
AI模型的思维方式:激活函数的关键作用及代码示例
在人工智能领域,机器学习是大多数革命性AI应用的基础。从语言处理到图像识别,机器学习无处不在。
机器学习依赖于算法、统计模型和神经网络。而深度学习是机器学习的一个子领域,专注于神经网络。
任何神经网络的关键组成部分都是激活函数。但确切地理解它们为何对任何神经网络系统都是至关重要的,是一个常见的问题,也可能是一个难以回答的问题。
本文重点解释为什么激活函数是必需的,以简单的方式和类比来说明。
通过理解这一点,您将了解到AI模型思维的过程。
在此之前,我们将探讨AI中的神经网络。我们还将探讨最常用的激活函数。
我们还将分析一个非常简单的PyTorch神经网络代码示例的每一行。
(本文视频讲解:java567.com)
本文将探讨以下内容:
- 人工智能与深度学习的崛起
- 理解激活函数:简化神经网络机制
- 简单类比:激活函数的必要性
- 没有激活函数会发生什么?
- PyTorch激活函数代码示例
- 结论:AI神经网络的默默英雄
本文不涵盖辍学或其他正则化技术、超参数优化、复杂架构如CNNs,或者梯度下降变体的详细差异。
我只想展示为什么需要激活函数以及当它们未应用到神经网络时会发生什么。
人工智能与深度学习的兴起
人工智能中的深度学习是什么?

显示社会与人工智能之间联系的图像
深度学习是人工智能的一个子领域。它使用神经网络来处理复杂的模式,就像体育团队为赢得比赛而采用的策略一样。
神经网络越大,就越能够做出令人惊叹的事情 - 就像ChatGPT一样,它使用自然语言处理来回答问题并与用户交互。
要真正理解神经网络的基础知识 - 每个单独的人工智能模型都具有的共同点,使其能够工作 - 我们需要理解激活层。
深度学习 = 训练神经网络

简单神经网络
深度学习的核心是训练神经网络。
这基本上意味着使用数据来获得正确的权重值,以便能够预测我们想要的内容。
神经网络由组织在层中的神经元构成。每一层从数据中提取独特的特征。
这种分层结构使得深度学习模型能够分析和解释复杂的数据。
理解激活函数:简化神经网络机制

Leaky ReLU激活函数
激活函数帮助神经网络处理复杂的数据。它们根据接收到的数据改变神经元的值。
几乎每个神经元在将其值发送到下一个神经元之前都有一个类似的过滤器。
实质上,激活函数控制神经网络的信息流 - 它们决定哪些数据是相关的,哪些是不相关的。
这有助于防止梯度消失,以确保网络正确学习。
梯度消失问题发生在神经网络的学习信号太弱以至于权重值不变时。这使得从数据中学习变得非常困难。
简单类比:激活函数为什么必要

足球运动员思考
在足球比赛中,球员决定是传球、运球还是射门。
这些决定基于当前的比赛情况,就像神经网络中的神经元处理数据一样。
在这种情况下,激活函数在决策过程中起到这样的作用。
如果没有它们,神经元将会毫无选择性地传递数据 - 就像球员毫无思考地踢球,不管比赛背景如何。
这样,激活函数引入了复杂性到神经网络中,使其能够学习复杂的模式。
没有激活函数会发生什么?

球员奔跑
为了理解没有激活函数会发生什么,让我们首先想一想如果在足球比赛中球员毫无考虑地踢球会发生什么情况。
他们很可能会输掉比赛,因为没有团队决策过程。球还是会被踢到某个地方 - 但大部分时间它不会飞往预期的地方。
这与没有激活函数的神经网络所发生的情况相似:神经网络不会做出良好的预测,因为神经元只是随机地向彼此传递数据。
我们仍然会得到一个预测结果。只是不是我们想要的,或者不是有用的。
这严重限制了足球队和神经网络的能力。
对激活函数的直观解释
现在让我们看一个例子,以便您可以直观地理解这一点。
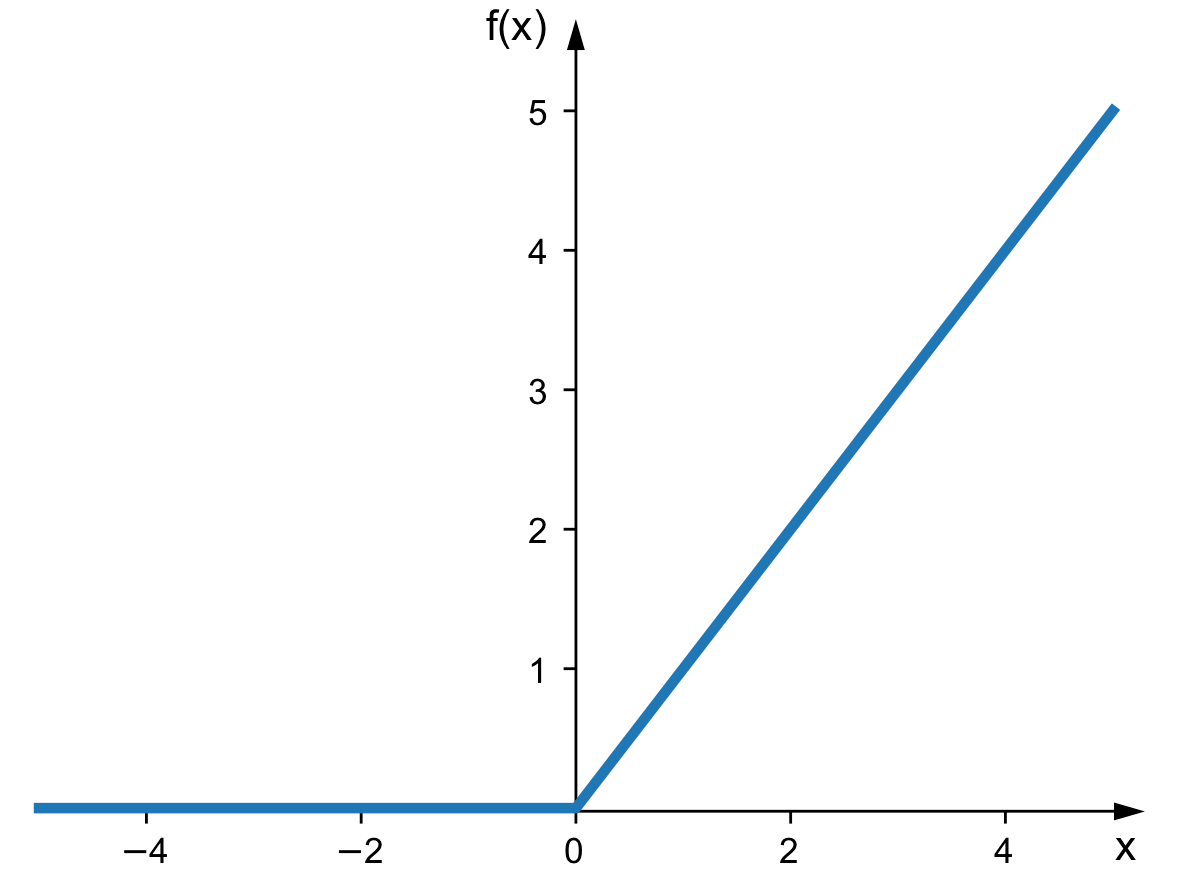
ReLU激活函数
让我们从深度学习中最广泛使用的激活函数开始(它也是最简单的之一)。
这是一个ReLU激活函数。它基本上充当了神经元发送值到其下一个神经元之前的过滤器。
这个过滤器基本上包含两个条件:
- 如果权重值为负,它变为0
- 如果权重值为正,它不改变任何值
通过这样做,我们为每个神经元增加了一个决策过程。它决定发送哪些数据,哪些不发送。
现在让我们看一些其他激活函数的例子。
Sigmoid激活函数
这个激活函数将输入值转换为0到1之间的值。Sigmoid在最后一个神经元中的二元分类问题中广泛使用。

Sigmoid激活函数
不过,Sigmoid激活函数存在问题。考虑给定线性变换的输出值:
- 0.00000003
- 0.99999992
- 0.00000247
- 0.99993320
我们可以询问这些值的一些问题:
- 像0.00000003和0.000002这样的值真的重要吗?它们不能只是0,这样我们就少了要在计算机上运行的东西吗?请记住,在今天的许多模型中,我们有数百万个权重。数百万的0.00000003和0.000002不能是0吗?
- 如果它是一个正值,它如何区分大值和非常大值?例如,在0.99993320和0.99999992中,输入值像7和13或7和55在哪里?0.99993320和0.99999992并没有准确地描述它们的输入值。
我们如何区分输出中微小差异,以保持准确性?
这就是ReLU激活函数解决的问题:将负数设为零,同时保持正数可以增强神经网络的计算效率。
Tanh(双曲正切)激活函数

tanh激活函数
这些激活函数的输出值在-1和1之间,与Sigmoid类似。
它们通常用于循环神经网络(RNNs)和长短期记忆网络(LSTMs)。
Tanh也被使用是因为它是以零为中心的。这意味着输出值的平均值大约为零。这种特性有助于处理梯度消失问题。
Leaky ReLU

Leaky ReLU激活函数
Leaky ReLU激活函数不是忽略负值,而是会有一个小的负值。
这样,当训练神经网络时,负值也会被使用。
使用ReLU激活函数时,带有负值的神经元是不活跃的,并且不会对学习过程做出贡献。
使用Leaky ReLU激活函数时,带有负值的神经元是活跃的,并且对学习过程有所贡献。
这种决策过程是由激活函数实现的。如果没有它,它将简单地将数据发送给下一个神经元(就像球员毫无思考地踢球)。
激活函数的数学解释

数学变换的力量
神经元做两件事情:
- 它们使用以前神经元的权重值进行线性变换
- 它们使用激活函数来过滤某些值以有选择地传递值。
如果没有激活函数,神经网络只做一件事情:线性变换。
如果它只做线性变换,它就是一个线性系统。
如果它是一个线性系统,简单地说而不太技术性地说,叠加定理告诉我们,两个或更多线性变换的任何混合都可以简化为一个单一的变换。
基本上,这意味着,没有激活函数,这个复杂的神经网络:

没有激活函数的长神经网络
与这个简单的神经网络相同:
没有激活函数的短神经网络
这是因为每一层在矩阵形式中都是前一层的线性变换的乘积。
根据定理,由于任何两个或更多线性变换的混合可以简化为一个单一的变换,那么神经网络中隐藏层(即神经元的输入和输出之间的层)的任何混合都可以简化为只有一个层。
这一切意味着什么?
这意味着它只能以线性方式对数据进行建模。但在现实生活中,使用真实数据,每个系统都是非线性的。所以我们需要激活函数。
我们引入非线性到神经网络中,以便它学习非线性模式。
PyTorch激活函数代码示例
在本节中,我们将训练以下神经网络:

简单的前馈神经网络
这是一个简单的神经网络AI模型,具有四层:
- 输入层有10个神经元
- 两个隐藏层,每层有18个神经元
- 一个隐藏层有18个神经元
- 一个输出层有1个神经元
在代码中,我们可以选择本教程中提到的四种激活函数中的任意一种。
下面是完整的代码 - 我们将逐步讨论:
import torch
import torch.nn as nn
import torch.optim as optim
# 在代码中选择要使用的激活函数
defined_activation_function = 'relu'
activation_functions = {
'relu': nn.ReLU(),
'sigmoid': nn.Sigmoid(),
'tanh': nn.Tanh(),
'leaky_relu': nn.LeakyReLU()
}
# 初始化超参数
num_samples = 100
batch_size = 10
num_epochs = 150
learning_rate = 0.001
# 定义一个简单的合成数据集
def generate_data(num_samples):
X = torch.randn(num_samples, 10)
y = torch.randn(num_samples, 1)
return X, y
# 生成合成数据
X, y = generate_data(num_samples)
class SimpleModel(nn.Module):
def __init__(self, activation=defined_activation_function):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(in_features=10, out_features=18)
self.fc2 = nn.Linear(in_features=18, out_features=18)
self.fc3 = nn.Linear(in_features=18, out_features=4)
self.fc4 = nn.Linear(in_features=4, out_features=1)
self.activation = activation_functions[activation]
def forward(self, x):
x = self.fc1(x)
x = self.activation(x)
x = self.fc2(x)
x = self.activation(x)
x = self.fc3(x)
x = self.activation(x)
x = self.fc4(x)
return x
# 初始化模型,定义损失函数和优化器
model = SimpleModel(activation=defined_activation_function)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练循环
for epoch in range(num_epochs):
for i in range(0, num_samples, batch_size):
# 获取小批量数据
inputs = X[i:i+batch_size]
labels = y[i:i+batch_size]
# 梯度清零
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播和优化
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {loss}')
print("训练完成。")
看起来有点多,不是吗?别担心 - 我们会一步步来解释。
1: 导入库并定义激活函数
import torch
import torch.nn as nn
import torch.optim as optim
# 在代码中选择要使用的激活函数
defined_activation_function = 'relu'
activation_functions = {
'relu': nn.ReLU(),
'sigmoid': nn.Sigmoid(),
'tanh': nn.Tanh(),
'leaky_relu': nn.LeakyReLU()
}

导入库并定义包含激活函数的字典
在这段代码中:
import torch:导入PyTorch库。import torch.nn as nn:从PyTorch导入神经网络模块。import torch.optim as optim:从PyTorch导入优化模块。
上述变量和字典帮助您轻松地为这个深度学习模型定义要使用的激活函数。
2: 定义超参数并生成数据集
# 初始化超参数
num_samples = 100
batch_size = 10
num_epochs = 150
learning_rate = 0.001
# 定义一个简单的合成数据集
def generate_data(num_samples):
X = torch.randn(num_samples, 10)
y = torch.randn(num_samples, 1)
return X, y
# 生成合成数据
X, y = generate_data(num_samples)
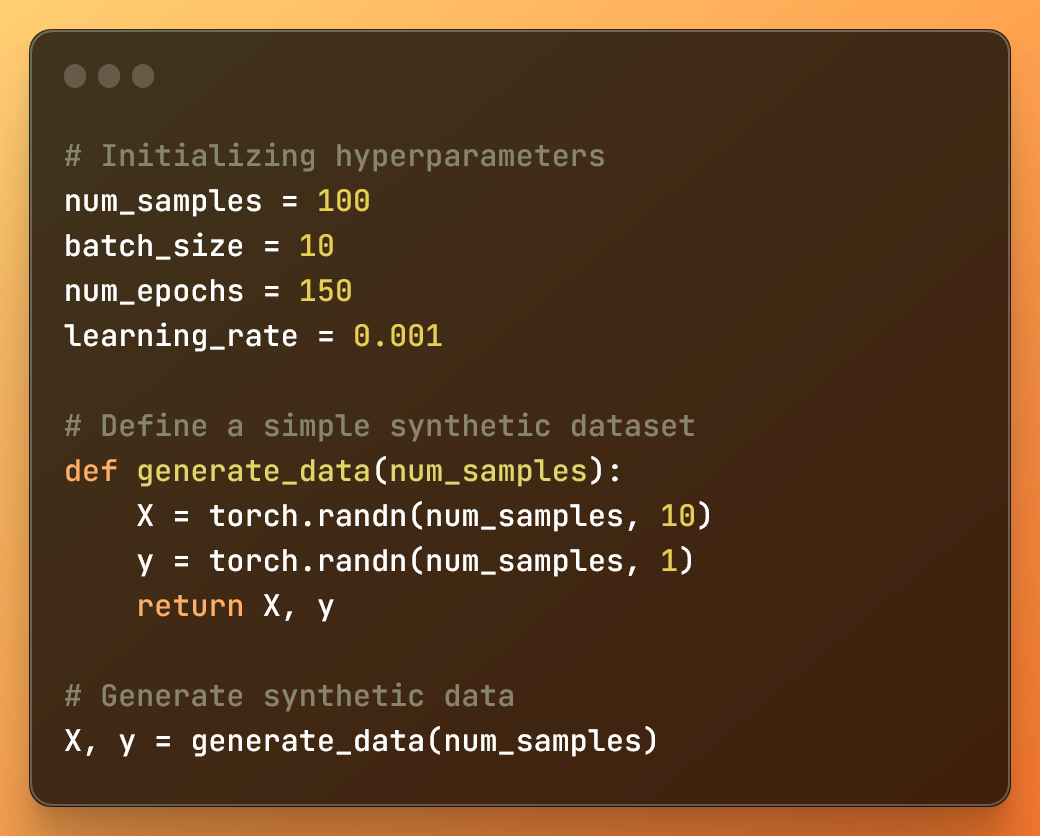
初始化超参数并使用函数创建合成数据集
在这段代码中:
num_samples是合成数据集中的样本数量。batch_size是训练过程中每个小批量的大小。num_epochs是在训练期间对整个数据集进行迭代的次数。learning_rate是优化算法使用的学习率。
此外,我们定义了一个 generate_data 函数来创建两个具有随机值的张量。然后调用该函数,为 X 和 y 生成具有随机值的两个张量。
3: 创建深度学习模型
class SimpleModel(nn.Module):
def __init__(self, activation=defined_activation_function):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(in_features=10, out_features=18)
self.fc2 = nn.Linear(in_features=18, out_features=18)
self.fc3 = nn.Linear(in_features=18, out_features=4)
self.fc4 = nn.Linear(in_features=4, out_features=1)
self.activation = activation_functions[activation]
def forward(self, x):
x = self.fc1(x)
x = self.activation(x)
x = self.fc2(x)
x = self.activation(x)
x = self.fc3(x)
x = self.activation(x)
x = self.fc4(x)
return x

一个简单的前馈神经网络深度学习模型
SimpleModel 类中的 __init__ 方法初始化了神经网络架构。它初始化了四个全连接层,并定义了我们将要使用的激活函数。
我们使用 nn.Linear 创建每一层,而 forward 方法定义了数据在神经网络中的流动方式。
4: 初始化模型并定义损失函数和优化器
model = SimpleModel(activation=defined_activation_function)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)

定义激活函数、损失函数和要使用的梯度下降变体
在这段代码中:
model = SimpleModel(activation=defined_activation_function)创建了一个带有指定激活函数的神经网络模型。criterion = nn.MSELoss()定义了均方误差(MSE)损失函数。optimizer = optim.Adam(model.parameters(), lr=learning_rate)设置了Adam优化器,用于在训练期间更新模型参数,并指定了学习率。
5: 训练深度学习模型
for epoch in range(num_epochs):
for i in range(0, num_samples, batch_size):
# 获取小批量数据
inputs = X[i:i+batch_size]
labels = y[i:i+batch_size]
# 梯度清零
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播和优化
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {loss}')
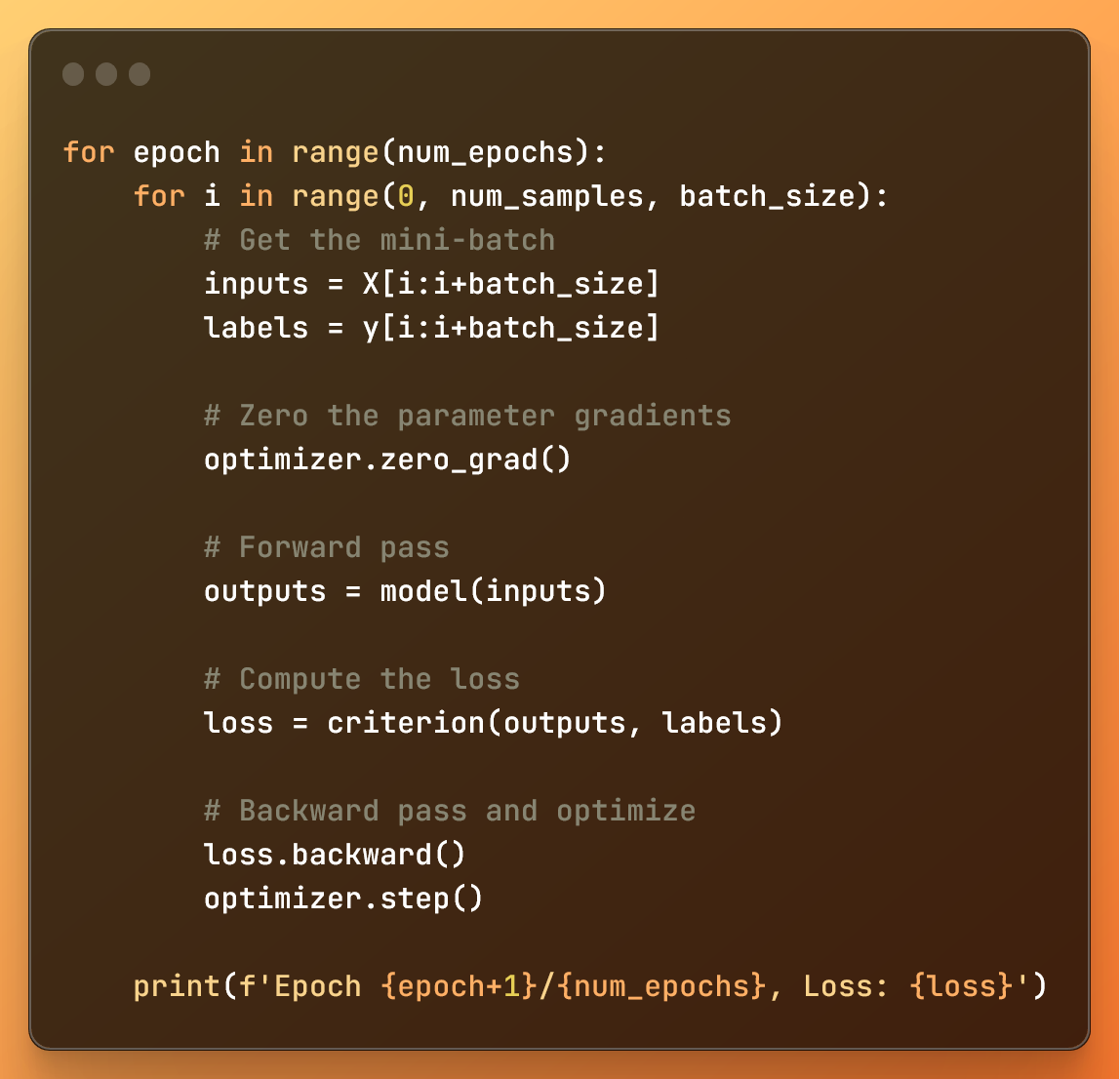
训练模型
- 外循环基于
num_epochs(迭代次数)控制整个数据集的处理次数。 - 内循环使用
range函数将数据集分成小批量。
在每个小循环中:
- 使用输入和标签,我们获取要处理的小批量数据。
- 我们使用
optimizer.zero_grad()消除上一个小批量迭代的梯度 - 这很重要,以防止在小批量之间混合梯度信息。 - 通过前向传播得到模型预测值(
outputs),并使用指定的损失函数(criterion)计算损失。 - 使用
loss.backward()计算权重的梯度。 - 最后,
optimizer.step()基于这些梯度更新模型的权重,以最小化损失函数。
这是在非常简单的数据集上训练非常简单的深度学习模型的完整代码。
它没有更高级的内容,比如卷积神经网络。
结论:AI神经网络的默默英雄
激活函数就像守门员一样。通过限制信息的流动,神经网络可以更好地学习。
激活函数就像人们学习时或足球运动员决定如何处理球时一样。
这些函数赋予了神经网络学习和正确预测的能力。
从数学上讲,激活函数是神经网络中正确逼近任何线性或非线性函数的关键。没有它们,神经网络只能逼近线性函数。
(本文视频讲解:java567.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号