
算法与数据结构基础<二>----排序基础之选择排序法
最简单的排序算法:选择排序法:
在上一次https://www.cnblogs.com/webor2006/p/13914100.html来了个算法的开篇,介绍了线性查找法的简单算法,这次继续夯实基础,而排序就是算法中非常基础又非常重要的算法,如题所示,这里先来学习最最简单的排序算法----选择排序。
思想:
它的排序思想比较简单:

过程分析:
对于它的实现其实是有两种,咱们先来看一下这两种的实现过程,基本这块都比较熟了,就当复习巩固。这里以如下整型数组为例进行分析:

实现方案一:借助临时数组
1、找最小的元素:

然后将这个元素放到一个新数据中:

2、从剩下的元素中还是找最小的元素:

将其放到新数组中:
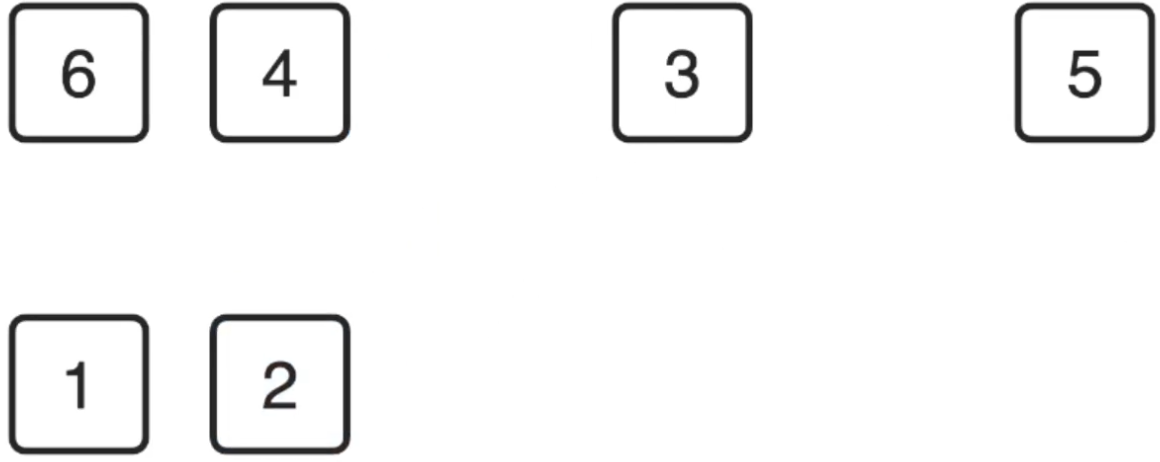
3、继续找最小的元素:
![]()
往新数组放:
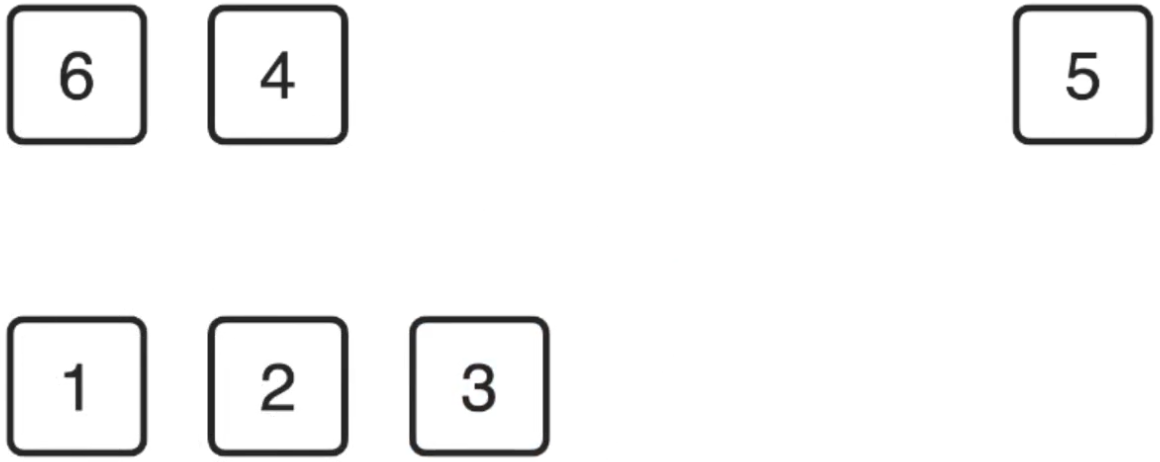
4、继续找最小的元素:
![]()
放:
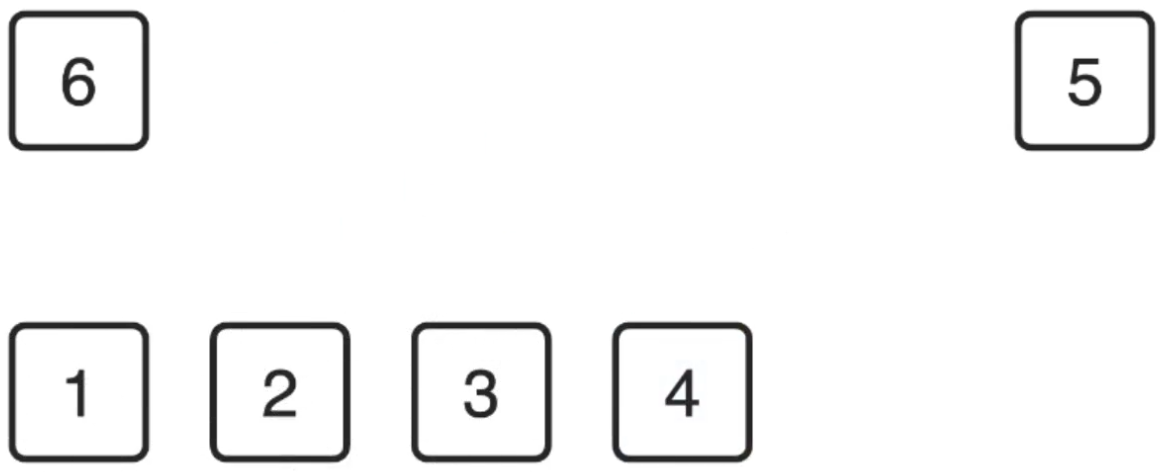
5、
![]()
放:
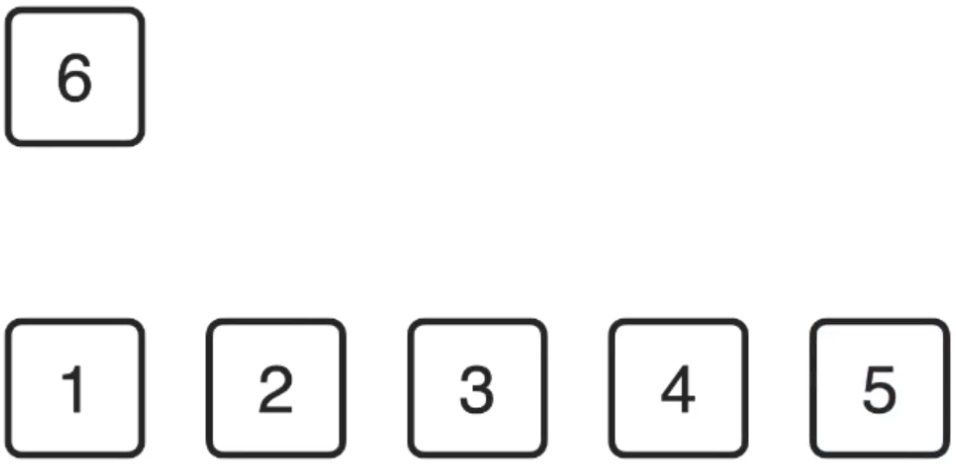
6、还剩最后一个元素,整个排序完成:

放:

对于这种排序实现可以看出会占用一个额外数组空间:
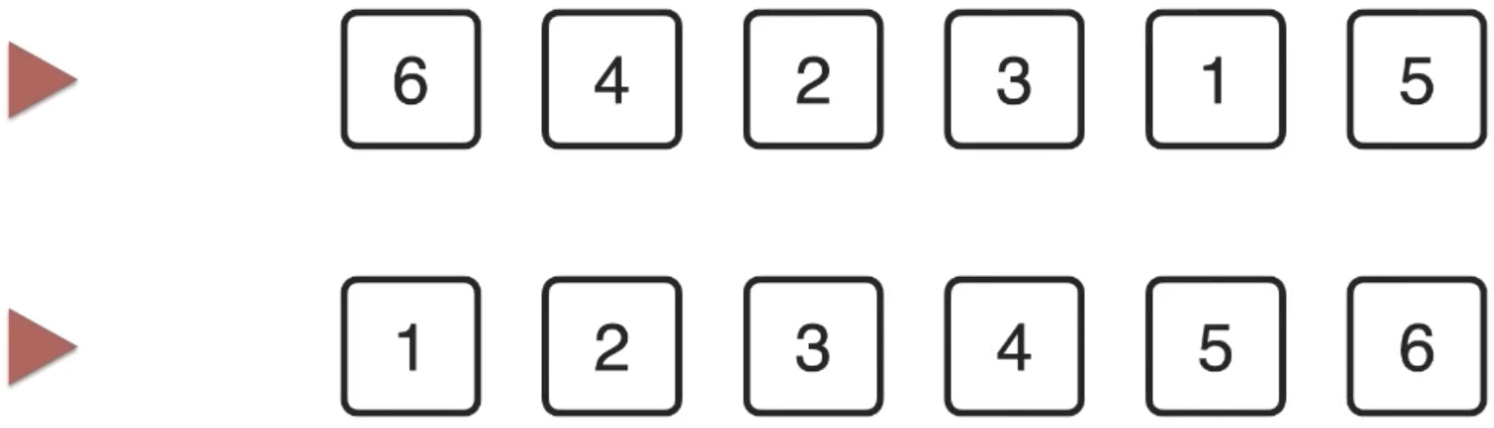
那有木有一种实现方式不额外申请空间也能达到同样的效果呢?其实在算法中这种思想可以称为“原地排序”,在未来的算法学习中也可以看到很多的算法可以实现原地排序,有些是必须借助额外空间才行的,对于咱们这种算法妥妥的是可以进行原地排序的,下面走起。
实现方案二:不借助临时数组原地排序
还是对于这样一个数组:

1、当前元素为第0个:
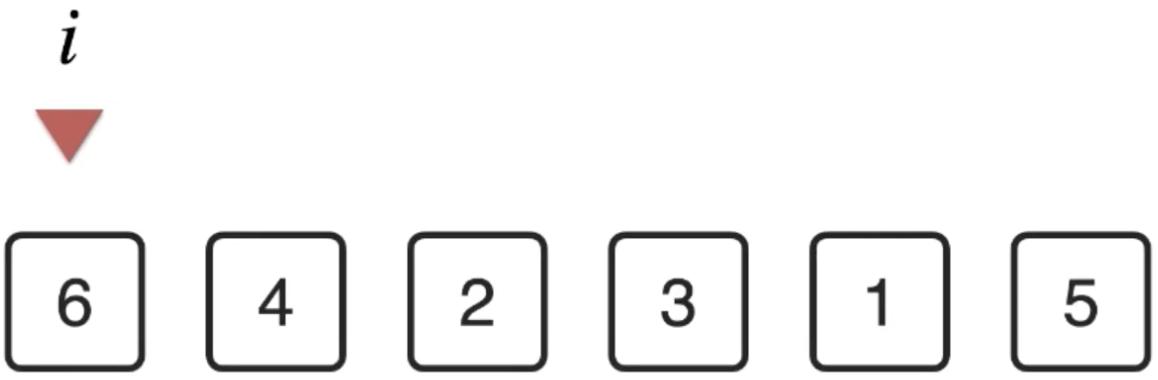
接下来从数据元素中找到一个最小的元素,此时得借助另一个下标:
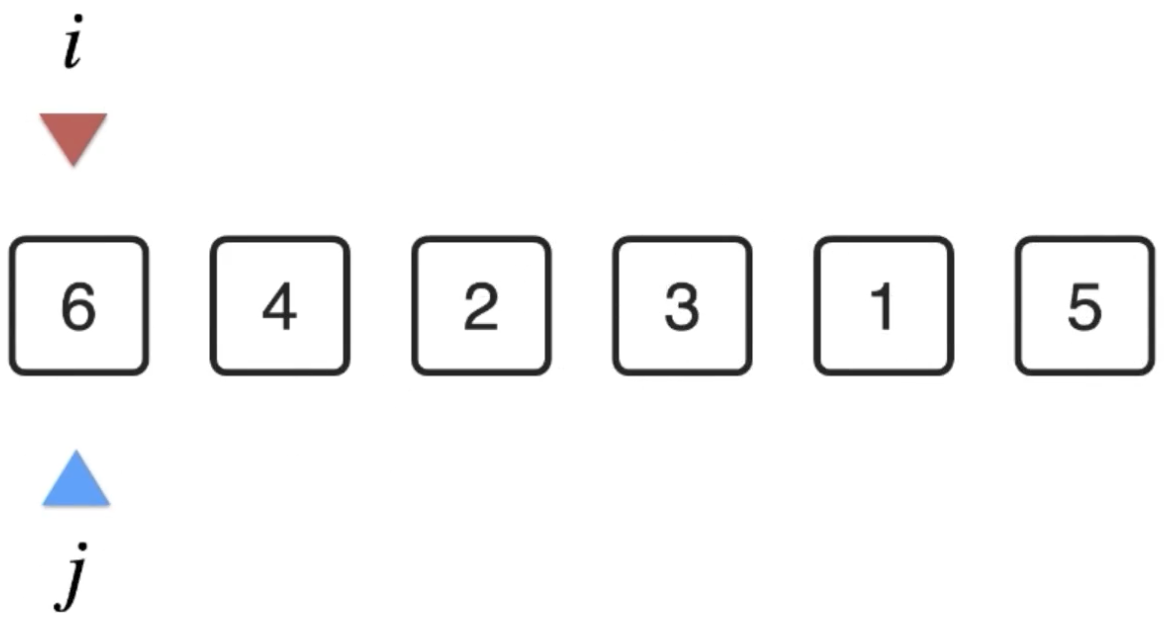
然后这个j会遍历所有元素进行最小值的查找:

此时就找到了数组中最小的那个了,用一个变量记录一下下标:
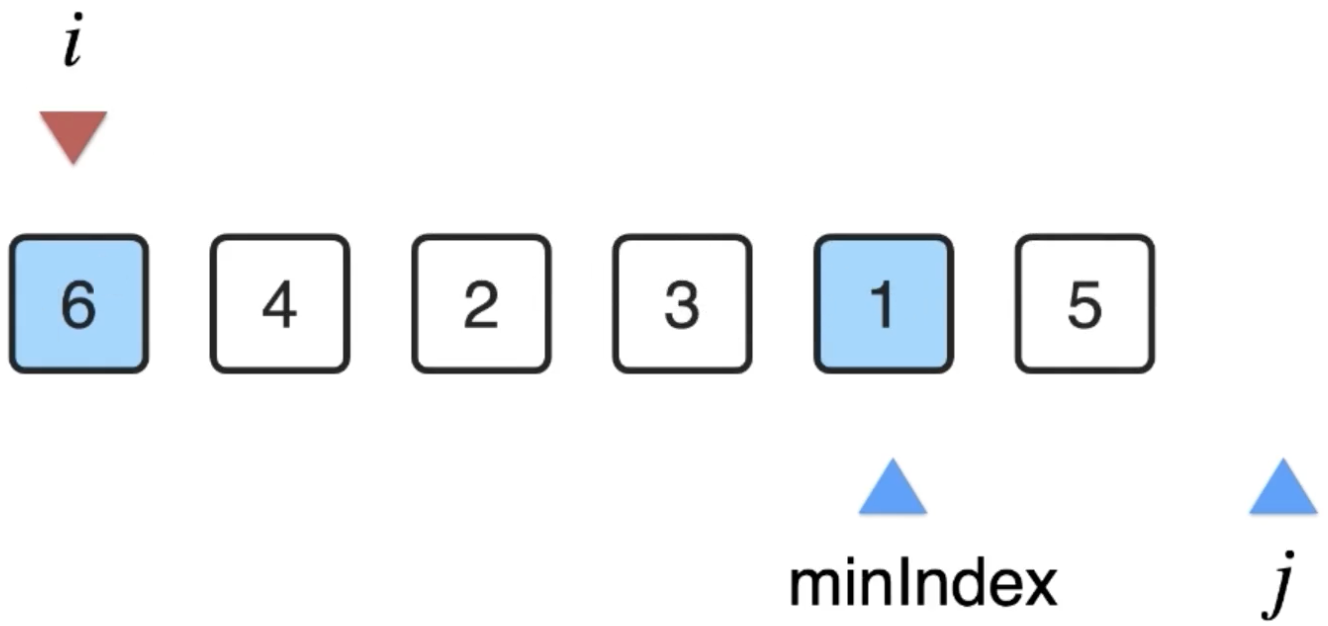
此时将数组中i位置和minIndex位置中的元素原地进行一下交换:
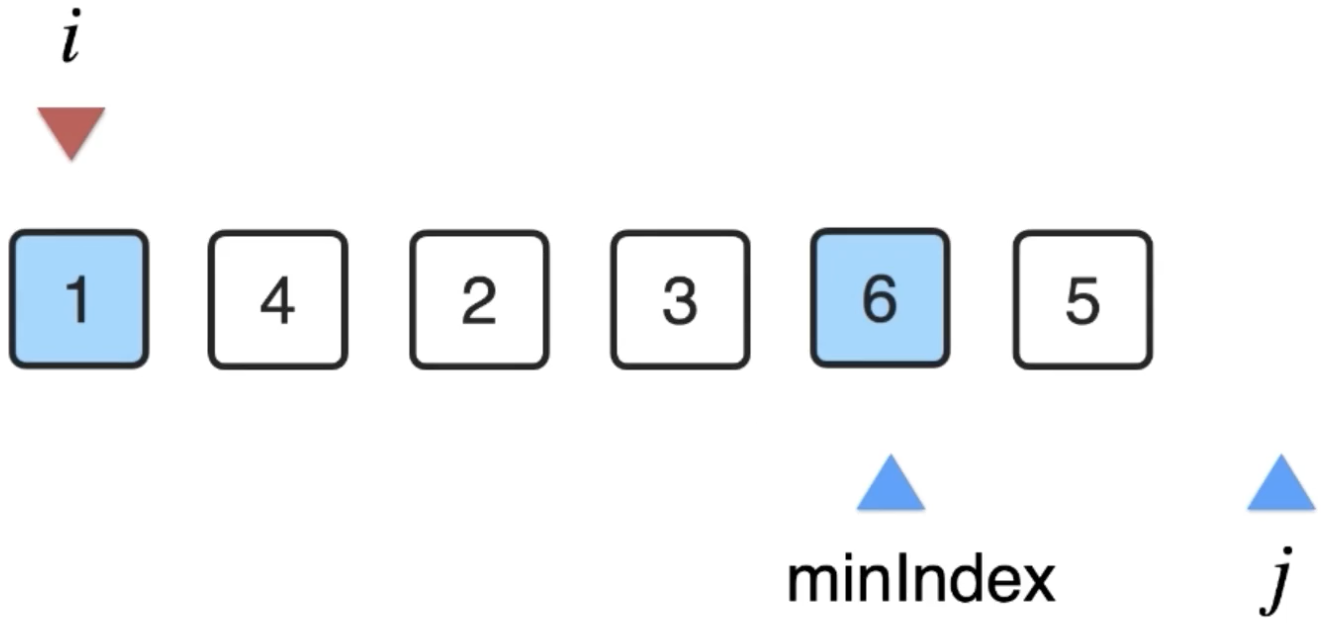
此时当前下标为i的位置的元素就已经是整个数组中最小的那个元素了,所以:
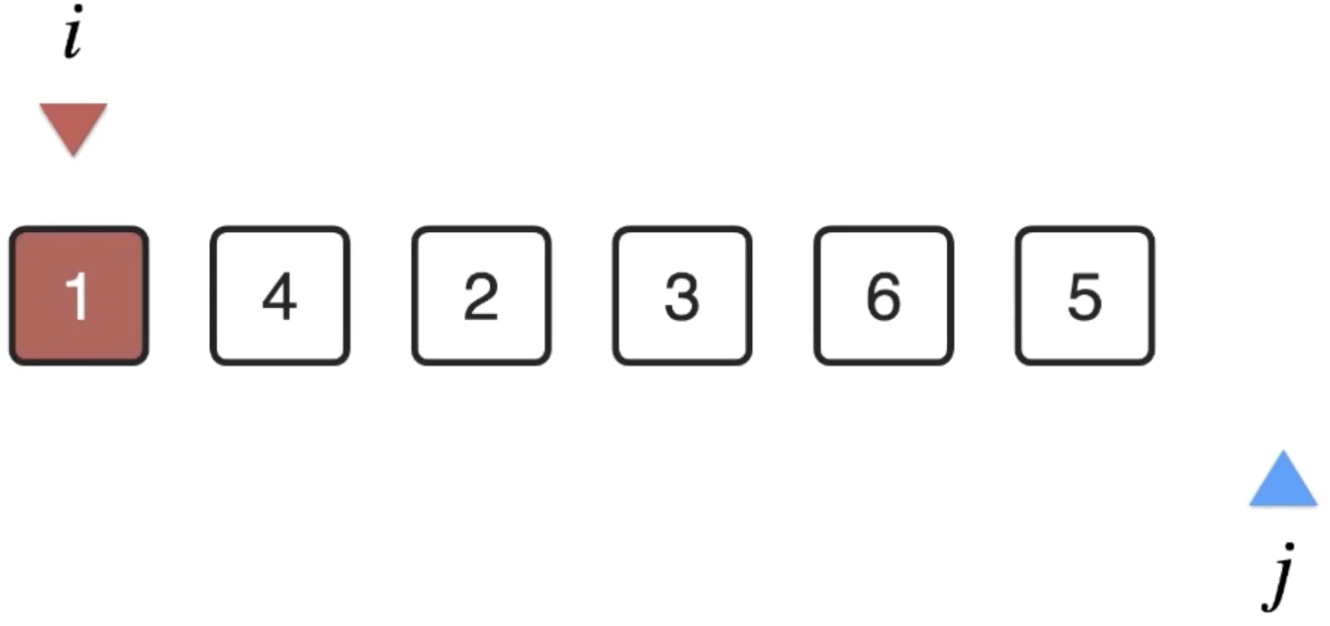
2、i++再来往后进行处理,i=1:
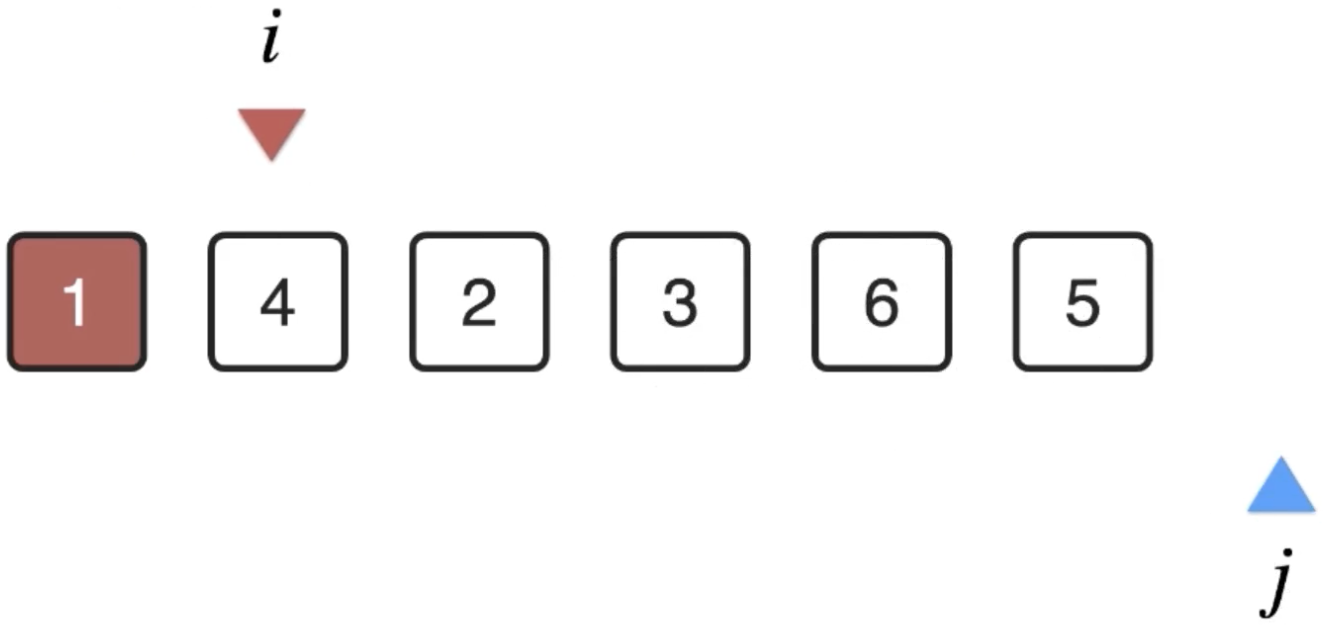
同样的思路,此时的j扫描位置从i开始:
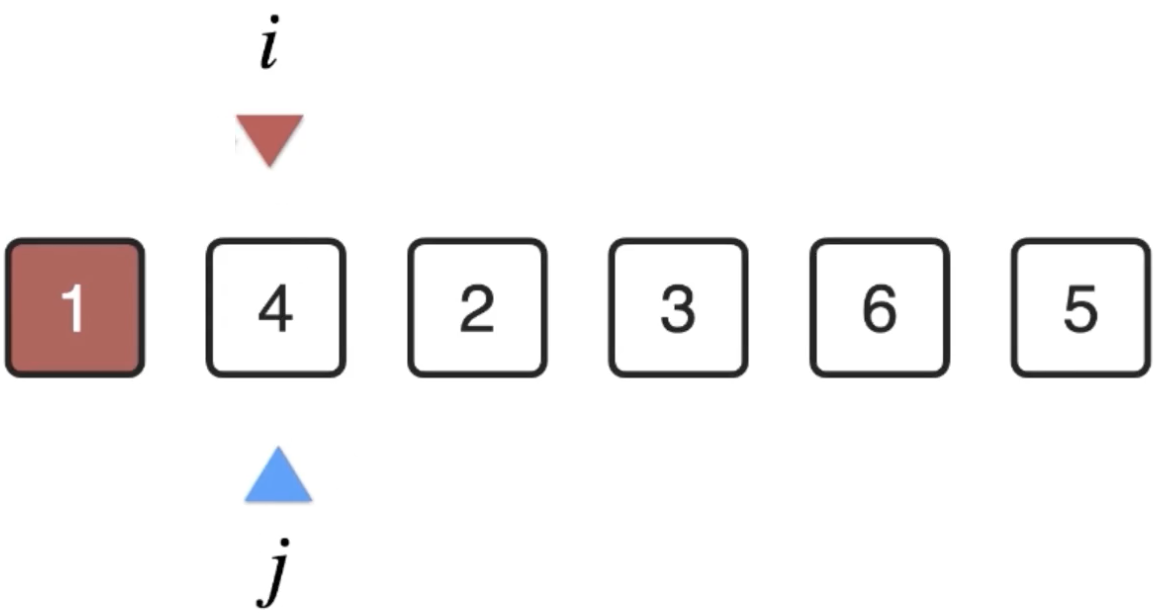
扫描完之后其剩余的最小值的下标为:
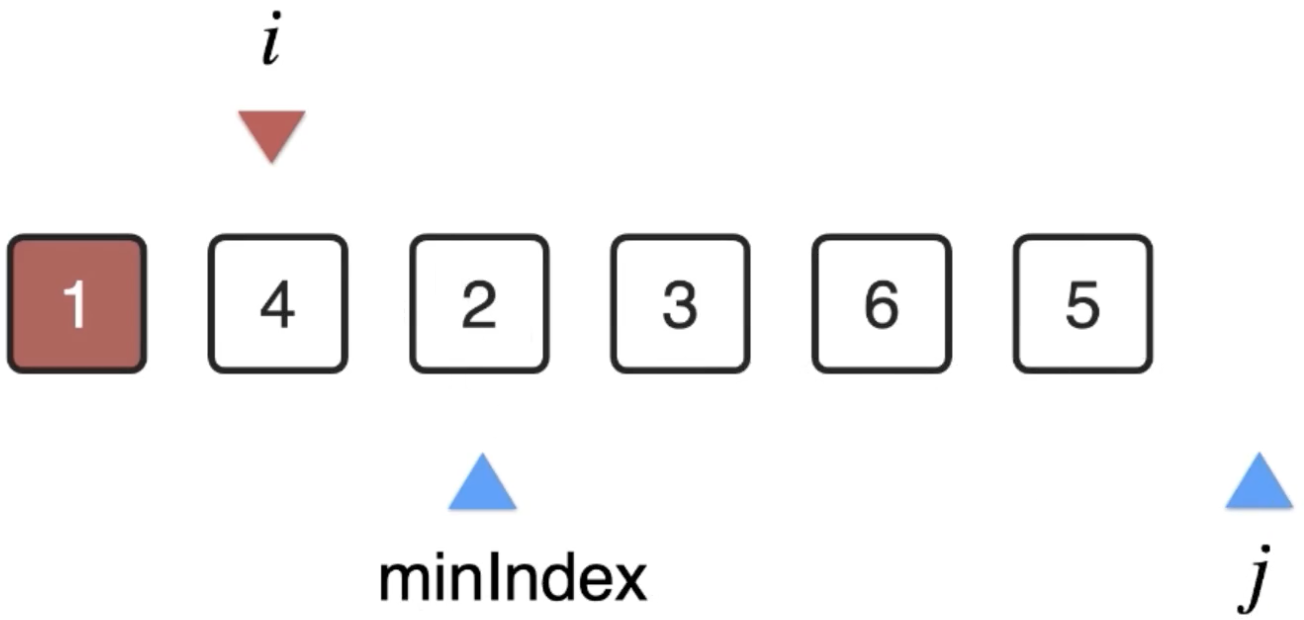
然后将i和minIndex的位置的元素交换一下:
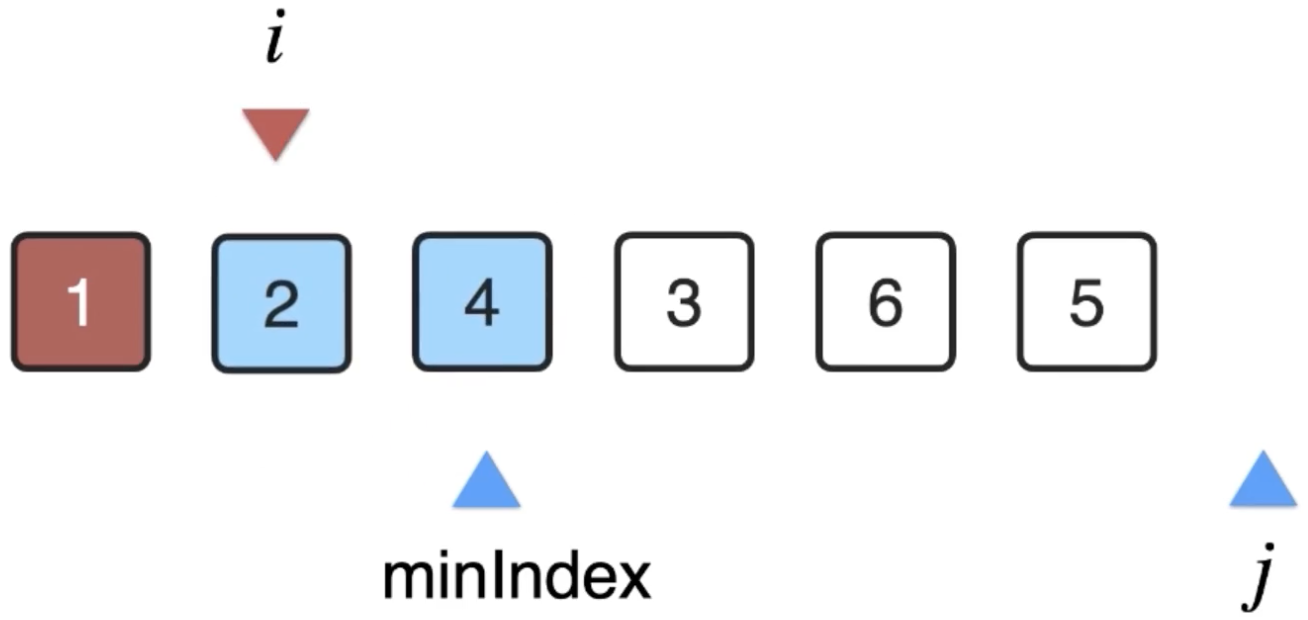
此时i所在的位置的元素就已经确定了,就可以i++了:
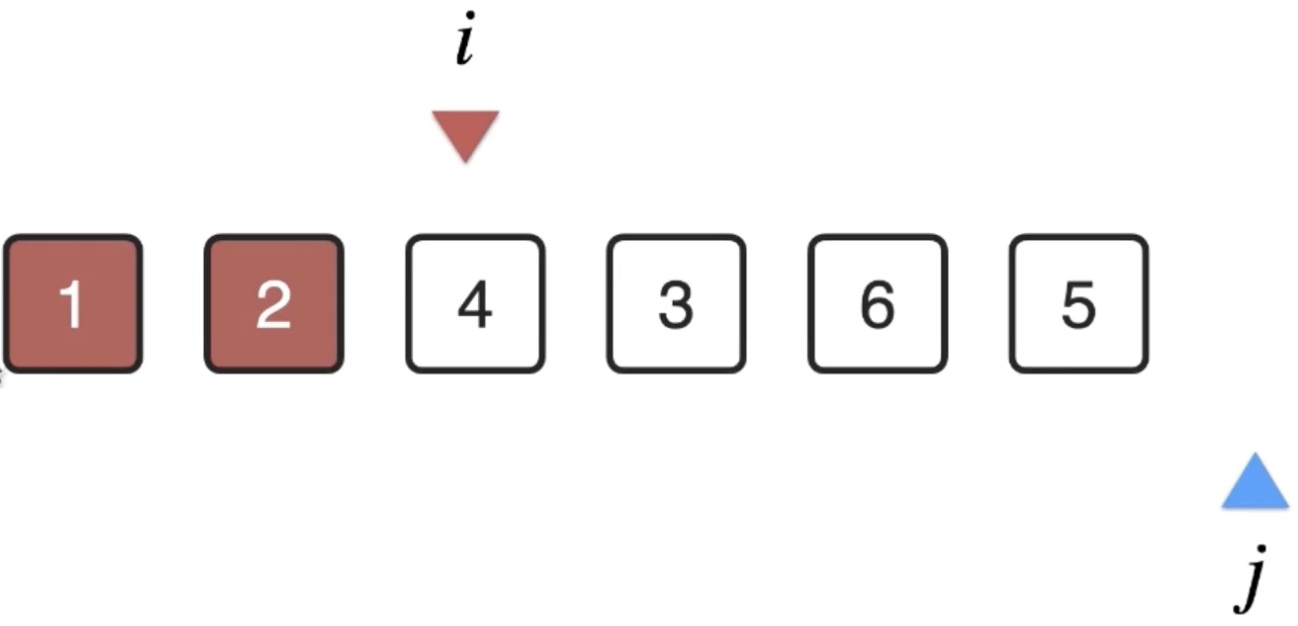
3、i++再来往后进行处理,i=2:
此时j又回到i的位置开始扫描:
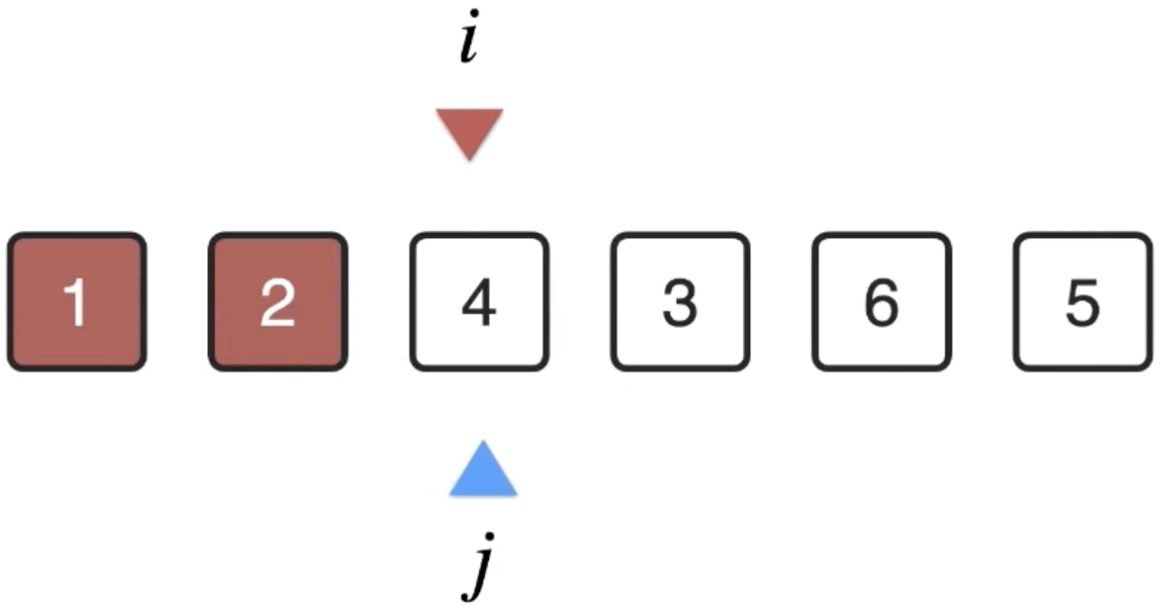
然后遍历扫描,找到最小的元素:
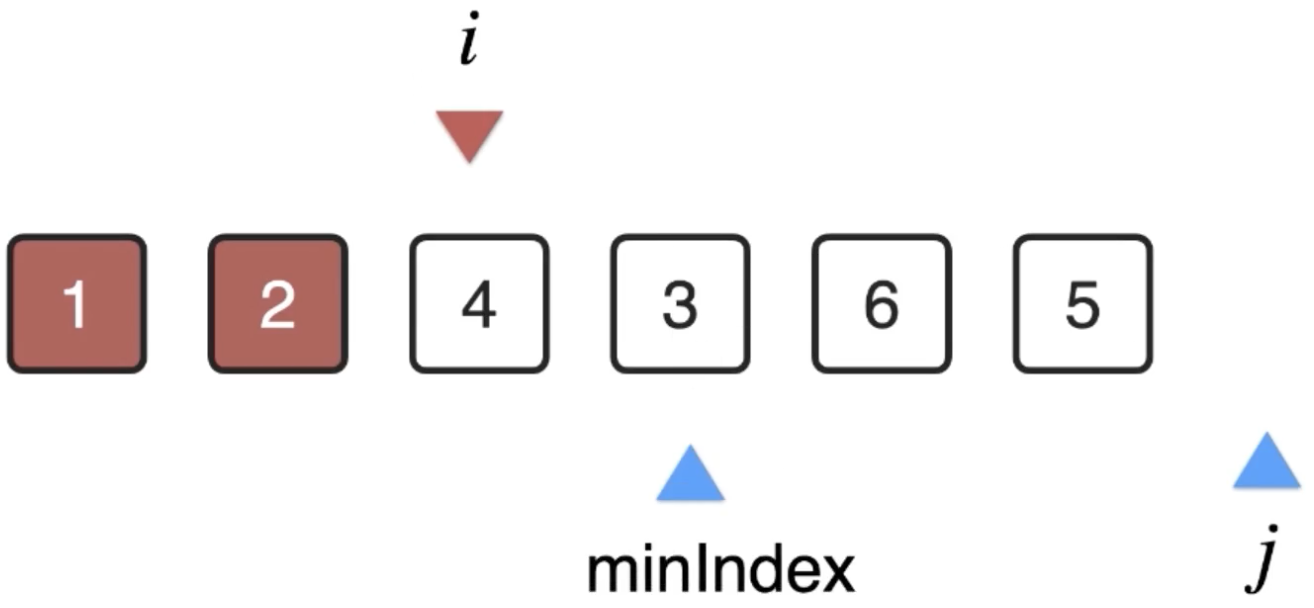
然后将i和minIndex的位置的元素进行交换:
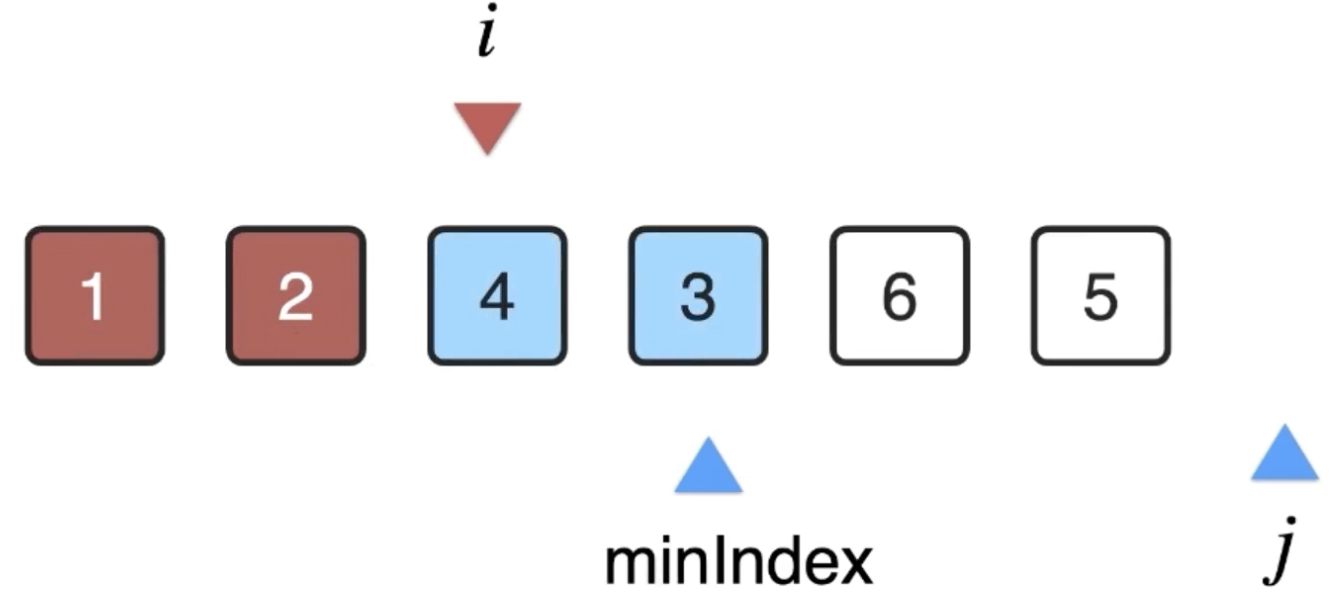
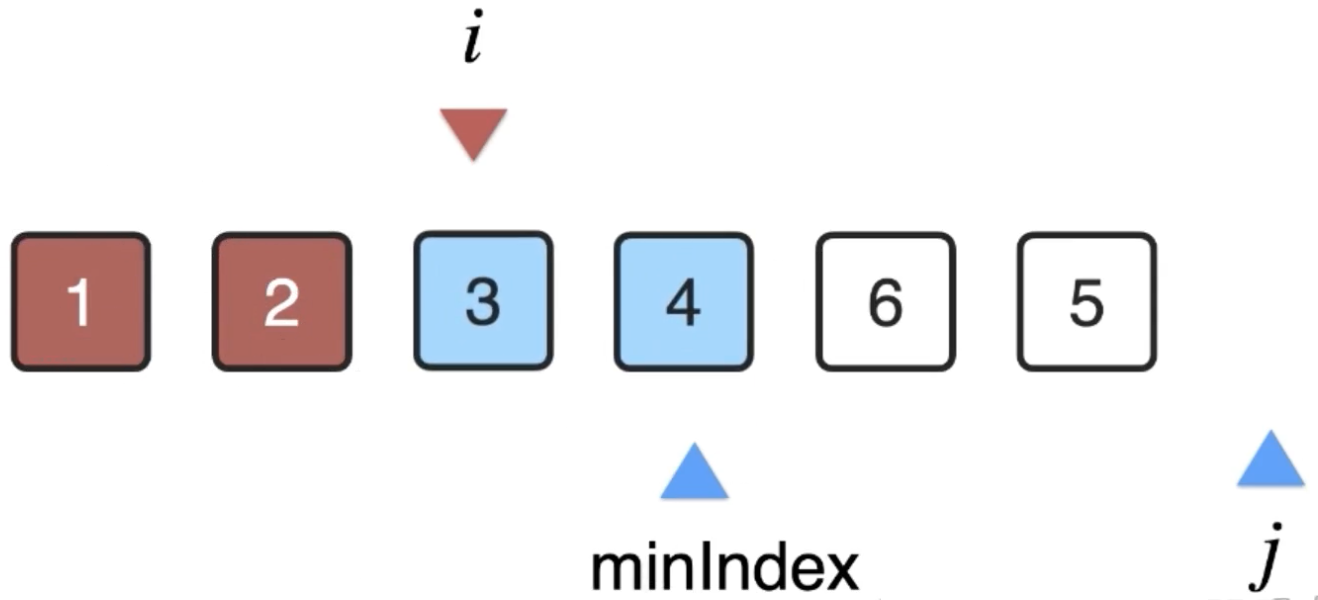
此时i元素上的位置确定好了,则可以++了:
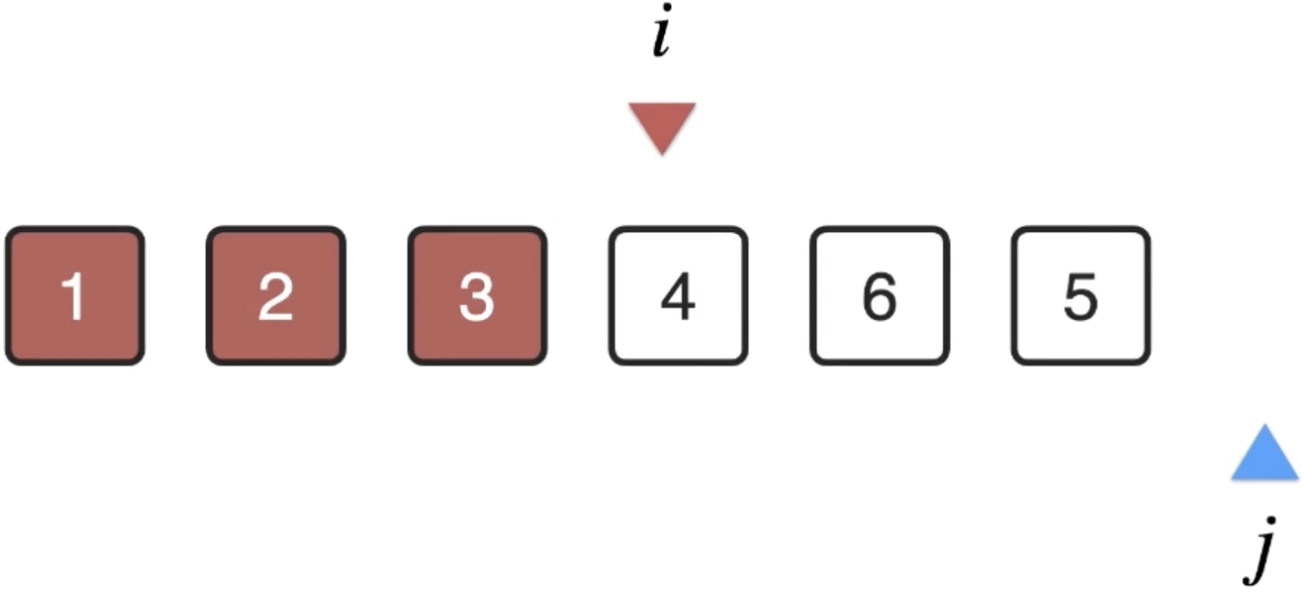
4、i++再来往后进行处理,i=3:
此时j又从i的位置开始扫描,找到剩余元素最小的元素下标:
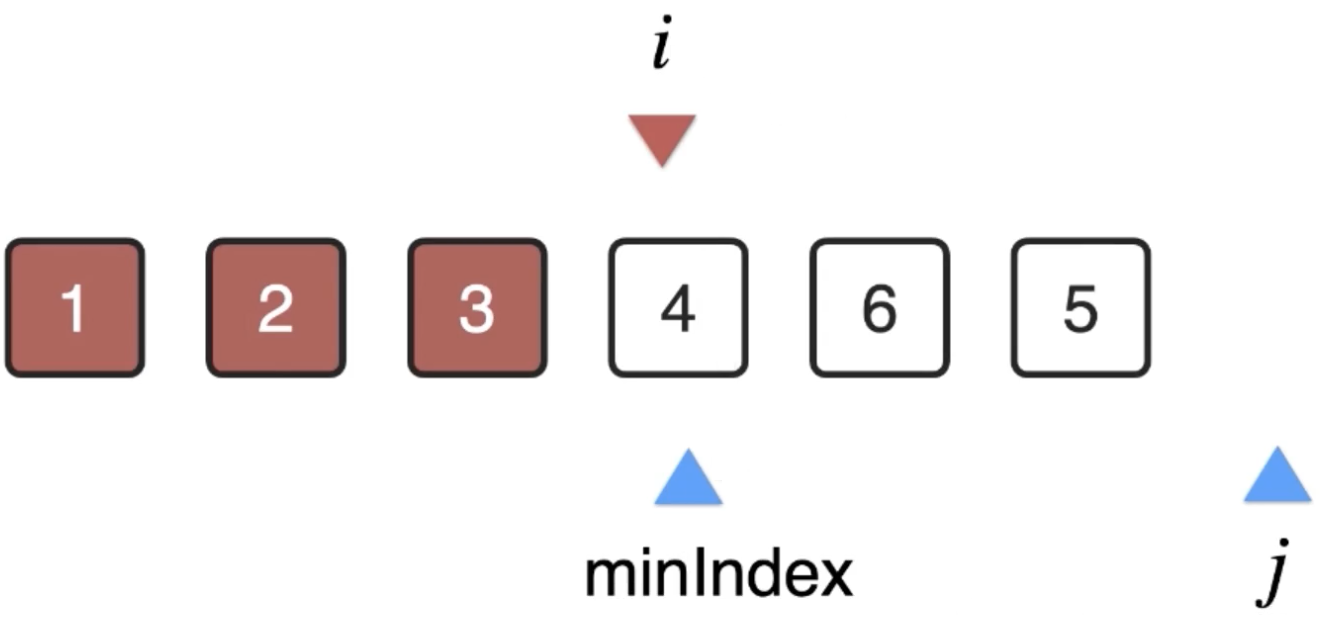
此时发现i和minIndex的元素是同一个,木有关系,还是可以按交换的思路进行处理,很明显自己和自己交换还是自己嘛,所以此时当前位置的元素也处理好了:
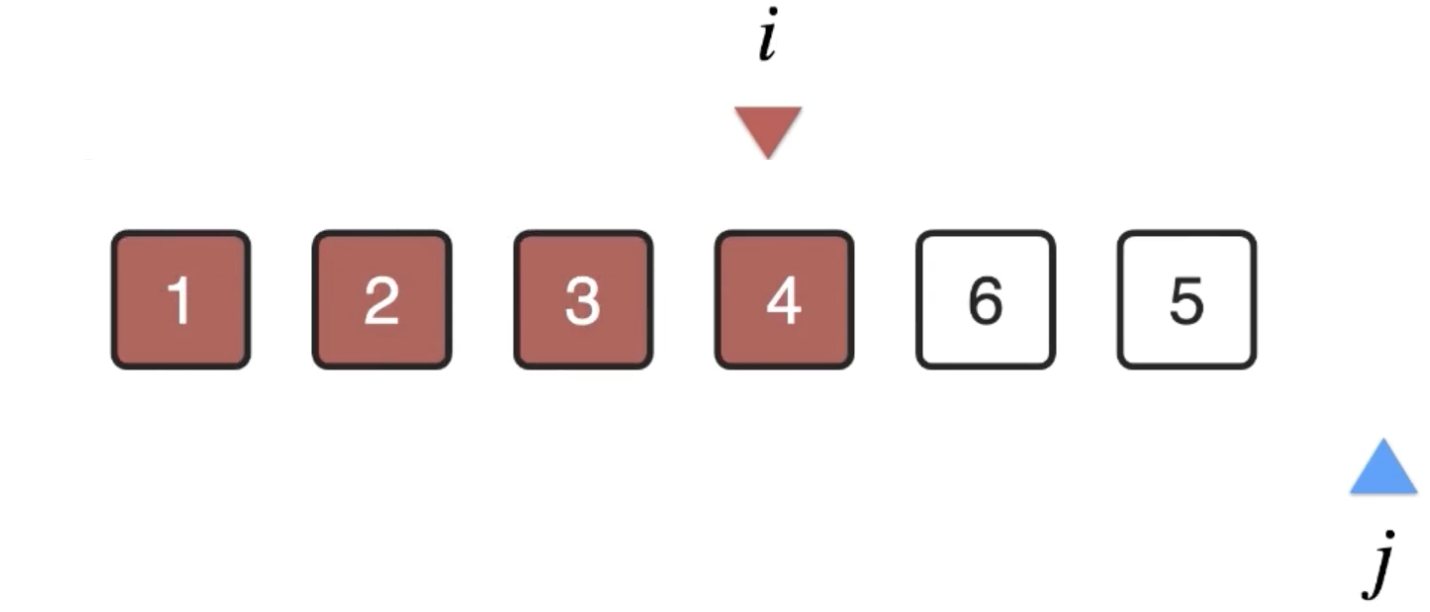
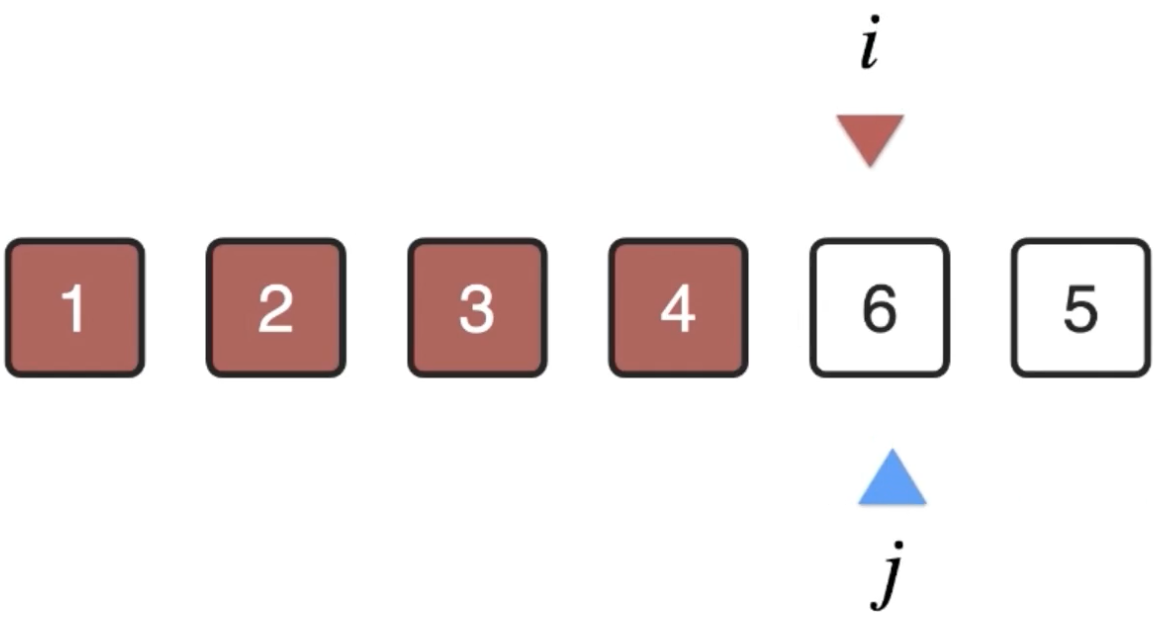
这里可以总结一下规律:此时可以看出arr[0..i)是已排序的,arr[i...n)是未排序的,而接下来就是从arr[i...n)中找到最小的值然后放到arr[i]的位置上来,其实“arr[0..i)是已排序的,arr[i...n)是未排序”就是这个排序算法的循环不变量,关于这个概念在上一篇中已经说明:

而为了维持这个循环不变量,则需要使用“从arr[i...n)中找到最小的值然后放到arr[i]的位置”这个方法,这也是对于咱们之前所学理论的一个回忆,因为"循环不变量"对于写出正确的算法是非常重要的概念,而往往在学习时概念是很容易被忽视的,所以在合适的时候提提它很有必要。
实现选择排序法:
接下来则来实现一下选择排序,这里只针对"原地"的方式进行实现,不过比较简单,直接贴出来了:
/** * 利用选择排序对数组进行从小到大的顺序 */ public class SelectionSort { private SelectionSort() { } public static void sort(int[] arr) { //其中这层循环维持这样一个"循环不变量":arr[0...i)是有序的;arr(i...n)是无序的 for (int i = 0; i < arr.length; i++) { //选择arr[i...n)中的最小值的索引 int minIndex = i; for (int j = i; j < arr.length; j++) { if (arr[j] < arr[minIndex]) minIndex = j; } //将i和minIndex位置的元素进行一下交换 swap(arr, i, minIndex); } } private static void swap(int[] arr, int i, int j) { int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } public static void main(String[] args) { int[] arr = {1, 4, 2, 3, 6, 5}; SelectionSort.sort(arr); for (int e : arr) { System.out.print(e + " "); } System.out.println(); } }
运行:
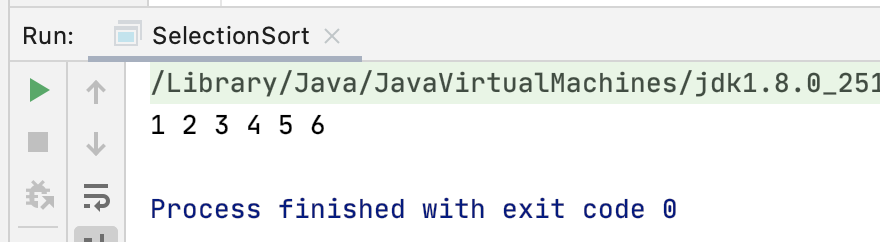
其中注释中标红处记得理解一下~~
使用带约束的泛型:
跟上次学习的套路一样,目前咱们的实现只支持int类型,接下来则使用泛型将其改造成通用的支持任何类型的选择排序, 所以:
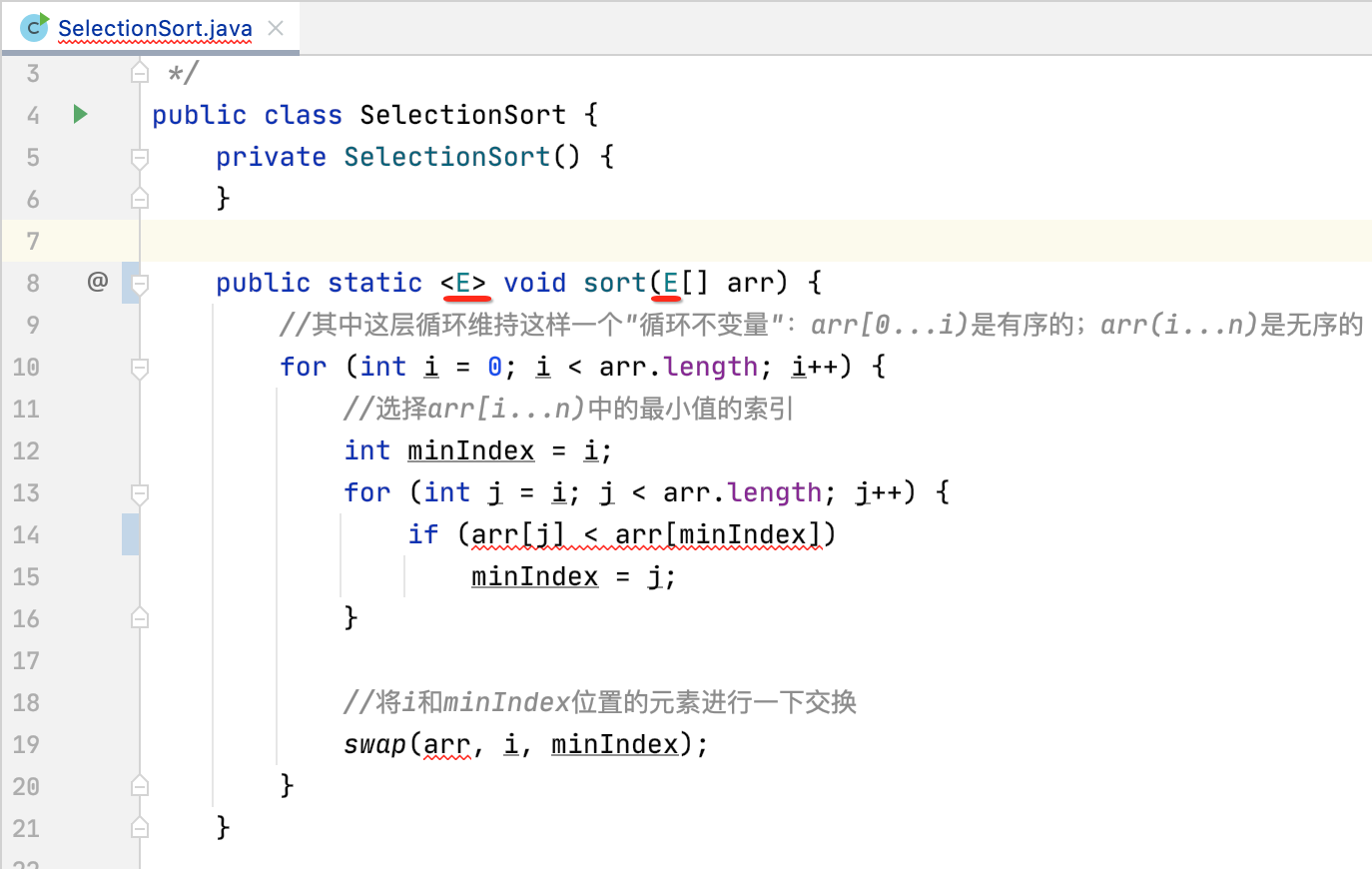
此时报错了,看一下:
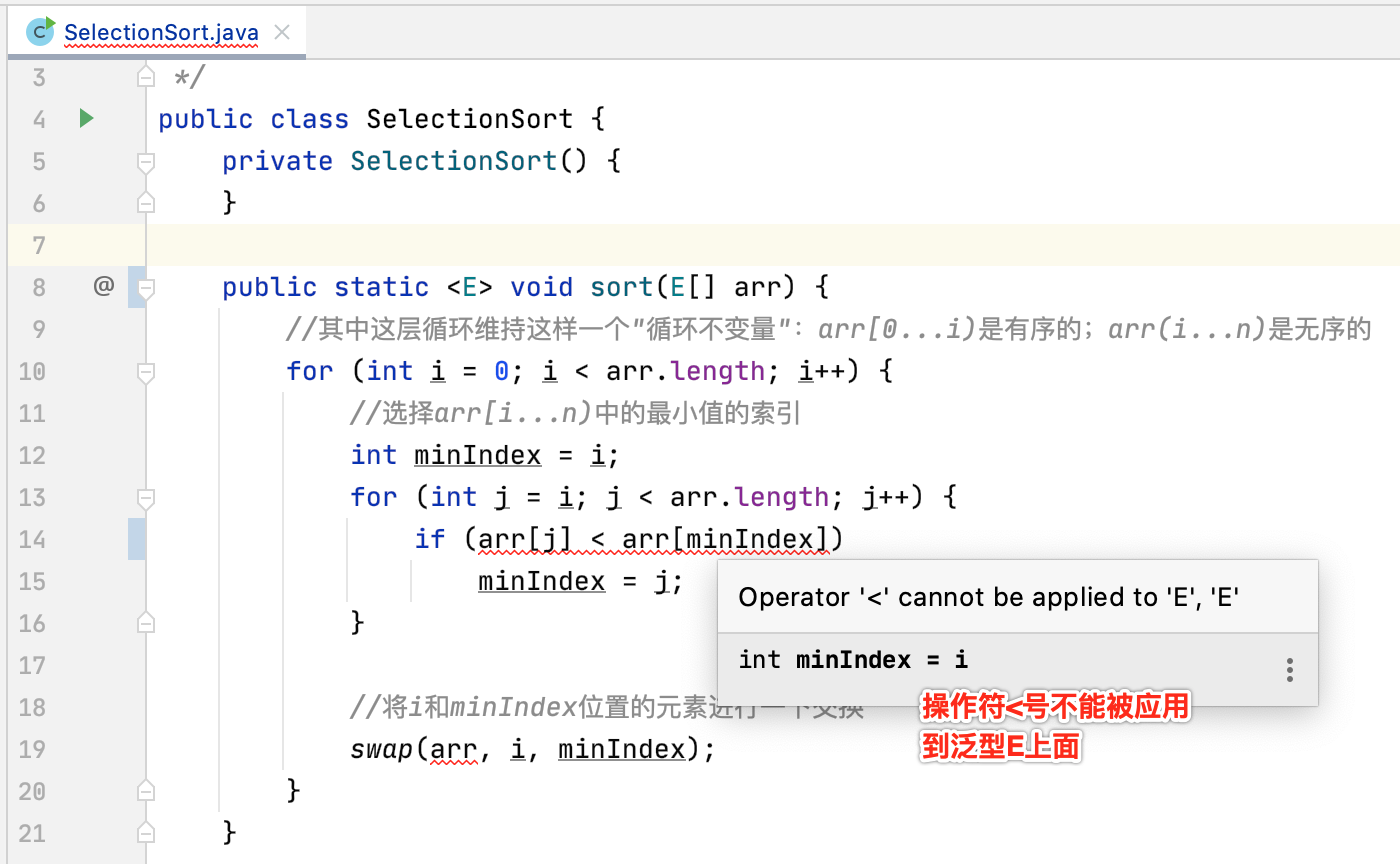
熟悉Java语法的都知道如果是要用通用的方式来对元素进行比较,其对象需要实现Comparable接口才行,它里面有个compareTo方法:
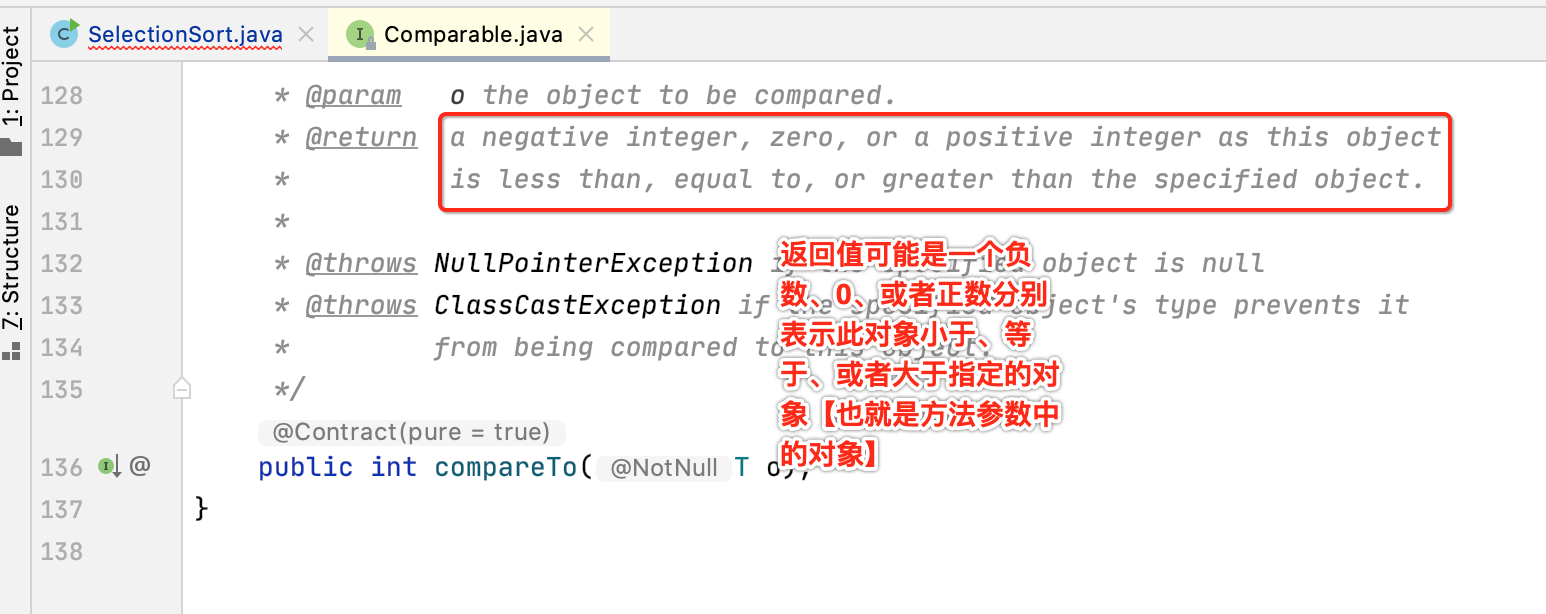
所以咱们此时可以将"<"改为"compareTo"试一下:
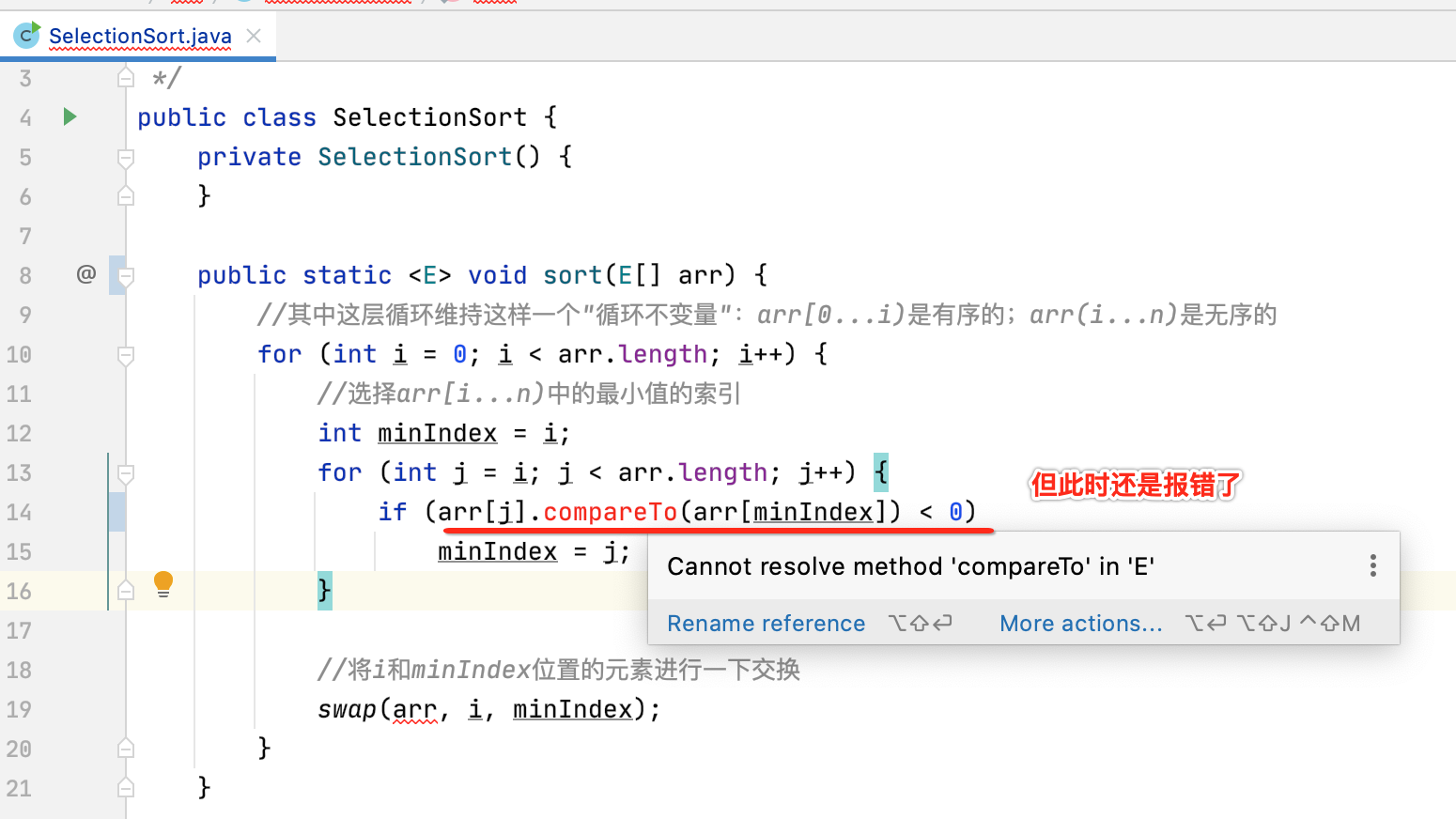
此时则需要给泛型加上一个类型约束了,因为只有实现了Comparable接口的对象才有compareTo()方法,所以,给E泛型增加一个接口的约束:
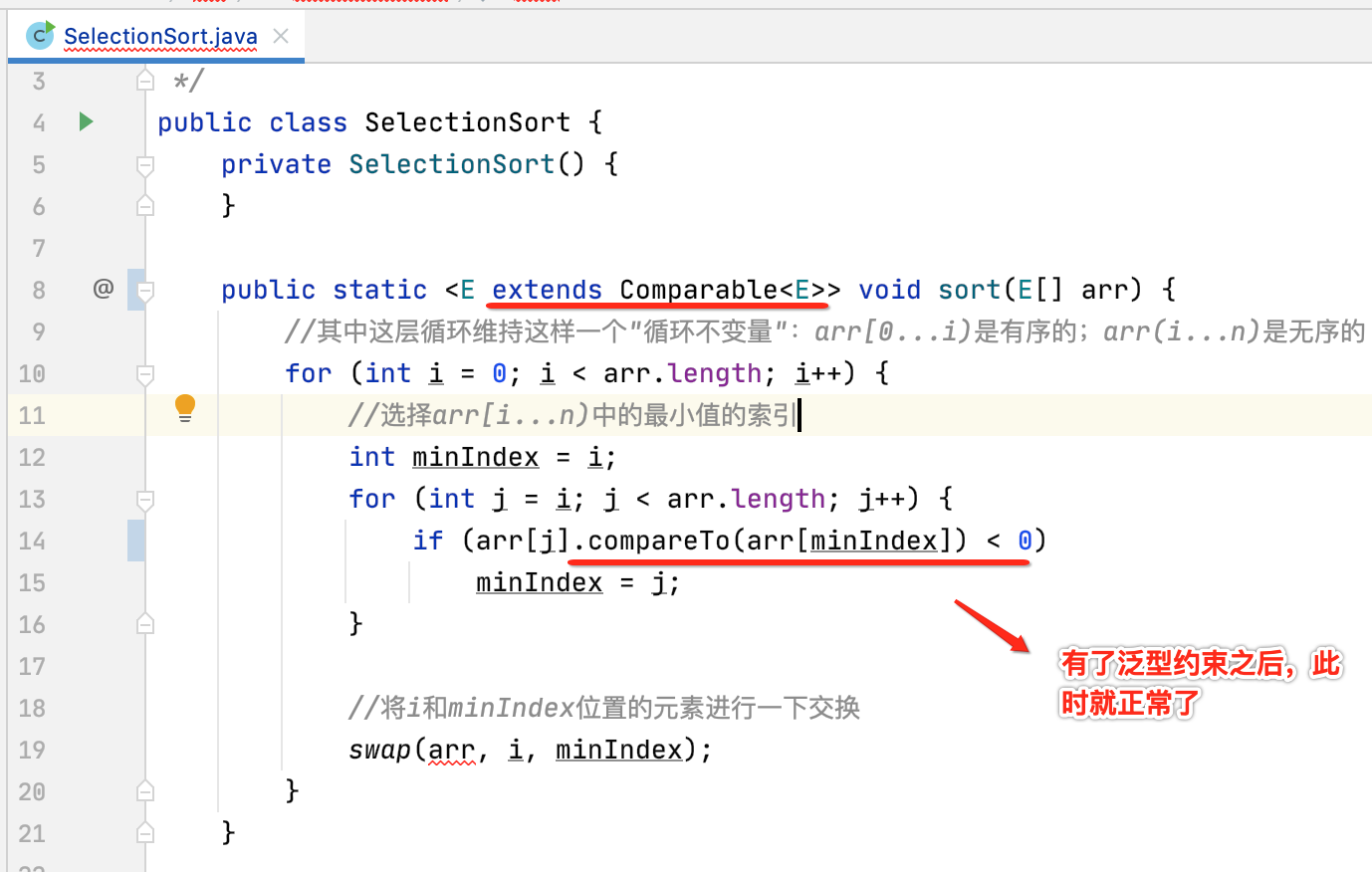
关于这块的泛型约束extends它还有一个知识点就是协变与逆变,在Koltin中也存在,关于这块可以参考https://www.cnblogs.com/webor2006/p/11291744.html有详细的说明,这里就不过多的说明了,继续回到程序的改造上来,目前还有一块报错了:
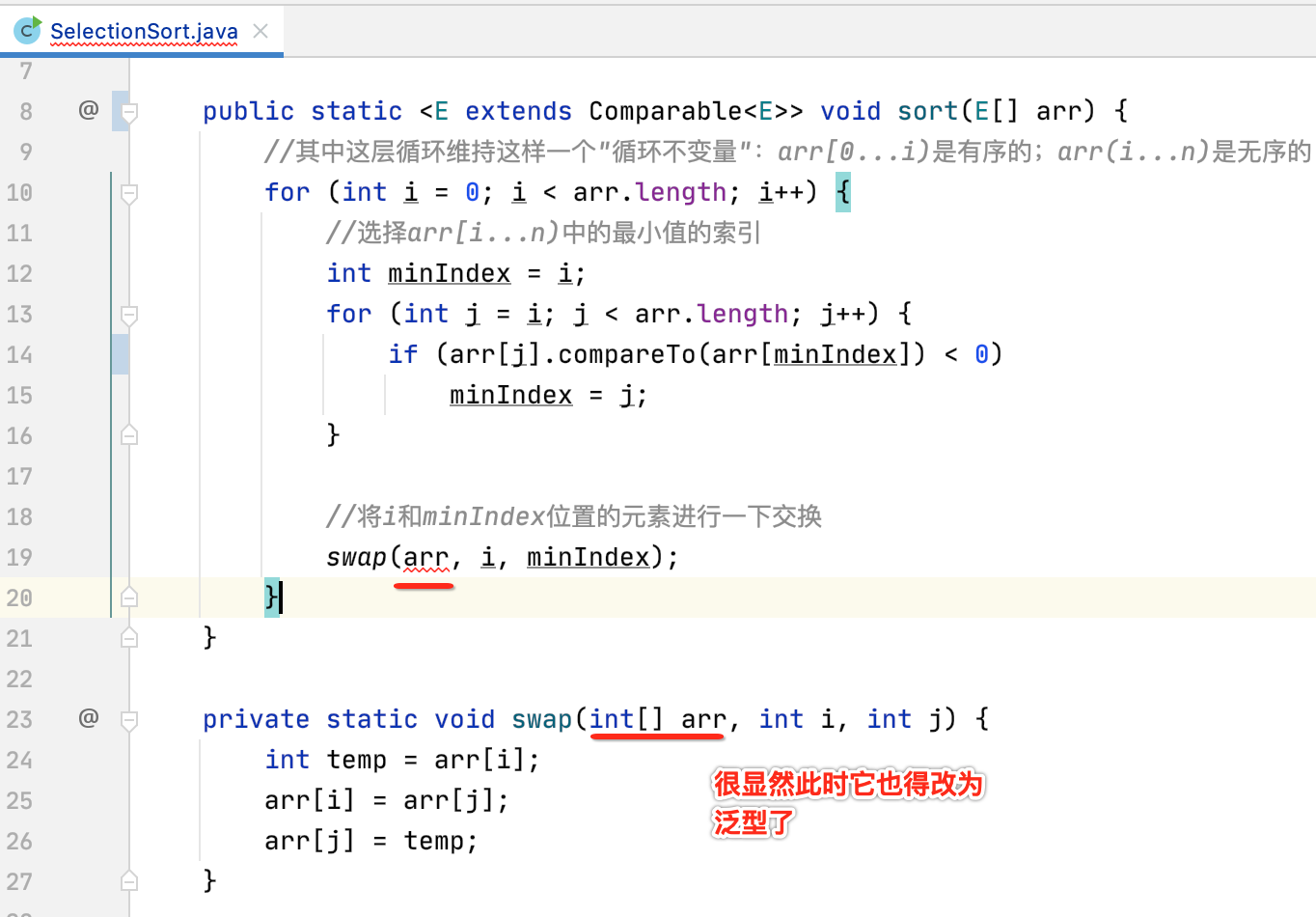
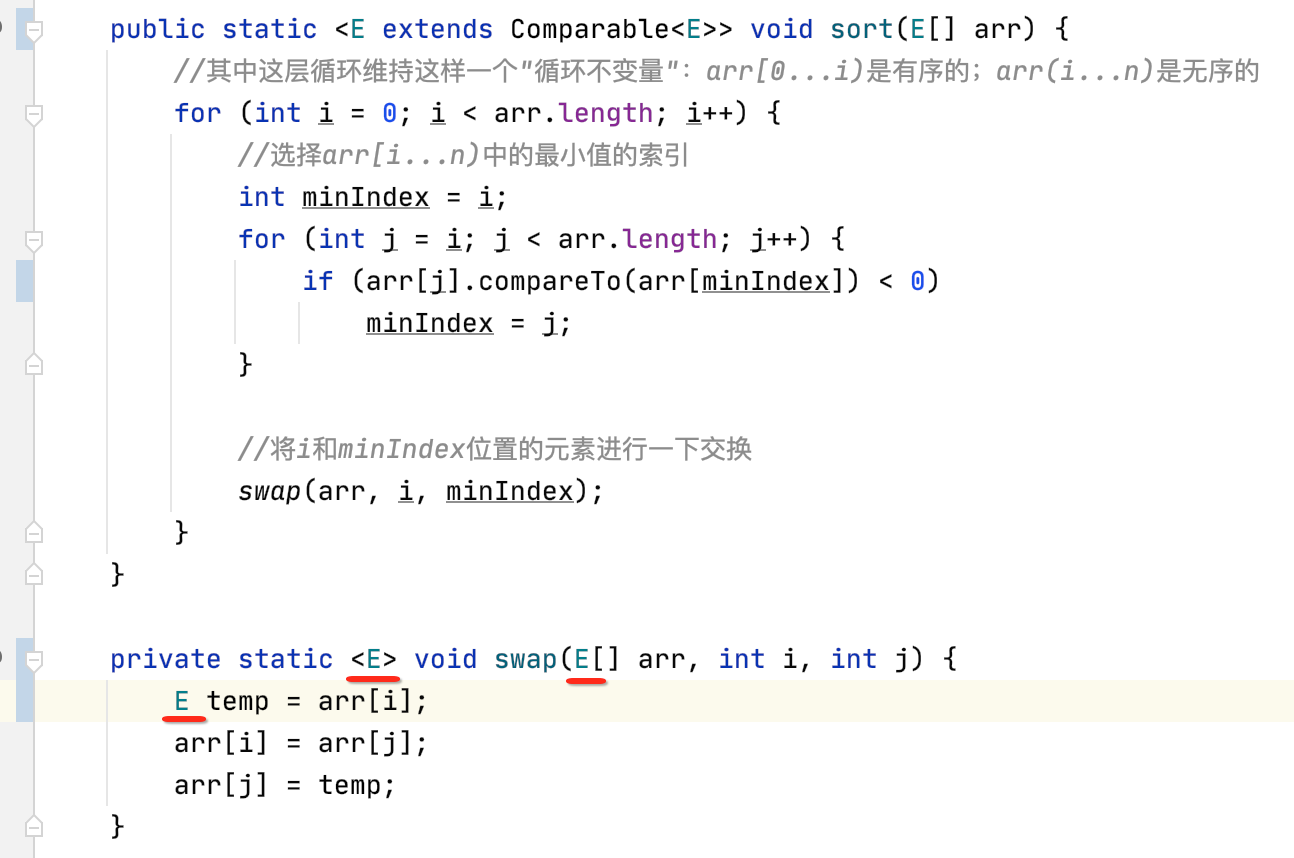
比较简单,但是!!!这里再反问一句,那这个泛型方法swap中的泛型E要不要增加一个Comparable的约束呢?其实是不需要的,为啥?因为对于元素的交换操作而言任何对象都可以进行交换,并非只有实现了Comparable的对象才能进行交换,所以这里就不需要增加泛型约束了,在做实际泛型设计时切勿滥用泛型约束哟~~
最后在调用处也还有个小错:
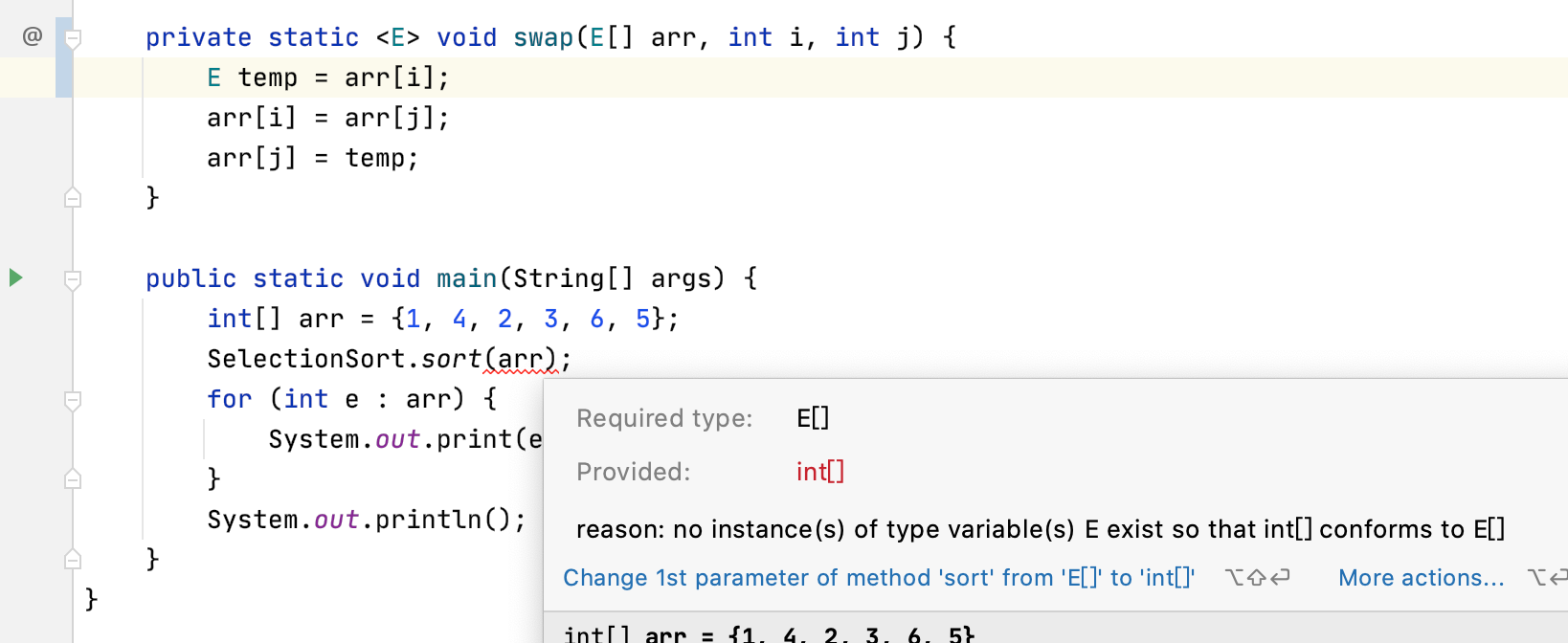
这个是因为泛型要求必须是一个类,而不能是一个基本数据类型,所以改成包装类既可:
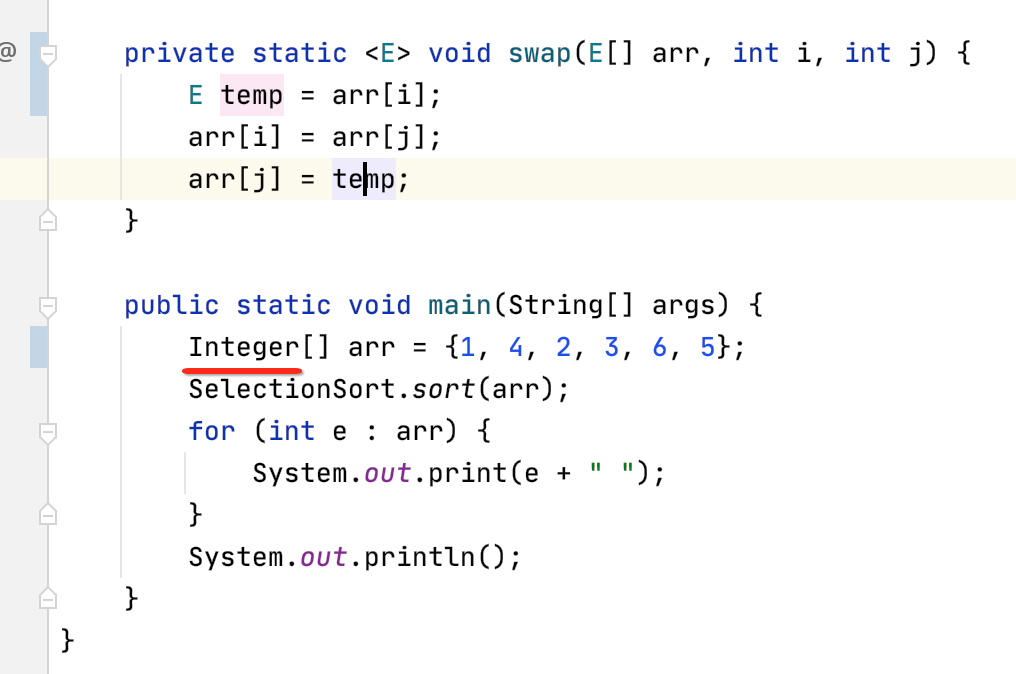
整个代码如下:
/** * 利用选择排序对数组进行从小到大的顺序 */ public class SelectionSort { private SelectionSort() { } public static <E extends Comparable<E>> void sort(E[] arr) { //其中这层循环维持这样一个"循环不变量":arr[0...i)是有序的;arr(i...n)是无序的 for (int i = 0; i < arr.length; i++) { //选择arr[i...n)中的最小值的索引 int minIndex = i; for (int j = i; j < arr.length; j++) { if (arr[j].compareTo(arr[minIndex]) < 0) minIndex = j; } //将i和minIndex位置的元素进行一下交换 swap(arr, i, minIndex); } } private static <E> void swap(E[] arr, int i, int j) { E temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } public static void main(String[] args) { Integer[] arr = {1, 4, 2, 3, 6, 5}; SelectionSort.sort(arr); for (int e : arr) { System.out.print(e + " "); } System.out.println(); } }
其运行结果也正确,这样就将咱们的选择排序算法改为通用的了。
使用 Comparable 接口:
既然已经将咱们的选择排序改为了通用类型了,那接下来采用自定义的类来测试一下通用算法的正确性,还是用上次学习线性算法的Student类为例:
将其拷过来:
public class Student { private String name; public Student(String name) { this.name = name; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student another = (Student) o; return this.name.equals(another.name); } }
接下来让它实现Comparable接口:
public class Student implements Comparable<Student> { private String name; public Student(String name) { this.name = name; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student another = (Student) o; return this.name.equals(another.name); } @Override public int compareTo(Student o) { //TODO return 0; } }
这里希望对学生的成绩进行从小到大的顺序进行排序,所以这里增加一个学生成绩的字段,如下:
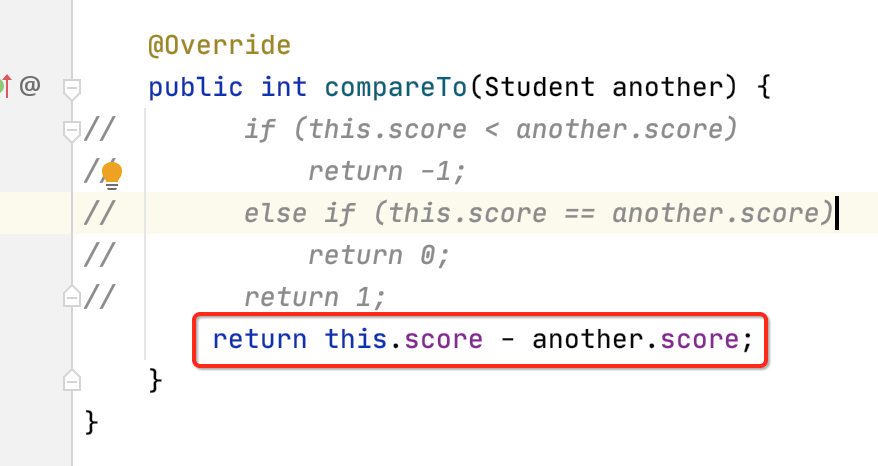
public class Student implements Comparable<Student> { private String name; private int score; public Student(String name, int score) { this.name = name; this.score = score; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student another = (Student) o; return this.name.equals(another.name); } @Override public int compareTo(Student another) { if (this.score < another.score) return -1; else if (this.score == another.score) return 0; return 1; } }
不过对于compareTo方法不用这么啰嗦,这种写法的目的是为了复习compareTo背后的判断逻辑,优雅的写法应该精简成这样:
另外这里为了看测试结果,覆写一下toString()方法:
public class Student implements Comparable<Student> { private String name; private int score; public Student(String name, int score) { this.name = name; this.score = score; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student another = (Student) o; return this.name.equals(another.name); } @Override public int compareTo(Student another) { // if (this.score < another.score) // return -1; // else if (this.score == another.score) // return 0; // return 1; return this.score - another.score; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", score=" + score + '}'; } }
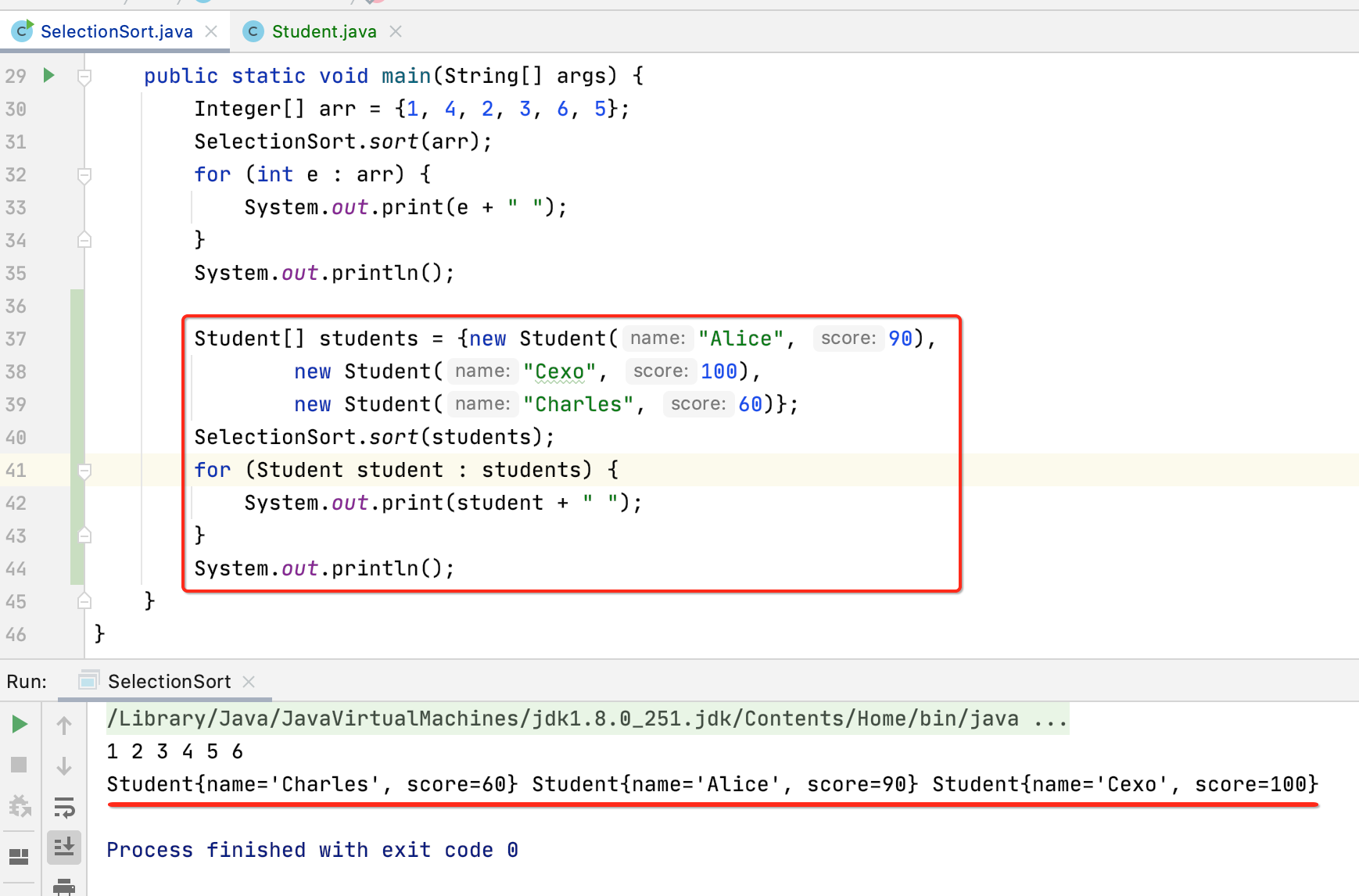
接下来测试一下:
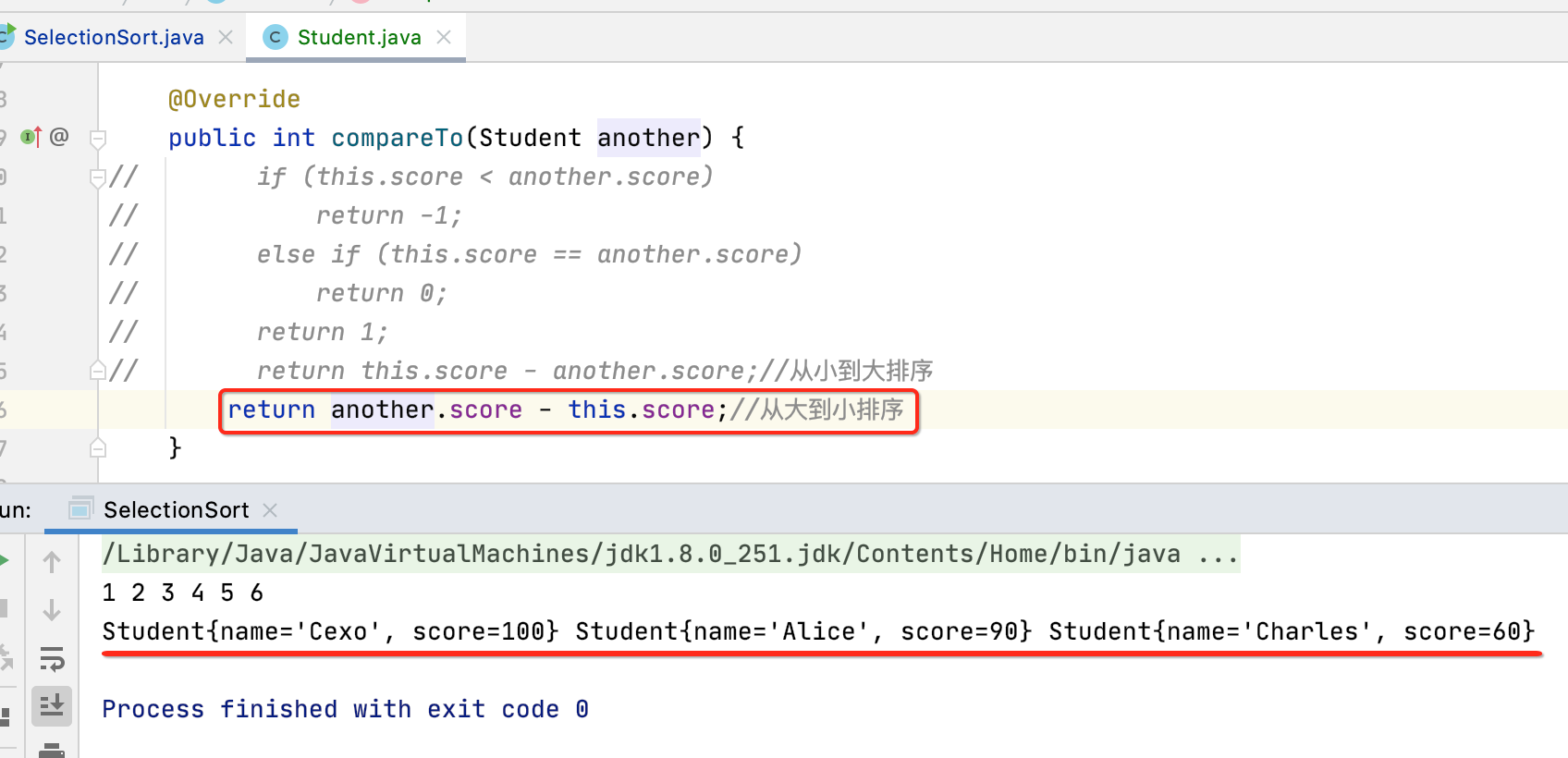
那如果想从大到小排序呢?改一下compareTo的逻辑既可:
选择排序法的复杂度分析:
分析:
对于一个算法的实现还有一个非常重要的任务需要做,那就是算法的时间复杂度分析啦,先来看一下咱们的实现:
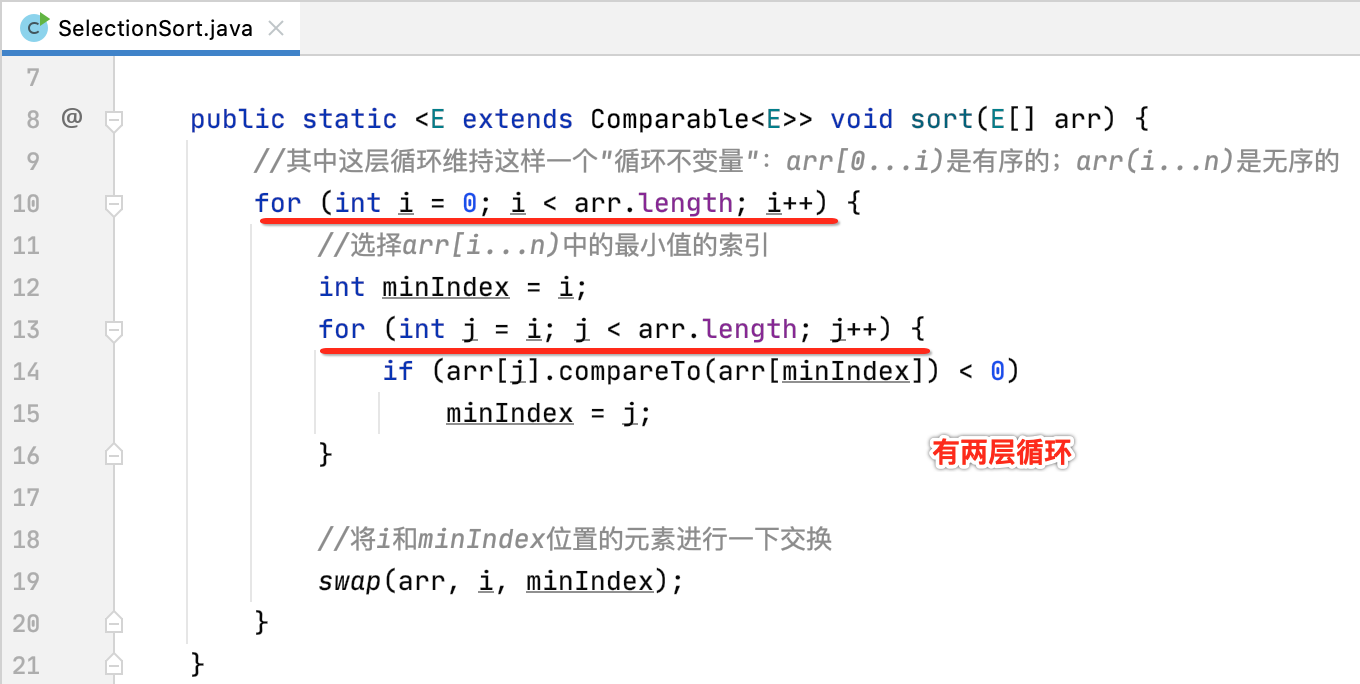
一看貌似就是O(n^2)级别的算法,事实就是如此,下面来计算一下:
1、当外层循环i=0时,内层循环j会运行n次【也就是数组个数】;
2、当外层循环i=1时,内层循环j会运行n-1次;
3、当外层循环i=2时,内层循环j会运行n-2次;
...
4、当外层循环i=n-1时,内层循环j会运行1次;
好,看一下标红的倒过来累加,是不是整体算法执行的次数公式其实是:
![]()
这在数学上其实是一个等差数列,百度一下它的定义:

而它的求和公式上图也介绍了:
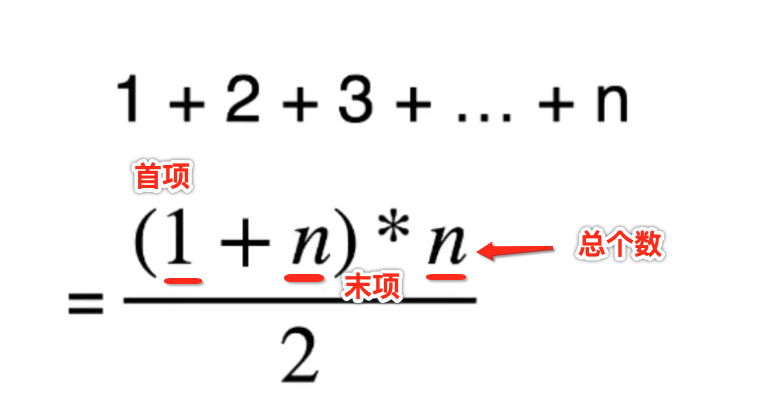
而将这公式展开就变成这样了:
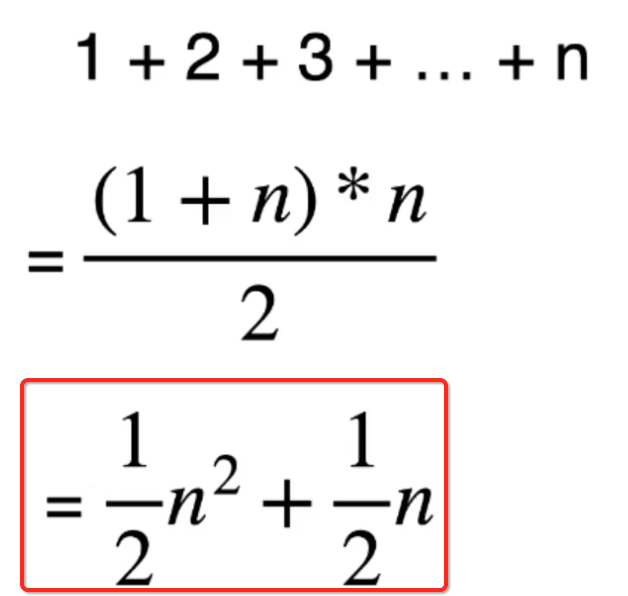
而根据上一次https://www.cnblogs.com/webor2006/p/13914100.html的理论说明:
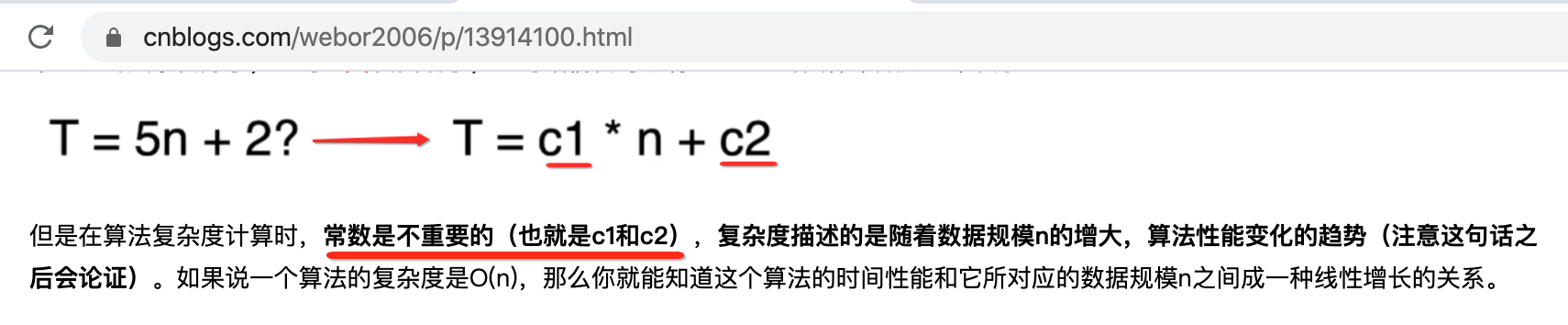
那不在算法分析时就变为了n²+n了,而在算算法复杂度时还有一条:“低阶项也是需要忽略的,因为复杂度是指随着数据n的增大算法性能变化的趋势,而这个趋势是由高阶项来决定的,而低阶项所起的作用太小了”,啥意思,n²的阶数是2,n的阶数是1,那根据这一条规则,那不整个算法的时间复杂度就定格到了O(n^2),
代码验证:
依然如上一次的学习一样,上面所分析的时间复杂度为O(n^2), 下面用代码来验证一下,这里以int[]数组排序进行分析,将自定义类的这个先注释掉:
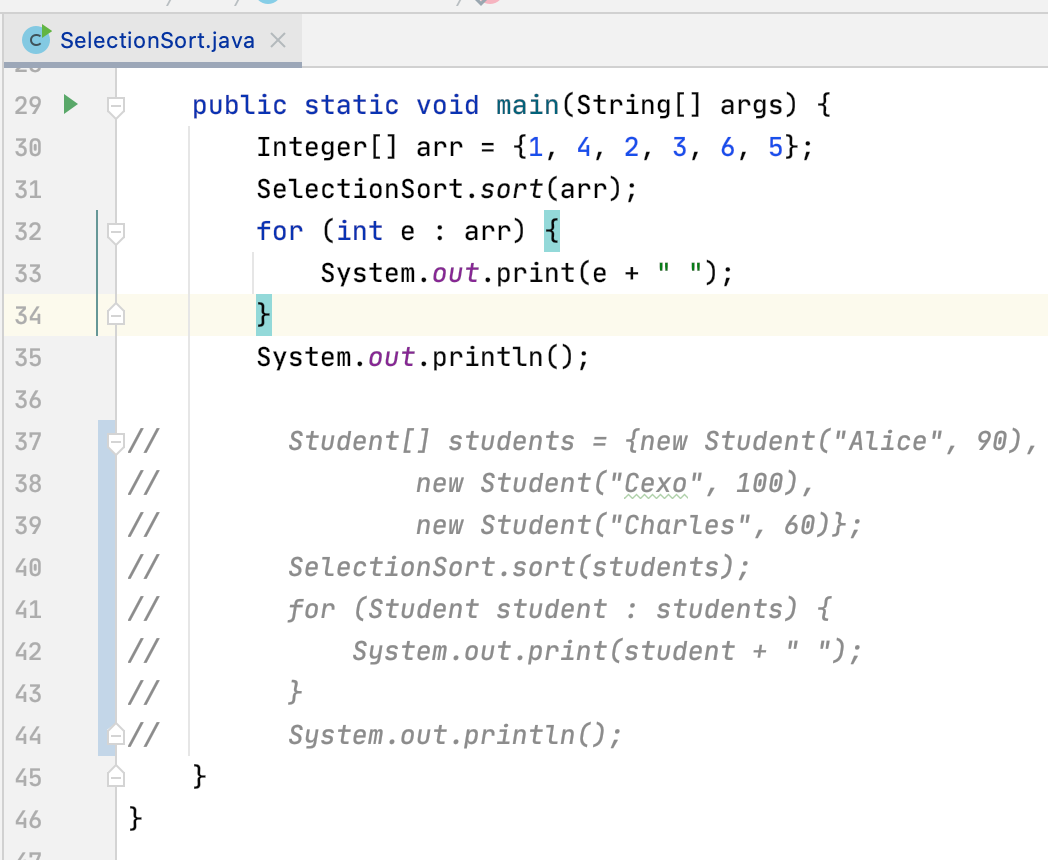
而验证是需要基于一定规模的数据才能看出的,所以将上一次自动生成指定个数数组的工具类拷过来:

但是这个工具方法是生成有序数组的,显然对于咱们这次要验证的不太符合,咱们需要乱序才对,基于此咱们再来封装一个方法既可,如下:
import java.util.Random; public class ArrayGenerator { private ArrayGenerator() { } /** * 生成一个长度为n的有序数组 */ public static Integer[] generateOrderedArray(int n) { Integer[] array = new Integer[n]; for (int i = 0; i < n; i++) { array[i] = i; } return array; } /** * 生成一个长度为n的随机数组,每个数字的范围是[0, bound) */ public static Integer[] generateRandomArray(int n, int bound) { Integer[] array = new Integer[n]; Random random = new Random(); for (int i = 0; i < n; i++) { array[i] = random.nextInt(bound); } return array; } }
接着来使用一下:
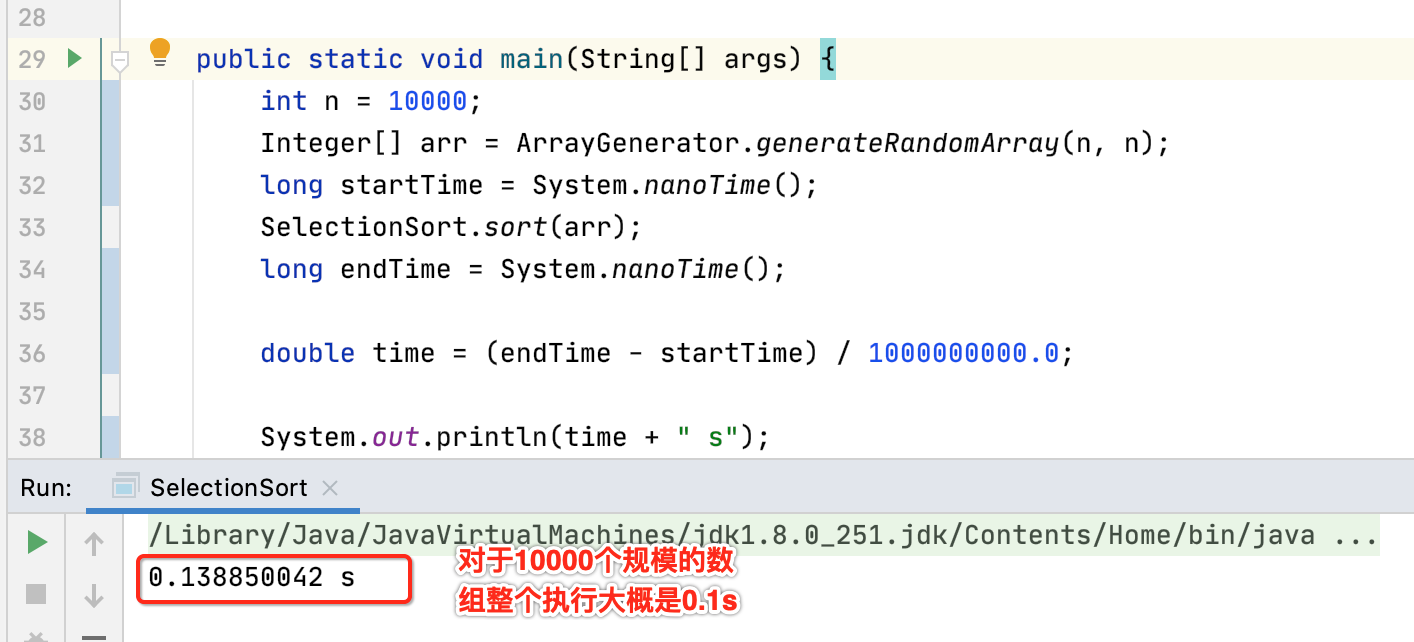
但是!!对于10000个数据你怎么能验证咱们的排序算法就是正确无误的呢?很明显无法用肉眼来观测了,有没有可能算法本身实现就有问题但是咱们只看到了一个执行时间,而且执行性能还特别的好,然后就感动自我了,基于此,很有必要需要用程序来验证一下咱们排序算法的正确性,那问题来了,怎么用程序来验证呢?其实很简单,只要遍历所有的元素,然后只要保证里面的元素是遵循“第一个元素都比它后面的一个元素要小”的原则如果都满足那肯定能证明整个排序是对的,所以咱们封装一个方法:
/** * 排序相关辅助工具类 */ public class SortingHepler { private SortingHepler() { } /** * 判断一个数组是否是有序的【从小到大排序】 */ public static <E extends Comparable<E>> boolean isSorted(E[] arr) { for (int i = 1; i < arr.length; i++) if (arr[i - 1].compareTo(arr[i]) > 0) return false; return true; } }
使用一下:
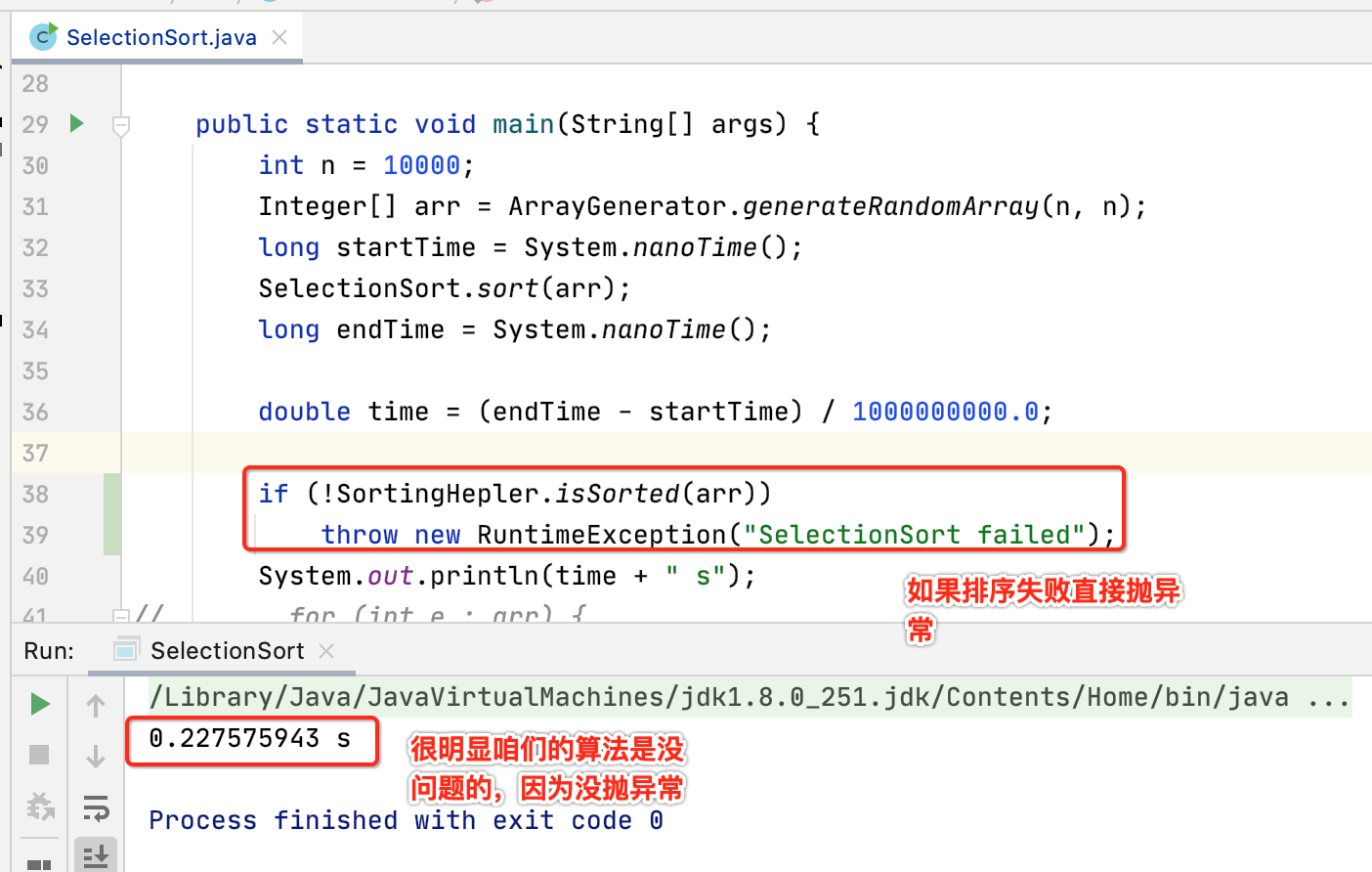
那为了验证没有排序的结果会抛异常,咱们将排序的这句代码注释掉再运行:
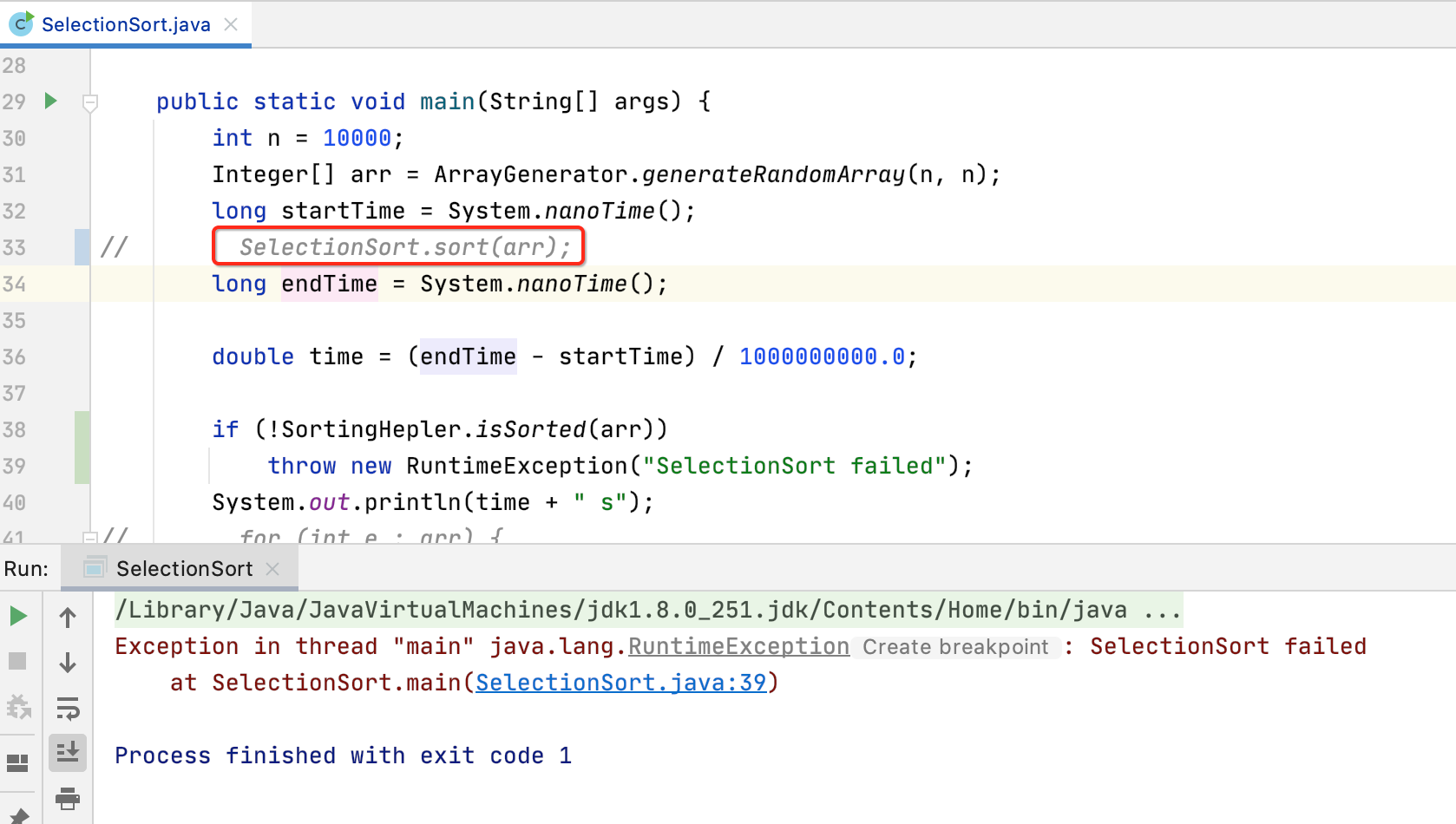
嗯,抛异常了,说明咱们封装的这个判断是否数组是有序的工具方法是没问题的,将这句注释的代码还是还原。
关于这块代码还可以继续改进,由于关于排序算法未来还有很多要学,为了能将测试算法性能的代码能为之后的学习进行复用,得抽取一下,将其放到SortingHelper当中,如下:
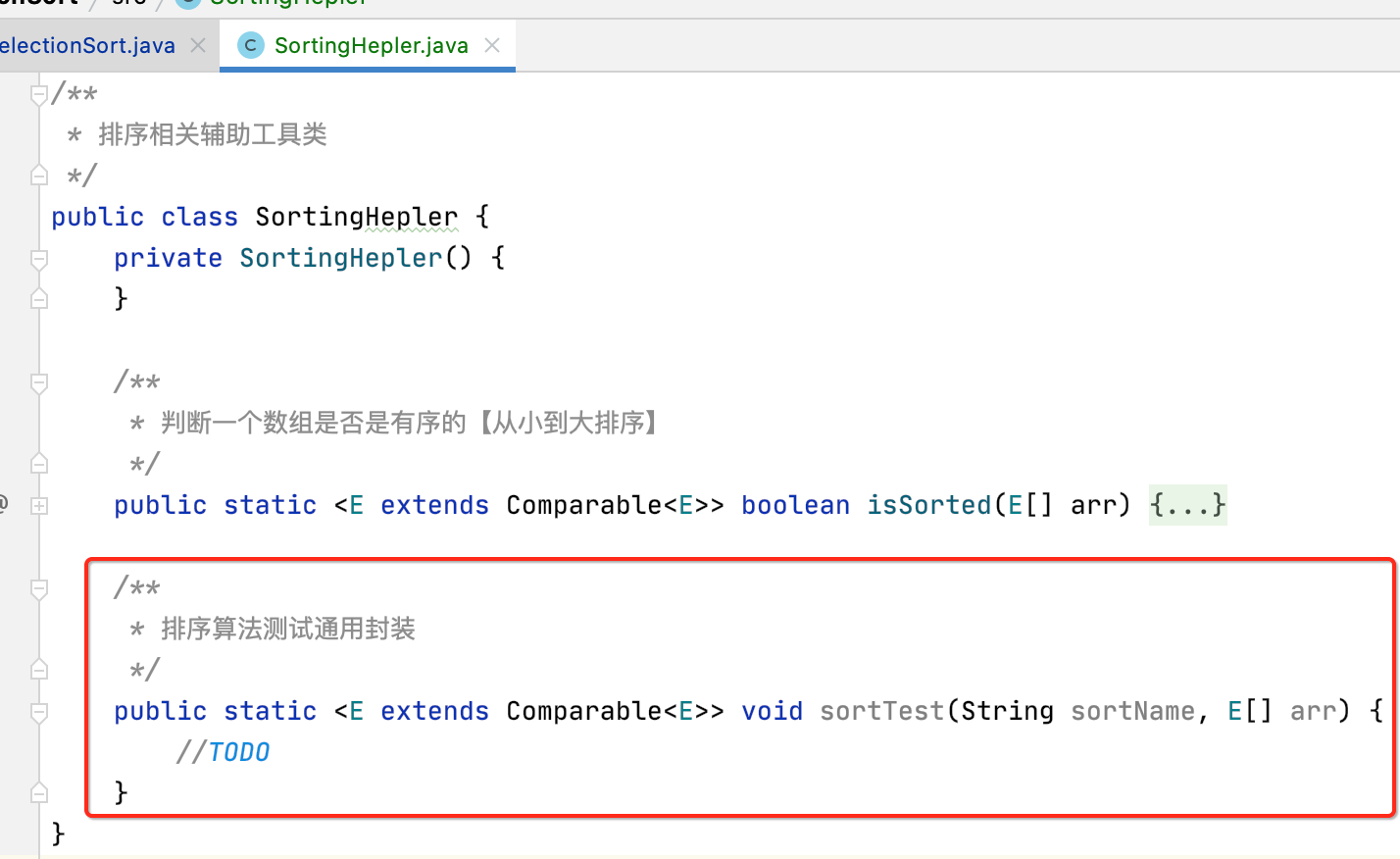
而它里面的实现咱们直接将这段拷贝过来:
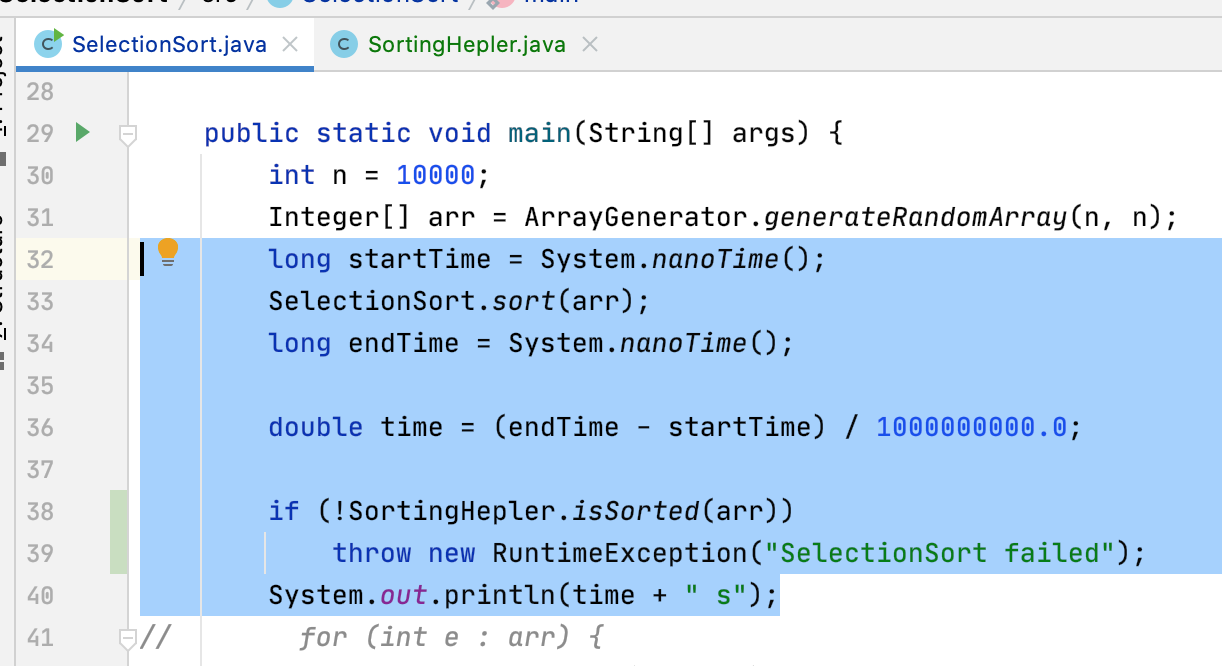
/** * 排序算法测试通用封装 */ public static <E extends Comparable<E>> void sortTest(String sortName, E[] arr) { long startTime = System.nanoTime(); SelectionSort.sort(arr); long endTime = System.nanoTime(); double time = (endTime - startTime) / 1000000000.0; if (!SortingHepler.isSorted(arr)) throw new RuntimeException("SelectionSort failed"); System.out.println(time + " s"); }
然后需要对其进行一些小调整:

对于上面这种判断的方式当然可以采取更加高级的方式比如利用反射来直接调用,但是这里的重点是研究算法而非研究java语法,所以这里就用比较low的方式能用就成,不能本末倒置了,继续完善:
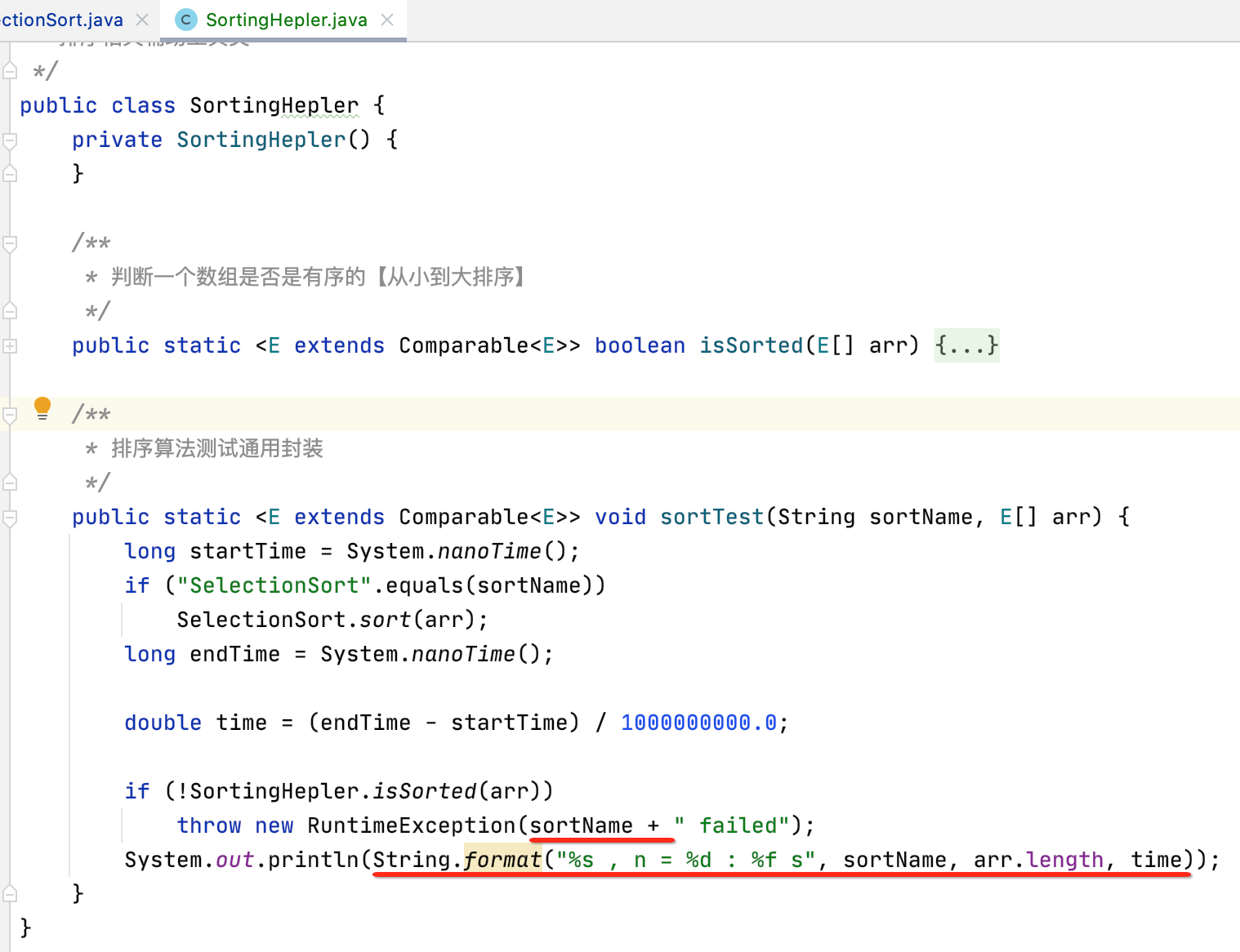
接下来调用一下:
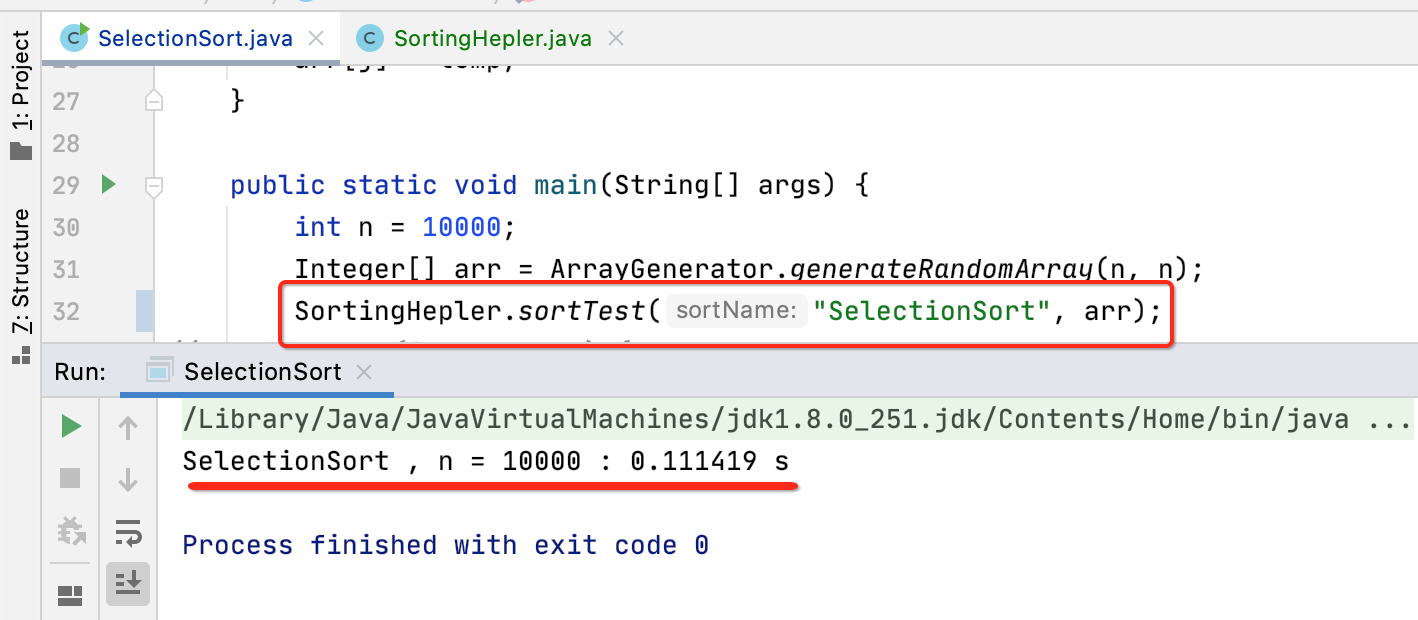
经过这样的封装之后,接下来可以很方便的进行多轮测试来验证咱们的时间复杂度是否如咱们之前所分析那样了,其实上一次也用过这种方式,代码如下:
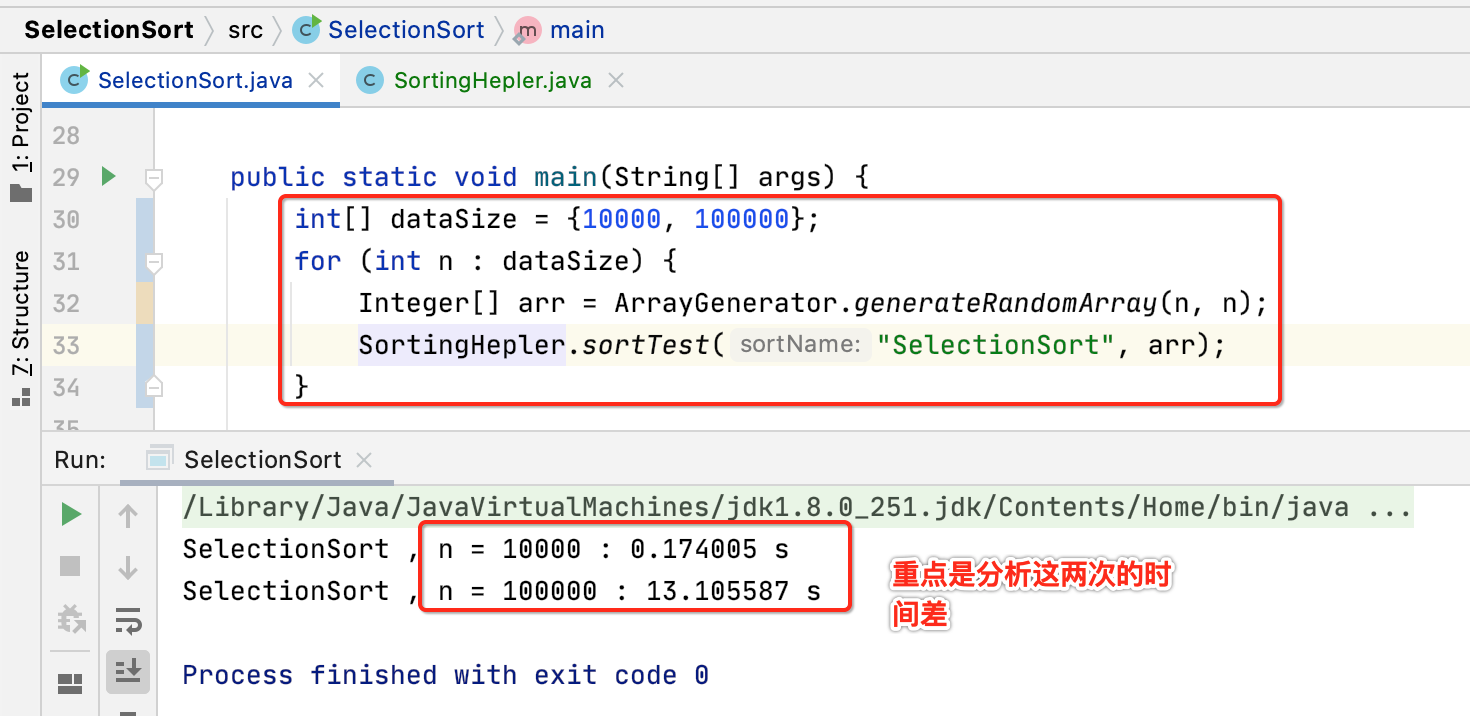
其中运行两次的n是差了10倍,而时间性能是差了13.10/0.17 = 77.058823529411765,但是不同的机子运行可能不一样,我的机子最差是大概90倍的样子,其实大概认为时间差是100倍,因为要往O(n^2)靠,也就是随着n的增大,它的时间复杂度是会往n^2级别进行增加,这样也能论证咱们所分析的时间复杂度是靠谱的。
换个角度实现选择排序法:
对于咱们目前实现的选择排序的循环不变量是“arr[0...i)是已排序,arr[i...n)是未排序”,那为了进一步巩固,咱们反过来实现一下,也就是将循环不变量【这个词啰嗦再多都不为过】改为“arr[i...n)是已排序,arr[0...i)是未排序”,其实非常之简单,下面来实现一下:
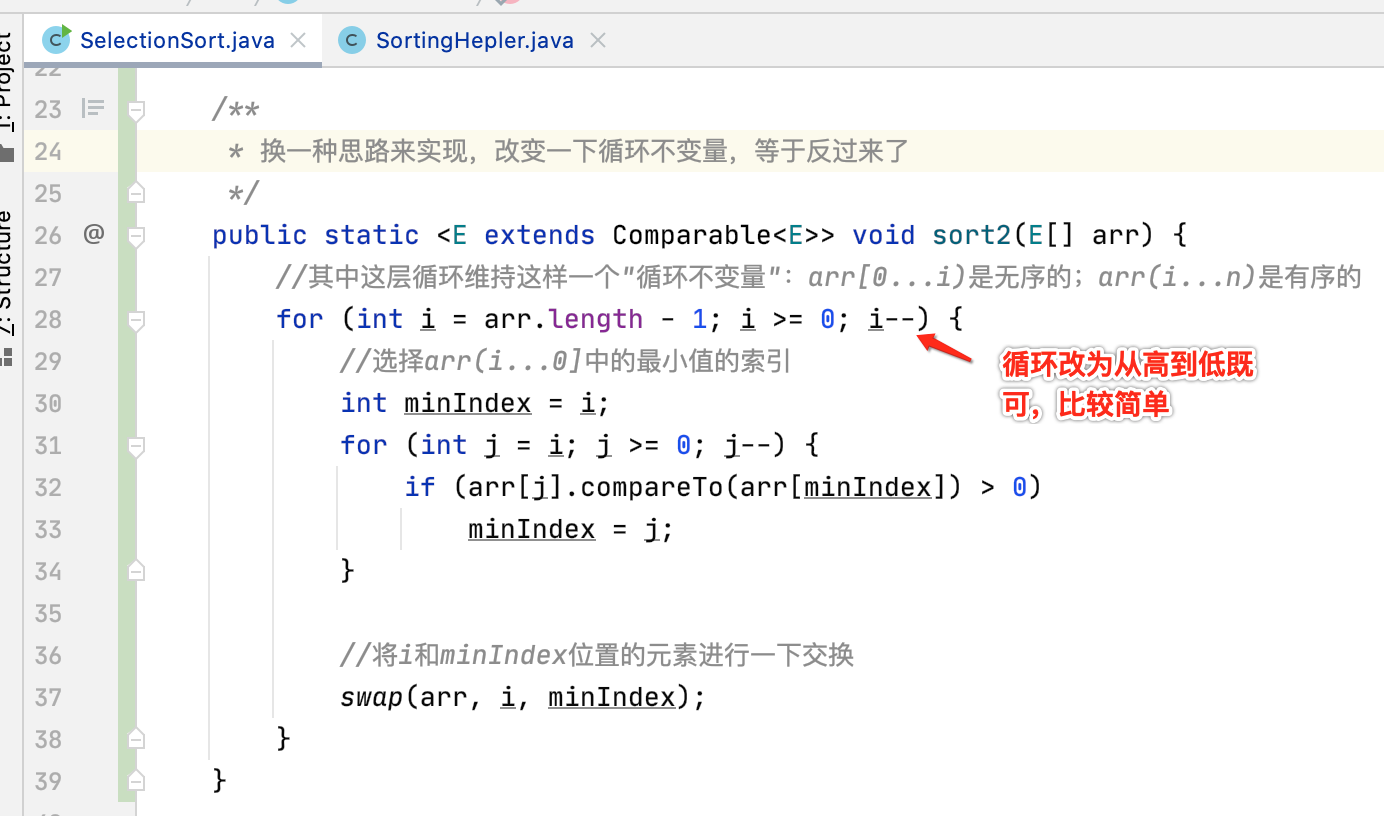
这里就不贴测试结果了,跟第一种是一模一样的效率。

