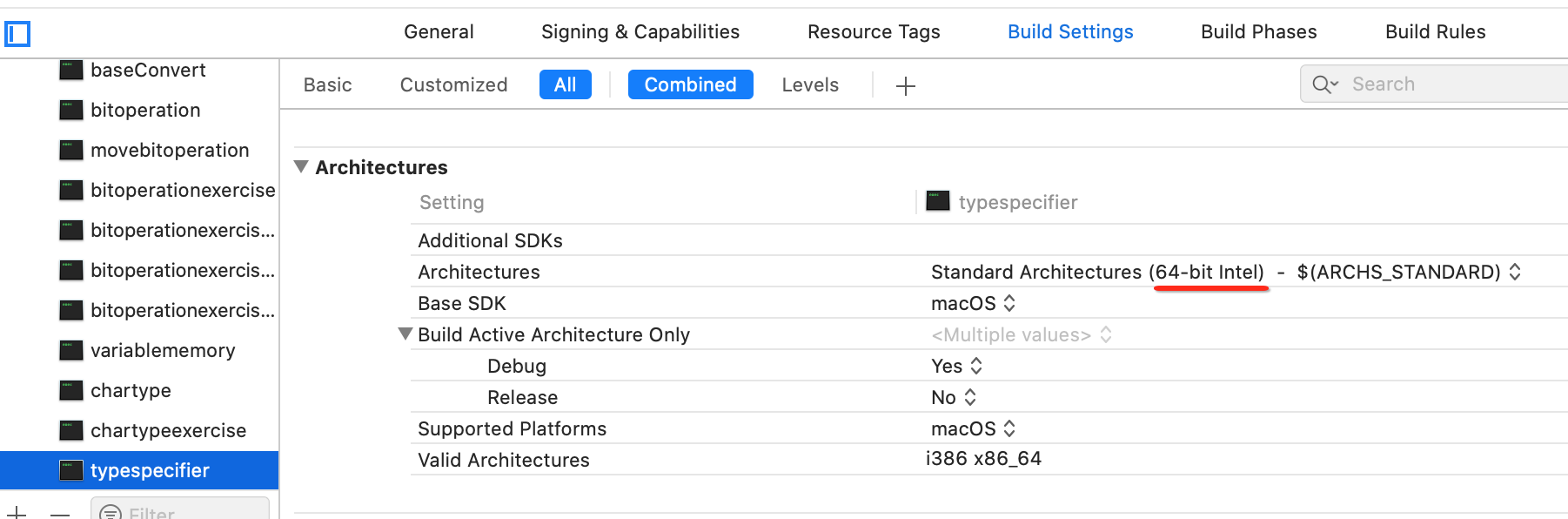
那如果切成32位再运行呢?其实是在这个选项中进行更改的,具体方法可以度娘,我本机的xcode还不能更改,这块比较好理解就不演示了。
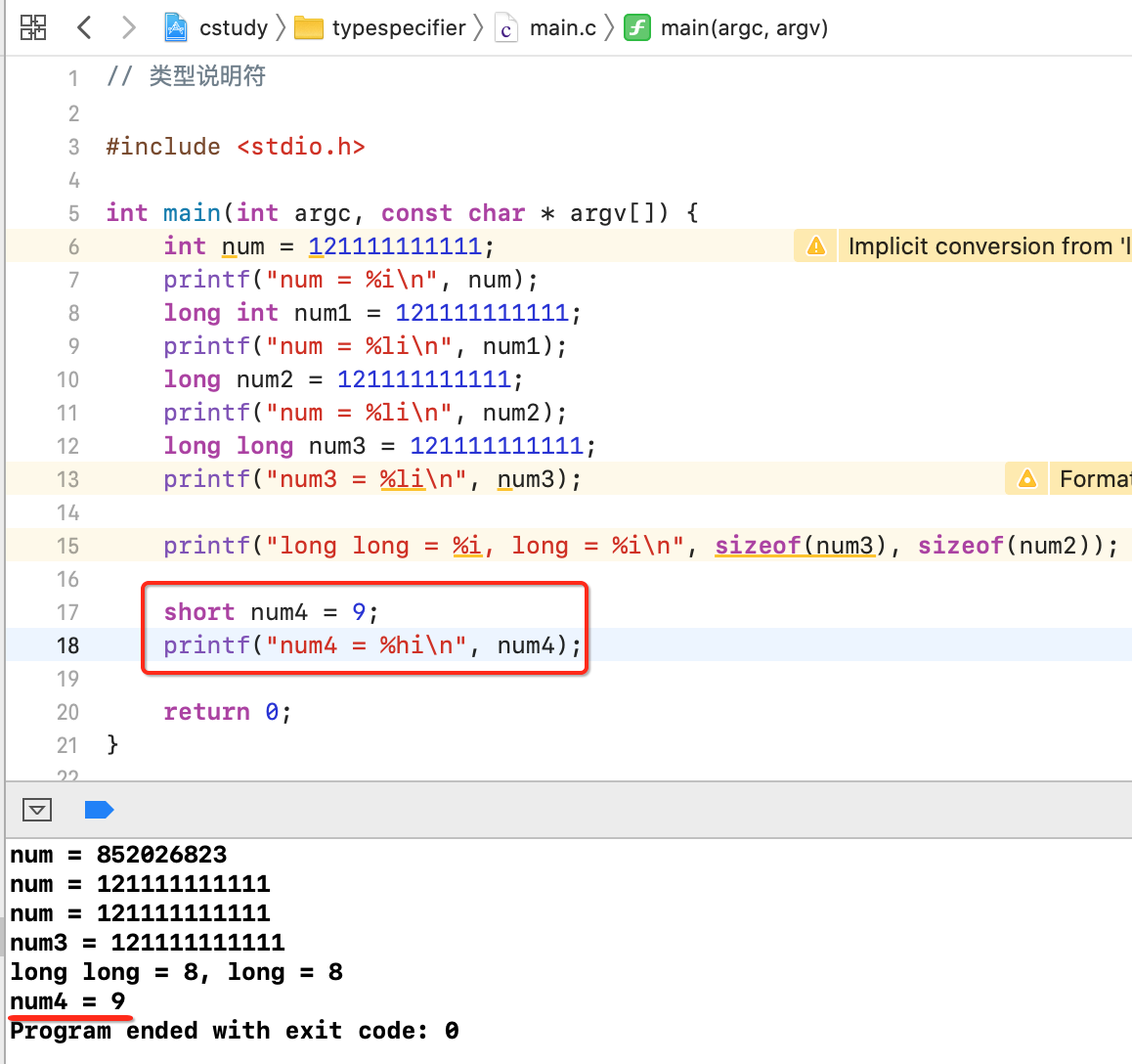
最后是有一个short,它是占2个字节,更加节省内存,而它的输出是用的hi,如下:
signed和unsigned:
-
-
signed和unsigned的区别就是它们的最高位是否要当做符号位,并不会像short和long那样改变数据的长度,即所占的字节数。
-
signed:表示有符号,也就是说最高位要当做符号位,所以包括正数、负数和0。其实int的最高位本来就是符号位,已经包括了正负数和0了,因此signed和int是一样的,signed等价于signed int,也等价于int。signed的取值范围是-2^31 ~ 2^31 - 1
-
unsigned:表示无符号,也就是说最高位并不当做符号位,所 以不包括负数。在64bit编译器环境下面,int占用4个字节(32bit),因此unsigned的取值范围是:0000 0000 0000 0000 0000 0000 0000 0000 ~ 1111 1111 1111 1111 1111 1111 1111 1111,也就是0 ~ 2^32 - 1
-
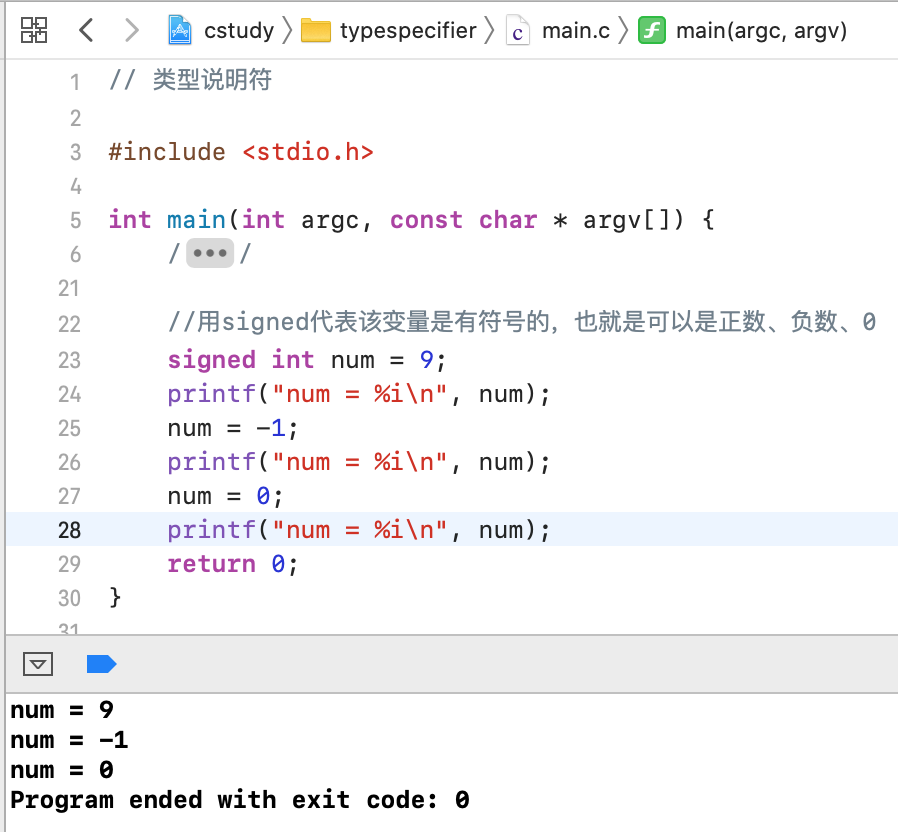
默认定义的变量都是有符合的,接下来重点就是看无符号的,它只能表示正数和0,如下:
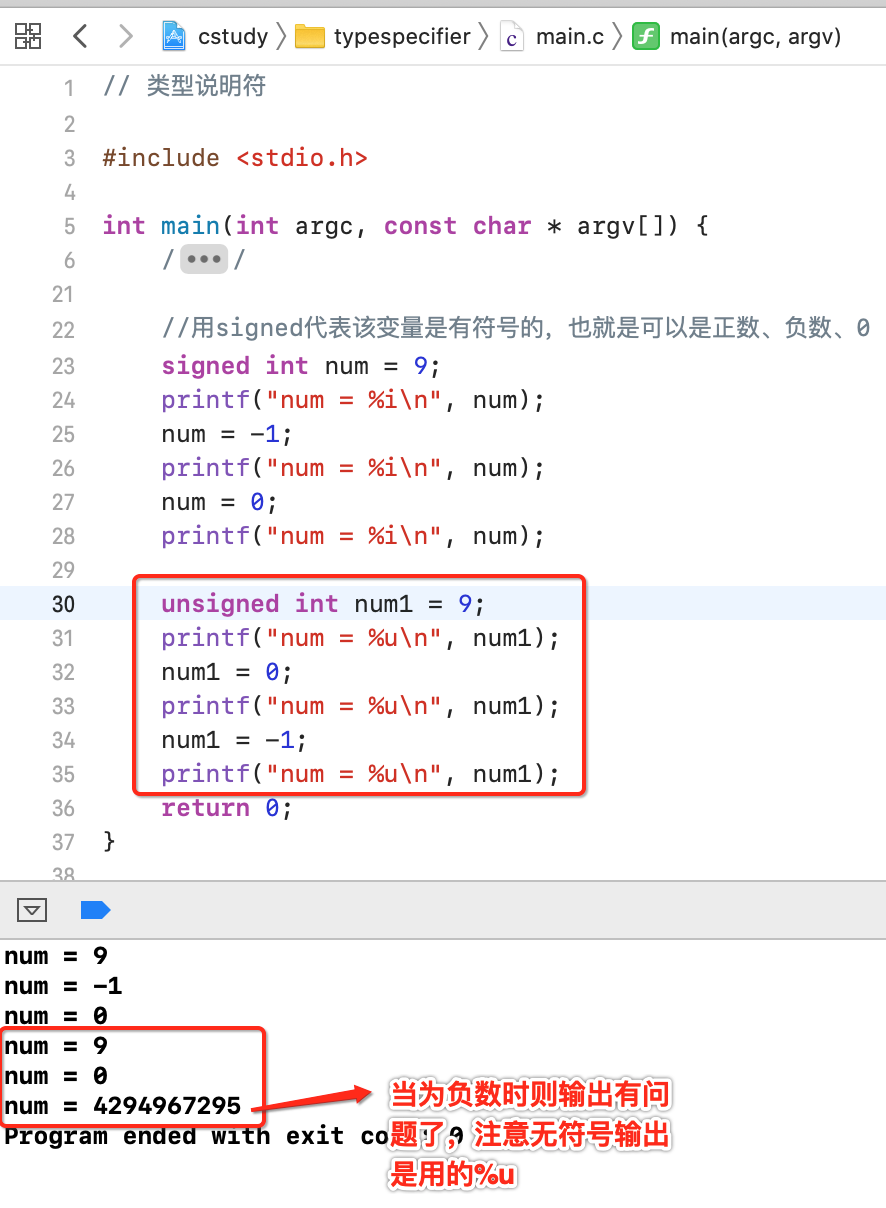
如果实际场景中你的数字不希望是负数,则可以将它定义成无符号的,既然没有符号,相比有符号的int很显然它能表示的范围更加的广。
混合使用:
既然类型说明符有两大类:表示长度和表示符号的,这俩也可以混合使用,比如:
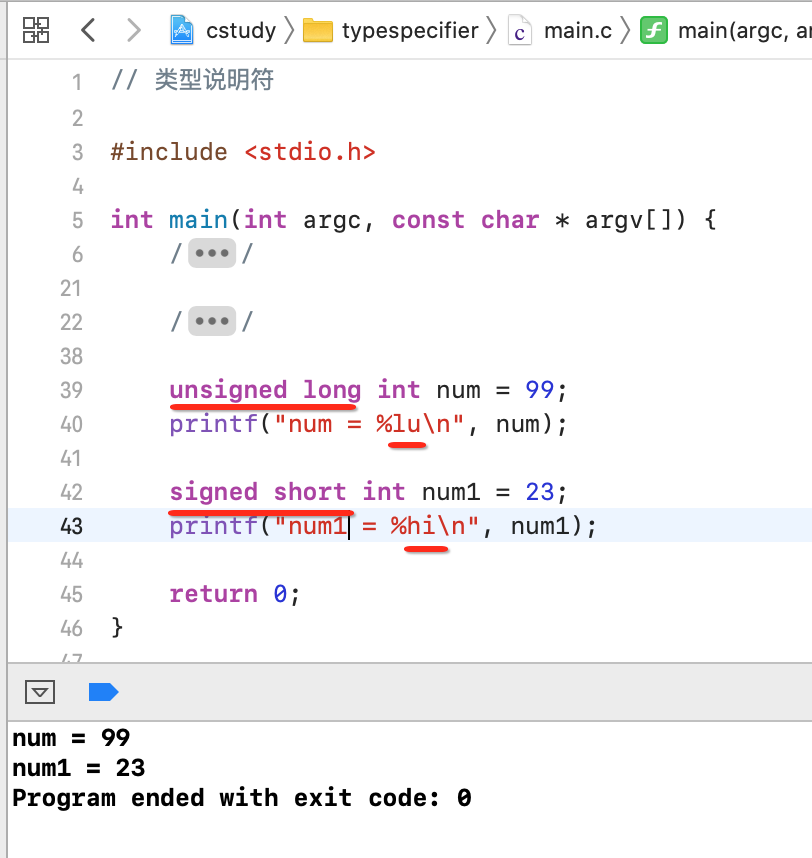
同一类型是不可以一起使用的,比如:

总结:
篇幅有限,这里先来个总结,本想通过这次将C的基础给收尾,但是学着学着发现细节还挺多,所以争取下篇搞定C基础,然后开启OC的学习,当然目前的这些超级基础的知识貌似学着有点浪费时间,还是那句话,人生漫漫,享受其过程,反正也不靠它挣钱~~

