Hive 面试题——HiveSQL 执行顺序
描述
今天刷到了一个面试题:hivesql 执行顺序,接下来就从一个带有 group by 的例子看看 hivesql 的执行顺序
执行顺序为
from ..on .. join .. where .. group by .. having .. select .. distinct .. order by .. limit
测试数据
desc movies; id int title_name varchar(25) score double select * from movies; 1007 侠客行 80.66 1008 小李飞刀 97.66 1005 流星蝴蝶剑 86.31 1006 萍踪侠影 85.75 1009 绝代双骄 81 1010 碧血剑 82.9 1011 射雕英雄传 92.88 1012 武林外传 88.95 1001 笑傲镜湖 91.69 1002 倚天屠龙记 95.21 1003 神雕侠侣 96.32 1004 孔雀翎 79.29
执行SQL
select id, title_name, min(score) min_score from movies group by id, title_name having min_score >= 80 order by id;
结果
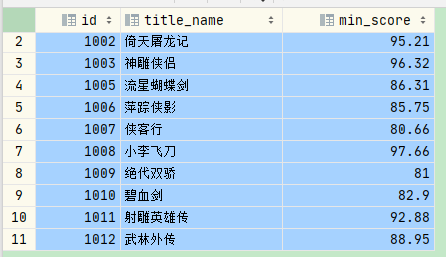
执行顺序:
from … where … select … group by … having … order by …
其实总结hive的执行顺序也是总结mapreduce的执行顺序:
MR程序的执行顺序:
map阶段:
1.执行from加载,进行表的查找与加载
2.执行where过滤,进行条件过滤与筛选
3.执行select查询:进行输出项的筛选
4.执行group by分组:描述了分组后需要计算的函数
5.map端文件合并:map端本地溢出写文件的合并操作,每个map最终形成一个临时文件。 然后按列映射到对应的reduceReduce阶段:
Reduce阶段:
1.group by:对map端发送过来的数据进行分组并进行计算。
2.select:最后过滤列用于输出结果
3.limit排序后进行结果输出到HDFS文件
所以通过上面的例子我们可以看到,在进行selectt之后我们会形成一张表,在这张表当中做分组排序这些操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号