决策树---------2020.9.20
一、 机器学习数据集
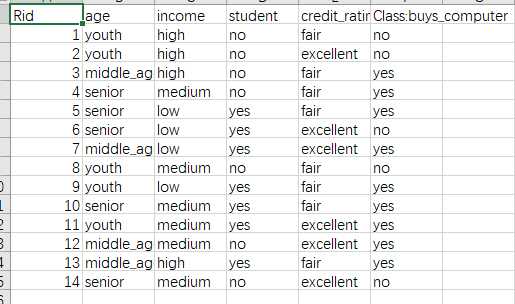
这组记录的集合称为一个“数据集”,其中每条记录是关于一个事件或对象的描述,称为一个“示例”或“样本”,反映事件或对象在某方面的表现或性质的事项,属性的取值称为属性值,属性展开的空间称为“属性空间”。
二、 分类/回归
三、 信息熵
ex1.
P(A)=1/4
P(B)=1/4
P(C)=1/4
P(D)=1/4
ex2.
P(A)=1/2
P(B)=1/4
P(C)=1/8
P(D)=1/8
如何编码?
对于ex1,我们可以编码A=00,B=01,C=10,D=11,显然我们需要用到两个bit来记录事件;对于ex2,我们可以编码A=0,B=10,C=110,D=111,所需bit数为
1×1/2+2×1/4+3×1/8+3×1/8=1.75bit。
记P(X=V1)=p1,P(X=V2)=p2,P(X=V3)=p3,…,P(X=Vm)=pm,如何计算传输信息需要的最小bit数是多少?
高信息熵意味着我们从数据集中获取的信息越少,不确定度越大;
低信息熵意味着我们从数据集中获取的信息越多,不确定度越小。
四、 列联表
列联表(contingency table)是观测数据按两个或更多属性(定性变量)分类时所列出的频数表。它是由两个以上的变量进行交叉分类的频数分布表。
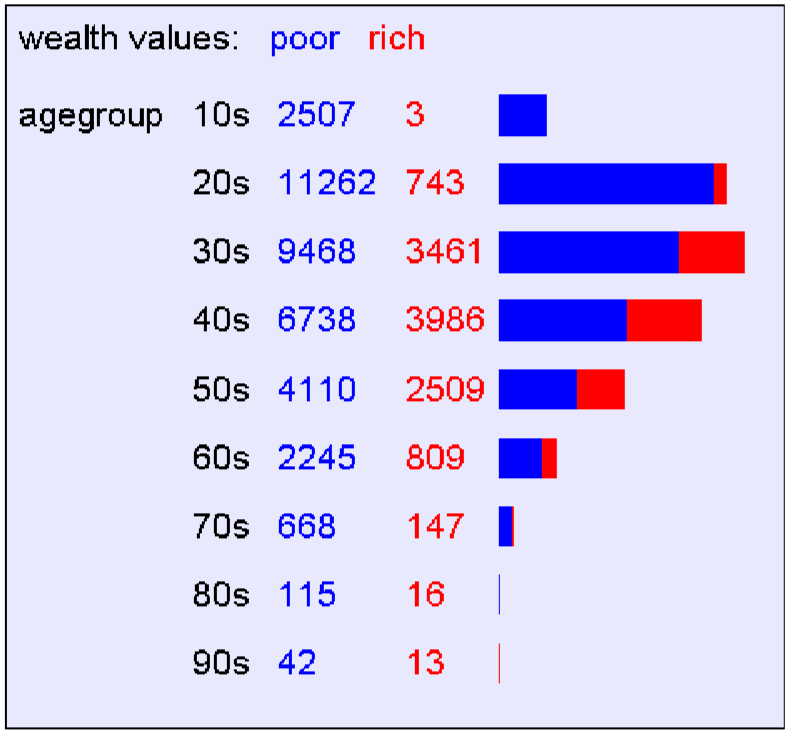
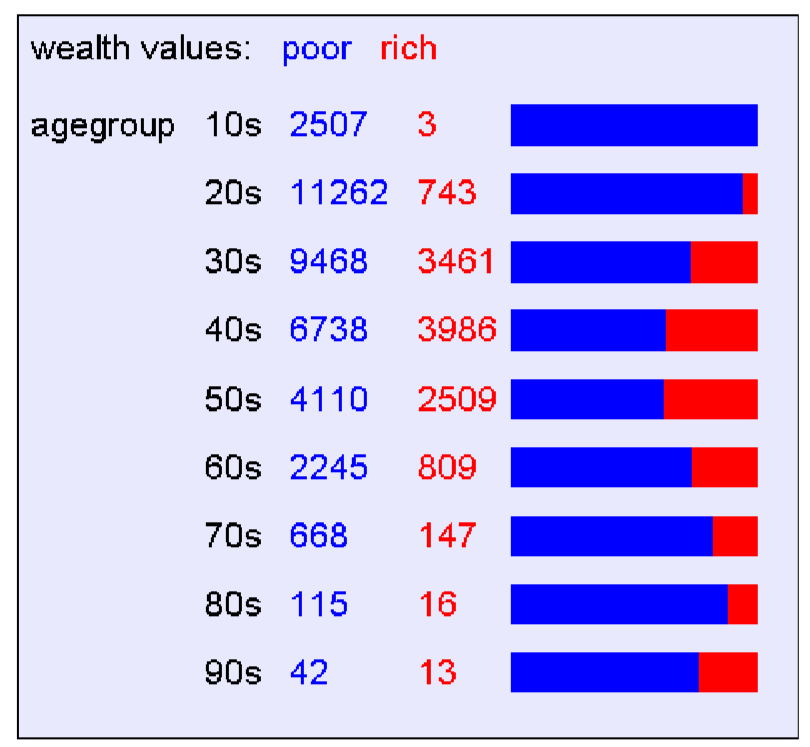
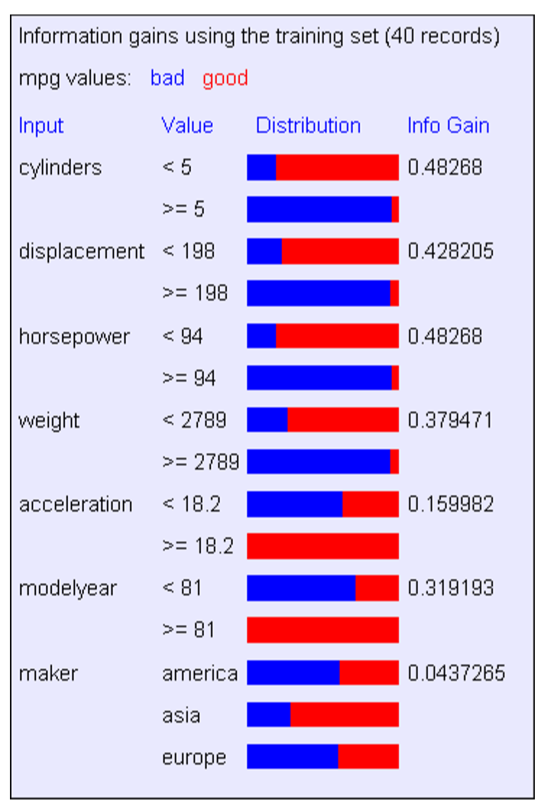
五、 信息增溢

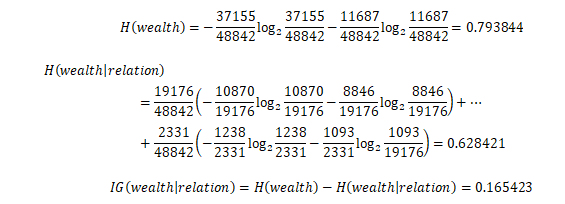
对各个参数依次方法进行计算,从而找到信息增溢最大的属性。
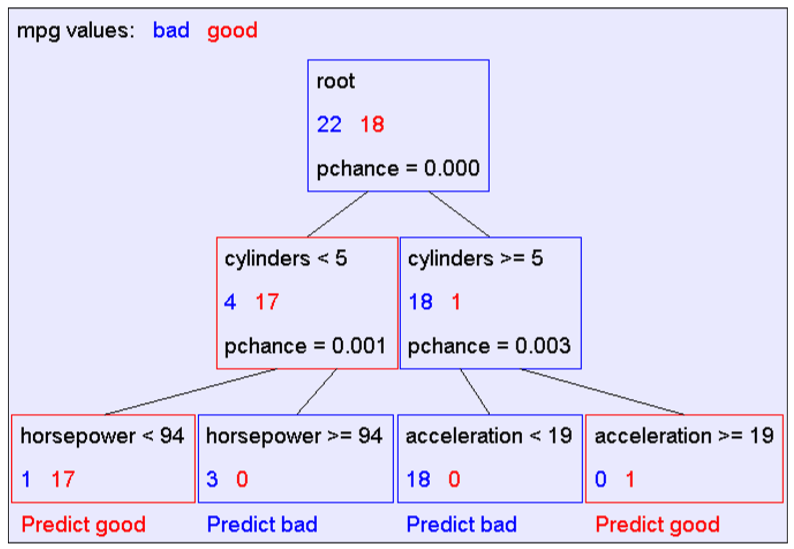
六、 生成决策树
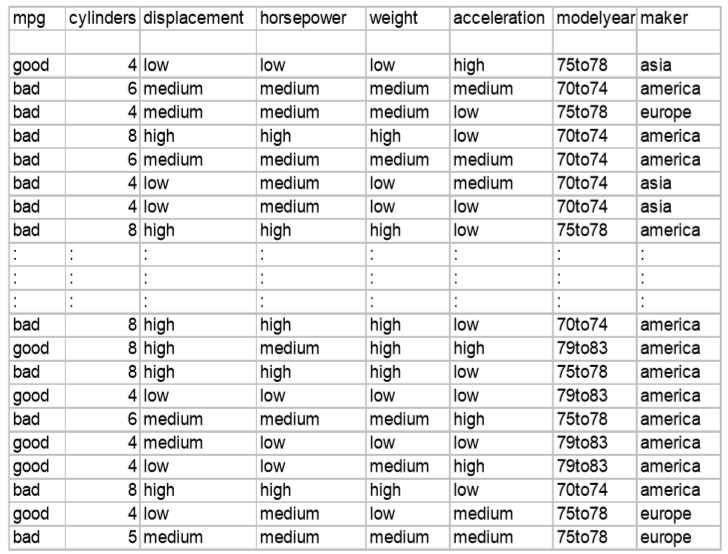
树以代表训练样本的单个结点开始。
如果样本都在同一个类,则该结点成为树叶,并用该类标号。
否则,算法使用称为信息增益的基于熵的度量作为启发信息,选择能够最好地将样本分类的属性。该属性成为该结点的“测试”或“判定”属性。
对测试属性的每个已知的值,创建一个分枝,并据此划分样本。
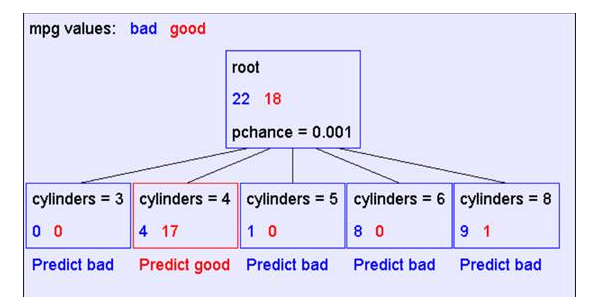
算法使用同样的过程,递归地形成每个划分上的样本判定树。
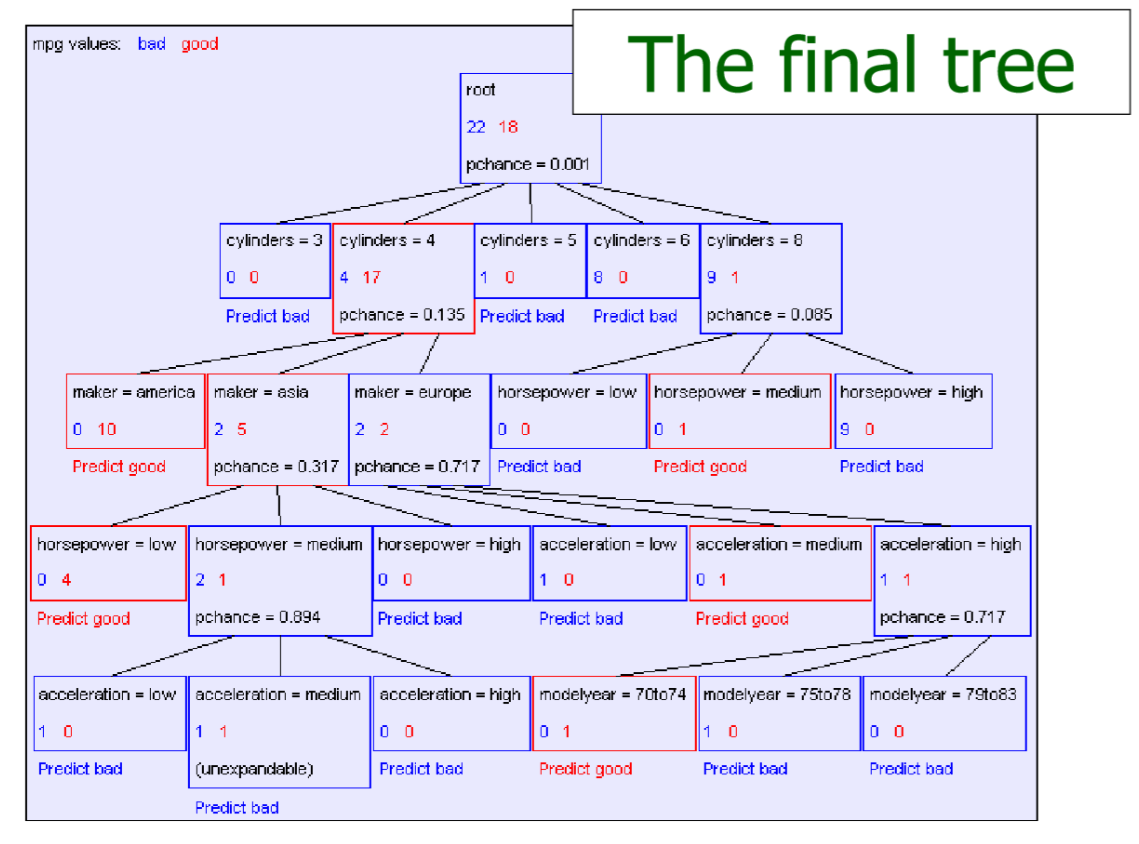
Tips:1.如果叶子节点都有同样的输出值,例如
,则该节点停止递归;
2.没有多余的属性可以进行划分,此时少数服从多数。
思考:若所有属性的信息增溢都是零就停止递归是否合理?
令Y=a XOR b
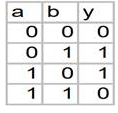
如果信息增益为0就停止递归,则生成决策树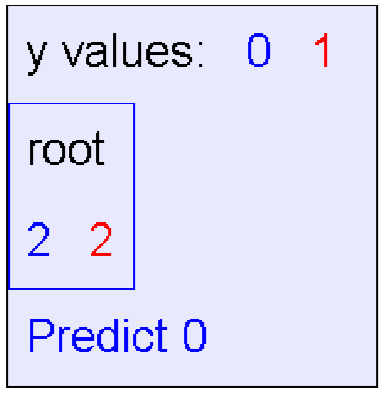
如果继续递归,则生成决策树
,显然这才是我们想要的结果。
七、 训练集误差与测试集误差
对所有训练集记录用生成的决策树进行预测,预测输出与实际输出不一致的记录量称为训练集误差。
对所有测试集记录用生成的决策树进行预测,预测输出与实际输出不一致的记录量称为测试集误差。
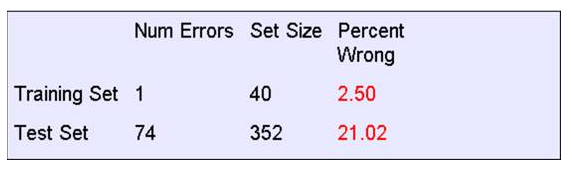
为啥测试集误差比训练集误差差这么多?
八、 过拟合
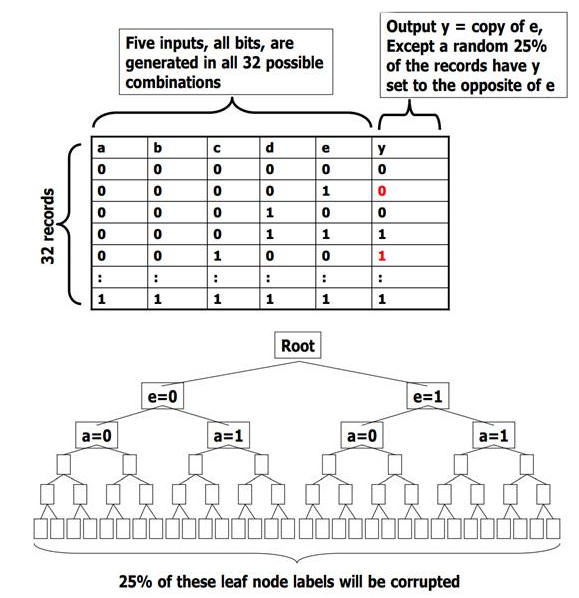
所有叶节点有且仅有一个记录,所以训练集误差为0。
用测试集进行测试:
| 错误的叶节点(1/4) | 正确的叶节点(3/4) | |
|---|---|---|
| 错误的测试集(1/4) | 1/16的测试集会因为错误的理由被正确的预测 | 3/16的测试集会因为测试集记录的错误被错误的预测 |
| 正确的测试集(3/4) | 3/16的测试集会因为叶节点预测错误而被错误的预测 | 9/16的测试集被正确的预测 |
结果:一共有3/8的测试集被错误预测。
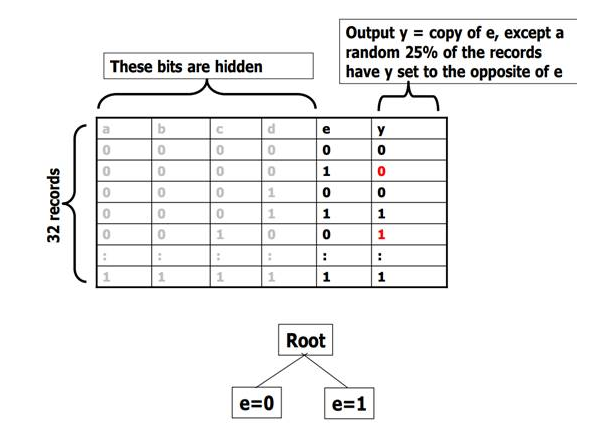
e=0叶结点共有16个记录,正确的记录约占75%即12个,所以该节点几乎一定会预测正确;同理e=1叶节点也几乎一定会预测正确。
| 几乎不存在错误的叶节点 | 几乎所有叶结点都正确 | |
|---|---|---|
| 错误的测试集(1/4) | ≈0 | 因为测试集记录错误,1/4的测试集会被错误的预测 |
| 正确的测试集(3/4) | ≈0 | 3/4的测试集被正确的预测 |
结果:一共有1/4的测试集被错误预测。
过拟合定义:如果机器学习算法过于匹配噪音或者过于匹配数据集中不相关的属性,则会导致过拟合。如果机器学习算法过拟合,在测试集上的预测通常不会好。
九、避免过拟合
一般来说我们一开始并不知道数据集中的属性哪些与输出并不相关,并且有时候属性与输出与否还与上下文有关(例如Y=a AND b,当b=0的时候,y的输出显然与a不相关)。

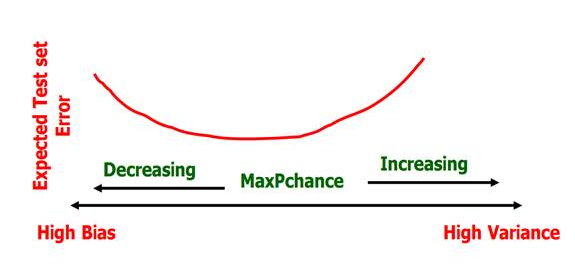
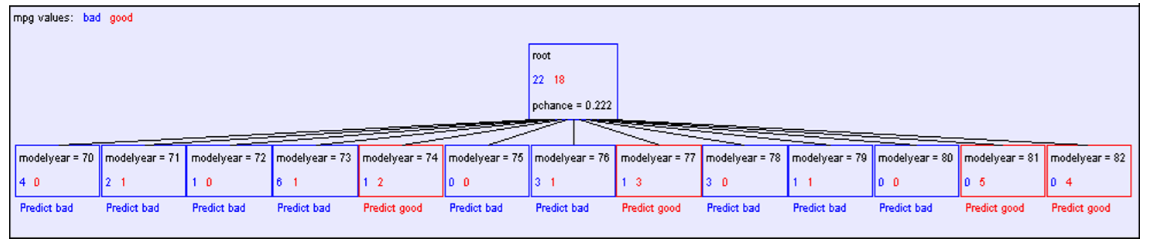
卡方检验:
计算得P(mpg与maker相互独立)=13.5%
使用卡方检验避免过拟合的方法:
-
用之前的方法生成决策树;
-
开始剪枝,从决策树底部开始删除所有p>MaxPChance的节点,直到没有节点p>MaxPChance.
MaxPChance是在生成决策树之前定义的魔法数。如果我们设置MaxPChance=0.1,那么剪枝后
十、数值型输入
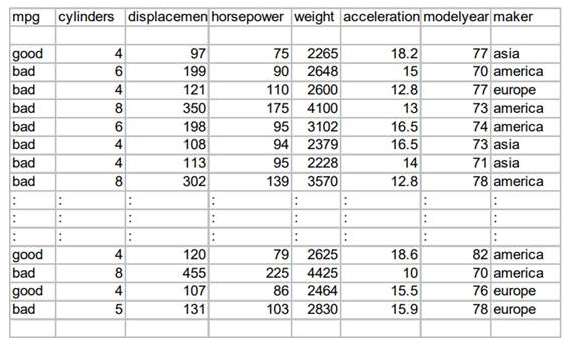
通过划分区间解决。
如何划分?
定义
对每个需要划分区间的数值型属性,用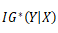 对其进行划分。
对其进行划分。
计算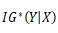 所需时间:
所需时间:
R---------------------该属性中的记录数
![]() --------------------该属性可能的取值数
--------------------该属性可能的取值数
十一、另一种分类方法

十二、总结
决策树优点: (1)速度快: 计算量相对较小, 且容易转化成分类规则. 只要沿着树根向下一直走到叶, 沿途的分裂条件就能够唯一确定一条分类。 (2)准确性高: 挖掘出来的分类规则准确性高, 便于理解, 决策树可以清晰的显示哪些字段比较重要。
(3)可以处理连续和种类字段。
缺点: (1)对于各类别样本数量不一致的数据, 信息增益偏向于那些更多数值的特征。 (2)容易过拟合。 (3)忽略属性之间的相关性。
实现代码:
1 from sklearn.feature_extraction import DictVectorizer 2 import csv 3 from sklearn import preprocessing,tree 4 5 allElectronicsData = open(r'C:\Users\dd\Desktop\cs_desktop\ex1.csv','r') 6 reader = csv.reader(allElectronicsData) 7 headers = next(reader) 8 9 featureList = [] 10 labelList = [] 11 12 for row in reader: 13 labelList.append(row[len(row)-1]) 14 rowDict = {} 15 for i in range(1,len(row)-1): 16 rowDict[headers[i]] = row[i] 17 featureList.append(rowDict) 18 19 vec = DictVectorizer() 20 dummyX = vec.fit_transform(featureList).toarray() 21 22 23 lb = preprocessing.LabelBinarizer() 24 dummyY = lb.fit_transform(labelList) 25 26 clf = tree.DecisionTreeClassifier(criterion='entropy') 27 clf = clf.fit(dummyX,dummyY) 28 29 with open("course1.dot",'w')as f: 30 f = tree.export_graphviz(clf, feature_names = vec.get_feature_names(),out_file = f) 31 32 oneRowX = dummyX[0,:] 33 newRowX = oneRowX.copy() 34 35 newRowX[0] = 1 36 newRowX[2] = 0 37 38 newRowXX = [] 39 newRowXX.append(oneRowX) 40 newRowXX.append(newRowX) 41 42 43 predictedY = clf.predict(newRowXX) 44 print("predictedY="+str(predictedY))
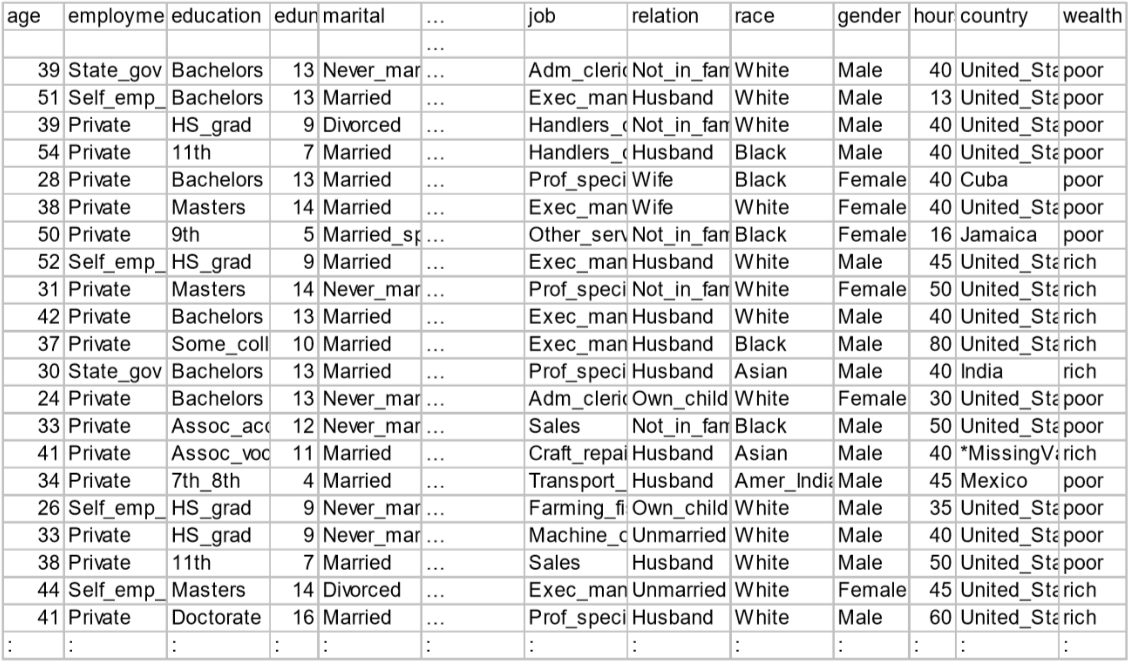
数据集: