Web Scraper 高级用法——Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器 | 简易数据分析 09

这是简易数据分析系列的第 9 篇文章。
今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器。
如何只抓取前 100 条数据?
如果跟着上篇教程一步一步做下来,你会发现这个爬虫会一直运作,根本停不下来。网页有 1000 条数据,他就会抓取 1000 条,有 10W 条,就会抓取 10W 条。如果我们的需求很小,只想抓取前 200 条怎么办?
如果你手动关闭抓取数据的网页,就会发现数据全部丢失,一条都没有保存下来,所以说这种暴力的方式不可取。我们目前有两种方式停止 Web Scraper 的抓取。
2019-10-26 补充:0.4.2 版本的 Web Scraper 已经支持实时保存,也就是说手动关闭抓取数据的网页也可以保存数据了
1.断网大法
当你觉得数据抓的差不多了,直接把电脑的网络断了。网络一断浏览器就加载不了数据,Web Scraper 就会误以为数据抓取完了,然后它会自动停止自动保存。
断网大法简单粗暴,虽不优雅,但是有效。缺点就是你得在旁边盯着,关键点手动操作,不是很智能。
2.通过数据编号控制条数
2019-10-26 补充:0.4.2 版本的 Web Scraper 改进了抓取方式,这种方法可能会失效
比如说上篇文章的少数派热门文章爬虫,container 的 Selector 为 dl.article-card,他会抓取网页里所有编号为 dl.article-card 的数据。

我们可以在这个 Selector 后加一个 :nth-of-type(-n+100),表示抓取前 100 条数据,前 200 条就为 :nth-of-type(-n+200),1000 条为 :nth-of-type(-n+1000),以此类推。

这样,我们就可以通过控制数据的编号来控制需要抓取的数据。
抓取链接数据时,页面跳转怎么办?
在上文抓取数据时,可能会遇到一些问题,比如说抓取标题时,标题本身就是个超链接,点击圈选内容后打开了新的网页,干扰我们确定圈选的内容,体验不是很好。
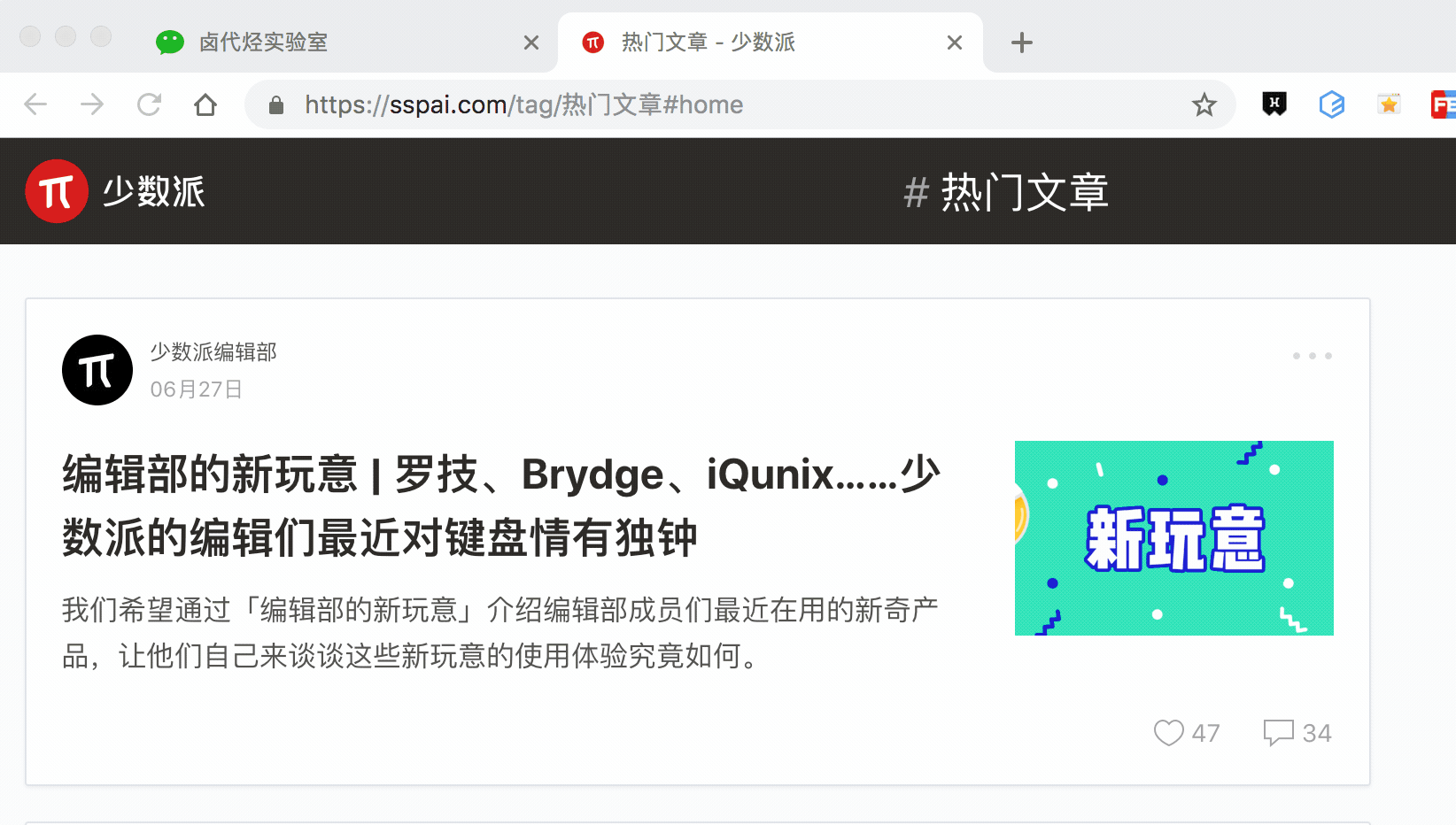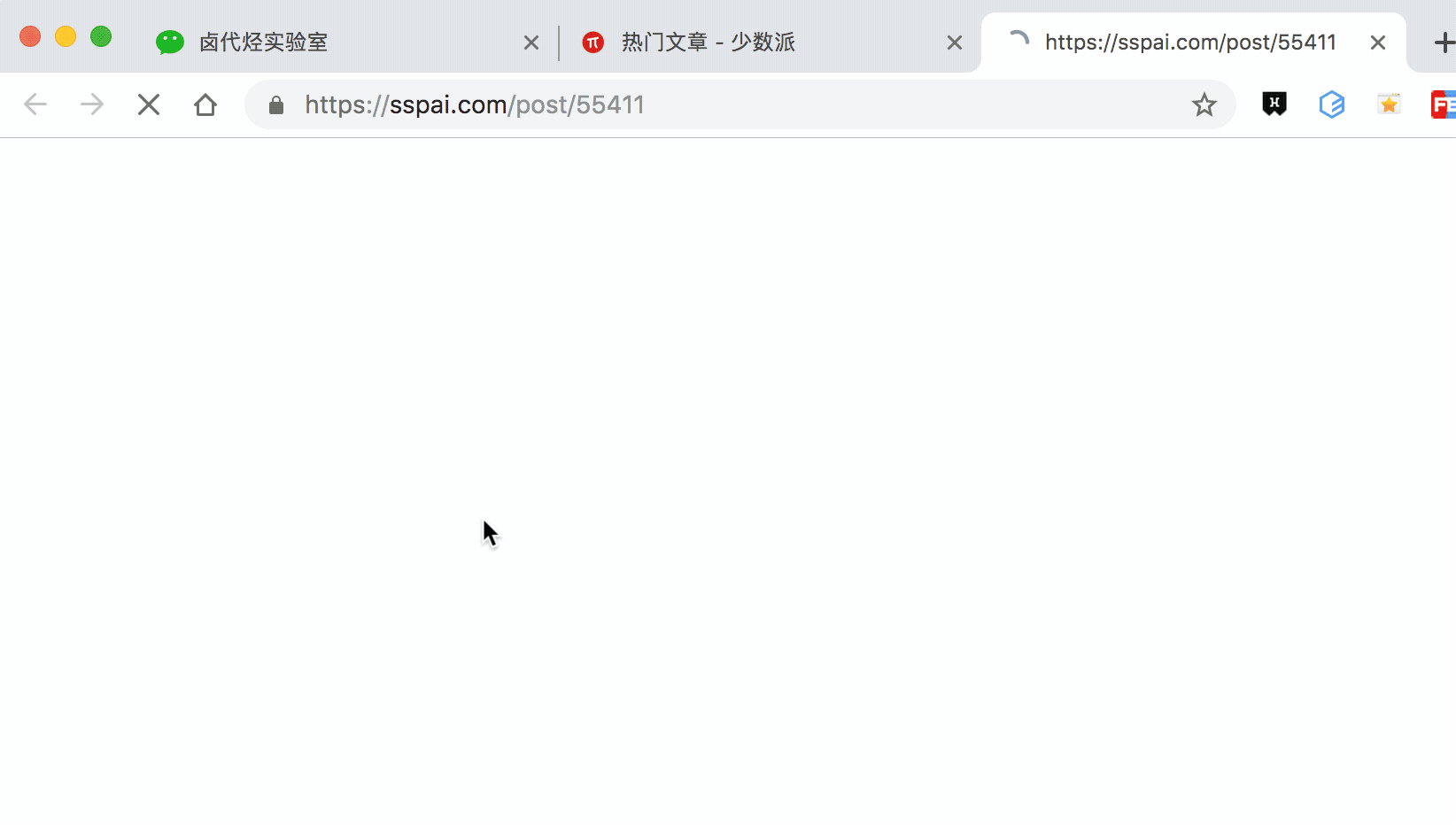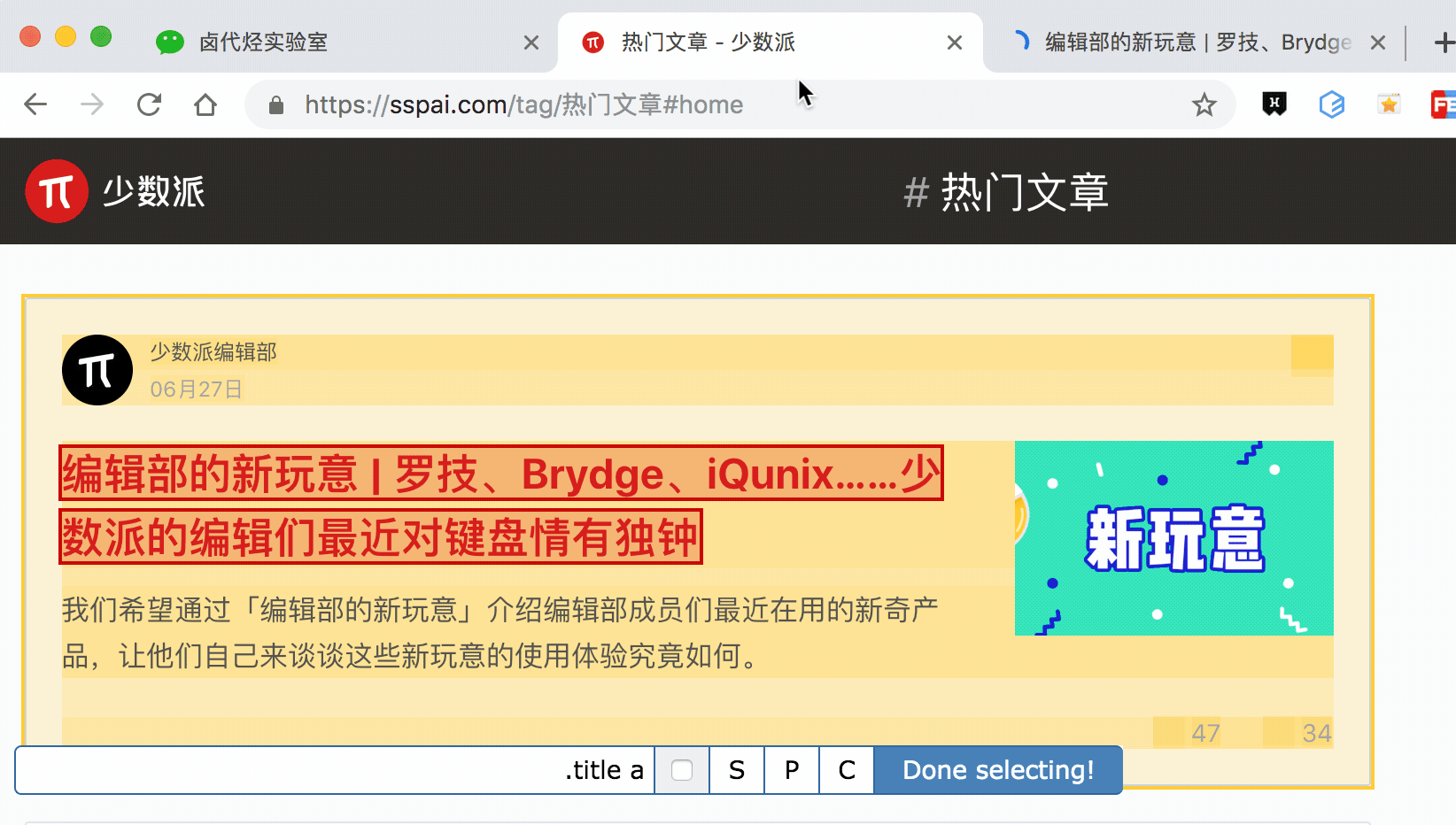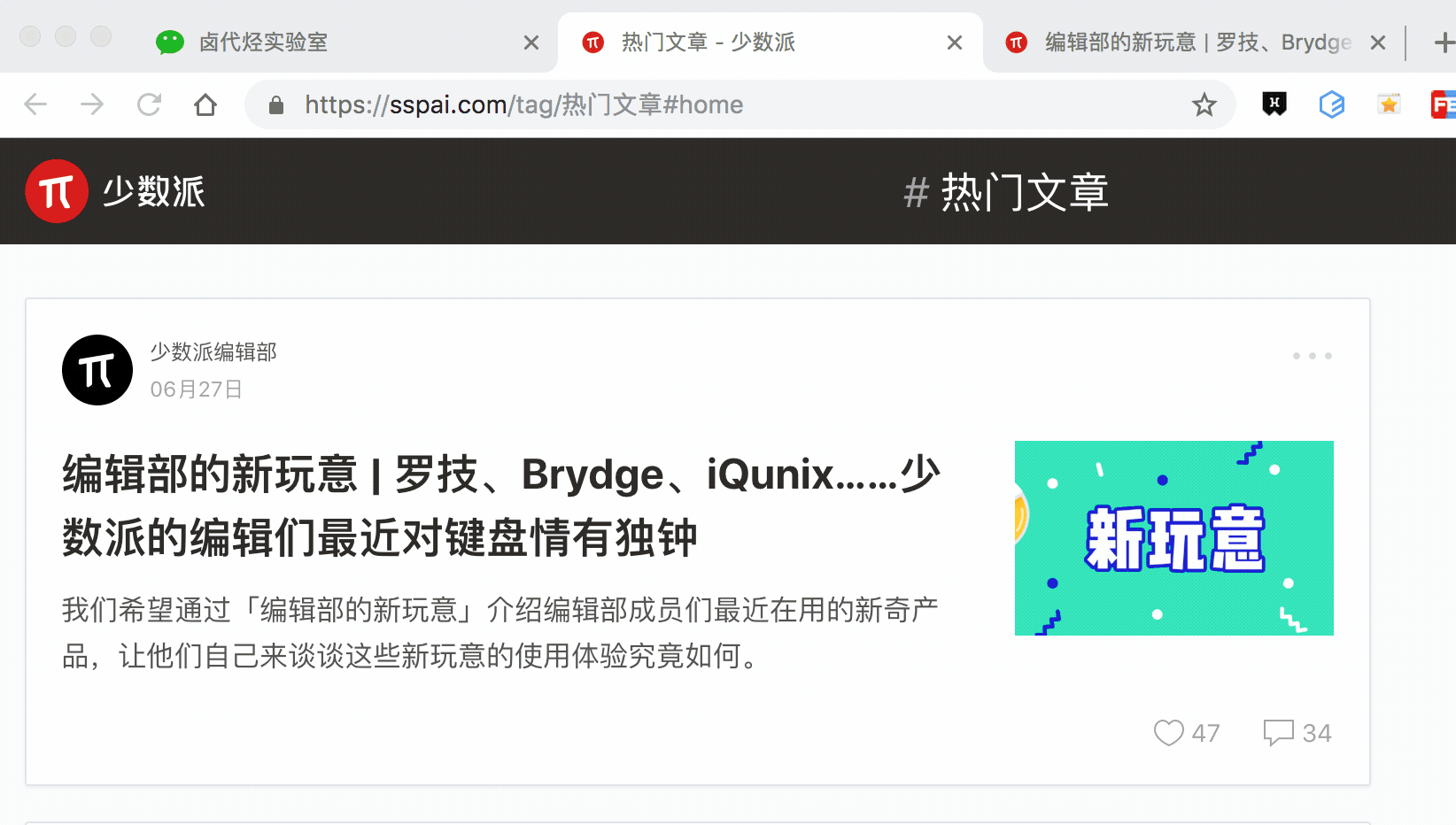
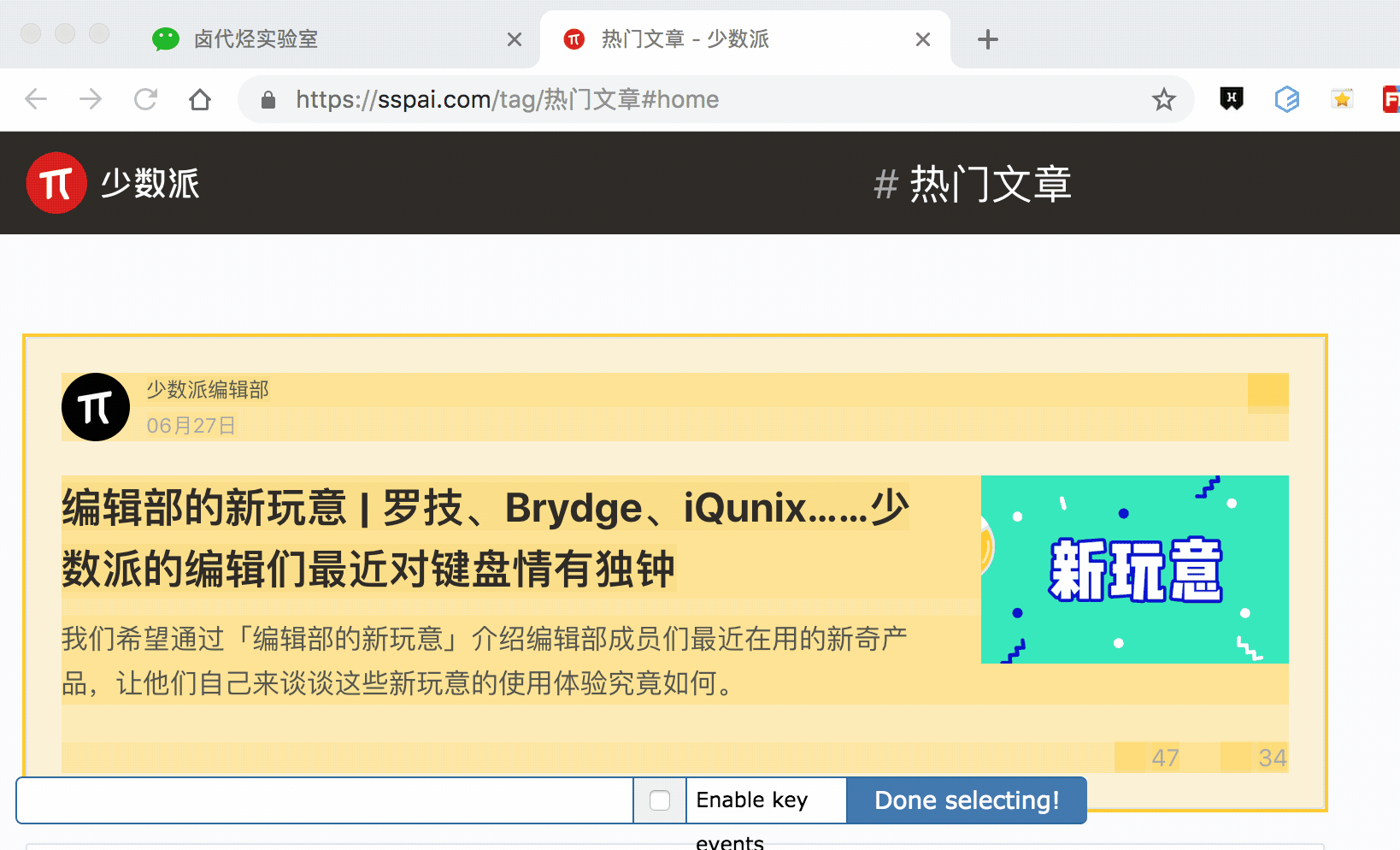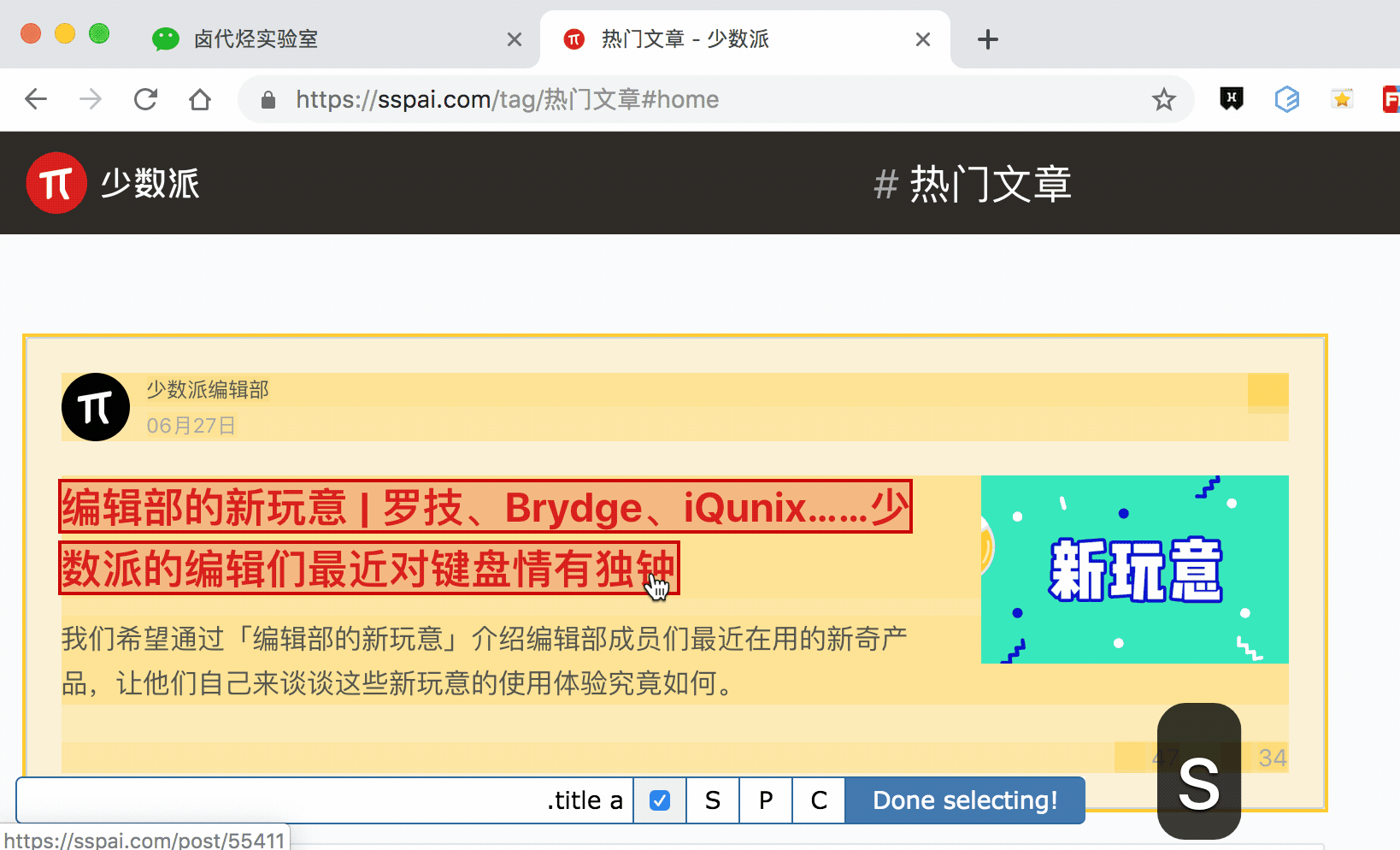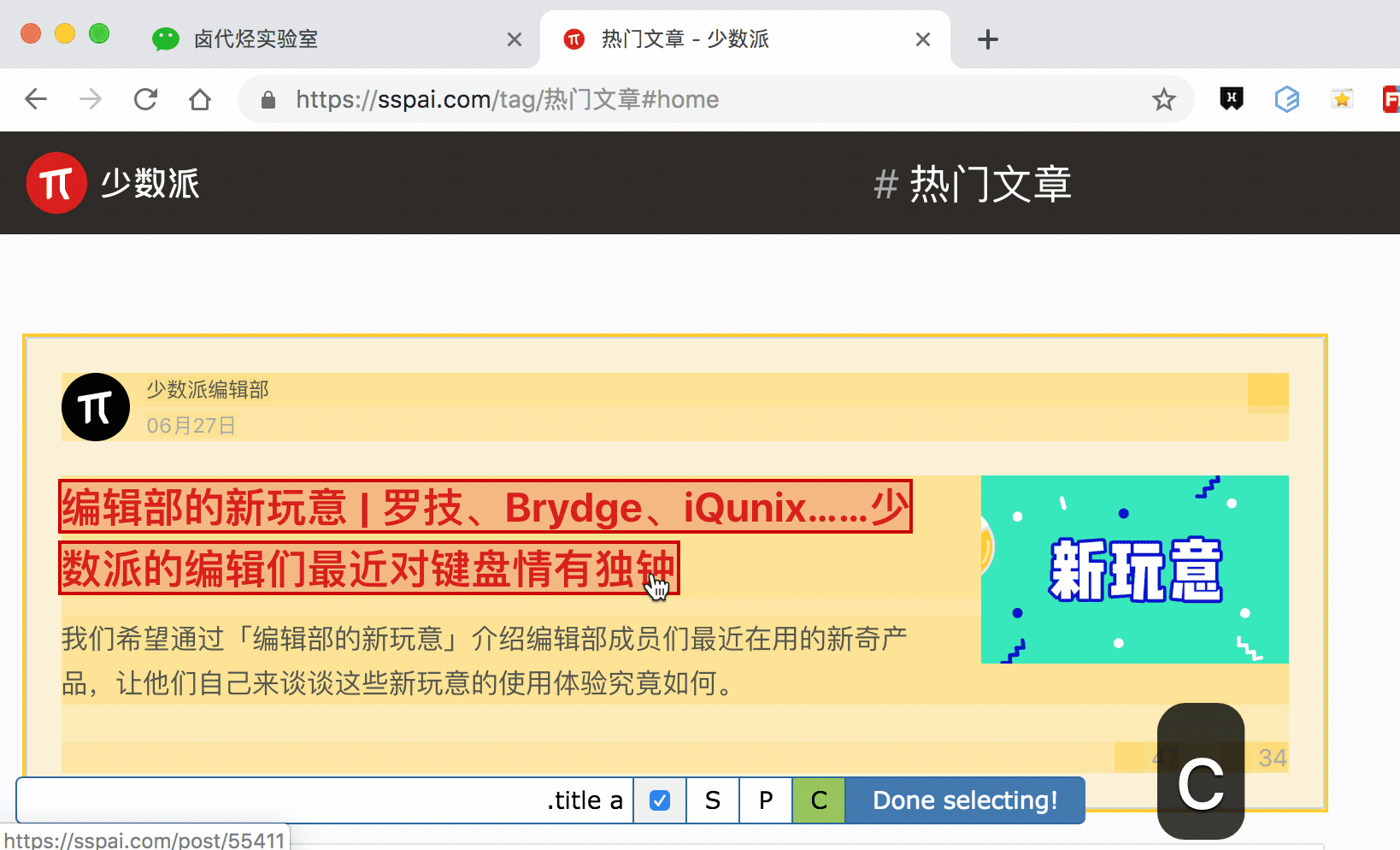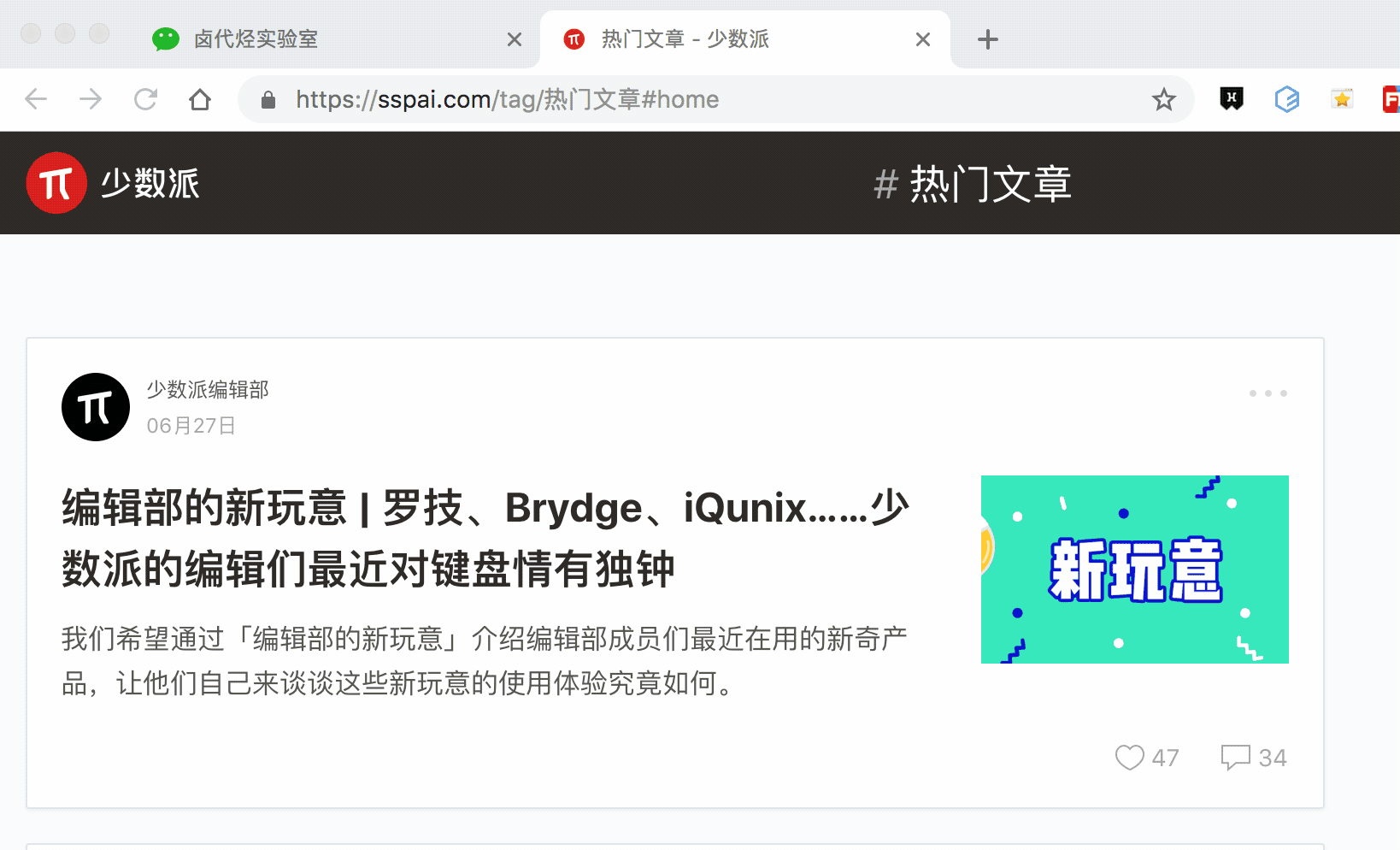
其实 Web scraper 提供了对应的解决方案,那就是通过键盘来选择元素,这样就不会触发点击打开新的网页的问题了。具体的操作面板如下所示,就是我们点击 Done Selecting 的那个控制条。

我们把单选按钮选择后,会出现 S ,P, C 三个字符,意思分别如下:

S:Select,按下键盘的 S 键,选择选中的元素
P:Parent,按下键盘的 P 键,选择选中元素的父节点
C:Child,按下键盘的 C 键,选择选中元素的子节点
我们分别演示一下,首先是通过 S 键选择标题节点:
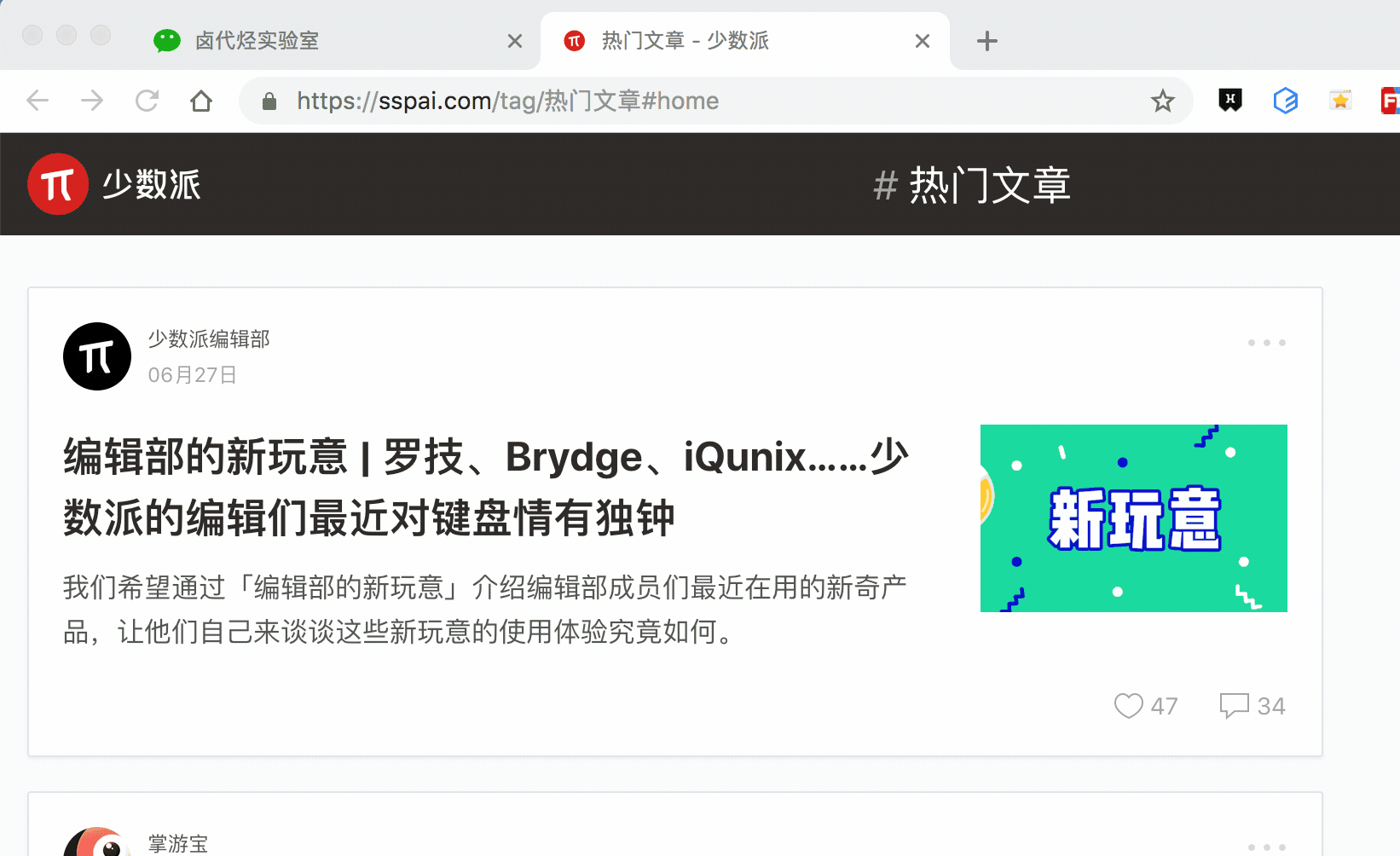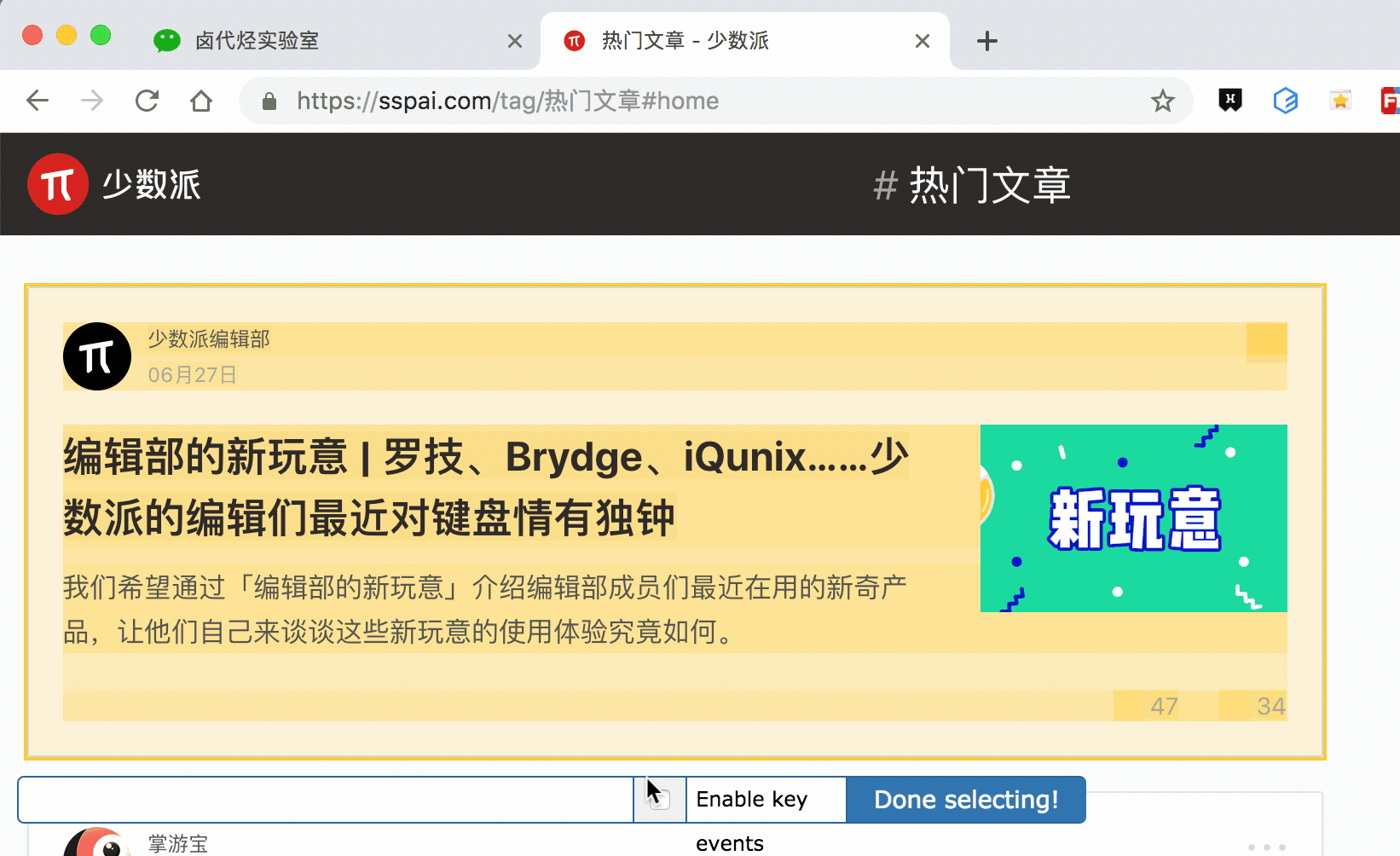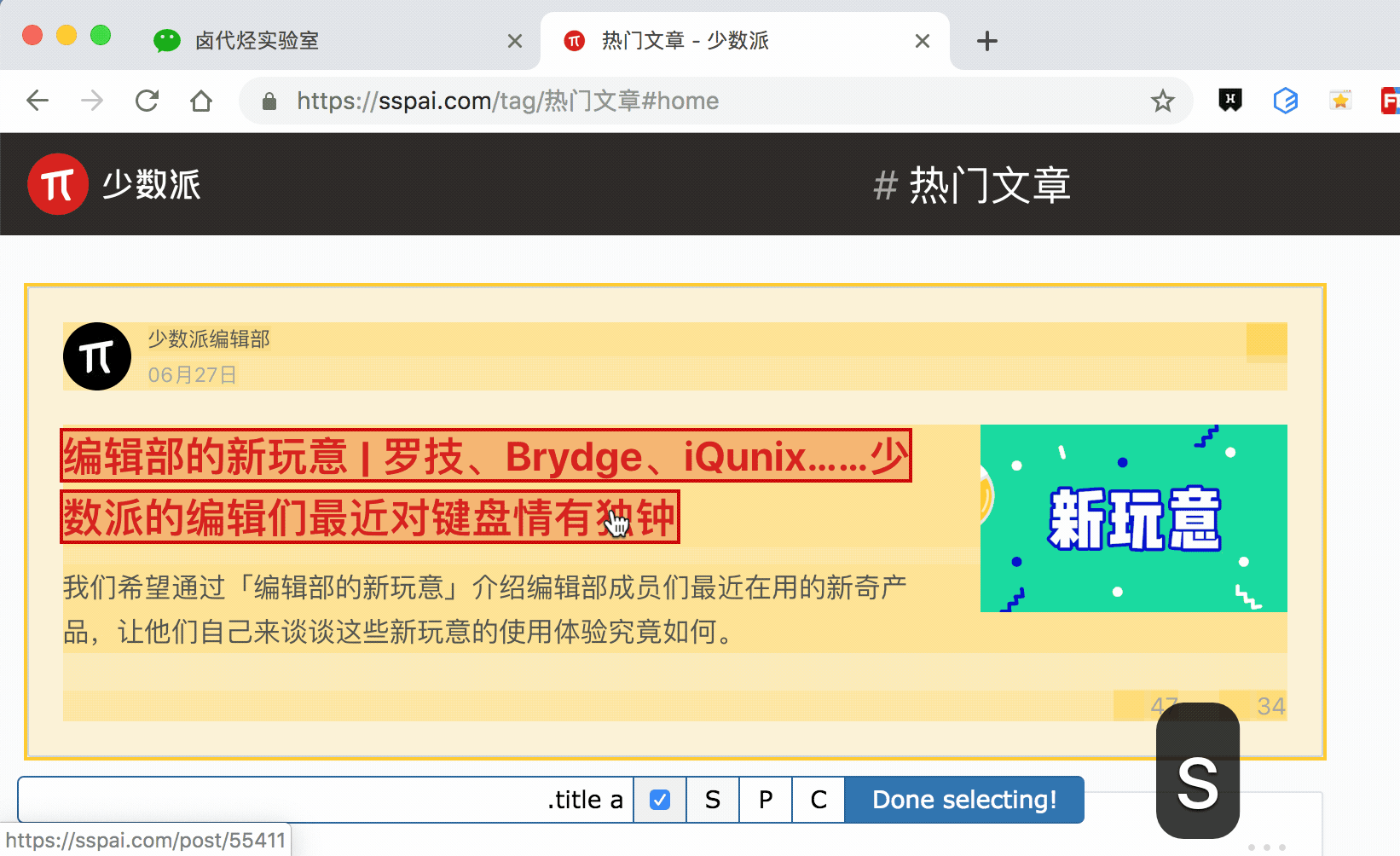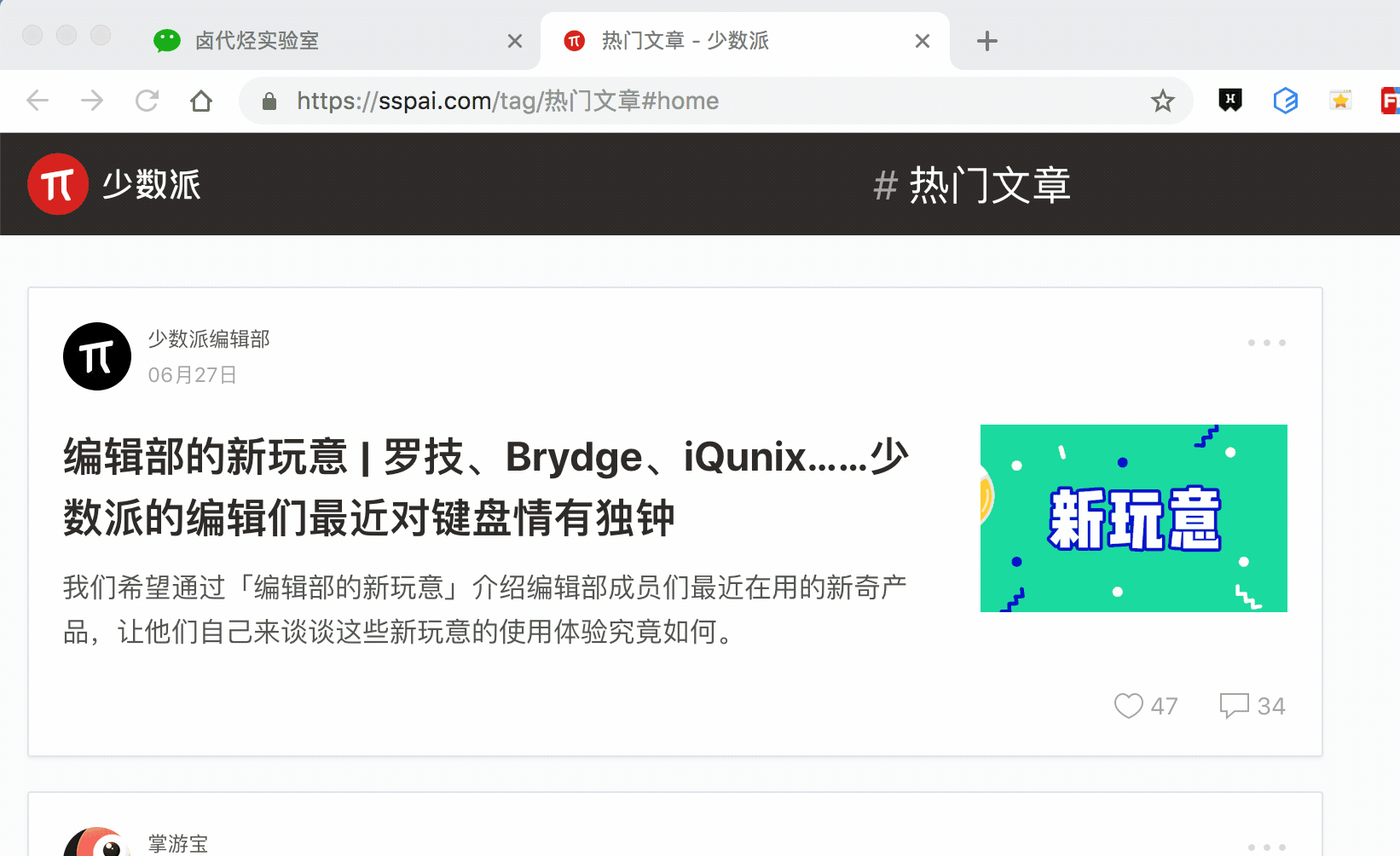
我们对比上个动图,会发现节点选中变红的同时,并没有打开新的网页。
如何抓取选中元素的父节点 or 子节点?
通过 P 键和 C 键选择父节点和子节点:
按压 P 键后,我们可以明显看到我们选择的区域大了一圈,再按 C 键后,选择区域又小了一圈,这个就是父子选择器的功能。
这期介绍了 Web Scraper 的两个使用小技巧,下期我们说说 Web Scraper 如何抓取无限滚动的网页。
联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤蛋实验室」,(或 wx 搜索 egglabs)关注上车防失联。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号