Encoder-Decoder 架构实现
基于循环网络实现编解码结构,代码参考了Jason Brownlee博士博客,看上去博士也是参考官方文档的内容。
1. 本人进行了一些注释。
2. 该架构并不是循环网络特有。
3. 序列的多部预测遵循循环导出的原则。
4.其中的隐状态和细胞状态确实依赖于LSTM这个特定模型
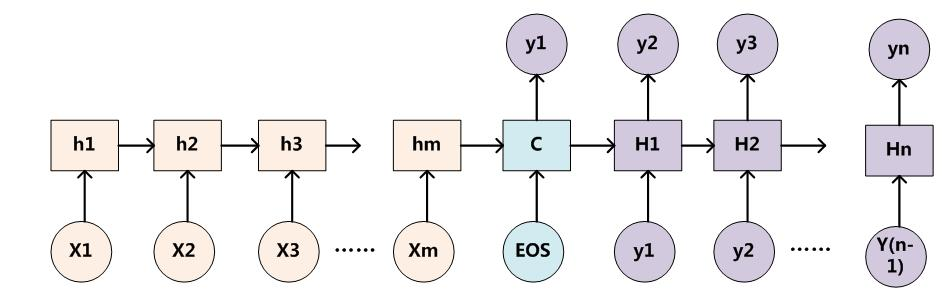
5. 对于上图的结构,基于循环网络的编解码结构,不忍许多人扯的血淋淋,故鄙人希望从简抓要点。
遵循一般做事原则:找出口或入口或转折点等重要接口;分割出循环单体。
a. 重要接口在于中间的状态
b. 循环单体在于循环网络时间步骤
c. 做过时间序列预测不难看出,解码器完成从不等长序列空间到状态空间的映射,状态没有时间步骤概念(指的就是在某个时间戳下;解码器就是一个一阶时间序列预测(错开一步预测);
既然是循环就需要起始条件,这也就是跟差分方程(或者微分方程)的起始条件差不多,由编码器提供;时间序列的玩法,与经典统计中类似,一步模型的多步预测就按如下方式搞。
1 from random import randint 2 from numpy import array, argmax, array_equal 3 from keras.utils import to_categorical 4 from keras.models import Model 5 from keras.layers import Input, LSTM, Dense 6 7 # generate a sequence of random integers 8 def generate_sequence(length, n_unique): 9 return [randint(1, n_unique-1) for _ in range(length)] 10 11 12 # prepare data for the LSTM 13 def get_dataset(n_in, n_out, cardinality, n_samples): 14 X1, X2, y = list(), list(), list() 15 for _ in range(n_samples): 16 # generate source sequence 17 source = generate_sequence(n_in, cardinality) 18 # define padded target sequence 19 target = source[:n_out] 20 target.reverse() 21 # create padded input target sequence 22 target_in = [0] + target[:-1] 23 # encode 24 src_encoded = to_categorical(source, num_classes=cardinality) 25 tar_encoded = to_categorical(target, num_classes=cardinality) 26 tar2_encoded = to_categorical(target_in, num_classes=cardinality) 27 # store 28 X1.append(src_encoded) 29 X2.append(tar2_encoded) 30 y.append(tar_encoded) 31 return array(X1), array(X2), array(y) 32 33 34 # returns train, inference_encoder and inference_decoder models 35 def define_models(n_input, n_output, n_units): 36 # 定义训练编码器 37 encoder_inputs = Input(shape=(None, n_input)) # n_input表示特征这一维(维的大小即特征的数目,如图像的feature map) 38 encoder = LSTM(n_units, return_state=True) # 编码器的特征维的大小dimension(n),即单元数。 39 encoder_outputs, state_h, state_c = encoder(encoder_inputs) # 取出输入生成的隐藏状态和细胞状态,作为解码器的隐藏状态和细胞状态的初始化值。 40 # 定义训练解码器 41 decoder_inputs = Input(shape=(None, n_output)) # n_output:输出响应序列的特征维的大小。 42 decoder_lstm = LSTM(n_units, return_sequences=True, return_state=True) # 因解码器用编码器的隐藏状态和细胞状态,所以n_units必等 43 decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=[state_h, state_c]) # 这个解码层在后面推断中会被共享!! 44 45 decoder_dense = Dense(n_output, activation='softmax') # 这个full层在后面推断中会被共享!! 46 decoder_outputs = decoder_dense(decoder_outputs) 47 model = Model([encoder_inputs, decoder_inputs], decoder_outputs) # 得到以输入序列和目标序列作为输入,以目标序列的移位为输出的训练模型 48 49 # 定义推断编码器 根据输入序列得到隐藏状态和细胞状态的路径图,得到模型,使用的输入到输出之间所有层的权重,与tf的预测签名一样 50 encoder_model = Model(encoder_inputs, [state_h, state_c]) # 层编程模型很简单,只要用Model包住其输入和输出即可。 51 #encoder_outputs, state_h, state_c = encoder(encoder_inputs) # ? 似乎就是上面的 52 # 定义推断解码器,由于循环网络的性质,由输入状态(前)推理出输出状态(后)。 53 decoder_state_input_h = Input(shape=(n_units,)) 54 decoder_state_input_c = Input(shape=(n_units,)) 55 56 decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=[decoder_state_input_h, decoder_state_input_c]) 57 decoder_outputs = decoder_dense(decoder_outputs) 58 # 由老状态更新出新的状态 59 decoder_model = Model([decoder_inputs, decoder_state_input_h, decoder_state_input_c], [decoder_outputs, state_h, state_c]) 60 # return all models 61 return model, encoder_model, decoder_model 62 63 64 # generate target given source sequence 65 def predict_sequence(infenc, infdec, source, n_steps, cardinality): 66 # encode 67 h_state, c_state = infenc.predict(source) # 根据输入计算该原输入在状态空间的取值 68 # start of sequence input 69 target_seq = array([0.0 for _ in range(cardinality)]).reshape(1, 1, cardinality) # shape (1, 1, 51) [[[0,0,..]]] 一步 70 # collect predictions 71 output = list() 72 for t in range(n_steps): 73 # predict next char 这是递归网络的序列预测过程 74 yhat,h_state, c_state = infdec.predict([target_seq, h_state, c_state]) # 获得循环地推的target_seq初始值,不停迭代产生新值 75 # store prediction 76 output.append(yhat[0, 0, :]) 77 # update state 78 # update target sequence 79 target_seq = yhat 80 return array(output) 81 82 # decode a one hot encoded string 83 def one_hot_decode(encoded_seq): 84 return [argmax(vector) for vector in encoded_seq] 85 86 # configure problem 87 n_features = 50 + 1 88 n_steps_in = 6 89 n_steps_out = 3 90 # define model 91 train, infenc, infdec = define_models(n_features, n_features, 128) 92 train.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc']) # 这一层需要被编译 93 # generate training dataset 94 X1, X2, y = get_dataset(n_steps_in, n_steps_out, n_features, 100000) 95 print(X1.shape,X2.shape,y.shape) 96 # train model 97 train.fit([X1, X2], y, epochs=1) 98 # evaluate LSTM 99 total, correct = 100, 0 100 # for _ in range(total): 101 # X1, X2, y = get_dataset(n_steps_in, n_steps_out, n_features, 1) 102 # target = predict_sequence(infenc, infdec, X1, n_steps_out, n_features) 103 # if array_equal(one_hot_decode(y[0]), one_hot_decode(target)): 104 # correct += 1 105 # print('Accuracy: %.2f%%' % (float(correct)/float(total)*100.0)) 106 # spot check some examples 107 for _ in range(10): 108 X1, X2, y = get_dataset(n_steps_in, n_steps_out, n_features, 1) 109 target = predict_sequence(infenc, infdec, X1, n_steps_out, n_features) 110 print('X=%s y=%s, yhat=%s' % (one_hot_decode(X1[0]), one_hot_decode(y[0]), one_hot_decode(target)))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号