2.安装Spark与Python练习
一、安装Spark
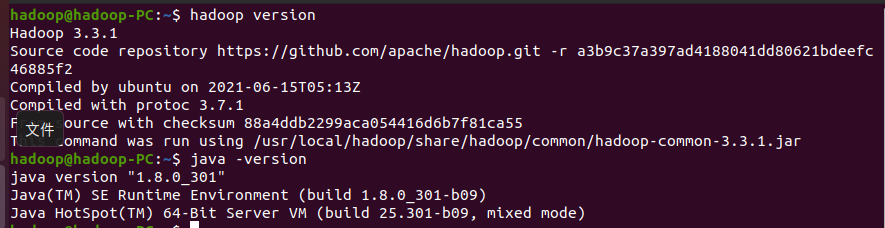
1.检查基础环境hadoop,jdk
2.下载spark(已操作)略
3.解压,文件夹重命名、权限(已操作)略
4.配置文件

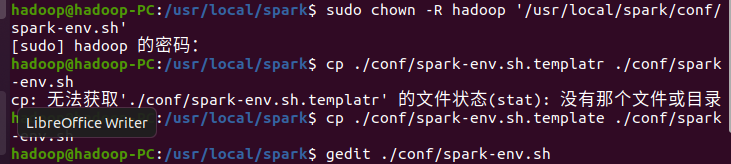
编辑该配置文件,在文件最后面加上如下一行内容:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
5.环境变量

在gedit ~/.bashrc加入代码
export SPARK_HOME=/usr/local/spark export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9-src.zip:PYTHONPATH export PYSPARK_PYTHON=python3 export PATH=$PATH:$SPARK_HOME/bin
6.试运行Python代码
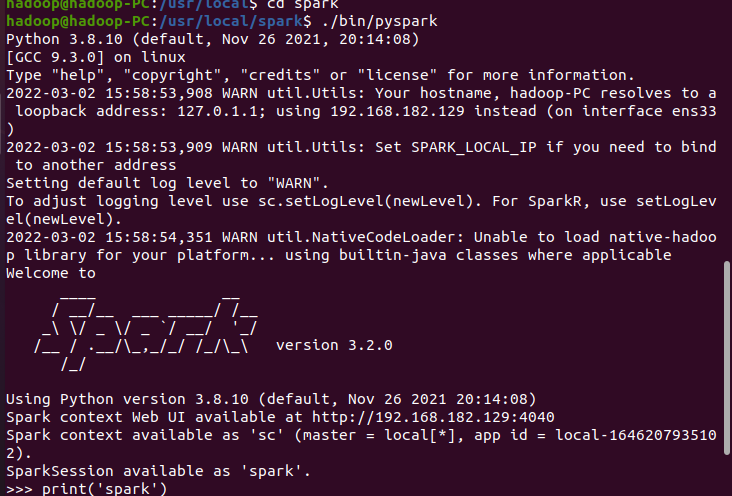
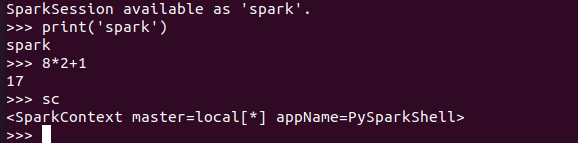
二、Python编程练习:英文文本的词频统计
1.准备文本文件
f1.txt
2.读文件
txt = open("f1.txt", "r",encoding='UTF-8').read()
3.预处理:大小写,标点符号,停用词
txt = txt.lower()
for ch in '!"@#$%^&*()+,-./:;<=>?@[\\]_`~{|}':
txt=txt.replace(ch," ")
words = txt.split()
stop_words = ['so','out','all','for','of','to','on','in','if','by','under','it','at','into','with','about']
4.分词
lenwords=len(words) afterwords=[] for i in range(lenwords): z=1 for j in range(len(stop_words)): if words[i]==stop_words[j]: continue else: if z==len(stop_words): afterwords.append(words[i]) break z=z+1 continue counts = {}
5.统计每个单词出现的次数
for word in afterwords: counts[word] = counts.get(word,0) + 1 items = list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) i=1
6.按词频大小排序
while i<=len(items):
word,count = items[i-1]
print("{0:<20}{1}".format(word,count))
i=i+1
7.结果写文件
txt= open("f1.txt", "w",encoding='UTF-8')
txt.write(str(items))
print("文件写入成功")
结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号