Spark 运行模式(local)
1、Spark 运行模式说明
部署Spark集群大体上分为两种模式:单机模式与集群模式;大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。但是在生产环境中,并不会使用单机模式。因此,后续直接按照集群模式部署Spark集群。下面详细列举了Spark目前支持的部署模式。
- Local模式:在本地部署单个Spark服务
- Standalone模式:Spark自带的任务调度模式。(国内常用)
- YARN模式:Spark使用Hadoop的YARN组件进行资源与任务调度。(国内常用)
- Mesos模式:Spark使用Mesos平台进行资源与任务的调度。
2、安装地址
说明:由于下载spark 需要参考 hadoop 版本,比如:我现在着手梳理的这套环境是基于 hdoop2.7.2,那么我下载的对应的版本是 spark-3.0.3-bin-hadoop2.7.tgz
3、Local 模式
Local 模式就是只有一个节点的的模式,通常用于学习测试;上传解压:3.0.3 是spark 版本,2.7 是对应的 hadoop 版本,3.0 是Spark版本;
3.1、解压安装,重命名安装目录
[hui@hadoop103 software]$ ll spark-3.0.3-bin-hadoop2.7.tgz -rw-r--r-- 1 hui wd 220400553 3月 13 05:55 spark-3.0.3-bin-hadoop2.7.tgz [hui@hadoop103 software]$ tar -zxvf spark-3.0.3-bin-hadoop2.7.tgz -C /opt/module/ [hui@hadoop103 module]$ cp -r spark-3.0.3-bin-hadoop2.7 spark-local [hui@hadoop103 module]$ cd spark-local/ [hui@hadoop103 spark-local]$ ll 总用量 156 drwxr-xr-x 2 hui wd 4096 5月 21 09:14 bin drwxr-xr-x 2 hui wd 4096 5月 21 09:14 conf drwxr-xr-x 5 hui wd 4096 5月 21 09:14 data drwxr-xr-x 4 hui wd 4096 5月 21 09:14 examples drwxr-xr-x 2 hui wd 20480 5月 21 09:14 jars drwxr-xr-x 4 hui wd 4096 5月 21 09:14 kubernetes -rw-r--r-- 1 hui wd 23312 5月 21 09:14 LICENSE drwxr-xr-x 2 hui wd 4096 5月 21 09:14 licenses -rw-r--r-- 1 hui wd 57677 5月 21 09:14 NOTICE drwxr-xr-x 7 hui wd 4096 5月 21 09:14 python drwxr-xr-x 3 hui wd 4096 5月 21 09:14 R -rw-r--r-- 1 hui wd 4488 5月 21 09:14 README.md -rw-r--r-- 1 hui wd 183 5月 21 09:14 RELEASE drwxr-xr-x 2 hui wd 4096 5月 21 09:14 sbin drwxr-xr-x 2 hui wd 4096 5月 21 09:14 yarn
3.2、官方求PI案例
[hui@hadoop103 spark-local]$ bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[2] \ ./examples/jars/spark-examples_2.12-3.0.3.jar \ 20
运行结果
Pi is roughly 3.1417835708917856
参数说明:
--class:表示要执行程序的主类; --master local[2] local: 没有指定线程数,则所有计算都运行在一个线程当中,没有任何并行计算 local[K]:指定使用K个Core来运行计算,比如local[2]就是运行2个Core来执行 local[*]: 自动帮你按照CPU最多核来设置线程数。比如CPU有4核,Spark帮你自动设置4个线程计算。 spark-examples_2.12-3.0.0.jar:要运行的程序; 20:要运行程序的输入参数(计算圆周率π的次数,计算次数越多,准确率越高);
查看所有参数
hui@hadoop103 spark-local]$ bin/spark-submit
3.3、官方WordCount 案例
需求:读取hdfs指定目录下文件,统计每个单词出现的总次数。
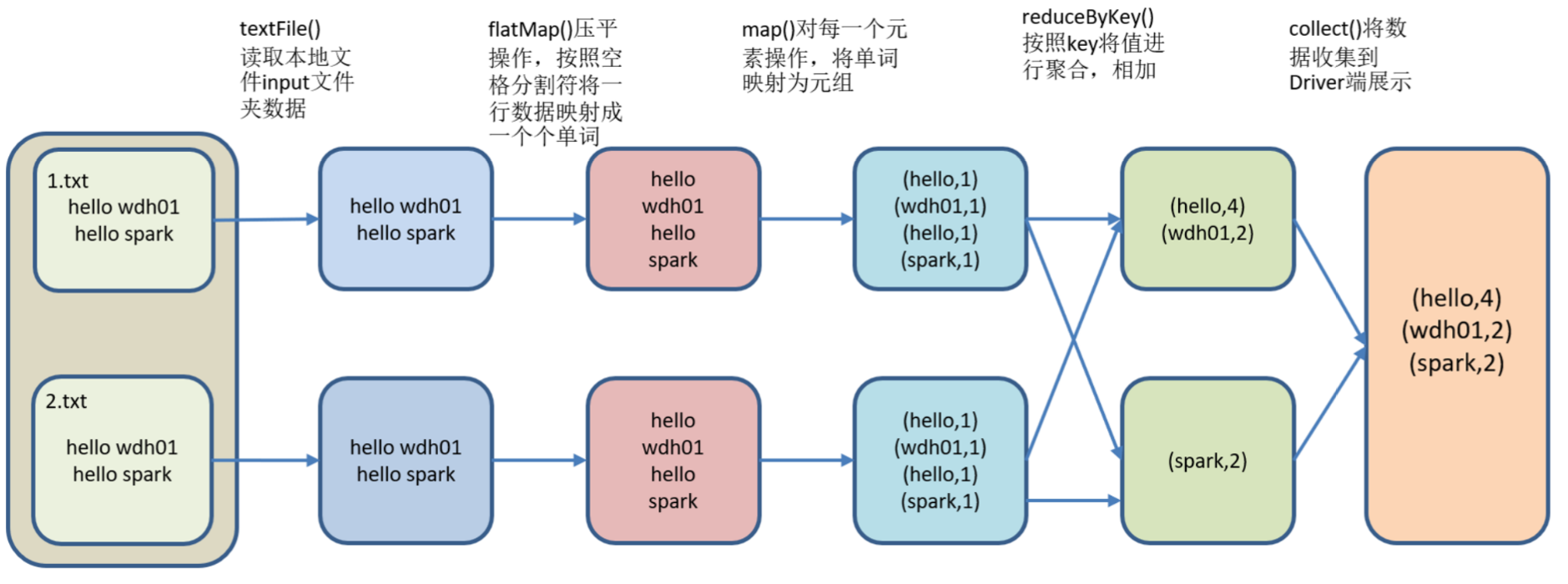
代码实现
数据准备
hui@hadoop103 bin]$ hadoop fs -mkdir /input
[hui@hadoop103 bin]$ vim 1.txt
hello wdh01
hello spark
[hui@hadoop103 bin]$ hadoop fs -put 1.txt /input
启动spark-shell
[hui@hadoop103 spark-local]$ bin/spark-shell 22/05/21 09:53:18 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://hadoop103:4040 Spark context available as 'sc' (master = local[*], app id = local-1653098014324). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3.0.3 /_/ Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144) Type in expressions to have them evaluated. Type :help for more information.
注意:sc是SparkCore程序的入口;spark是SparkSQL程序入口;master = local[*]表示本地模式运行。
spark-shell 启动后发现有一个名为 SparkSubmit 的进程
[hui@hadoop103 software]$ jps 5464 Jps 5385 SparkSubmit
运行任务方式说明:spark-submit,是将jar上传到集群,执行Spark任务;spark-shell,相当于命令行工具,本身也是一个Application。
登录hadoop103:4040,查看程序运行情况(注意:spark-shell窗口关闭掉,则hadoop102:4040页面关闭):http://hadoop103:4040/jobs/
说明:本地模式下,默认的调度器为FIFO(先进先出)。运行WordCount程序
scala> sc.textFile("hdfs://hadoop103:9000/input")
res6: org.apache.spark.rdd.RDD[String] = /input MapPartitionsRDD[23] at textFile at <console>:25
scala> sc.textFile("hdfs://hadoop103:9000/input").flatMap(_.split(" "))
res7: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[26] at flatMap at <console>:25
scala> sc.textFile("hdfs://hadoop103:9000/input").flatMap(_.split(" ")).map((_,1))
res8: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[30] at map at <console>:25
scala> sc.textFile("hdfs://hadoop103:9000/input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
res9: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[35] at reduceByKey at <console>:25
scala> sc.textFile("hdfs://hadoop103:9000/input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res11: Array[(String, Int)] = Array((wdh01,1), (hello,2), (spark,1))
注意:这里的 只有一个行动算子,collect ,只有在遇到行动算子的时候才会进行加载数据计算.
可登录hadoop103:4040查看程序运行结果;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号