RDD 依赖关系
1、血缘关系&依赖关系
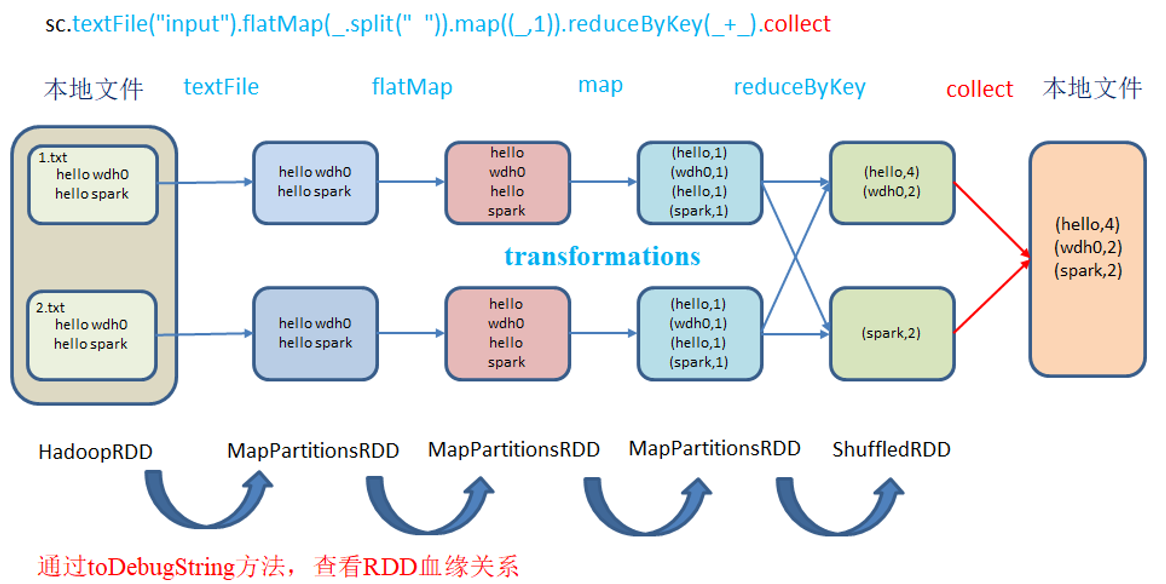
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
血缘关系
依赖关系
代码实现
object Spark01_lineage {
def main(args: Array[String]): Unit = {
//创建 配置对象
val conf: SparkConf = new SparkConf().setAppName("wordcount").setMaster("local[*]")
//配置上下文对象
var sc: SparkContext = new SparkContext(conf)
val rdd: RDD[String] = sc.makeRDD(List("hello spark", "flink", "hello", "word hello"))
//rdd 血缘关系
println(rdd.toDebugString)
println(rdd.dependencies)
println("**************************************")
val flatMap: RDD[String] = rdd.flatMap(_.split(" "))
println(flatMap.toDebugString)
println(flatMap.dependencies)
println("**************************************")
val map: RDD[(String, Int)] = flatMap.map((_, 1))
println(map.toDebugString)
println(map.dependencies)
println("**************************************")
val resRDD: RDD[(String, Int)] = map.reduceByKey(_ + _)
println(resRDD.toDebugString)
println(resRDD.dependencies)
resRDD.collect().foreach(println)
//关闭
sc.stop()
}
}
血缘关系
(4) ParallelCollectionRDD[0] at makeRDD at Spark01_lineage.scala:15 [] ************************************** (4) MapPartitionsRDD[1] at flatMap at Spark01_lineage.scala:20 [] | ParallelCollectionRDD[0] at makeRDD at Spark01_lineage.scala:15 [] ************************************** (4) MapPartitionsRDD[2] at map at Spark01_lineage.scala:24 [] | MapPartitionsRDD[1] at flatMap at Spark01_lineage.scala:20 [] | ParallelCollectionRDD[0] at makeRDD at Spark01_lineage.scala:15 [] ************************************** (4) ShuffledRDD[3] at reduceByKey at Spark01_lineage.scala:28 [] +-(4) MapPartitionsRDD[2] at map at Spark01_lineage.scala:24 [] | MapPartitionsRDD[1] at flatMap at Spark01_lineage.scala:20 [] | ParallelCollectionRDD[0] at makeRDD at Spark01_lineage.scala:15 []
血缘关系说明
(4) ParallelCollectionRDD[0] at makeRDD at Spark01_lineage.scala:15 [] //第15行通过集合创建RDD,makeRDD 是 ParallelCollectionRDD 的封装 ************************************** (4) MapPartitionsRDD[1] at flatMap at Spark01_lineage.scala:20 [] //第20行通过flatMap创建RDD,flatMap 是 MapPartitionsRDD的封装 | ParallelCollectionRDD[0] at makeRDD at Spark01_lineage.scala:15 [] ************************************** (4) MapPartitionsRDD[2] at map at Spark01_lineage.scala:24 [] //第24行map转换结构,map 也是 MapPartitionsRDD的封装 | MapPartitionsRDD[1] at flatMap at Spark01_lineage.scala:20 [] | ParallelCollectionRDD[0] at makeRDD at Spark01_lineage.scala:15 [] ************************************** (4) ShuffledRDD[3] at reduceByKey at Spark01_lineage.scala:28 [] //28行执行了 reduceByKey ,存在shuffle,单独列了一行 +-(4) MapPartitionsRDD[2] at map at Spark01_lineage.scala:24 [] | MapPartitionsRDD[1] at flatMap at Spark01_lineage.scala:20 [] | ParallelCollectionRDD[0] at makeRDD at Spark01_lineage.scala:15 []
整个RDD的血缘关系是从下至上的,输出的依赖关系
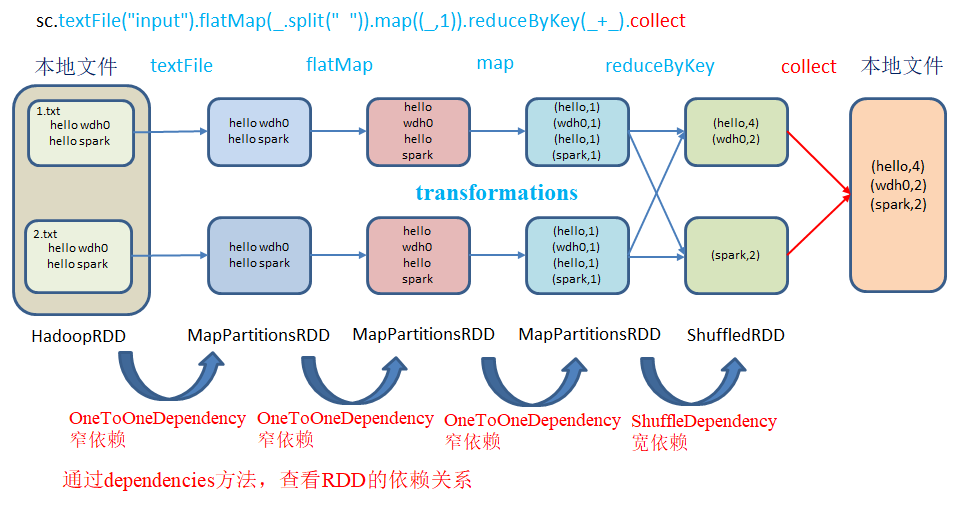
List() List(org.apache.spark.OneToOneDependency@27d57a2c) List(org.apache.spark.OneToOneDependency@59532566) List(org.apache.spark.ShuffleDependency@5524b72f)
全局搜索(ctrl+n)org.apache.spark.OneToOneDependency
@DeveloperApi
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}
NarrowDependency 即窄依赖,查看当前类名是
@DeveloperApi
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
按 ctrl + h 查看实现方法

注意:要想理解RDD是如何工作的,最重要的就是理解Transformations。
RDD 之间的关系可以从两个维度来理解: 一个是 RDD 是从哪些 RDD 转换而来, 也就是 RDD 的 parent RDD(s)是什么; 另一个就是 RDD 依赖于 parent RDD(s)的哪些 Partition(s). 这种关系就是 RDD 之间的依赖.
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)
2、宽/窄依赖
窄依赖 窄依赖表示每一个父RDD的Partition最多被子RDD的一个Partition使用,窄依赖我们形象的比喻为独生子女。
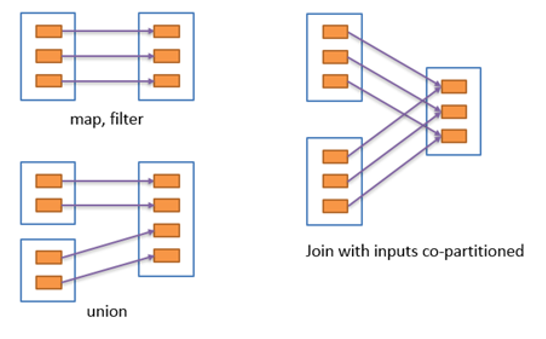
宽依赖 宽依赖表示同一个父RDD的Partition被多个子RDD的Partition依赖,会引起Shuffle,总结:宽依赖我们形象的比喻为超生。
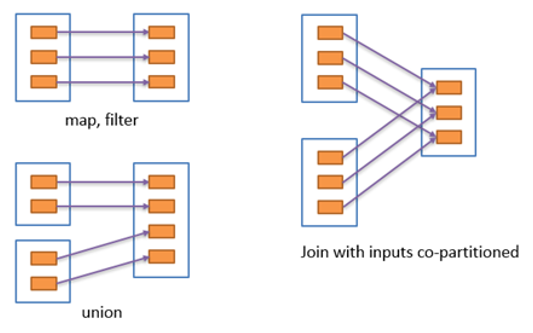
具有宽依赖的 transformations 包括: sort, reduceByKey, groupByKey, join, 和调用rePartition函数的任何操作.宽依赖对 Spark 去评估一个 transformations 有更加重要的影响, 比如对性能的影响.
3、Spark 中Job 调度
一个Spark应用包含一个驱动进程(driver process,在这个进程中写Spark的逻辑代码)和多个执行器进程(executor process,跨越集群中的多个节点)。Spark 程序自己是运行在驱动节点, 然后发送指令到执行器节点。一个Spark集群可以同时运行多个Spark应用, 这些应用是由集群管理器(cluster manager)来调度。Spark应用可以并发的运行多个job, job对应着给定的应用内的在RDD上的每个 action操作。Spark应用:一个Spark应用可以包含多个Spark job, Spark job是在驱动程序中由SparkContext 来定义的。当启动一个 SparkContext 的时候, 就开启了一个 Spark 应用。 一个驱动程序被启动了, 多个执行器在集群中的多个工作节点(worker nodes)也被启动了。 一个执行器就是一个 JVM, 一个执行器不能跨越多个节点, 但是一个节点可以包括多个执行器。一个 RDD 会跨多个执行器被并行计算. 每个执行器可以有这个 RDD 的多个分区, 但是一个分区不能跨越多个执行器.
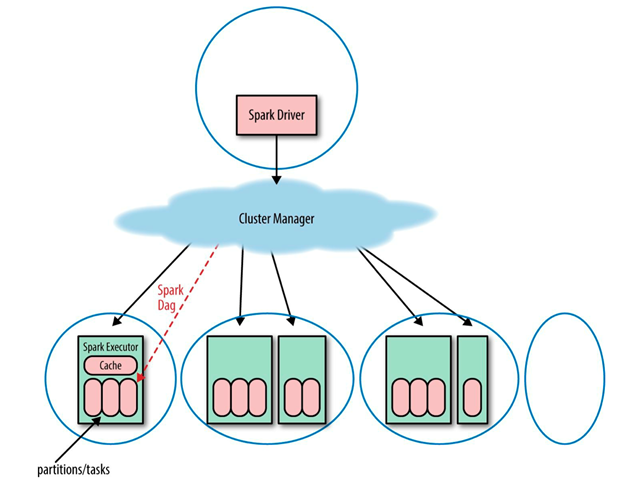
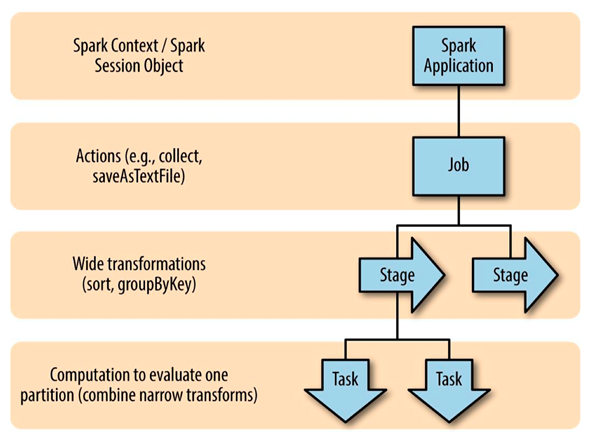
Spark Job 的划分:由于Spark的懒执行, 在驱动程序调用一个action之前, Spark 应用不会做任何事情,针对每个action,Spark 调度器就创建一个执行图(execution graph)和启动一个 Spark job。每个 job 由多个stages 组成, 这些 stages 就是实现最终的 RDD 所需的数据转换的步骤。一个宽依赖划分一个stage。每个 stage 由多个 tasks 来组成, 这些 tasks 就表示每个并行计算, 并且会在多个执行器上执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号