哈希表与树的入门
哈希表:
特点:
数组(顺序表):寻址容易
链表:插入与删除容易
哈希表:寻址容易,插入删除也容易的数据结构,也就是综合了上述两种数据结构的优点于一身。
Hash table:
定义:
哈希表(Hash table,也叫散列表)
是根据关键码值(Key value)而直接进行访问的数据结构,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
关键码值(Key value)也可以当成是key的hash值,这个映射函数叫做散列函数,是需要我们自己来设计的。
存放记录的数组叫做散列表。
例子:
上面的定义有点抽象,下面用一个例子来对它进行说明,比如有如下数据:
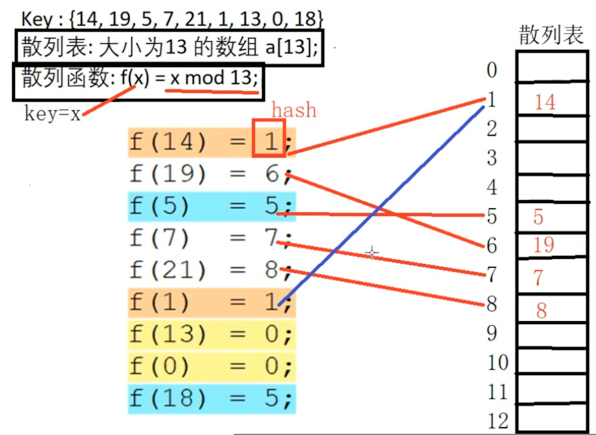
Key : {14, 19, 5, 7, 21, 1, 13, 0, 18}
散列表: 大小为13 的数组 a[13];
散列函数: f(x) = x mod 13;
所以根据散列函数我们可以算出每个Key对应的数组的位置,如下:

第一个值算出来它的key位置为1,所以:

则就将14存放在位置为1的散列表处,以此类推,再放第二个、第三个、第四个、第五个,如下:

对应散列表的分布为:

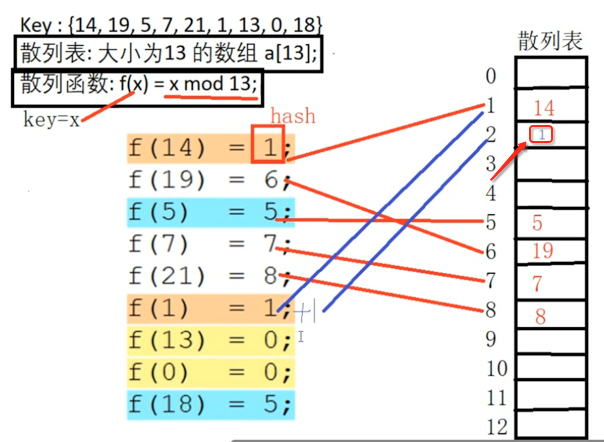
好,到了一个关键的值了:

此时就属于hash冲突了,那如何解决hash冲突则需要我们自己来制定规则,假如我们这样来定制冲突解决办法为:将hash+1,如果还是冲突则再+1,以此类推,所以此时的存放就为:
接下来再看一个更加极端的:

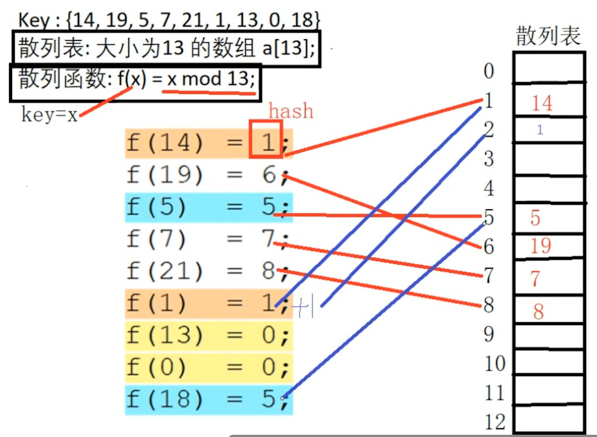
此时hash为5已经冲突了,所以hash+1=6:
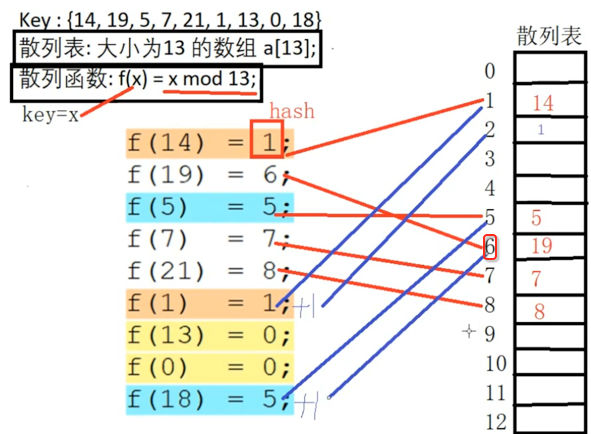
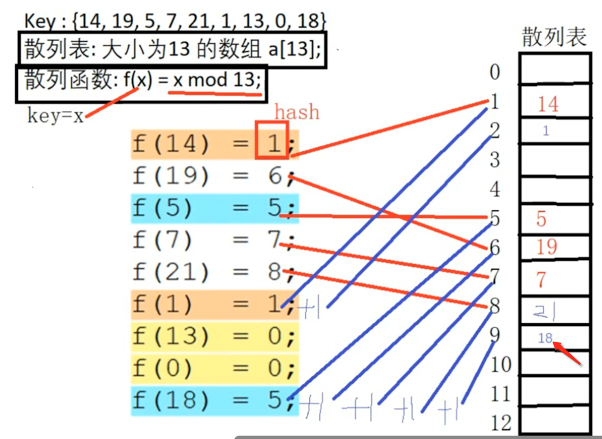
此时还是冲突了,继续hash+1=7,发现也冲突了,再hash+1=8,还是冲突,那就再hash+1=9,嗯,此时终于不冲突了则直接存放到这个位置:
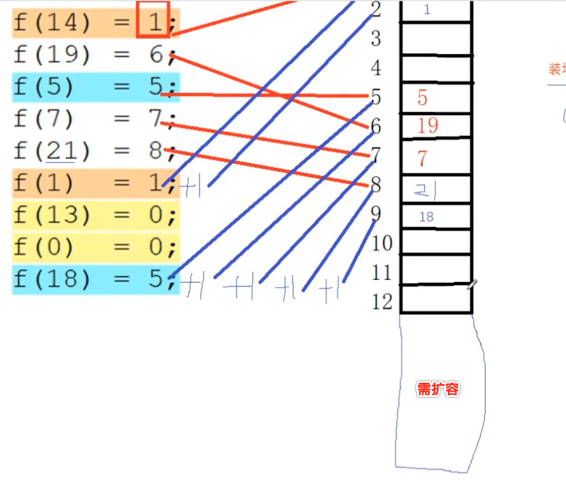
另外为了避免hash碰撞,需要引入装填因子这个概念,为什么需要这个值?因为数据越接近数组最大值,可能产生冲突的情况就越多,啥叫装填因子呢?比如说我们定义0.8的装填因子,还是拿上面的13个散列表的情况来说,当填到第9个位置时因为到达这个80%的空间了,所以接下来会给这个散列表进行扩容,具体扩大多少自己可以定义,如下:
缺点:
虽说它是综合了数组和链表的优点,但是它扩容需要消费大量的空间和性能,因为散列函数也需要发生变化:

散列函数一变,则存放到散列表中的下标都得重新进行计算,所以性能会大大受到影响。
应用:
电话号码,字典,点歌系统,QQ,微信的好友等,都有一个上限,就是为了避免散列表扩容导致性能有影响。
JDK中HashMap的散列表应用:
对于jdk1.8以前的HashMap是采用这种结构:
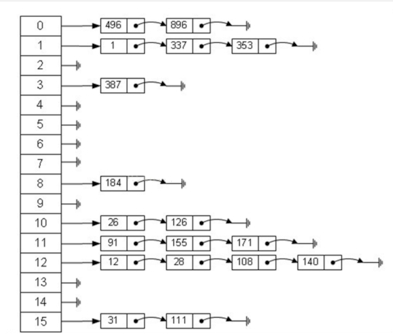
它是采用数组+链表来进行存放的,就不像之前我们解决Hash冲突时简单的去让hash+1了。我们来看一下通过这种结构想要查387这个数字其速度有多好,首先f(387)=3,则直接在3的位置来找到它的链表,然后第一个就找到了。
但是到了JDK1.8时,由于处于大数据的时代了,所以此时的HashMap的结构也发生了变化了,比如有1000万的数据,这样很可机率会出现某一个散列表位置的链表有几十万的数据,比如:
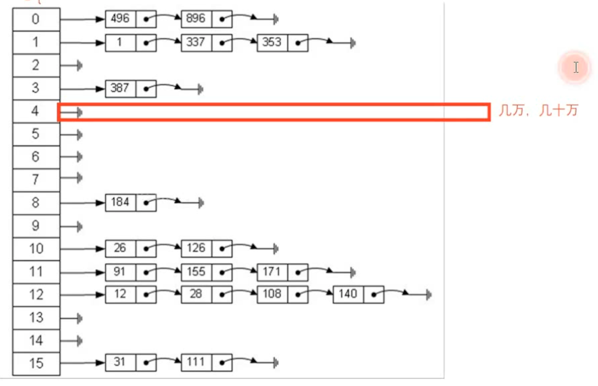
所以JDK1.8开始HashMap中当链表长度超过阈值,就转换成红黑树:
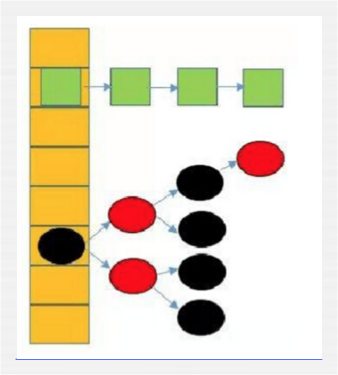
这里先有个概念,之外会专门去学红黑树的,反正就是数据量越大其查询的速度会变成级数级增长,效率是非常之高的。
关于HashMap的源码解读由于目前看还为时尚早,咱们先来贴一下它的resize()方法感受一下其难度:
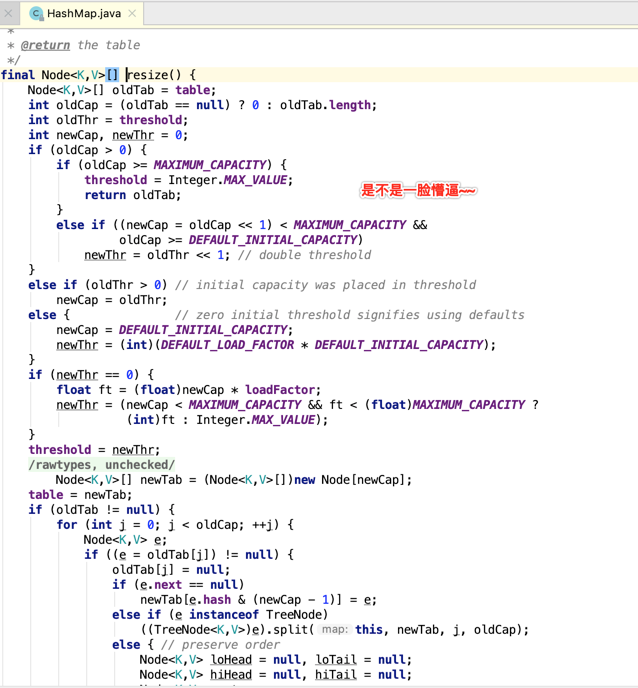
,很明显目前基础还没打牢,所以这里只先对Hash表做一个入门,在未来会将HashMap的源码实现给看透滴。
树:
什么树?

其中提到了“互不相交”,啥意思?下面看一下各种树:
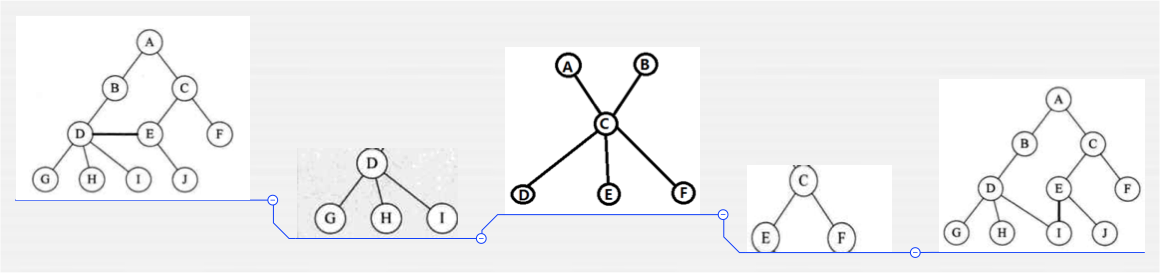
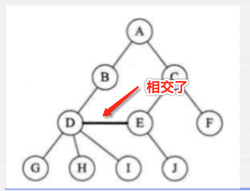
其中第一张图和最后一张图都有相交的情况,所以它就不属于树了,其它的都是属于树。

其实这俩是图的数据结构了,而非树。
树的概念【了解】:
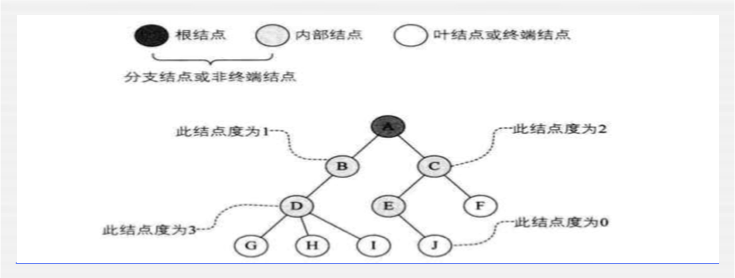
节点与树的度:
结点拥有的子树数称为结点的度。
度为0的结点称为叶子结点或终端结点,度不为0的结点称为非终端结点或分支结点。
除根结点以外,分支结点也称为内部结点。
树的度是树内各结点的度的最大值。
用图来表示下:
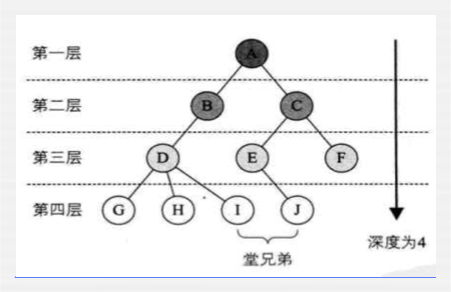
层次和深度:

森林:
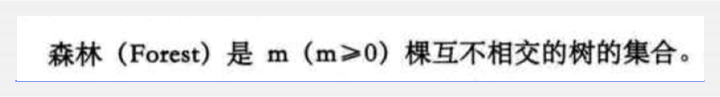
树的存储结构:
双亲表示法【在未来启发示寻路算法会用到它】:
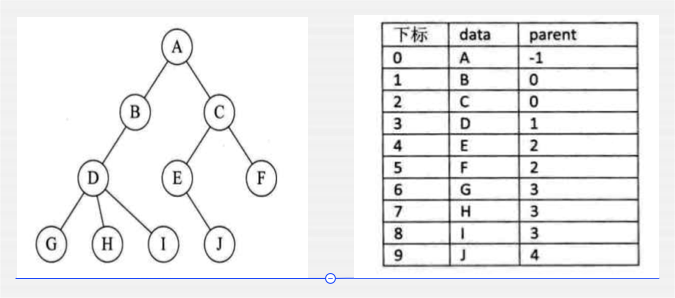
孩子表示法【二叉树典型的表示法】:
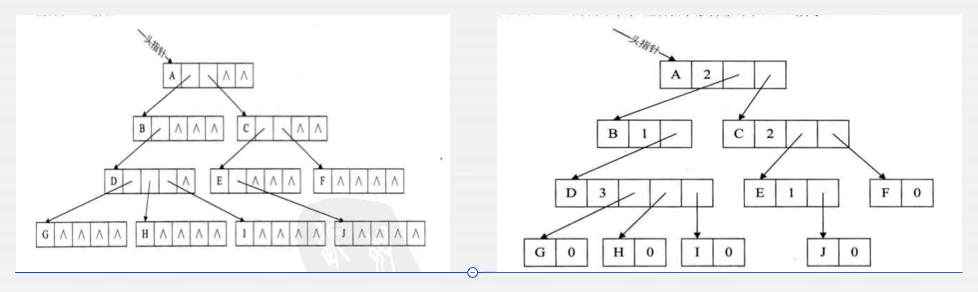
前面第一张比较浪费空间,而第二张则是优化版本。
双亲孩子表示法【用得少,了解】:
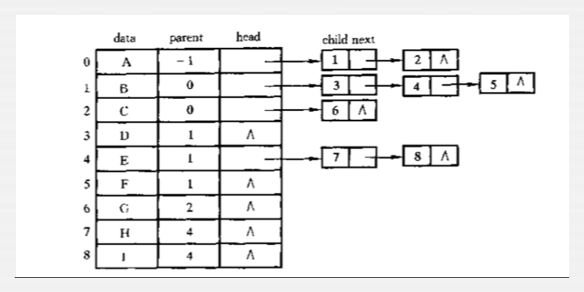
把每个结点的孩子结点排列起来,以单链表作为存储结构,
则n个结点有n个孩子链表,如果是叶子结点则此单链表为空,
然后n个头指针又组成一个线性表,采用顺序存储结构,存放在一个一维数组中
孩子兄弟表示法【用得少,了解】:
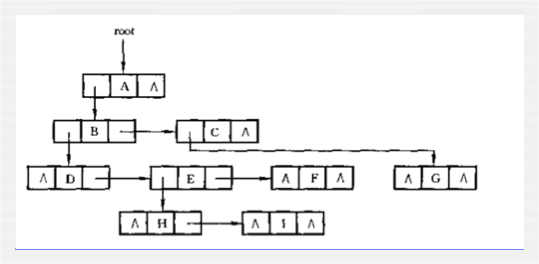
孩子兄弟表示法为每个节点设计三个域:
一个数据域,一个该节点的第一个孩子节点域,一个该节点的下一个节点的兄弟指针域
二叉树:
概念:


斜树:
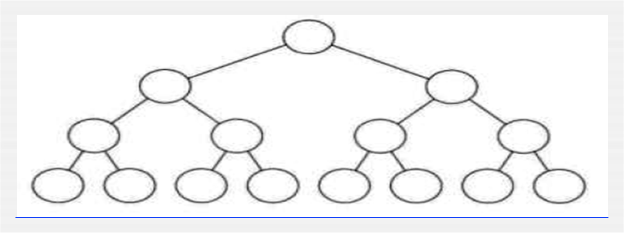
满二叉树:
一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
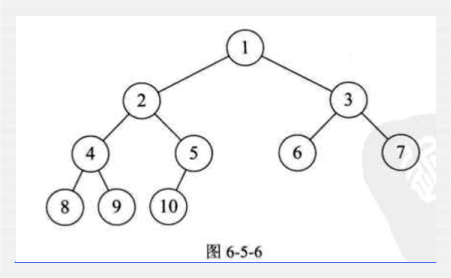
完全二叉树:
若设二叉树的深度为k,除第k层外,其他各层(1~(k-1)层)的节点数都达到最大值,且第k层所有的节点都连续集中在最左边,这样的树就是完全二叉树。如下图:
那判定一下下面三个树哪些是完全二叉树:
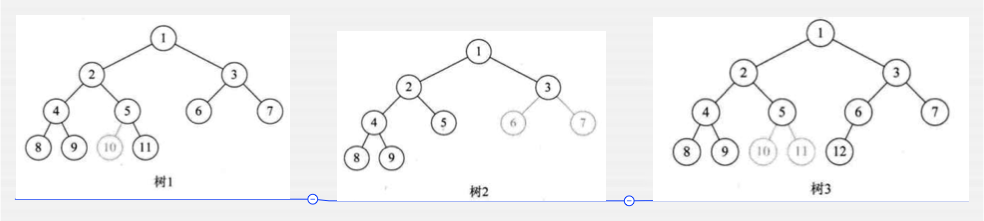
其实简单判断的办法就是看编号是否是连续的,由于树1缺了10之后,编号就不连续了,同样的树2少了6、7也不连续了,同样的树3也是少了10,11也不连续了,所以都不是完全二叉树了。
二叉树的存储结构:
顺序存储【用得少】:

链式存储【用得多】:
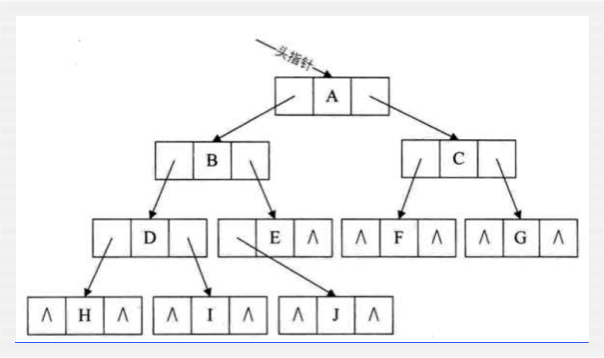
其实它表示的树的形态就为: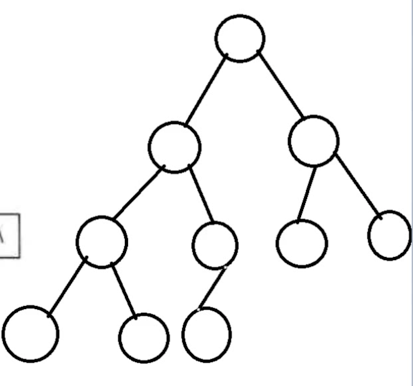
下面咱们用代码来构建一下二叉树,为下面的遍历做准备:
先定义树的结构体:
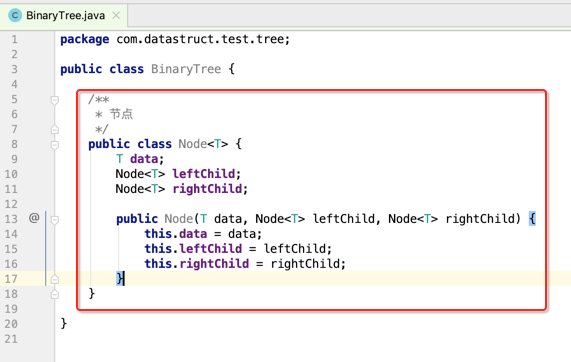
然后定义一个根结点:
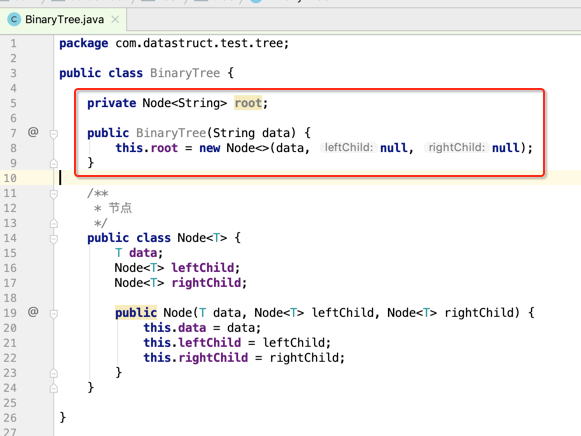
接下来咱们来生成这样一棵树:
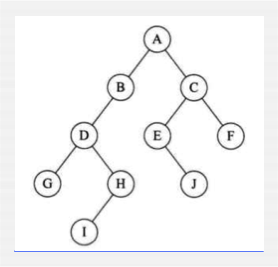
所以在里面定义一个生成树的方法:
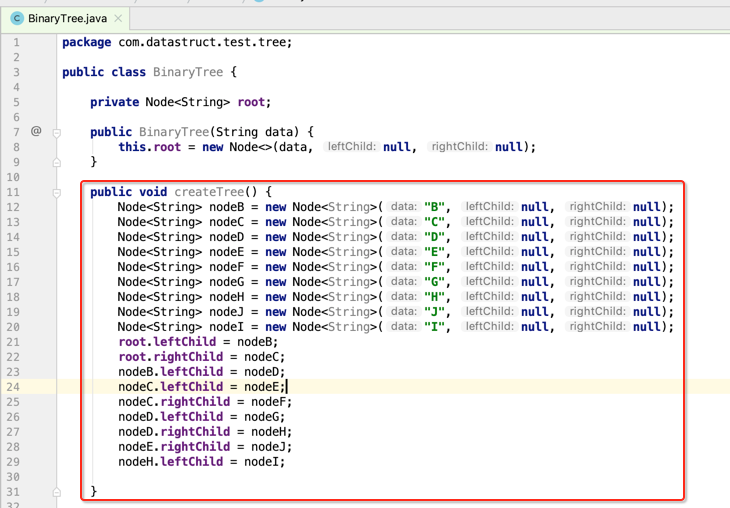
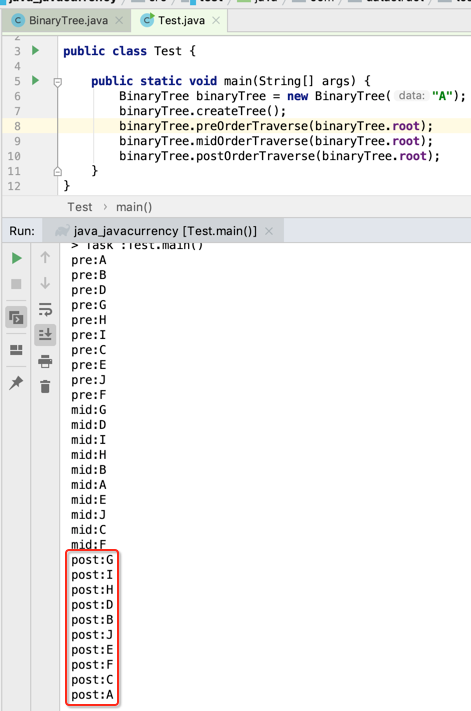
接下来咱们来调用生成树,可以如下:

那只调用了,木有输出呀,此时就需要往下看它的遍历方法了。
二叉树的遍历:
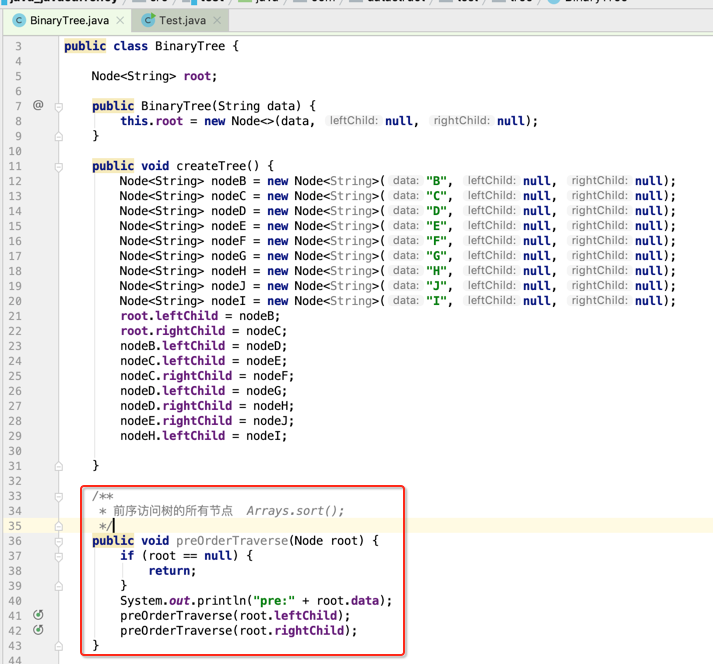
前序(DLR):
规则是若二叉树为空,则空操作返回,否则先访问跟结点,然后前序遍历左子树,再前序遍历右子树。
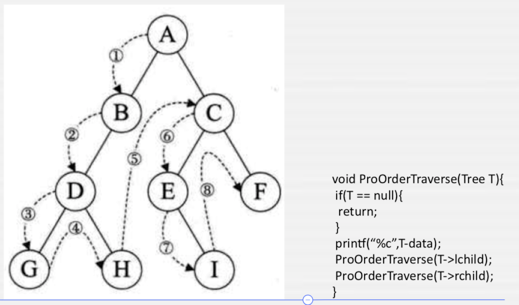
利用递归很容易实现,如下:
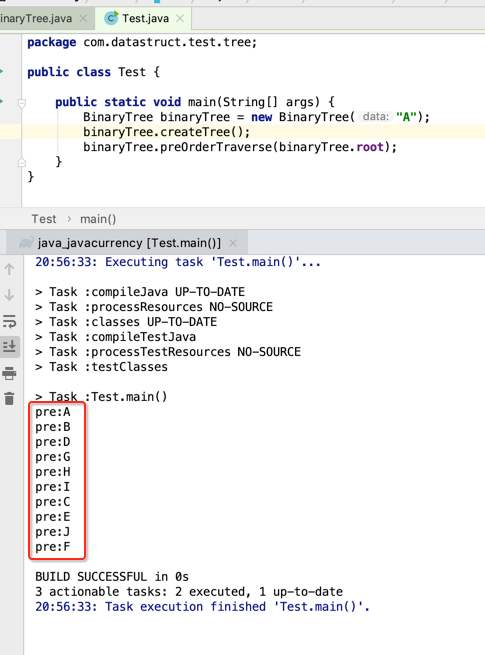
调用一下:
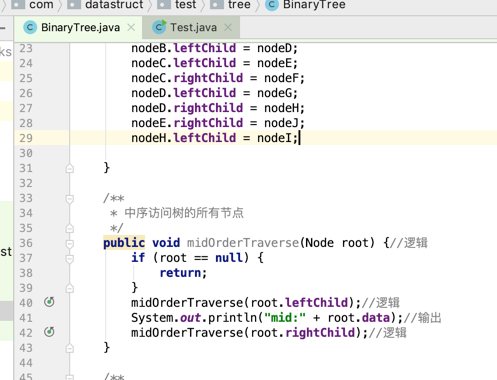
中序(LDR):
规则是若树为空,则空操作返回,否则从根结点开始(注意并不是先访问根结点),
中序遍历根结点的左子树,然后是访问根结点,最后中序遍历右子树。

咱们用代码来写一下:
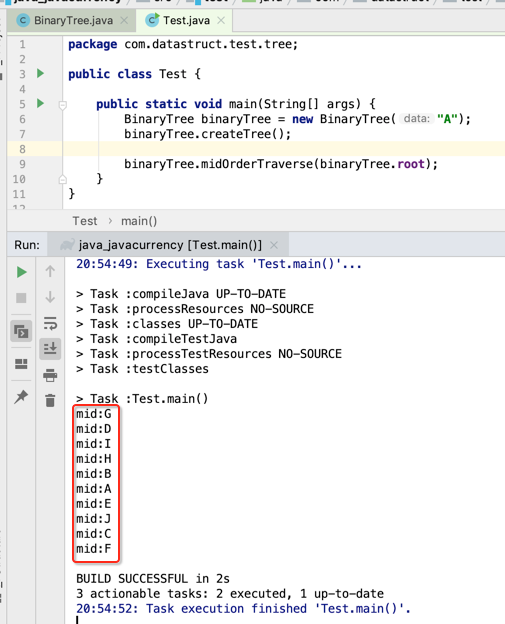
调用一下:
在上一次咱们写了个汉诺塔的小算法,其中提到了它其实就是二叉树的中序遍历,回忆一下:
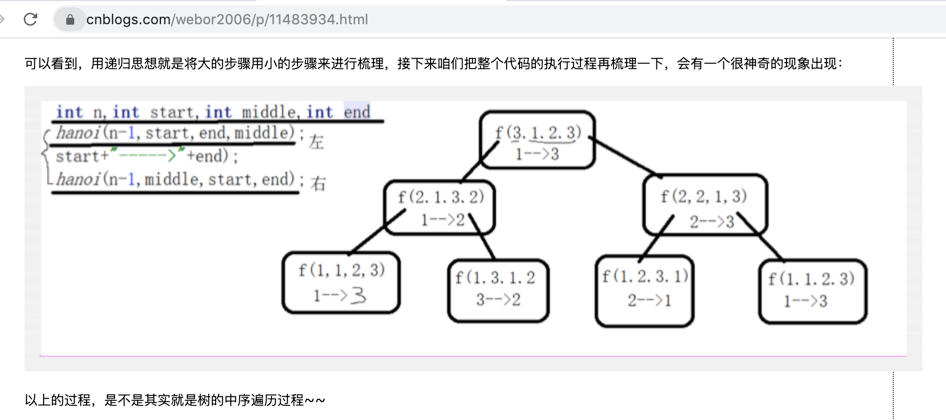
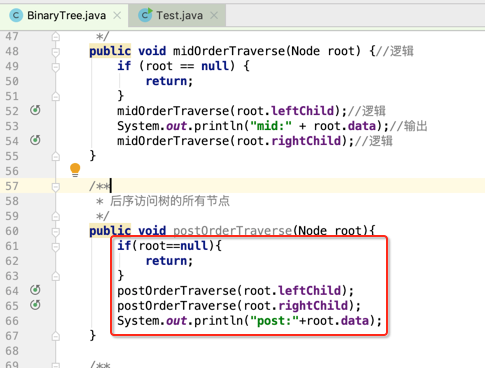
后序(LRD):
规则是若树为空,则空操作返回,否则从左到右先叶子后结点的方式遍历访问左右子树,最后是访问根结点。
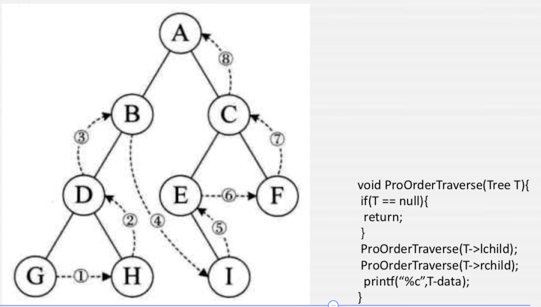
依葫芦画瓢: