
angular源码分析:angular中脏活累活承担者之$parse
我们在上一期中讲 $rootscope时,看到$rootscope是依赖$prase,其实不止是$rootscope,翻看angular的源码随便翻翻就可以发现很多地方是依赖于$parse的。而$parse的源码打开一看,它的代码量有接近两千行。翻开angular的api文档,官方只给出了简短的解释"Converts Angular expression into a function(将一个angular的表达式转化为一个函数)",心中神兽奔腾————就这么点功能为什么要“两千行代码”呢。
一、分享一下源码作者的第一段注释
/* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
* Any commits to this file should be reviewed with security in mind. *
* Changes to this file can potentially create security vulnerabilities. *
* An approval from 2 Core members with history of modifying *
* this file is required. *
* *
* Does the change somehow allow for arbitrary javascript to be executed? *
* Or allows for someone to change the prototype of built-in objects? *
* Or gives undesired access to variables likes document or window? *
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * */
这段声明,我只在angular源码中的三个文件中看到:$parse,$sce,$compile。
这段声明的大体意思是:所有提交到这个文件的修改都会因为出于安全性的考虑被检视。修改这个文件可能会带来安全漏洞。至少需要两位angular的核心成员审批,这个文件才能修改。所做的修改是否会导致任意的js代码的执行,或者允许某人修改绑定在对象上的原型(prototype),或者给予不被希望的访问变量(比如document,window)的权限。
敢情,作者实现了一个编译器,正在学习编译原理的同学有福了
通过阅读后面的注释以及https://docs.angularjs.org/guide/security,可以知道:这里实现$parse使用了2000行代码是出于安全性的考虑,而使用了编译器的方式来编译需要解析的表达式。在词法解析的过程中,本来可以使用正则表达式的,但是作者使用了自己构建一个词法解析器(Lexer),我的猜测是出于性能的考虑。通过编译原理的学习,我们知道词法的解析只需要3型文法,而3型文法等价于正则表示,所以用正则表示能够识别所有的需要的词法。利用通行的正则表达式,固然可以很快的写出一个词法分析器,但是效率却是很低的,正则表达式的执行,需要反复多次的遍历字符串,对于被频繁调用的$parse服务(我们说它干的是脏活累活)用正则表达式来实现词法分析器显然是不合适的。
二、编译原理(这一部分对于angular的源码分析,没有太大卵用,可以跳过)
对于编译原理,其实就是计算机科学家在编写编译器过程中总结出来的一套理论。而编译器,是一个程序,它的输入是一种编程语言,输出结果是另外一种编程语言,相当于是一个翻译官,比如可以将英语翻译成中文。抽象出来,就是将A语言翻译成B语言的程序,称之为编译器。这会带来一个问题,A语言和B语言的描述能力是否相同,就是A语言和B语言是否等价,是否能否翻译。
说点题外话
读者有没有想过这个问题:为什么人类的语言能够相互翻译呢?反正,这个问题我是一直在思索,最近在读《乔姆斯基的思想与理想》算是找到了一种解释:人类有一种共同内在语言,乔姆斯基称之为I语言,这是源自于人类的固有属性的东西,而我们使用的汉语、英语神马的都不过是一种表观的语言,它们是I语言的编码,其描述能力自然等价于I语言,那么这些语言的表述能力也就相等了。(乔姆斯基是现在还健在的大师,我个人觉得可以将他与牛顿、达尔文、爱因斯坦等人齐名)
1.编译器的一般构成:
一个编译器一般包含这几个子程序:代码预处理程序,词法分析器,语法分析器,语义分析器,目标代码生成器,目标代码优化器等。
代码预处理程序:作用在于干掉代码中的不相关的部分,包括注释、多余的空格,以及将预编译指令翻译成代码。
词法分析器:根据语言规定的词汇表规则识别出合法的词汇,如果有非法词汇停止编译,抛出错误信息。比如,在写C语言中,对标识符的定义是,以字母或下划线开头可以包含字母、数字、下划线的字符串,词法分析器就是根据这个定义来识别标识符。
算了,限于篇幅,后面省略。。。。
2.文法分类
1956年,Chomsky建立形式语言的描述。通过对产生式的施加不同的限制,Chomsky把文法分为4种类型
首先定义一个产生式α→β
0型文法(PSG):
α∈(VN∪VT)* ,且至少含一个VN
β∈(VN∪VT)*
对产生式没有任何限制
例如:A0→A0,A1→B
0型文法说明:
0型文法也称为短语文法。
一个非常重要的理论结果是,0型文法的能力相当于图灵机(Turing),关于图灵机,我的另一篇博文《第一章,计算机的发明》有讲到。或者说,任何0型语言都是递归可枚举的;反之,递归可枚举集必定是一个0型语言。对0型文法产生式的形式作某些限制,以给出1,2和3型文法的定义。
注意
文法G 定义为四元组(VN ,VT ,P,S)
VN :非终结符集
VT :终结符集
P :产生式集合(规则集合)
S :开始符号(识别符号)
1型文法(上下文有关文法context-sensitive):
对任一产生式α→β,都有|β|>=|α|, 仅仅S→ε除外
产生式的形式描述:α1Aα2→α1βα2
(其中,α1、α2、β∈(VN∪VT)*,β≠ε,A∈VN)
即:A只有出现在α1α2的上下文中,才允许用β替换。
产生的语言称“上下文有关语言”
例如:0A0→011000,1A1→101011
2型文法(CFG):
对任一产生式α→β,都有α∈VN,β∈(VN∪VT)*
产生式的形式描述:A→β(A∈VN)
即β取代A时,与A所处的上下文无关。
产生的语言称“上下文无关语言”
例如:G[S]:S→01 S→0S1
3型文法(RG):也称正规文法
每个产生式均为A→aB或A→a —— 右线性
A→Ba或A→a —— 左线性
其中,A、B∈VN,a∈VT*
产生的语言称“正规语言”
例如:G[S]: S→0A | 0,A→1B | B,B→1 | 0
三、$parse的词法解析器
1.在讲源代码前,先讲字符串搜索的预搜索技术.
在匹配运算符号的时候会出现一个问题:比如,在匹配x += y中的运算符时,如果逐个字符扫描,将得到连接x和y中的中间运算符是+和=,而我们知道这里其实是一个运算符号+=,那么怎么办呢?
很简单:遇到+时,我们先不要断言它是一个"加预算符",继续读入一个字符,看这两个字符是否能够组成一个新的符号,如果能组成则一个识别,索引标签步进两个单位,如果不能则判断+号是"加运算符",提前读入的字符不算数。
我们将这种预先处理的技术,称为"预搜索技术"。
推广下去,你会得到KMP算法。
2.词法解析器的源代码:
var Lexer = function(options) {
this.options = options;
};
Lexer.prototype = {
constructor: Lexer,
lex: function(text) { //将一个字符串转换成一个词汇表
this.text = text;
this.index = 0;
this.tokens = [];
while (this.index < this.text.length) {
var ch = this.text.charAt(this.index);
if (ch === '"' || ch === "'") { //识别字符串
this.readString(ch);
} else if (this.isNumber(ch) || ch === '.' && this.isNumber(this.peek())) {//识别number(包括,整数、浮点数和科学计数法
this.readNumber();
} else if (this.isIdent(ch)) {//识别标识符
this.readIdent();
} else if (this.is(ch, '(){}[].,;:?')) { //识别边界符号
this.tokens.push({index: this.index, text: ch});
this.index++;
} else if (this.isWhitespace(ch)) { //识别空格
this.index++;
} else { //运算符的识别,一个运算符由1到3个字符组成,需要预搜索
var ch2 = ch + this.peek();//预搜索1个字符
var ch3 = ch2 + this.peek(2);//预搜索2个字符
var op1 = OPERATORS[ch];
var op2 = OPERATORS[ch2];
var op3 = OPERATORS[ch3];
if (op1 || op2 || op3) {
var token = op3 ? ch3 : (op2 ? ch2 : ch);
this.tokens.push({index: this.index, text: token, operator: true});
this.index += token.length;
} else {
this.throwError('Unexpected next character ', this.index, this.index + 1); //发生异常,抛出
}
}
}
return this.tokens;//返回存储下来的词汇表
},
is: function(ch, chars) { //判断ch是否是chars字符串中一个字符
return chars.indexOf(ch) !== -1;
},
peek: function(i) { //返回,预读i个字符
var num = i || 1;
return (this.index + num < this.text.length) ? this.text.charAt(this.index + num) : false;
},
isNumber: function(ch) { //判断字符是否是数字
return ('0' <= ch && ch <= '9') && typeof ch === "string";
},
isWhitespace: function(ch) { //判断字符是否是非打印字符
// IE treats non-breaking space as \u00A0
return (ch === ' ' || ch === '\r' || ch === '\t' ||
ch === '\n' || ch === '\v' || ch === '\u00A0');
},
isIdent: function(ch) { //判断ch是否是属于标识符的字符集
return ('a' <= ch && ch <= 'z' ||
'A' <= ch && ch <= 'Z' ||
'_' === ch || ch === '$');
},
isExpOperator: function(ch) { //是否科学技术法中的符号(+或者-)
return (ch === '-' || ch === '+' || this.isNumber(ch));
},
throwError: function(error, start, end) { //错误抛出
end = end || this.index;
var colStr = (isDefined(start)
? 's ' + start + '-' + this.index + ' [' + this.text.substring(start, end) + ']'
: ' ' + end);
throw $parseMinErr('lexerr', 'Lexer Error: {0} at column{1} in expression [{2}].',
error, colStr, this.text);
},
readNumber: function() { //读入一个数
var number = '';
var start = this.index;
while (this.index < this.text.length) {
var ch = lowercase(this.text.charAt(this.index));
if (ch == '.' || this.isNumber(ch)) {
number += ch;
} else {
var peekCh = this.peek();
if (ch == 'e' && this.isExpOperator(peekCh)) {
number += ch;
} else if (this.isExpOperator(ch) &&
peekCh && this.isNumber(peekCh) &&
number.charAt(number.length - 1) == 'e') {
number += ch;
} else if (this.isExpOperator(ch) &&
(!peekCh || !this.isNumber(peekCh)) &&
number.charAt(number.length - 1) == 'e') {
this.throwError('Invalid exponent');
} else {
break;
}
}
this.index++;
}
this.tokens.push({
index: start,
text: number,
constant: true,
value: Number(number)
});
},
readIdent: function() { //读入一个标识符
var start = this.index;
while (this.index < this.text.length) {
var ch = this.text.charAt(this.index);
if (!(this.isIdent(ch) || this.isNumber(ch))) {
break;
}
this.index++;
}
this.tokens.push({
index: start,
text: this.text.slice(start, this.index),
identifier: true
});
},
readString: function(quote) { //读入一个字符串
var start = this.index;
this.index++;
var string = '';
var rawString = quote;
var escape = false;
while (this.index < this.text.length) {
var ch = this.text.charAt(this.index);
rawString += ch;
if (escape) {
if (ch === 'u') {
var hex = this.text.substring(this.index + 1, this.index + 5);
if (!hex.match(/[\da-f]{4}/i)) {
this.throwError('Invalid unicode escape [\\u' + hex + ']');
}
this.index += 4;
string += String.fromCharCode(parseInt(hex, 16));
} else {
var rep = ESCAPE[ch];
string = string + (rep || ch);
}
escape = false;
} else if (ch === '\\') {
escape = true;
} else if (ch === quote) {
this.index++;
this.tokens.push({
index: start,
text: rawString,
constant: true,
value: string
});
return;
} else {
string += ch;
}
this.index++;
}
this.throwError('Unterminated quote', start);
}
};
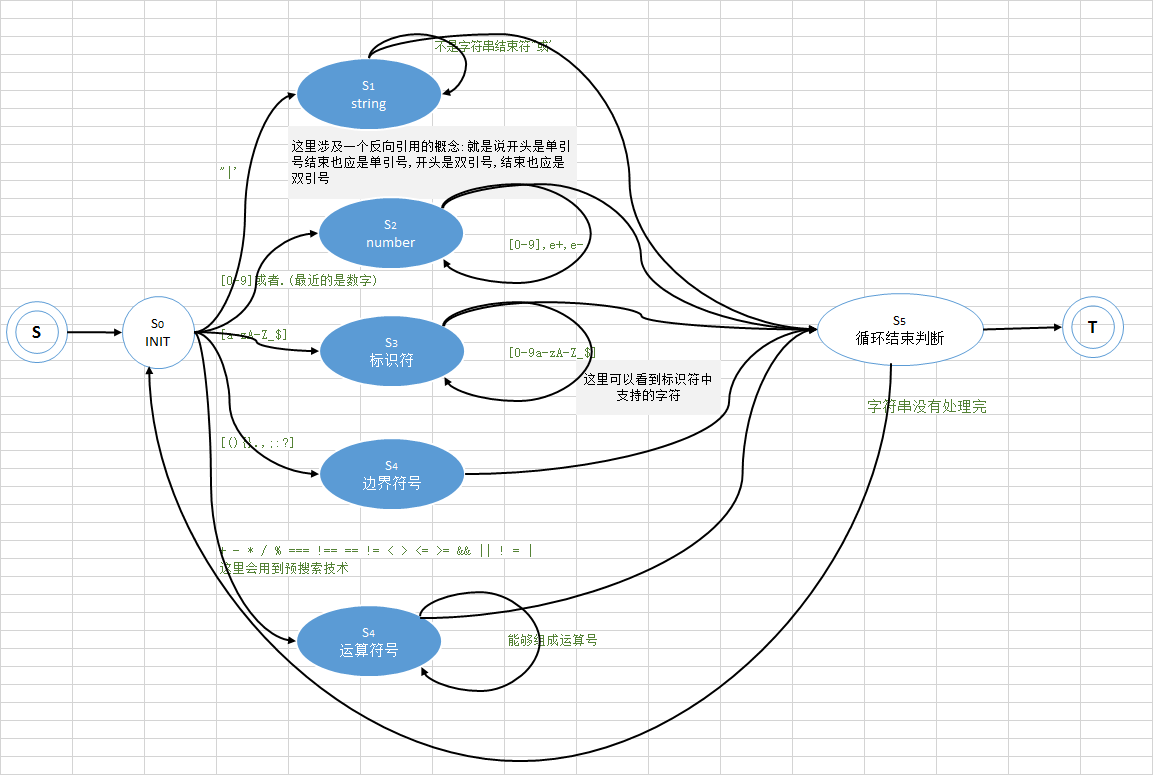
3.上面代码对应的有限状态机
4.如果用正则表达式来实现
1.字符串:/(["'])\S+\1/
2.number:/([0-9]*.)?[0-9]+(e[\+-][0-9]+)?/
3.标识符:/[a-zA-Z_\$][a-zA-Z0-9_\$]*/
4.运算符:/\+|-|\*|\/|%|===|\!==|==|\!=|<|>|<=|>=|&&|\|\||\!|=|\|/
四、$parse的语法解析器
1.概念
AST:Abstract Syntax Tree,抽象语法树
抽象语法树(Abstract Syntax Tree ,AST)作为程序的一种中间表示形式,在程序分析等诸多领域有广泛的应用。利用抽象语法树可以方便地实现多种源程序处理工具,比如源程序浏览器、智能编辑器、语言翻译器等。
2.$parse的AST实现:
var AST = function(lexer, options) {
this.lexer = lexer;
this.options = options;
};
//下面定义了语法树节点的类型
AST.Program = 'Program';//代表程序的根节点
AST.ExpressionStatement = 'ExpressionStatement'; //表达式节点
AST.AssignmentExpression = 'AssignmentExpression';//赋值表达式
AST.ConditionalExpression = 'ConditionalExpression';//判断表达式
AST.LogicalExpression = 'LogicalExpression';//逻辑运算表达式
AST.BinaryExpression = 'BinaryExpression';//二进制预算处理表达式(按位与、按位或)? 看了后面,才知道这种理解是不对的.这表示的大小关系.但是为什么要取这个名字呢?
AST.UnaryExpression = 'UnaryExpression'; //非数据表达式
AST.CallExpression = 'CallExpression'; //调用表达式
AST.MemberExpression = 'MemberExpression'; //成员变量表达式
AST.Identifier = 'Identifier'; //标识符
AST.Literal = 'Literal'; //文字,额,这里是指ture,false,null,undefined等
AST.ArrayExpression = 'ArrayExpression';//数据表达式
AST.Property = 'Property'; //对象属性表达式
AST.ObjectExpression = 'ObjectExpression';//对象表达式
AST.ThisExpression = 'ThisExpression';//this表达式
// Internal use only
AST.NGValueParameter = 'NGValueParameter';
AST.prototype = {
ast: function(text) {//语法树的入口
this.text = text;
this.tokens = this.lexer.lex(text);//调用词法分析器,得到合法的词汇表
var value = this.program();//调用"program"子程序,开始生成语法树
if (this.tokens.length !== 0) {
this.throwError('is an unexpected token', this.tokens[0]);
}
return value;
},
program: function() {
var body = [];
while (true) {//循环,调用expressionStatement读取语句
if (this.tokens.length > 0 && !this.peek('}', ')', ';', ']'))
body.push(this.expressionStatement());
if (!this.expect(';')) {
return { type: AST.Program, body: body};//返回一个语法树
}
}
},
expressionStatement: function() { //表达式节点,代表的是js的一个语句
return { type: AST.ExpressionStatement, expression: this.filterChain() };//其中调用过滤器链filterChain.这是是为识别过滤器的语法如:timestamp|date:'yyyy-mm-dd'
},
filterChain: function() {
var left = this.expression();//调用expression,获取语法树的节点
var token;
while ((token = this.expect('|'))) { //过滤器可能是以链状存在的,比如:xxx|filter1|filter2...,所以需要循环处理
left = this.filter(left); //调用filter
}
return left;
},
expression: function() {
return this.assignment();
},
assignment: function() {//识别赋值语句
var result = this.ternary();
if (this.expect('=')) {
result = { type: AST.AssignmentExpression, left: result, right: this.assignment(), operator: '='};
}
return result;
},
ternary: function() {//识别三元运算:xxx?Axxx:Bxxx;
var test = this.logicalOR();
var alternate;
var consequent;
if (this.expect('?')) {
alternate = this.expression();
if (this.consume(':')) {
consequent = this.expression();
return { type: AST.ConditionalExpression, test: test, alternate: alternate, consequent: consequent};
}
}
return test;
},
logicalOR: function() { //识别逻辑运算 "或"(||)
var left = this.logicalAND();
while (this.expect('||')) {
left = { type: AST.LogicalExpression, operator: '||', left: left, right: this.logicalAND() };
}
return left;
},
logicalAND: function() { //识别逻辑运算 "与"(&&)
var left = this.equality();
while (this.expect('&&')) {
left = { type: AST.LogicalExpression, operator: '&&', left: left, right: this.equality()};
}
return left;
},
equality: function() { //识别逻辑运算 "等"(==)
var left = this.relational();
var token;
while ((token = this.expect('==','!=','===','!=='))) {
left = { type: AST.BinaryExpression, operator: token.text, left: left, right: this.relational() };
}
return left;
},
relational: function() { //识别大小比较的表达式
var left = this.additive();
var token;
while ((token = this.expect('<', '>', '<=', '>='))) {
left = { type: AST.BinaryExpression, operator: token.text, left: left, right: this.additive() };//没搞懂为什么要取这个名字Binary,一开始还以为是二进制运算相关
}
return left;
},
additive: function() { //识别加减表达式
var left = this.multiplicative();
var token;
while ((token = this.expect('+','-'))) {
left = { type: AST.BinaryExpression, operator: token.text, left: left, right: this.multiplicative() };
}
return left;
},
multiplicative: function() {//识别乘除法
var left = this.unary();
var token;
while ((token = this.expect('*','/','%'))) {
left = { type: AST.BinaryExpression, operator: token.text, left: left, right: this.unary() };
}
return left;
},
unary: function() { //处理非数组的表达式
var token;
if ((token = this.expect('+', '-', '!'))) {
return { type: AST.UnaryExpression, operator: token.text, prefix: true, argument: this.unary() };
} else {
return this.primary();
}
},
primary: function() {//处理js的远程语法写的内容
var primary;
if (this.expect('(')) {
primary = this.filterChain();
this.consume(')');
} else if (this.expect('[')) {
primary = this.arrayDeclaration();
} else if (this.expect('{')) {
primary = this.object();
} else if (this.constants.hasOwnProperty(this.peek().text)) {
primary = copy(this.constants[this.consume().text]);
} else if (this.peek().identifier) {
primary = this.identifier();
} else if (this.peek().constant) {
primary = this.constant();
} else {
this.throwError('not a primary expression', this.peek());
}
var next;
while ((next = this.expect('(', '[', '.'))) {
if (next.text === '(') {
primary = {type: AST.CallExpression, callee: primary, arguments: this.parseArguments() };
this.consume(')');
} else if (next.text === '[') {
primary = { type: AST.MemberExpression, object: primary, property: this.expression(), computed: true };
this.consume(']');
} else if (next.text === '.') {
primary = { type: AST.MemberExpression, object: primary, property: this.identifier(), computed: false };
} else {
this.throwError('IMPOSSIBLE');
}
}
return primary;
},
filter: function(baseExpression) {//处理过滤器语法
var args = [baseExpression];//将传入参数放入args ,做第一个参数节点
var result = {type: AST.CallExpression, callee: this.identifier(), arguments: args, filter: true};//使用过滤器,其实质是调用一个函数,所以语法树节点是一个"CallExpression"
while (this.expect(':')) {
args.push(this.expression());//压缩其他参数节点
}
return result;
},
parseArguments: function() { //处理参数
var args = [];
if (this.peekToken().text !== ')') {
do {
args.push(this.expression());
} while (this.expect(','));
}
return args;
},
identifier: function() { //处理标识符
var token = this.consume();
if (!token.identifier) {
this.throwError('is not a valid identifier', token);
}
return { type: AST.Identifier, name: token.text };
},
constant: function() { //处理常量
// TODO check that it is a constant
return { type: AST.Literal, value: this.consume().value };
},
arrayDeclaration: function() { //处理数组
var elements = [];
if (this.peekToken().text !== ']') {
do {
if (this.peek(']')) {
// Support trailing commas per ES5.1.
break;
}
elements.push(this.expression());
} while (this.expect(','));
}
this.consume(']');
return { type: AST.ArrayExpression, elements: elements };
},
object: function() {//处理Object
var properties = [], property;
if (this.peekToken().text !== '}') {
do {
if (this.peek('}')) {
// Support trailing commas per ES5.1.
break;
}
property = {type: AST.Property, kind: 'init'};
if (this.peek().constant) {
property.key = this.constant();
} else if (this.peek().identifier) {
property.key = this.identifier();
} else {
this.throwError("invalid key", this.peek());
}
this.consume(':');
property.value = this.expression();
properties.push(property);
} while (this.expect(','));
}
this.consume('}');
return {type: AST.ObjectExpression, properties: properties };
},
throwError: function(msg, token) {
throw $parseMinErr('syntax',
'Syntax Error: Token \'{0}\' {1} at column {2} of the expression [{3}] starting at [{4}].',
token.text, msg, (token.index + 1), this.text, this.text.substring(token.index));
},
consume: function(e1) {
if (this.tokens.length === 0) {
throw $parseMinErr('ueoe', 'Unexpected end of expression: {0}', this.text);
}
var token = this.expect(e1);
if (!token) {
this.throwError('is unexpected, expecting [' + e1 + ']', this.peek());
}
return token;
},
peekToken: function() {
if (this.tokens.length === 0) {
throw $parseMinErr('ueoe', 'Unexpected end of expression: {0}', this.text);
}
return this.tokens[0];
},
peek: function(e1, e2, e3, e4) {
return this.peekAhead(0, e1, e2, e3, e4);
},
peekAhead: function(i, e1, e2, e3, e4) {
if (this.tokens.length > i) {
var token = this.tokens[i];
var t = token.text;
if (t === e1 || t === e2 || t === e3 || t === e4 ||
(!e1 && !e2 && !e3 && !e4)) {
return token;
}
}
return false;
},
expect: function(e1, e2, e3, e4) {//期望子程序,如果满足期望,将this.tokens队列头部弹出一个元素返回,否则返回false
var token = this.peek(e1, e2, e3, e4);
if (token) {
this.tokens.shift();
return token;
}
return false;
},
/* `undefined` is not a constant, it is an identifier,
* but using it as an identifier is not supported
*/
constants: {
'true': { type: AST.Literal, value: true },
'false': { type: AST.Literal, value: false },
'null': { type: AST.Literal, value: null },
'undefined': {type: AST.Literal, value: undefined },
'this': {type: AST.ThisExpression }
}
};
3.语法树的数据结构:
从上面的代码中可以得知,语法树的一个节点的数据结构
{
type: AST.xxxStatement, //节点类型
xxx:xxx, //每种节点类型的所含的元素不同
}
//1.语法树根节点
{
type: AST.Program,
body: body
}
//2.语法数表达式节点
{
type: AST.ExpressionStatement,
expression: this.filterChain()
}
//3.赋值语句节点
{
type: AST.AssignmentExpression,
left: result,
right: this.assignment(),
operator: '='
}
//4.条件表达式节点(三目预算)
{
type: AST.ConditionalExpression,
test: test,
alternate: alternate,
consequent: consequent
}
//5.逻辑预算节点
{
type: AST.LogicalExpression,
operator: '||',
left: left,
right: this.logicalAND()
}
//6.比较运算节点
{
type: AST.BinaryExpression,
operator: token.text,
left: left,
right: this.relational()
}
//7.非数据节点
{
type: AST.UnaryExpression,
operator: token.text,
prefix: true,
argument: this.unary()
}
//8.成员变量节点
{
type: AST.MemberExpression,
object: primary,
property: this.expression(),
computed: true
}
//9.标识符节点
{
type: AST.Identifier,
name: token.text
}
//10.常量节点
{
type: AST.Literal,
value: this.consume().value
}
//11.数据节点
{
type: AST.ArrayExpression,
elements: elements
}
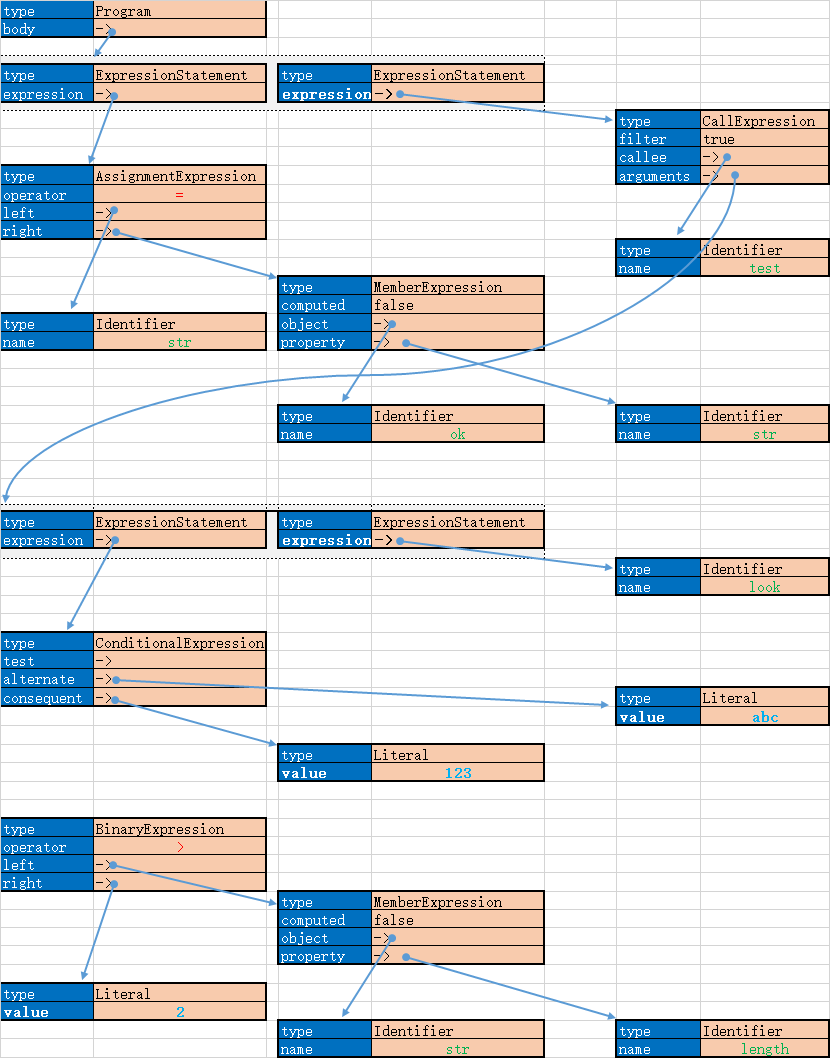
4.举例
假设angular表达式是str = ok.str;str.length>2?'abc':123|test:look;
那么通过上面的程序,得到的语法树将是:
五、$parse编译器
在$parse中定义了两个编译器:ASTCompiler 和 ASTInterpreter,他们的作用都是调用AST生成语法树,然后将语法树组装成js函数。
两者之间的差别是
1.ASTCompiler 会将句法树按语义组装成函数,ASTInterpreter是按语义组装成语句,然后调用循环,主句执行;
2.ASTInterpreter的语句执行过程中,会被附加ensureSafeXXX的函数,进行安全性检查。
3.看看,他们都是怎么被调用的:
/**
* @constructor
*/
var Parser = function(lexer, $filter, options) {
this.lexer = lexer;
this.$filter = $filter;
this.options = options;
this.ast = new AST(this.lexer);
this.astCompiler = options.csp ? new ASTInterpreter(this.ast, $filter) : //什么是csp??
new ASTCompiler(this.ast, $filter);
};
Parser.prototype = {
constructor: Parser,
parse: function(text) {
return this.astCompiler.compile(text, this.options.expensiveChecks);
}
};
什么是csp,请看CSP 1.1 specification;
还有一篇:浏览器安全策略说之内容安全策略CSP;
另外推荐angular-ngcsp和angular-Security
写得太多了,其他代码就不再分析了。如果有机会,后面再补一篇博文。
六、$parse服务
这里,将$parse代码函数代码贴出来,如果上面的代码明白了,下面的也就很简单了,不再赘述了.
function $parse(exp, interceptorFn, expensiveChecks) {
var parsedExpression, oneTime, cacheKey;
switch (typeof exp) {
case 'string':
exp = exp.trim();
cacheKey = exp;
var cache = (expensiveChecks ? cacheExpensive : cacheDefault);
parsedExpression = cache[cacheKey];
if (!parsedExpression) {
if (exp.charAt(0) === ':' && exp.charAt(1) === ':') {
oneTime = true;
exp = exp.substring(2);
}
var parseOptions = expensiveChecks ? $parseOptionsExpensive : $parseOptions;
var lexer = new Lexer(parseOptions);
var parser = new Parser(lexer, $filter, parseOptions);
parsedExpression = parser.parse(exp);
if (parsedExpression.constant) {
parsedExpression.$$watchDelegate = constantWatchDelegate;
} else if (oneTime) {
parsedExpression.$$watchDelegate = parsedExpression.literal ?
oneTimeLiteralWatchDelegate : oneTimeWatchDelegate;
} else if (parsedExpression.inputs) {
parsedExpression.$$watchDelegate = inputsWatchDelegate;
}
cache[cacheKey] = parsedExpression;
}
return addInterceptor(parsedExpression, interceptorFn);
case 'function':
return addInterceptor(exp, interceptorFn);
default:
return noop;
}
};
这篇博文,我从昨天写到今天,终于勉强写完了。
你说$parse是不是专干脏活和累活呢?
上一期:angular源码分析:angular中$rootscope的实现——scope的一生
下一期:angular源码分析:angular源码分析:angular中入境检察官$sce
ps:sec,是Strict Contextual Escaping的缩写。这个可以被我们用的较少,这里给api的链接:$sec

 浙公网安备 33010602011771号
浙公网安备 33010602011771号