ClickHouse 建表优化
1、数据类型
1.1、时间字段类型
建表时能用数值型或日期时间型表示的字段就不要用字符串,全String类型在以Hive为中心的数仓建设中常见,但ClickHouse环境不应受此影响。虽然ClickHouse底层将DateTime存储为时间戳Long类型,但不建议存储Long类型,因为DateTime不需要经过函数转换处理,执行效率高、可读性好。
执行下面建表语句
create table t_type2( id UInt32, sku_id String, total_amount Decimal(16,2) , create_time Int32 ) engine =ReplacingMergeTree(create_time) partition by toYYYYMMDD(toDate(create_time)) –-需要转换一次,否则报错 primary key (id) order by (id, sku_id); 说明:create_time 建表时类型指明 int32,分区时需要使用 toDate 进行转换 直接使用 DateTime ,分区时不用进行 toDate,方便一些
报错
Code: 43, e.displayText() = DB::Exception: Illegal type Int32 of argument of function toYYYYMMDD. Should be a date or a date with time: While processing toYYYYMMDD(create_time) (version 21.7.3.14 (official build))
改为时间类型即可,此处无需转换
create table t_type2( id UInt32, sku_id String, total_amount Decimal(16,2) , create_time DateTime ) engine =ReplacingMergeTree(create_time) partition by toYYYYMMDD(create_time) primary key (id) order by (id, sku_id);
1.2、空值存储类型
官方已经指出Nullable类型几乎总是会拖累性能,因为存储Nullable列时需要创建一个额外的文件来存储NULL的标记,并且Nullable列无法被索引。因此除非极特殊情况,应直接使用字段默认值表示空,或者自行指定一个在业务中无意义的值(例如用-1表示没有商品ID)。
CREATE TABLE t_null ( x Int8, y Nullable(Int8) ) ENGINE TinyLog; INSERT INTO t_null VALUES (1, NULL), (2, 3); SELECT x + y FROM t_null;
dategrip 效果
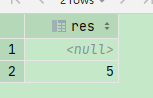
小窗口效果
hadoop201 :) SELECT x + y :-] FROM t_null; SELECT x + y FROM t_null Query id: 10634f73-6643-4a35-bb66-7168a4f2a2fd ┌─plus(x, y)─┐ │ ᴺᵁᴸᴸ │ │ 5 │ └────────────┘ 2 rows in set. Elapsed: 0.008 sec.
存储信息:y 值单独存储null
/var/lib/clickhouse/data/default/t_null [root@hadoop201 t_null]# ll total 16 -rw-r----- 1 clickhouse clickhouse 91 Aug 4 14:06 sizes.json -rw-r----- 1 clickhouse clickhouse 28 Aug 4 14:06 x.bin -rw-r----- 1 clickhouse clickhouse 28 Aug 4 14:06 y.bin -rw-r----- 1 clickhouse clickhouse 28 Aug 4 14:06 y.null.bin
2、分区和索引
分区粒度根据业务特点决定,不宜过粗或过细。一般选择按天分区,也可以指定为Tuple(),以单表一亿数据为例,分区大小控制在10-30个为最佳。必须指定索引列,ClickHouse中的索引列即排序列,通过order by指定,一般在查询条件中经常被用来充当筛选条件的属性被纳入进来;可以是单一维度,也可以是组合维度的索引;通常需要满足高级列在前、查询频率大的在前原则;还有基数特别大的不适合做索引列,如用户表的userid字段;通常筛选后的数据满足在百万以内为最佳。
比如官方案例的hits_v1表:
…… PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate, intHash32(UserID)) ……
visits_v1表
…… PARTITION BY toYYYYMM(StartDate) ORDER BY (CounterID, StartDate, intHash32(UserID), VisitID) ……
3、表参数
Index_granularity是用来控制索引粒度的,默认是8192,如非必须不建议调整。如果表中不是必须保留全量历史数据,建议指定TTL(生存时间值),可以免去手动过期历史数据的麻烦,TTL 也可以通过alter table语句随时修改。(参考基础文档4.4.5 数据TTL)
4、写入和删除优化
(1)尽量不要执行单条或小批量删除和插入操作,这样会产生小分区文件,给后台Merge任务带来巨大压力
(2)不要一次写入太多分区,或数据写入太快,数据写入太快会导致Merge速度跟不上而报错,一般建议每秒钟发起2-3次写入操作,每次操作写入2w~5w条数据(依服务器性能而定)
写入过快报错,报错信息:
1. Code: 252, e.displayText() = DB::Exception: Too many parts(304). Merges are processing significantly slower than inserts 2. Code: 241, e.displayText() = DB::Exception: Memory limit (for query) exceeded:would use 9.37 GiB (attempt to allocate chunk of 301989888 bytes), maximum: 9.31 GiB
处理方式:
“ Too many parts 处理 ” :使用WAL预写日志,提高写入性能。 in_memory_parts_enable_wal 默认为 true;在服务器内存充裕的情况下增加内存配额,一般通过max_memory_usage来实现;在服务器内存不充裕的情况下,建议将超出部分内容分配到系统硬盘上,但会降低执行速度,一般通过max_bytes_before_external_group_by、max_bytes_before_external_sort参数来实现。
5、常用配置
配置项主要在config.xml或users.xml中, 基本上都在users.xml里
5.1、CPU 优化
|
配置
|
描述
|
|
background_pool_size
|
后台线程池的大小,merge线程就是在该线程池中执行,该线程池不仅仅是给merge线程用的,默认值16,允许的前提下建议改成cpu个数的2倍(线程数)。
|
|
background_schedule_pool_size
|
执行后台任务(复制表、Kafka流、DNS缓存更新)的线程数。默认128,建议改成cpu个数的2倍(线程数)。
|
|
background_distributed_schedule_pool_size
|
设置为分布式发送执行后台任务的线程数,默认16,建议改成cpu个数的2倍(线程数)。
|
|
max_concurrent_queries
|
最大并发处理的请求数(包含select,insert等),默认值100,推荐150(不够再加)~300。
|
|
max_threads
|
设置单个查询所能使用的最大cpu个数,默认是cpu核数
|
5.2、内存资源
|
配置
|
描述
|
|
max_memory_usage
|
此参数在users.xml 中,表示单次Query占用内存最大值,该值可以设置的比较大,这样可以提升集群查询的上限。
保留一点给OS,比如128G内存的机器,设置为100GB。
|
|
max_bytes_before_external_group_by
|
一般按照max_memory_usage的一半设置内存,当group使用内存超过阈值后会刷新到磁盘进行。
因为clickhouse聚合分两个阶段:查询并及建立中间数据、合并中间数据,结合上一项,建议50GB。
|
|
max_bytes_before_external_sort
|
当order by已使用max_bytes_before_external_sort内存就进行溢写磁盘(基于磁盘排序),如果不设置该值,那么当内存不够时直接抛错,设置了该值order by可以正常完成,但是速度相对存内存来说肯定要慢点(实测慢的非常多,无法接受)。
|
|
max_table_size_to_drop
|
此参数在 config.xml 中,应用于需要删除表或分区的情况,默认是50GB,意思是如果删除50GB以上的分区表会失败。建议修改为0,这样不管多大的分区表都可以删除。
|
5.3、存储
ClickHouse不支持设置多数据目录,为了提升数据io性能,可以挂载虚拟券组,一个券组绑定多块物理磁盘提升读写性能,多数据查询场景SSD会比普通机械硬盘快2-3倍;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号