
transformers的bert预训练模型的返回值简要描述
一般使用transformers做bert finetune时,经常会编写如下类似的代码:
outputs = self.bert(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask)
在BertModel(BertPreTrainedModel)中,对返回值outputs的解释如下:
r""" Outputs: `Tuple` comprising various elements depending on the configuration (config) and inputs: **last_hidden_state**: ``torch.FloatTensor`` of shape ``(batch_size, sequence_length, hidden_size)`` Sequence of hidden-states at the output of the last layer of the model. **pooler_output**: ``torch.FloatTensor`` of shape ``(batch_size, hidden_size)`` Last layer hidden-state of the first token of the sequence (classification token) further processed by a Linear layer and a Tanh activation function. The Linear layer weights are trained from the next sentence prediction (classification) objective during Bert pretraining. This output is usually *not* a good summary of the semantic content of the input, you're often better with averaging or pooling the sequence of hidden-states for the whole input sequence. **hidden_states**: (`optional`, returned when ``config.output_hidden_states=True``) list of ``torch.FloatTensor`` (one for the output of each layer + the output of the embeddings) of shape ``(batch_size, sequence_length, hidden_size)``: Hidden-states of the model at the output of each layer plus the initial embedding outputs. **attentions**: (`optional`, returned when ``config.output_attentions=True``) list of ``torch.FloatTensor`` (one for each layer) of shape ``(batch_size, num_heads, sequence_length, sequence_length)``: Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. """
这里的pooler_output指的是输出序列最后一个隐层,即CLS标签。查看forward函数的源码,最后返回的部分代码如下:
sequence_output = encoder_outputs[0] pooled_output = self.pooler(sequence_output) outputs = (sequence_output, pooled_output,) + encoder_outputs[ 1: ] # add hidden_states and attentions if they are here return outputs # sequence_output, pooled_output, (hidden_states), (attentions)
可以看到sequence_output进入了一个pooler层,这个pooler层结构如下:
class BertPooler(nn.Module): def __init__(self, config): super(BertPooler, self).__init__() self.dense = nn.Linear(config.hidden_size, config.hidden_size) self.activation = nn.Tanh() def forward(self, hidden_states): # We "pool" the model by simply taking the hidden state corresponding # to the first token. first_token_tensor = hidden_states[:, 0] pooled_output = self.dense(first_token_tensor) pooled_output = self.activation(pooled_output) return pooled_output
所以bert的model并不是简单的组合返回。一般说来,如果需要用bert做句子级的任务,可以使用pooled_output结果做baseline;进一步的微调可以使用last_hidden_state的结果。
last_hidden_state的结构如下所示:
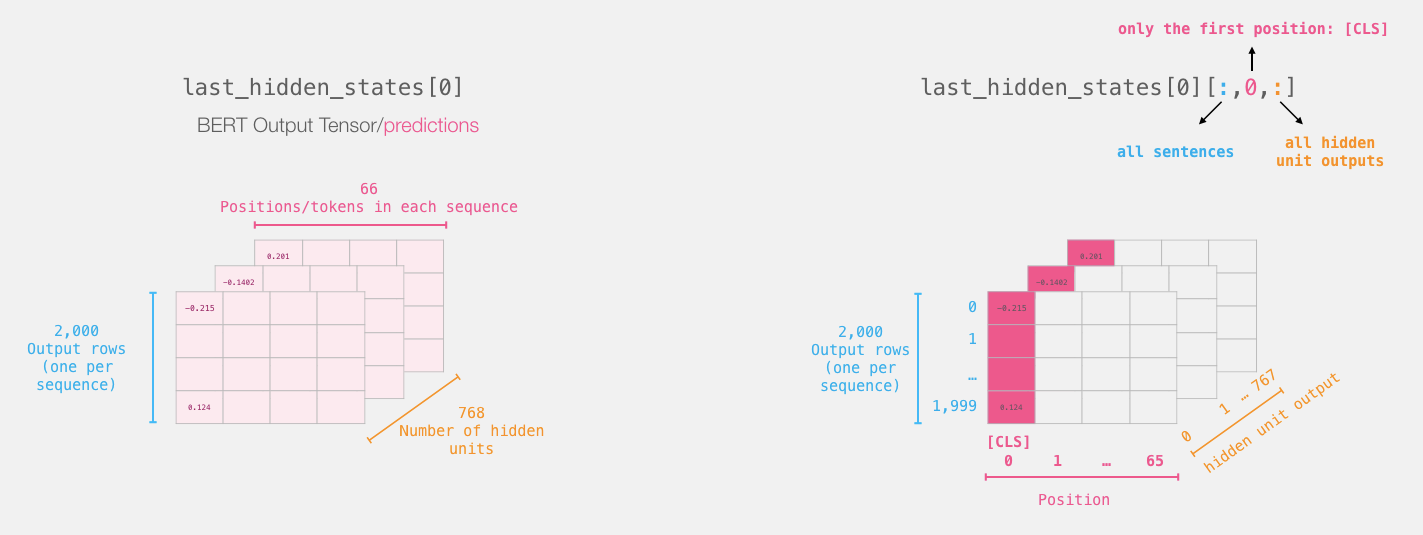
第0列为CLS,对应句向量,其他列对应词向量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号