部署node api的二三事
当接到node开发node api的时候,我就想用docker来部署,众所周知,node的版本更新迭代很快。很多以前需要babel后才能采用的方法正在不断被node 原生的支持。如果随便更换生产服务器的node版本,可能对以前的服务产生一定程度的冲击。我想用docker就是想单纯固定住node版本。关于docker的基本用法,其实网上有很多,自己不想赘述,提供链接一篇,其中我的实现基本参照于此 https://segmentfault.com/a/1190000010541792。然而想法是好的,我兴冲冲的去创建dockerhub账号,将自己的镜像上传,等着运维pull的时候,他们说他们暂时不想采用docker,理由是为了统一,据理力争不得,只能按照普通方式来部署,不过我有自己的服务器,部署到自己的服务器简直迅速又完美。之前每次源码的改动我一般都是重新构建镜像,其实每次怎么做都是很繁琐,docker container run -v /usr/src/project:/app --name server- bind-directory -p 4000:3001 -it bind-directory:0.0.1,这里的 "-v /usr/src/project:/app" 就是把宿主机的 /usr/src/project 与容器目录 app 映射起来。这样当我们代码修改后,更新项目后,就不需要再构建 image 了,依赖修改也只需要在宿主机上直接安装即可,不用构建 image,部署方便了许多。
采用普通方式来部署,不过是执行入口文件,然后用pm2来守护这个进程,看起来还是蛮不错的。但是运行了一段时间,发现有的时候接口返回的数据好大,固定几秒如果接口的数据没有 content download 完毕,接口就会报错误,类似err_content_length_mismatch,解决方法代码层面 https://github.com/expressjs/express/issues/3392,在这期间我发现我对请求的每个时间点好像不是特别清楚,于是又发现好文章一篇 network http请求时间分析 https://www.cnblogs.com/zhenwen/p/5827925.html,其中ttfb(浏览器发送请求到服务器返回第一个字节所用的时间),还有其他的什么dns解析的时间和tcp三次握手的时间,不得不说chrome对于前端开发工程师真是太友好了。不过这些东西跟接口返回大数据的处理没有多大关系,主要原因是response 太大了,导致contentdownload时间过长。怎么才能减少接口返回的数据的大小呢,肯定是压缩,于是想到gzip.怎么才能用上gzip.我想到的是nginx,可能node存在类似的中间件来实现,但是即使存在,也不能比nginx来的成熟。
,
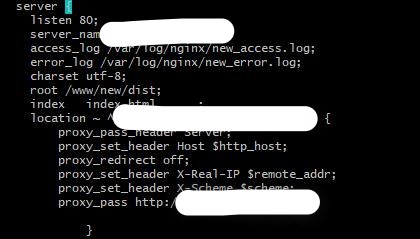

为了配置gzip接口采用的反向代理, 上图分别是虚拟主机和gzip的配置
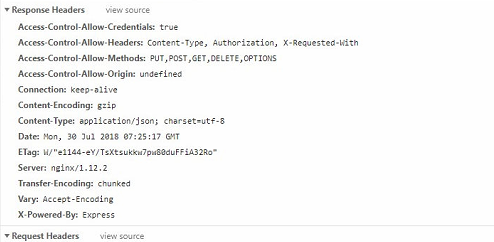
可以看到response的server nginx , gzip已经开启,完美!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号