Hadoop之HDFS数据写流程和写失败的情况
HDFS的写流程
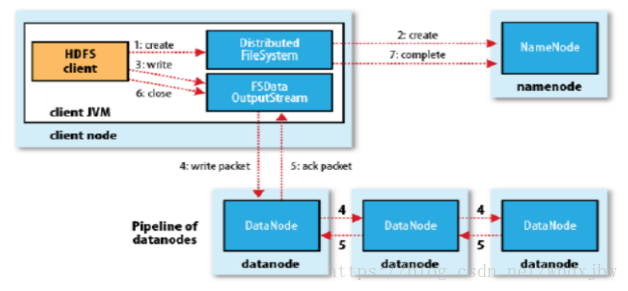
- 首先客户端通过DistributedFileSystem上调用create()方法来创建一个文件。
- DistributedFileSystem使用RPC呼叫NameNode,让NameNode在NameSpace上创建一个没有与任何关联的新文件,并确认客户端是否拥有创建文件的权限,如果检查通过,NameNode就会为新文件生成一条记录;不然文件创建失败,客户端会抛出IOException,成功之后,DistributedFileSystem会返回一个FSDataOutputStream(其中包装了一个DFSOutputStream,DFSOutputStream,其掌握了与DataNode与NameNode的练习)给客户端。
- 客户端开始写数据,DFSOutputStream将文件分割成很多很小的数据,然后将每个小块放进一个个包(数据包,包中除了数据还有描述数据用的标识)中,这些包会写进一个名为数据队列(Data quence)的内部队列。
- 数据队列被DataStream消费,DataStream负责NameNode去挑选出适合存储块备份的DataNode的一个队列。这个列表会构成一个pipline,包流进pipline后存储在DataNode中。
- DFSOutputStream也会维护一个包门的内部队列,其中也会有所有的数据包,该队列等待Dataode门的写入确认,所以叫做确认队列(ack quence),当一个包被pipeline中的所有DataNode确认写入磁盘成功,这个包才会从确认队列中移除。
- 当客户端完成了数据写入,会在流上调用close()方法,这个行为会将所有剩下的包flush进DataNode中。
- 之后等待确认信息到达之后,客户端就联系NameNode告之文件数据已经放好。
写失败的情况与解决方案
DataNode写入数据失败
- pipeline被关闭,在确认队列中剩下的包会被添加进数据队列的起始位置上,以至于在失败的节点下游的任何节点都不会丢失任何的包。
- 之后与NameNode练习后,当前在一个好的DataNode会联系NameNode,给失败节点上还未写完的块生成一个新的标识ID,以至于如果这个失败的DataNode不久后恢复了,这个不完整的块会被删除。
- 失败节点从pipeline中移除,之后剩下来好的DataNode会组成一个新的pipeline,剩下的这些块(刚刚放进数据队列队首的包)会继续写进pipeline中好的DataNode中。
- 最后,NameNode注意到备份数小于规定的备份数,它就安排在另一个节点上创建完成备份,直接从已有的块中复制就好了。直到满足了备份数。如果有多个节点写入失败了,如果满足了最小备份数的设置,写入也将成功,之后剩下的备份会被集群异步的执行备份,直到满足了备份数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号