


从OkHttp的源码来看 HTTP
先来了解一下OkHttp的历史,最早是square公司觉得Android给的HttpClient这块的库不太好用,于是乎做了一层包装,再后来他们包装的这个库被Android官方给收回去了,而Android内部的HttpUrlConnection的实现用的其实是OkHttp的代码,而Okhttp是完全重新写的一套HTTP库,包含TCP、TLS的实现,最初是依赖于Google的那套网络框架,而现在完全不依赖了,最终还被Google给收购了,所以,好好了解OkHttp的本质是毋庸置疑的。
先上一下OkHttp的官网瞅下:
看一下它的简单用法:

好,咱们还是以上一节【https://www.cnblogs.com/webor2006/p/10502230.html】获取github的仓库为例,简单用一下OkHttp,如下:
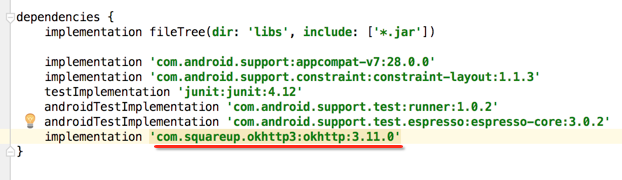
首先增加OkHttp的依赖:
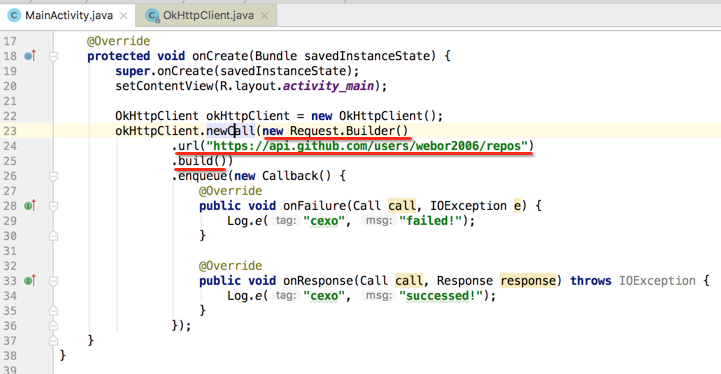
然后来访问这个接口“https://api.github.com/users/webor2006/repos”为例,看下OkHttp是如何来请求的:
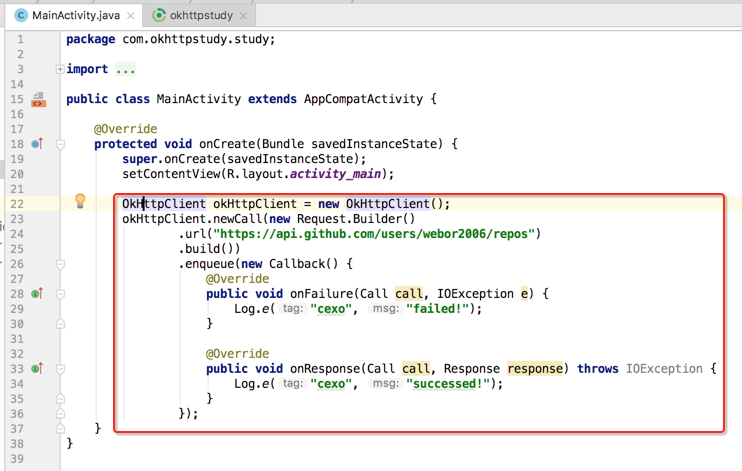
运行一下:

其实原因是在build中木有指定Java的编译版本为Java8导致,因为OkHttp库中如今用到了Lambda表达式,所以指定一下:

再次运行:

ok,关于用法就到这,关于OkHttp的具体使用这里就不详细赘述啦,用一用就会了,重点是分析它的原理机制,直接开始看源码了,首先先看下它:
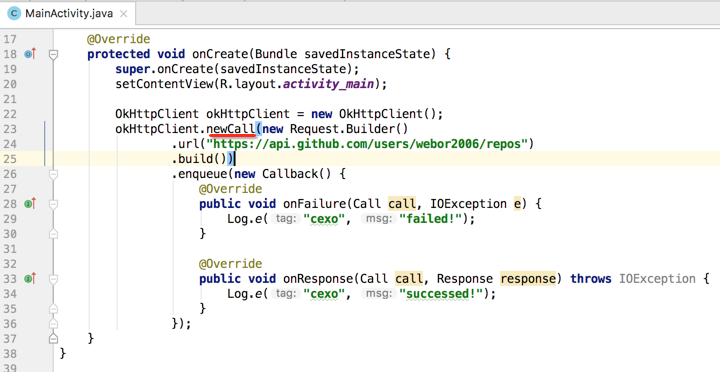
其中Request又是采用Builder模式来构建的,真的是无处不见Builder模式:
点进去看一下源码:
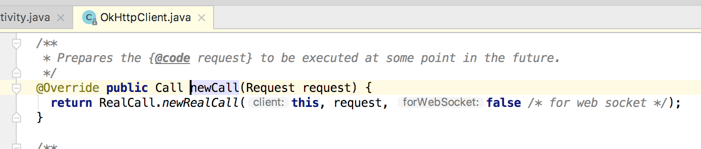
可以发现是由RealCall来返回的,很明显RealCall是Call的具体实现,所以点击RealCall.newRealCall看下它的源码:
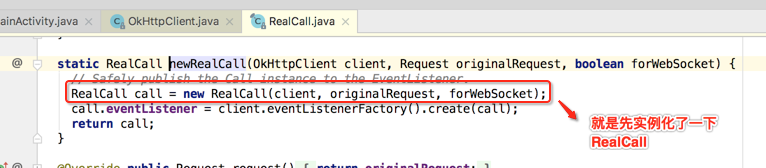
其中为啥第二个参数名叫originalRequest,也就是在之后会对这个Request进行转型,所以这是一个最初始的状态;第三个参数涉及到了WebSocket,那啥叫WebSocket呢,百度百科一下:
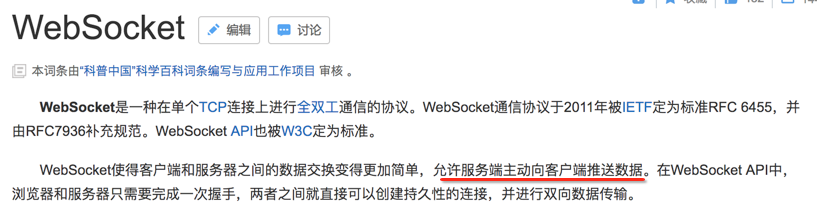
也就是说它其实是HTTP的一种扩展,正常的HTTP服务器端是不可能主动给客户端消息推送的,而WebSocket一般是炒股交易的软件会用,因为消息会比较实时,通常软件 是不会用到它的,了解一下既可。
接下来再继续:
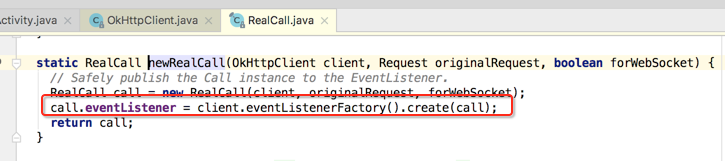
那这个eventListener有啥用呢?HTTP请求过程中有各种状态,如TCP连接、SSL连接、请求等状态,它主要是用来记录这些状态用的,不重要,貌似这个方法比较简单,接着来就需要分析一下它了:

走进去:
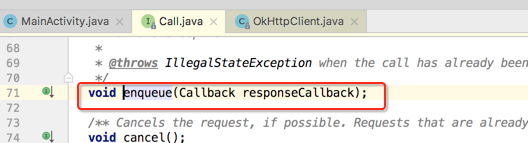
很明显它的实现应该是在RealCall里面如下:

分析核心代码,首先调用eventListener中的一个状态方法:
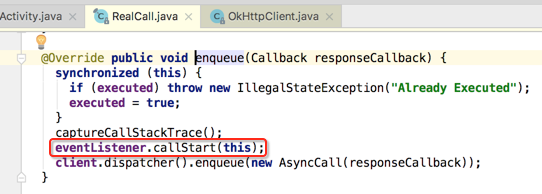
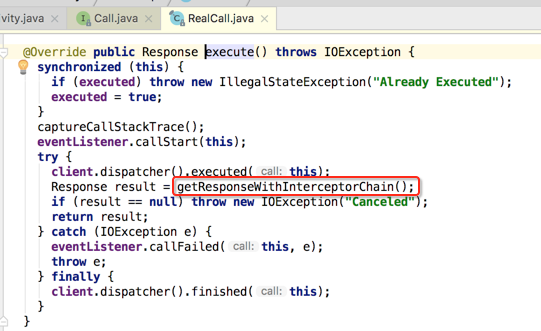
然后接下来一句就是核心代码了:
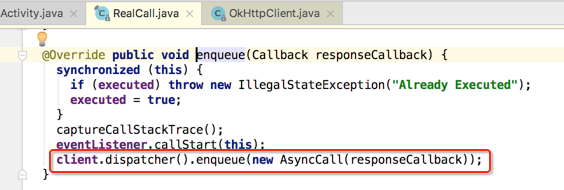
这句代码涉及到三个东东:dispatcher()、enqueue()、AsyncCall,所以分别来了解一下:
dispatcher():
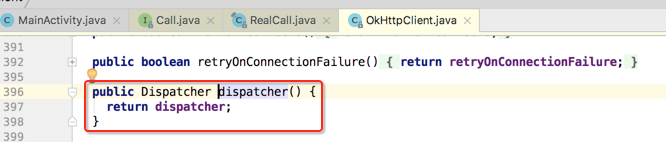
那瞅一下Dispatcher类:

而它用到了线程池:
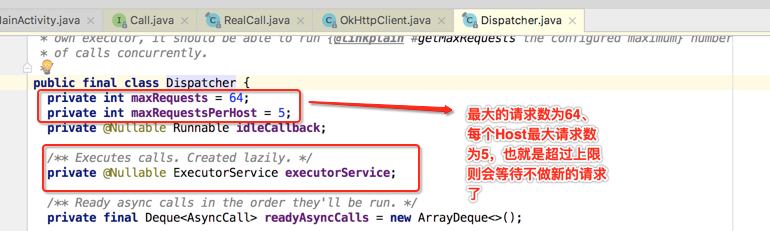
假如想要所有的请求一个个先后执行,那只要将上面的max设置为1既可。
enqueue():
接下来则看一下它的源码:
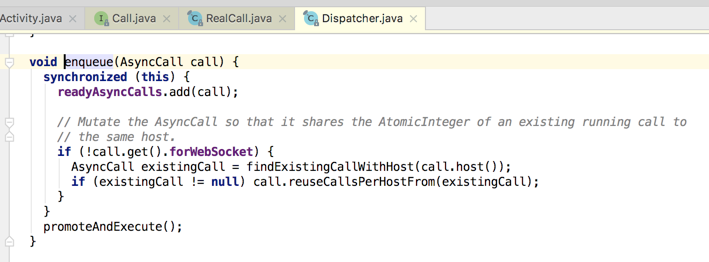
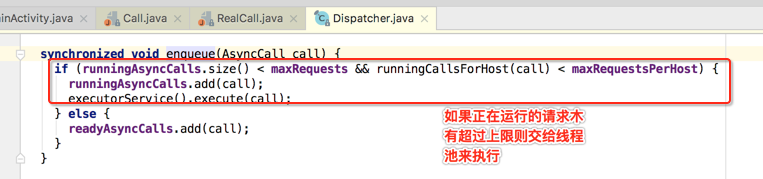
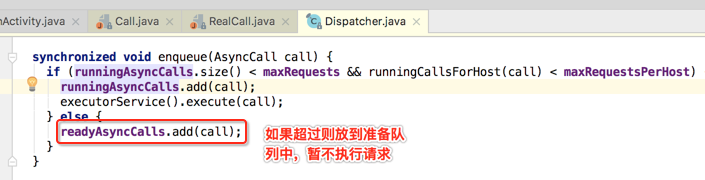
这里有三个队列定义于Dispatcher类中,如下:
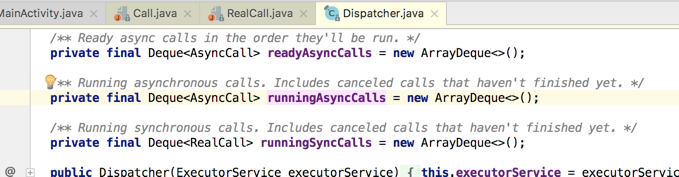
所以说Dispatcher类就是一个任务调度类。
AsyncCall:
enqueue方法参数中还涉及到此类,先来瞅一下:
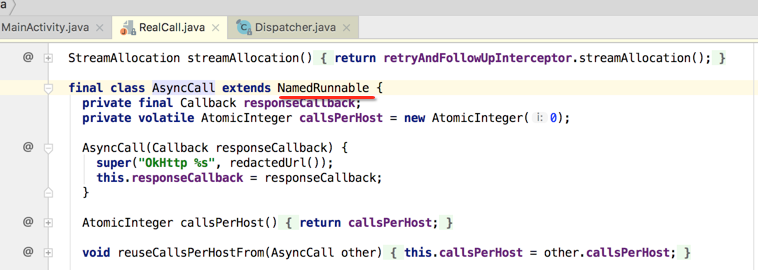
貌似对于Runnable应该里面会有一个run()方法吧,可AsyncCall中木有看到,如它的结构所示:
那有可能定义在它的父类NamedRunnable中,所以瞅一下:

final class AsyncCall extends NamedRunnable { private final Callback responseCallback; private volatile AtomicInteger callsPerHost = new AtomicInteger(0); AsyncCall(Callback responseCallback) { super("OkHttp %s", redactedUrl()); this.responseCallback = responseCallback; } ... @Override protected void execute() { boolean signalledCallback = false; timeout.enter(); try { Response response = getResponseWithInterceptorChain(); if (retryAndFollowUpInterceptor.isCanceled()) { signalledCallback = true; responseCallback.onFailure(RealCall.this, new IOException("Canceled")); } else { signalledCallback = true; responseCallback.onResponse(RealCall.this, response); } } catch (IOException e) { e = timeoutExit(e); if (signalledCallback) { // Do not signal the callback twice! Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e); } else { eventListener.callFailed(RealCall.this, e); responseCallback.onFailure(RealCall.this, e); } } finally { client.dispatcher().finished(this); } } }
那这里面应该就是整个请求处理的关键,下面来搞定它:

不过这里暂且不深入分析它,先来总结一下enqueue()的整个流程:它会去调用Dispather.enqueue()方法,而这个方法会生成一个AsyncCall对象,最终会执行AsyncCall.execute()方法,然后最终再真正请求给出结果反馈。
另外对于OkHttp的经典使用除了enqueue()异常请求之外,还有一个execute()方法,它是同步的,也来大致瞅一下它的实现:
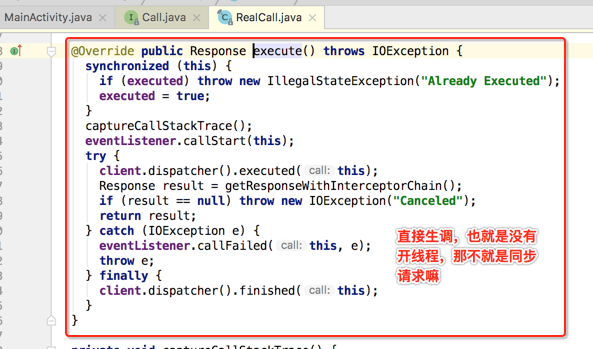
也就是enqueue()和execute()就是是否是同步的区别而已。
好,接下来则需要研究两个东东了:
一是OkHttpClient在实用角度(理解OkHttp跟Http的关系)需要理解一下它的配置项;
二是上面提到的拦截链。
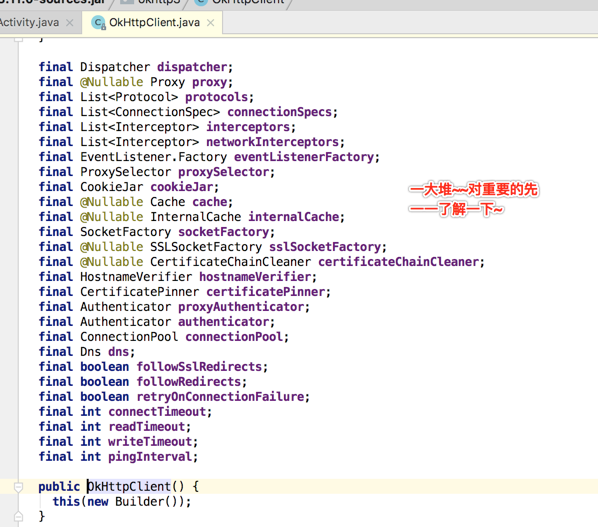
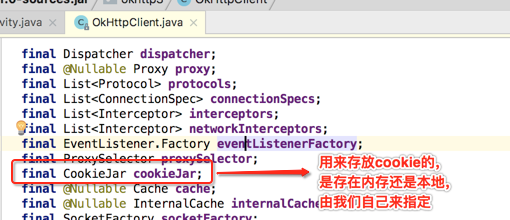
好,先来瞅一下OkHttpClient这个类:
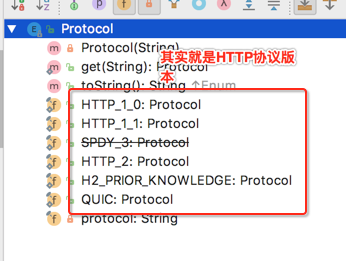
这个就是客户端告诉OkHttp支持HTTP的版本,就像浏览器能支持HTTP1.0、HTTP1.2,这个属性就是干这个用的。
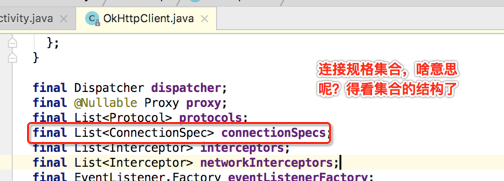
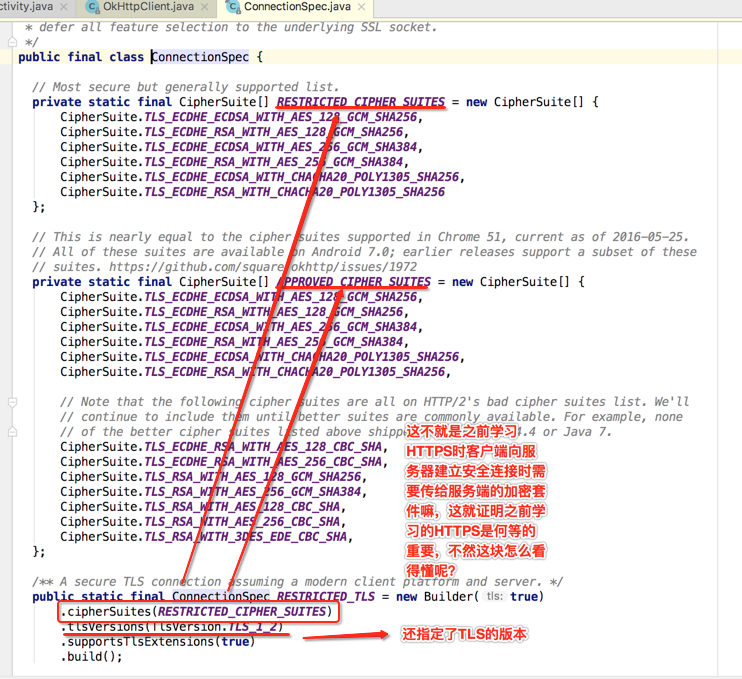

所以这个是告诉OkHttp是否支持HTTP,还是支持HTTPS,而HTTPS要怎么支持,也就是对于HTTP的底层支持OkHttp全部都实现了,这就可以看出跟Retrofit的一个区别了,好,继续!
关于这俩在之后再详说,跟拦截器链有关,往下继续:

这个还记得么,回顾一下:

也就是它是用来创建eventListener的东东,往下:

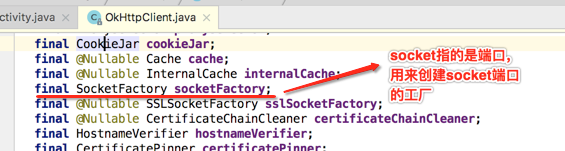
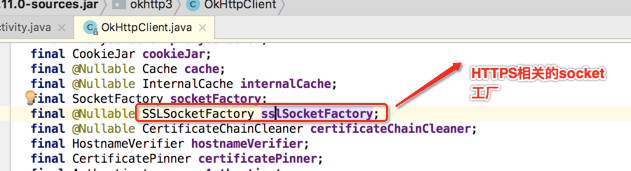
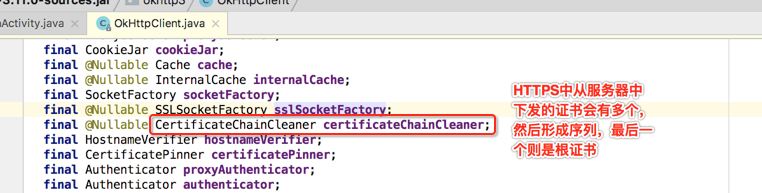
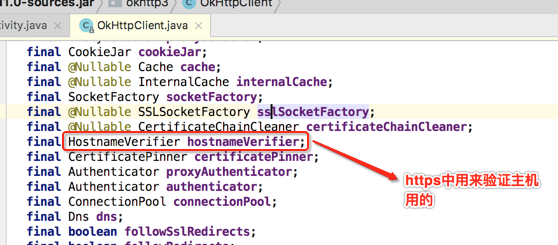
关于它的使用场景在之前HTTPS中已经学习过了,这里简单点击瞅一下:

它是JDK中的接口,其中OkHttp的实现如下:
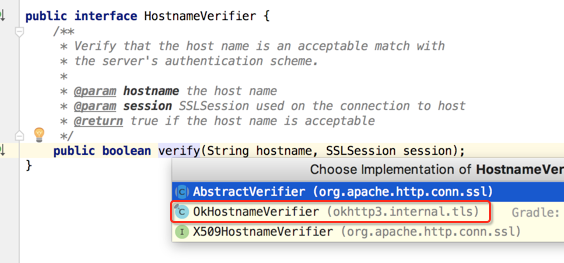
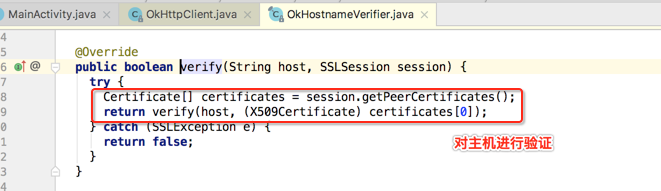
就不细看了,继续往下看:
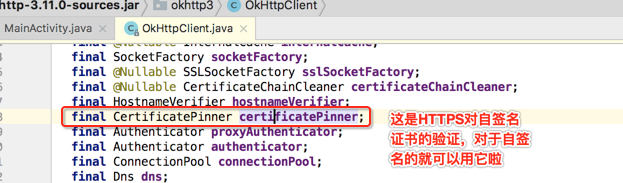
对于有自签名的需求用它是非常合适的,这里来简单了解一下它的用法,文档上有描述,如下:
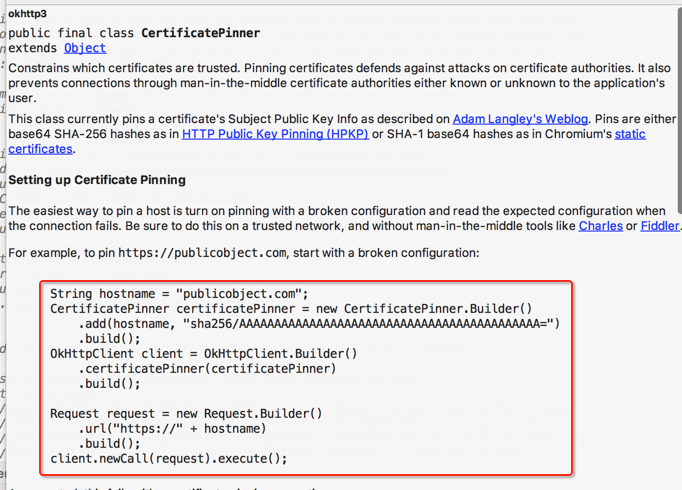
咱们来贴过来试一下:

其中增加了一个验证的选项,这样就不会使用本地根证书进行验证了,就会使用咱们自己的验证方式了,如下:
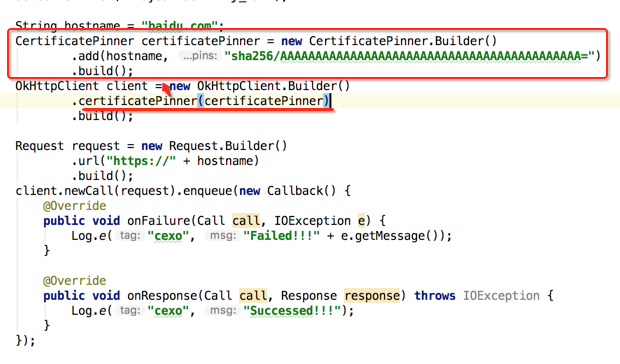
此时肯定会验证失败,运行如下:
03-15 23:01:48.172 24248-24267/com.okhttpstudy.study E/cexo: Failed!!!Certificate pinning failure! Peer certificate chain: sha256/uL6J3XldY7njtfGsRP7HZgYsrNPrDZXpG7kT7wfg1m0=: CN=www.baidu.cn,OU=service operation department,O=BeiJing Baidu Netcom Science Technology Co.\, Ltd,L=Beijing,C=CN sha256/5kJvNEMw0KjrCAu7eXY5HZdvyCS13BbA0VJG1RSP91w=: CN=DigiCert SHA2 Secure Server CA,O=DigiCert Inc,C=US sha256/r/mIkG3eEpVdm+u/ko/cwxzOMo1bk4TyHIlByibiA5E=: CN=DigiCert Global Root CA,OU=www.digicert.com,O=DigiCert Inc,C=US Pinned certificates for baidu.com: sha256/AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA=
其会在错误中会将此网站的所有签名信息都会列出来,此时要想自签名让其通过验证,则将错误提示的三个sha值添加到okhttpclient上,如下:

这个当有自签名的需求时还是比较好用滴。再继续:
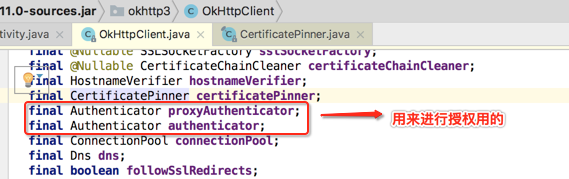
那具体是怎么用它的呢?
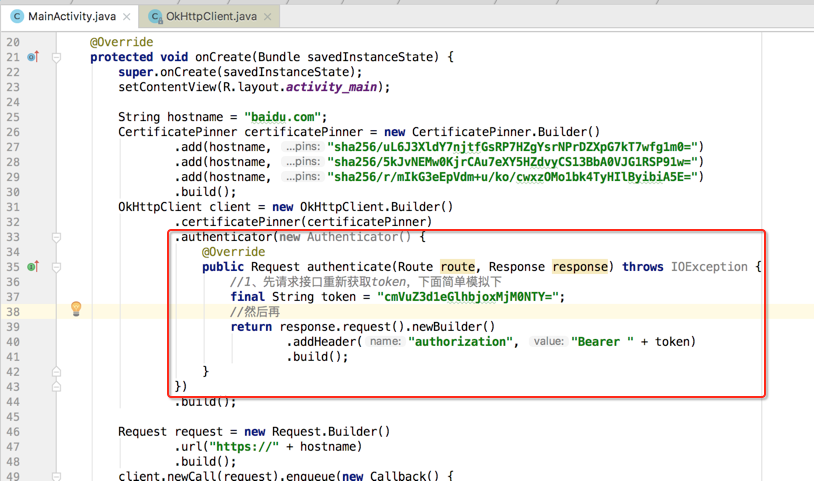
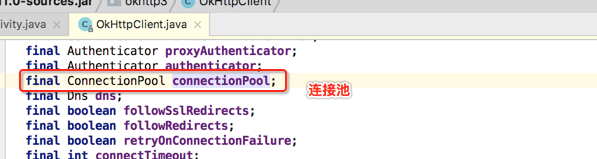

简单瞅下它:

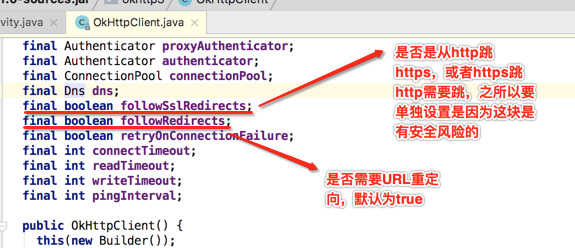


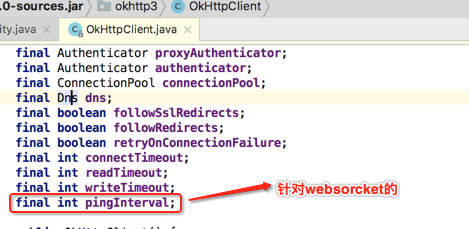
至此整个OkHttpClient的字段都过了一遍,很明显通过了解这些字段的含义能知道OkHttp底层做了好多事,清楚的能看到到处有http的身影。
接下来则需要研究Okhttp最核心的拦截器链啦,如下:
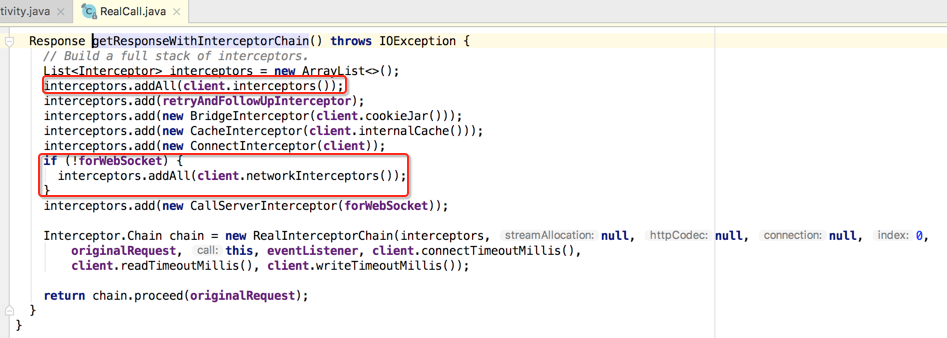
点进去瞅瞅它的实现:
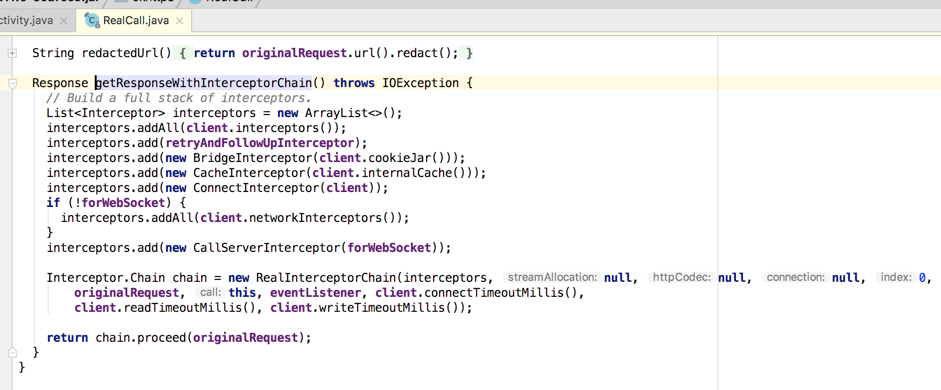
其中首先是准备各种interceptor,如下:

接着将其生成一个InterceptorChain对像,如下:
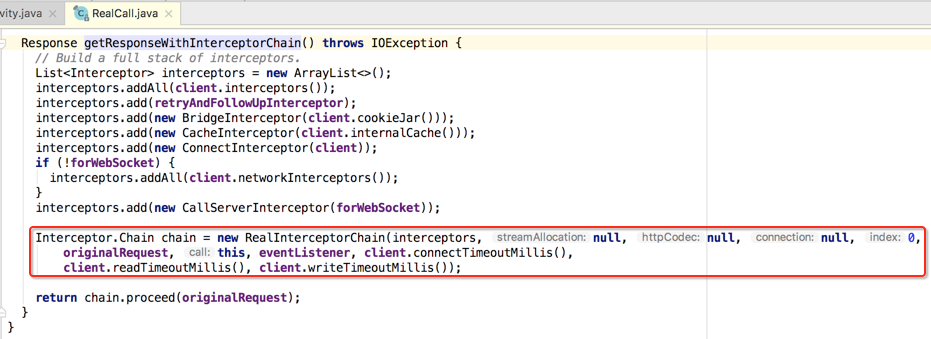
用图来表达一下拦截器链:

最后执行拦截器链的proceed(),此时其实是这么个过程:
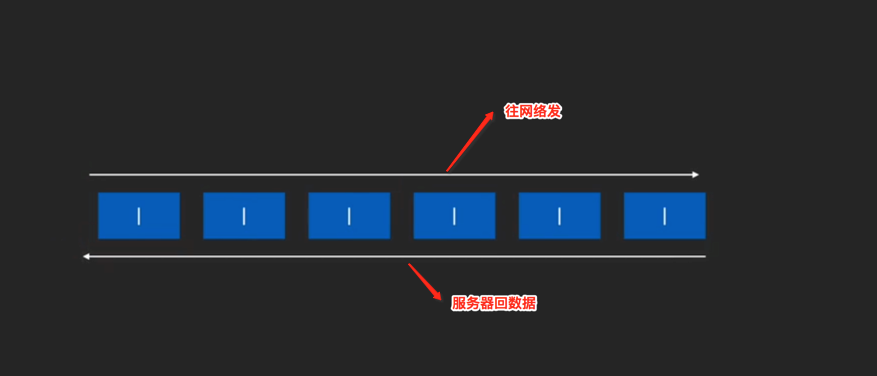
为啥要一个链呢?这里可以举一个汉堡相关的例子用来理解:有人打电话进来订了汉堡的餐,然后店老板将汉堡做好了并且给负责分发的员工,接着送餐员到店取了汉堡骑着电动送到订餐人的家里,然后送餐员将汉堡给了订餐的人,与此同时订餐人将钱给了送餐员, 送餐员又拿着钱回到了店里,并从中拿了1块钱的提成,然后将剩下的钱全部交给了负责分发的店员,然后店员又将钱交给了店长,这就是一个链,店长是链的起点【做汉堡并分配给店员】和终点【从店员中拿到钱】。当一个事件比较复杂的时候采用链的方式会职责清晰,每一个链则就是拦截器。
其中关于proceed()这里还是以上面举的汉堡的店长为例进一步阐述一下:其实对于店长的proceed()过程就是“做汉堡并分发给店员--->等待收钱---->收钱之后装进自己的裤腰袋”,而结合图的第一个节点表示店长的链,其过程其实是这样:

此时店长proceed()了,则会将链接给下一个接点,也就是分发的店员,如下:

接着经过漫长的等待,最终会从店员中收到钱,此时节点就会回到了如下位置:


用更加形象一点的图来表示整个proceed()的过程,其实有点像递归:

从中可以看到链上的每一个结点都执行proceed()之后则就行成了一个一去一回的完整链的过程。
大概理解拦截链之后,接下来则细看一下具体的各个链,对于OkHttp的链,有两个可以自动配置的,如下:
这个先放一下,先来看一下其它具体的拦截器
RetryAndFollowUpInterceptor:
第一个是它:
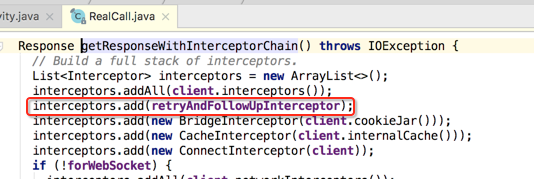

重试及重定向拦截器,点进去,对于每一个拦截器主要是看它的intercept()方法,所以:

其里面做的事情基本上如我们上面理论所说会有如下三件事件【OkHttp所有链的工作方式都遵循此原则,所以理解它非常之重要!】:
1、最初的准备(准备汉堡并交给店员)。
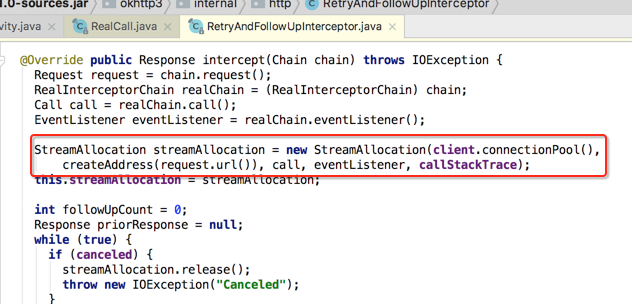
其中瞅一下StreamAllocation:

基本上这个拦截器前置工作比较简单,重点是后置工作。
2、等待结果(等待收钱)。
接着执行proceed():
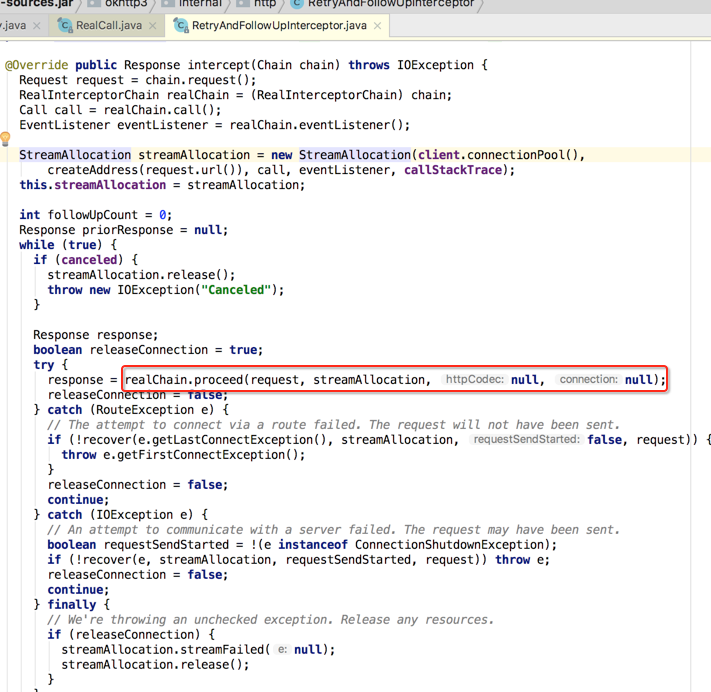
此时就会等待它之后的所有节点都处理完之后,此proceed()才会返回结果。
3、处理结果(将钱装自自己口袋)。
也就是proceed()之后的则是处理结果,具体来瞅下此拦截器的后置处理:

所以瞅一下recover方法:
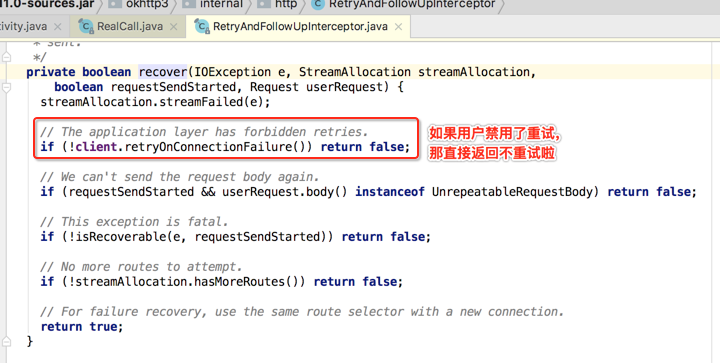

如果符合重试条件,那么直接再次循环:

其它的重试处理也类似:
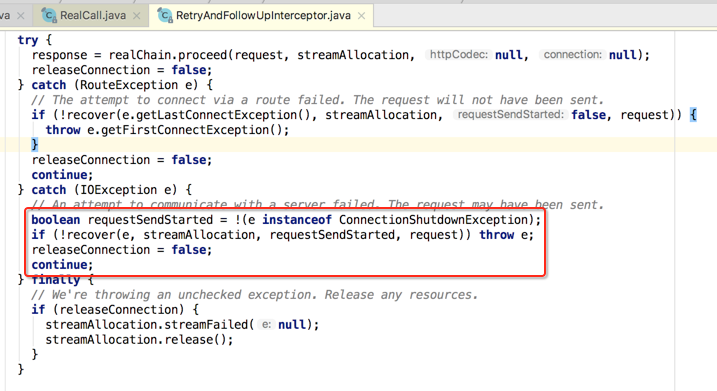
最终:

BridgeInterceptor:
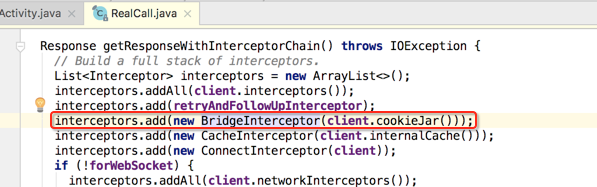
点进来瞅下,能很清楚的看到http的影子,如下:
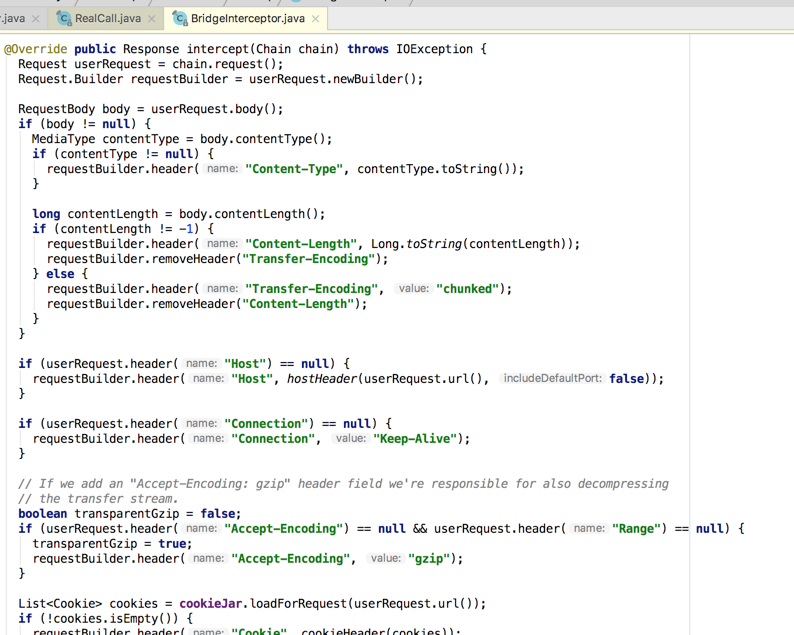
好,还是按之前的三步骤来分析:
1、最初的准备(准备汉堡并交给店员)。
基本全是加头信息:


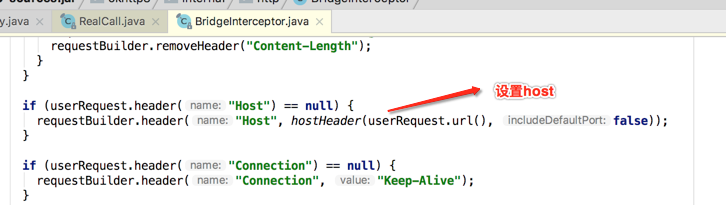

也就是OkHttp自身就已经支持gzip压缩解压缩,也就是开发者完全透明,具体解的地方在:
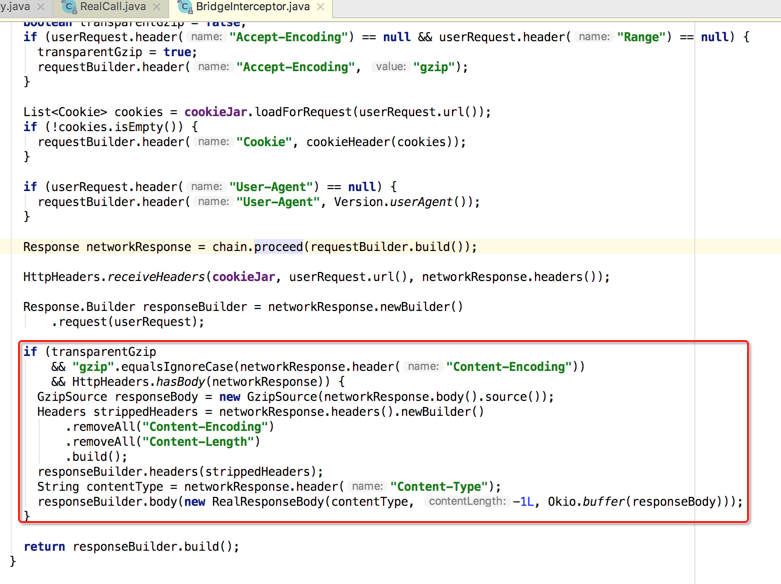

这个是需要开发者自己定义的,因为CookieJar默认是空实现的,如下:
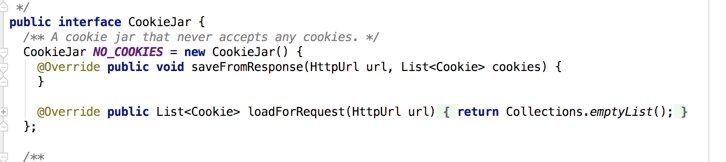
其大致用法可以这样写:
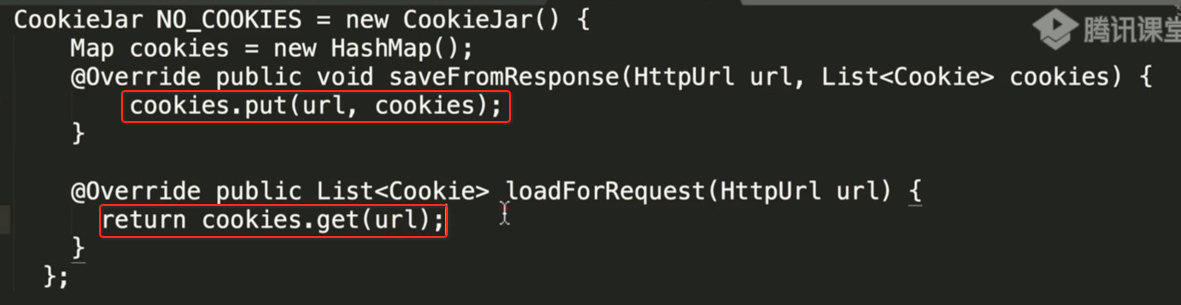
2、等待结果(等待收钱)。
当然就是执行proceed()方法喽:
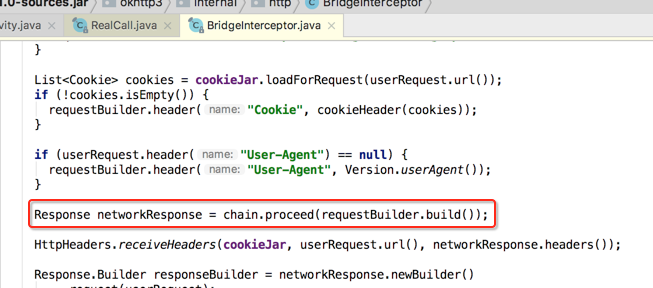
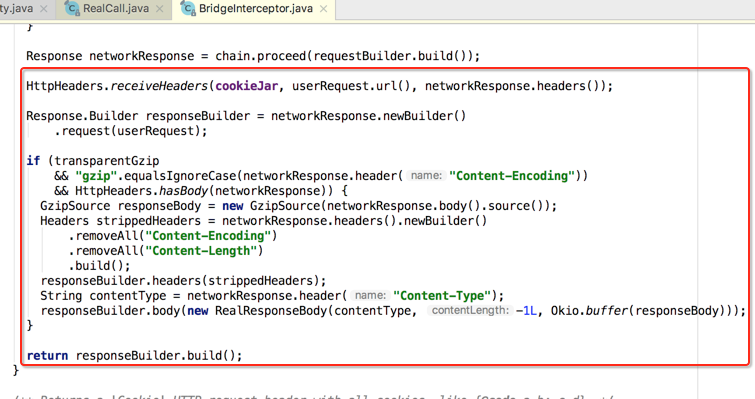
3、处理结果(将钱装自自己口袋)。
基本上做解工作,在proceed()之后:
CacheInterceptor:

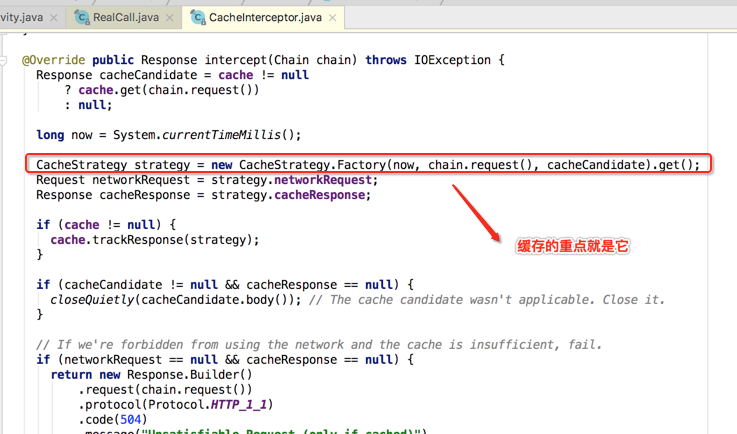
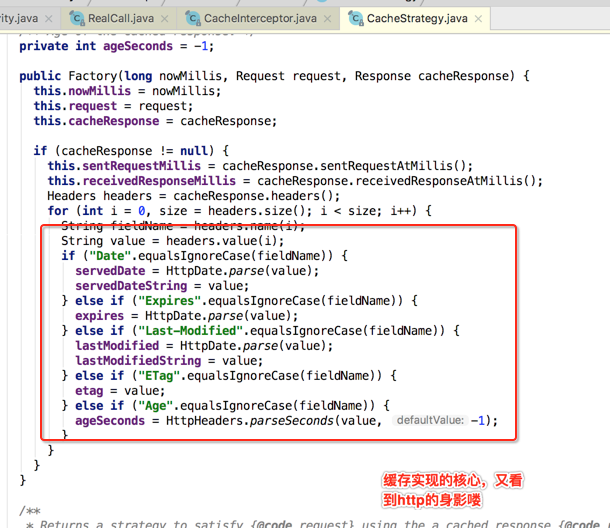

比较简单,就直接过了。
ConnectInterceptor【真正跟http或https进行交互了】:
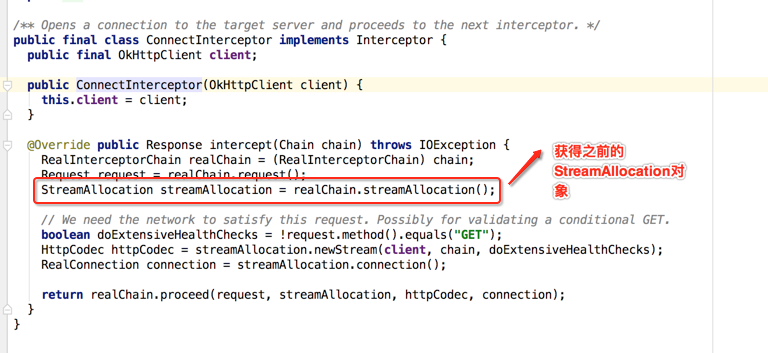
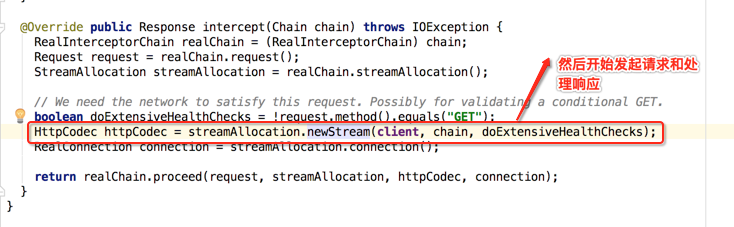
点进去瞅下细节,主要是看流程,因为这个流程能够让我们清楚的发现跟TCP和SSL的建立过程:
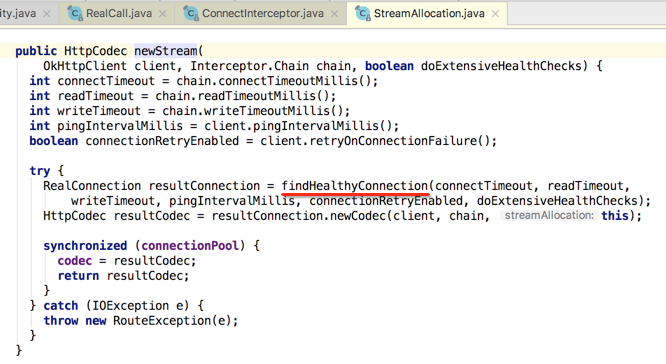

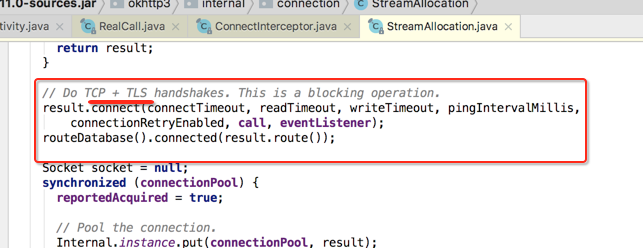
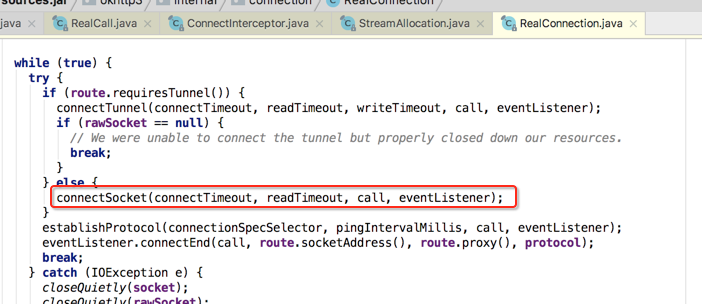
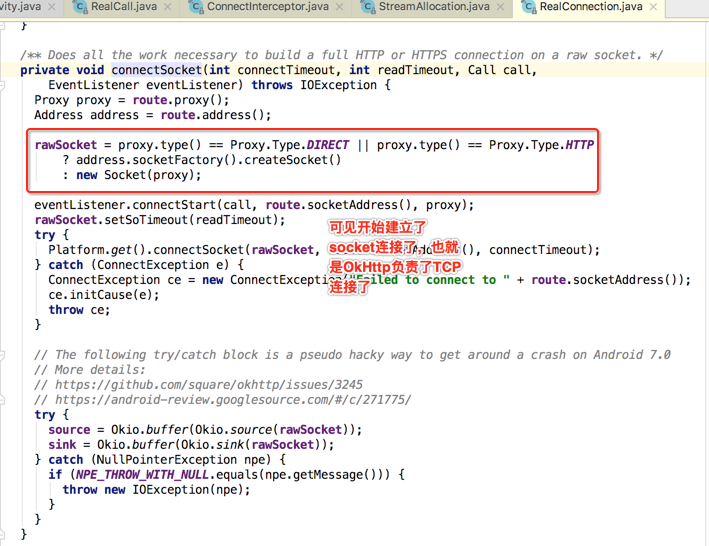
好,目前TCP的连接已经看到了,那SSL的连接呢?得回到上一层,这:
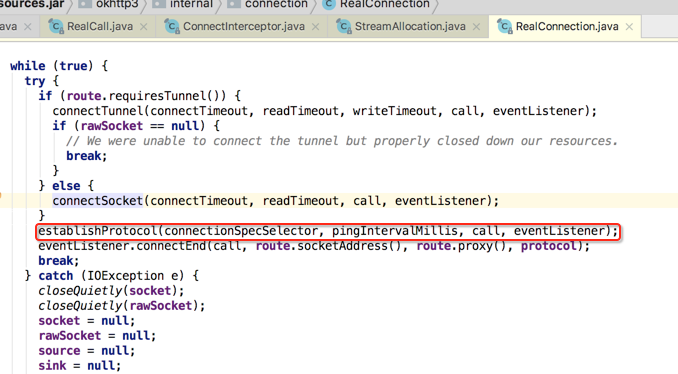
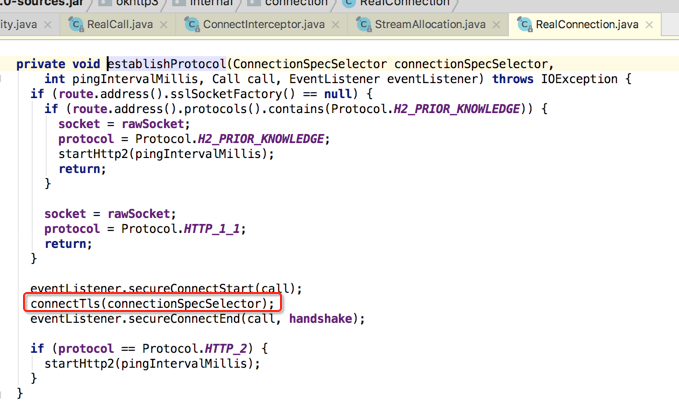
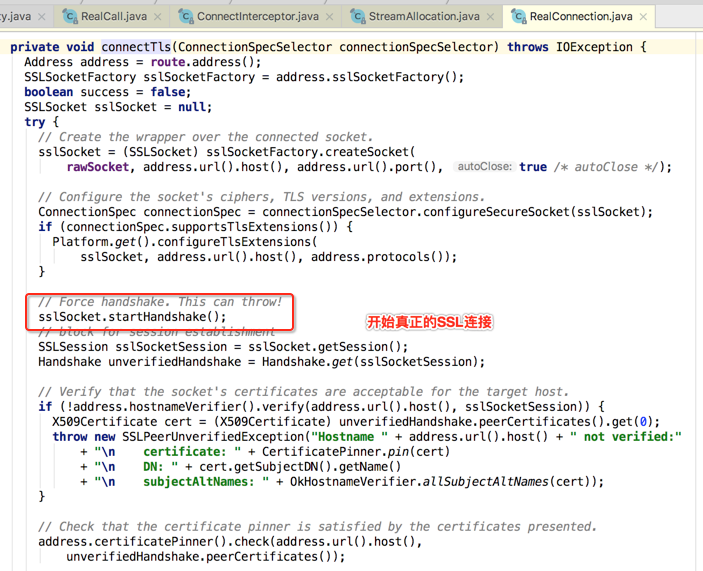
所以此拦截器的作用就是用来建立TCP+SSL连接用的,而它木有后置工作:

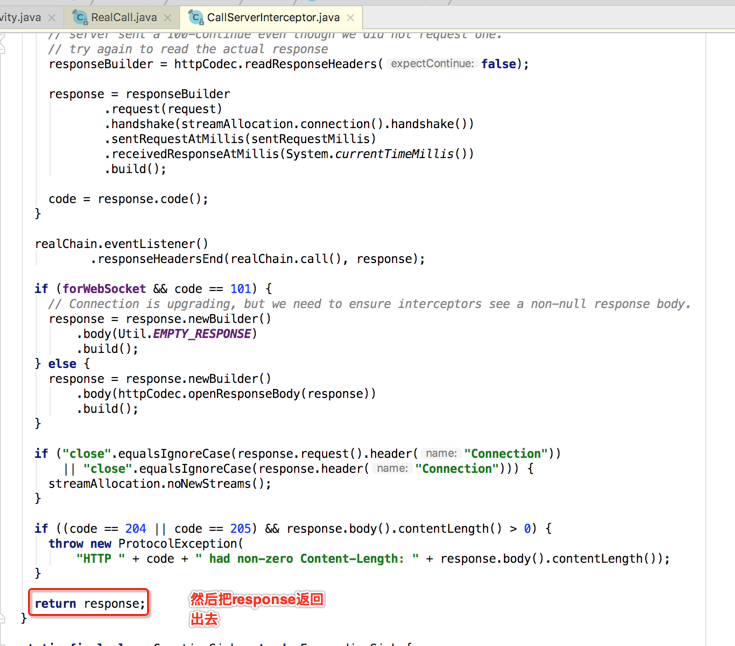
CallServerInterceptor:
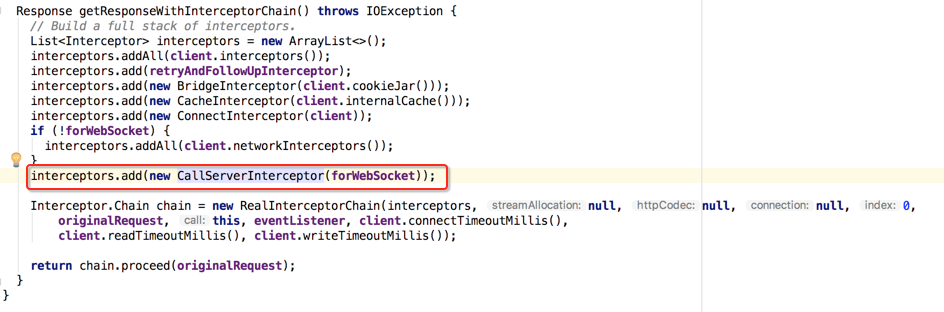
因为它是最后一个拦截器了,所以木有proceed()了,做完事情直接返回就ok了,它都是做的实质工作,下面也来分析其关键代码:
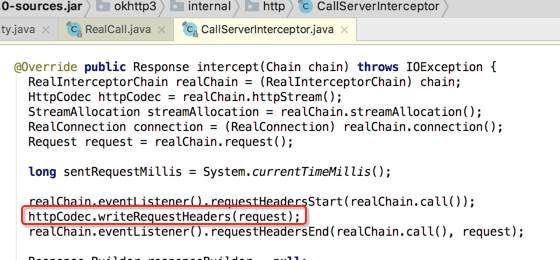

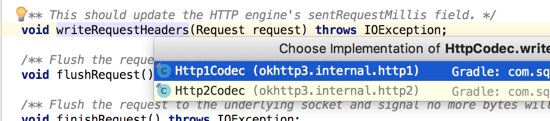
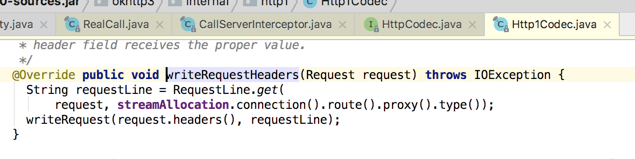
我们看http1的就成:
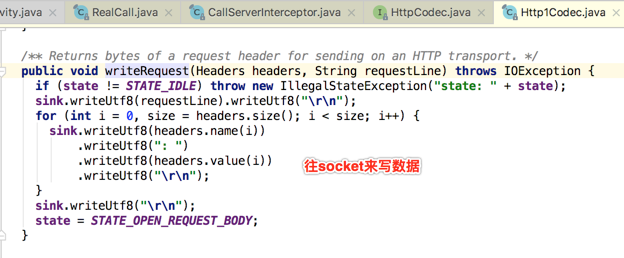
也就是通过TCP来往服务器建立通信了,接着来处理response并返回:
最后就只剩自定义的拦截器木有看了,这个比较简单,首先可以配置一个自己的拦截器,如下:
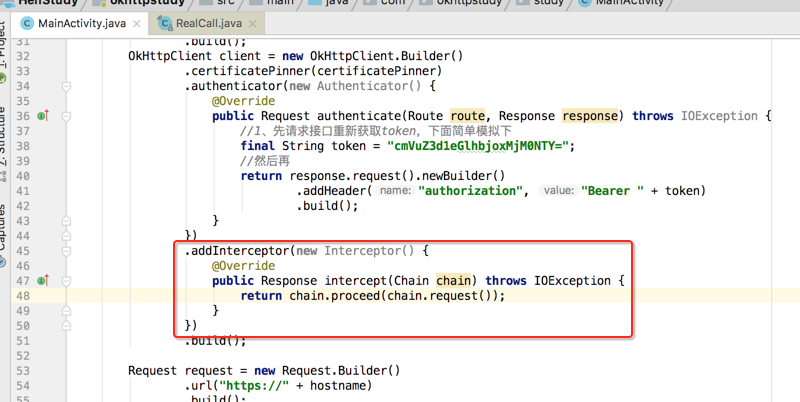
对于我在公司的项目通常会用这个拦截器来打印一下日志,或者传一些公共头信息之类的,总之比较好用。
那对于这两个自定义的拦截器,有啥区别呢?

所以如果想直接http数据时则需要用networkInterceptors,一般用不到它,主要是用上面的自定义拦截器。
到此,整个完整的链都分析完了,可以看到OkHttp是整个接管了整个Http的工作,从TCP连接的建立,TLS连接的建立,HTTP报文相关的处理,而Retrofit是利用Okhttp来实现的,只是API做了很多的容错。


