
Scrapy
安装:


- Win: 下载:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted pip3 install wheel pip install Twisted‑18.4.0‑cp36‑cp36m‑win_amd64.whl pip3 install pywin32 pip3 install scrapy # windows不支持pip直接安装,需要下载源码,而且依赖wheel、pywin32 - Linux: pip3 install scrapy
创建项目:
# 创建project scrapy startproject xxx cd xxx # 创建爬虫 scrapy genspider chouti chouti.com scrapy genspider cnblogs cnblogs.com # 启动爬虫 scrapy crawl chouti scrapy crawl chouti --nolog
def parse(self, response): # from scrapy.http.response.html import HtmlResponse # print(type(response)) # class 'scrapy.http.response.html.HtmlResponse' # print(response) # print(response.text) item_list = response.xpath('//div[@id="content-list"]/div[@class="item"]') # print(item_list) for item in item_list: text = item.xpath('.//a/text()').extract_first() href = item.xpath('.//a/@href').extract_first() print("href>>>:", href) print(text.strip()) page_list = response.xpath('//div[@id="dig_lcpage"]//a/@href').extract() for page in page_list: # 页码 # 深度爬取 from scrapy.http import Request page = "https://dig.chouti.com" + page yield Request(url=page, callback=self.parse)
Selector(response=response).xpath() //div 全局所有div //div[@id='i1'] 全局id='i1'的div @+属性名 //div[starts-with(@id,'i1')] //div[re:test(@id,'i1')] //div/a #找到的结果是一个列表,里边封装一个个的对象 obj.xpath('./') 当前对象的儿子 obj.xpath('.//') 当前对象的子孙 //div/a/text() # a标签的文本 //div/a/@href # a标签的href属性 Selector().extract() 对象转换成字符串 Selector().extract_first() 返回第一个
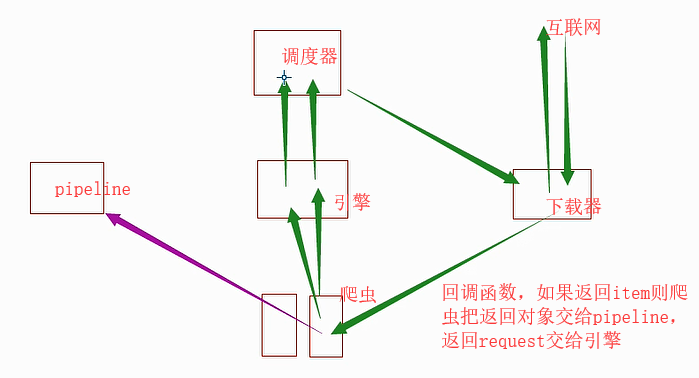
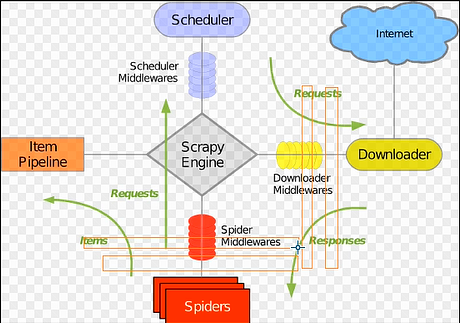
组件以及执行流程:
- 引擎找到要执行的爬虫,并执行爬虫的 start_requests 方法,并的到一个 迭代器。
- 迭代器循环时会获取Request对象,而request对象中封装了要访问的URL和回调函数。
- 将所有的request对象(任务)放到调度器中,用于以后被下载器下载。
- 下载器去调度器中获取要下载任务(就是Request对象),下载完成后执行回调函数。
- 回到spider的回调函数中,
yield Request()
yield Item()
Pipeline做持久化
a.先写pipeline类 class XXXPipeline(object): def process_item(self, item, spider): return item b.写Item类 class XxxItem(scrapy.Item): href = scrapy.Field() title = scrapy.Field() c.配置 ITEM_PIPELINES = { 'xxx.pipelines.XxxPipeline': 300, } d.爬虫,yield每执行一次,process_item就调用一次。 yield Item对象
# piplines.py class FilePipeline(object): def __init__(self, path): self.f = None self.path = path @classmethod def from_crawler(cls, crawler): """ 初始化时候,用于创建pipeline对象 :param crawler: :return: """ print('File.from_crawler') path = crawler.settings.get('HREF_FILE_PATH') return cls(path) def open_spider(self, spider): """ 爬虫开始执行时,调用 :param spider: :return: """ # if spider.name == 'chouti': print('File.open_spider') self.f = open(self.path, 'a+') def process_item(self, item, spider): # f = open('xx.log','a+') # f.write(item['href']+'\n') # f.close() print('File', item['href']) self.f.write(item['href'] + '\n') return item # 把item交给下一个pipline # from scrapy.exceptions import DropItem # raise DropItem() # 不让后边的pipline处理item def close_spider(self, spider): """ 爬虫关闭时,被调用 :param spider: :return: """ print('File.close_spider') self.f.close() class DbPipeline(object): def __init__(self, path): self.f = None self.path = path @classmethod def from_crawler(cls, crawler): """ 初始化时候,用于创建pipeline对象 :param crawler: :return: """ print('DB.from_crawler') path = crawler.settings.get('HREF_DB_PATH') return cls(path) def open_spider(self, spider): """ 爬虫开始执行时,调用 :param spider: :return: """ print('Db.open_spider') self.f = open(self.path, 'a+') def process_item(self, item, spider): # f = open('xx.log','a+') # f.write(item['href']+'\n') # f.close() print('Db', item) # self.f.write(item['href']+'\n') return item def close_spider(self, spider): """ 爬虫关闭时,被调用 :param spider: :return: """ print('Db.close_spider') self.f.close() # items.py class Scrapy1StItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() href = scrapy.Field() title = scrapy.Field() # settings.py ITEM_PIPELINES = { # 'scrapy_1st.pipelines.Scrapy1StPipeline': 300, # 优先级,0-1000,小的优先 'scrapy_1st.pipelines.FilePipeline': 301, # 优先级,0-1000,小的优先 'scrapy_1st.pipelines.DbPipeline': 301, # 优先级,0-1000,小的优先 } # # 持久化文件路径 HREF_FILE_PATH = "news.log" HREF_DB_PATH = "db.log" # 爬虫 spiders/chouti.py class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['http://chouti.com/'] def parse(self, response): item_list = response.xpath('//div[@id="content-list"]/div[@class="item"]') for item in item_list: text = item.xpath('.//a/text()').extract_first() href = item.xpath('.//a/@href').extract_first() yield Scrapy1StItem(title=text, href=href)
dupefilter做去重:
scrapy内部有默认的去重规则,但也可以自定制
from scrapy.utils.request import request_fingerprint from scrapy.http import Request url1 = "http://www.luffycity.com?k1=123&k2=456" req1 = Request(url=url1) url2 = "http://www.luffycity.com?k2=456&k1=123" req2 = Request(url=url2) # url1和url2如果用md5加密的话会得到不同的md5值 # scrapy内置的request_fingerprint用来处理url fd1 = request_fingerprint(request=req1) fd2 = request_fingerprint(request=req2) print(fd1) print(fd2)
from scrapy.dupefilter import BaseDupeFilter from scrapy.utils.request import request_fingerprint class MyDupeFilter(BaseDupeFilter): def __init__(self): self.visited_fd = set() @classmethod def from_settings(cls, settings): return cls() def request_seen(self, request): fd = request_fingerprint(request=request) # 对url做类似md5的处理 if fd in self.visited_fd: return True # url已访问过 self.visited_fd.add(fd) def open(self): # can return deferred print('开始') def close(self, reason): # can return a deferred print('结束') # def log(self, request, spider): # log that a request has been filtered # print('日志')
# 修改默认的去重规则 # DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter' DUPEFILTER_CLASS = 'xxx.dupefilters.MyDupeFilter'
爬虫中,可以通过dont_filter控制是否去重,默认False,如果为True则不去重
def parse(self, response): yield Request(url=page, callback=self.parse, dont_filter=True)
深度限制:
配置文件加上 DEPTH_LIMIT = 3
cookie:
- 携带 Request( url='https://dig.chouti.com/login', method='POST', body="phone=****&password=***&oneMonth=1", # body=urlencode({})"phone=8615131255555&password=12sdf32sdf&oneMonth=1" cookies=self.cookie_dict, headers={ 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8' }, callback=self.check_login ) - 解析: cookie_dict cookie_jar = CookieJar() cookie_jar.extract_cookies(response, response.request) # 去对象中将cookie解析到字典 for k, v in cookie_jar._cookies.items(): for i, j in v.items(): for m, n in j.items(): cookie_dict[m] = n.value
from scrapy.http.cookies import CookieJar from scrapy.http import Request class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] # 定向爬虫,抽屉主页有很多a标签,有抽屉的也有其他域名下的, # 定向表示只爬抽屉下的忽略其他域名 start_urls = ['http://chouti.com/'] cookie_dict = {} def parse(self, response): # 去响应头中获取cookie # 去响应头中获取cookie,cookie保存在cookie_jar对象 cookie_jar = CookieJar() cookie_jar.extract_cookies(response, response.request) # 去对象中将cookie解析到字典 for k, v in cookie_jar._cookies.items(): for i, j in v.items(): for m, n in j.items(): self.cookie_dict[m] = n.value yield Request( url='https://dig.chouti.com/login', method='POST', body="phone=***&password=***&oneMonth=1", # body=urlencode({})"phone=8615131255555&password=12sdf32sdf&oneMonth=1" cookies=self.cookie_dict, headers={ 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8' }, callback=self.check_login ) def check_login(self,response): print(response.text) yield Request( url='https://dig.chouti.com/all/hot/recent/1', cookies=self.cookie_dict, callback=self.index ) # 点赞 def index(self, response): news_list = response.xpath('//div[@id="content-list"]/div[@class="item"]') for new in news_list: link_id = new.xpath('.//div[@class="part2"]/@share-linkid').extract_first() yield Request( url='http://dig.chouti.com/link/vote?linksId=%s' % (link_id,), method='POST', cookies=self.cookie_dict, callback=self.check_result ) # 翻页 page_list = response.xpath('//div[@id="dig_lcpage"]//a/@href').extract() for page in page_list: page = "https://dig.chouti.com" + page yield Request(url=page, callback=self.index) # https://dig.chouti.com/all/hot/recent/2 def check_result(self, response): print(response.text)
起始url:
scrapy引擎来爬虫中取起始URL: 1. 调用start_requests并获取返回值 2. v = iter(返回值) 3. req1 = 执行 v.__next__() req2 = 执行 v.__next__() req3 = 执行 v.__next__() ... 4. req全部放到调度器中
class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['https://dig.chouti.com/'] cookie_dict = {} def start_requests(self): # 方式一: for url in self.start_urls: yield Request(url=url) # 方式二: # req_list = [] # for url in self.start_urls: # req_list.append(Request(url=url)) # return req_list
scrapy中设置代理:
内置代理:在爬虫启动时,提前在os.envrion中设置代理
class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['https://dig.chouti.com/'] cookie_dict = {} def start_requests(self): import os os.environ['HTTPS_PROXY'] = "http://root:woshiniba@192.168.11.11:9999/" os.environ['HTTP_PROXY'] = '19.11.2.32', for url in self.start_urls: yield Request(url=url, callback=self.parse)
class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['https://dig.chouti.com/'] cookie_dict = {} def start_requests(self): for url in self.start_urls: yield Request(url=url, callback=self.parse, meta={'proxy': '"http://root:woshiniba@192.168.11.11:9999/"'})
xpath:
html = """<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body> <ul> <li class="item-"><a id='i1' href="link.html">first item</a></li> <li class="item-0"><a id='i2' href="llink.html">first item</a></li> <li class="item-1"><a href="llink2.html">second item<span>vv</span></a></li> </ul> <div><a href="llink2.html">second item</a></div> </body> </html> """ from scrapy.http import HtmlResponse from scrapy.selector import Selector response = HtmlResponse(url='http://example.com', body=html,encoding='utf-8') # url随意 response.xpath('')
hxs = HtmlXPathSelector(response) print(hxs) hxs = Selector(response=response).xpath('//a') print(hxs) hxs = Selector(response=response).xpath('//a[2]') print(hxs) hxs = Selector(response=response).xpath('//a[@id]') print(hxs) hxs = Selector(response=response).xpath('//a[@id="i1"]') print(hxs) hxs = Selector(response=response).xpath('//a[@href="link.html"][@id="i1"]') print(hxs) hxs = Selector(response=response).xpath('//a[contains(@href, "link")]') print(hxs) hxs = Selector(response=response).xpath('//a[starts-with(@href, "link")]') print(hxs) hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]') # 格式:re:test(正则表达式) print(hxs) hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/text()').extract() print(hxs) hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/@href').extract() print(hxs) hxs = Selector(response=response).xpath('/html/body/ul/li/a/@href').extract() print(hxs) hxs = Selector(response=response).xpath('//body/ul/li/a/@href').extract_first() print(hxs) ul_list = Selector(response=response).xpath('//body/ul/li') for item in ul_list: v = item.xpath('./a/span') # 或 # v = item.xpath('a/span') # 或 # v = item.xpath('*/a/span') print(v)
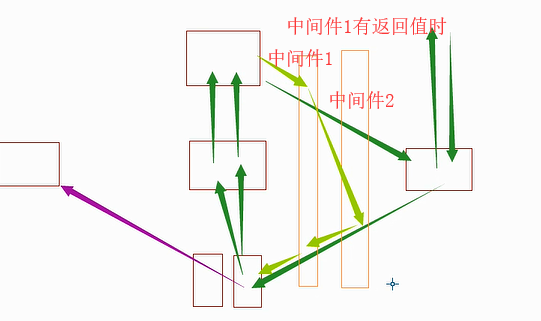
中间件
下载中间件:
from scrapy.http import HtmlResponse from scrapy.http import Request class Md1(object): @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() return s def process_request(self, request, spider): # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called print('md1.process_request',request) # 1. 返回Response 请求不会到达下载器,直接返回给md2.process_response # import requests # result = requests.get(request.url) # return HtmlResponse(url=request.url, status=200, headers=None, body=result.content) # 2. 返回Request 中间件又返回给调度器,实际上并不会去下载 # return Request('https://dig.chouti.com/r/tec/hot/1') # 3. 抛出异常 # from scrapy.exceptions import IgnoreRequest # raise IgnoreRequest # 4. 对请求进行加工(*) # request.headers['user-agent'] = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36" pass def process_response(self, request, response, spider): # Called with the response returned from the downloader. # Must either; # - return a Response object # - return a Request object # - or raise IgnoreRequest print('m1.process_response',request,response) return response def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain pass class Md2(object): @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() return s def process_request(self, request, spider): # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called print('md2.process_request',request) def process_response(self, request, response, spider): # Called with the response returned from the downloader. # Must either; # - return a Response object # - return a Request object # - or raise IgnoreRequest print('m2.process_response', request,response) return response def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain pass
DOWNLOADER_MIDDLEWARES = { 'project.md.Md1':666, 'project.md.Md2':667, }
1、user-agent
2、代理
爬虫中间件:
class Sd1(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the spider middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() return s def process_spider_input(self, response, spider): # Called for each response that goes through the spider # middleware and into the spider. # Should return None or raise an exception. return None def process_spider_output(self, response, result, spider): # Called with the results returned from the Spider, after # it has processed the response. # Must return an iterable of Request, dict or Item objects. for i in result: yield i def process_spider_exception(self, response, exception, spider): # Called when a spider or process_spider_input() method # (from other spider middleware) raises an exception. # Should return either None or an iterable of Response, dict # or Item objects. pass # 只在爬虫启动时,执行一次。 def process_start_requests(self, start_requests, spider): # Called with the start requests of the spider, and works # similarly to the process_spider_output() method, except # that it doesn’t have a response associated. # Must return only requests (not items). for r in start_requests: yield r # 要么yield,要么 return 可迭代对象 class Sd2(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the spider middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() return s def process_spider_input(self, response, spider): # Called for each response that goes through the spider # middleware and into the spider. # Should return None or raise an exception. return None def process_spider_output(self, response, result, spider): # Called with the results returned from the Spider, after # it has processed the response. # Must return an iterable of Request, dict or Item objects. for i in result: yield i def process_spider_exception(self, response, exception, spider): # Called when a spider or process_spider_input() method # (from other spider middleware) raises an exception. # Should return either None or an iterable of Response, dict # or Item objects. pass # 只在爬虫启动时,执行一次。 def process_start_requests(self, start_requests, spider): # Called with the start requests of the spider, and works # similarly to the process_spider_output() method, except # that it doesn’t have a response associated. # Must return only requests (not items). for r in start_requests: yield r
SPIDER_MIDDLEWARES = { 'project.sd.Sd1': 666, 'project.sd.Sd2': 667, }
- 深度
- 优先级
定制命令:
1、在脚本中启动单个爬虫:
项目目录下创建任意py文件,如start.py
import sys from scrapy.cmdline import execute if __name__ == '__main__': execute(["scrapy","crawl","chouti","--nolog"])
2、定制启动所有爬虫的命令,可以在cmd中使用,也可在start中使用
- 在spiders同级创建任意目录,如:commands - 在其中创建 crawlall.py 文件 (此处文件名就是自定义的命令) - 在settings.py 中添加配置 COMMANDS_MODULE = '项目名称.目录名称' - 在项目目录执行命令:scrapy crawlall
from scrapy.commands import ScrapyCommand from scrapy.utils.project import get_project_settings class Command(ScrapyCommand): requires_project = True def syntax(self): return '[options]' def short_desc(self): return 'Runs all of the spiders' def run(self, args, opts): spider_list = self.crawler_process.spiders.list() # 找到所有爬虫 for name in spider_list: self.crawler_process.crawl(name, **opts.__dict__) self.crawler_process.start()
scrapy-redis组件
使用scrapy-redis
scrapy-redis在保存url到redis时,默认以时间戳为键,所以需要修改RFPDupeFilter。
from scrapy.dupefilter import BaseDupeFilter import redis from scrapy.utils.request import request_fingerprint import scrapy_redis class DupFilter(BaseDupeFilter): def __init__(self): self.conn = redis.Redis(host='140.143.227.206',port=8888,password='beta') def request_seen(self, request): """ 检测当前请求是否已经被访问过 :param request: :return: True表示已经访问过;False表示未访问过 """ fid = request_fingerprint(request) result = self.conn.sadd('visited_urls', fid) if result == 1: return False return True from scrapy_redis.dupefilter import RFPDupeFilter from scrapy_redis.connection import get_redis_from_settings from scrapy_redis import defaults class RedisDupeFilter(RFPDupeFilter): @classmethod def from_settings(cls, settings): """Returns an instance from given settings. This uses by default the key ``dupefilter:<timestamp>``. When using the ``scrapy_redis.scheduler.Scheduler`` class, this method is not used as it needs to pass the spider name in the key. Parameters ---------- settings : scrapy.settings.Settings Returns ------- RFPDupeFilter A RFPDupeFilter instance. """ server = get_redis_from_settings(settings) # XXX: This creates one-time key. needed to support to use this # class as standalone dupefilter with scrapy's default scheduler # if scrapy passes spider on open() method this wouldn't be needed # TODO: Use SCRAPY_JOB env as default and fallback to timestamp. key = defaults.DUPEFILTER_KEY % {'timestamp': 'redis_key'} debug = settings.getbool('DUPEFILTER_DEBUG') return cls(server, key=key, debug=debug)
# ############### scrapy redis连接 #################### REDIS_HOST = '140.143.227.206' # 主机名 REDIS_PORT = 8888 # 端口 REDIS_PARAMS = {'password':'beta'} # Redis连接参数 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,}) REDIS_ENCODING = "utf-8" # redis编码类型 默认:'utf-8' # REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置) DUPEFILTER_KEY = 'dupefilter:%(timestamp)s' # DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 默认redis DUPEFILTER_CLASS = 'project.xxx.RedisDupeFilter' # 修改后

 浙公网安备 33010602011771号
浙公网安备 33010602011771号