
大数据JavaWeb之MySQL基础----多表&事务&DCL
多表查询:
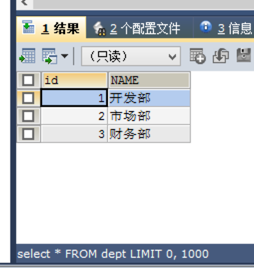
准备sql:
CREATE DATABASE db2; USE db2; # 创建部门表 CREATE TABLE dept( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20) ); INSERT INTO dept (NAME) VALUES ('开发部'),('市场部'),('财务部'); # 创建员工表 CREATE TABLE emp ( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(10), gender CHAR(1), -- 性别 salary DOUBLE, -- 工资 join_date DATE, -- 入职日期 dept_id INT, FOREIGN KEY (dept_id) REFERENCES dept(id) -- 外键,关联部门表(部门表的主键) ); INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('孙悟空','男',7200,'2013-02-24',1); INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('猪八戒','男',3600,'2010-12-02',2); INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('唐僧','男',9000,'2008-08-08',2); INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('白骨精','女',5000,'2015-10-07',3); INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('蜘蛛精','女',4500,'2011-03-14',1);

笛卡尔积:
笛卡尔积它是一个人名,是一个传大的数学家,先来百度百科一下:

什么是笛卡尔积现象?
需求:查询所有的员工和所有的部门,此时用到多表查询可以这样写:

结果分析:

那这样的数据其实查出来是有问题的,分析一下咱们查询的结果集:

所以总结一下:有两个集合A,B .取这两个集合的所有组成情况。此现象则为笛卡尔积。
此时就需要消除这种笛卡尔积这种现象。
如何清除笛卡尔积现象的影响?
我们发现不是所有的数据组合都是有用的,只有员工表.dept_id = 部门表.id 的数据才是有用的。所以需要 通过条件过滤掉没用的数据。这里就涉及到多表查询了,对于多表查询其实有几个分类,下面具体来学习一下,反正这块我很容易忘记,当时在面试时还被问到过外连接相关的东东。
多表查询的分类:

内连接查询:
用左边表的记录去匹配右边表的记录,如果符合条件的则显示。如:从表.外键=主表.主键。
- 隐式内连接:使用where条件消除无用数据。
1、查询所有员工信息和对应的部门信息:
2、查询员工表的名称,性别。部门表的名称。

但是实际写法会给表增加别名,因为有可能表名会比较长,所以正确的写法应该是这样:

- 显式内连接:
语法: select 字段列表 from 表名1 [inner] join 表名2 on 条件
咱们来试一下: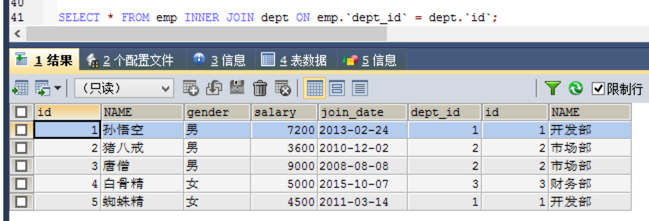
其中inner关键字是可以省略的:
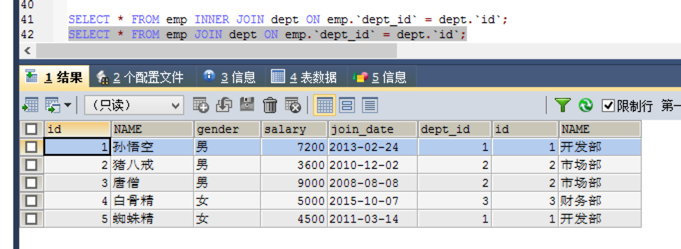
- 内连接查询总结:
1. 从哪些表中查询数据。
2. 条件是什么。
3. 查询哪些字段。
外链接查询:
- 左外连接:
语法:select 字段列表 from 表1 left [outer] join 表2 on 条件;
查询的是左表所有数据以及其交集部分。
例子:查询所有员工信息,如果员工有部门,则查询部门名称,没有部门,则不显示部门名称。
首先给表中增加一个没有部门的员工便于看到效果: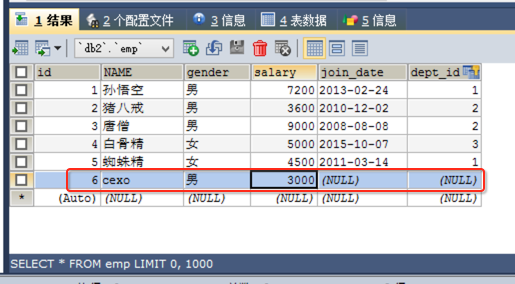
好,接下来实现一下:


- 右外连接:理解了左外连接之后,则理解右外顺其自然
语法:select 字段列表 from 表1 right [outer] join 表2 on 条件;
所以对于上面的SQL只将Left改为Right,看一下效果:用右边表的记录去匹配左边表的记录,如果符合条件的则显示;否则,显示 NULL,可以理解为:在内连接的基础上保证右表的数据全部显示。

所以执行结果为:

子查询:
- 概念:查询中嵌套查询,称嵌套查询为子查询。
比如我们要查询工资最高的员工信息,先不用子查询的步骤来实现一下:
1、查询最高的工资是多少 9000。
2、查询员工信息,并且工资等于9000的。

以上如果不用子查询则需要写二条SQL语句,而如果使用子查询一条就搞定了,如下:

- 子查询不同情况。
1. 子查询的结果是单行单列的:
子查询可以作为条件,使用运算符去判断。 运算符: > >= < <= =。
举例:查询员工工资小于平均工资的人:
2. 子查询的结果是多行单列的:
子查询可以作为条件,使用运算符in来判断。
举例:查询'财务部'和'市场部'所有的员工信息。
3. 子查询的结果是多行多列的:
子查询可以作为一张虚拟表参与查询。
举例:查询员工入职日期是2011-11-11日之后的员工信息和部门信息。
其实也可以用内连接来实现,如下:
多表查询练习:
先来重新创建一个数据库,新建若干个表用来进行多表查询的练习。
CREATE DATABASE db3; USE db3; -- 部门表 CREATE TABLE dept ( id INT PRIMARY KEY PRIMARY KEY, -- 部门id dname VARCHAR(50), -- 部门名称 loc VARCHAR(50) -- 部门所在地 ); -- 添加4个部门 INSERT INTO dept(id,dname,loc) VALUES (10,'教研部','北京'), (20,'学工部','上海'), (30,'销售部','广州'), (40,'财务部','深圳'); -- 职务表,职务名称,职务描述 CREATE TABLE job ( id INT PRIMARY KEY, jname VARCHAR(20), description VARCHAR(50) ); -- 添加4个职务 INSERT INTO job (id, jname, description) VALUES (1, '董事长', '管理整个公司,接单'), (2, '经理', '管理部门员工'), (3, '销售员', '向客人推销产品'), (4, '文员', '使用办公软件'); -- 员工表 CREATE TABLE emp ( id INT PRIMARY KEY, -- 员工id ename VARCHAR(50), -- 员工姓名 job_id INT, -- 职务id mgr INT , -- 上级领导 joindate DATE, -- 入职日期 salary DECIMAL(7,2), -- 工资 bonus DECIMAL(7,2), -- 奖金 dept_id INT, -- 所在部门编号 CONSTRAINT emp_jobid_ref_job_id_fk FOREIGN KEY (job_id) REFERENCES job (id), CONSTRAINT emp_deptid_ref_dept_id_fk FOREIGN KEY (dept_id) REFERENCES dept (id) ); -- 添加员工 INSERT INTO emp(id,ename,job_id,mgr,joindate,salary,bonus,dept_id) VALUES (1001,'孙悟空',4,1004,'2000-12-17','8000.00',NULL,20), (1002,'卢俊义',3,1006,'2001-02-20','16000.00','3000.00',30), (1003,'林冲',3,1006,'2001-02-22','12500.00','5000.00',30), (1004,'唐僧',2,1009,'2001-04-02','29750.00',NULL,20), (1005,'李逵',4,1006,'2001-09-28','12500.00','14000.00',30), (1006,'宋江',2,1009,'2001-05-01','28500.00',NULL,30), (1007,'刘备',2,1009,'2001-09-01','24500.00',NULL,10), (1008,'猪八戒',4,1004,'2007-04-19','30000.00',NULL,20), (1009,'罗贯中',1,NULL,'2001-11-17','50000.00',NULL,10), (1010,'吴用',3,1006,'2001-09-08','15000.00','0.00',30), (1011,'沙僧',4,1004,'2007-05-23','11000.00',NULL,20), (1012,'李逵',4,1006,'2001-12-03','9500.00',NULL,30), (1013,'小白龙',4,1004,'2001-12-03','30000.00',NULL,20), (1014,'关羽',4,1007,'2002-01-23','13000.00',NULL,10); -- 工资等级表 CREATE TABLE salarygrade ( grade INT PRIMARY KEY, -- 级别 losalary INT, -- 最低工资 hisalary INT -- 最高工资 ); -- 添加5个工资等级 INSERT INTO salarygrade(grade,losalary,hisalary) VALUES (1,7000,12000), (2,12010,14000), (3,14010,20000), (4,20010,30000), (5,30010,99990);

先在“架构设计器”来看一下这四张表之间的关系:

再来看一下各个表的数据:
dept:

emp:

job:

salarygrade:

好,接下来则开始进行操练了:
- 查询所有员工信息。查询员工编号,员工姓名,工资,职务名称,职务描述。
分析:
1.员工编号,员工姓名,工资,需要查询emp表;职务名称,职务描述 需要查询job表。
实现:
2.查询条件 emp.job_id = job.id。
- 查询员工编号,员工姓名,工资,职务名称,职务描述,部门名称,部门位置。
分析:使用内联查询
1. 员工编号,员工姓名,工资 需要查询emp表;职务名称,职务描述 需要查询job表; 部门名称,部门位置 需要查询dept表。
实现:
2. 条件: emp.job_id = job.id and emp.dept_id = dept.id。
- 查询员工姓名,工资,工资等级。
分析:
1.员工姓名,工资 需要查询emp表; 工资等级 需要查询salarygrade表。
实现:
2.条件 emp.salary >= salarygrade.losalary and emp.salary <= salarygrade.hisalary
或者:emp.salary BETWEEN salarygrade.losalary and salarygrade.hisalary。
- 查询员工姓名,工资,职务名称,职务描述,部门名称,部门位置,工资等级。
分析:
1. 员工姓名,工资 需要查询emp表 ; 职务名称,职务描述 需要查询job表; 部门名称,部门位置 需要查询dept表; 工资等级 需要查询salarygrade表。
实现:
2. 条件: emp.job_id = job.id and emp.dept_id = dept.id and emp.salary BETWEEN salarygrade.losalary and salarygrade.hisalary。
- 查询出部门编号、部门名称、部门位置、部门人数。
分析:
1.部门编号、部门名称、部门位置 需要查询dept表。 部门人数 需要查询emp表。
实现:
2.使用分组查询。按照emp.dept_id完成分组,查询count(id)。
3.使用子查询将第2步的查询结果和dept表进行关联查询。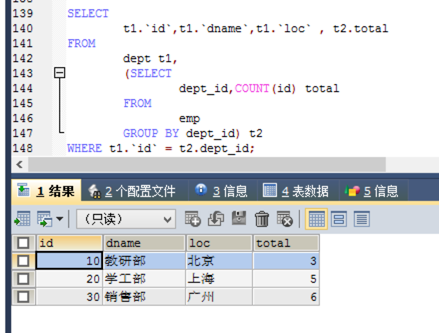
- 查询所有员工的姓名及其直接上级的姓名,没有领导的员工也需要查询。
分析:
1.姓名 需要查询emp表, 直接上级的姓名 需要查询emp表。
实现:
其中emp表的id 和 mgr 是自关联。
2.条件 emp.id = emp.mgr。
3.查询左表的所有数据,和 交集数据,很明显得使用左外连接查询。
首先查询所有员工的姓名及其直接上级的姓名,采用自关联,如下:
而在员工表中的所有记录中有一个员工木有领导,如下:

目前的SQL中只查询出了有领导的所有记录,那怎么来把没有领导的也查询出来呢?好,接下来再来看“没有领导的员工也需要查询”,很明显就需要左外连接了:
事务:
事务的基本介绍:
概念:
如果一个包含多个步骤的业务操作,被事务管理,那么这些操作要么同时成功,要么同时失败。
操作:
1. 开启事务: start transaction;
2. 回滚:rollback;
3. 提交:commit;
例子:
先创建一张表:
然后此时我们将所有账户的钱都更新到1000块钱:
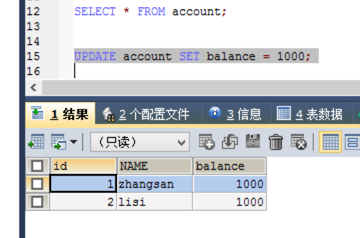
此时默认就会提交一次事务,数据会被持久化的更新,也就是如果其它数据库登录用户查看时也能立马看到这个1000的记录,而不会出现不同步的现象,这是属于自动化的事务提交,那如果我们要手动的来提交,则就需要手动来提交事务了,为了看到事务的效果,这里再开一个mysql客户端:
比如张三要准备给李四转500元钱:

此时看到在这个执行的客户端上能看到正常的银行账户的钱的更新了,但是此时由于事务还没有提交,所以另一个客户端上是看不到更新的,切到另一个客户端来查询一下:

此时则需要提交一下事务才能持久化到数据库中,如下:
此时对于另一个客户端查到的数据则就可以看到更新过后的了:

而假如对于这次事务在提交前有问题想回滚,则直接执行回滚既可:

MySQL数据库中事务默认自动提交:
事务提交的两种方式:
- 自动提交:
mysql就是自动提交的。
一条DML(增删改)语句会自动提交一次事务。 - 手动提交:
Oracle 数据库默认是手动提交事务。
需要先开启事务,再提交。
修改事务的默认提交方式:
- 查看事务的默认提交方式:SELECT @@autocommit; -- 1 代表自动提交 0 代表手动提交。
- 修改默认提交方式: set @@autocommit = 0;
事务的四大特征:
- 原子性:是不可分割的最小操作单位,要么同时成功,要么同时失败。
- 持久性:当事务提交或回滚后,数据库会持久化的保存数据。
- 隔离性:多个事务之间。相互独立。
- 一致性:事务操作前后,数据总量不变。
事务的隔离级别(了解):
概念:
多个事务之间隔离的,相互独立的。但是如果多个事务操作同一批数据,则会引发一些问题,设置不同的隔离级别就可以解决这些问题。
存在的问题:
- 脏读:一个事务,读取到另一个事务中没有提交的数据。
- 不可重复读(虚读):在同一个事务中,两次读取到的数据不一样。
- 幻读:一个事务操作(DML)数据表中所有记录,另一个事务添加了一条数据,则第一个事务查询不到自己的修改。
隔离级别:
mysql中有四种隔离级别:
1. read uncommitted:读未提交
产生的问题:脏读、不可重复读、幻读
2. read committed:读已提交 (Oracle默认)
产生的问题:不可重复读、幻读
3. repeatable read:可重复读 (MySQL默认)
产生的问题:幻读
4. serializable:串行化
可以解决所有的问题
注意:隔离级别从小到大安全性越来越高,但是效率越来越低
数据库查询隔离级别:
select @@tx_isolation;
数据库设置隔离级别:
set global transaction isolation level 级别字符串;
演示:
下面咱们用终端来登录一下mysql,然后还是以这个账号表为例进行隔离级别设置之后问题的展现:

接下来设备一下隔离级别为"read uncommitted":
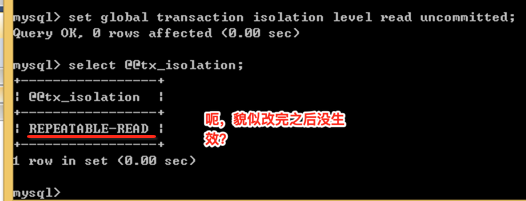
其实需要重新再连接一下,所以咱们关掉终端,再登录查询一下隔离级别:

好,接下来再开一个窗口,来演示设置成这种隔离级别带来的一个问题:

然后左边的窗口先来开启事务,并对账户的钱进行更新,注意,此时不要提交事务:

好,右边的窗口直接来查询一下,看是否能读到左边窗还未提交更新的数据?

好,更可怕的还在后面,此时左边窗口的并未提交事务,而是回滚了,也就是李四从张三那借了500块钱,最终回滚了打算赖账:
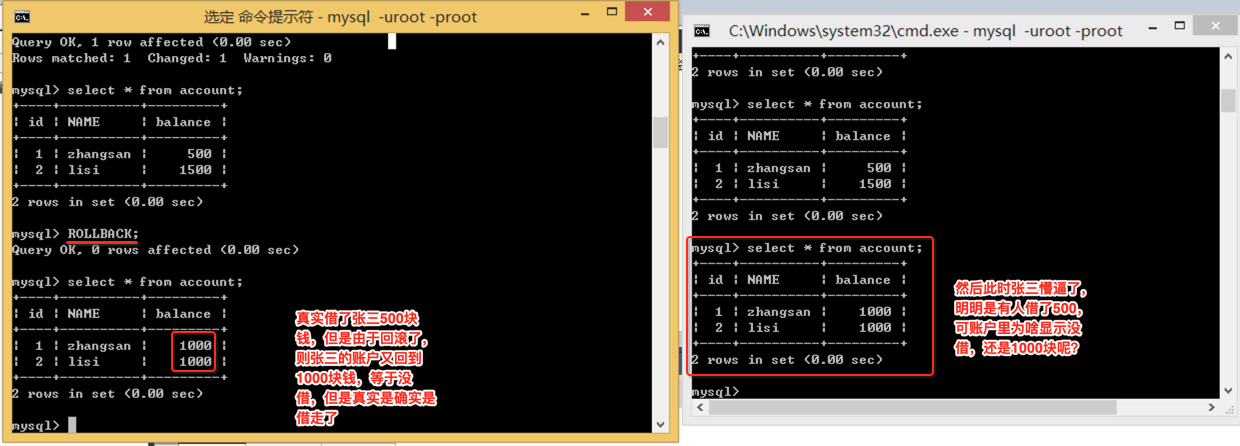
所以脏读就出现了,解决办法就是改变数据库的隔离级别:read committed

然后为了再看到效果,将里面的账户钱都改为1000:

为了能看到隔离级别生效了则需要重启一下终端:

此时在左边窗口中李四从张三那借500块钱:

此时要解决这个不可重复读的问题,则又要修改这种数据隔离级别了:repeatable read

此时为了生效依然将其重新登录一下,然后将账户都还原成1000,为了能看到效果。

好,左边的窗口开启事务,然后李四从张三那借了500块钱,但不提交:

而此时回到右边窗口,开启一下事务,然后读一次结果:
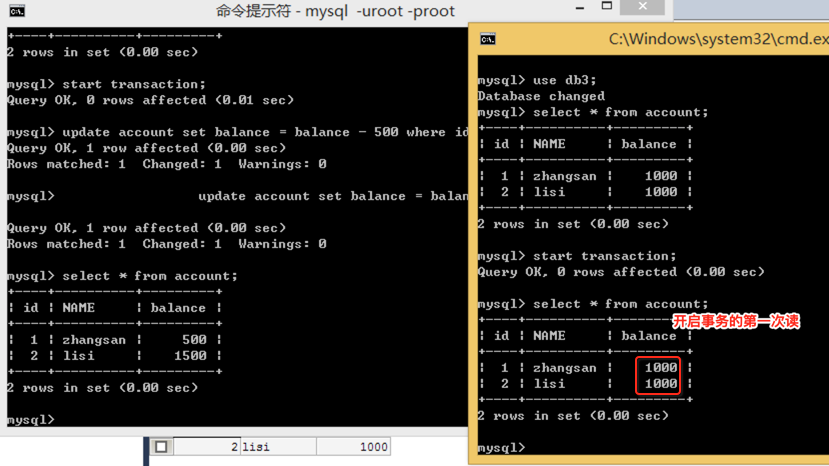
好,接下来左边窗口提交一下事务:

此时右边窗口将事务提交一下,则才可以看到左边窗口提交变化的情况了,如下:

好,还剩最后一种隔离级别,是安全级别最高的,但是也是性能最低的:serializable,下面也来演示一下:

然后左边开始进行转账:

如果左边事务不commit的话,则过一会就会有超时提示:

而如果左边正常提交的事务,那么右边阻塞的这个查询就会成功返回:

咱们还是将默认隔离级别改mysql默认的---repeatable read

DCL:
回顾一下SQL分类:
1. DDL:操作数据库和表
2. DML:增删改表中数据
3. DQL:查询表中数据
4. DCL:管理用户,授权【这块属于DBA的事,不过了解一下】
管理用户:
查询用户:
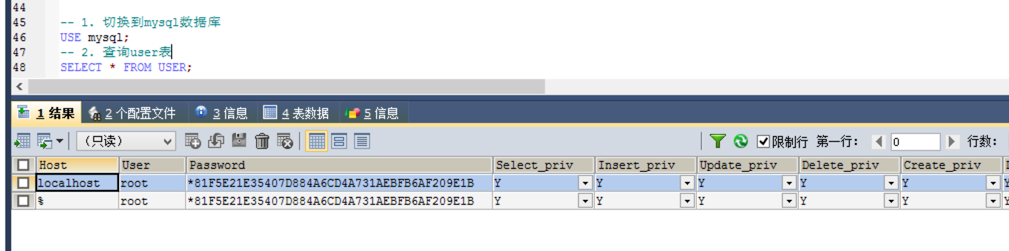
其中:通配符: % 表示可以在任意主机使用用户登录数据库
添加用户:
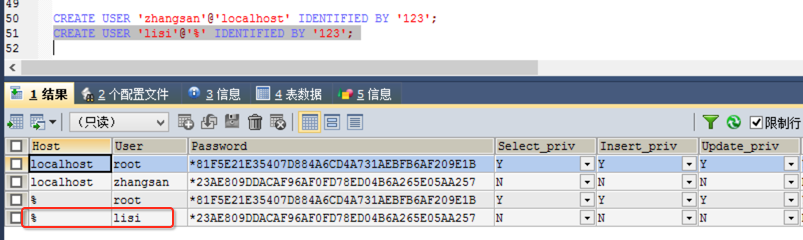
语法:CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
实践一下:

然后再创建一个任意主机都可以登录的账户:
然后咱们来用新建的账户登录一下,看是否好使:

删除用户:
语法:DROP USER '用户名'@'主机名';
实践下:

修改用户密码:
语法:UPDATE USER SET PASSWORD = PASSWORD('新密码') WHERE USER = '用户名';
下面咱们把lisi的密码由123改为abc,如下:

另外还有一种改密码的方式:
SET PASSWORD FOR '用户名'@'主机名' = PASSWORD('新密码');
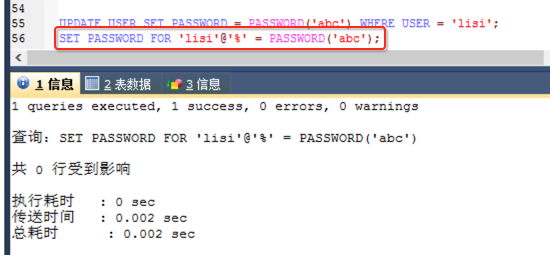
然后咱们试一下登录是否好使:
mysql中忘记了root用户的密码?
在实际使用中,一般都会用root用户来进行数据库操作,但是!!!实际中root密码如果忘记了该咋办呢?其实是有办法的,如下:
1. cmd -- > net stop mysql 停止mysql服务
需要管理员运行该cmd


2. 使用无验证方式启动mysql服务: mysqld --skip-grant-tables

3. 打开新的cmd窗口,直接输入mysql命令,敲回车。就可以登录成功
此时既然能登录mysql了,那则就可以改root的密码了嘛。
4. use mysql;

5. update user set password = password('你的新密码') where user = 'root';

6. 关闭两个窗口
7. 打开任务管理器,手动结束mysqld.exe 的进程

8. 启动mysql服务,还是得用管理员身份。
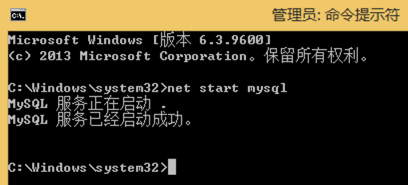
9. 使用新密码登录。

权限管理:
查询权限:
语法:SHOW GRANTS FOR '用户名'@'主机名';

上面的权限代码lisi只有登录mysql的权限,木有其它权限,咱们试一下登录之后的其它操作是否允许:

那咱们再查一下root用户都有啥权限呢?

可以看到它权限巨多。
授予权限:
语法:grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
好,下面咱们给李四来授予db3中的account表的查询权限,如下:

那咱们来验证一下权限是否生效了?

那如果要给表授予删除,更新权限,那不就得在授权限时再增加DELETE、UPDATE权限,那。。如果要给某个用户授予所有权限,就类似于root用户一样,那不在授权命令中写一大堆语句?其实这里有通配符来应对这种场景,如下:

咱们来登录一下:

撤销权限:
语法:revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';
之前我们给李四授予了db3中的account的查询权限,下面撤消一下:


此时就啥权限都木有了。
至此,mysql的学习就到此结束了,有很多是会的,也有很多是不会的,总之完整的对它进行一个梳理为将来更稳的学习大数据做了良好的铺垫,接下来则要学习JDBC相关的东东了,加油!!


