

Hive窗口函数中range和rows的区别
说明
聊到 hive,就少不了灵活的开窗函数,今天介绍下开窗函数中 over 子句内部经常会用到的 rows 和 range 的用法;
数据准备

create table temp_id_0116 ( id int ) stored as orc tblproperties ("orc.compress" = "snappy"); insert into temp_id_0116 (id) values (1), (1), (3), (6), (6), (6), (7), (8), (9); select * from temp_id_0116; 1 1 3 6 6 6 7 8 9
查询演示
select id, sum(id) over (order by id ) default_num, sum(id) over (order by id range between unbounded preceding and current row) range_sum, sum(id) over (order by id rows between unbounded preceding and current row) rows_sum, sum(id) over (order by id range between 1 preceding and 2 following) range_sum1, sum(id) over (order by id rows between 1 preceding and 2 following) rows_sum1 from temp_id_0116;
结果: 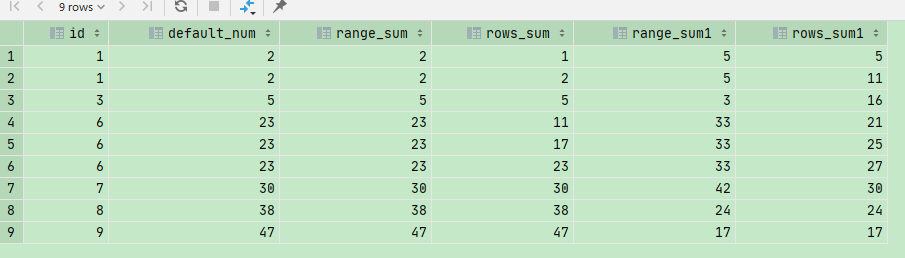 注意:
注意:
rows 是物理窗口,是哪一行就是哪一行,与当前行的值(order by key 的 key 的值)无关,只与排序后的行号相关,就是我们常规理解的那样。 range 是逻辑窗口,与当前行的值有关(order by key 的 key 的值),在 key 上操作 range 范围。
结果分析
1.当order by后面的rows/range缺失时,默认是range between unbounded preceding and current row
2、range_sum 按照 order by 的值进行划分窗口大小,由于出现两个id = 1 的记录,两个1 会划分到同一个窗口,所以第一行和第二行两个1进行了求和都是2,第三行进行累加5,第4 5 6 三行都是6,再一次同时划分到了同一个窗口进行累加,7 8 9 分别和第3行一样
3、rows_sum :rows 与排序值无关,与排序后的序号有关,所以在进行汇总求和的时候,即使遇到数值相同的数据,但是由于排序后的序号不同,不会将两个相同的数同时划分到同一个窗口。
后面两列划分方式和之前两列一样;
平时工作中 range可应用于订单日期等纬度值,rows可应用于金额,用户数汇总值;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
2022-02-06 hive 字符串模糊匹配的实现两种实现方案